kafka是apache基金會管理的開源流處理平臺(官網http://kafka.apache.org/),但國內大多數人對其認知基本都是訊息佇列,所以我們先來了解下什么是訊息佇列,
訊息佇列
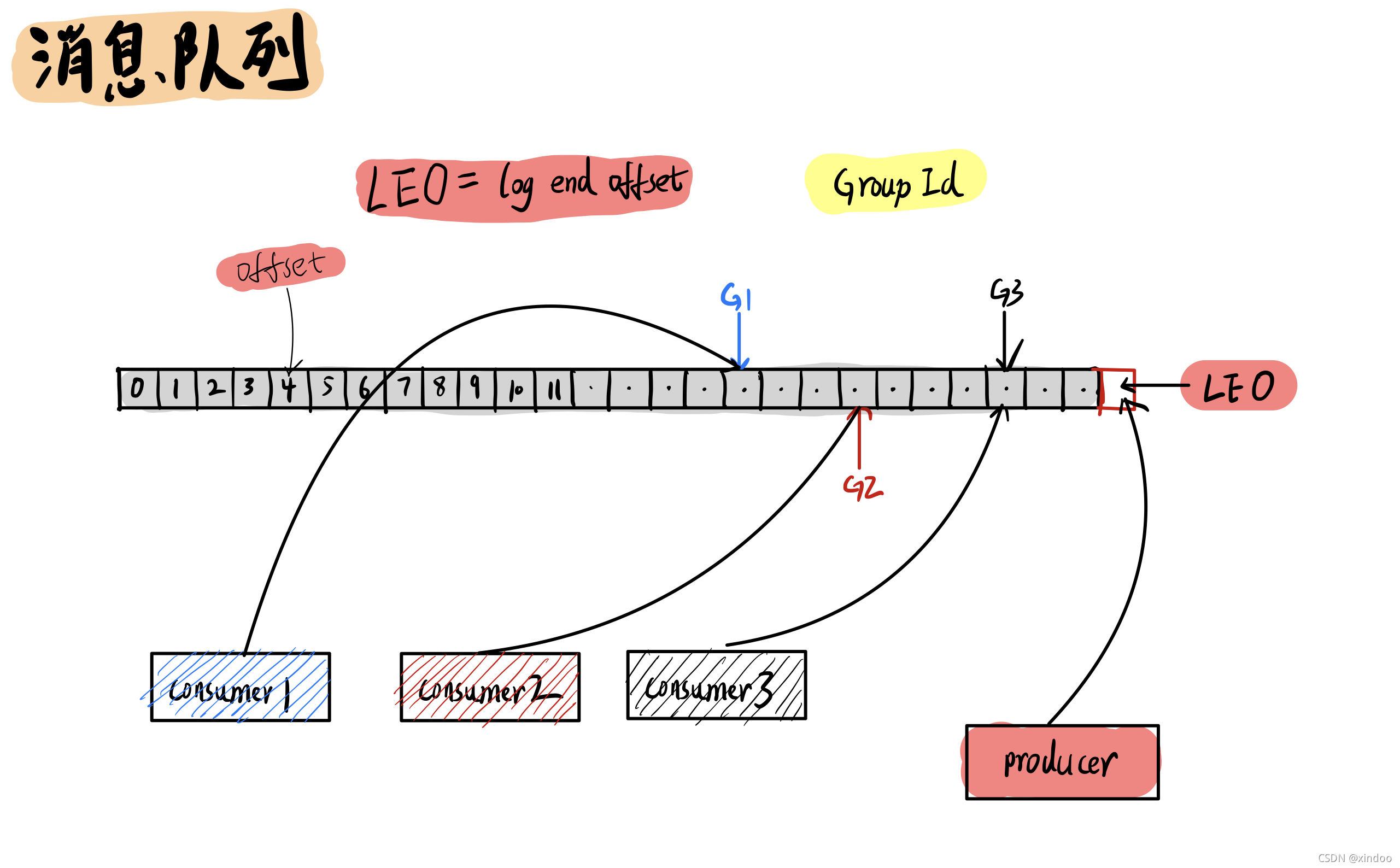
訊息佇列顧名思義就是存盤訊息的一個佇列,訊息生產者(producer) 往訊息佇列中投放訊息, 消費者(consumer)讀取訊息佇列中的內容,在訊息佇列中的每條訊息都會有個位置,就好比陣列中的下標(index),在kafka中我們稱之為offset,對于生產者而言,有個特殊的offset——LEO(log end offset) ,指向的是訊息佇列中下一個將被存放訊息的位置,
這里重點說下消費者(consumer),一個訊息佇列當然可以被多個消費者(consumer)讀取,每個消費者(consumer)都有唯一一個group-id將其區分開來,kafka也會記錄下來每個消費者(consumer)已經讀到哪個位置了(offset),
問:為什么消費者消費的offset是由kafka記錄,而不是由消費者自己記錄?
主題(Topic)
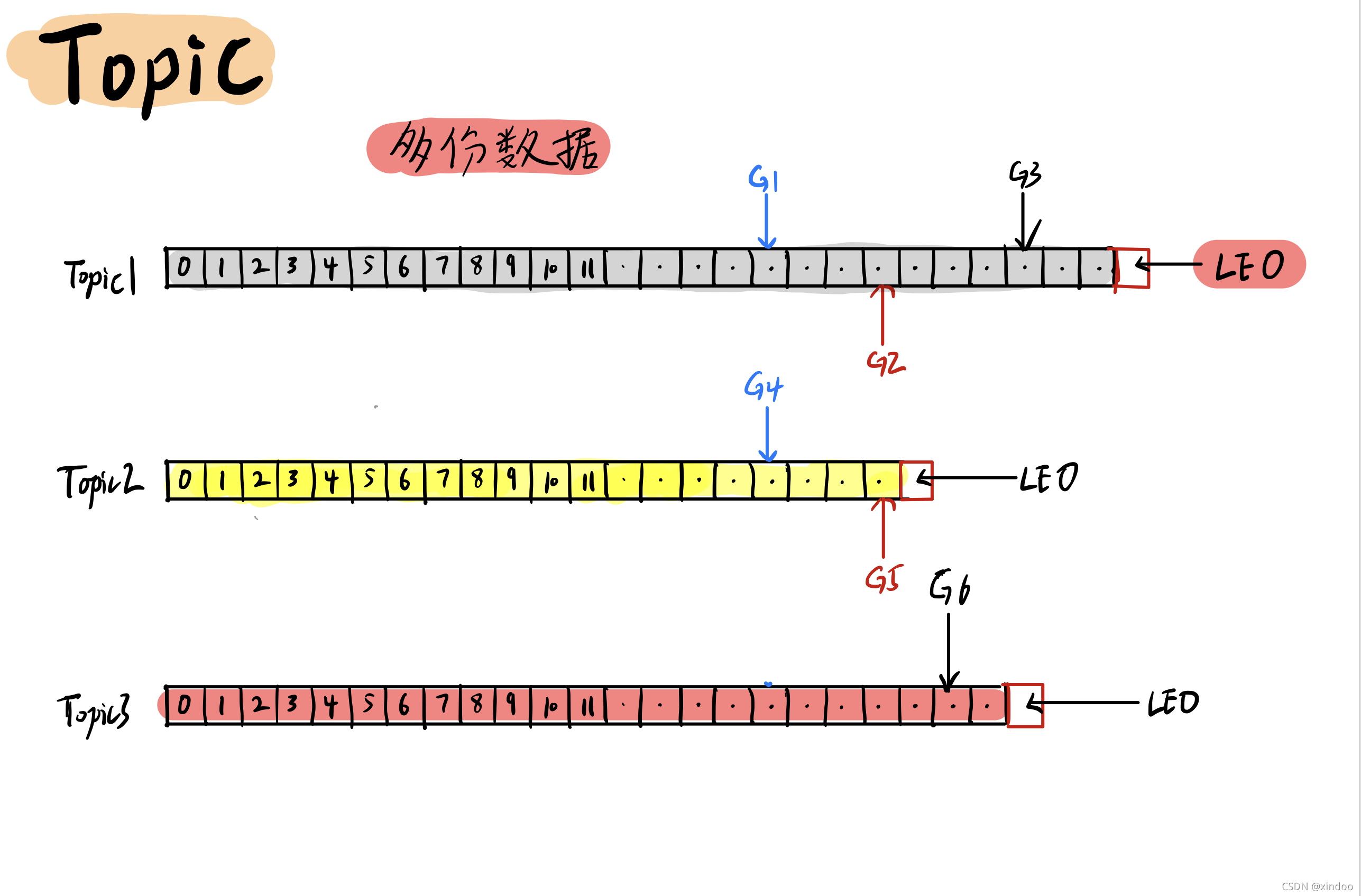
上文我們以一份資料為例,講了什么是訊息佇列,如果有多份資料(多個佇列)該怎么辦? 也很簡單,kafka中我們可以使用不同的主題(Topic)將不同的資料區分開,不同的生產者(producer)可以往不同的Topic中存放資料,不同的消費者(consumer)也可以從不同的Topic中讀取資料,
磁區(Partation)
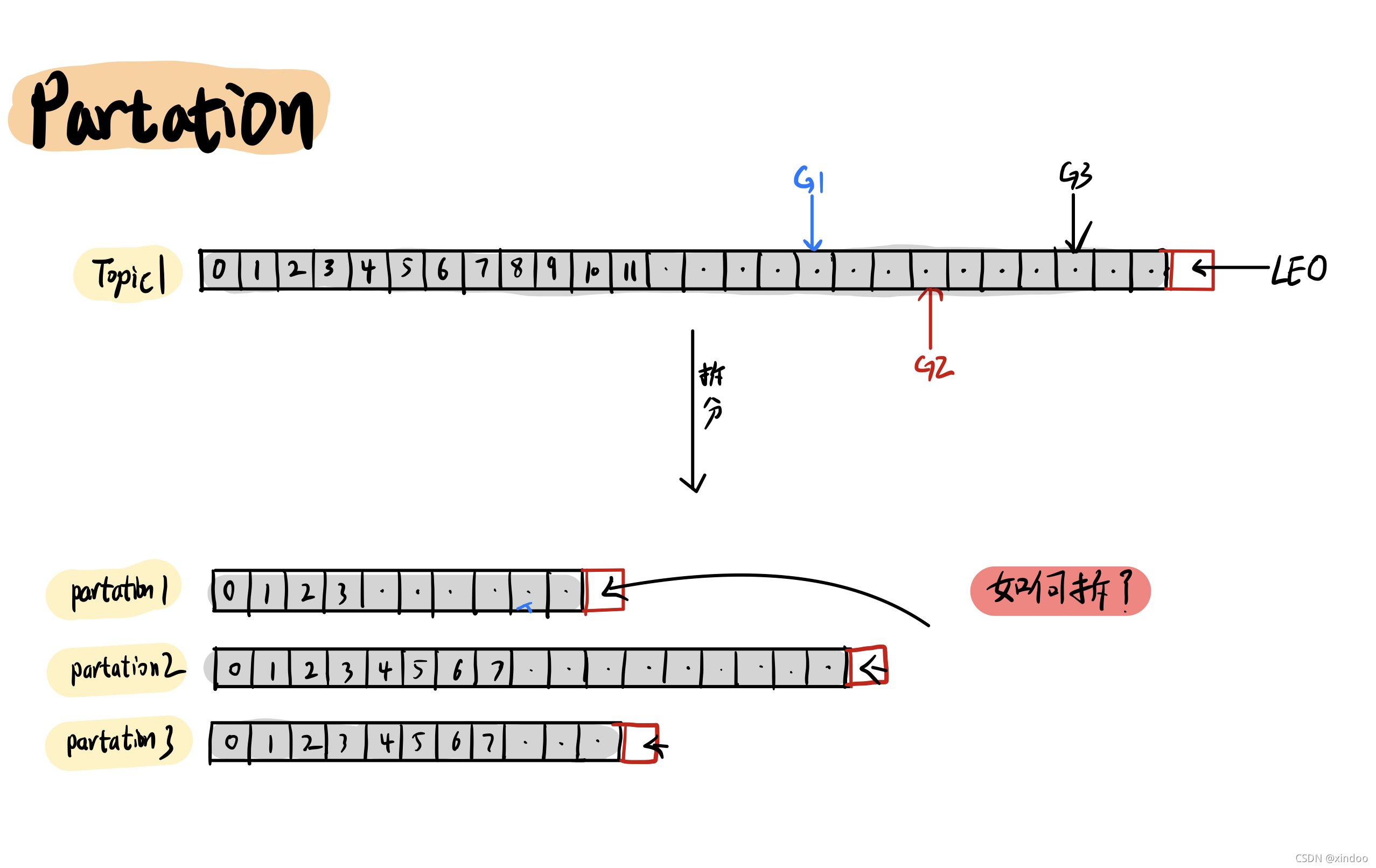
當一份資料非常大的情況下怎么辦? 當然是考慮拆分了,在kafka中,你可以設定將一個主題(Topic)拆分成多個不同的磁區(Partation),然后以磁區(Partation)的維度來管理、生產和消費資料, 拆分帶來最明顯的好處就是提升吞吐性能,多個磁區(Partation)之間并行,互不干擾,
至于怎么拆分,kafka有提供幾個默認磁區策略 輪詢、隨機、hash,當然你可以自己實作自己的磁區策略,這里就不過多展開了,
消費者組(Consumer-group)
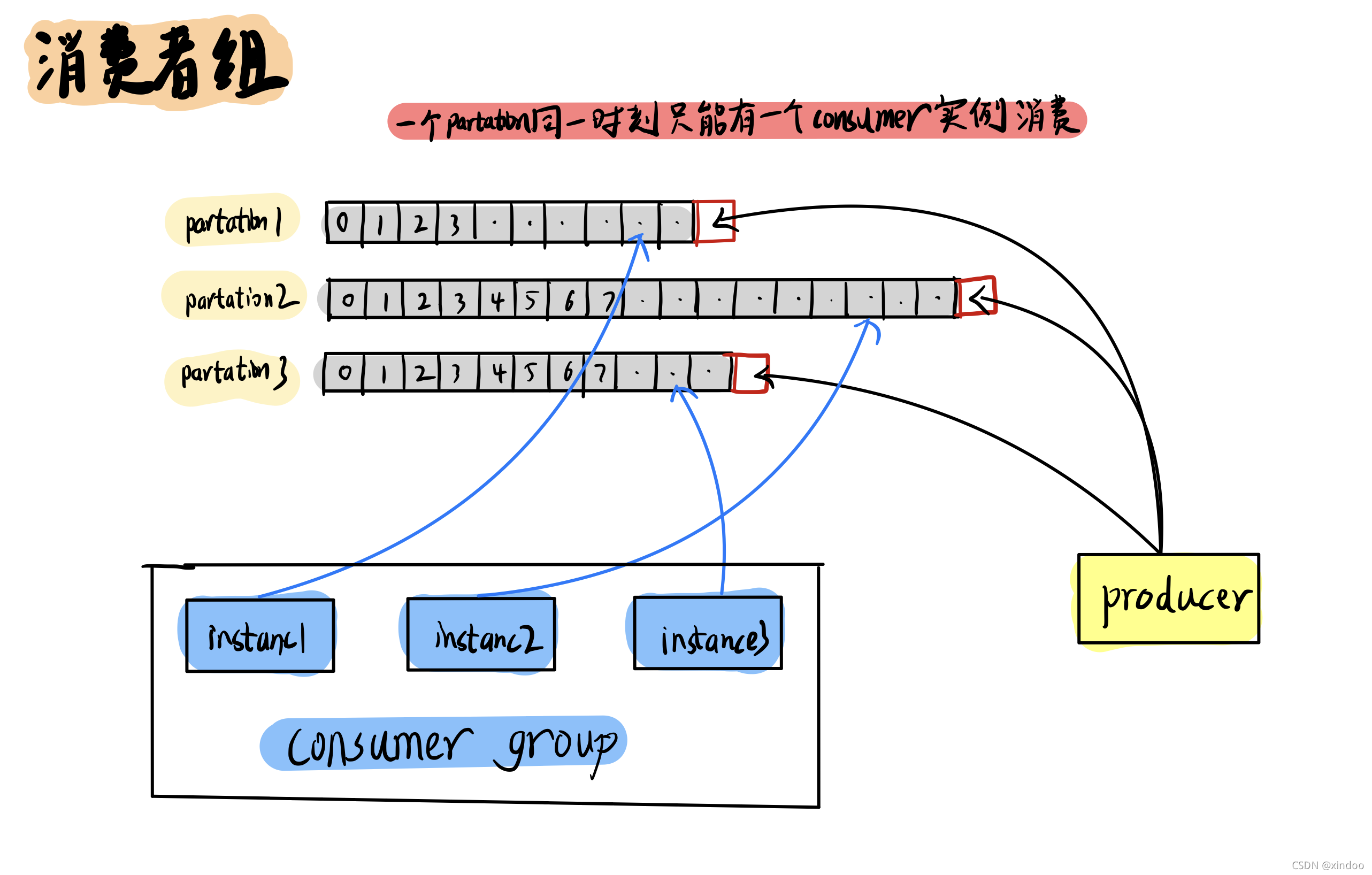
主題(Topic)做完磁區以后,消費者如何消費? 這里就不得不提到消費者組(Consumer-group)的概念,在kafka中,為了保證資料的一致性,同一個磁區(Partation)同時只能被一個消費者(consumer)實體消費,為了提升消費者(consumer)的吞吐量,一般都會設定多個消費者(consumer)實體來消費不同的磁區(Partation),這些實體共同組成一個消費者組(Consumer-group) ,他們共用一個Group-id,
注意:
- 由于同一個磁區(Partation)同時只能被一個消費者(consumer)實體消費,所以超過磁區(Partation)數量的消費者(consumer)實體個數沒有任何意義,多余的消費者(consumer)實體也會被閑置,
- 如果消費者組(Consumer-group) 中有實體發生變化(上下線),或者磁區(Partation)數量發生變化,都會觸發消費者組rebalence,
副本(Replication)
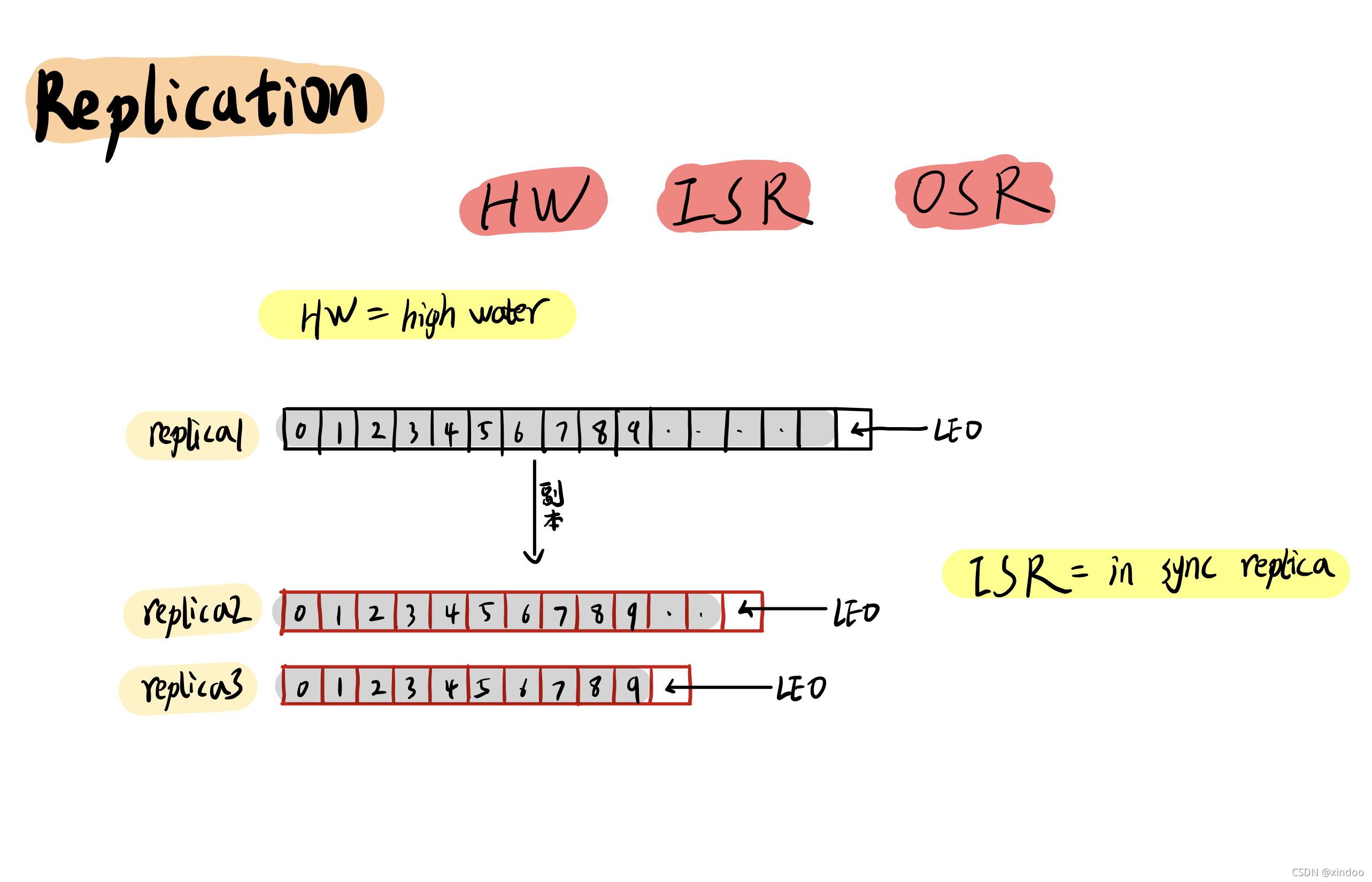
kafka如何解決資料高可用的問題?在分布式環境下,要想保證資料盡可能不丟失,唯一的方法就是多復制幾份放到不同的機器上,復制出來的資料就叫做副本(Replication),
這里有幾個關鍵詞,
HW: high-water,一個特殊的offset,只有在這個offset以下的訊息才能被消費者(consumer)讀到,高水位的具體值取決于主從副本資料同步的狀態,這里不再展開,
ISR: in-sync-replica,處于同步狀態的副本集合,是指副本資料和主副本資料相差在一定回傳(時間范圍或數量范圍)之內的副本,當然主副本肯定是一直在ISR中的, 當主副本掛了之后,新的主副本將從ISR中被選出來接替它的作業,
OSR: 和IRS相對應 out-sync-replica,其實就是指那些不在ISR中的副本,
副本主從同步
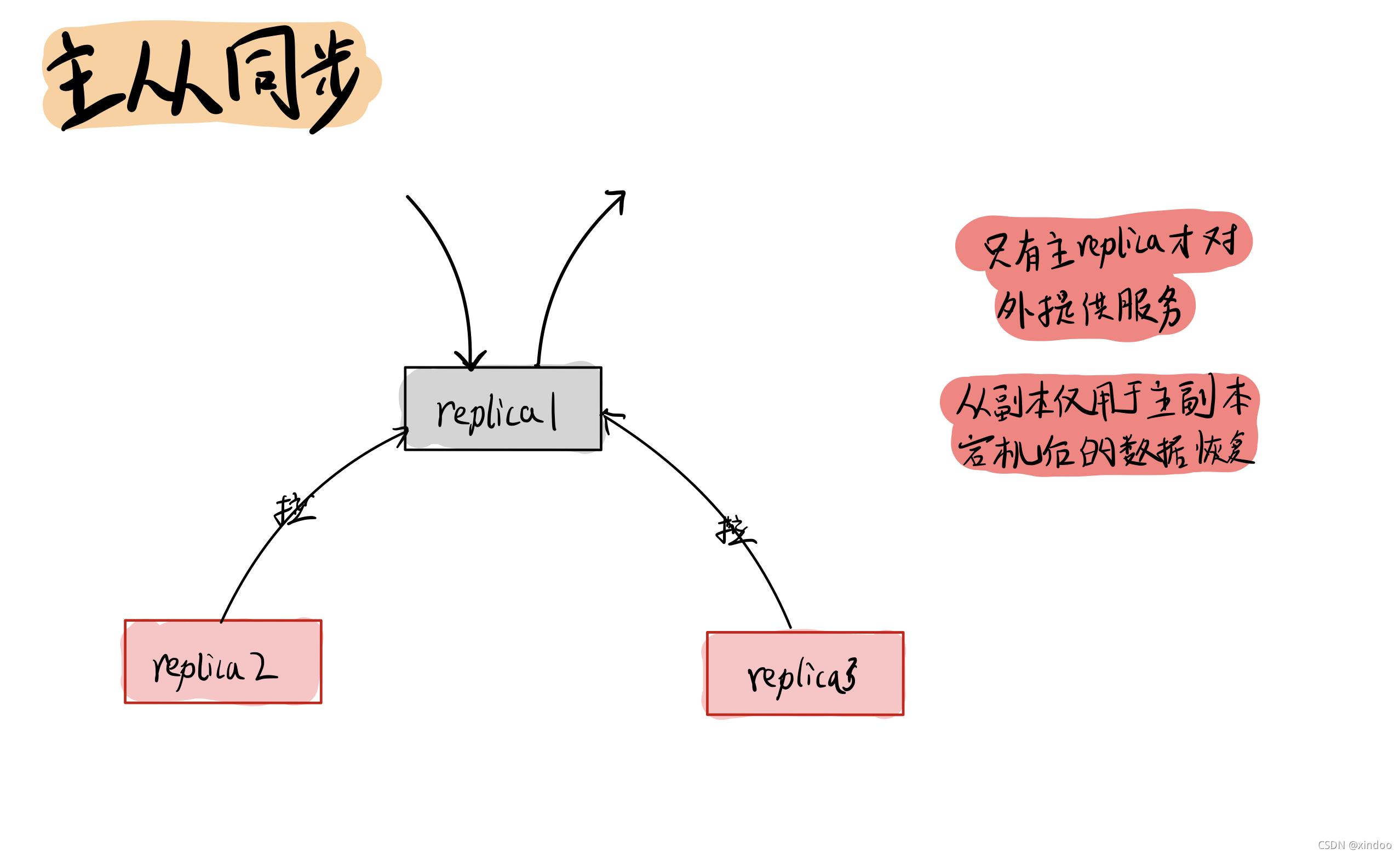
當一份資料比復制出多份副本后,肯定得涉及到主從副本的同步在,從副本會定期從主副本拉去最新的資料, 另外需要注意kafka中,只有主副本才會對外提供讀和寫(高版本kafka從副本提供了有限的讀功能),從副本的唯一作用就是給主副本當備胎,
說到主從同步,順帶提一下kafka的ack設定,
kafka中生產者(producer),可以通過request.required.acks引數來設定資料可靠性的級別:
- 0: 生產者(producer) 不等待來自主副本的確認,發出去即認為發送成功,這種情況效率最高但可能有丟失資料的風險,
- 1: (默認)生產者(producer) 發出資料后會等待主副本確認收到后,才認為訊息發送成功,這種情況下主副本宕機時可能會丟失訊息,
- -1: (或者是all):生產者(producer) 等待ISR中的所有副本都確認接收到資料后才任務訊息發送成功,可靠性最高,但因為需要等從副本拉去和確認,效率最低,
Broker
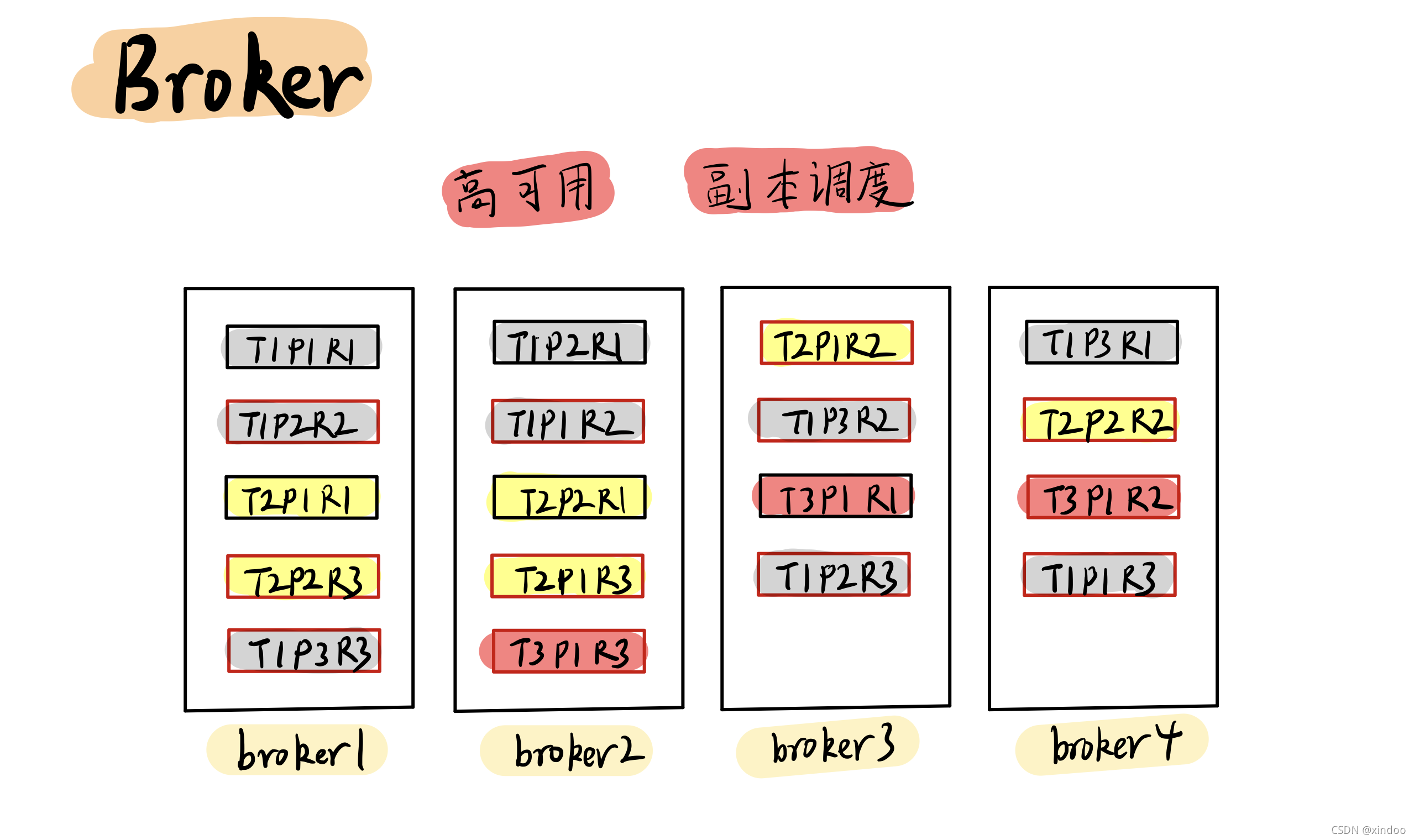
Kafka是以副本(Replica)維度管理資料的,管理這些資料肯定是需要管理者的,這個管理者就是Broker,Broker會將同一份資料的不同副本(Replication) 調度到不同的機器上,并且在副本(Replication) 數不足時生成新的副本,從而保證在部分Broker宕機后也能保證資料不丟失,
所有的Broker之間也會做一些元資料的相互同步,比如某份主資料在誰哪,從副本要從誰哪去拉取資料……
結語
第一次嘗試手繪風講解kafka入門知識,講的很粗淺,確實很多細節都沒有展開,見諒,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297708.html
標籤:Java