文章目錄
- 🍅寫在前面
- 🍉網頁分析
- 🍋完整代碼
- 🍇運行結果
- 🍈語音包下載
🍅寫在前面
上次爬取《王者榮耀》全英雄語音之后,我又找尋了全皮膚語音的資源,找了一會,雖然不是官方發布的,但是是一位網友整理的,我看了下,是非常全面的(甚至包括沒有走出體驗服的八神庵的語音),
- Python爬取王者榮耀全英雄臺詞語音及對應的文本:
https://blog.csdn.net/qq_44921056/article/details/119673018
- 網頁鏈接如下:
https://m.ximalaya.com/erciyuan/41725731/448284273
本文如有侵權,請聯系我洗掉文章!!!
🍉網頁分析
進入頁面之后,首先對網頁進行分析,
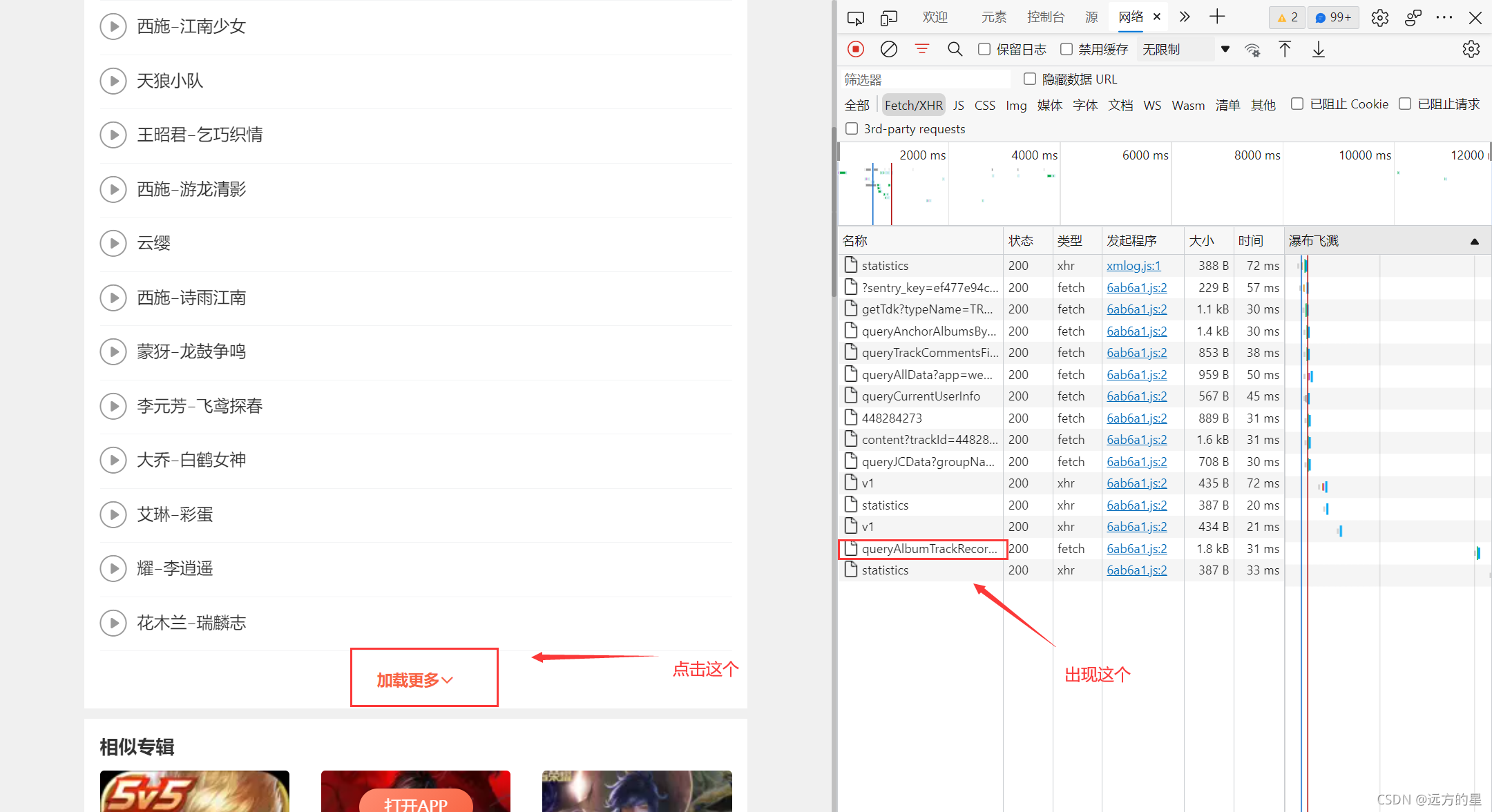
通過分析,發現語音包其實就放在json檔案里面,
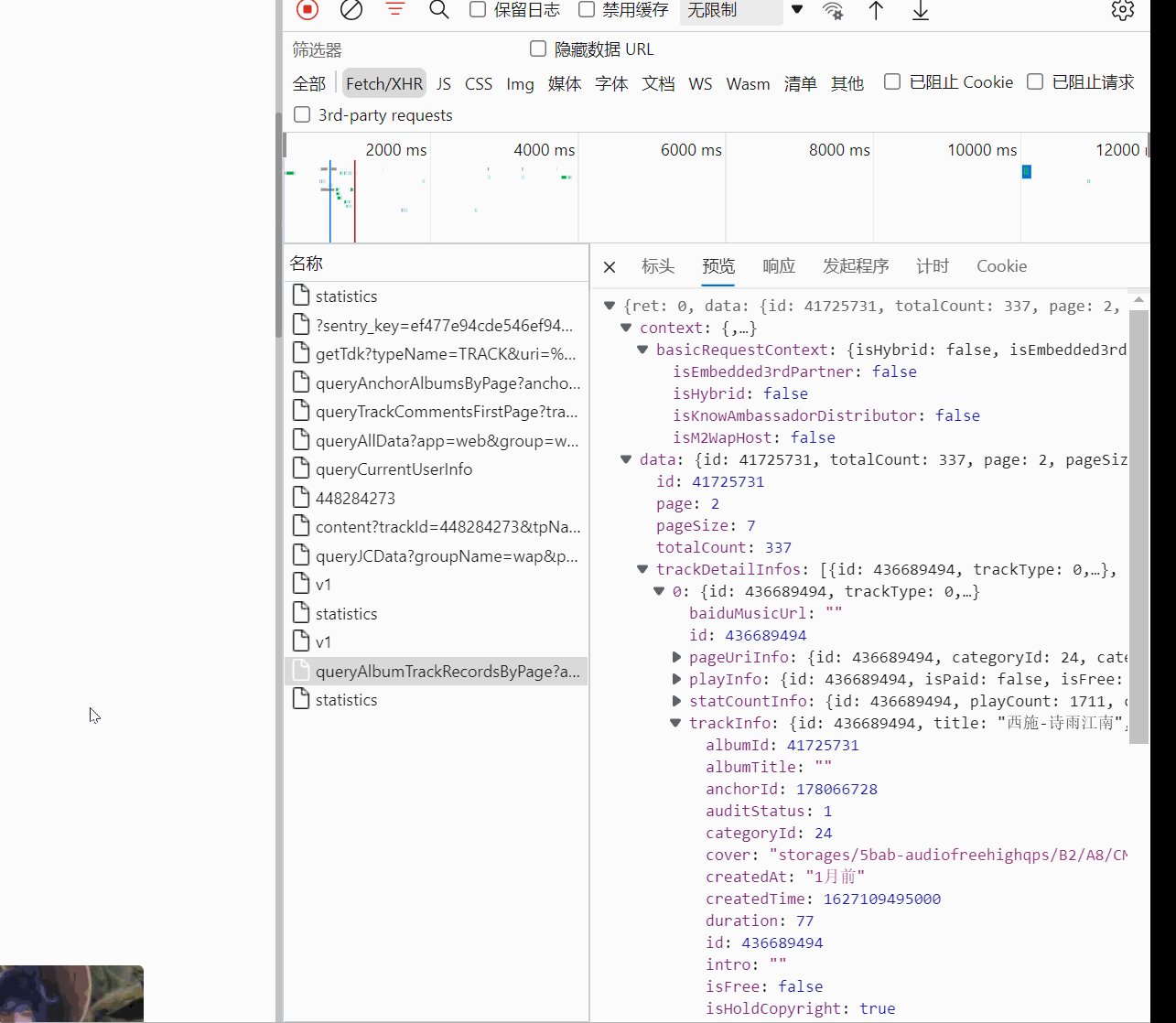
取一個鏈接,就取上面動圖選中的那個,來查看驗證一下,
https://aod.cos.tx.xmcdn.com/storages/211c-audiofreehighqps/B8/3D/CKwRIaIE0Xt6AAmdVwDM5vcs.m4a

成功出現語音頁面,且可以播放,
目標找到!!!
那么接下來就要看json檔案怎么爬取,
首先,來看一下有什么規律,
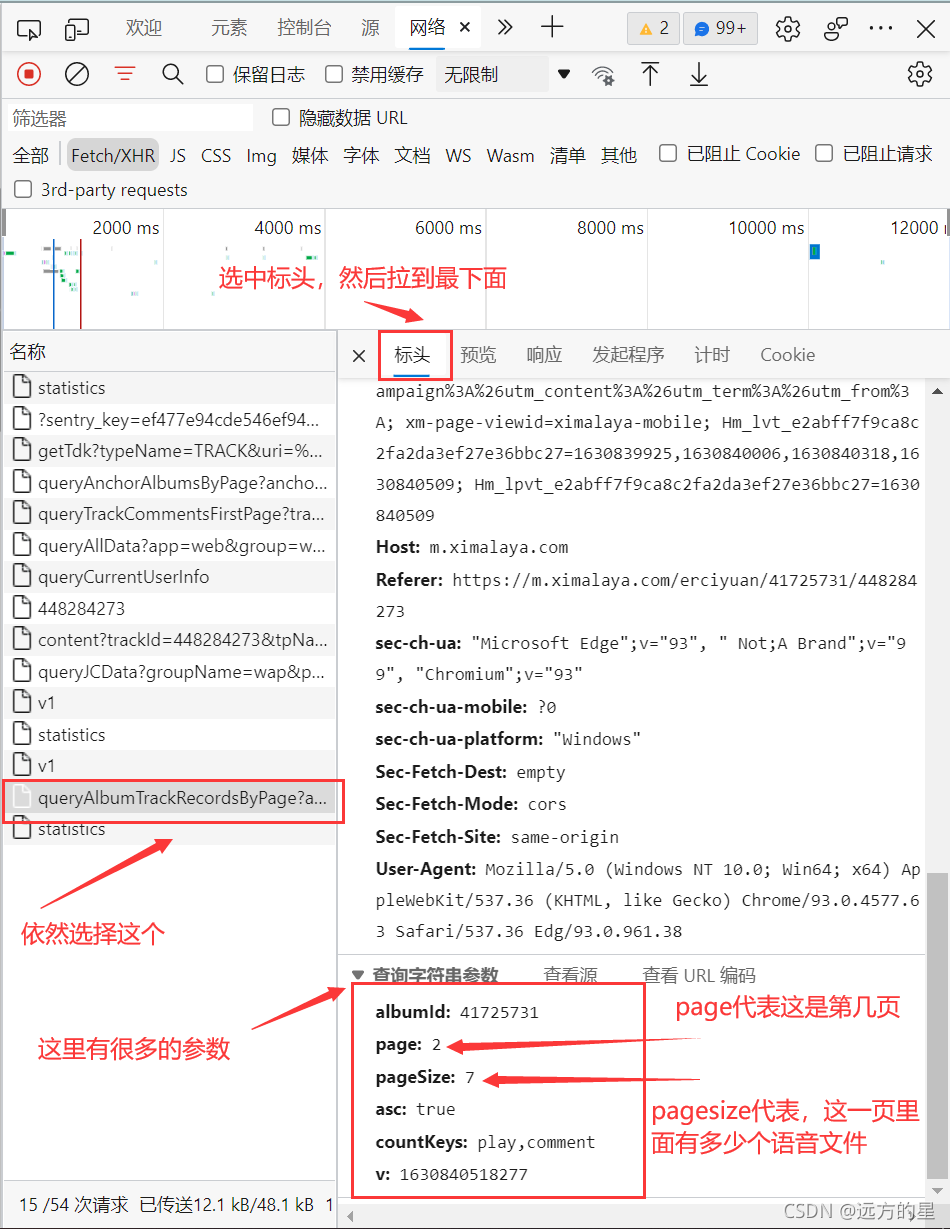
由此可見,需要我們改變的引數,就只有page這一個,
想要全部爬取,就要知道總共有多少頁,
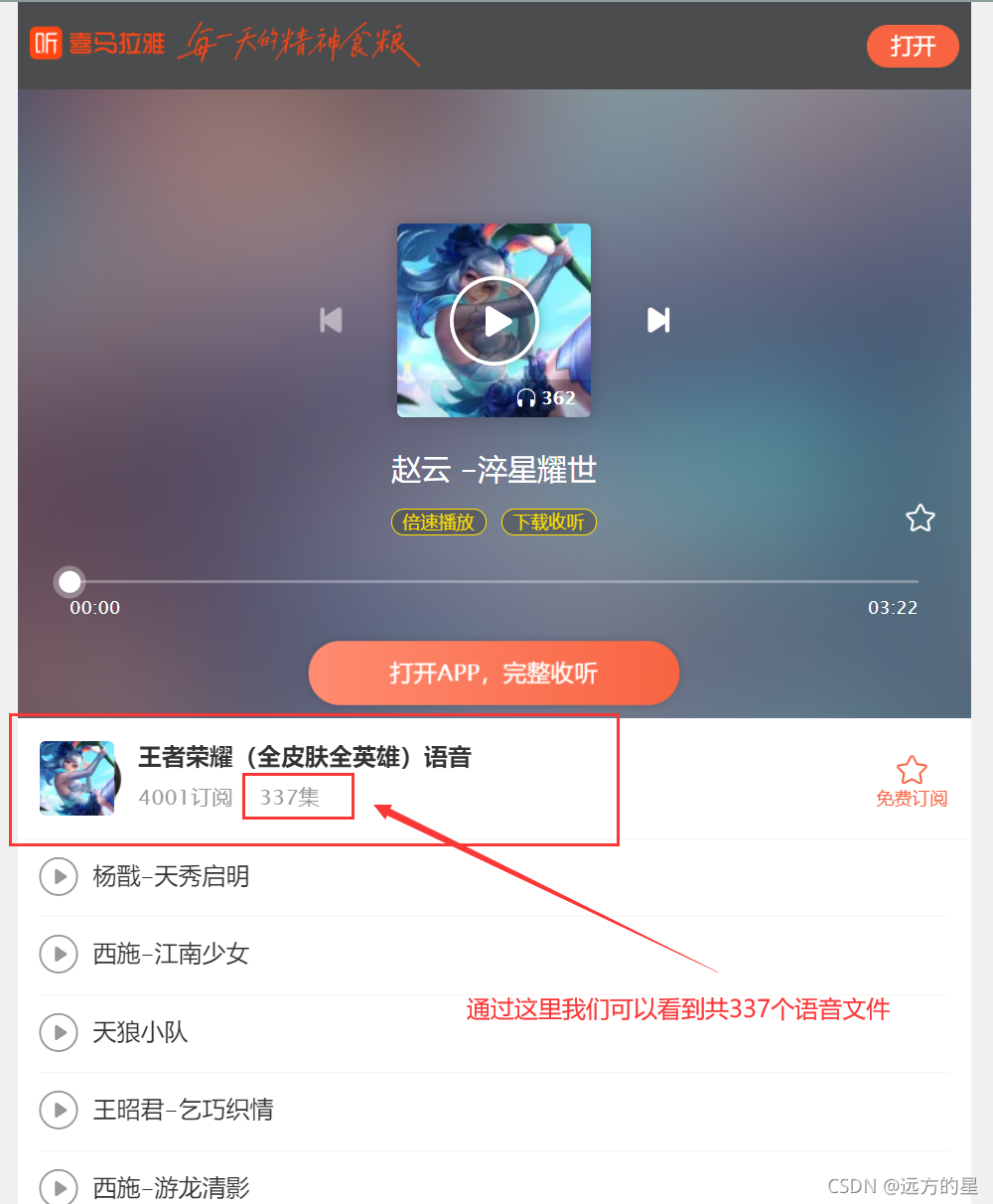
共337個語音內容,10個一組,所以共需要34組,
🍋完整代碼
# -*- coding: UTF-8 -*-
"""
# @Time: 2021/9/1 23:52
# @Author: 遠方的星
# @CSDN: https://blog.csdn.net/qq_44921056
"""
import os
import json
import requests
import chardet
from tqdm import tqdm
from fake_useragent import UserAgent
# 隨機產生請求頭
ua = UserAgent(verify_ssl=False, path='D:/Pycharm/fake_useragent.json')
# 提前創建一個檔案夾,方便創建子檔案夾
path_f = "./王者皮膚語音/"
if not os.path.exists(path_f):
os.mkdir(path_f)
# 隨機切換請求頭
def random_ua():
headers = {
"accept-encoding": "gzip", # gzip壓縮編碼 能提高傳輸檔案速率
"user-agent": ua.random
}
return headers
# 下載語音內容
def download(file_name, text, path): # 下載函式
file_path = path + file_name
with open(file_path, 'wb') as f:
f.write(text)
f.close()
# 獲取網頁內容并json化
def get_json(page):
url = 'https://m.ximalaya.com/m-revision/common/album/queryAlbumTrackRecordsByPage?'
param = {
'albumId': '41725731',
'page': '{}'.format(page),
'pageSize': '10',
'asc': 'true',
'countKeys': 'play', 'comment'
'v': '1630511230862'
}
res = requests.get(url=url, headers=random_ua(), params=param)
res.encoding = chardet.detect(res.content)["encoding"] # 確定編碼格式
res = res.text
text_json = json.loads(res) # 資料json化
return text_json
def main():
print("開始下載語音內容^-^")
for page in tqdm(range(1, 35)): # 共337個語音內容,10個一組,所以共需要34組
text_json = get_json(page)
data_s = text_json["data"]["trackDetailInfos"] # 得到一個存放資訊的串列
for i in range(len(data_s)):
voice_url = data_s[i]["trackInfo"]["playPath"] # 語音下載地址
voice_name = data_s[i]["trackInfo"]["title"] + '.mp3' # 語音名稱
voice = requests.get(url=voice_url, headers=random_ua()).content # 獲取語音內容
download(voice_name, voice, path_f) # 下載語音
print('所有語音下載完畢^-^')
if __name__ == '__main__':
main()
🍇運行結果
這里共需要2分鐘左右,故只錄了一部分

🍈語音包下載
上次王者全英雄語音,有很多小伙伴私信我,
這次我已經把爬取的語音準備好啦,小伙伴可以自取,
- 百度網盤:
鏈接:https://pan.baidu.com/s/191ugG6P1_T-ENif1q4q-_A
提取碼:1dn7
如果對你有幫助,記得點個贊👍喲,也是對作者最大的鼓勵🙇?♂?,
如有不足之處可以在評論區👇多多指正,我會在看到的第一時間進行修正
作者:遠方的星
CSDN:https://blog.csdn.net/qq_44921056
本文僅用于交流學習,未經作者允許,禁止轉載,更勿做其他用途,違者必究,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297840.html
標籤:python