最近【稿定設計】這個站點挺火,設計組的大哥一直在提,啊,這個好,這個好,
機智的我,思考了一下,決定給他采集一些公開素材,以后跟設計對線的時候,肯定要賣個人情,
目標站點分析
本次要采集的站點是:https://sucai.gaoding.com/plane/materials,高清圖肯定不能采集啦,僅采集 1080 P 的縮略圖,
目的是給設計組大哥提供素材參考,畢竟做設計的可不能抄襲哦(思路枯竭的時候,借鑒一下還湊合),
目標站點的篩選項非常“貼心”的提供“全部”這一選項,省的我們拼湊分類了,

在查閱分頁的時候,發現稿定設計網站僅開放了 100 頁資料,每頁 100 條,也就是咱只能獲取到 10000 張圖片,
看了一眼設計大哥的頭發,我覺得夠他用一年了,
頁面 URL 跳轉鏈接規則如下:
https://sucai.gaoding.com/plane/materials?p=1
https://sucai.gaoding.com/plane/materials?p=100
但是資料的請求鏈接為下述規則:
https://api-sucai.gaoding.com/api/search-api/sucai/templates/search?q=&sort=&colors=&styles=&filter_id=1617130&page_size=100&page_num=1
https://api-sucai.gaoding.com/api/search-api/sucai/templates/search?q=&sort=&colors=&styles=&filter_id=1617130&page_size=100&page_num=2
引數說明
q:搜索的關鍵字,為空即可;sort:排序規則,可空;colors和styles:顏色和風格, 保持空;filter_id:過濾 ID,保持全部應該是1617130;page_size:獲取的每頁資料量;page_num:頁碼,該值最大為 100,
有了上述分析之后,就可以進行編碼作業了,
編碼時間
在正式編碼前,先通過一張圖整理邏輯,該案例依舊為生產者與消費者模式爬蟲,采用 threading 模塊與 queue 佇列模塊實作,
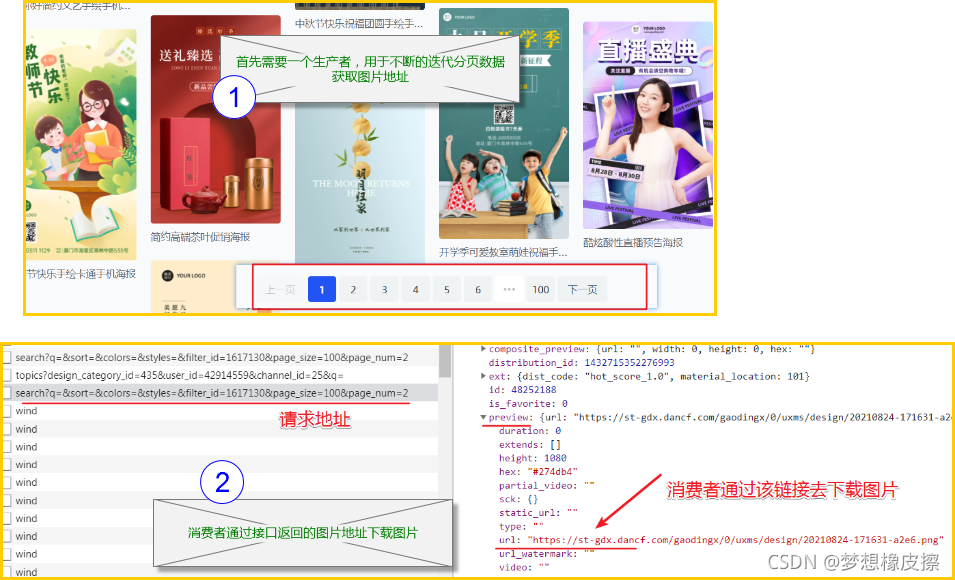
理解上圖之后,就可以撰寫下述代碼了,重點部分在注釋中體現,本次采用類寫法,學習的時候需要特別注意一下,
import requests
from queue import Queue
import random
import threading
import time
def get_headers():
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"其它UA,自行查找即可"
]
UserAgent = random.choice(user_agent_list)
headers = {'User-Agent': UserAgent,'referer': 'https://sucai.gaoding.com/'}
return headers
# 生產者執行緒
class Producer(threading.Thread):
def __init__(self, t_name, queue):
threading.Thread.__init__(self, name=t_name)
self.data = queue
# 測驗爬取 3 頁,實際采集的時候,可以放大到100頁
def run(self):
# 測驗資料,爬取3頁
for i in range(1,3):
print("執行緒名: %s,序號:%d, 正在向佇列寫入資料 " % (self.getName(), i))
# 拼接URL地址
url = 'https://api-sucai.gaoding.com/api/search-api/sucai/templates/search?q=&sort=&colors=&styles=&filter_id=1617130&page_size=100&page_num={}'.format(i)
res = requests.get(url=url,headers=get_headers(),timeout=5)
# 這里可以增加 try catch 驗證,防止報錯
if res:
data = res.json()
# JSON 提取資料
for item in data:
title = item["title"]
img_url = item["preview"]["url"]
self.data.put((title,img_url))
print("%s: %s 寫入完成!" % (time.ctime(), self.getName()))
# 消費者執行緒
class Consumer(threading.Thread):
def __init__(self, t_name, queue):
threading.Thread.__init__(self, name=t_name)
self.data = queue
def run(self):
while True:
# 從佇列獲取資料
val = self.data.get()
if val is not None:
print("執行緒名:%s,正在讀取資料:%s" % (self.getName(), val))
title,url = val
# 請求圖片
res = requests.get(url=url,headers=get_headers(),timeout=5)
if res:
# 保存圖片
with open(f"./imgs/{title}.png","wb") as f:
f.write(res.content)
print(f"{val}","寫入完畢")
# 主函式
def main():
queue = Queue()
producer = Producer('生產者', queue)
consumer = Consumer('消費者', queue)
producer.start()
consumer.start()
producer.join()
consumer.join()
print('所有執行緒執行完畢')
if __name__ == '__main__':
main()
生產者執行緒用于產生圖片地址,存放到佇列 queue 中,消費者執行緒通過一個“死回圈”不斷從佇列中,獲取圖片地址,然后進行下載,
代碼運行效果如下圖所示:


收藏時間
代碼倉庫地址:https://codechina.csdn.net/hihell/python120,去給個關注或者 Star 吧,
你需要的 10000 張設計參考圖下載地址
- 第一部分參考圖下載地址,接近 1G
- 第二部分參考圖下載地址,接近 1G
- 第三部分參考圖下載地址,接近 1G
- 第四部分參考圖下載地址,接近 1G
資料沒有采集完畢,想要的可以在評論區留言交流
今天是持續寫作的第 211 / 365 天,
可以關注我,點贊我、評論我、收藏我啦,
更多精彩
- Python 爬蟲 100 例教程導航帖(已完結,復盤更新中,目前 110+ 篇)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297849.html
標籤:python