前言
軟科中國大學排名以專業、客觀、透明的優勢贏得了高等教育領域和社會的廣泛關注和認可,本次將利用Python對我國大學排名和分布情況進行一番研究,
先展示下爬蟲的原始碼
import requests import parsel import csv f = open('排名.csv', mode='a', encoding='utf-8', newline='') csv_writer = csv.DictWriter(f, fieldnames=['名次', '學校名稱', '綜合得分', '星級排名', '辦學層次']) url = 'http://m.gaosan.com/gaokao/265440.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, headers=headers) response.encoding = response.apparent_encoding selector = parsel.Selector(response.text) trs = selector.css('#page tr') for tr in trs: dit = {} ranking = tr.css('td:nth-child(1)::text').get() dit['名次'] = ranking school = tr.css('td:nth-child(2)::text').get() dit['學校名稱'] = school score = tr.css('td:nth-child(3)::text').get() dit['綜合得分'] = score star = tr.css('td:nth-child(4)::text').get() dit['星級排名'] = star level = tr.css('td:nth-child(5)::text').get() dit['辦學層次'] = level csv_writer.writerow(dit) print(dit) f.close()
Python從零基礎入門到實戰系統教程、原始碼、視頻,想要資料集的同學也可以點這里
資料分析涉及到的內容
- Pandas — 資料處理
- Pyecharts — 資料可視化
匯入模塊
from pyecharts.charts import Map,Bar,Pie from pyecharts import options as opts import pandas as pd
Pandas資料處理
讀取資料
df = pd.read_csv('中國大學綜合排名.csv',index_col=0) df.head()
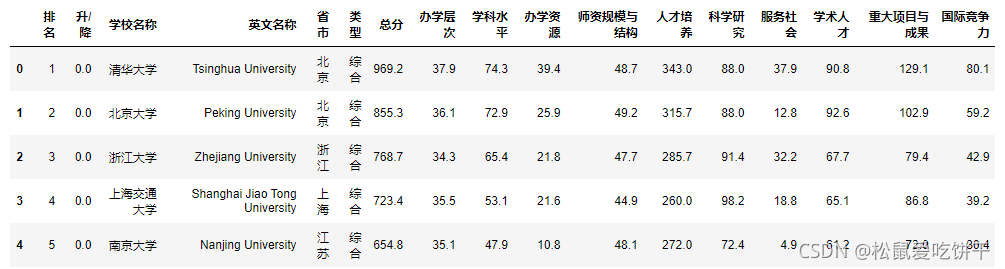
查看表格資料型別
df.dtypes

統計各省市大學數量
# 各省份大學數量 df_counts = df.groupby('省市').count()['排名'] df0 = df_counts.copy() # 進行降序排列 并在當前df0上進行修改 df0.sort_values(ascending=False, inplace=True) df0

各省市大學平均分排序
# 統計每個省份大學的數量以及平均分 # 算出平均分 df_means0 = df.groupby('省市').mean()['總分'] # 取兩位小數 df_means = df_means0.round(2) # 合并上面的大學數量跟平均分 df1 = pd.concat([df_counts, df_means], axis=1) # 改變列名 df1.columns = ['數量', '平均分'] # 通過 平均分 進行降序排列 并在當前df1上進行修改 df1.sort_values(by=['平均分'], ascending=False, inplace=True) df1
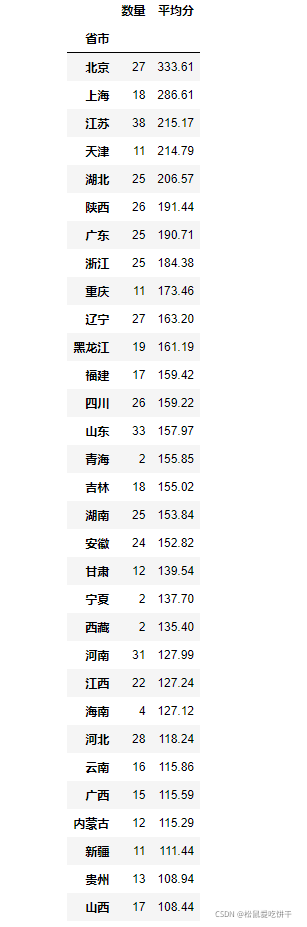
Pyecharts資料可視化
各省市大學數量和平均分柱狀圖(橫向)
d1 = df1.index.tolist() d2 = df1['數量'].values.tolist() d3 = df1['平均分'].values.tolist() bar0 = ( Bar() .add_xaxis(d1) .add_yaxis('數量', d2) .add_yaxis('平均分數', d3) .set_global_opts( title_opts=opts.TitleOpts(title='中國大學排名'), yaxis_opts=opts.AxisOpts(name='量'), xaxis_opts=opts.AxisOpts(name='省份'), ) ) bar0.render_notebook()
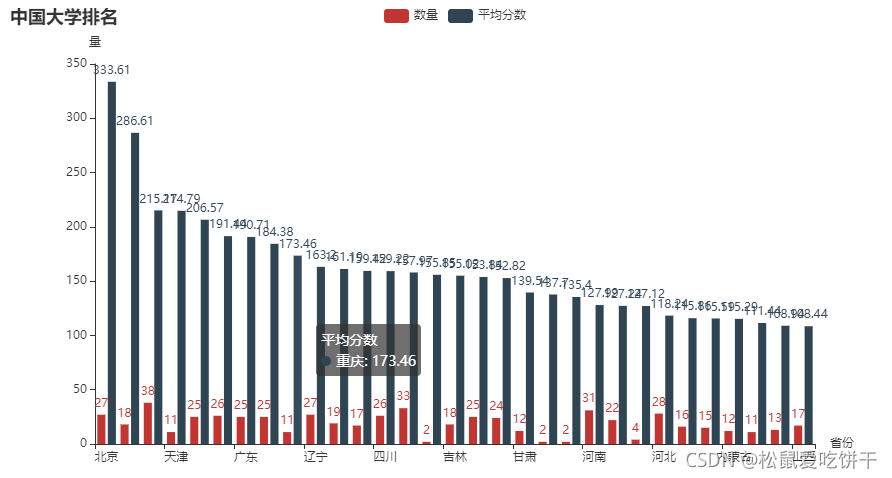
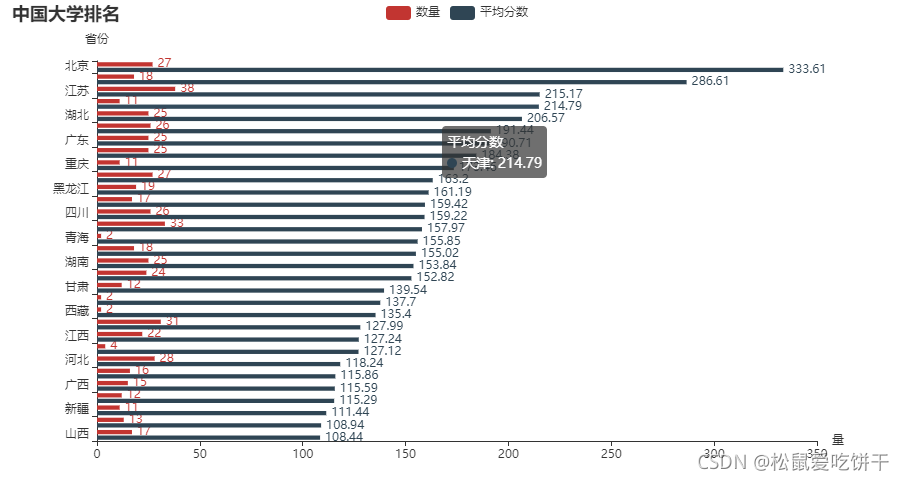
各省市大學數量和平均分柱狀圖(縱向)
df1.sort_values(by=['平均分'], inplace=True) d1 = df1.index.tolist() d2 = df1['數量'].values.tolist() d3 = df1['平均分'].values.tolist() bar1 = ( Bar() .add_xaxis(d1) .add_yaxis('數量', d2) .add_yaxis('平均分數', d3) # 坐標軸翻轉 .reversal_axis() # 數值顯示靠右 .set_series_opts(label_opts=opts.LabelOpts(position='right')) .set_global_opts( title_opts=opts.TitleOpts(title='中國大學排名'), yaxis_opts=opts.AxisOpts(name='省份'), xaxis_opts=opts.AxisOpts(name='量'), ) ) bar1.render_notebook()
各省市大學數量玫瑰圖
弗羅倫斯·南丁格爾(Florence Nightingale),一位著名的英國護士,同時她也是一位統計學家,很多人沒有想到吧?
她被號稱為資料可視化的鼻祖,就是資料可視化的祖師爺,你可能也沒有想到吧?
她是英國皇家統計學會的第一個女成員,也是美國統計協會的名譽會員,
克里米亞戰爭時期,南丁格爾發現大多數士兵不是陣亡,而是因為饑餓、營養不良、衛生條件差和野戰醫院的條件差才死于其戰傷,
于是她向上級報告了克里米亞戰爭的醫療條件,同時申請一批醫療物質來改變醫療條件,由于國會議員不會閱讀統計報告,所以她的申請一直得不到批準,于是她改用了極座標餅圖的形式來展示戰地醫院的病人死亡率在不同季節的變化,重新提交這個申請報告,沒想到馬上就得到了批準,這是這批物質改善了戰地醫院的衛生條件,僅此一項改革就大大地提高了受傷戰士的生存率,
后被這個圖就被稱為南丁格爾玫瑰圖,南丁格爾也被尊稱為資料可視化鼻祖
name = df_counts.index.tolist() count = df_counts.values.tolist() c0 = ( Pie() .add( '', [list(z) for z in zip(name, count)], # 餅圖的半徑,陣列的第一項是內半徑,第二項是外半徑 # 默認設定成百分比,相對于容器高寬中較小的一項的一半 radius=['20%', '60%'], # 讓圖在這個位置顯示 center=['50%', '65%'], # 是否展示成南丁格爾圖,通過半徑區分資料大小,有'radius'和'area'兩種模式, # radius:扇區圓心角展現資料的百分比,半徑展現資料的大小 # area:所有扇區圓心角相同,僅通過半徑展現資料大小 rosetype="radius", # 顯示標簽 label_opts=opts.LabelOpts(is_show=False), ) .set_series_opts(label_opts=opts.LabelOpts(formatter='{b}: {c}')) ) c0.render_notebook()
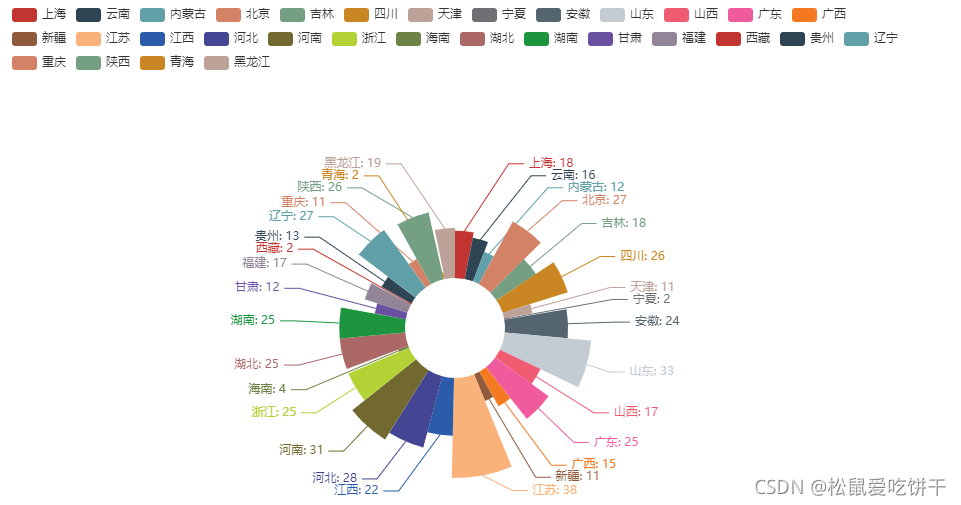
各省市大學數量南丁格爾玫瑰圖
provinces = df0.index.tolist() num = df0.values.tolist() c1 = ( Pie() .add('', [list(z) for z in zip(provinces, num)], radius=['30%', '105%'], rosetype='area' ) .set_global_opts( title_opts=opts.TitleOpts(title='中國大學排名'), legend_opts=opts.LegendOpts(is_show=False), toolbox_opts=opts.ToolboxOpts() ) .set_series_opts( label_opts=opts.LabelOpts( # 是否顯示標簽 is_show=True, # 設定標簽位置 position="inside", font_size=12, formatter='{b}: {c}', # 斜體 font_style='italic', # 加粗 font_weight='bold', # 微軟的雅黑字體 font_family='Microsoft YaHei' ) ) ) c1.render_notebook()
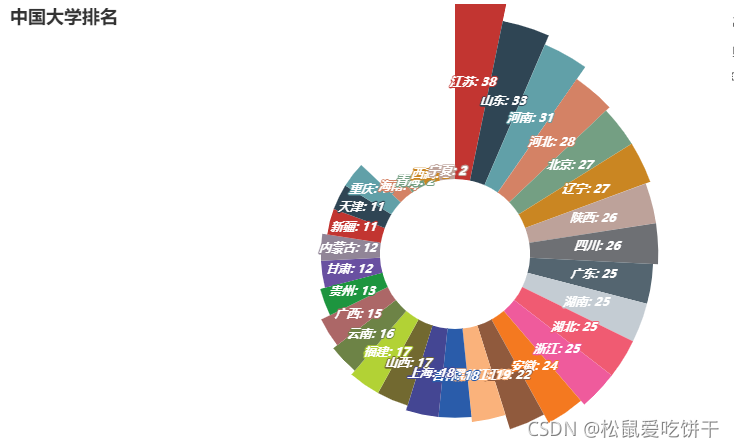
總結
大學數量較多的省市:江蘇、山東、河南、河北、北京、遼寧 、陜西、四川 、廣東 、湖南 、湖北、浙江等地(只看學校數量),后期探索可根據學校排名
排名前20的大學較前一年的波動較小(這也符合常理,畢竟前幾的學校都是多年沉淀下來的)
西部地區大學數量較少
本資料集不包含港、澳、臺大學(網站未統計)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297987.html
標籤:其他