cookie在發明之初,為了幫助服務器同步網頁上的用戶資訊,同時保存用戶操作,以此減輕服務器壓力,
沒有cookie之前,人們還停留在像電視一樣只能對網頁進行點播,網站分辨不出是誰在通信,
題外話:第一代密碼,屬于通用性的密鑰
有了cookie后,你就那個網頁做互動了,這時才有了網站賬號,
由正在瀏覽的網站創建的cookie被稱為第一方cookie,
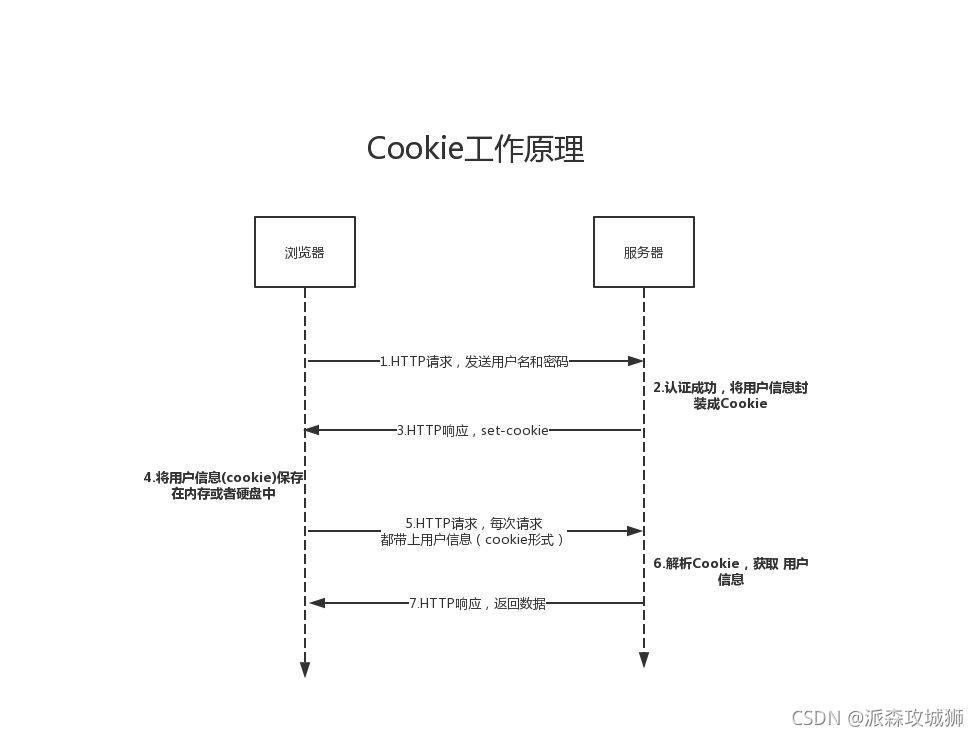
這個東西很重要,你要是不信邪,把這種第一方cookie給禁止了,
那么,恭喜你,回到了廣播時代,
Python requests庫默認是打開了cookie的,
– 檢查cookie
import requests
from requests.cookies import RequestsCookieJar
headers = {
'Host': 'accounts.douban.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
}
request_url = "https://accounts.douban.com/passport/login"
res = requests.get(request_url, headers=headers)
status_code = res.status_code
res_header = res.headers
res_cookies = res.cookies
cookie1111 = res.cookies.get_dict() # 格式化 字典形式輸出
cookie2222 = requests.utils.dict_from_cookiejar(res_cookies) # 格式化 字典形式輸出
for cookie in res_cookies:
print(cookie.name+"\t"+cookie.value)
print("回應狀態碼:", status_code)
print("回應請求請求頭:", res_header)
print("回應cookies:", res_cookies)
print("格式化cookie1111 :", cookie1111)
print("格式化cookie2222 :", cookie2222)
– 到這里自帶cookie說明白了!
接下來,我們引入一個概念 第三方cookie,
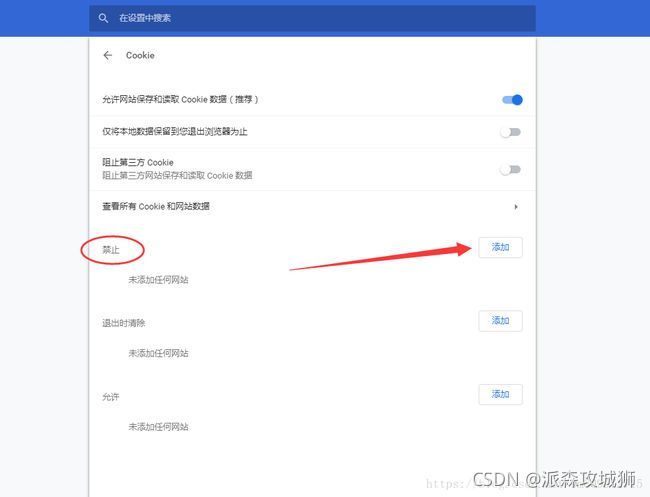
使用空瀏覽器來看下效果,
清除瀏覽器cookie記錄,也可以進行模擬,
進入一個網站csdn.net,
然后點擊網頁地址欄左側的那個小鎖就能看到這些資訊,
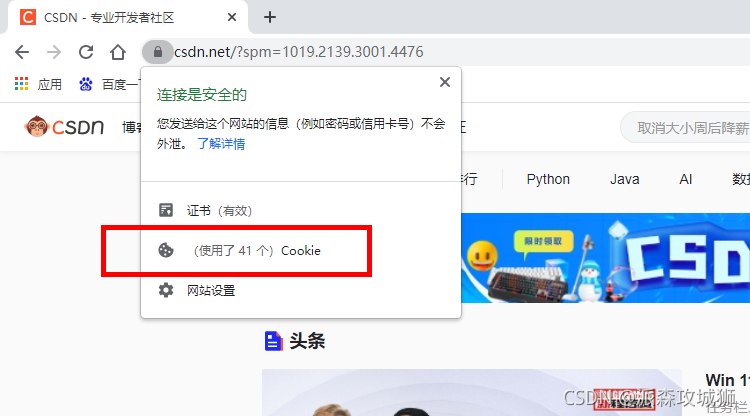
正在訪問的csdn.net以外
還有來自其它40個cookie,這些在你訪問的網址之外的域名,創建的cookie就被稱作,作為第三方cookie,
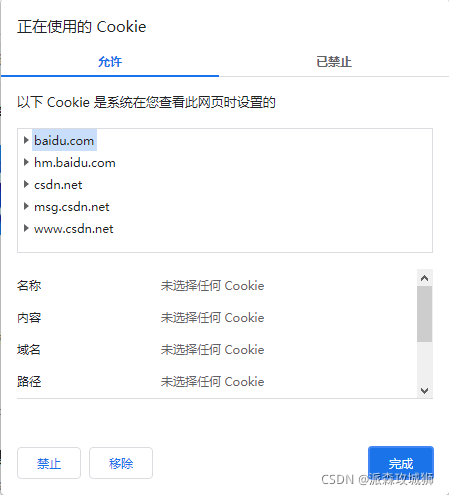
這些第三方cookie怎么來的呢?他們又有什么作用了,
你通過進入csdn.com,這個網站就訪問了baidu.com的服務器了,
咱們按下F12進入瀏覽器的開發者模式中,觀察一下網路結構,
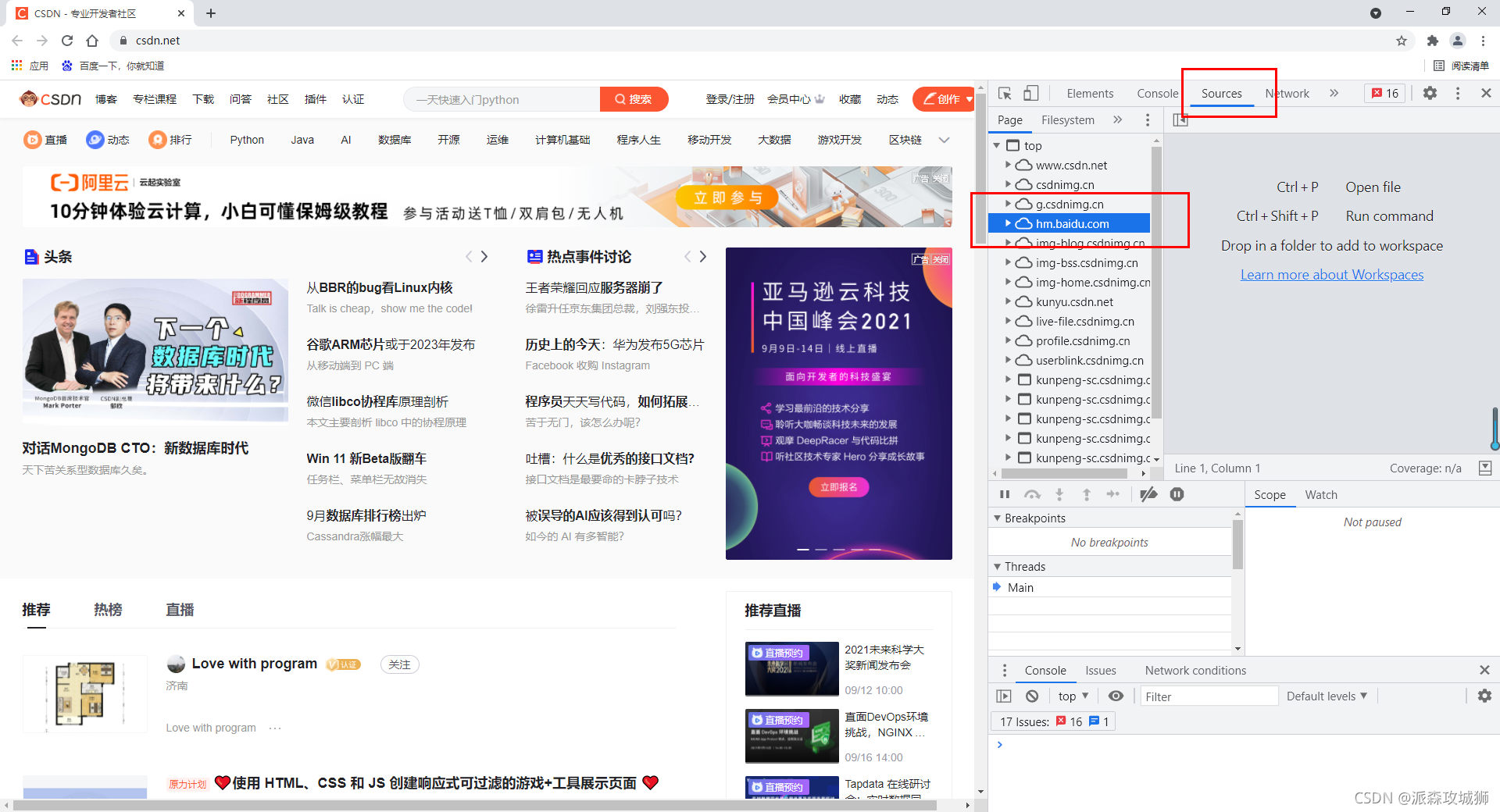
仔細查看一下這個網站的加載,我們可以在它的目錄中發現baidu.com來源,他使用了baidu.com提供的功能,撰寫進了自己的網站代碼中,
– 我們在訪問這個網站的程序中,也同時使用了百度為你提供的服務,那么這個服務是什么呢?
# 不得不提cookie的另外一個作用! ## 除了可以系結網頁和用戶的身份,還可以記錄網頁的瀏覽歷史, ### 這樣就給 ==廣告提供商== 機會,使用不同的代碼模塊,嵌入到不同的網站中,以此實行產品推薦, ### 第三方cookie,它默默的,把你的喜好記錄下來,在你進入其他網站時,再通過讀取之前已經記錄好的資訊,這樣就能對你進行個性化廣告推薦,
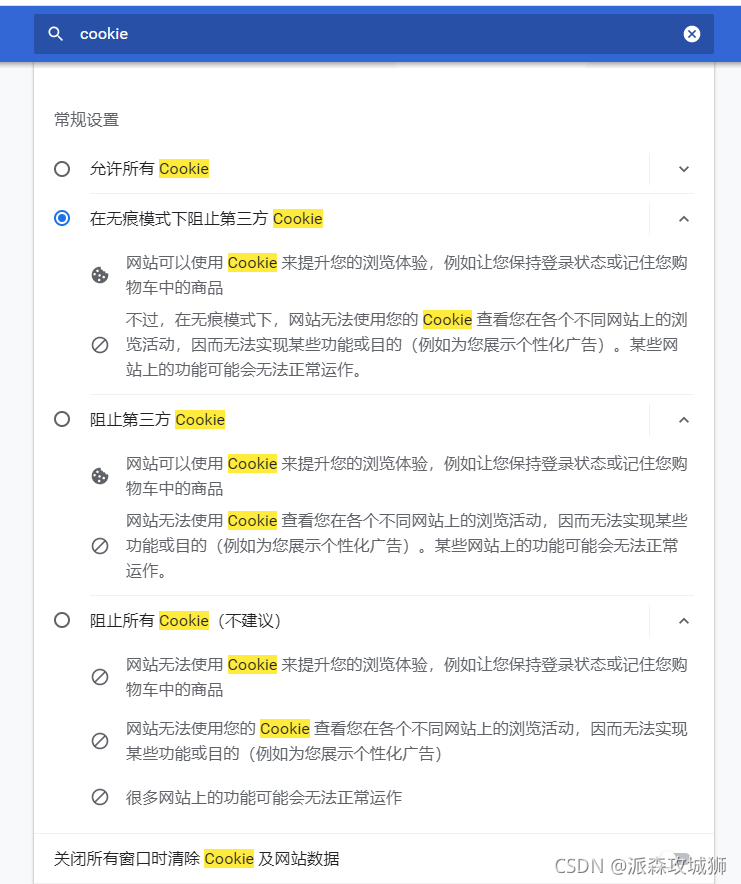
禁用第三方cookie是不是就沒有廣告了?
這也是爬蟲遇到最多的情況,
手動模擬一下,禁用第三方cookie,會發現 驗證碼 輸入次數開始變得頻繁了,
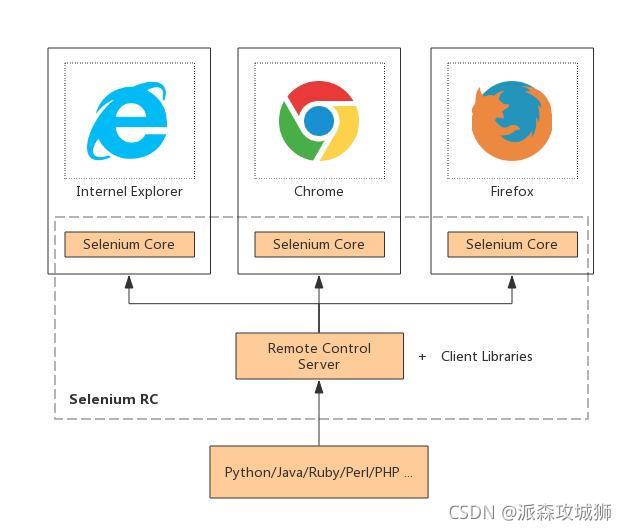
鑒于此,爬蟲產生了另外一個工具selenium,
寫在最后
1.了解歷史,有助于,我們更好的定位問題,
2.很多博主只告訴你們,第二次爬去的時候需要攜帶cookie,對第三方cookie只字不提
import requests
cookies="從網上復制的cookie值"
cookies_dict={}
for i in cookies.split("; "):
cookies_dict[i.splict('=')[0]] = i.splict('=')[1]
html=requests.get(url='',cookies=cookies_dict}
3.更高級的工具,學習,使用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/298120.html
標籤:python