?? 一條獨家專欄 ?? 搞技術,進大廠,聊人生
📚《大廠面試突擊》——面試10多家中大廠的萬字總結
📚《技術專家修煉》——高薪必備,企業真實場景
📚《leetcode 300題》——每天一道演算法題,進大廠必備
📚《糊涂演算法》——資料結構+演算法全面講解
📚《從實戰學python》——python的各種應用
📚《程式人生》——聽一條聊職場,聊人生
?更多java面試學習資料,請看下方圖片內容

把快樂放進重點反復背誦,
前言
哈嘍,大家好,我是一條,
《大廠面試突擊》專欄目前已發布三篇萬字總結,識訓700+的訂閱,感謝各位的支持,
面試10多家中大廠后的萬字總結——??集合篇??
面試10多家中大廠后的萬字總結——??JavaWeb篇??
面試10多家中大廠后的萬字總結——??java基礎篇??
下期預告:
從HashMap肝到AQS——面試10多家中大廠后的萬字總結又雙叒叕來了??
今天分享一個粉絲在美團二面遇到的問題——如何設計一個百萬人抽獎系統?
思維導圖
導圖源檔案:
鏈接: https://pan.baidu.com/s/1FrUMGAdrbvzlDLdftnLV1A
提取碼: nw57
鏈接失效或者下載速度過慢請私信我!
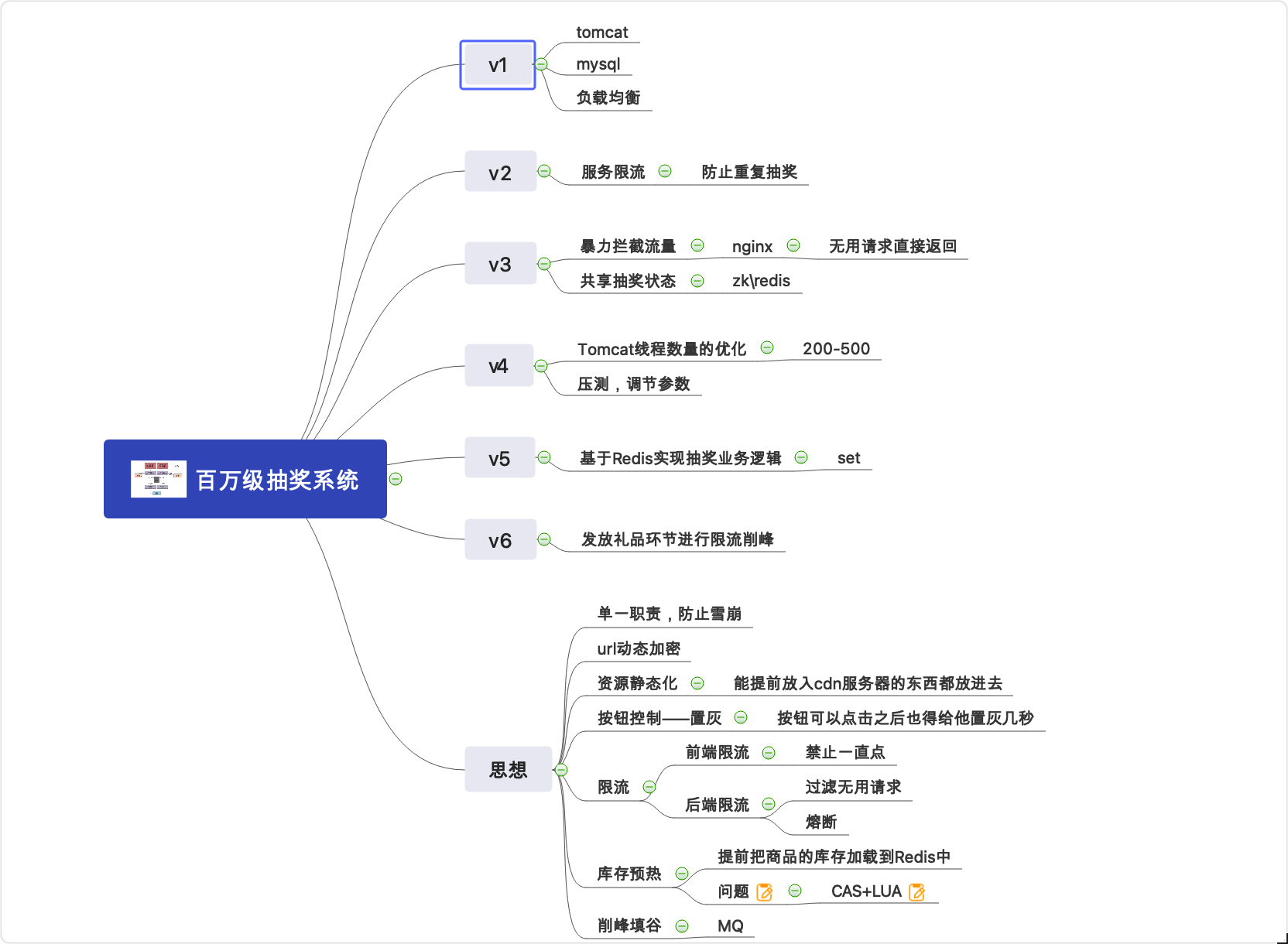
導圖按照由淺入深的方式進行講解,架構從來不是設計出來的,而是演進而來的
從一個幾百人的抽獎系統到幾萬人,再到到百萬人,不斷增加新的東西,
最后總結歸納一套設計思想,也是萬能模板,這樣面試官問任何高并發系統,只需從這幾個方向去考慮就可以了,
文章目錄
- 前言
- 思維導圖
- V0——單體架構
- V1——負載均衡
- V2——服務限流
- 防止用戶重復抽獎
- 攔截無效流量
- 服務降級和服務熔斷
- V3 同步狀態
- V4執行緒優化
- V5業務邏輯
- V6流量削峰
- 答題模板
- 單一職責
- URL動態加密
- 靜態資源——CDN
- 服務限流
- 資料預熱
- 削峰填谷
- 最后
V0——單體架構
如果現在讓你實作幾十人的抽獎系統,簡單死了吧,直接重拳出擊!
兩貓一豚走江湖,中獎入庫,調通知服務,查庫通知,完美!
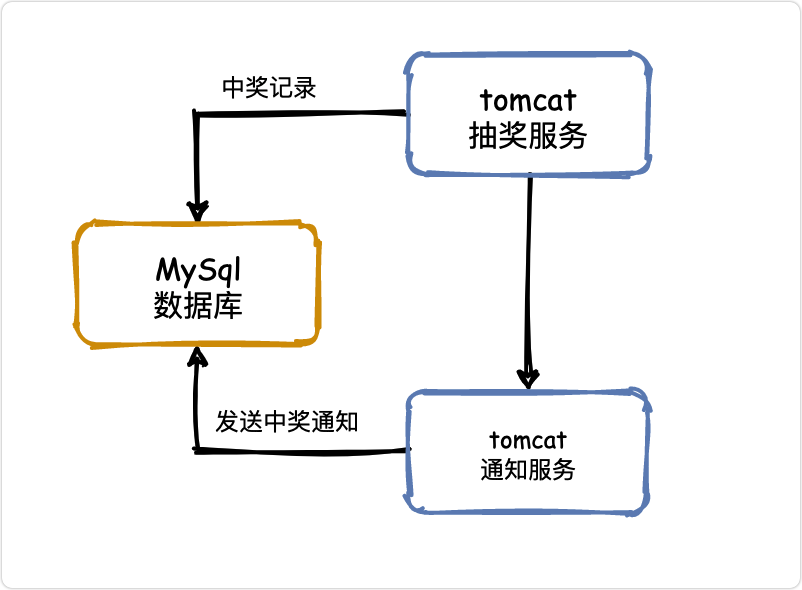
相信大家學java時可能都做過這種案例,思考🤔一下存在什么問題?
- 單體服務,一著不慎滿盤皆輸
- 抽了再抽,一個人就是一支軍隊
- 惡意腳本,沒有程式員中不了的獎
接下來就聊聊怎么解決這些問題?
V1——負載均衡
當一臺服務器的單位時間內的訪問量越大時,服務器壓力就越大,大到超過自身承受能力時,服務器就會崩潰,
為了避免服務器崩潰,讓用戶有更好的體驗,我們通過負載均衡的方式來分擔服務器壓力,
負載均衡就是建立很多很多服務器,組成一個服務器集群,當用戶訪問網站時,先訪問一個中間服務器,好比管家,由他在服務器集群中選擇一個壓力較小的服務器,然后將該訪問請求引入該服務器,
如此以來,用戶的每次訪問,都會保證服務器集群中的每個服務器壓力趨于平衡,分擔了服務器壓力,避免了服務器崩潰的情況,
負載均衡是用「反向代理」的原理實作的,具體負載均衡演算法及其實作方式我們下文再續,
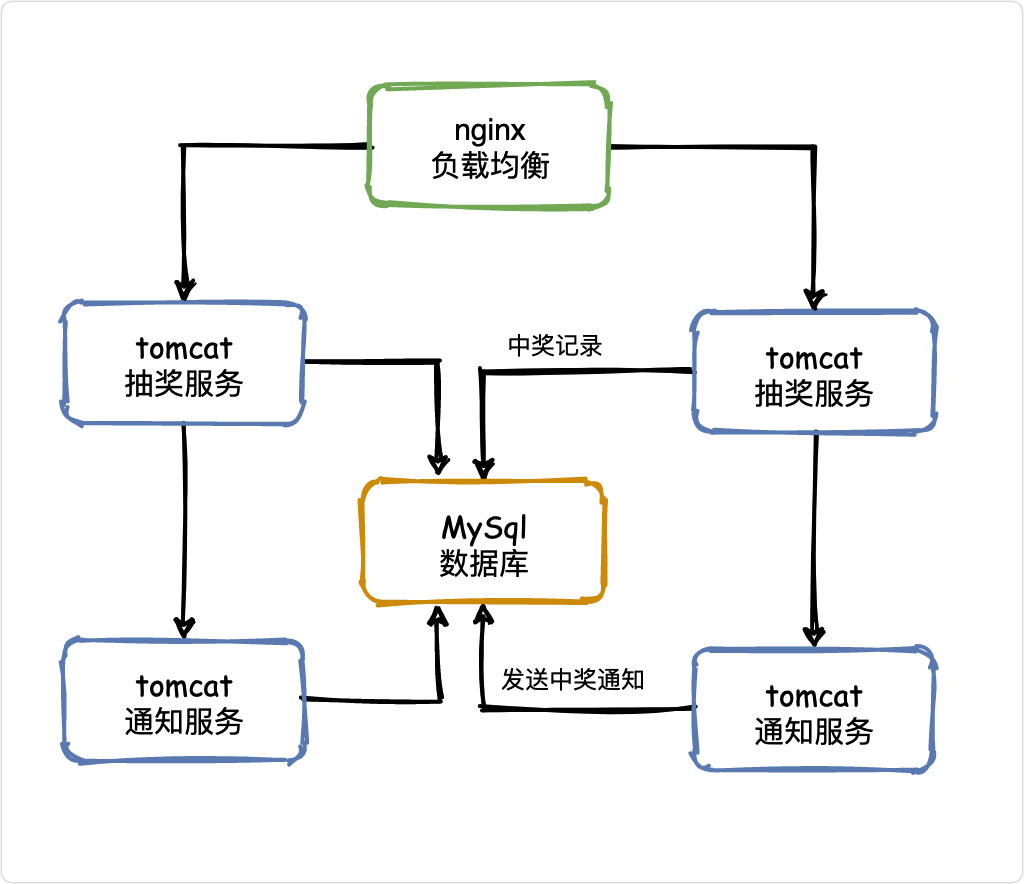
負載均衡雖然解決了單體架構一著不慎滿盤皆輸的問題,但服務器成本依然不能保護系統周全,我們必須想好一旦服務器宕機,如何保證用戶的體驗,
即如何緩解開獎一瞬間時的大量請求,
V2——服務限流
限流主要的作用是保護服務節點或者集群后面的資料節點,防止瞬時流量過大使服務和資料崩潰(如前端快取大量實效),造成不可用,
還可用于平滑請求,
在上一小節我們做好了負載均衡來保證集群的可用性,但公司需要需要考慮服務器的成本,不可能無限制的增加服務器數量,一般會經過計算保證日常的使用沒問題,
限流的意義就在于我們無法預測未知流量,比如剛提到的抽獎可能遇到的:
- 重復抽獎
- 惡意腳本
其他一些場景:
- 熱點事件(微博)
- 大量爬蟲
這些情況都是無法預知的,不知道什么時候會有10倍甚至20倍的流量打進來,如果真碰上這種情況,擴容是根本來不及的(彈性擴容都是虛談,一秒鐘你給我擴一下試試)
明確了限流的意義,我們再來看看如何實作限流
防止用戶重復抽獎
重復抽獎和惡意腳本可以歸在一起,同時幾十萬的用戶可能發出幾百萬的請求,
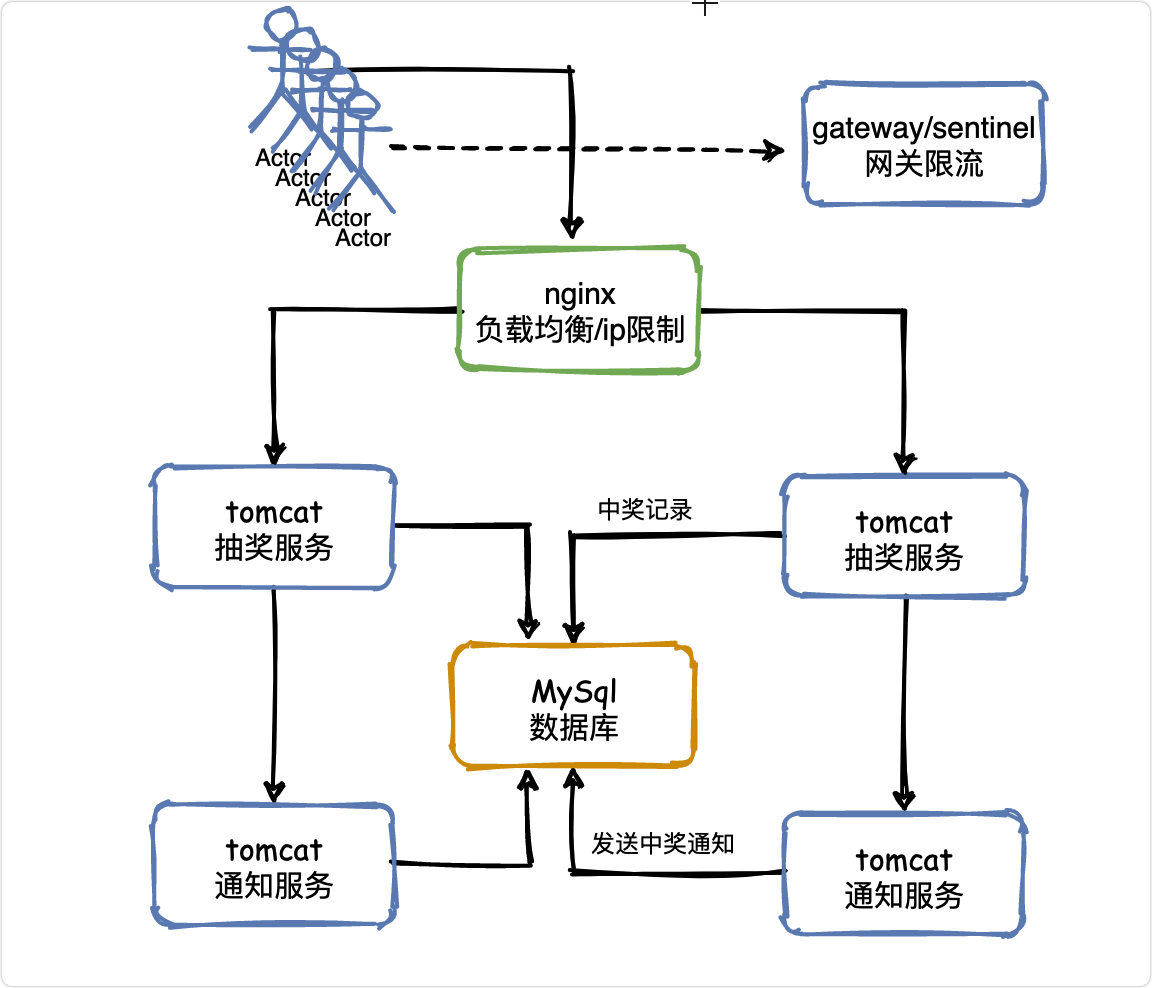
如果同一個用戶在1分鐘之內多次發送請求來進行抽獎,就認為是惡意重復抽獎或者是腳本在刷獎,這種流量是不應該再繼續往下請求的,在負載均衡層給直接屏蔽掉,
可以通過nginx配置ip的訪問頻率,或者在在網關層結合sentinel配置限流策略,
用戶的抽獎狀態可以通過redis來存盤,后面會說,
攔截無效流量
無論是抽獎還是秒殺,獎品和商品都是有限的,所以后面涌入的大量請求其實都是無用的,
舉個例子,假設50萬人抽獎,就準備了100臺手機,那么50萬請求瞬間涌入,其實前500個請求就把手機搶完了,后續的幾十萬請求就沒必要讓他再執行業務邏輯,直接暴力攔截回傳抽獎結束就可以了,
同時前端在按鈕置灰上也可以做一些文章,
那么思考一下如何才能知道獎品抽完了呢,也就是庫存和訂單之前的資料同步問題,
服務降級和服務熔斷
有了以上措施就萬無一失了嗎,不可能的,所以再服務端還有降級和熔斷機制,
在此簡單做個補充,詳細內容請持續關注作者,
有好多人容易混淆這兩個概念,通過一個小例子讓大家明白:
假設現在一條粉絲數突破100萬,沖上微博熱搜,粉絲甲和粉絲乙都打開微博觀看,但甲看到了一條新聞發布會的內容,乙卻看到”系統繁忙“,過了一會,乙也能看到內容了,
(請允許一潭訓想一下😎)
在上述程序中,首先是熱點時間造成大量請求,發生了服務熔斷,為了保證整個系統可用,犧牲了部分用戶乙,乙看到的”系統繁忙“就是服務降級(fallback),過了一會有恢復訪問,這也是熔斷器的一個特性(hystrix)
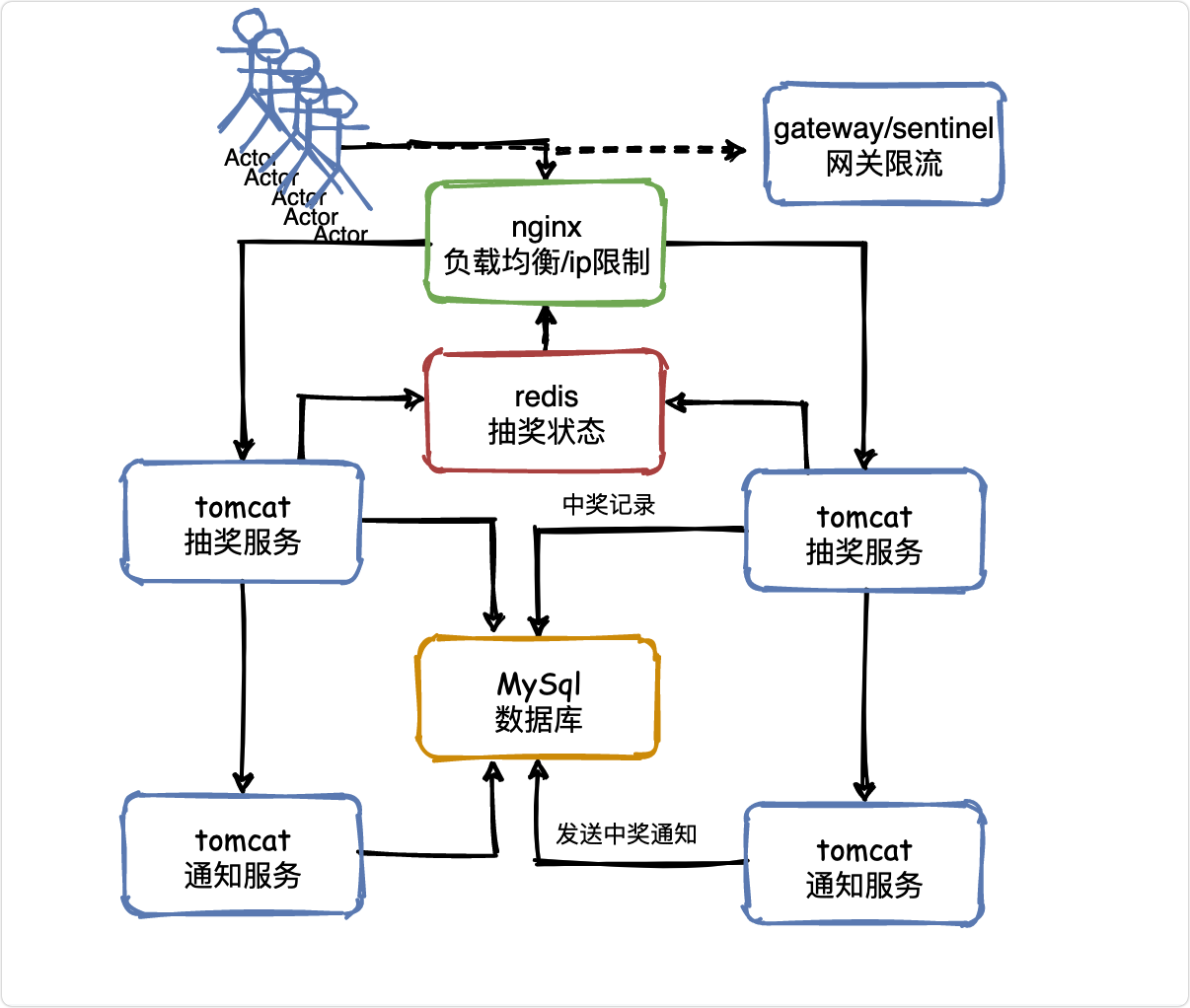
V3 同步狀態
接著回到上一節的問題,如何同步抽獎狀態?
這不得不提到redis,被廣泛用于高并發系統的快取資料庫,
我們可以基于Redis來實作這種共享抽獎狀態,它非常輕量級,很適合兩個層次的系統的共享訪問,
當然其實用ZooKeeper也是可以的,在負載均衡層可以基于zk客戶端監聽某個znode節點狀態,一旦抽獎結束,抽獎服務更新zk狀態,負載均衡層會感知到,
V4執行緒優化
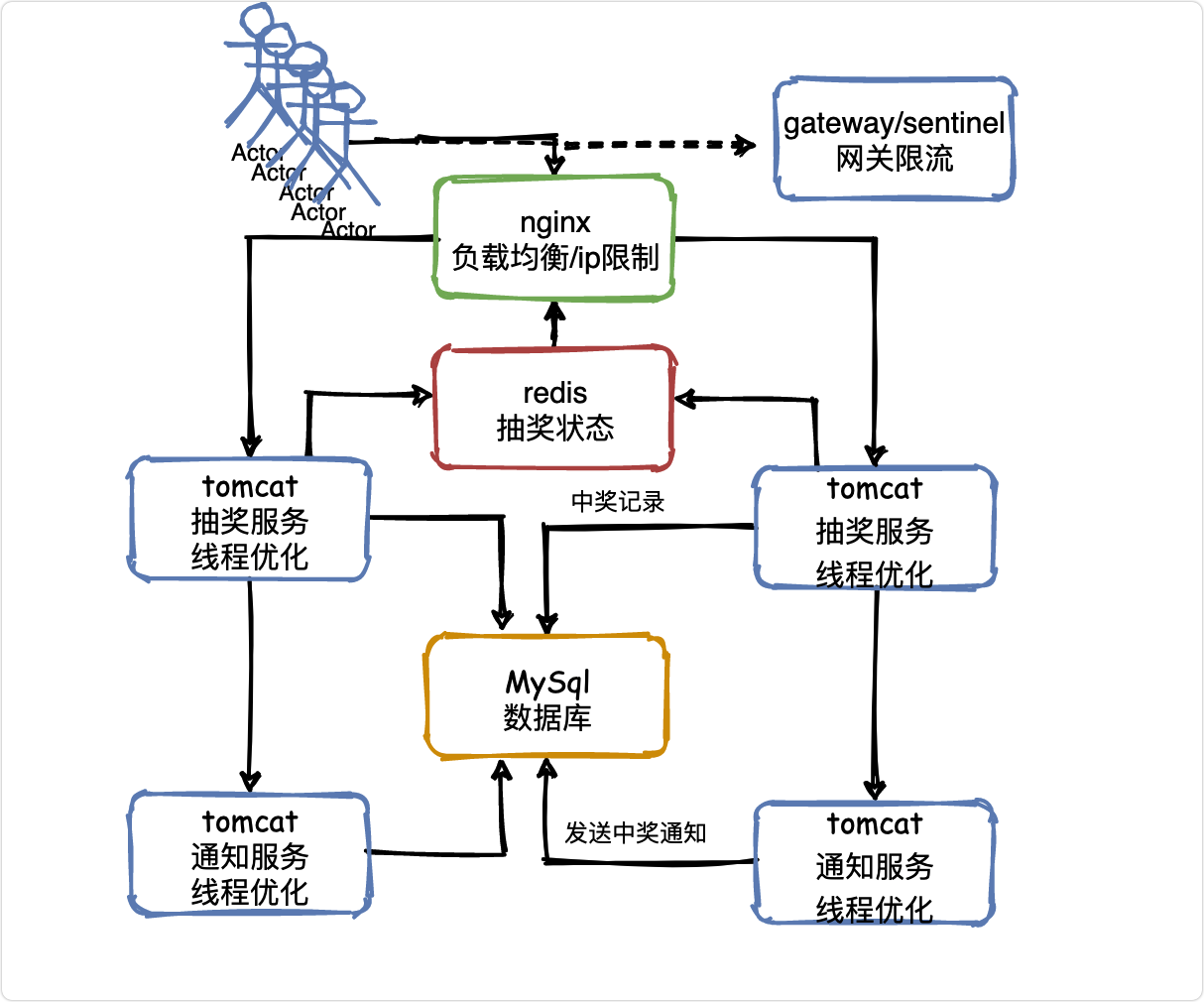
對于線上環境,作業執行緒數量是一個至關重要的引數,需要根據自己的情況調節,
眾所周知,對于進入Tomcat的每個請求,其實都會交給一個獨立的作業執行緒來進行處理,那么Tomcat有多少執行緒,就決定了并發請求處理的能力,
但是這個執行緒數量是需要經過壓測來進行判斷的,因為每個執行緒都會處理一個請求,這個請求又需要訪問資料庫之類的外部系統,所以不是每個系統的引數都可以一樣的,需要自己對系統進行壓測,
但是給一個經驗值的話,Tomcat的執行緒數量不宜過多,因為執行緒過多,普通服務器的CPU是扛不住的,反而會導致機器CPU負載過高,最終崩潰,
同時,Tomcat的執行緒數量也不宜太少,因為如果就100個執行緒,那么會導致無法充分利用Tomcat的執行緒資源和機器的CPU資源,
所以一般來說,Tomcat執行緒數量在200~500之間都是可以的,但是具體多少需要自己壓測一下,不斷的調節引數,看具體的CPU負載以及執行緒執行請求的一個效率,
在CPU負載尚可,以及請求執行性能正常的情況下,盡可能提高一些執行緒數量,
但是如果到一個臨界值,發現機器負載過高,而且執行緒處理請求的速度開始下降,說明這臺機扛不住這么多執行緒并發執行處理請求了,此時就不能繼續上調執行緒數量了,
V5業務邏輯
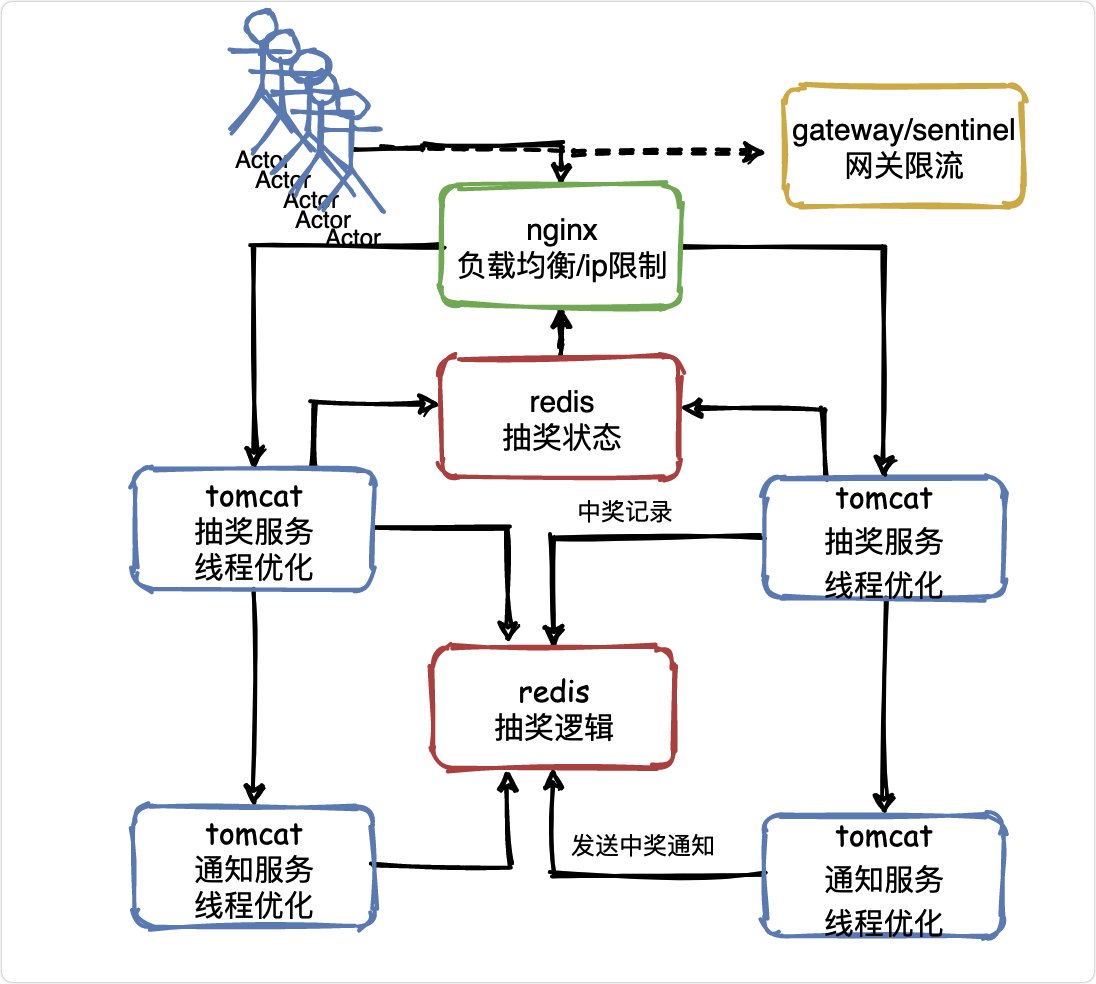
抽獎邏輯怎么做?
好了,現在該研究一下怎么做抽獎了
在負載均衡那個層面,已經把比如50萬流量中的48萬都攔截掉了,但是可能還是會有2萬流量進入抽獎服務,
因為抽獎活動都是臨時服務,可以阿里云租一堆機器,也不是很貴,tomcat優化完了,服務器的問題也解決了,還剩啥呢?
Mysql,是的,你的Mysql能抗住2萬的并發請求嗎?
答案是很難,怎么辦呢?
把Mysql給替換成redis,單機抗2萬并發那是很輕松的一件事情,
而且redis的一種資料結構set很適合做抽獎,可以隨機選擇一個元素并剔除,
V6流量削峰
由上至下,還剩中獎通知部分沒有優化,
思考這個問題:假設抽獎服務在2萬請求中有1萬請求抽中了獎品,那么勢必會造成抽獎服務對禮品服務呼叫1萬次,
那也要和抽獎服務同樣處理嗎?
其實并不用,因為發送通知不要求及時性,完全可以讓一萬個請求慢慢發送,這時就要用到訊息中間件,進行限流削峰,
也就是說,抽獎服務把中獎資訊發送到MQ,然后通知服務慢慢的從MQ中消費中獎訊息,最終完成完禮品的發放,這也是我們會延遲一些收到中獎資訊或者物流資訊的原因,
假設兩個通知服務實體每秒可以完成100個通知的發送,那么1萬條訊息也就是延遲100秒發放完畢罷了,
同樣對MySQL的壓力也會降低,那么資料庫層面也是可以抗住的,
看一下最終結構圖:
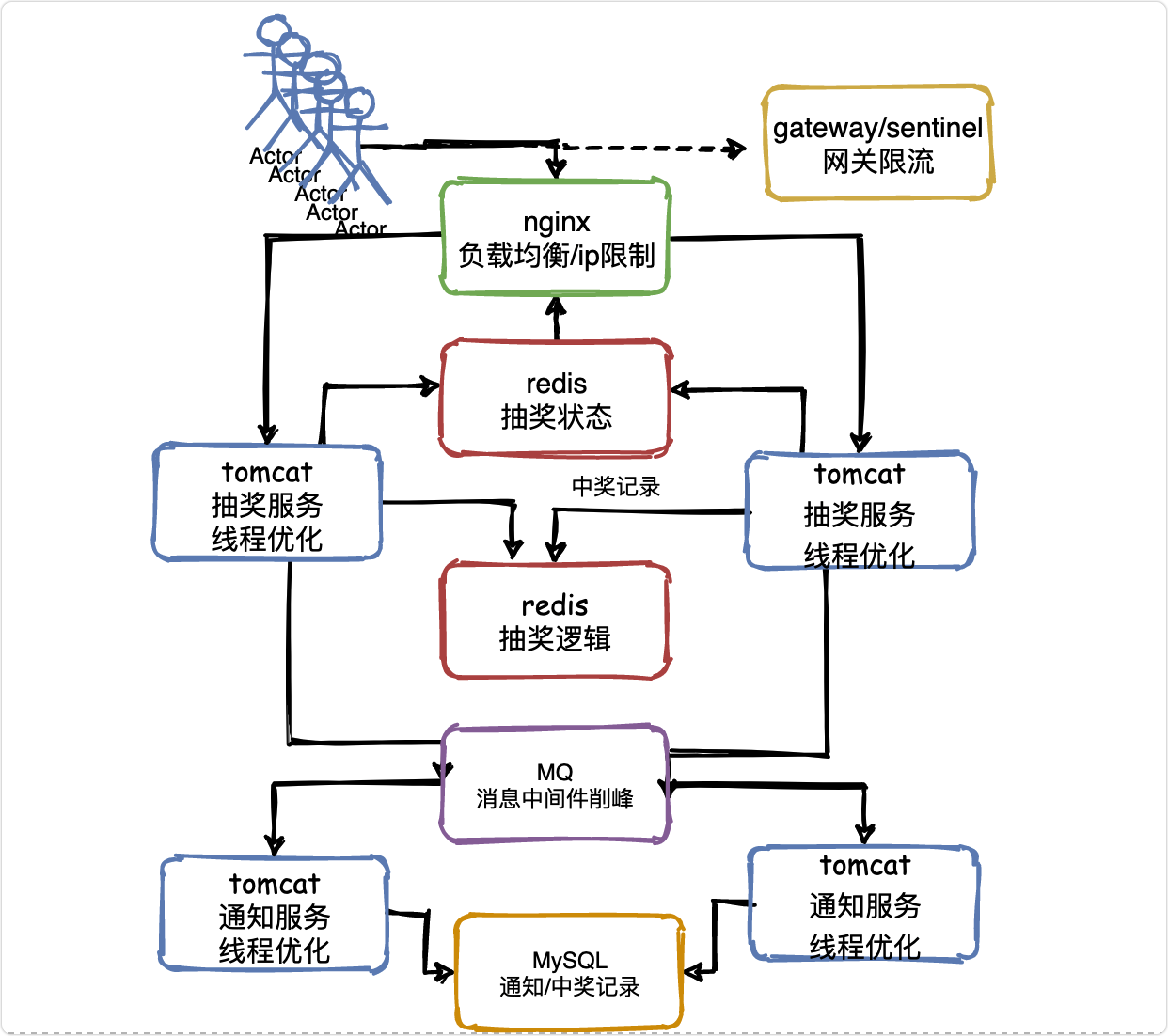
答題模板
所謂答題模板,就是高并發問題的幾個思考方向和解決方案,
單一職責
一個基本的設計思想,回想高中物理的串聯和并聯,串聯一滅全滅,并聯各自有一個通路,
一樣的道理,高內聚,低耦合,
微服務之所以興起就是因為把復雜的功能進行拆分,即使網站崩了,無法下單,但是瀏覽功能依然健康,而不是所有服務引起連鎖反應,像雪崩一樣,全面癱瘓,
URL動態加密
這說的是防止惡意訪問,有些爬蟲或者刷量腳本會造成大量的請求訪問你的介面,你更加不知道他會傳什么引數給你,所以我們定義介面時一定要多加驗證,因為不止是你的朋友調你的介面,敵人也有可能,
靜態資源——CDN
CDN全稱內容分發網路,是建立并覆寫在承載網之上,由分布在不同區域的邊緣節點服務器群組成的分布式網路,
通俗的講,就是把經常訪問又費時的資源放在你附近的服務器上,
淘寶的圖片訪問,有98%的流量都走了CDN快取,只有2%會回源到源站,節省了大量的服務器資源,
但是,如果在用戶訪問高峰期,圖片內容大批量發生變化,大量用戶的訪問就會穿透cdn,對源站造成巨大的壓力,
所以,對于圖片這種靜態資源,盡可能都放入CDN,
服務限流
在上面已有講解,可分為前端限流和后端限流,
- 前端:按鈕禁用,ip黑名單
- 后端:服務熔斷,服務降級,權限驗證
資料預熱
可以采用定時任務(elastic-job)實時查詢Druid,把熱點資料放入redis快取中,
思考一個問題:
比如現在庫存只剩下1個了,我們高并發嘛,4個服務器一起查詢了發現都是還有1個,那大家都覺得是自己搶到了,就都去扣庫存,那結果就變成了-3,是的只有一個是真的搶到了,別的都是超賣的,咋辦?
回答:
可以用CAS+LUA腳本實作,
Lua腳本是類似Redis事務,有一定的原子性,不會被其他命令插隊,可以完成一些Redis事務性的操作,這點是關鍵,
寫一個腳本把判斷庫存扣減庫存的操作都寫在一個腳本丟給Redis去做,那到0了后面的都Return False了是吧,一個失敗了你修改一個開關,直接擋住所有的請求,
削峰填谷
精通一個中間件會給你加分很多
訊息佇列已經逐漸成為企業IT系統內部通信的核心手段,
它具有低耦合、可靠投遞、廣播、流量控制、最終一致性等一系列功能,成為異步RPC的主要手段之一,
當今市面上有很多主流的訊息中間件,如老牌的ActiveMQ、RabbitMQ,炙手可熱的Kafka,阿里巴巴自主開發RocketMQ等,
最原始的MQ,生產者先將訊息投遞一個叫做「佇列」的容器中,然后再從這個容器中取出訊息,最后再轉發給消費者,僅此而已,
更詳細的MQ下文再續,
今天就學這么多,相信大家都對高并發系統有了初步的認識,面試官問起來也不至于無話可說,但是想要學好任重而道遠,希望大家關注一條,帶各位一起學習!
最后
?今天是堅持刷題更文的第52/100天
?各位的點贊、關注、收藏、評論、訂閱就是一條創作的最大動力
?更多干歡訓迎訂閱專欄《技術專家修煉》
為了回饋各位粉絲,禮尚往來,給大家準備了一條多年積累下來的優質資源,包括 學習視頻、面試資料、珍藏電子書等
需要的小伙伴請私信「資料」,記得先關注哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/298654.html
標籤:java
上一篇:淺析 DDD 領域驅動設計