目錄
前言
準備作業
分析(x0)
分析(x1)
分析(x2)
分析(x3)
代碼
結語
前言
本人所有文章內容、原始碼,除官方企業外,禁止個人轉載,謝謝配合,
....太多培訓機構拿我的文章原始碼去講公開課了,還有很多培訓機構的招生員拿我原始碼自己編個小故事直接就是一篇文章(但凡這種都是一大堆廢話+原始碼,毫無分析邏輯),
大家好,我叫善念,有大概一周沒有來更新博文了,一個原因是反響并不理想,第二個原因則是每篇文章都是現寫的,花費的時間并不少,
其實我并不是非常想更新這篇文章,這樣子會造成很多人利用我的辦法,給大家帶來一些生活上的小困擾,可是很多人又很想學,我只想說:技術無罪,
在這里真心感謝一直在支持我的那幾個粉絲,謝謝你們的持續關注點贊,

準備作業
使用到的模塊
from selenium import webdriver
import json
import requests
import execjs
import jsonpath模塊的安裝
主要利用到這五個模塊,其中json為內置模塊,其它均為第三方模塊,安裝方式如下所示:
pip install selenium
pip install requests
pip install PyExecjs
pip install jsonpath插件的安裝
關于selenium這個模塊,咱們來重點介紹一下:
Selenium是一個用于Web應用程式測驗的工具,Selenium測驗直接運行在瀏覽器中,就像真正的用戶在操作一樣,
如果不能夠理解我就講點白話,如果你是web開發人員,開發好了幾百個網站,那么如果你認為的去一個個的測驗BUG,是不是很浪費時間?而selenium這個框架就是用來模擬人去自動化操控瀏覽器的,那么是不是就節約了很多時間呢,
既然selenium能夠操控瀏覽器,那么它們之間必須要有一個橋梁,總不能無中生有吧?
那么操控的瀏覽器款式不一樣,中間的橋梁也是不一樣的,比如我更喜歡用chrome瀏覽器,那么咱們需要下載一個selenium與Chrome的橋梁——Chromedriver插件
下載地址
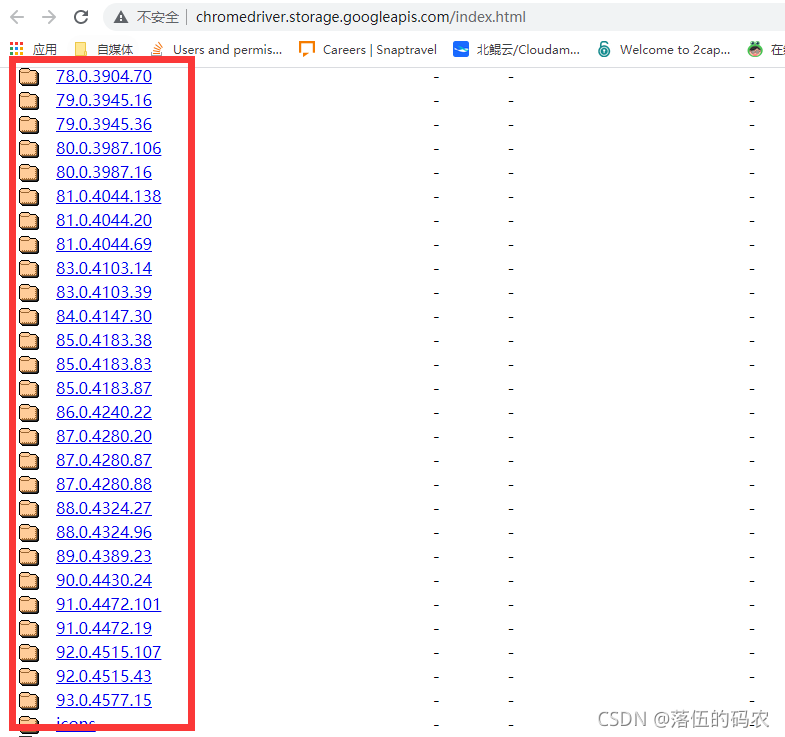
下載與你當前谷歌瀏覽器版本最相近的Chromedriver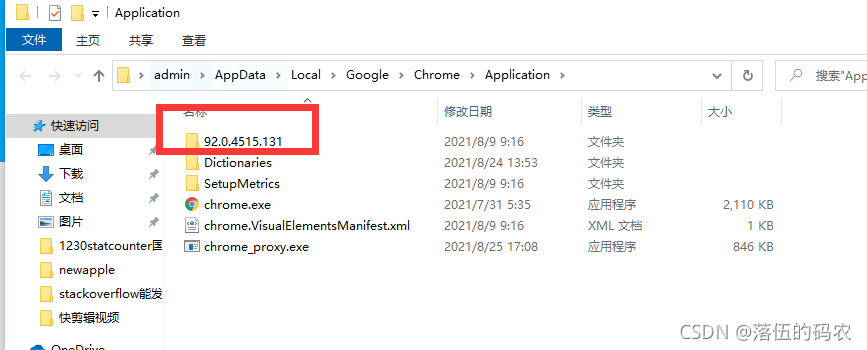
那么像我的話,下載![]() 即可,
即可,
Windows系統需下載32位,其它的自己看著辦,點進去下載win32即可,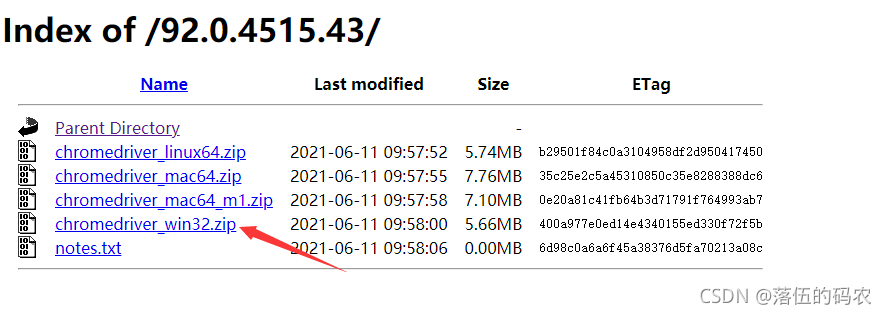
那么如何讓Python與selenium連接起來呢,這里咱們需要配置一個環境變數,就是把Python與selenium處于同一個目錄:

到此為止,咱們的環境就搭建好了,
分析(x0)
進入咱們的目標網站:目標網站
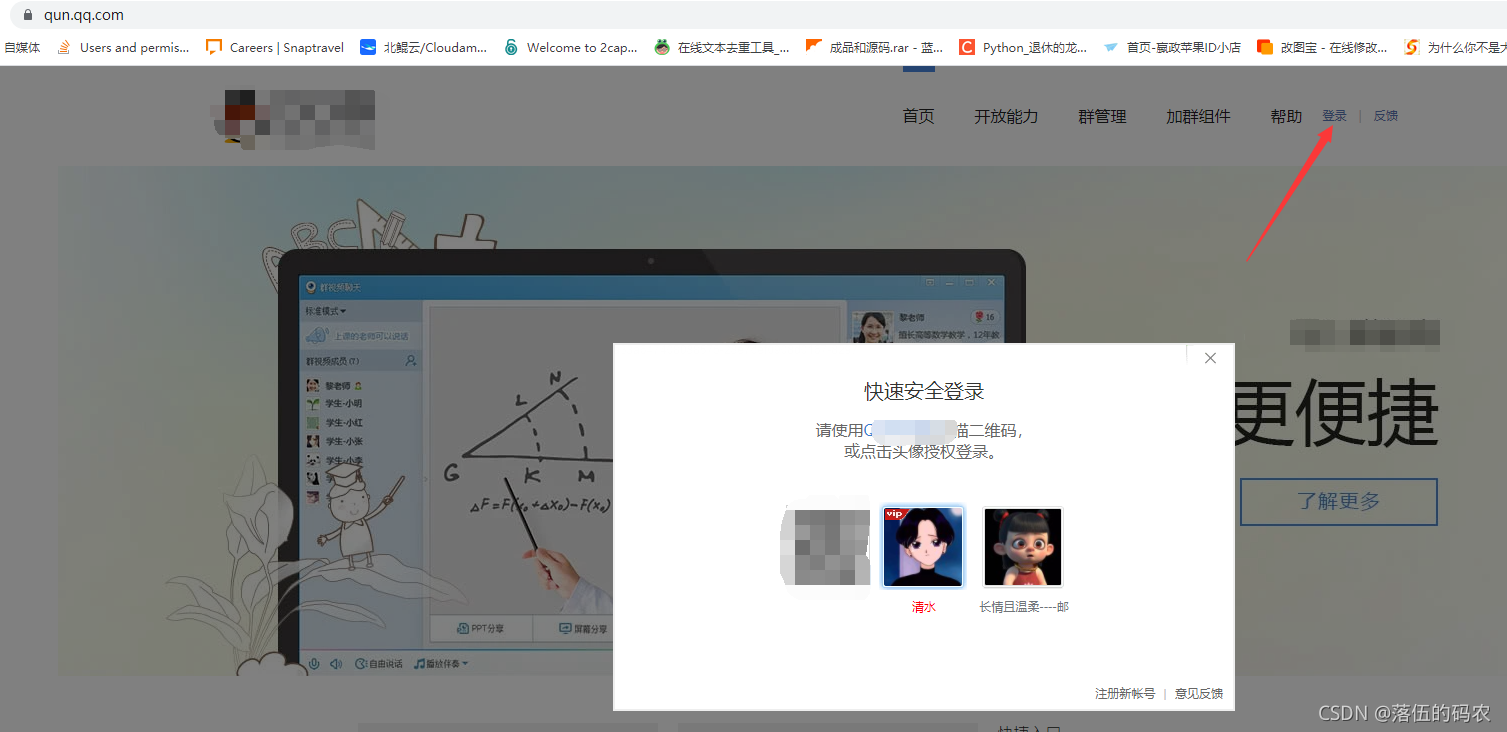
點擊登錄后點擊群管理:
再點擊成員管理,進入咱們的資料頁面: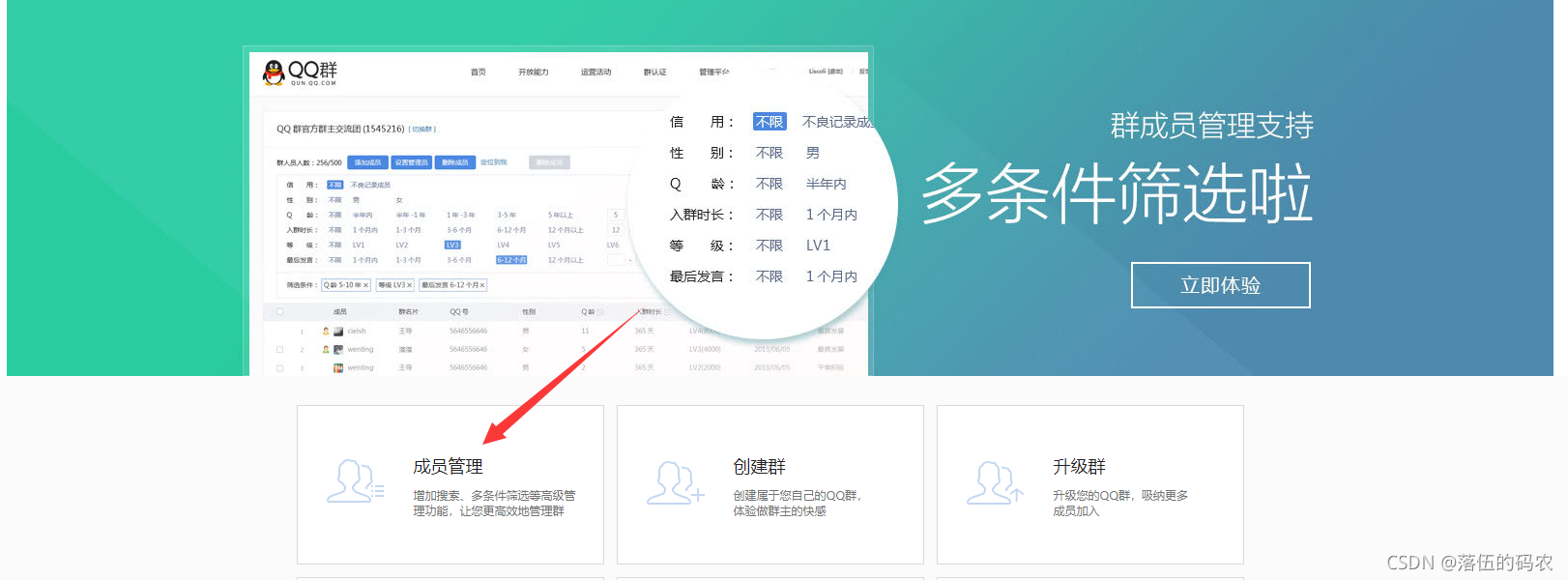
在這個頁面可以看到有很多的群,我們隨便點擊一個就可以看到當群的成員資料: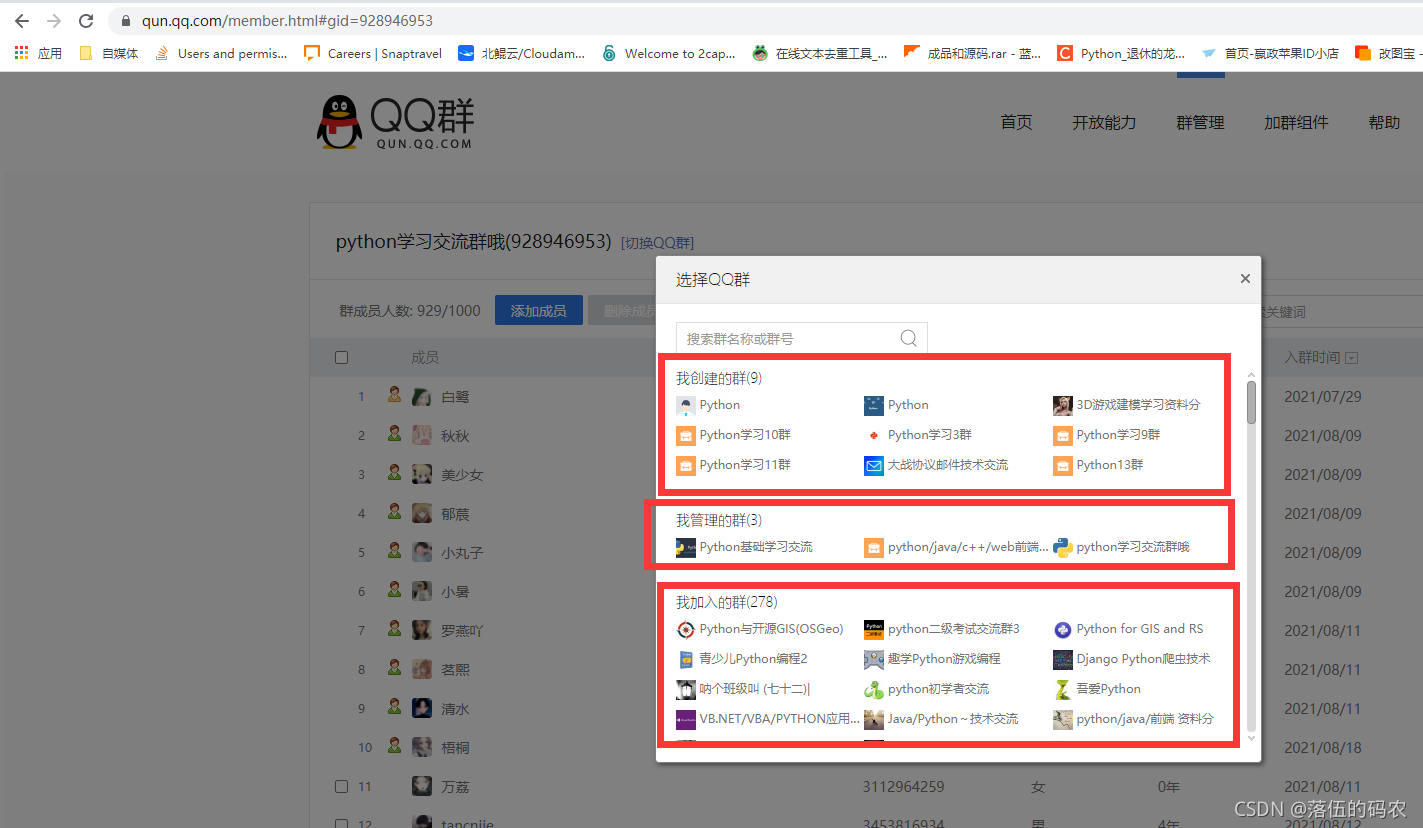
可以看到咱們的群的號碼其實就在當前網頁的url中....不難想到它的url就是隨咱們的群的號碼變化的,
以此群為例,咱們看下網頁源代碼中是否包含咱們的資料,直接搜一下自己的號碼即可,因為我自己是肯定在群當中的嘛: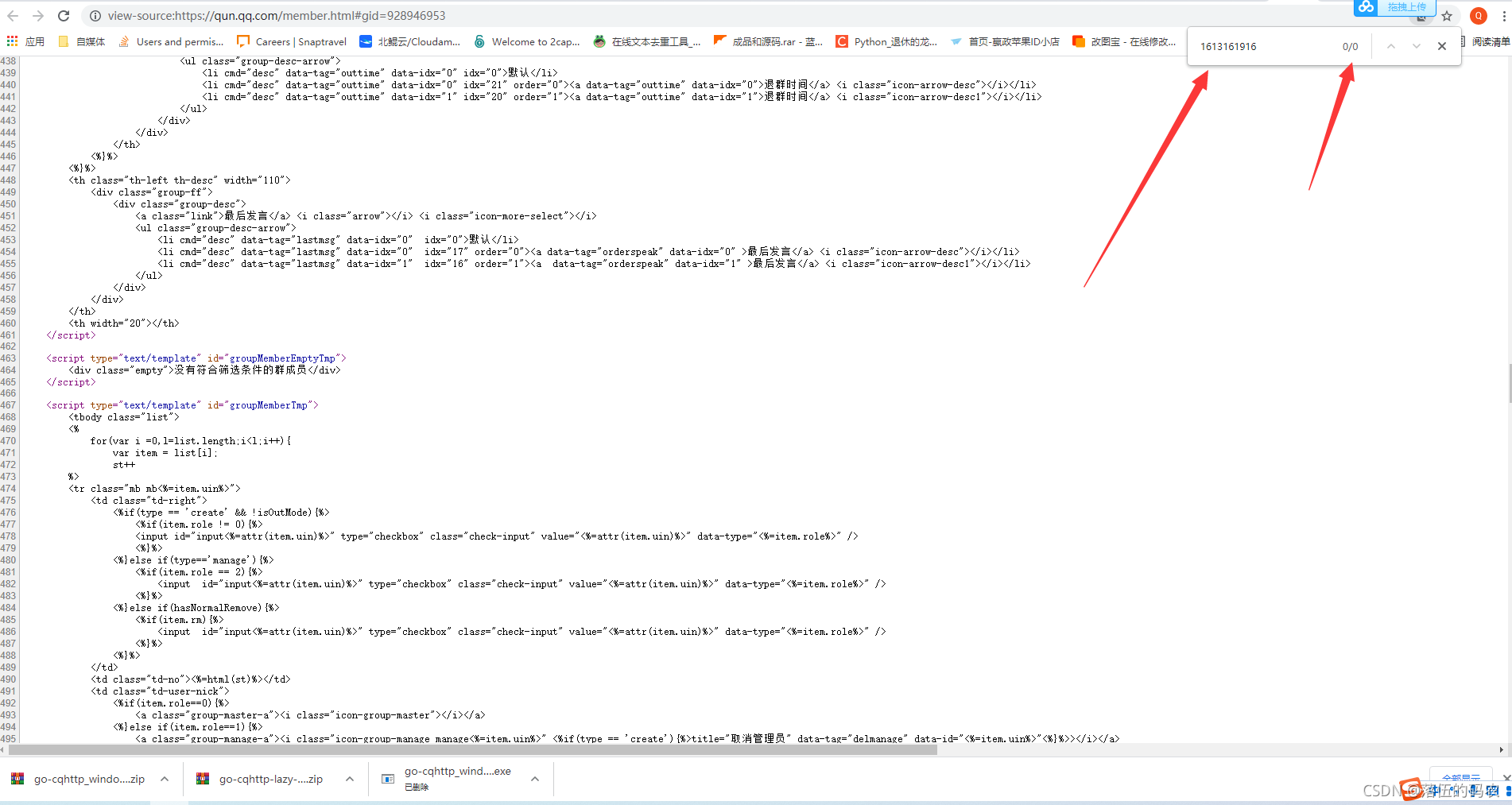
emmm什么都沒有,再去網頁元素中看一下吧: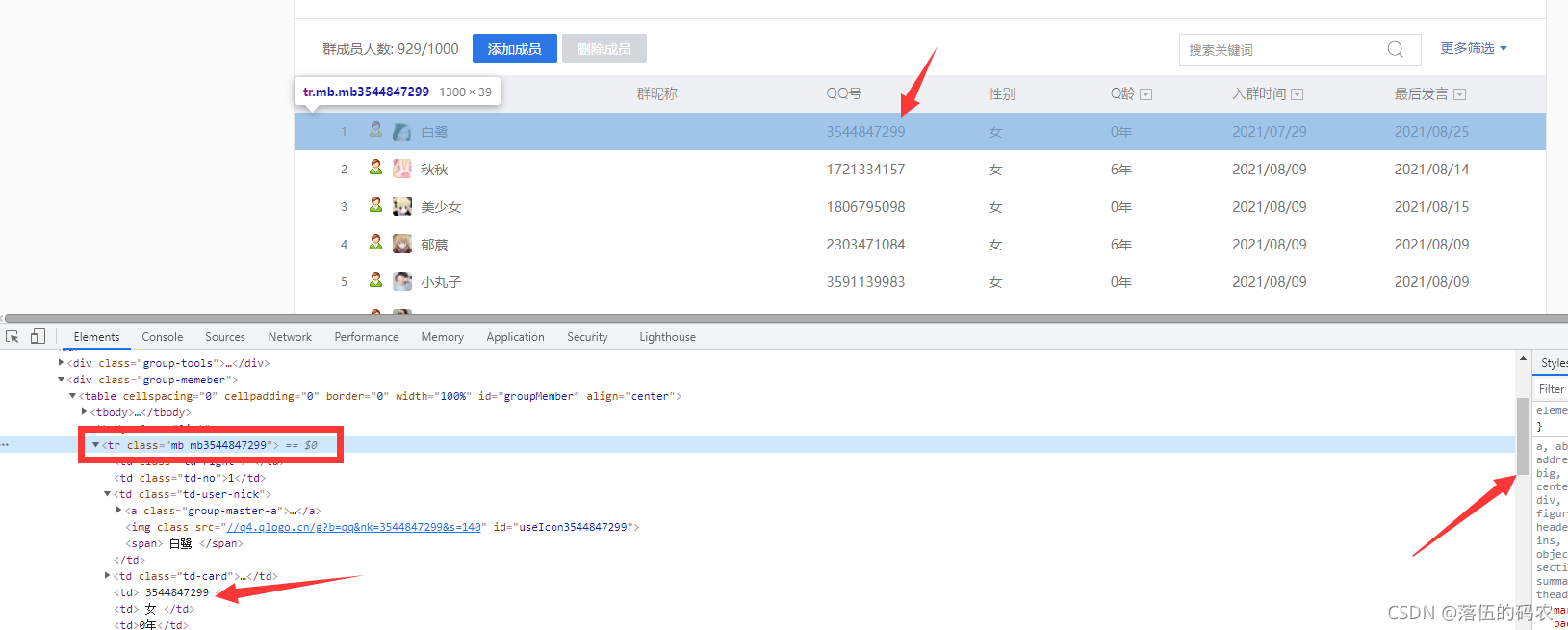
網頁元素中是有的,一個tr標簽保存了一個成員資訊,不過我群里九百多個人,為什么右邊的進度條這么粗....
說明什么?異步加載咯,經常說到得瀑布流,當我們拉動下滑條的時候才會重繪出更多得成員資料
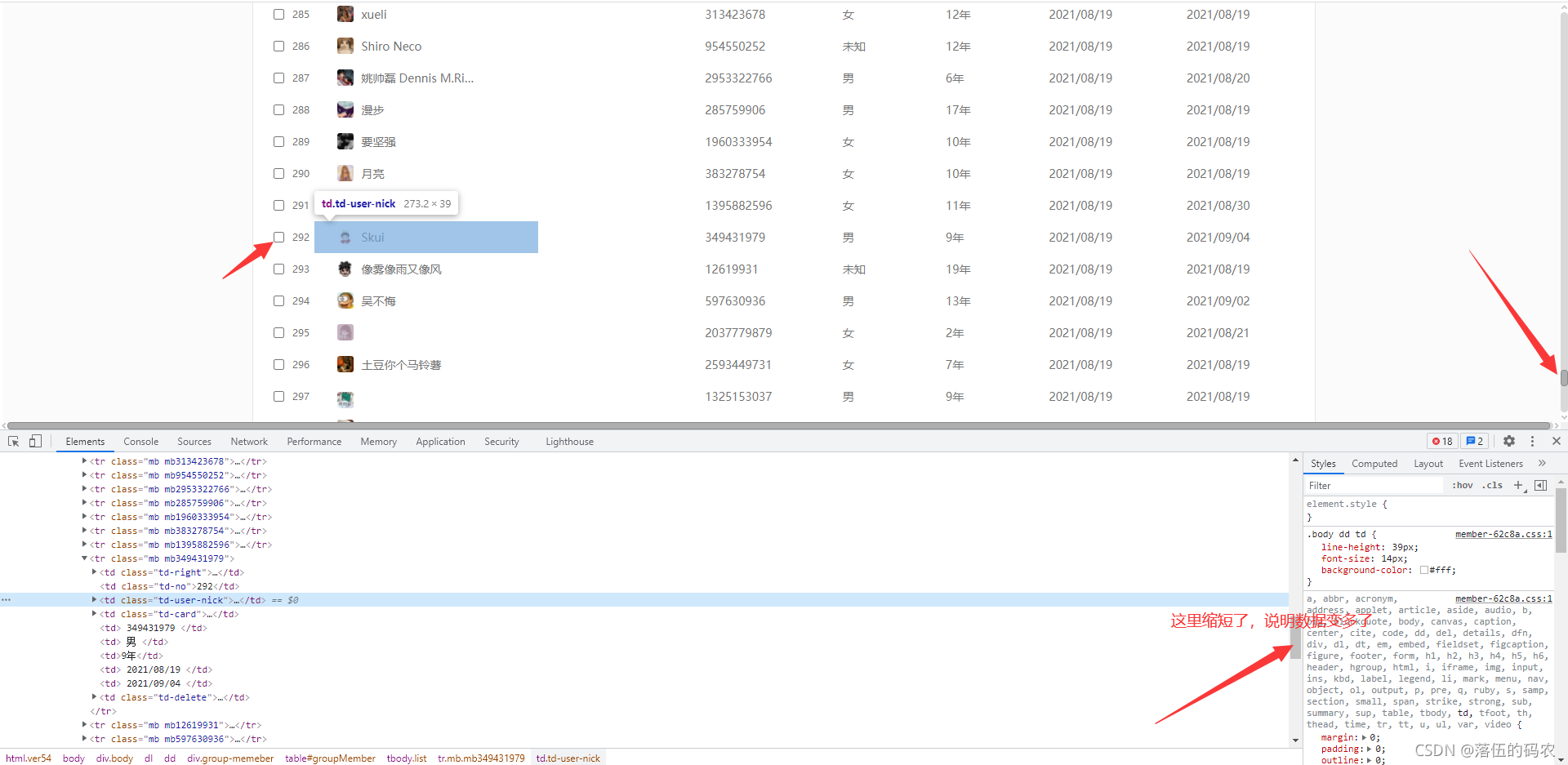
明顯看得到吧,當我們拉動下滑條后,元素中的元素變多了,那個進度條變短了,
分析(x1)
那么就可以總結出來思路了,就是當我們用selenium模擬人打開一個瀏覽器,然后我們登錄、點開群管理、找到需要采集的群點擊(或者直接進入到當前群的url也是可行的)、最后就是拉動下滑條然后用selenium從網頁元素上爬取資料咯,
應該不難理解吧,這其實就是我們剛才人為做的一個事情,我只是用selenium代替我們人去模擬這個事情再做一遍,
而我反復強調過:selenium的速度太慢太慢,盡量不要去使用它!
那么怎么辦?抓包唄,網頁源代碼中沒有資料,而下拉滑動條后網頁元素中出現了該資料,不就是說明當我們拉動下滑條就執行了一些JavaScript腳本或者一些介面從而產生了資料?
資料也是不可能無中生有的,總有個來源,咱們監聽下服務器與客服端的一個交流程序:
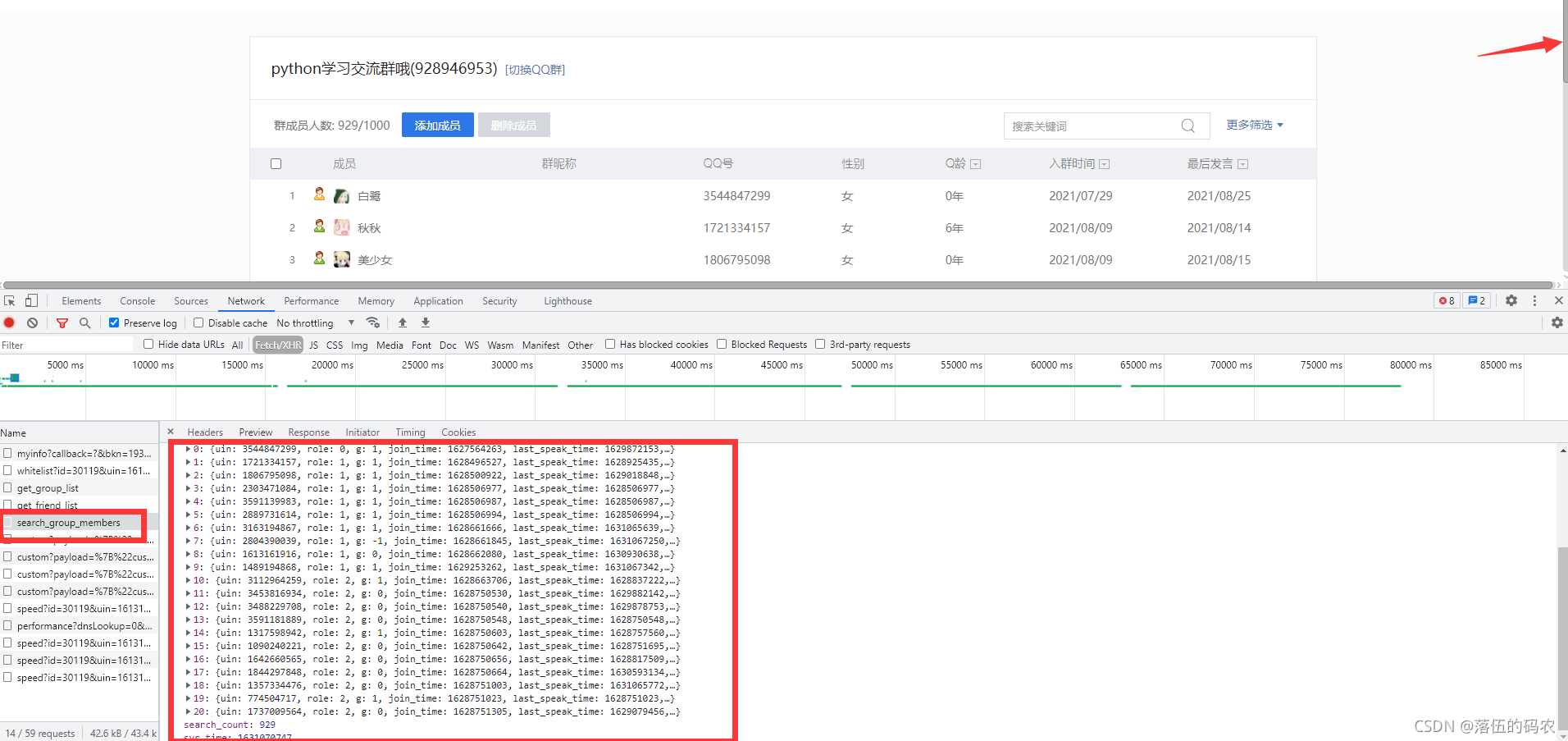
重繪當前網頁抓包后,可以看到咱們抓的包當中生成了0-20就是21條資料,然后再看看這個包需要的引數: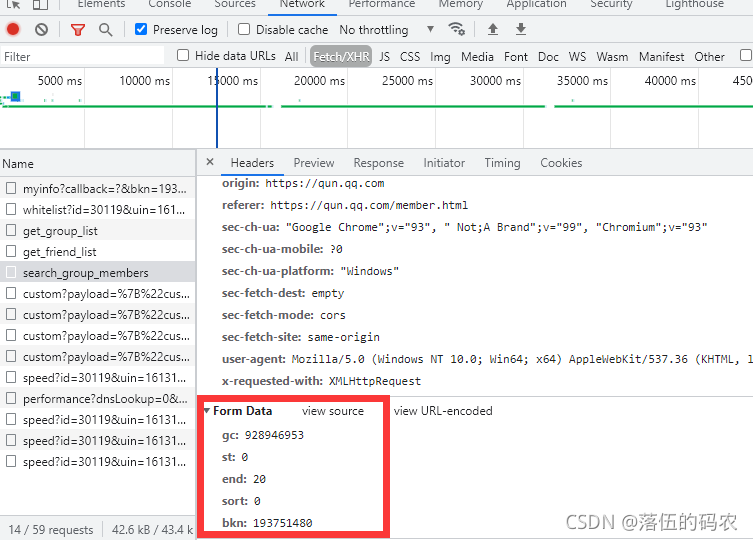
是一個post請求,然后引數的話...gc貌似就是群的號碼,然后st為0、end為20啥的估計就是說0-20總共21條資料吧,bkn......大頭菜,明顯不是一個時間戳,按道理是JavaScript加密,
我們再拉動點滑動條往下面拉,再抓一個包看看有沒有什么引數發生變化:
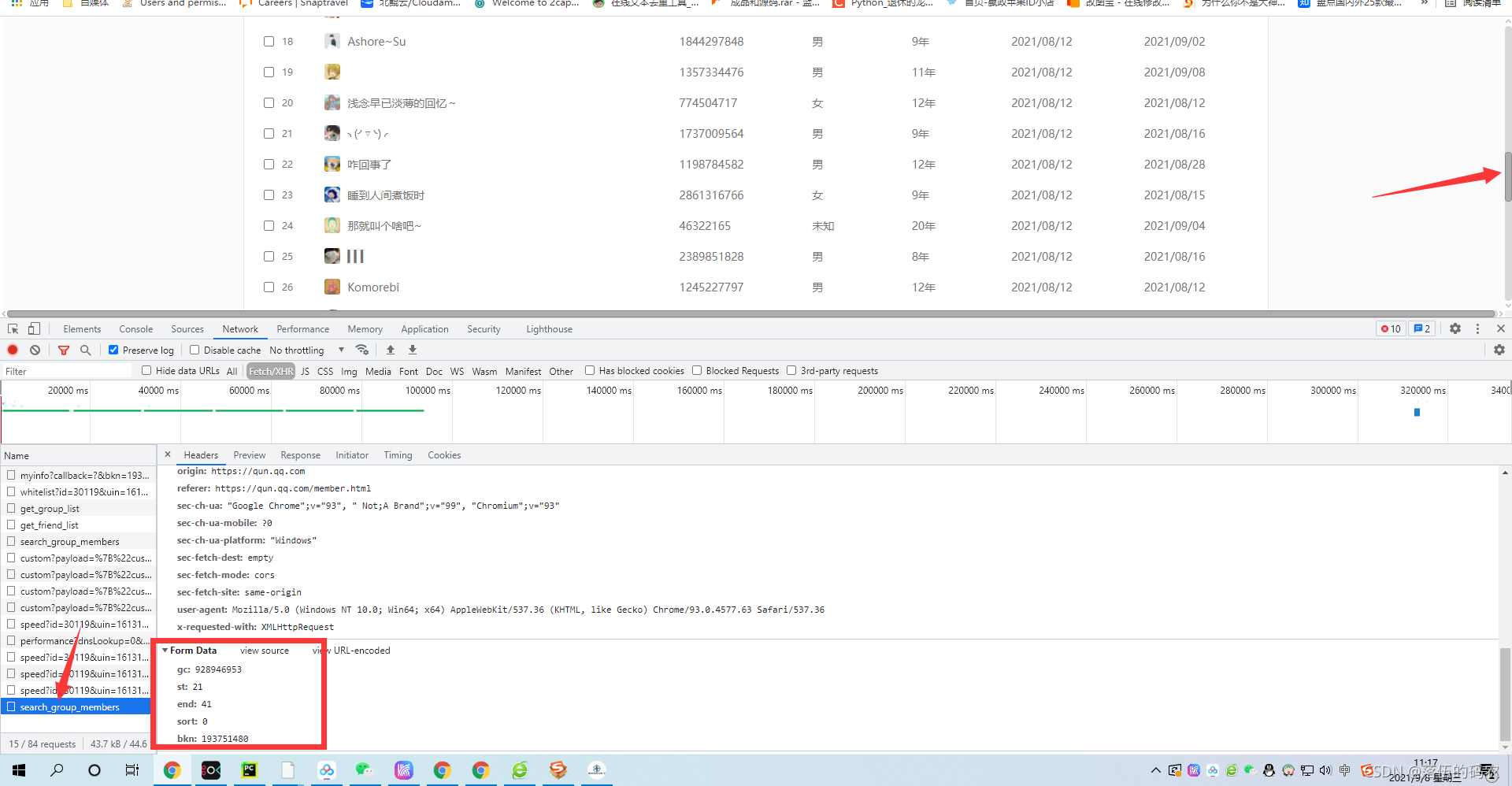
果然0-20就是代表一個資料的排序,比如我第一個包是0-20是前面的21條資料,那么第二個包當然就是21-41了,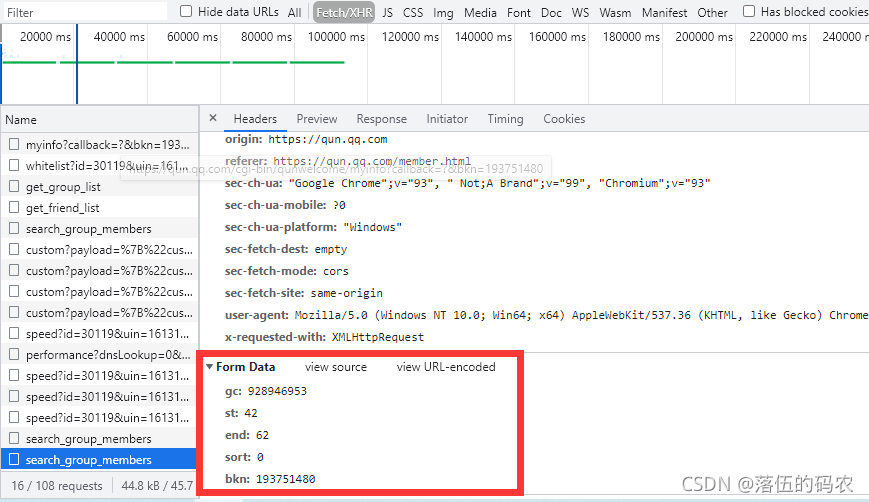
果然,第三個包也是按21的步差來的,而sort為零不變,bkn也不變,
分析(x2)
走吧,開始去分析咱們的bkn是如何生成的:
上次有人問我,這個玩意該怎么搜...我這里告訴你們了,先點一下那三個點,然后點擊search:
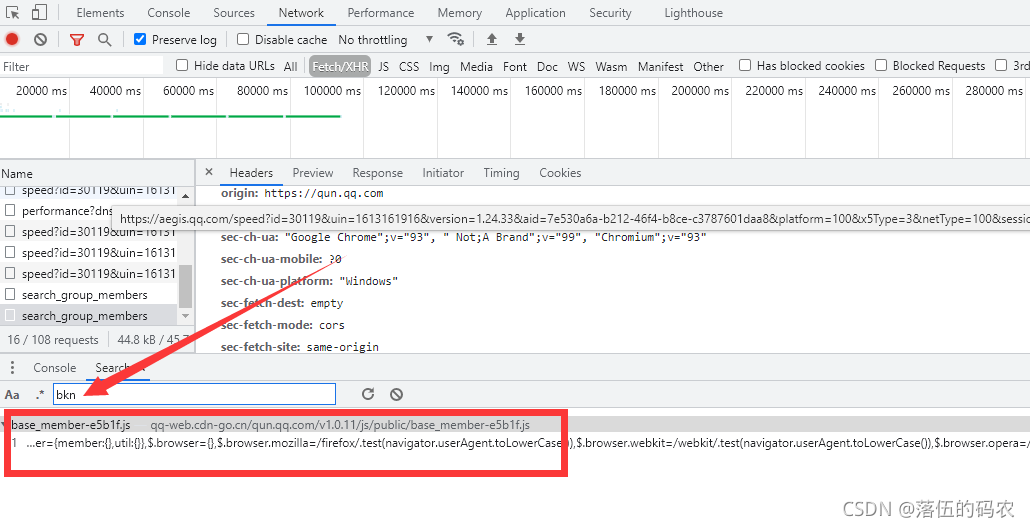
可以看到就一個JS檔案中包含bkn,簡直完美了,事情變得越來越簡單,
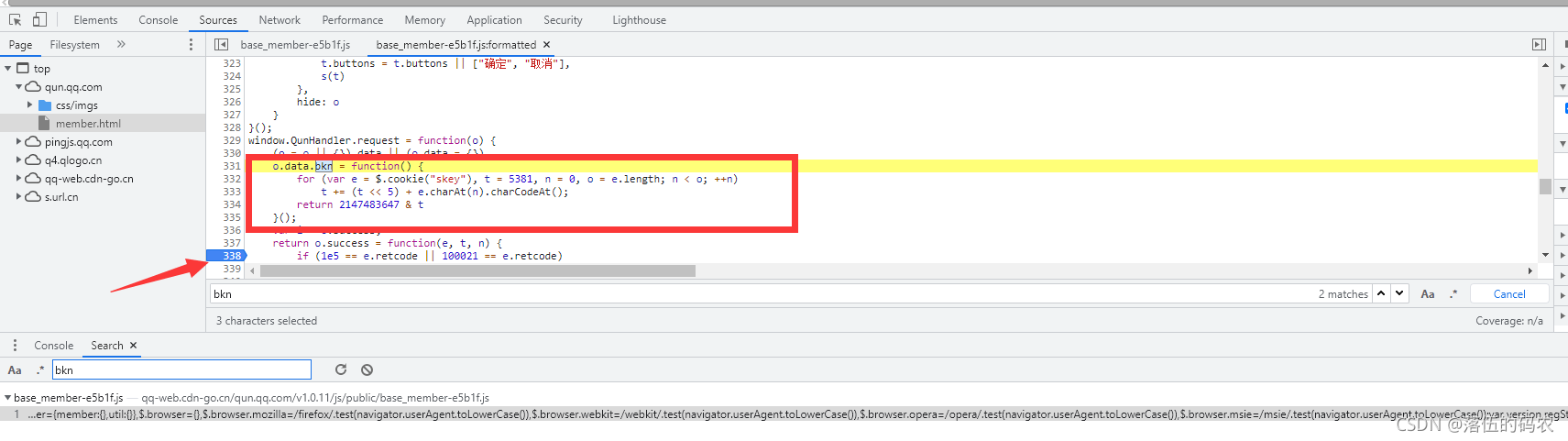
請不要遇到JavaScript加密就鬧心,靜下心來好好看看
o.data.bkno字典里面的data里面的bkn就是個嵌套而已,也就是說明bkn屬于o字典里面的一個鍵,然后它居然賦值給了一個函式function,注意看結尾用了一個()啥意思?
把把函式賦值給一個變數bkn,然后呼叫該函式,說明什么?bkn就為函式中return的值呀......是不是很簡單?看不懂多看幾遍,
函式里面的話就是個回圈咯,當條件不滿足時就一直加,知道條件滿足為止,看不懂可以去學學基本的JavaScript語法,不學也問題不大,咱們直接摳JavaScript代碼也行,
for (var e = $.cookie("skey"), t = 5381, n = 0, o = e.length; n < o; ++n)
t += (t << 5) + e.charAt(n).charCodeAt();
return 2147483647 & te為cookie中"skey"鍵所對應的值,o為e這個字串的長度,n起始值為0.....居然都是已知資料,壓根沒有變數,那么咱們看看skey對應的值是啥:
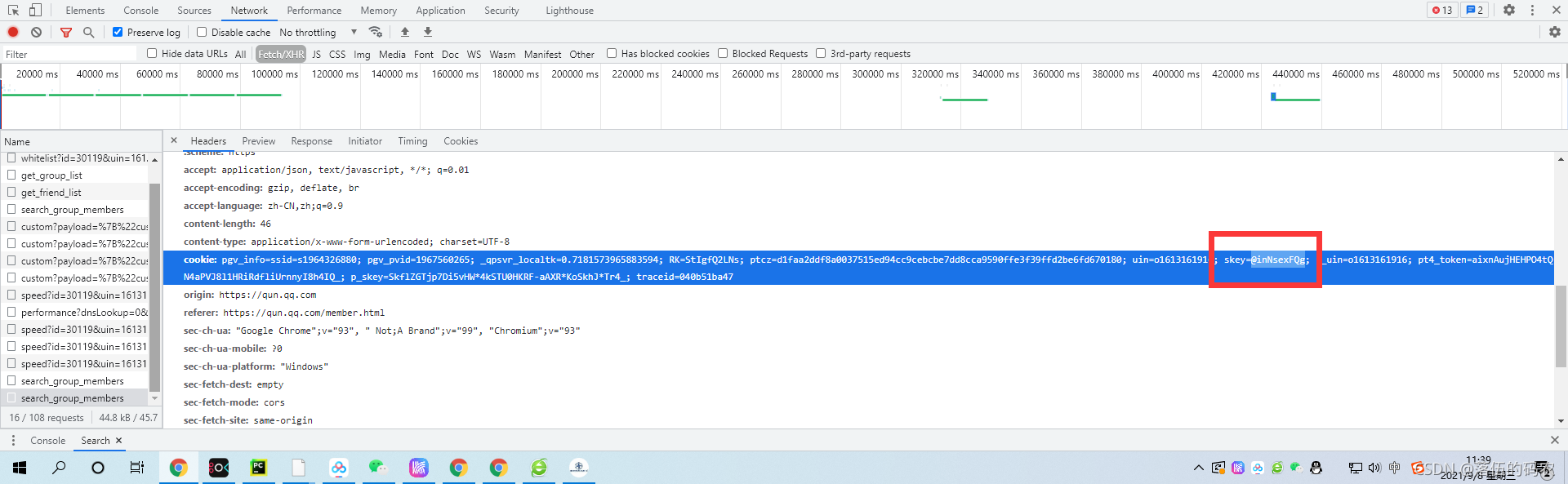
好像問題是已經解決了吧,那么咱們來測驗一下: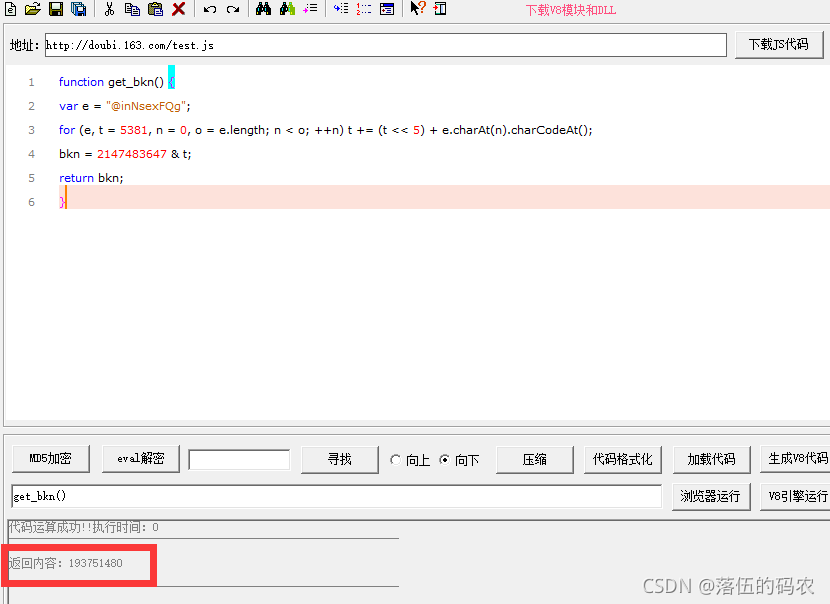
看下與咱們的post引數是否相同: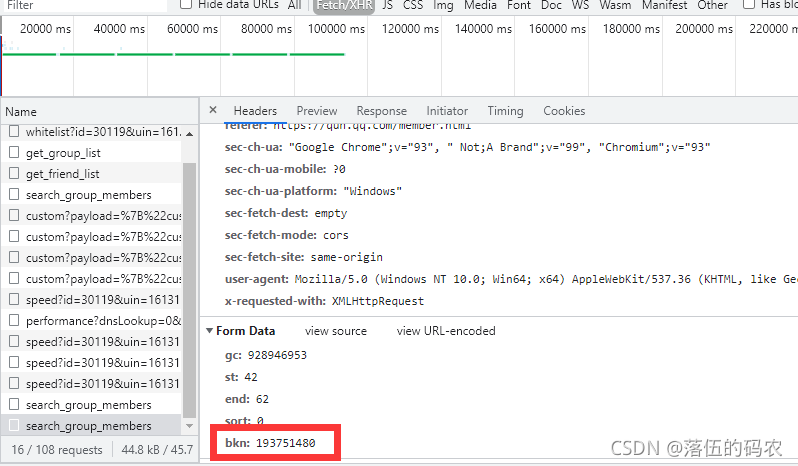
emmmmm,大功告成拉!
分析(x3)
總結下思路:
1.利用selenium打開瀏覽器然后登錄
2.獲取cookies保存(后期用來解密bkn的)
3.解密JavaScript
4.發送post請求想要采集的群號
代碼
JS代碼:
function GetBkn(e) {
for (t = 5381, n = 0, o = e.length; n < o; ++n) t += (t << 5) + e.charAt(n).charCodeAt();
return 2147483647 & t
}Python代碼:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/6/02 21:44
# @Author : 善念
# @File : demo12.py
# @Software: PyCharm
from selenium import webdriver
# from time import sleep
import json
import requests
import execjs
import jsonpath
# import sys
def get_cookies():
driver = webdriver.Chrome()
driver.get('https://qun.qq.com/manage.html#click')
driver.find_element_by_xpath('//*[@id="headerInfo"]/p[1]/a').click()
# sleep(5)
input('登陸后請按Enter')
cookie_list = driver.get_cookies()
cookie = {}
for i in cookie_list:
cookie[i["name"]] = i["value"]
with open("cookies.txt", "w") as f:
f.write(json.dumps(cookie))
f = open("cookies.txt")
# 字串轉字典
cookies = json.loads(f.read())
f.close()
driver.close()
return cookies
def get_bkn(cookies):
e = cookies['skey']
with open("gtk.js", encoding='utf-8') as f:
jsData = f.read()
js_text = execjs.compile(jsData)
bkn = js_text.call('GetBkn', e)
return bkn
def get_data(bkn, cookies):
headers = {
'origin': 'https://qun.qq.com',
'referer': 'https://qun.qq.com/member.html',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.29 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
qq_group = input('請輸入你要查詢的QQ群號碼:')
offset = 21
max_num = []
for index, i in enumerate(range(0, 5000, offset)):
data = {
'gc': qq_group,
'st': i,
'end': 20 + offset*index,
'sort': '0',
'bkn': bkn,
}
req = requests.post('https://qun.qq.com/cgi-bin/qun_mgr/search_group_members', headers=headers, data=data, cookies=cookies).json()
qq_numbers = jsonpath.jsonpath(req, '$..uin',)
qq_names = jsonpath.jsonpath(req, '$..nick',)
try:
max_num.append(len(qq_numbers))
for QQ_number, QQ_name in zip(qq_numbers, qq_names):
with open(qq_group+'.txt', 'a', encoding='utf-8')as f:
f.write(str(QQ_number)+'@qq.com'+'\n')
print('共獲得成員數:%d' % sum(max_num))
except TypeError:
exit()
def go():
cookies = get_cookies()
bkn = get_bkn(cookies)
get_data(bkn, cookies)
if __name__ == '__main__':
go()
結語
當你毫無保留的信任一個人,最終只會有兩個結果,不是生命中的那個人,就是生命中的一堂課,
但凡文章內容中有不懂之處,歡迎及時私信于我,我每天都會抽時間給我的粉絲解答,給與一些學習資源,
原創不易,再次謝謝大家~

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/298667.html
標籤:python