一、簡介
索參考于快速找出在某個列中有一特定值的行,
不使用索引,MySQL必須從第一條記錄開始讀完整個表,直到找出相關的行,表越大,查詢資料所花費的時間就越多,如果表中查詢的列有一個索引,MySQL能夠快速到達一個位置去搜索資料檔案,而不必查看所有資料,那么將會節省很大一部分時間,
如果有了索引,那么會將該Phone欄位,通過一定的方法進行存盤,好讓查詢該欄位上的資訊時,能夠快速找到對應的資料,
二、優缺點
2.1優點
-
所有的MySql列型別(欄位型別)都可以被索引,也就是可以給任意欄位設定索引
-
大大加快資料的查詢速度
2.2缺點
創建索引和維護索引要耗費時間,并且隨著資料量的增加所耗費的時間也會增加
索引也需要占空間,資料表中的資料也會有最大上限的
如果我們有大量的索引,索引檔案可能會比資料檔案更快達到上線值
當對表中的資料進行增加、洗掉、修改時,索引也需要動態的維護,降低了資料的維護速度,
三、分類
操作:
查看索引:show index from
洗掉索引:drop index <索引名> on <表名>
3.1 單列索引
1.主鍵索引(自動創建)
create table user(id varchar(20) primary key,name varchar(20))
2.普通索引
MySQL中基本索引型別,沒有什么限制,允許在定義索引的列中插入重復值和空值,純粹為了查詢資料更快一點,
-建表時創建(此時索引名和列名相同)
create table user(id varchar(20) primary key, name varchar(20),key(name))
-建表后創建
create index name_index on user(name)
3.唯一索引
索引列中的值必須是唯一的,但是允許為空值,
-建表示創建
create table user(id varchar(20) primary key, name varchar(20),unique(name))
-建表后創建
create unique index name_index on user(name)
3.2 組合索引(復合索引)
在表中的多個欄位組合上創建的索引
只有在查詢條件中使用了這些欄位的左邊欄位時,索引才會被使用,使用組合索引時遵循最左前綴集合,
-建表示創建
create table user (id varchar(20) primary key, name varchar(20), age int,key(name,key))
-建表后創建
create index name_age_index on user(name,age)
MySQL 最左前綴原則
mysql 建立多列索引(聯合索引)有最左前綴的原則,即最左優先,如:
如果有一個 2 列的索引 (col1, col2),則已經對 (col1)、(col1, col2) 上建立了索引;
如果有一個 3 列索引 (col1, col2, col3),則已經對 (col1)、(col1, col2)、(col1, col2, col3) 上建立了索引;
并且mysql 具有查詢優化器:
MySQL 的查詢優化器會自動調整 where 子句的條件順序以使用適合的索引,所以 MySQL 不存在 where 子句的順序問題而造成索引失效
四、資料結構

在mysql 使用InnoDB存盤引擎時,首先會將插入的資料按照主鍵進行排序從而形成一個單向鏈表,然后為了提高查找效率,mysql就將單向鏈表升級成了B+樹,
一般高度為3的B+數可存盤的記錄為10億左右,因此對于我們2-3層樹就足夠了,
4.1 B+樹特點
B+樹是B樹的一種變形,比B樹具有更廣泛的應用
- 為所有葉子結點增加一個鏈指標;
- 所有關鍵字都在葉子結點出現;
- 非葉子結點作為葉子結點的索引;B+樹總是到葉子結點才命中;
4.2為什么使用B+數
五、聚簇/非聚簇索引
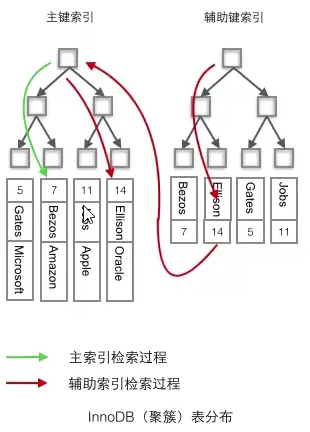
5.1 聚簇索引
定義
將資料與索引放到了一起,索引結構的葉子節點保存了行資料,
簡介
1.如果一個主鍵被定義了,那么這個主鍵就是作為聚集索引
-
如果沒有主鍵被定義,那么該表的第一個唯一非空索引被作為聚集索引
-
如果沒有主鍵也沒有合適的唯一索引,那么innodb內部會生成一個隱藏的主鍵作為聚集索引,這個隱藏的主鍵是一個6個位元組的列,改列的值會隨著資料的插入自增,
-
自增主鍵會把資料自動向后插入,避免了插入程序中的聚集索引排序問題,聚集索引的排序,必然會帶來大范圍的資料的物理移動,這里面帶來的磁盤IO性能損耗是非常大的,
注意
? 主鍵索引一定是聚簇索引(在mysql資料庫innodb引擎里面,主鍵的確就是聚集索引,)
5.2 非聚簇索引(輔助索引)
將資料與索引分開存盤,索引結構的葉子節點指向了資料對應的位置,
輔助索引訪問資料總是需要二次查找
葉子節點存盤的是主鍵值:(不存主鍵地址原因)如果資料記錄發生了頁裂變導致資料地址變了,那輔助索引也要更新,對于這種情況來說存盤主鍵更好
5.3注意
建議使用int 自增作為主鍵
原因:
聚簇索引的資料在索引中存放順序與物理存放順序是一樣的,那么,只要索引是相鄰的,對應的資料在磁盤上也是相鄰的,
如果不是自增id,那么在添加記錄時就會不斷地調整資料的地址、資料的物理地址、分頁,而不是直接添加到索引樹的末尾,
如果是自增的,就簡單了,直接一頁一頁逐步添加,索引結構相對緊湊,并且磁盤碎片也少,效率高,
六、無法使用索引
情況一:查詢陳述句中使用like關鍵字
? 如果使用like關鍵字,并且匹配字串時的第一個字符為“%”,那么就無法查詢索引樹,因為不知道要查詢什么,但如果%在后面,就可以 使用,
情況二:查詢陳述句中使用多列索引
? 不滿足最左前綴原則時
情況三:查詢陳述句中使用or關鍵字
? 只有當or兩邊的欄位都創建了索引,才可以使用索引,否則無法使用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/298841.html
標籤:其他
上一篇:Python-函式定義詳解