最近這段時間開始了一個新專案,專案使用rabbitMQ存盤采集資料,通過storm對rabbitMQ中的資料進行實時計算,將結果存入到rabbitMQ的另一個佇列中,再由另外一個storm服務將結果保存到elasticsearch中進行存盤,以此實作大資料的實時計算存盤,
在專案首次部署階段,一切正常,在storm服務部署完成并啟動后,開啟采集服務,成功實作了資料的實時計算與存盤,設定的單批次最大消費數為10000,rabbit的incoming與diliver為400-500/s,運行結果一切正常,沒有出現資料丟失或資料積壓的情況,
然而好景不長,沒過幾天后的一次更新,將storm服務kill掉重啟后,rabbit的資料在重啟程序中有了一定量的堆積,此時重啟storm后出現了OOM例外,

WHAT???為啥之前本地測驗積壓了十幾萬條資料,每秒1000-1200條資料都能成功消費,而生產不過每秒400-500條的資料卻出現了OOM記憶體不足的情況呢?

錯誤復現
首先在本地模擬資料,模擬資料總計20000條,存入rabbitMQ中,

為了測驗資料堆積場景下的資料消費情況,分別開啟Storm服務,對rabbit資料進行計算與存盤,
第一階段:資料的實時計算

第二階段:資料的存盤

可以看到storm的資料是能夠成功計算與存盤的,即使出現積壓也沒有出現資料丟失或OOM例外,
此刻,模擬資料總計條數不變,將每條訊息的大小擴大為以前的10倍左右
原資料大小:

修改后的資料大小:

重新開啟storm服務
第一階段:


第二階段:

可以看到資料出現了很明顯的丟失情況,后臺日志也列印出了OOM例外

問題分析
Storm對每個Topology默認的大小分配是768M,在生產環境,資料通過analyse服務時沒超過這個記憶體閾值,所以當時analyse服務在生產沒有出現OOM例外,而通過計算處理后放入另外一個佇列中的資料,單批次資料的大小超過了記憶體大小閾值,所以在save服務出現了OOM例外,
在測驗條件下,saveTopology的記憶體占用就已經超過了768M,所以在analyse服務下也出現了OOM例外,
到了Save服務下甚至只有600條不到資料成功寫入ES,
問題解決
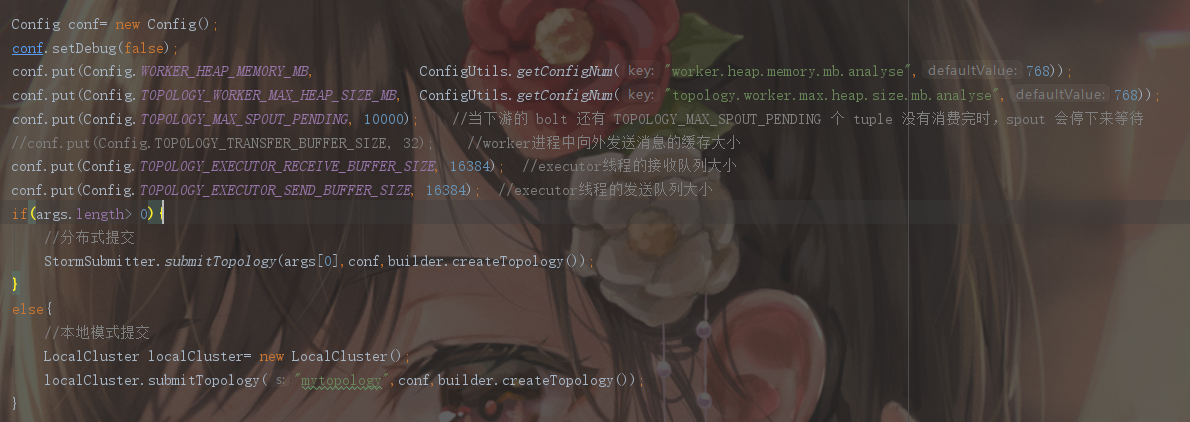
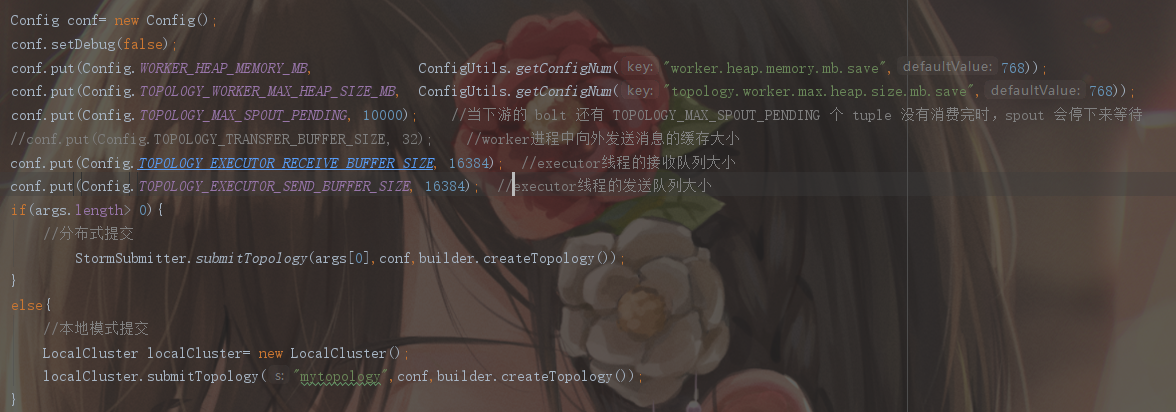
在專案中,添加配置
worker.heap.memory.mb
topology.worker.max.heap.size.mb
配置從Zookeeper中讀取,不同的環境下配置不同的記憶體大小,
Assigned Mem(MB) 為配置的記憶體大小(默認條件下是768M)+LogWriter的64M

此時再重新進行資料模擬及積壓資料的計算與存盤
第一階段

第二階段

可以看到這次不再出現OOM例外,資料成功進行了計算與存盤,
總結
在一般流式計算的場景下,資料進入佇列立刻被消費時,很多問題不會出現,但這并不代表系統就是沒有問題的,在某個時間點,突然有大批量的資料寫入,或當Storm服務中斷掉等一系列場景使得訊息佇列中有大量資料積壓時,記憶體、執行緒、佇列等一系列因素會導致很多在開發時沒有注意的細節問題,如何保證資料能加速消費的同時不出現資料的丟失,也是一個需要開發者思考的問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299076.html
標籤:其他
下一篇:發展黨員管理系統所遇到的問題