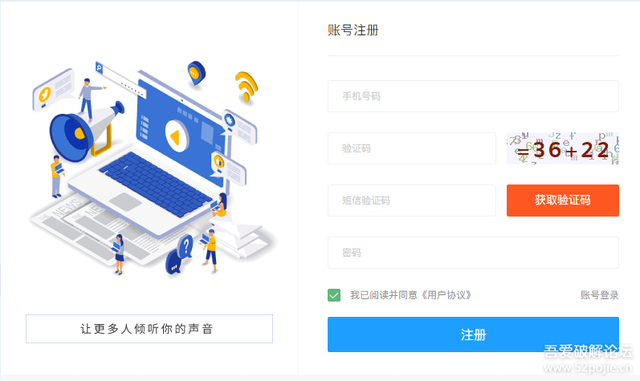
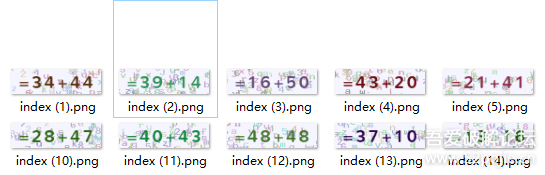
如圖,我們在使用python自動化的時候經常會遇到很多各式各樣的驗證碼,這個是一個數字加法的驗證碼,
干擾項里包含完整的數字、字母資訊,普通的OCR識別可能不是很準確,
但是不管怎么樣,咱們先把必要的環境搭建起來,試一下Tesseract的識別結果吧,
很多人學習python,不知道從何學起, 很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手, 很多已經做案例的人,卻不知道如何去學習更加高深的知識, 那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼! QQ群:701698587 歡迎加入,一起討論 一起學習!
- 1、安裝Tesseract:
首先需要下載Tesseract的安裝包 官方網址:
https://digi.bib.uni-mannheim.de/tesseract/,網上的教程很多推薦安裝名稱里不帶dev的正式版,據說更穩定
- 配置Tesseract:
安裝完畢之后需要配置一下環境變數,分為兩步:
1、在path里加入安裝路徑,及安裝路徑內的tessdata檔案夾路徑,
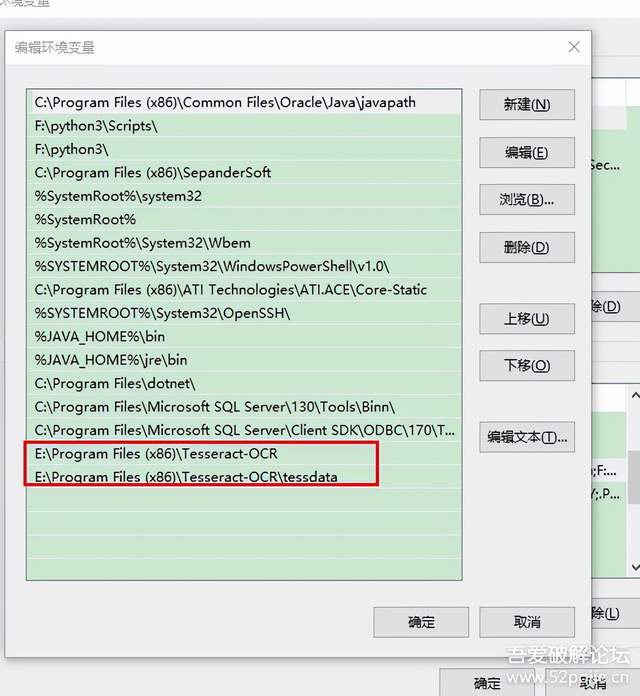
2、新建系統變數{TESSDATA_PREFIX:E:\Program Files (x86)\Tesseract-OCR\tessdata} 這里變數名是固定的TESSDATA_PREFIX,值是剛剛提到的安裝路徑內下一級tessdata檔案夾的完整路徑
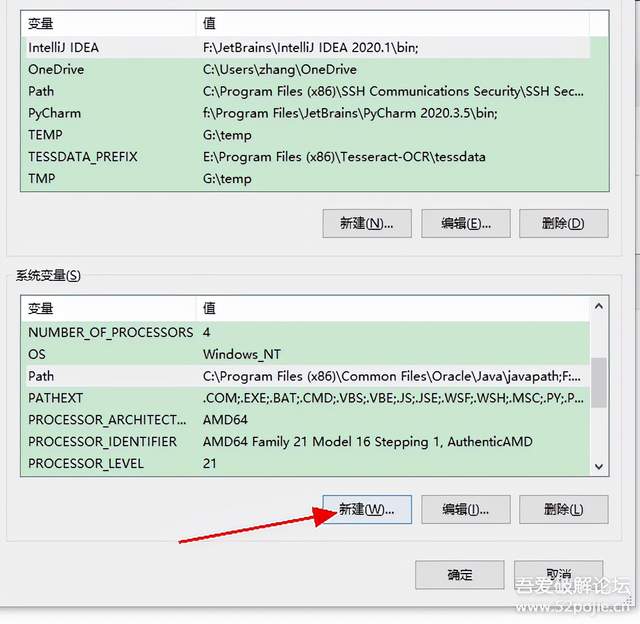
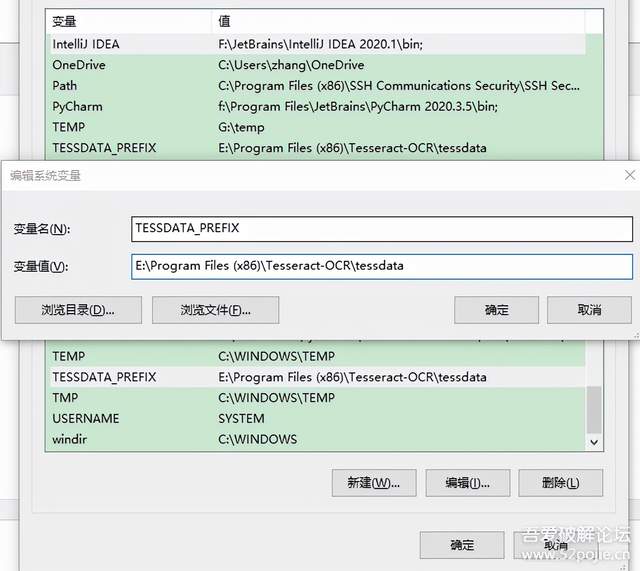
然后命令列里 安裝pytesseract:
pip install pytesseract完成以上步驟之后,請重新啟動電腦,
- 圖片無法處理識別:
直接呼叫ocr識別出結果的話,只需要3行代碼:
import pytesseract
text = pytesseract.image_to_string('圖片路徑或者記憶體的圖片物件')
print(text)但是對于這個驗證碼的效果不是非常好,比如:
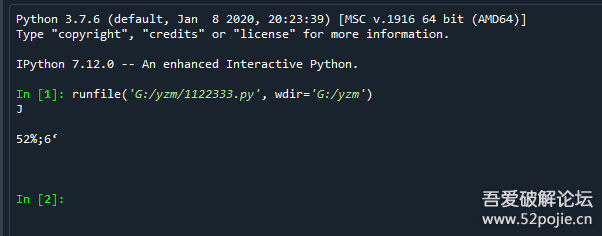

要么是沒有結果,要么就是一堆亂七八糟的東西,
這樣肯定是用不了的
那么只能先處理一下圖片了
- 圖片處理識別:
我下載了20張這個網站的二維碼,發現了以下規律:
1、驗證碼內容一定包含“ = 2位數字+2位數字”的
2、驗證碼內容的顏色是隨機的,
3、驗證碼內容的位置應該是固定的(20張圖片的加號都在同一位置)
4、驗證碼圖片的干擾內容包含字母、數字、符號
5、驗證碼圖片的干擾內容顏色沒有跟主要內容一模一樣,但是每張圖的干擾項一定包含主要內容顏色相近的部分,
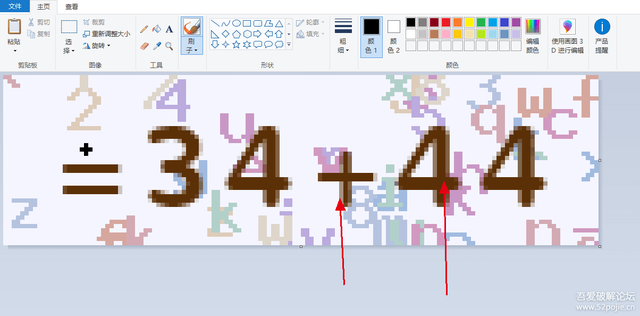
可以看到,根據字體的不同,顯示的時候,主干是棕色的,但是構成這個字的邊緣顏色是稍微淡一些的,不過20張圖里都沒有發現有干擾項的顏色跟主要內容顏色一模一樣,
所以我的想法是因為存在主干的近似色,所以主要的濾波手段可能導致把圖片變得更難處理的可能性,所以不如直接獲取主干顏色,其他像素不是主干顏色的全部以白色替代,洗掉干擾項之后再進行識別,
主干顏色可以使用固定的加號的正中間那一點的坐標獲取,(80,23)(80,24)
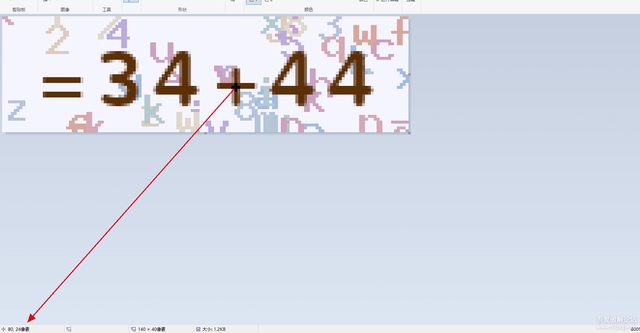
Python代碼如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Apr 14 16:23:47 2021
@author: roshinntou
"""
from PIL import Image
import pytesseract
def images_to_string(index):
#匯入圖片,抓取的時候可以直接獲取io流
img1= Image.open('index ('+str(index)+').png')
#獲取圖片的長寬
w,h = img1.size
print('Original image size: %sx%s' % (w, h))
'''
因為是PNG圖片,像素不是直接以RGB保存的,PNG的每個像素里還有透明度
我們不需要處理透明度,tesseract對于白色和不透明的識別是一樣的,這里就轉成RGB
如果圖片是jpg的,可以直接使用,不需要 convert
'''
img1rbg = img1.convert('RGB')
#讀取全部的像素資料
src_strlist = img1rbg.load()
#獲取主干顏色
data = https://www.cnblogs.com/pythonQqun200160592/p/src_strlist[80,23]
print(data)
#雙層回圈開始替換全部的像素點顏色
for x in range(0,w):
for y in range(0,h):
#判斷當前點顏色是否等于主干顏色
co = src_strlist[x,y]
if co !=data:
src_strlist[x,y] = (245, 245, 255)
#直接呼叫記憶體里的PIL image物件進行圖片識別
text = pytesseract.image_to_string(img1rbg)
text = text.replace(" ","").replace("\r\n","").replace(" ","").replace("\r","").replace("\n","")
#列印結果
print(text)
#保存圖片
img1rbg.save(text+'.png')
if __name__ == '__main__':
for i in range(1,21):
images_to_string(i)
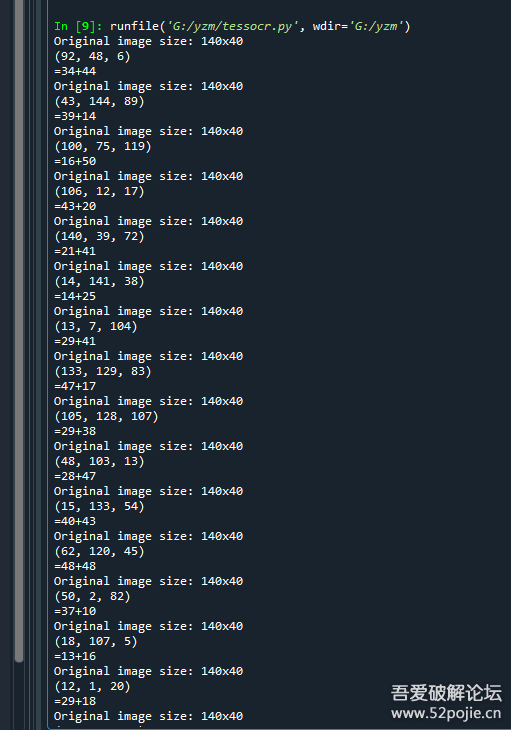
檔案如下:

結語:
準確率我大概看了一下,應該是100%的,以上算是成功破解了對方網站的驗證碼,
驗證碼的識別整體思路應該就是這樣子了,當然我舉得例子是比較簡單的驗證碼,還有各種麻煩的驗證碼,未來可能需要用到截取、卷積、濾波、清洗等等方法,需要根據實際的情況靈活地使用,但是整體的思路就是:
找到驗證碼規律,根據規律清洗干擾噪點,然后識別,希望可以啟發到大家,
最后的最后,現在已經可以獲取驗證碼的字串了,計算結果非常簡單我就不做了,有興趣的可以試試,我會把所有圖片、源代碼打包,大家可以下載試一下,
Tesseract安裝的時候,系統變數哪里2步都不能少,少一個程式執行就會報錯,切記
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299278.html
標籤:Python