前言
在上一篇文章中我們已經詳細介紹基于ID3演算法進行改良的C4.5演算法以及決策樹擬合度的優化問題,那這篇文章呢,則是介紹如何使用sklearn實作決策樹,
當然,如果只是簡單實作決策樹的話,我是不可能單獨拿出來寫成一篇文章的,我會在本篇文章中詳細地介紹到各種具體功能的代碼實作,如剪枝等,同時重要的引數也一個都不會放過(hhh),而且文末也介紹了決策樹模型的優缺點有哪些方面,真的是干貨滿滿,
目錄
- 前言
- 一、使用SK-LEARN實作決策樹
- 1 引數CRITERION
- 2 初步建模
- 3 探索資料
- 4 畫出一棵樹
- 5 探索決策樹屬性
- 5.1 clf.feature_importances_
- 5.2 clf.apply
- 5.3 clf.tree_.node_count
- 5.4 clf.tree_.feature
- 6 防止過擬合
- 6.1 random_state & splitter
- 6.2 剪枝引數
- 6.2.1 max_depth
- 6.2.2 min_samples_leaf
- 6.2.3 min_samples_split
- 6.2.4 max_features
- 6.2.5 min_impurity_decrease
- 6.2.6 確認最優的剪枝引數
- 7 總結
- 二、決策樹的演算法評價
- 1 決策樹優點
- 2 決策樹缺點
- 結束語
一、使用SK-LEARN實作決策樹
1 引數CRITERION
criterion 這個引數是用來決定不純度的計算方法,sklearn 提供了兩種選擇:
- 輸入 “entropy”,使用資訊熵(Entropy)
- 輸入 “gini”,使用基尼系數(Gini Impurity)
比起基尼系數,資訊熵對不純度更加敏感,對不純度的懲罰最強,但是在實際使用中,資訊熵和基尼系數的效果基本相同,
資訊熵的計算比基尼系數緩慢一些,因為基尼系數的計算不涉及對數,
另外,因為資訊熵對不純度更加敏感,所以資訊熵作為指標時,決策樹的生長會更加 ”精細”,因 此對于高緯資料或者噪聲很多的資料,資訊熵很容易過擬合,基尼系數在這種情況下效果往往比較好,
當模型擬合程度不足時,即當模型在訓練集和測驗集上都表現不太好的時候,使用資訊熵,當然,這些不是絕對的,
| 引數 | criterion |
|---|---|
| 如何影響模型? | 確定不純度的計算最佳結點和最佳分支,不純度越低,決策樹對訓練集的擬合越好 |
| 可能的輸入有哪些? | 不填默認為系數,填寫gini使用基尼系數,填寫entropy使用資訊增益 |
| 怎樣選取引數? | 通常就使用基尼系數;資料維度很大、噪音很大時使用基尼系數;維度低、資料比較清晰的時候,兩者沒區別;當決策樹的擬合程度不夠時,使用資訊熵;兩個都試試,不好就換另外一個 |
2 初步建模
# 匯入需要的演算法庫和模塊
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif']=['Simhei']
plt.rcParams['axes.unicode_minus']=False
3 探索資料
wine = load_wine()
wine.data.shape
wine.target

這一部分是顯示資料的標簽,其中這些資料就是來源于sklearn.datasets,
wine_pd=pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1).head() # 合并特征和標簽
wine.feature_names.append("result")
wine_pd.columns=wine.feature_names
wine_pd

在開始建模前,我們先劃分一下資料集:
Xtrain, Xtest, Ytrain, ytest = train_test_split(wine.data,wine.target,test_size=0.3, random_state=420)
Xtrain.shape
Xtest.shape
(124, 13)
(54, 13)
接下來開始建模:
clf = tree.DecisionTreeClassifier(criterion="gini")
clf = clf.fit(Xtrain, Ytrain)
clf.score(Xtest, ytest) #回傳預測的準確度
0.9444444444444444
(換成entropy的結果是0.9629629629629629)
4 畫出一棵樹
同時,我們可以利用 Graphviz 模塊匯出決策樹模型,
第一次使用 Graphviz 之前需要對其進行安裝:
- 先從官網下載msi檔案進行安裝;
- 安裝完記得將安裝好的目錄下的bin目錄添加到環境變數中;
- 在命令列界面使用下述指令進行安裝:
pip install graphviz
接下來開始畫圖:
import matplotlib.pyplot as plt
feature_name = ['酒精','蘋果酸','灰','灰的堿性','鎂','總酚','類黃酮','非黃烷類酚類','花青 素','顏色強度','色調','od280/od315 稀釋葡萄酒','脯氨酸']
import graphviz
dot_data = tree.export_graphviz(clf,
out_file = None,
feature_names= feature_name,
class_names=["琴酒","雪莉","貝爾摩德"],
filled=True,
rounded=True)
graph = graphviz.Source(dot_data)
graph
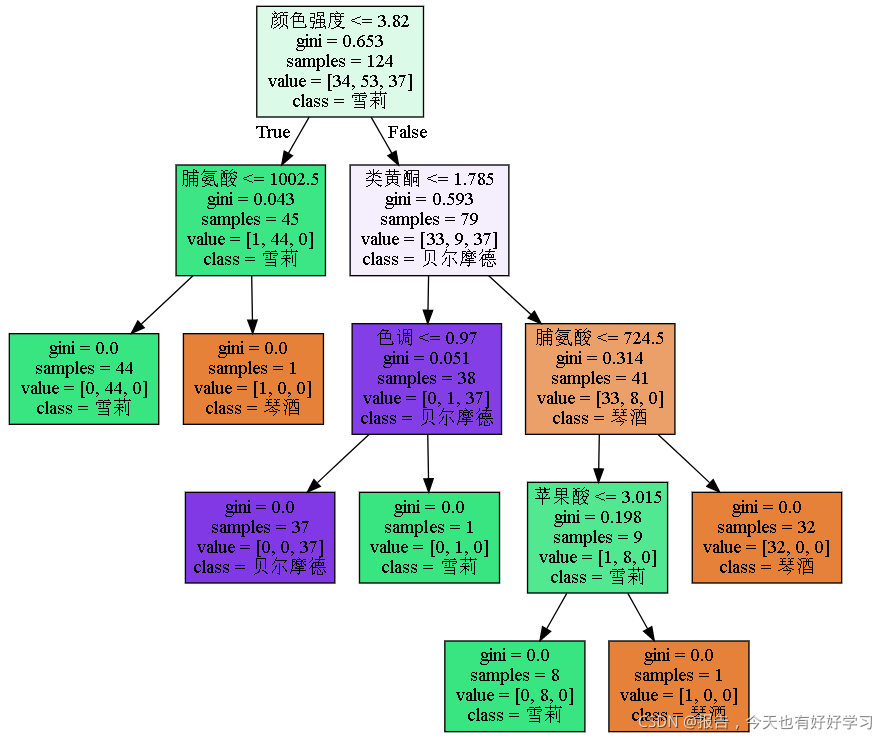
export_graphviz生成一個DOT格式的決策樹:
- feature_names:每個屬性的名字
- class_names:每個因變數類別的名字
- label:是否顯示不純度資訊的標簽,默認為"all"表都顯示,可以是"root"或"none"
- filled:是否給每個結點的主分類繪制不同的顏色,默認為False
- out_file:輸出的dot檔案的名字,默認為None表示不輸出檔案,可以是自定義名字如"tree.dot"
- rounded:默認為Ture,表示對每個結點的邊框加圓角,并使用Helvetica字體
5 探索決策樹屬性
5.1 clf.feature_importances_
顯示每個特征重要性:
#顯示每個特征的重要程度
clf.feature_importances_
想更好地顯示可以用以下方式:
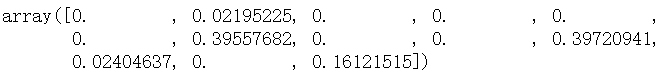
[*zip(feature_names,clf.feature_importances_)] # 這里使用[*]是因為jupyter上才顯示得出來

5.2 clf.apply
回傳每個預測樣本的葉子索引:
clf.apply(xtrain)

5.3 clf.tree_.node_count
樹的節點個數:
clf.tree_.node_count
13
5.4 clf.tree_.feature
每個節點對應的屬性索引值,-2 表示葉節點:
clf.tree_.feature
array([ 9, 12, -2, -2, 6, 10, -2, -2, 12, 0, -2, -2, -2], dtype=int64)
6 防止過擬合
在不加限制的情況下,一棵決策樹會生長到衡量不純度的指標最優,或者沒有更多的特征可用為止,這樣的決策樹往往會過擬合,這就是說,它會在訓練集上表現很好,在測驗集上卻表現糟糕,我們收集的樣本資料不可能和整體的狀況完全一致,因此當一棵決策樹對訓練資料有了過于優秀的解釋性,它找出的規則必然包含了訓練樣本中的噪聲,并使它對未知資料的擬合程度不足,
#我們的樹對訓練集的擬合程度如何?
score_train = clf.score(Xtrain, Ytrain)
score_train
1.0
這個1.0是真的離譜對吧,絕對的過擬合,
所以為了讓決策樹有更好的泛化性,我們要對決策樹進行剪枝,剪枝策略對決策樹的影響巨大,正確的剪枝策略是優化決策樹演算法的核心,
6.1 random_state & splitter
random_state
如果我們改動 random_state,畫出來的每一棵樹都不一樣,它為什么會不穩定呢?如果使用其他資料集,它還會不穩定嗎?
我們之前提到過,無論決策樹模型如何進化,在分支上的本質都還是追求某個不純度相關的指標的優化,而正如我們提到的,不純度是基于節點來計算的,也就是說,決策樹在建樹時,是靠優化節點來追求一棵優化的樹,但最優的節點能夠保證最優的樹嗎?
集成演算法被用來解決這個問題:sklearn 表示,既然一棵樹不能保證最優,那就建更多的不同的樹,然后從中取最好的,怎樣從一組資料集中建不同的樹?在每次分支時,不使用全部特征,而是隨機選取一部分特征,從中選取不純度相關指標最優的作為分支用的節點,這樣,每次生成的樹也就不同了,
random_state 用來設定分支中的隨機模式的引數,默認 None,在高維度時隨機性會表現更明顯,低維度的資料(比如鳶尾花資料集),隨機性幾乎不會顯現,輸入任意整數,會一直長出同一棵樹,讓模型穩定下來,
splitter
splitter 也是用來控制決策樹中的隨機選項的,有兩種輸入值:
- 輸入”best",決策樹在分支時雖然隨機,但是還是會優先選擇更重要的特征進行分支(重要性可以通過屬性 feature_importances_查看);
- 輸入“random",決策樹在分支時會更加隨機,樹會因為含有更多的不必要資訊而更深更大,并因這些不必要資訊而降低對訓練集的擬合,這也是防止過擬合的一種方式,
當你預測到你的模型會過擬合,用這兩個引數來幫你降低樹建立之后過擬合的可能性,當然,樹一旦建成,我們依然是使用剪枝引數來防止過擬合,
clf = tree.DecisionTreeClassifier(criterion="entropy" ,
random_state=30 ,
splitter="random" )
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, ytest) score
plt.rcParams['font.sans-serif']=['Simhei']
plt.rcParams['axes.unicode_minus']=False
大家可以自行比較一下有設定和沒設定引數模型的區別,
6.2 剪枝引數
6.2.1 max_depth
max_depth 限制樹的最大深度,超過設定深度的樹枝全部剪掉,一般用作樹的”精修“ ,
這是用得最廣泛的剪枝引數,在高維度低樣本量時非常有效,決策樹多生長一層,對樣本量的需求會增加一倍,所以限制樹深度能夠有效地限制過擬合,在集成演算法中也非常實用,
實際使用時,建議從=3 開始嘗試,看看擬合的效果再決定是否增加設定深度,
6.2.2 min_samples_leaf
一個節點在分支后的每個子節點都必須包含至少 min_samples_leaf 個訓練樣本,否則分支就不會發生, 或者,分支會朝著滿足每個子節點都包min_samples_leaf 個樣本的方向去發生,
一般搭配 max_depth 使用,在回歸樹中有神奇的效果,可以讓模型變得更加平滑,這個引數的數量設定得太小會引起過擬合,設定得太大就會阻止模型學習資料,
一般來說,建議從=5 開始使用,
如果葉節點中含有的樣本量變化很大,建議輸入浮點數作為樣本量的百分比來使用,同時,這個引數可以保證每個葉子的最小尺寸,避免低方差,過擬合的葉子節點出現,
6.2.3 min_samples_split
一個節點必須要包含至少 min_samples_split 個訓練樣本,這個節點才允許被分支,否則分支就不會發生,
6.2.4 max_features
max_features 限制分支時考慮的特征個數,超過限制個數的特征都會被舍棄, 和 max_depth 異曲同工, max_features 是用來限制高維度資料的過擬合的剪枝引數,但其方法比較暴力,是直接限制可以使用的特征數量而強行使決策樹停下的引數,在不知道決策樹中的各個特征的重要性的情況下,強行設定這個引數可能會導致模型學習不足,
如果希望通過降維的方式防止過擬合,建議使用 PCA,ICA 或者特征選擇模塊中的降維演算法,
6.2.5 min_impurity_decrease
min_impurity_decrease 限制資訊增益的大小,資訊增益小于設定數值的分支不會發生,這是在 0.19 版本中更新的功能,在 0.19 版本之前時使用 min_impurity_split,
6.2.6 確認最優的剪枝引數
那具體怎么來確定每個引數填寫什么值呢?這時候,我們就要使用確定超引數的曲線來進行判斷了,繼續使用我們已經訓練好的決策樹模型 clf,
超引數的學習曲線,是一條以超引數的取值為橫坐標,模型的度量指標為縱坐標的曲線,它是用來衡量不同超引數取值下模型的表現的線,在我們建好的決策樹里,我們的模型度量指標就是 score,
test= []
for i in range(10):
clf = tree.DecisionTreeClassifier(criterion='entropy'
,max_depth=i+1 #最大深度
#,min_samples_leaf=5 #子節點包含樣本最小個數(父節點)
#,min_samples_split=20
,random_state=30
,splitter='random'
) #生成決策樹分類器 entropy
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
test.append(score)
plt.plot(range(1,11),test,color='red')
plt.ylabel('score')
plt.xlabel('max_depth')
plt.xticks(range(1,11))
plt.show()
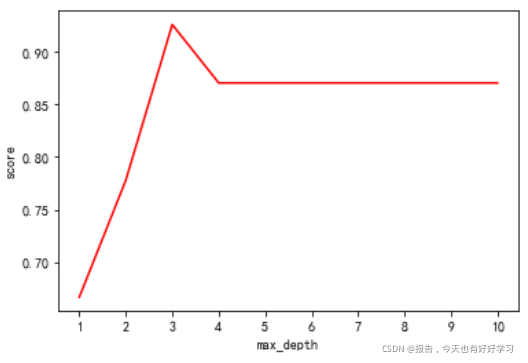
思考:
- 剪枝引數一定能夠提升模型在測驗集上的表現嗎? - 調參沒有絕對的答案,一切都是看資料本身,
- 這么多引數,一個個畫學習曲線? - 這個在以后的案例中會解決,
無論如何,剪枝引數的默認值會讓樹無盡地生長,這些樹在某些資料集上可能非常巨大,對記憶體的消耗也非常巨大,
所以如果你手中的資料集非常巨大,你已經預測到無論如何你都是要剪枝的,那提前設定這些引數來控制樹的復雜性和大小會比較好,
7 總結
屬性是在模型訓練之后,能夠呼叫查看的模型的各種性質 ,對決策樹來說,最重要的是feature_importances_,能夠查看各個特征對模型的重要性,
sklearn 中許多演算法的介面都是相似的,比如說我們之前已經用到的 fit 和 score,幾乎對每個演算法都可以使用,除了這兩個介面之外,決策樹最常用的介面還有 apply 和 predict,
apply 中輸入測驗集回傳每個測驗樣本所在的葉子節點的索引,
predict 輸入測驗集回傳每個測驗樣本的標簽,回傳的內容一目了然并且非常容易,大家感興趣可以自己下去試試看,
在這里不得不提的是,所有介面中要求輸入 Xtrain 和 Xtest 的部分,輸入的特征矩陣必須至少是一個二維矩陣, sklearn 不接受任何一維矩陣作為特征矩陣被輸入,如果你的資料的確只有一個特征,那必須用 reshape(-1,1)來給矩陣增維,
我們已經學完了分類樹 DecisionTreeClassifier 和用決策樹繪圖(export_graphviz)的所有基礎,我們講解了決策樹的基本流程,分類樹的八個引數,一個屬性,四個介面,以及繪圖所用的代碼:
- 八個引數:criterion;
- 兩個隨機性相關的引數(random_state,splitter);
- 五個剪枝引數 (max_depth, min_samples_split , min_samples_leaf , max_feature ,min_impurity_decrease) ;
- 一個屬性:feature_importances_ ;
- 四個介面:fit,score,apply,predict
二、決策樹的演算法評價
1 決策樹優點
- 易于理解和解釋,因為樹木可以畫出來被看見,
- 需要很少的資料準備,其他很多演算法通常都需要資料規范化,需要創建虛擬變數并洗掉空值等,但請注意,sklearn 中的決策樹模塊不支持對缺失值的處理,
- 使用樹的成本(比如說,在預測資料的時候)是用于訓練樹的資料點的數量的對數,相比于其他演算法,這是一個很低的成本,
- 能夠同時處理數字和分類資料,既可以做回歸又可以做分類,其他技術通常專門用于分析僅具有一種變數型別的資料集,
- 即使其假設在某種程度上違反了生成資料的真實模型,也能夠表現良好,
2 決策樹缺點
- 使用決策樹可能創建過于復雜的樹,這些樹不能很好地推廣資料,這稱為過度擬合,修剪,設定 葉節點所需的最小樣本數或設定樹的最大深度等機制是避免此問題所必需的,而這些引數的整合和調整對 初學者來說會比較晦澀,
- 決策樹可能不穩定,資料中微小的變化可能導致生成完全不同的樹,這個問題需要通過集成演算法來解決,
- 決策樹的學習是基于貪婪演算法,它靠優化區域最優(每個節點的最優)來試圖達到整體的最優,但這種做法不能保證回傳全域最優決策樹,這個問題也可以由集成演算法來解決,在隨機森林中,特征和樣本會在分枝程序中被隨機采樣,
- 如果標簽中的某些類占主導地位,決策樹學習者會創建偏向主導類的樹,因此,建議在擬合決策樹之前平衡資料集,
結束語
學到這里,決策樹相關的知識基本也就完了,
后續我會再出一期模型評估的內容,然后可能會再介紹一下線性回歸和邏輯回歸,或者是關于決策樹的專案實戰,
推薦關注的專欄
👨?👩?👦?👦 機器學習:分享機器學習實戰專案和常用模型講解
👨?👩?👦?👦 資料分析:分享資料分析實戰專案和常用技能整理
機器學習系列往期回顧
🧡 開始學習機器學習時你必須要了解的模型有哪些?機器學習系列之決策樹進階篇
💚 開始學習機器學習時你必須要了解的模型有哪些?機器學習系列之決策樹基礎篇
?? 以??簡單易懂??的語言帶你搞懂有監督學習演算法【附Python代碼詳解】機器學習系列之KNN篇
💜 開始學習機器學習之前你必須要了解的知識有哪些?機器學習系列入門篇
往期內容回顧
🖤 我和關注我的前1000個粉絲“合影”啦!收集前1000個粉絲進行了一系列資料分析,識訓滿滿
?? 分享一個超nice的資料分析實戰案例 ? “手把手”教學,收藏等于學會
💙 資料分析必須掌握的RFM模型是什么?一文搞懂如何利用RFM對用戶進行分類【附實戰講解】
💚 MySQL必須掌握的技能有哪些?超細長文帶你掌握MySQL【建議收藏】
💜 Hive必須了解的技能有哪些?萬字博客帶你掌握Hive??【建議收藏】
🧡 一文帶你了解Hive【詳細介紹】Hive與傳統資料庫有什么區別?
CSDN@報告,今天也有好好學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299346.html
標籤:python
上一篇:Python 演算法的時間復雜度和空間復雜度 (實體決議)
下一篇:Django-框架介紹&環境安裝