
目錄
第一個爬蟲程式:
Web請求的全程序剖析:
HTTP協議:
請求:
請求頭中常見的重要內容:
請求方式:
回應:
Requests:
資料決議:
資料提取的三種決議方式:
正則運算式:
爬取案例:
獲取資料結果:
安裝bs4:
環境搭建:
安裝Selenium
安裝瀏覽器驅動程式:
EdgeDriver:
ChromeDriver:
Selenium元素定位:
Chrome Handless:
系統要求:
第一個爬蟲程式:
爬蟲:通過撰寫程式來獲取互聯網上的資源!
需求:用程式模擬瀏覽器,輸入一個網址,從該網站中獲取到資源或者內容!
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
with open("mybaidu.html", mode="w",encoding="utf-8") as f:
f.write(resp.read().decode("utf-8")) # 讀取到網站頁面源代碼
print("over!")Web請求的全程序剖析:
- 服務器渲染:在服務器那邊直接把資料和html整合在一起,統一回傳給瀏覽器,在頁面原代碼中能看到資料,
- 客戶端渲染:第一次請求只要一個html骨架,第二次請求拿到資料,進行資料展示,在頁面源代碼中,看不到資料
HTTP協議:
協議:就是把兩個計算機之間為了能夠流暢的進行溝通而設定的一個君子協定,常見的協議有TCP/IP,SOAP協議,HTTP協議,SMTP協議等等......
HTTP協議,Hyper Text Transfer Protocol(超文本傳輸協議)的縮寫,是用從萬維網(WWW:World Wide Web)服務器傳輸超文本到本地瀏覽器的傳送協議,就是瀏覽器和服務器之間的資料互動遵守的就是HTTP協議,
HTTP協議把一條訊息分為三大塊內容,無論是請求還是回應都應該是三大塊內容:
請求:
請求行 -> 請求方式(get/post) 請求url地址 協議
請求頭 -> 存放些服務器要使用的附加資訊
請求體 -> 一般放一些請求引數請求頭中常見的重要內容:
- User-Agent:請求載體的身份標識(用什么來發送的請求)
- Referer:防盜鏈(此次請求是從哪個頁面進行獲取,反爬使用)
- cookie:本地字串資料資訊(用戶登錄資訊,反爬token)
請求方式:
- GET:顯示請求
- POST:隱式請求
回應:
狀態行 -> 協議 狀態碼
回應頭 -> 存放一些客戶端需要使用的附加資訊
回應體 -> 服務器回傳的真正客戶端要使用的內容(HTML,JSON)等資料
Requests:
安裝Requests:pip install requests
在PyCharm中點擊Terminal打開命令視窗:
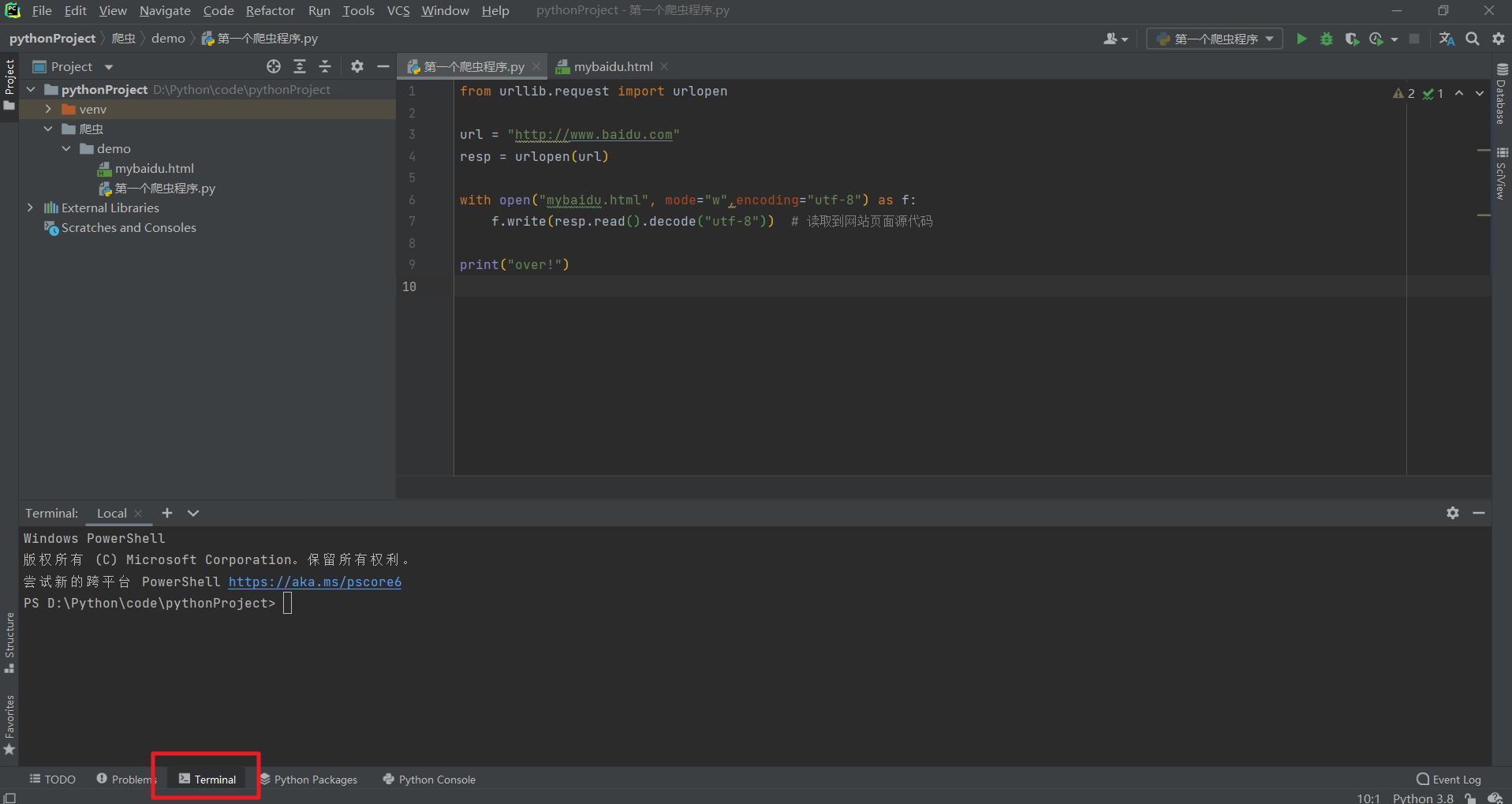
# 使用requests包,使用前需要通過命令列進行安裝!!!
import requests
url = 'https://cn.bing.com/search?q=java' # url:瀏覽器請求地址,爬蟲爬取資料地址
dic = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78'
}
resp = requests.get(url, headers=dic) # 添加請求載體,處理一個簡單的反爬機制
print(resp.text) # 獲取到網頁原始碼資料決議:
在大多數的情況下,我們并不需要整個網頁的內容,只是需要其中有效資料,這就涉及到了資料的提取,
資料提取的三種決議方式:
- re決議
- bs4決議
- xpath決議
這三種方式可以混合使用,完全以結果為導向,只要能獲取需要的資料,用什么方法并不重要,當你掌握了這些之后,再考慮性能的問題!!!
正則運算式:
文章連接:一篇搞定正則運算式
爬取案例:
# 通過requests,拿到頁面源代碼
# 通過re來提取想要的有效資訊
import requests
import re
# 資料存盤格式模塊
import csv
# 1.獲取爬取站點的url地址,配置請求頭:
url = 'https://movie.douban.com/top250'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome'
'/92.0.4515.159 Safari/537.36 Edg/92.0.902.78'
}
# 2.通過requests模塊中的get方法,對該地址的服務器進行請求,回傳回應rsp:
rsp = requests.get(url=url, headers=header)
# 3.請求結果:
page_content = rsp.text
# 決議資料(使用正則運算式):
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">(?P<director>.*?) '
r'(?P<performer>.*?)<br>.*?(?P<year>.*?) / .*?<span property="v:best" content="10.0">'
r'</span>.*?<span>(?P<comment>.*?)</span>.*?<span class="inq">'
r'(?P<direction>.*?)</span>',
re.S)
result = obj.finditer(page_content)
# 準備檔案:
file = open('data.csv', mode='w', encoding='utf-8') # 設定檔案字符編碼為utf-8,默認是GBK,會導致檔案編碼和IDE(utf-8)寫入編碼不一致
# 準備CSV寫入器(資料內容會寫入到file檔案中):
CSVWrite = csv.writer(file)
# 通過迭代器,寫出資料到CSV檔案:
for r in result:
# print(r.group('name').split())
# print(r.group('director').split())
# print(r.group('performer').split())
# print(r.group('year').split())
# print(r.group('comment').split())
# print(r.group('direction').split())
# print('\n')
dic = r.groupdict()
dic['name'] = dic['name'].strip()
dic['director'] = dic['director'].strip()
dic['performer'] = dic['performer'].strip()
dic['year'] = dic['year'].strip()
dic['comment'] = dic['comment'].strip()
dic['direction'] = dic['direction'].strip()
CSVWrite.writerow(dic.values())
# 關閉檔案:
file.close()
# 列印結果:
print('over!')
# 4.關閉rsp:
rsp.close()獲取資料結果:
肖申克的救贖,導演: 弗蘭克·德拉邦特 Frank Darabont,主演: 蒂姆·羅賓斯 Tim Robbins /...,1994,2435461人評價,希望讓人自由,
霸王別姬,導演: 陳凱歌 Kaige Chen,主演: 張國榮 Leslie Cheung / 張豐毅 Fengyi Zha...,1993,1811073人評價,風華絕代,
阿甘正傳,導演: 羅伯特·澤米吉斯 Robert Zemeckis,主演: 湯姆·漢克斯 Tom Hanks / ...,1994,1831357人評價,一部美國近現代史,
這個殺手不太冷,導演: 呂克·貝松 Luc Besson,主演: 讓·雷諾 Jean Reno / 娜塔莉·波特曼 ...,1994,1997475人評價,怪蜀黍和小蘿莉不得不說的故事,
泰坦尼克號,導演: 詹姆斯·卡梅隆 James Cameron,主演: 萊昂納多·迪卡普里奧 Leonardo...,1997,1793280人評價,失去的才是永恒的,
美麗人生,導演: 羅伯托·貝尼尼 Roberto Benigni,主演: 羅伯托·貝尼尼 Roberto Beni...,1997,1122598人評價,最美的謊言,
千與千尋,導演: 宮崎駿 Hayao Miyazaki,主演: 柊瑠美 Rumi H?ragi / 入野自由 Miy...,2001,1911622人評價,最好的宮崎駿,最好的久石讓,
辛德勒的名單,導演: 史蒂文·斯皮爾伯格 Steven Spielberg,主演: 連姆·尼森 Liam Neeson...,1993,934608人評價,拯救一個人,就是拯救整個世界,
盜夢空間,導演: 克里斯托弗·諾蘭 Christopher Nolan,主演: 萊昂納多·迪卡普里奧 Le...,2010,1761254人評價,諾蘭給了我們一場無法盜取的夢,
忠犬八公的故事,導演: 萊塞·霍爾斯道姆 Lasse Hallstr?m,主演: 理查·基爾 Richard Ger...,2009,1211124人評價,永遠都不能忘記你所愛的人,
星際穿越,導演: 克里斯托弗·諾蘭 Christopher Nolan,主演: 馬修·麥康納 Matthew Mc...,2014,1435042人評價,愛是一種力量,讓我們超越時空感知它的存在,
楚門的世界,導演: 彼得·威爾 Peter Weir,主演: 金·凱瑞 Jim Carrey / 勞拉·琳妮 Lau...,1998,1356451人評價,如果再也不能見到你,祝你早安,午安,晚安,
海上鋼琴師,導演: 朱塞佩·托納多雷 Giuseppe Tornatore,主演: 蒂姆·羅斯 Tim Roth / ...,1998,1431659人評價,每個人都要走一條自己堅定了的路,就算是粉身碎骨,
三傻大鬧寶萊塢,導演: 拉庫馬·希拉尼 Rajkumar Hirani,主演: 阿米爾·汗 Aamir Khan / 卡...,2009,1605312人評價,英俊版憨豆,高情商版謝耳朵,
機器人總動員,導演: 安德魯·斯坦頓 Andrew Stanton,主演: 本·貝爾特 Ben Burtt / 艾麗...,2008,1129897人評價,小瓦力,大人生,
放牛班的春天,導演: 克里斯托夫·巴拉蒂 Christophe Barratier,主演: 熱拉爾·朱尼奧 Gé...,2004,1114896人評價,天籟一般的童聲,是最接近上帝的存在,
無間道,導演: 劉偉強 / 麥兆輝,主演: 劉德華 / 梁朝偉 / 黃秋生,2002,1098361人評價,香港電影史上永不過時的杰作,
瘋狂動物城,導演: 拜倫·霍華德 Byron Howard / 瑞奇·摩爾 Rich Moore,主演: 金妮弗·...,2016,1588576人評價,迪士尼給我們營造的烏托邦就是這樣,永遠善良勇敢,永遠出乎意料,
大話西游之大圣娶親,導演: 劉鎮偉 Jeffrey Lau,主演: 周星馳 Stephen Chow / 吳孟達 Man Tat Ng...,1995,1304007人評價,一生所愛,
熔爐,導演: 黃東赫 Dong-hyuk Hwang,主演: 孔侑 Yoo Gong / 鄭有美 Yu-mi Jung /...,2011,790634人評價,我們一路奮戰不是為了改變世界,而是為了不讓世界改變我們,
教父,導演: 弗朗西斯·福特·科波拉 Francis Ford Coppola,主演: 馬龍·白蘭度 M...,1972,794767人評價,千萬不要記恨你的對手,這樣會讓你失去理智,
當幸福來敲門,導演: 加布里爾·穆奇諾 Gabriele Muccino,主演: 威爾·史密斯 Will Smith ...,2006,1292846人評價,平民勵志片,
龍貓,導演: 宮崎駿 Hayao Miyazaki,主演: 日高法子 Noriko Hidaka / 坂本千夏 Ch...,1988,1080655人評價,人人心中都有個龍貓,童年就永遠不會消失,
怦然心動,導演: 羅伯·萊納 Rob Reiner,主演: 瑪德琳·卡羅爾 Madeline Carroll / 卡...,2010,1540956人評價,真正的幸福是來自內心深處,
控方證人,導演: 比利·懷爾德 Billy Wilder,主演: 泰隆·鮑華 Tyrone Power / 瑪琳·...,1957,390934人評價,比利·懷德滿分作品,安裝bs4:
pip install bs4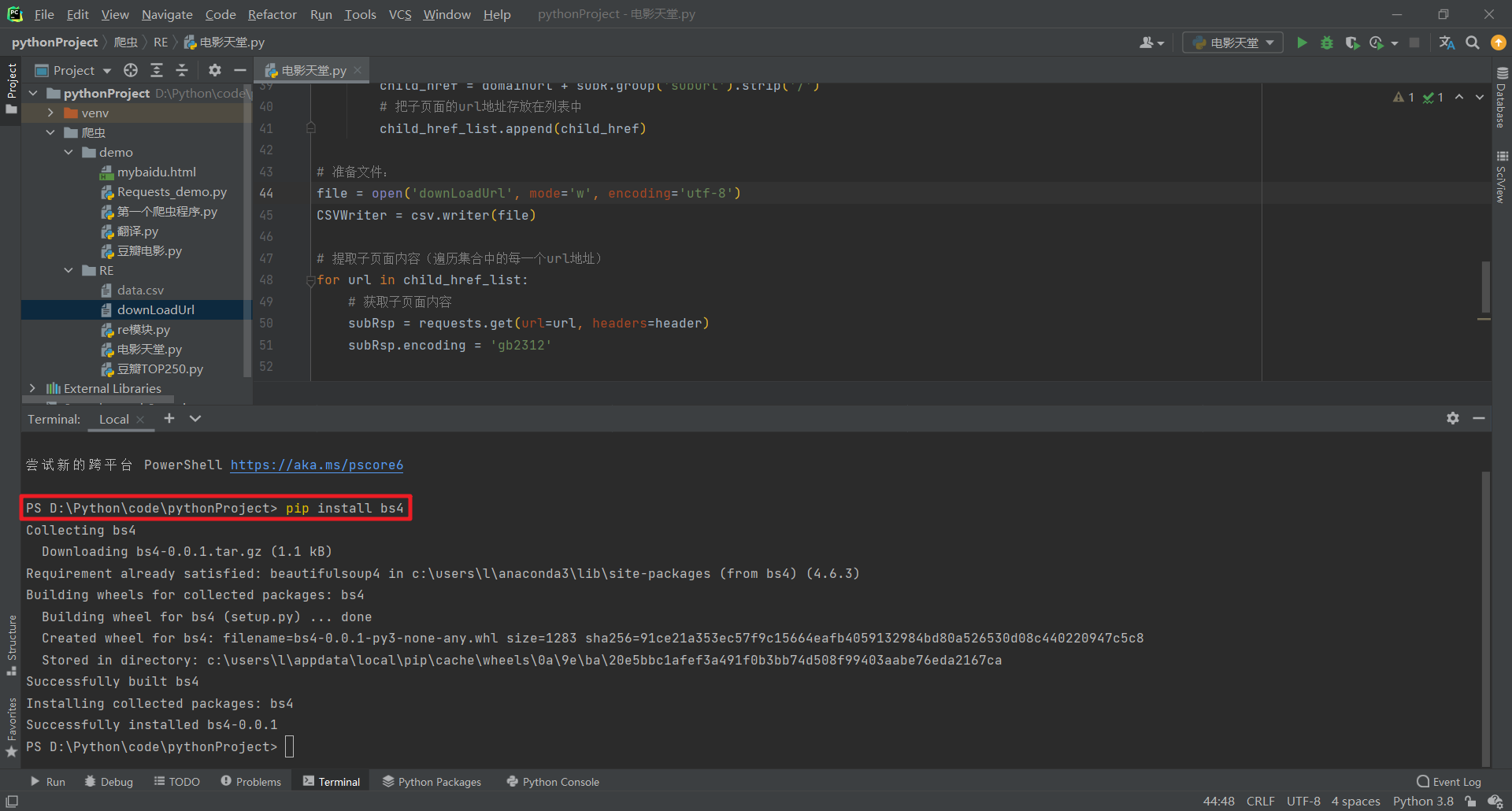
環境搭建:
安裝Selenium
打開IDEA的Terminal視窗,輸入以下命令:
pip install selenium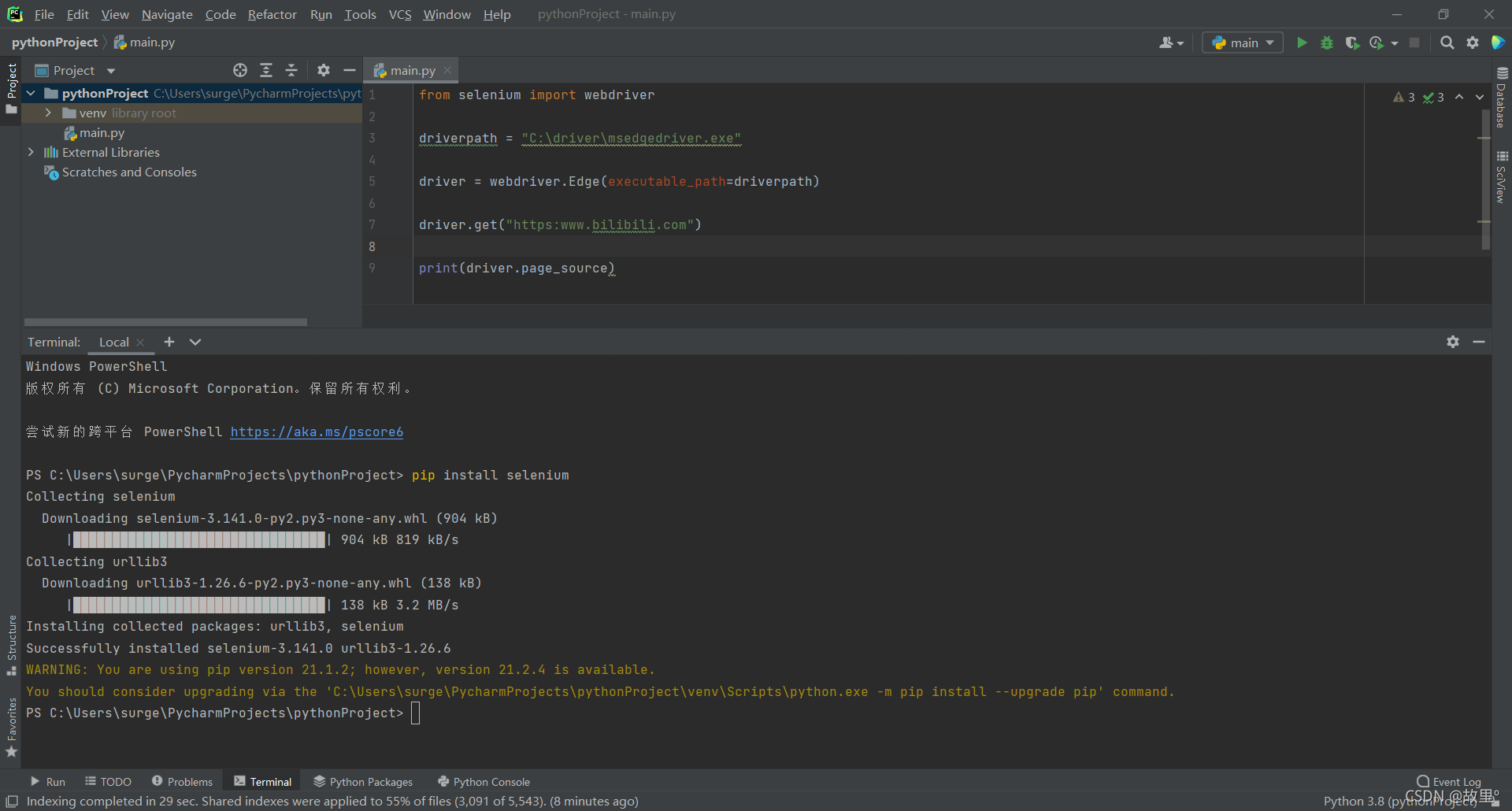
安裝瀏覽器驅動程式:
EdgeDriver:
我這里使用的是Edge瀏覽器,需要在官網上去下載,Edge瀏覽器的驅動檔案
官網傳送口: Microsoft Edge Driver - Microsoft Edge Developer
from selenium import webdriver
driverpath = "C:\driver\msedgedriver.exe" # 我存放驅動檔案地址
driver = webdriver.Edge(executable_path=driverpath) # 加載驅動
driver.get("https:www.bilibili.com") # 瀏覽器訪問的路徑
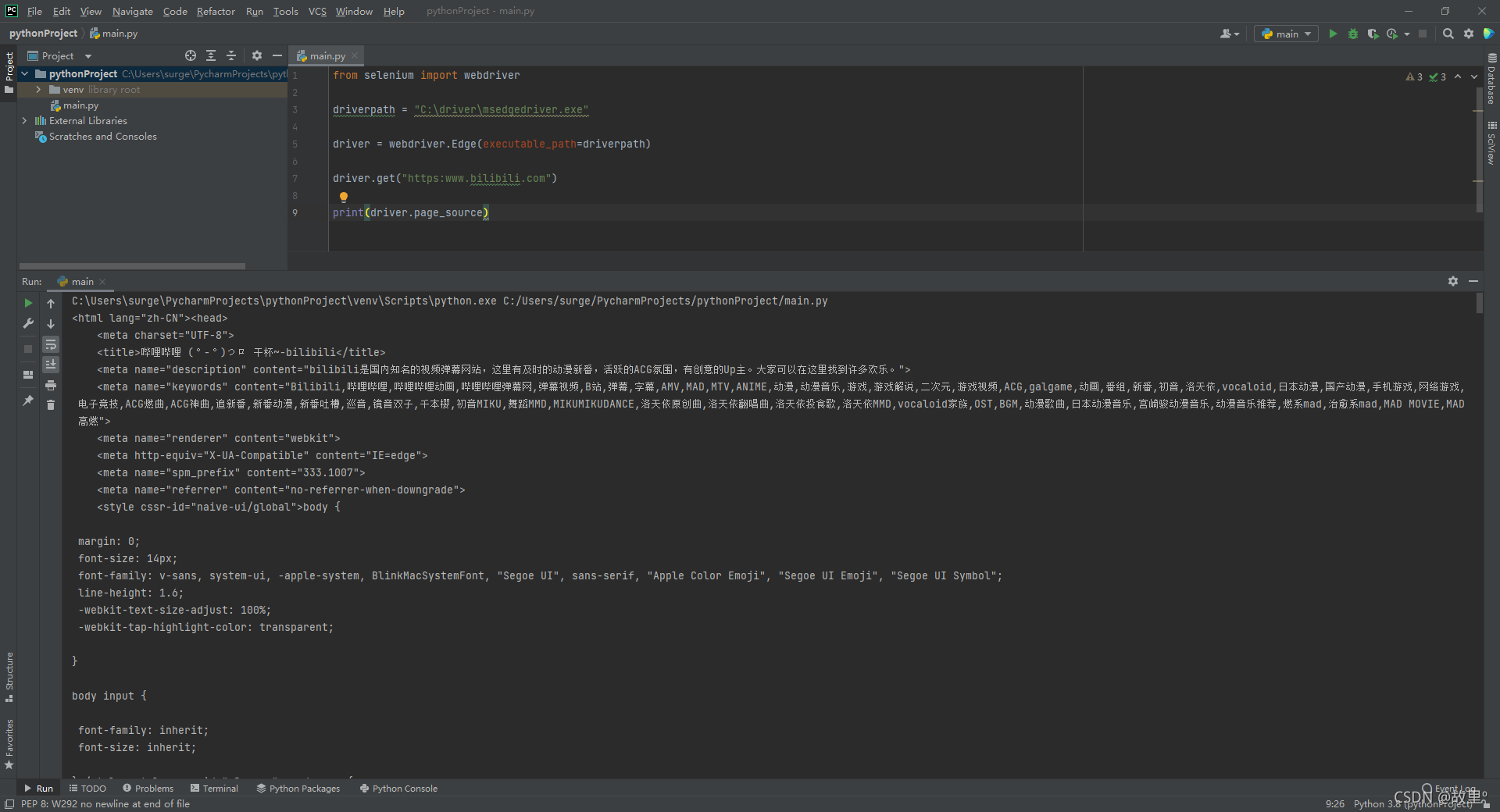
print(driver.page_source)程式執行成功后,電腦上的Edge瀏覽器會被測驗程式(EdgeDriver)進行托管:
控制臺列印出網頁原始碼:
ChromeDriver:
谷歌瀏覽器驅動傳送口:
??????ChromeDriver Mirror (taobao.org)
查看你安裝的Chrome瀏覽器版本:
- 進入Chrome瀏覽器設定
- 找到關于Chrome
- 查看當前瀏覽器版本
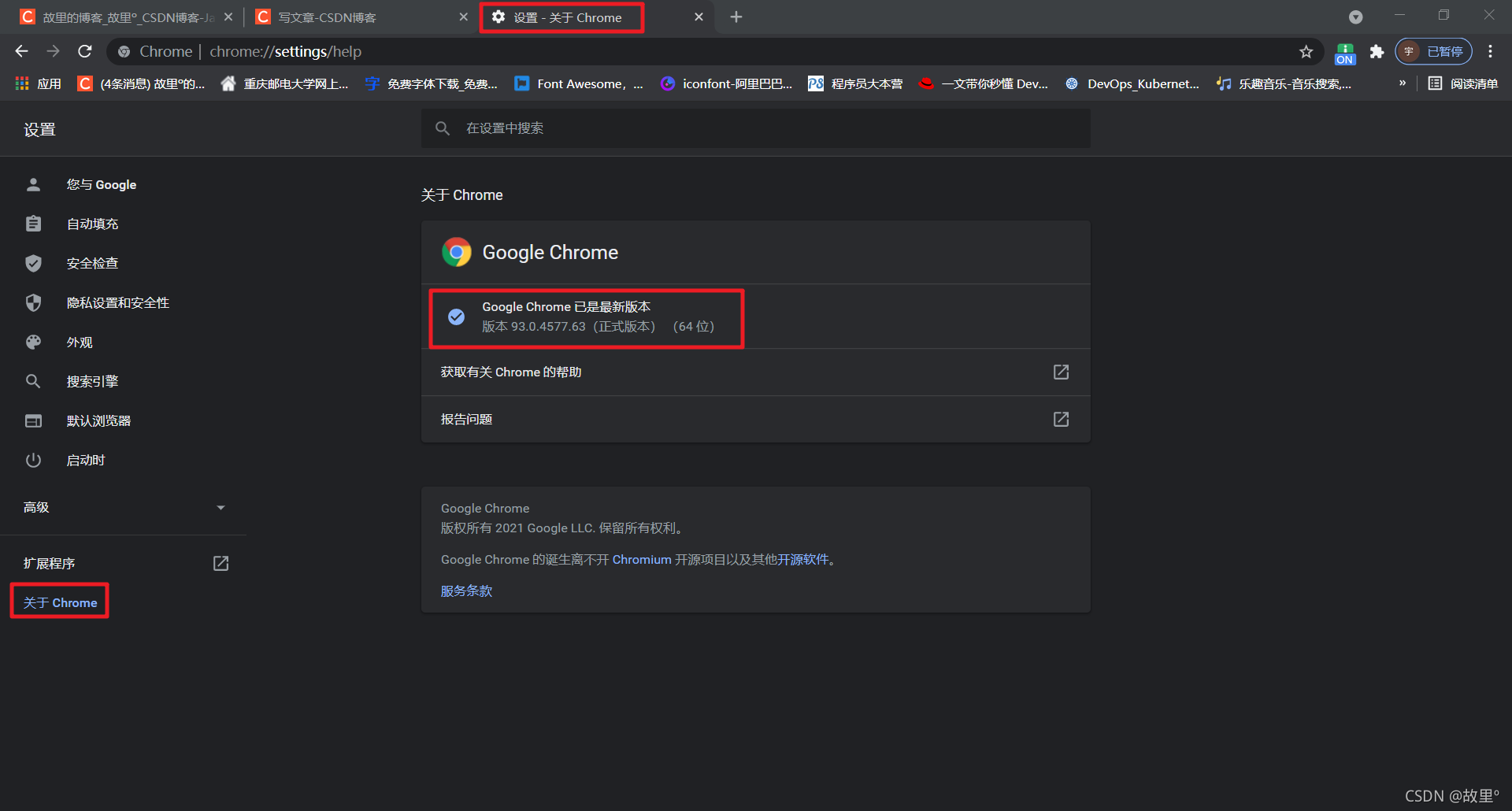
這里的驅動程式一般都是向下兼容的,如果找不到對應的版本號的瀏覽器驅動,可以選擇臨近的新版本,不影響使用!
# 匯入包依賴
from selenium import webdriver
# 指定Driver路徑
driverPath = '../driver/chromedriver.exe'
# 創建瀏覽器物體
browser = webdriver.Chrome(driverPath)
# 指定訪問網站
url = 'https://www.bilibili.com'
browser.get(url=url)
Selenium元素定位:
元素定位:自動化要做的就是模擬滑鼠和鍵盤來操作這些元素,點擊,輸入等等,進行這些操作之前,首先需要找到他們,Webdriver提供了多種定位元素的方法:
| 方法 | EG |
|---|---|
| find_element_by_id | button = browser.find_element_by_id(' su ') |
| find_element_by_name | name = browser.find_element_by_name(' wd ') |
| find_element_by_xpath | xpathDemo = browser.find_element_by_xpath(' //imput[@id="su"] ') |
| find_element_by_tag_name | names = browser.find_elemnet_by_tag_name(' input ') |
| find_element_by_css_selector | my_input = browser.find_element_by_css_selecter(' #kw ')[0] |
| find_element_by_link_text | browser.find_element_by_link_text(' 新聞 ') |
定位到回應元素之后,我們可以通過以下幾種方式獲取元素中的資訊:
| 方法 | 代碼實作 |
| 獲取元素屬性 | .get_attribute(' class ') |
| 獲取元素文本 | .text |
| 獲取標簽名 | .tag_name |
Selenium的互動:
| 事件 | 代碼實作 |
| 點擊 | click() |
| 輸入 | send_keys() |
| 后退操作 | browser.back() |
| 前進操作 | browser.forword() |
| 模擬JS滾動 | JS = 'document.documentElement.scrollTop = 100000' browser.execute_script(JS) # 執行JS代碼 |
| 獲取網頁原始碼 | page_source |
| 退出 | browser.quit() |
Chrome Handless:
簡而言之,Headless Browser是沒有圖形用戶界面(GUI)的web瀏覽器,通常是通過編程或命令列界面來控制的,Headless Browser的許多用處之一是自動化可用性測驗或測驗瀏覽器互動,
Chrome Handless 模式,Google針對Chrome瀏覽器 59版新增加的一種模式,可以讓你不打開UI界面的情況下使用Chrome瀏覽器,所以運行效果與Chrome保持一致,
系統要求:
- Chrome瀏覽器版本 >= 60
- Python 3.6 以上
- Selenium 3.4 以上
- ChromeDriver 2.31 以上
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path:存放瀏覽器執行檔案路徑
path = 'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(options=chrome_options)
# 目標地址
url = 'https://www.bilibili.com'
browser.get(url=url)
browser.save_screenshot('bilibili.png')
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299683.html
標籤:python