倘若有一天你去面試的時候,面試官問起了你HashMap的底層實作原理,你怎么辦?是一臉懵逼支支吾吾嗎?再讓你自己通過代碼實作你自己的HashMap的時候,難道完全破防?讀完這篇文章,讓我們對這個情況say no!

首先我們來通過下面的圖看看JDK1.7時代的HashMap是如何通過陣列+鏈表的形式進行值儲存的,
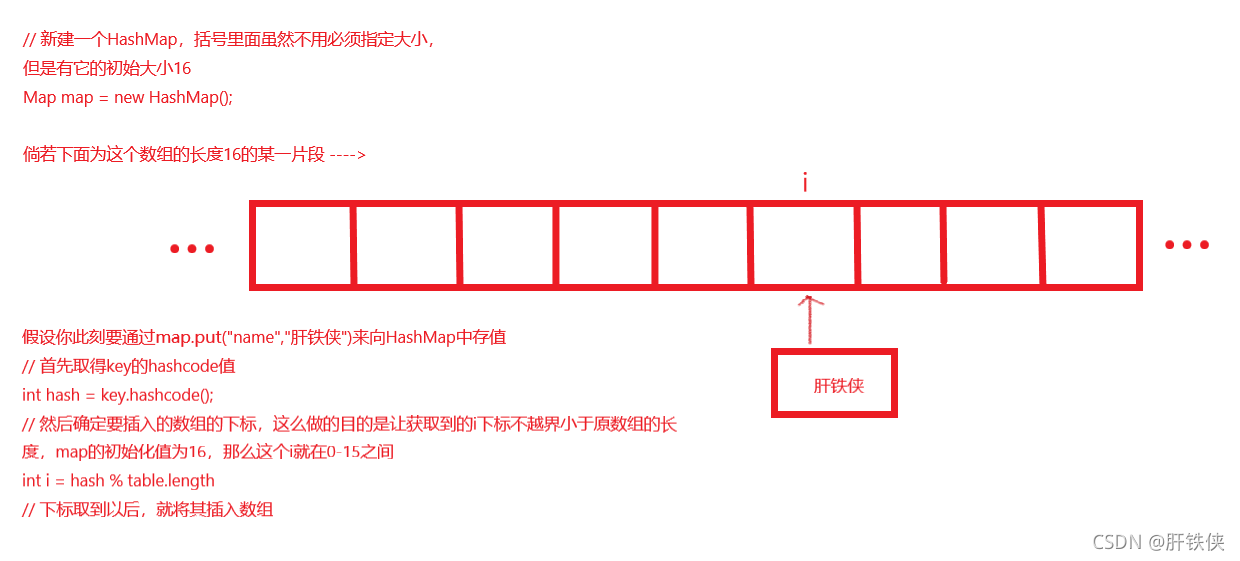
由圖中的描述可以清楚地看出來,當陣列第一次被定義并且第一次被賦值的時候,這個時候的操作很簡單,就是將這個值賦值到我們的table陣列上面去,這個操作完成以后,然后我們進行二次put:
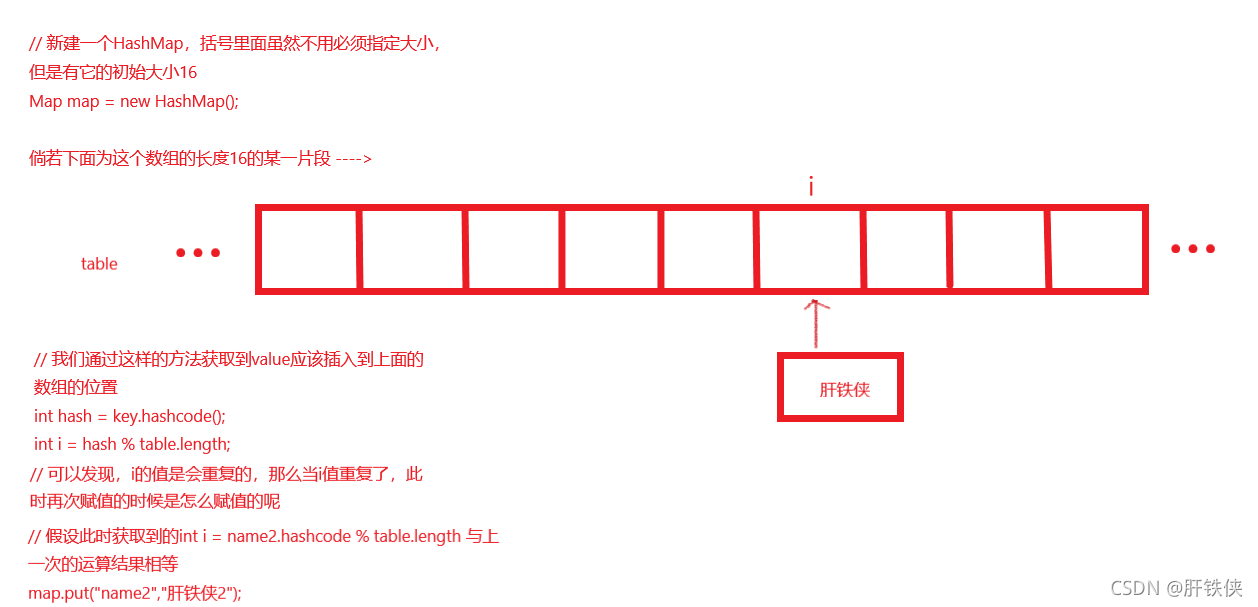
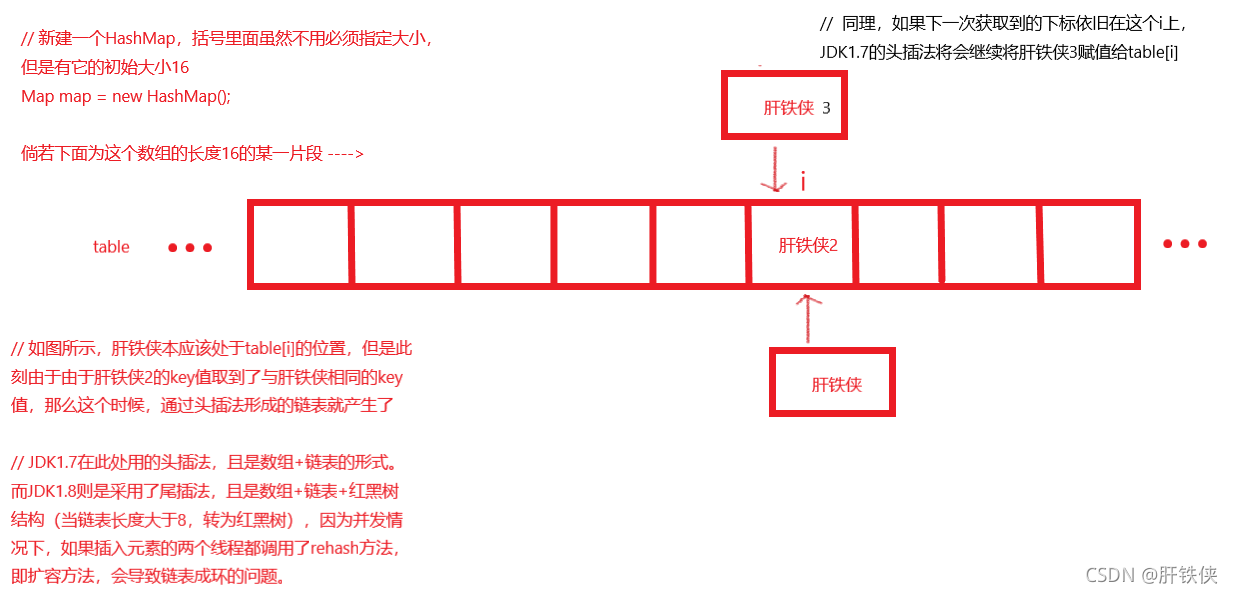
如圖左下角描述所示的情況,當陣列table下標出現了相等的情況的時候,此時此刻還是將肝鐵俠2的值賦值給tablle[i]的,這里講述的是JDK1.7版本下HashMap中插入的頭插法,而JDK1.8版本中是用的尾插法,插入以后,我們要讓陣列指向鏈表的頭部,那么鏈表的頭部也就是頭節點是不是就是table[i]的位置呀,
如上,最終插入完成以后的模型就是這樣的:
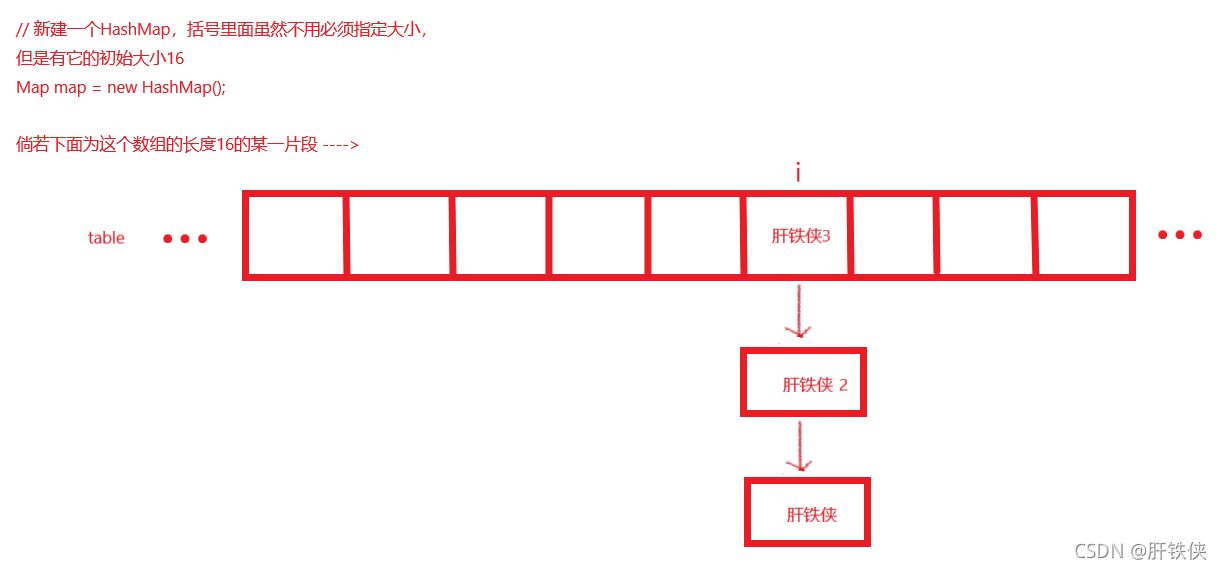
那我們此時此刻是不是就可以大膽地猜測,在HashMap中,使用map.get(“name”)獲取到它的value的時候,是不是就是通過int hash = “name”.hashcode,然后獲取到對應table下的陣列下標int i = hash % table.length獲取到table[i]的具體位置的鏈表,然后再通過hash去對應table[i]上的鏈表中找到對應的值呢?
有了這個思維,我們再去看HashMap的原始碼就會輕松許多許多,下一期為大家帶來HashMap的手動實作,
再順帶兩個基本的關于HashMap的問題:
HashMap底層是怎么實作的呢?
在JDK1.7中是通過陣列+鏈表實作的,JDK1.8中是通過陣列+鏈表+樹(紅黑樹)組成的,
為什么要用鏈表呢?
①HashMap陣列元素為鏈表的時候,插入直接使用頭插,插入復雜度O(1),即操作的數量為常數,與輸入的資料的規模無關,效率是非常快的;當鏈表較短時候,查找資料時對性能并沒有什么影響,但是如果鏈表一長,查找起來就很影響性能了,
②在Java8中,如果鏈表長度到達了8個,就會轉化為紅黑樹,提高了查找的性能,但每次插入新的資料,都得維護紅黑樹的結構,復雜度為O(log n),其實算是對查找和插入元素時性能的一個權衡,畢竟存入的效果就是用來查詢的,
這個問題的答案不唯一,可以自行了解一下,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299976.html
標籤:java