?👻相信不少小伙伴們通過我的兩篇萬字博文的輪番轟炸已經實作了從入坑到會完全學會requests庫,并且可以獨立開發出屬于自己的小爬蟲專案!!!——爬蟲之路,永無止境~👻
?
?💦第一篇爬蟲入坑文;一篇萬字博文帶你入坑爬蟲這條不歸路 【萬字圖文】💦
?💦第二篇爬蟲庫requests庫詳解,兩萬字博文教你python爬蟲requests庫【詳解篇】💦
?
?😬但是爬蟲爬蟲,重在爬取到我們想要的資料,那么我們該如何提取頁面中我們所需要的資訊呢?為了讓小伙伴們更加深入的學習本文所講的頁面決議庫,我先一步肝了一篇HTML萬字詳解,希望小伙伴們認認真真看完,看明白,看懂,多敲敲,日后你們自會感受到本博主的用意——HTML兩萬字王者筆記大總結【??熬夜整理&建議收藏??】(上篇)和HTML兩萬字王者筆記大總結【??熬夜整理&建議收藏??】(下篇)😬
?
???????👇
👉🚔直接跳到末尾🚔👈 ——>領取專屬粉絲福利💖
?????????
?
?😜爬取到我們想要的資料——專業點說就是進行頁面決議!對于網頁的節點來說,它可以定義id,class等多種屬性,而且節點之間還有層次關系,在網頁中可以通過XPath或CSS選擇器來定位一個或多個節點,那么,在頁面決議時,利用XPath或CSS選擇器來提取某個節點,然后呼叫相應方法獲取它的正文內容或者屬性,不就可以提取我們想要的資訊了嗎!😜

??我們偉大的Python已經為我們封裝了很多實作上述操作的決議庫,其中比較強大&&用的較多的有lxml,Beautiful Soup,pyquery等,本篇博文帶領小伙伴們走入XPath(我們日后最常用/最實用的決議庫之一)的世界!
| 學好決議庫,網頁資料任我取!!! |
??bs4&&XPath??
- 💎1.XPath(路徑運算式)
- 🎉(1)簡介:
- 🎅(2)安裝:
- 🎃(3)常用規則:
- 🎈(2)實體引入:
- 👻(3)各種常用操作詳解
- ?戰前準備第一步——自定義一個HTML文本模擬爬取到的頁面資料!
- ?💝戰前準備第二步——構造XPath決議物件!
- 🏄(1)常用規則詳解:
- 🎅①nodename表示根據標簽名字選取標簽,注意只會選擇子標簽!比如:如果是兒子的兒子則選取不到,
- 🍏②/表示從根節點選取 一級一級篩選(不能跳)
- 🍒③// 表示從匹配選擇的當前節點選擇檔案中的節點,而不考慮它們的位置, 注意:是所有符合條件的
- 🍓④ .表示選取當前標簽
- 🍌⑤兩個.表示選取當前標簽的父節點
- 🍠⑥@表示獲取標簽的屬性值
- 🎍上述常用規則測驗代碼(建議自己多敲多練多思考!):
- 🐱(2)謂語講解:
- 🐹①選取所有擁有屬性class的p標簽:
- 🐸②選取所有p標簽,且擁有屬性class同時值為story的標簽:
- 🚀③選取所有的p標簽,且其中a標簽的文本值大于889:
- 🐻④選取屬于class為story的p標簽 子元素的第一個a元素:
- 👑⑤選取屬于class為story的p標簽 子元素的最后一個a元素:
- 🐮⑥選取屬于class為story的p標簽 子元素的倒數第二個a元素:
- 🐒⑦選取最前面的兩個屬于class為story的p標簽的子元素的a元素:
- ??上述謂語講解測驗代碼(建議自己多敲多練多思考!):
- 📌(3)獲取文本:
- 🐫①用text()獲取某個節點下的文本:
- 💊②用string()獲取某個節點下所有的文本:
- 🔆上述獲取文本測驗代碼(建議自己多敲多練多思考!):
- 🏃(4)XPath通配符:
- 🔮①*表示匹配任何元素節點:
- 🐾②@* 匹配任何屬性節點:
- 🌷上述XPath通配符測驗代碼(建議自己多敲多練多思考!):
- 🌻(5)使用|運算:
- 🍃①選取p元素的所有a和b元素:
- 🍄②選取檔案中的所有a和b元素:
- 🐚上述使用|運算測驗代碼(建議自己多敲多練多思考!):
- 🌖(4)拓展——騷操作:
- 🌜1.屬性多值匹配(有些時候,有些節點的屬性可能有多個值,)
- 🌋2.多屬性匹配:(有些時候,要根據多個屬性確定一個節點,這時需要同時匹配多個屬性,此時可以使用運算子and來連接!)
- 一些常用的運算子:
- 🌼3.節點軸選擇:
- ??①ancestor軸:
- 🎒②attribute軸:
- 💝③child軸:
- 💝④descendant軸:
- ??⑤following軸:
- 🔇⑥following-sibling軸:
- 🔓2.實戰之豆瓣Top250電影資訊爬取
- 💣3.In The End!

💎1.XPath(路徑運算式)
🎉(1)簡介:
??XPath 是一門在 XML 檔案中查找資訊的語言,但它同樣可用于HTML檔案的搜索,(相比于BeautifulSoup,Xpath在提取資料時會更有效率)
| ??XPath功能十分強大,它提供了非常簡單使用的路徑選擇運算式以及超過100個內建函式,用于字串,數值,時間的匹配以及節點,序列的處理等!所以這也是諸多爬蟲工程師進行頁面決議時的首選!!! |
🎅(2)安裝:
??在python中很多庫都提供XPath的功能,但是最流行的還是lxml這個庫,效率最高,(直接pip install lxml 即可)
| 需要注意的是: |
| 1.python3.7匯入etree的方法為from lxml import html; |
| 2.python3.6匯入etree的方法為from lxml import etree; |
🎃(3)常用規則:
| 運算式 | 描述 |
|---|---|
| nodename | 選取此節點的所有子節點 |
| / | 從當前節點選取直接子節點 |
| // | 從當前接點選取子孫節點 |
| . | 選取當前接點 |
| … | 選取當前接點的父節點 |
| @ | 選取屬性 |
🎈(2)實體引入:
??(我們定義一個text字串模擬爬取到的頁面資料)
from lxml import etree
text = '''
<div class="navli "><span class="nav_tit"><a href="javascript:;">時政</a><i class="group"></i></span></div>
<div class="navli "><span class="nav_tit"><a href="https://news.cctv.com/">新聞</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://v.cctv.com/">視頻</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://jingji.cctv.com/">經濟</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://opinion.cctv.com/">評論</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://sports.cctv.com/">體育</a></span>
'''
html = etree.HTML(text) # 呼叫HTML類進行初始化,這樣就成功構造了一個XPath決議物件,
result = etree.tostring(html)
print(result.decode('utf-8'))
??注意上面HTML文本中的最后一個div節點是沒有閉合的,但是etree模塊可以自動補全HTML文本,為了觀察被自動補全后的HTML文本,再呼叫tostring()方法,注意結果是bytes型別,所以需要decode()方法將其轉為str型別!
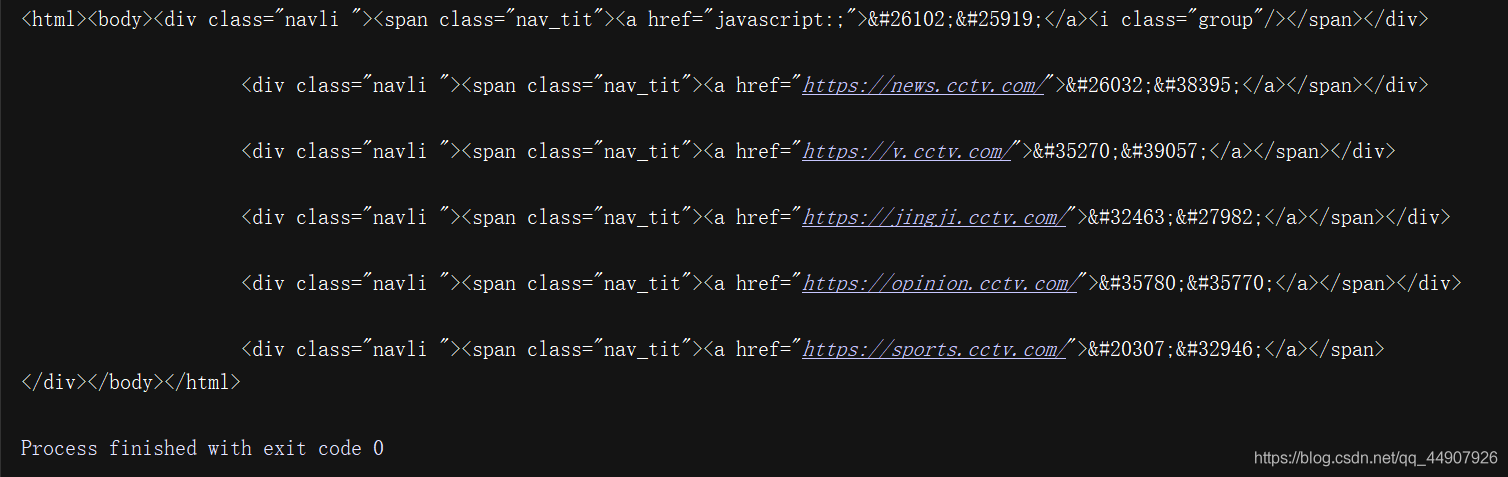
??觀察上面結果可知——經過處理之后,div節點標簽被補全,并且還自動添加了body,html節點!

👻(3)各種常用操作詳解
?戰前準備第一步——自定義一個HTML文本模擬爬取到的頁面資料!
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story" id="66">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">999</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
?💝戰前準備第二步——構造XPath決議物件!
from lxml import etree #原理和beautiful一樣,都是將html字串轉換為我們易于處理的標簽物件
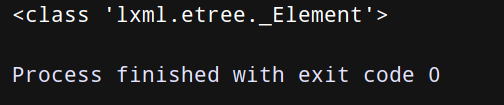
page = etree.HTML(html_doc) #回傳了html節點
print(type(page)) #輸出為:<class 'lxml.etree._Element'>
🏄(1)常用規則詳解:
??XPath使用路徑運算式在 XML/HTML 檔案中選取節點,節點是通過沿著路徑或者 step 來選取的,(注意:所有選中的節點都包含在串列中!)
??下面列出了最有用/最常用的路徑運算式:
🎅①nodename表示根據標簽名字選取標簽,注意只會選擇子標簽!比如:如果是兒子的兒子則選取不到,

🍏②/表示從根節點選取 一級一級篩選(不能跳)
🍒③// 表示從匹配選擇的當前節點選擇檔案中的節點,而不考慮它們的位置, 注意:是所有符合條件的

🍓④ .表示選取當前標簽
🍌⑤兩個.表示選取當前標簽的父節點

🍠⑥@表示獲取標簽的屬性值

🎍上述常用規則測驗代碼(建議自己多敲多練多思考!):
# 1. 根據nodename(標簽名字)選取標簽的時候,只會選擇子標簽;比如:如果是兒子的兒子則選取不到,
print(page.xpath("body"))
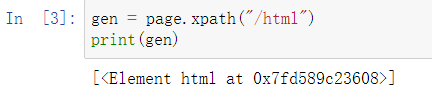
#2. /從根節點選取 一級一級篩選(不能跳)
gen = page.xpath("/html")
print(gen)
#3. 從匹配選擇的當前節點選擇檔案中的節點,而不考慮它們的位置, 注意:是所有符合條件的
a = page.xpath("//a")
print(a)
#4. .選取當前標簽
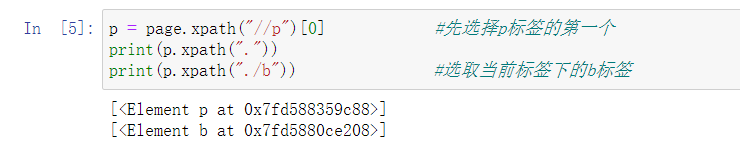
p = page.xpath("//p")[0] #先選擇p標簽的第一個
print(p.xpath("."))
print(p.xpath("./b")) #選取當前標簽下的b標簽
#5. ..選取當前標簽的父節點
a = page.xpath("//a")[0]
print(a.xpath("..")) # a.xpath("parent::")也可獲取父節點!
# 6.獲取標簽的屬性值
bb = page.xpath('//p[@class="story"]/@id') #獲取標簽的id屬性值
print(bb)

🐱(2)謂語講解:
謂語:
??謂語用來查找某個或某些特定的節點或者包含某個指定值的節點
??謂語被嵌在方括號中,
下面列出了帶有最常用/最有用的謂語的一些路徑運算式,以及運算式的結果
🐹①選取所有擁有屬性class的p標簽:

🐸②選取所有p標簽,且擁有屬性class同時值為story的標簽:

🚀③選取所有的p標簽,且其中a標簽的文本值大于889:

🐻④選取屬于class為story的p標簽 子元素的第一個a元素:

👑⑤選取屬于class為story的p標簽 子元素的最后一個a元素:

🐮⑥選取屬于class為story的p標簽 子元素的倒數第二個a元素:

🐒⑦選取最前面的兩個屬于class為story的p標簽的子元素的a元素:

??上述謂語講解測驗代碼(建議自己多敲多練多思考!):
#1.選取所有擁有屬性class的p標簽
j = page.xpath('//p[@class]')
print("j:",j)
#選取所有p標簽,且擁有屬性class同時值為story的標簽
b = page.xpath('//p[@class="story"]')
print("b",b)
#2.選取所有的p標簽,且其中a標簽的文本值大于889,
print(page.xpath('//p[a>889]'))
#3.選取屬于class為story的p標簽 子元素的第一個a元素,
dd = page.xpath('//p[@class="story"]/a[1]') #如果是在xpath里進行索引選擇,是從1開始
ee = page.xpath('//p[@class="story"]/a')[0] #如果是從串列里進行索引選擇,是從0開始
print("dd:",dd)
print("ee",ee)
# 選取屬于class為story的p標簽 子元素的最后一個a元素,
ss = page.xpath('//p[@class="story"]/a[last()]')
print("ss:",ss)
# 選取屬于class為story的p標簽 子元素的倒數第二個a元素,
rr = page.xpath('//p[@class="story"]/a[last()-1]')
print("rr",rr)
# 選取最前面的兩個屬于class為story的p標簽的子元素的a元素,
gg = page.xpath('//p[@class="story"]/a[position()<3]')
print("gg:",gg)
📌(3)獲取文本:
🐫①用text()獲取某個節點下的文本:

💊②用string()獲取某個節點下所有的文本:

🔆上述獲取文本測驗代碼(建議自己多敲多練多思考!):
#1.用text()獲取某個節點下的文本
contents=page.xpath("//p/a/text()") #獲取文本資料 放在串列里
print(contents)
#2.用string()獲取某個節點下所有的文本
con = page.xpath("string(//p)") #只拿到第一個標簽下的所有文本
print(con)

🏃(4)XPath通配符:
??用處:選取未知節點,即XPath通配符可用來選取未知節點
🔮①*表示匹配任何元素節點:

🐾②@* 匹配任何屬性節點:

🌷上述XPath通配符測驗代碼(建議自己多敲多練多思考!):
# 1.* 匹配任何元素節點
s = page.xpath("//p/*") #選擇p標簽的所有子元素
print(s)
#2.@* 匹配任何屬性節點
ss = page.xpath("//p/@*") #選取選中標簽(所有p標簽)的所有的屬性值
print(ss)

🌻(5)使用|運算:
選取多個路徑
?? 通過在路徑運算式中使用"|"運算子,可以實作選取若干個路徑,
🍃①選取p元素的所有a和b元素:

🍄②選取檔案中的所有a和b元素:

🐚上述使用|運算測驗代碼(建議自己多敲多練多思考!):
# 選取p元素的所有a和b元素
print(page.xpath('//p/a|//p/b'))
#選取檔案中的所有a和b元素
print(page.xpath('//a|//b'))

🌖(4)拓展——騷操作:
🌜1.屬性多值匹配(有些時候,有些節點的屬性可能有多個值,)
from lxml import etree
text = '''
<div class="navli navli-first"><span class="nav_tit"><a href="javascript:;">時政</a><i class="group"></i></span></div>
'''
html = etree.HTML(text)
print(html.xpath('//div[@class="navli"]//a/text()'))
??比如上述HTML文本中的div節點的class屬性有兩個值navli和navli-first,此時如果還想用之前的屬性匹配獲取,就無法匹配到了,上述代碼的輸出為[],
?
??兩個解決方法:
????①xpath語法寫入完整的屬性值:print(html.xpath(’//div[@class=“navli navli-first”]//a/text()’)),這樣輸出為:[‘時政’]
????②使用contains()函式,不需要寫入完整屬性值,第一個引數傳入屬性名稱,第二個引數傳入屬性值,只要此屬性包含所傳入的屬性值,就可以完成匹配!如:print(html.xpath(’//div[contains(@class,“navli”)]//a/text()’)),這樣輸出也為:[‘時政’]
🌋2.多屬性匹配:(有些時候,要根據多個屬性確定一個節點,這時需要同時匹配多個屬性,此時可以使用運算子and來連接!)
from lxml import etree
text = '''
<div class="navli navli-first" name="second"><span class="nav_tit"><a href="javascript:;">時政</a><i class="group"></i></span></div>
'''
html = etree.HTML(text)
print(html.xpath('//div[contains(@class,"navli") and @name="second"]//a/text()'))
| 輸出為['時政'] |
一些常用的運算子:
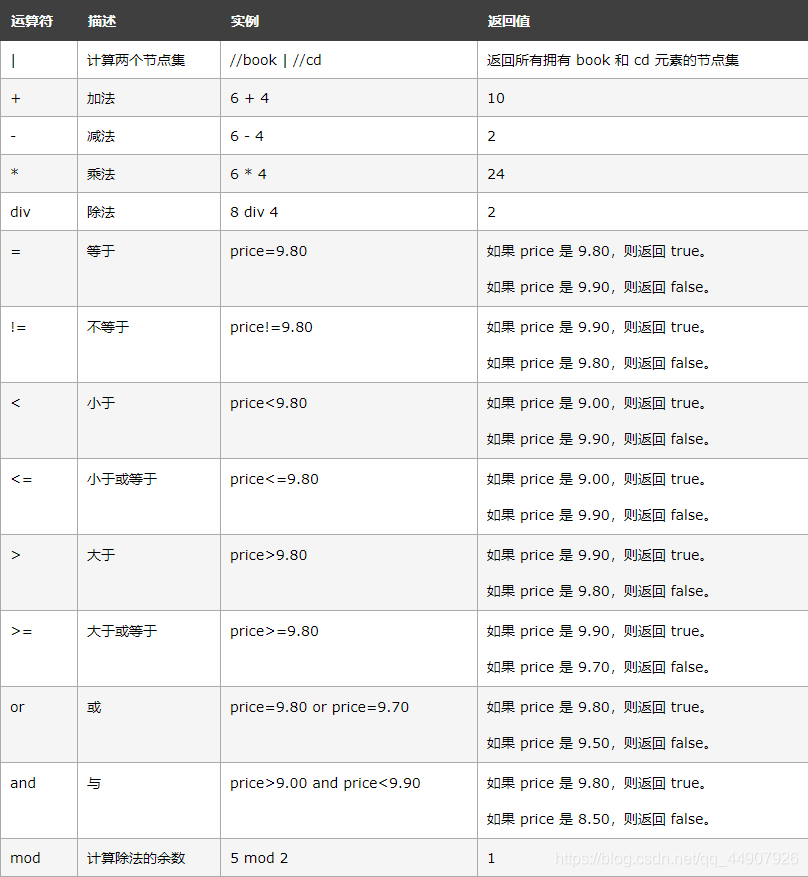 (此表參考自w3school)
(此表參考自w3school)
🌼3.節點軸選擇:
??①ancestor軸:
# 呼叫ancestor軸,獲取所有祖先節點,其后需要跟兩個冒號,然后是節點的選擇器,回傳結果:第一個li節點的所有祖先節點,
html.xpath('//li[1]/ancestor::*')
🎒②attribute軸:
# 呼叫了attribute軸,獲取所有屬性值,回傳結果:li節點的所有屬性值,
html.xpath('//li[1]/attribute::*')
💝③child軸:
# 呼叫了child軸,獲取所有直接子節點,回傳結果:選取href屬性為link.html的a子節點,
html.xpath('//li[1]/child::a[@href="link1.html"]')
💝④descendant軸:
# 呼叫了descendant軸,獲取所有子孫節點,同時加了限定條件,回傳結果:選取li節點下的子孫節點里的span節點,
html.xpath('//li[1]/descendant::span')
??⑤following軸:
# 呼叫了following軸,獲取當前節點之后的所有節點,
html.xpath('//li[1]/following::*[2]')
🔇⑥following-sibling軸:
# 呼叫了following-sibling軸,獲取當前節點之后的所有同級節點,
html.xpath('//li[1]/following-sibling::*')
🔓2.實戰之豆瓣Top250電影資訊爬取
??經過本次實戰實用XPath庫,你會發現進行頁面決議,提取你需要的資料是十分方便快捷的——這也是廣大爬蟲工程師的感受,所以XPath小伙伴們必須要掌握的牢牢的哦!
詳情請看~
💣3.In The End!

| 從現在做起,堅持下去,一天進步一小點,不久的將來,你會感謝曾經努力的你! |
?本博主會持續更新爬蟲基礎分欄及爬蟲實戰分欄,認真仔細看完本文的小伙伴們,可以點贊收藏并評論出你們的讀后感,并可關注本博主,在今后的日子里閱讀更多爬蟲文!
如有錯誤或者言語不恰當的地方可在評論區指出,謝謝!
如轉載此文請聯系我說明用以意并標注出處及本博主名,謝謝!
?
??可通過點擊下面——>添加私人VX號—>請標明來自CSDN,會拉你進入技術交流群(群內涉及各個領域大佬級人物,任何問題都可討論~)—>互相學習&&共同進步(非誠勿擾):
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299994.html
標籤:python