大家好,我是辣條,
Pandas 是Python的核心資料分析支持庫,提供了快速、靈活、明確的資料結構,旨在簡單、直觀地處理關系型、標記型資料,Pandas常用于處理帶行列標簽的矩陣資料、與 SQL 或 Excel 表類似的表格資料,應用于金融、統計、社會科學、工程等領域里的資料整理與清洗、資料分析與建模、資料可視化與制表等作業,
練習題索引
| 習題編號 | 內容 | 相應資料集 |
|---|---|---|
| 練習1 - 開始了解你的資料 | 探索Chipotle快餐資料 | chipotle.tsv |
| 練習2 - 資料過濾與排序 | 探索2012歐洲杯資料 | Euro2012_stats.csv |
| [練習3 - 資料分組] | 探索酒類消費資料 | drinks.csv |
| [練習4 -Apply函式] | 探索1960 - 2014 美國犯罪資料 | US_Crime_Rates_1960_2014.csv |
| [練習5 - 合并] | 探索虛擬姓名資料 | 練習中手動內置的資料 |
| [練習6 - 統計 | 探索風速資料 | wind.data |
| [練習7 - 可視化] | 探索泰坦尼克災難資料 | train.csv |
| [練習8 - 創建資料框 | 探索Pokemon資料 | 練習中手動內置的資料 |
| [練習9 - 時間序列 | 探索Apple公司股價資料 | Apple_stock.csv |
| [練習10 - 洗掉資料 | 探索Iris紙鳶花資料 | iris.csv |
練習1-開始了解你的資料
探索Chipotle快餐資料

步驟1 匯入必要的庫
In [7]:
# 運行以下代碼
import pandas as pd步驟2 從如下地址匯入資料集
In [5]:
# 運行以下代碼
path1 = "./exercise_data/chipotle.tsv" # chipotle.tsv
步驟3 將資料集存入一個名為chipo的資料框內
In [8]:
# 運行以下代碼
chipo = pd.read_csv(path1, sep = '\t')
步驟4 查看前10行內容
In [9]:
# 運行以下代碼
chipo.head(10)
Out[9]:
| order_id | quantity | item_name | choice_description | item_price | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | Chips and Fresh Tomato Salsa | NaN | $2.39 |
| 1 | 1 | 1 | Izze | [Clementine] | $3.39 |
| 2 | 1 | 1 | Nantucket Nectar | [Apple] | $3.39 |
| 3 | 1 | 1 | Chips and Tomatillo-Green Chili Salsa | NaN | $2.39 |
| 4 | 2 | 2 | Chicken Bowl | [Tomatillo-Red Chili Salsa (Hot), [Black Beans... | $16.98 |
| 5 | 3 | 1 | Chicken Bowl | [Fresh Tomato Salsa (Mild), [Rice, Cheese, Sou... | $10.98 |
| 6 | 3 | 1 | Side of Chips | NaN | $1.69 |
| 7 | 4 | 1 | Steak Burrito | [Tomatillo Red Chili Salsa, [Fajita Vegetables... | $11.75 |
| 8 | 4 | 1 | Steak Soft Tacos | [Tomatillo Green Chili Salsa, [Pinto Beans, Ch... | $9.25 |
| 9 | 5 | 1 | Steak Burrito | [Fresh Tomato Salsa, [Rice, Black Beans, Pinto... | $9.25 |
步驟6 資料集中有多少個列(columns)
In [236]:
# 運行以下代碼
chipo.shape[1]
Out[236]:
5
步驟7 列印出全部的列名稱
In [237]:
# 運行以下代碼
chipo.columns
Out[237]:
Index(['order_id', 'quantity', 'item_name', 'choice_description',
'item_price'],
dtype='object')
步驟8 資料集的索引是怎樣的
In [238]:
# 運行以下代碼
chipo.index
Out[238]:
RangeIndex(start=0, stop=4622, step=1)
步驟9 被下單數最多商品(item)是什么?
In [239]:
# 運行以下代碼,做了修正
c = chipo[['item_name','quantity']].groupby(['item_name'],as_index=False).agg({'quantity':sum})
c.sort_values(['quantity'],ascending=False,inplace=True)
c.head()
Out[239]:
| item_name | quantity | |
|---|---|---|
| 17 | Chicken Bowl | 761 |
| 18 | Chicken Burrito | 591 |
| 25 | Chips and Guacamole | 506 |
| 39 | Steak Burrito | 386 |
| 10 | Canned Soft Drink | 351 |
步驟10 在item_name這一列中,一共有多少種商品被下單?
In [240]:
# 運行以下代碼
chipo['item_name'].nunique()
Out[240]:
50
步驟11 在choice_description中,下單次數最多的商品是什么?
In [241]:
# 運行以下代碼,存在一些小問題
chipo['choice_description'].value_counts().head()
Out[241]:
[Diet Coke] 134
[Coke] 123
[Sprite] 77
[Fresh Tomato Salsa, [Rice, Black Beans, Cheese, Sour Cream, Lettuce]] 42
[Fresh Tomato Salsa, [Rice, Black Beans, Cheese, Sour Cream, Guacamole, Lettuce]] 40
Name: choice_description, dtype: int64
步驟12 一共有多少商品被下單?
In [242]:
# 運行以下代碼
total_items_orders = chipo['quantity'].sum()
total_items_orders
Out[242]:
4972
步驟13 將item_price轉換為浮點數
In [243]:
# 運行以下代碼 dollarizer = lambda x: float(x[1:-1]) chipo['item_price'] = chipo['item_price'].apply(dollarizer)
步驟14 在該資料集對應的時期內,收入(revenue)是多少
In [244]:
# 運行以下代碼,已經做更正 chipo['sub_total'] = round(chipo['item_price'] * chipo['quantity'],2) chipo['sub_total'].sum()
Out[244]:
39237.02
步驟15 在該資料集對應的時期內,一共有多少訂單?
In [245]:
# 運行以下代碼 chipo['order_id'].nunique()
Out[245]:
1834
步驟16 每一單(order)對應的平均總價是多少?
In [246]:
# 運行以下代碼,已經做過更正
chipo[['order_id','sub_total']].groupby(by=['order_id']
).agg({'sub_total':'sum'})['sub_total'].mean()
Out[246]:
21.39423118865867
步驟17 一共有多少種不同的商品被售出?
In [247]:
# 運行以下代碼 chipo['item_name'].nunique()
Out[247]:
練習2-資料過濾與排序
探索2012歐洲杯資料

步驟1 - 匯入必要的庫
In [248]:
# 運行以下代碼 import pandas as pd
步驟2 - 從以下地址匯入資料集
In [249]:
# 運行以下代碼 path2 = "./exercise_data/Euro2012_stats.csv" # Euro2012_stats.csv
步驟3 - 將資料集命名為euro12
In [250]:
# 運行以下代碼 euro12 = pd.read_csv(path2) euro12
Out[250]:
| Team | Goals | Shots on target | Shots off target | Shooting Accuracy | % Goals-to-shots | Total shots (inc. Blocked) | Hit Woodwork | Penalty goals | Penalties not scored | ... | Saves made | Saves-to-shots ratio | Fouls Won | Fouls Conceded | Offsides | Yellow Cards | Red Cards | Subs on | Subs off | Players Used | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Croatia | 4 | 13 | 12 | 51.9% | 16.0% | 32 | 0 | 0 | 0 | ... | 13 | 81.3% | 41 | 62 | 2 | 9 | 0 | 9 | 9 | 16 |
| 1 | Czech Republic | 4 | 13 | 18 | 41.9% | 12.9% | 39 | 0 | 0 | 0 | ... | 9 | 60.1% | 53 | 73 | 8 | 7 | 0 | 11 | 11 | 19 |
| 2 | Denmark | 4 | 10 | 10 | 50.0% | 20.0% | 27 | 1 | 0 | 0 | ... | 10 | 66.7% | 25 | 38 | 8 | 4 | 0 | 7 | 7 | 15 |
| 3 | England | 5 | 11 | 18 | 50.0% | 17.2% | 40 | 0 | 0 | 0 | ... | 22 | 88.1% | 43 | 45 | 6 | 5 | 0 | 11 | 11 | 16 |
| 4 | France | 3 | 22 | 24 | 37.9% | 6.5% | 65 | 1 | 0 | 0 | ... | 6 | 54.6% | 36 | 51 | 5 | 6 | 0 | 11 | 11 | 19 |
| 5 | Germany | 10 | 32 | 32 | 47.8% | 15.6% | 80 | 2 | 1 | 0 | ... | 10 | 62.6% | 63 | 49 | 12 | 4 | 0 | 15 | 15 | 17 |
| 6 | Greece | 5 | 8 | 18 | 30.7% | 19.2% | 32 | 1 | 1 | 1 | ... | 13 | 65.1% | 67 | 48 | 12 | 9 | 1 | 12 | 12 | 20 |
| 7 | Italy | 6 | 34 | 45 | 43.0% | 7.5% | 110 | 2 | 0 | 0 | ... | 20 | 74.1% | 101 | 89 | 16 | 16 | 0 | 18 | 18 | 19 |
| 8 | Netherlands | 2 | 12 | 36 | 25.0% | 4.1% | 60 | 2 | 0 | 0 | ... | 12 | 70.6% | 35 | 30 | 3 | 5 | 0 | 7 | 7 | 15 |
| 9 | Poland | 2 | 15 | 23 | 39.4% | 5.2% | 48 | 0 | 0 | 0 | ... | 6 | 66.7% | 48 | 56 | 3 | 7 | 1 | 7 | 7 | 17 |
| 10 | Portugal | 6 | 22 | 42 | 34.3% | 9.3% | 82 | 6 | 0 | 0 | ... | 10 | 71.5% | 73 | 90 | 10 | 12 | 0 | 14 | 14 | 16 |
| 11 | Republic of Ireland | 1 | 7 | 12 | 36.8% | 5.2% | 28 | 0 | 0 | 0 | ... | 17 | 65.4% | 43 | 51 | 11 | 6 | 1 | 10 | 10 | 17 |
| 12 | Russia | 5 | 9 | 31 | 22.5% | 12.5% | 59 | 2 | 0 | 0 | ... | 10 | 77.0% | 34 | 43 | 4 | 6 | 0 | 7 | 7 | 16 |
| 13 | Spain | 12 | 42 | 33 | 55.9% | 16.0% | 100 | 0 | 1 | 0 | ... | 15 | 93.8% | 102 | 83 | 19 | 11 | 0 | 17 | 17 | 18 |
| 14 | Sweden | 5 | 17 | 19 | 47.2% | 13.8% | 39 | 3 | 0 | 0 | ... | 8 | 61.6% | 35 | 51 | 7 | 7 | 0 | 9 | 9 | 18 |
| 15 | Ukraine | 2 | 7 | 26 | 21.2% | 6.0% | 38 | 0 | 0 | 0 | ... | 13 | 76.5% | 48 | 31 | 4 | 5 | 0 | 9 | 9 | 18 |
16 rows × 35 columns
步驟4 只選取 Goals 這一列
In [251]:
# 運行以下代碼 euro12.Goals
Out[251]:
0 4 1 4 2 4 3 5 4 3 5 10 6 5 7 6 8 2 9 2 10 6 11 1 12 5 13 12 14 5 15 2 Name: Goals, dtype: int64
步驟5 有多少球隊參與了2012歐洲杯?
In [252]:
# 運行以下代碼 euro12.shape[0]
Out[252]:
16
步驟6 該資料集中一共有多少列(columns)?
In [253]:
# 運行以下代碼 euro12.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 16 entries, 0 to 15 Data columns (total 35 columns): Team 16 non-null object Goals 16 non-null int64 Shots on target 16 non-null int64 Shots off target 16 non-null int64 Shooting Accuracy 16 non-null object % Goals-to-shots 16 non-null object Total shots (inc. Blocked) 16 non-null int64 Hit Woodwork 16 non-null int64 Penalty goals 16 non-null int64 Penalties not scored 16 non-null int64 Headed goals 16 non-null int64 Passes 16 non-null int64 Passes completed 16 non-null int64 Passing Accuracy 16 non-null object Touches 16 non-null int64 Crosses 16 non-null int64 Dribbles 16 non-null int64 Corners Taken 16 non-null int64 Tackles 16 non-null int64 Clearances 16 non-null int64 Interceptions 16 non-null int64 Clearances off line 15 non-null float64 Clean Sheets 16 non-null int64 Blocks 16 non-null int64 Goals conceded 16 non-null int64 Saves made 16 non-null int64 Saves-to-shots ratio 16 non-null object Fouls Won 16 non-null int64 Fouls Conceded 16 non-null int64 Offsides 16 non-null int64 Yellow Cards 16 non-null int64 Red Cards 16 non-null int64 Subs on 16 non-null int64 Subs off 16 non-null int64 Players Used 16 non-null int64 dtypes: float64(1), int64(29), object(5) memory usage: 4.5+ KB
步驟7 將資料集中的列Team, Yellow Cards和Red Cards單獨存為一個名叫discipline的資料框
In [254]:
# 運行以下代碼 discipline = euro12[['Team', 'Yellow Cards', 'Red Cards']] discipline
Out[254]:
| Team | Yellow Cards | Red Cards | |
|---|---|---|---|
| 0 | Croatia | 9 | 0 |
| 1 | Czech Republic | 7 | 0 |
| 2 | Denmark | 4 | 0 |
| 3 | England | 5 | 0 |
| 4 | France | 6 | 0 |
| 5 | Germany | 4 | 0 |
| 6 | Greece | 9 | 1 |
| 7 | Italy | 16 | 0 |
| 8 | Netherlands | 5 | 0 |
| 9 | Poland | 7 | 1 |
| 10 | Portugal | 12 | 0 |
| 11 | Republic of Ireland | 6 | 1 |
| 12 | Russia | 6 | 0 |
| 13 | Spain | 11 | 0 |
| 14 | Sweden | 7 | 0 |
| 15 | Ukraine | 5 | 0 |
步驟8 對資料框discipline按照先Red Cards再Yellow Cards進行排序
In [255]:
# 運行以下代碼 discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending = False)
Out[255]:
| Team | Yellow Cards | Red Cards | |
|---|---|---|---|
| 6 | Greece | 9 | 1 |
| 9 | Poland | 7 | 1 |
| 11 | Republic of Ireland | 6 | 1 |
| 7 | Italy | 16 | 0 |
| 10 | Portugal | 12 | 0 |
| 13 | Spain | 11 | 0 |
| 0 | Croatia | 9 | 0 |
| 1 | Czech Republic | 7 | 0 |
| 14 | Sweden | 7 | 0 |
| 4 | France | 6 | 0 |
| 12 | Russia | 6 | 0 |
| 3 | England | 5 | 0 |
| 8 | Netherlands | 5 | 0 |
| 15 | Ukraine | 5 | 0 |
| 2 | Denmark | 4 | 0 |
| 5 | Germany | 4 | 0 |
步驟9 計算每個球隊拿到的黃牌數的平均值
In [256]:
# 運行以下代碼 round(discipline['Yellow Cards'].mean())
Out[256]:
7.0
步驟10 找到進球數Goals超過6的球隊資料
In [257]:
# 運行以下代碼 euro12[euro12.Goals > 6]
Out[257]:
| Team | Goals | Shots on target | Shots off target | Shooting Accuracy | % Goals-to-shots | Total shots (inc. Blocked) | Hit Woodwork | Penalty goals | Penalties not scored | ... | Saves made | Saves-to-shots ratio | Fouls Won | Fouls Conceded | Offsides | Yellow Cards | Red Cards | Subs on | Subs off | Players Used | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | Germany | 10 | 32 | 32 | 47.8% | 15.6% | 80 | 2 | 1 | 0 | ... | 10 | 62.6% | 63 | 49 | 12 | 4 | 0 | 15 | 15 | 17 |
| 13 | Spain | 12 | 42 | 33 | 55.9% | 16.0% | 100 | 0 | 1 | 0 | ... | 15 | 93.8% | 102 | 83 | 19 | 11 | 0 | 17 | 17 | 18 |
2 rows × 35 columns
步驟11 選取以字母G開頭的球隊資料
In [258]:
# 運行以下代碼
euro12[euro12.Team.str.startswith('G')]
Out[258]:
| Team | Goals | Shots on target | Shots off target | Shooting Accuracy | % Goals-to-shots | Total shots (inc. Blocked) | Hit Woodwork | Penalty goals | Penalties not scored | ... | Saves made | Saves-to-shots ratio | Fouls Won | Fouls Conceded | Offsides | Yellow Cards | Red Cards | Subs on | Subs off | Players Used | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | Germany | 10 | 32 | 32 | 47.8% | 15.6% | 80 | 2 | 1 | 0 | ... | 10 | 62.6% | 63 | 49 | 12 | 4 | 0 | 15 | 15 | 17 |
| 6 | Greece | 5 | 8 | 18 | 30.7% | 19.2% | 32 | 1 | 1 | 1 | ... | 13 | 65.1% | 67 | 48 | 12 | 9 | 1 | 12 | 12 | 20 |
2 rows × 35 columns
步驟12 選取前7列
In [259]:
# 運行以下代碼 euro12.iloc[: , 0:7]
Out[259]:
| Team | Goals | Shots on target | Shots off target | Shooting Accuracy | % Goals-to-shots | Total shots (inc. Blocked) | |
|---|---|---|---|---|---|---|---|
| 0 | Croatia | 4 | 13 | 12 | 51.9% | 16.0% | 32 |
| 1 | Czech Republic | 4 | 13 | 18 | 41.9% | 12.9% | 39 |
| 2 | Denmark | 4 | 10 | 10 | 50.0% | 20.0% | 27 |
| 3 | England | 5 | 11 | 18 | 50.0% | 17.2% | 40 |
| 4 | France | 3 | 22 | 24 | 37.9% | 6.5% | 65 |
| 5 | Germany | 10 | 32 | 32 | 47.8% | 15.6% | 80 |
| 6 | Greece | 5 | 8 | 18 | 30.7% | 19.2% | 32 |
| 7 | Italy | 6 | 34 | 45 | 43.0% | 7.5% | 110 |
| 8 | Netherlands | 2 | 12 | 36 | 25.0% | 4.1% | 60 |
| 9 | Poland | 2 | 15 | 23 | 39.4% | 5.2% | 48 |
| 10 | Portugal | 6 | 22 | 42 | 34.3% | 9.3% | 82 |
| 11 | Republic of Ireland | 1 | 7 | 12 | 36.8% | 5.2% | 28 |
| 12 | Russia | 5 | 9 | 31 | 22.5% | 12.5% | 59 |
| 13 | Spain | 12 | 42 | 33 | 55.9% | 16.0% | 100 |
| 14 | Sweden | 5 | 17 | 19 | 47.2% | 13.8% | 39 |
| 15 | Ukraine | 2 | 7 | 26 | 21.2% | 6.0% | 38 |
步驟13 選取除了最后3列之外的全部列
In [260]:
# 運行以下代碼 euro12.iloc[: , :-3]
Out[260]:
| Team | Goals | Shots on target | Shots off target | Shooting Accuracy | % Goals-to-shots | Total shots (inc. Blocked) | Hit Woodwork | Penalty goals | Penalties not scored | ... | Clean Sheets | Blocks | Goals conceded | Saves made | Saves-to-shots ratio | Fouls Won | Fouls Conceded | Offsides | Yellow Cards | Red Cards | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Croatia | 4 | 13 | 12 | 51.9% | 16.0% | 32 | 0 | 0 | 0 | ... | 0 | 10 | 3 | 13 | 81.3% | 41 | 62 | 2 | 9 | 0 |
| 1 | Czech Republic | 4 | 13 | 18 | 41.9% | 12.9% | 39 | 0 | 0 | 0 | ... | 1 | 10 | 6 | 9 | 60.1% | 53 | 73 | 8 | 7 | 0 |
| 2 | Denmark | 4 | 10 | 10 | 50.0% | 20.0% | 27 | 1 | 0 | 0 | ... | 1 | 10 | 5 | 10 | 66.7% | 25 | 38 | 8 | 4 | 0 |
| 3 | England | 5 | 11 | 18 | 50.0% | 17.2% | 40 | 0 | 0 | 0 | ... | 2 | 29 | 3 | 22 | 88.1% | 43 | 45 | 6 | 5 | 0 |
| 4 | France | 3 | 22 | 24 | 37.9% | 6.5% | 65 | 1 | 0 | 0 | ... | 1 | 7 | 5 | 6 | 54.6% | 36 | 51 | 5 | 6 | 0 |
| 5 | Germany | 10 | 32 | 32 | 47.8% | 15.6% | 80 | 2 | 1 | 0 | ... | 1 | 11 | 6 | 10 | 62.6% | 63 | 49 | 12 | 4 | 0 |
| 6 | Greece | 5 | 8 | 18 | 30.7% | 19.2% | 32 | 1 | 1 | 1 | ... | 1 | 23 | 7 | 13 | 65.1% | 67 | 48 | 12 | 9 | 1 |
| 7 | Italy | 6 | 34 | 45 | 43.0% | 7.5% | 110 | 2 | 0 | 0 | ... | 2 | 18 | 7 | 20 | 74.1% | 101 | 89 | 16 | 16 | 0 |
| 8 | Netherlands | 2 | 12 | 36 | 25.0% | 4.1% | 60 | 2 | 0 | 0 | ... | 0 | 9 | 5 | 12 | 70.6% | 35 | 30 | 3 | 5 | 0 |
| 9 | Poland | 2 | 15 | 23 | 39.4% | 5.2% | 48 | 0 | 0 | 0 | ... | 0 | 8 | 3 | 6 | 66.7% | 48 | 56 | 3 | 7 | 1 |
| 10 | Portugal | 6 | 22 | 42 | 34.3% | 9.3% | 82 | 6 | 0 | 0 | ... | 2 | 11 | 4 | 10 | 71.5% | 73 | 90 | 10 | 12 | 0 |
| 11 | Republic of Ireland | 1 | 7 | 12 | 36.8% | 5.2% | 28 | 0 | 0 | 0 | ... | 0 | 23 | 9 | 17 | 65.4% | 43 | 51 | 11 | 6 | 1 |
| 12 | Russia | 5 | 9 | 31 | 22.5% | 12.5% | 59 | 2 | 0 | 0 | ... | 0 | 8 | 3 | 10 | 77.0% | 34 | 43 | 4 | 6 | 0 |
| 13 | Spain | 12 | 42 | 33 | 55.9% | 16.0% | 100 | 0 | 1 | 0 | ... | 5 | 8 | 1 | 15 | 93.8% | 102 | 83 | 19 | 11 | 0 |
| 14 | Sweden | 5 | 17 | 19 | 47.2% | 13.8% | 39 | 3 | 0 | 0 | ... | 1 | 12 | 5 | 8 | 61.6% | 35 | 51 | 7 | 7 | 0 |
| 15 | Ukraine | 2 | 7 | 26 | 21.2% | 6.0% | 38 | 0 | 0 | 0 | ... | 0 | 4 | 4 | 13 | 76.5% | 48 | 31 | 4 | 5 | 0 |
16 rows × 32 columns
步驟14 找到英格蘭(England)、意大利(Italy)和俄羅斯(Russia)的射正率(Shooting Accuracy)
In [261]:
# 運行以下代碼 euro12.loc[euro12.Team.isin(['England', 'Italy', 'Russia']), ['Team','Shooting Accuracy']]
Out[261]:
| Team | Shooting Accuracy | |
|---|---|---|
| 3 | England | 50.0% |
| 7 | Italy | 43.0% |
| 12 | Russia | 22.5% |
練習3-資料分組
探索酒類消費資料

步驟1 匯入必要的庫
In [262]:
# 運行以下代碼 import pandas as pd
步驟2 從以下地址匯入資料
In [10]:
# 運行以下代碼 path3 ='./exercise_data/drinks.csv' #'drinks.csv'
步驟3 將資料框命名為drinks
In [11]:
# 運行以下代碼 drinks = pd.read_csv(path3) drinks.head()
Out[11]:
| country | beer_servings | spirit_servings | wine_servings | total_litres_of_pure_alcohol | continent | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | 0 | 0 | 0 | 0.0 | AS |
| 1 | Albania | 89 | 132 | 54 | 4.9 | EU |
| 2 | Algeria | 25 | 0 | 14 | 0.7 | AF |
| 3 | Andorra | 245 | 138 | 312 | 12.4 | EU |
| 4 | Angola | 217 | 57 | 45 | 5.9 | AF |
步驟4 哪個大陸(continent)平均消耗的啤酒(beer)更多?
In [12]:
# 運行以下代碼
drinks.groupby('continent').beer_servings.mean()
Out[12]:
continent AF 61.471698 AS 37.045455 EU 193.777778 OC 89.687500 SA 175.083333 Name: beer_servings, dtype: float64
步驟5 列印出每個大陸(continent)的紅酒消耗(wine_servings)的描述性統計值
In [13]:
# 運行以下代碼
drinks.groupby('continent').wine_servings.describe()
Out[13]:
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| continent | ||||||||
| AF | 53.0 | 16.264151 | 38.846419 | 0.0 | 1.0 | 2.0 | 13.00 | 233.0 |
| AS | 44.0 | 9.068182 | 21.667034 | 0.0 | 0.0 | 1.0 | 8.00 | 123.0 |
| EU | 45.0 | 142.222222 | 97.421738 | 0.0 | 59.0 | 128.0 | 195.00 | 370.0 |
| OC | 16.0 | 35.625000 | 64.555790 | 0.0 | 1.0 | 8.5 | 23.25 | 212.0 |
| SA | 12.0 | 62.416667 | 88.620189 | 1.0 | 3.0 | 12.0 | 98.50 | 221.0 |
步驟6 列印出每個大陸每種酒類別的消耗平均值
In [15]:
# 運行以下代碼
drinks.groupby('continent').mean()
Out[15]:
| beer_servings | spirit_servings | wine_servings | total_litres_of_pure_alcohol | |
|---|---|---|---|---|
| continent | ||||
| AF | 61.471698 | 16.339623 | 16.264151 | 3.007547 |
| AS | 37.045455 | 60.840909 | 9.068182 | 2.170455 |
| EU | 193.777778 | 132.555556 | 142.222222 | 8.617778 |
| OC | 89.687500 | 58.437500 | 35.625000 | 3.381250 |
| SA | 175.083333 | 114.750000 | 62.416667 | 6.308333 |
步驟7 列印出每個大陸每種酒類別的消耗中位數
In [268]:
# 運行以下代碼
drinks.groupby('continent').median()
Out[268]:
| beer_servings | spirit_servings | wine_servings | total_litres_of_pure_alcohol | |
|---|---|---|---|---|
| continent | ||||
| AF | 32.0 | 3.0 | 2.0 | 2.30 |
| AS | 17.5 | 16.0 | 1.0 | 1.20 |
| EU | 219.0 | 122.0 | 128.0 | 10.00 |
| OC | 52.5 | 37.0 | 8.5 | 1.75 |
| SA | 162.5 | 108.5 | 12.0 | 6.85 |
步驟8 列印出每個大陸對spirit飲品消耗的平均值,最大值和最小值
In [269]:
# 運行以下代碼
drinks.groupby('continent').spirit_servings.agg(['mean', 'min', 'max'])
Out[269]:
| mean | min | max | |
|---|---|---|---|
| continent | |||
| AF | 16.339623 | 0 | 152 |
| AS | 60.840909 | 0 | 326 |
| EU | 132.555556 | 0 | 373 |
| OC | 58.437500 | 0 | 254 |
| SA | 114.750000 | 25 | 302 |
練習4-Apply函式
探索1960 - 2014 美國犯罪資料

步驟1 匯入必要的庫
In [16]:
# 運行以下代碼 import numpy as np import pandas as pd
步驟2 從以下地址匯入資料集
In [27]:
# 運行以下代碼 path4 = './exercise_data/US_Crime_Rates_1960_2014.csv' # "US_Crime_Rates_1960_2014.csv"
步驟3 將資料框命名為crime
In [28]:
# 運行以下代碼 crime = pd.read_csv(path4) crime.head()
Out[28]:
| Year | Population | Total | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1960 | 179323175 | 3384200 | 288460 | 3095700 | 9110 | 17190 | 107840 | 154320 | 912100 | 1855400 | 328200 |
| 1 | 1961 | 182992000 | 3488000 | 289390 | 3198600 | 8740 | 17220 | 106670 | 156760 | 949600 | 1913000 | 336000 |
| 2 | 1962 | 185771000 | 3752200 | 301510 | 3450700 | 8530 | 17550 | 110860 | 164570 | 994300 | 2089600 | 366800 |
| 3 | 1963 | 188483000 | 4109500 | 316970 | 3792500 | 8640 | 17650 | 116470 | 174210 | 1086400 | 2297800 | 408300 |
| 4 | 1964 | 191141000 | 4564600 | 364220 | 4200400 | 9360 | 21420 | 130390 | 203050 | 1213200 | 2514400 | 472800 |
步驟4 每一列(column)的資料型別是什么樣的?
In [29]:
# 運行以下代碼 crime.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 55 entries, 0 to 54 Data columns (total 12 columns): Year 55 non-null int64 Population 55 non-null int64 Total 55 non-null int64 Violent 55 non-null int64 Property 55 non-null int64 Murder 55 non-null int64 Forcible_Rape 55 non-null int64 Robbery 55 non-null int64 Aggravated_assault 55 non-null int64 Burglary 55 non-null int64 Larceny_Theft 55 non-null int64 Vehicle_Theft 55 non-null int64 dtypes: int64(12) memory usage: 5.2 KB
注意到了嗎,Year的資料型別為 int64,但是pandas有一個不同的資料型別去處理時間序列(time series),我們現在來看看,
步驟5 將Year的資料型別轉換為 datetime64
In [30]:
# 運行以下代碼 crime.Year = pd.to_datetime(crime.Year, format='%Y') crime.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 55 entries, 0 to 54 Data columns (total 12 columns): Year 55 non-null datetime64[ns] Population 55 non-null int64 Total 55 non-null int64 Violent 55 non-null int64 Property 55 non-null int64 Murder 55 non-null int64 Forcible_Rape 55 non-null int64 Robbery 55 non-null int64 Aggravated_assault 55 non-null int64 Burglary 55 non-null int64 Larceny_Theft 55 non-null int64 Vehicle_Theft 55 non-null int64 dtypes: datetime64[ns](1), int64(11) memory usage: 5.2 KB
步驟6 將列Year設定為資料框的索引
In [31]:
# 運行以下代碼
crime = crime.set_index('Year', drop = True)
crime.head()
Out[31]:
| Population | Total | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | |||||||||||
| 1960-01-01 | 179323175 | 3384200 | 288460 | 3095700 | 9110 | 17190 | 107840 | 154320 | 912100 | 1855400 | 328200 |
| 1961-01-01 | 182992000 | 3488000 | 289390 | 3198600 | 8740 | 17220 | 106670 | 156760 | 949600 | 1913000 | 336000 |
| 1962-01-01 | 185771000 | 3752200 | 301510 | 3450700 | 8530 | 17550 | 110860 | 164570 | 994300 | 2089600 | 366800 |
| 1963-01-01 | 188483000 | 4109500 | 316970 | 3792500 | 8640 | 17650 | 116470 | 174210 | 1086400 | 2297800 | 408300 |
| 1964-01-01 | 191141000 | 4564600 | 364220 | 4200400 | 9360 | 21420 | 130390 | 203050 | 1213200 | 2514400 | 472800 |
步驟7 洗掉名為Total的列
In [32]:
# 運行以下代碼 del crime['Total'] crime.head()
Out[32]:
| Population | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||
| 1960-01-01 | 179323175 | 288460 | 3095700 | 9110 | 17190 | 107840 | 154320 | 912100 | 1855400 | 328200 |
| 1961-01-01 | 182992000 | 289390 | 3198600 | 8740 | 17220 | 106670 | 156760 | 949600 | 1913000 | 336000 |
| 1962-01-01 | 185771000 | 301510 | 3450700 | 8530 | 17550 | 110860 | 164570 | 994300 | 2089600 | 366800 |
| 1963-01-01 | 188483000 | 316970 | 3792500 | 8640 | 17650 | 116470 | 174210 | 1086400 | 2297800 | 408300 |
| 1964-01-01 | 191141000 | 364220 | 4200400 | 9360 | 21420 | 130390 | 203050 | 1213200 | 2514400 | 472800 |
In [33]:
crime.resample('10AS').sum()
Out[33]:
| Population | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||
| 1960-01-01 | 1915053175 | 4134930 | 45160900 | 106180 | 236720 | 1633510 | 2158520 | 13321100 | 26547700 | 5292100 |
| 1970-01-01 | 2121193298 | 9607930 | 91383800 | 192230 | 554570 | 4159020 | 4702120 | 28486000 | 53157800 | 9739900 |
| 1980-01-01 | 2371370069 | 14074328 | 117048900 | 206439 | 865639 | 5383109 | 7619130 | 33073494 | 72040253 | 11935411 |
| 1990-01-01 | 2612825258 | 17527048 | 119053499 | 211664 | 998827 | 5748930 | 10568963 | 26750015 | 77679366 | 14624418 |
| 2000-01-01 | 2947969117 | 13968056 | 100944369 | 163068 | 922499 | 4230366 | 8652124 | 21565176 | 67970291 | 11412834 |
| 2010-01-01 | 1570146307 | 6072017 | 44095950 | 72867 | 421059 | 1749809 | 3764142 | 10125170 | 30401698 | 3569080 |
步驟8 按照Year對資料框進行分組并求和
*注意Population這一列,若直接對其求和,是不正確的**
In [34]:
# 更多關于 .resample 的介紹
# (https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.resample.html)
# 更多關于 Offset Aliases的介紹
# (http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases)
# 運行以下代碼
crimes = crime.resample('10AS').sum() # resample a time series per decades
# 用resample去得到“Population”列的最大值
population = crime['Population'].resample('10AS').max()
# 更新 "Population"
crimes['Population'] = population
crimes
Out[34]:
| Population | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||
| 1960-01-01 | 201385000 | 4134930 | 45160900 | 106180 | 236720 | 1633510 | 2158520 | 13321100 | 26547700 | 5292100 |
| 1970-01-01 | 220099000 | 9607930 | 91383800 | 192230 | 554570 | 4159020 | 4702120 | 28486000 | 53157800 | 9739900 |
| 1980-01-01 | 248239000 | 14074328 | 117048900 | 206439 | 865639 | 5383109 | 7619130 | 33073494 | 72040253 | 11935411 |
| 1990-01-01 | 272690813 | 17527048 | 119053499 | 211664 | 998827 | 5748930 | 10568963 | 26750015 | 77679366 | 14624418 |
| 2000-01-01 | 307006550 | 13968056 | 100944369 | 163068 | 922499 | 4230366 | 8652124 | 21565176 | 67970291 | 11412834 |
| 2010-01-01 | 318857056 | 6072017 | 44095950 | 72867 | 421059 | 1749809 | 3764142 | 10125170 | 30401698 | 3569080 |
步驟9 何時是美國歷史上生存最危險的年代?
In [279]:
# 運行以下代碼 crime.idxmax(0)
Out[279]:
Population 2014-01-01 Violent 1992-01-01 Property 1991-01-01 Murder 1991-01-01 Forcible_Rape 1992-01-01 Robbery 1991-01-01 Aggravated_assault 1993-01-01 Burglary 1980-01-01 Larceny_Theft 1991-01-01 Vehicle_Theft 1991-01-01 dtype: datetime64[ns]
練習5-合并
探索虛擬姓名資料
步驟1 匯入必要的庫
In [280]:
# 運行以下代碼 import numpy as np import pandas as pd
步驟2 按照如下的元資料內容創建資料框
In [281]:
# 運行以下代碼
raw_data_1 = {
'subject_id': ['1', '2', '3', '4', '5'],
'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']}
raw_data_2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
raw_data_3 = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
步驟3 將上述的資料框分別命名為data1, data2, data3
In [282]:
# 運行以下代碼 data1 = pd.DataFrame(raw_data_1, columns = ['subject_id', 'first_name', 'last_name']) data2 = pd.DataFrame(raw_data_2, columns = ['subject_id', 'first_name', 'last_name']) data3 = pd.DataFrame(raw_data_3, columns = ['subject_id','test_id'])
步驟4 將data1和data2兩個資料框按照行的維度進行合并,命名為all_data
In [283]:
# 運行以下代碼 all_data = pd.concat([data1, data2]) all_data
Out[283]:
| subject_id | first_name | last_name | |
|---|---|---|---|
| 0 | 1 | Alex | Anderson |
| 1 | 2 | Amy | Ackerman |
| 2 | 3 | Allen | Ali |
| 3 | 4 | Alice | Aoni |
| 4 | 5 | Ayoung | Atiches |
| 0 | 4 | Billy | Bonder |
| 1 | 5 | Brian | Black |
| 2 | 6 | Bran | Balwner |
| 3 | 7 | Bryce | Brice |
| 4 | 8 | Betty | Btisan |
步驟5 將data1和data2兩個資料框按照列的維度進行合并,命名為all_data_col
In [284]:
# 運行以下代碼 all_data_col = pd.concat([data1, data2], axis = 1) all_data_col
Out[284]:
| subject_id | first_name | last_name | subject_id | first_name | last_name | |
|---|---|---|---|---|---|---|
| 0 | 1 | Alex | Anderson | 4 | Billy | Bonder |
| 1 | 2 | Amy | Ackerman | 5 | Brian | Black |
| 2 | 3 | Allen | Ali | 6 | Bran | Balwner |
| 3 | 4 | Alice | Aoni | 7 | Bryce | Brice |
| 4 | 5 | Ayoung | Atiches | 8 | Betty | Btisan |
步驟6 列印data3
In [285]:
# 運行以下代碼 data3
Out[285]:
| subject_id | test_id | |
|---|---|---|
| 0 | 1 | 51 |
| 1 | 2 | 15 |
| 2 | 3 | 15 |
| 3 | 4 | 61 |
| 4 | 5 | 16 |
| 5 | 7 | 14 |
| 6 | 8 | 15 |
| 7 | 9 | 1 |
| 8 | 10 | 61 |
| 9 | 11 | 16 |
步驟7 按照subject_id的值對all_data和data3作合并
In [286]:
# 運行以下代碼 pd.merge(all_data, data3, on='subject_id')
Out[286]:
| subject_id | first_name | last_name | test_id | |
|---|---|---|---|---|
| 0 | 1 | Alex | Anderson | 51 |
| 1 | 2 | Amy | Ackerman | 15 |
| 2 | 3 | Allen | Ali | 15 |
| 3 | 4 | Alice | Aoni | 61 |
| 4 | 4 | Billy | Bonder | 61 |
| 5 | 5 | Ayoung | Atiches | 16 |
| 6 | 5 | Brian | Black | 16 |
| 7 | 7 | Bryce | Brice | 14 |
| 8 | 8 | Betty | Btisan | 15 |
步驟8 對data1和data2按照subject_id作連接
In [287]:
# 運行以下代碼 pd.merge(data1, data2, on='subject_id', how='inner')
Out[287]:
| subject_id | first_name_x | last_name_x | first_name_y | last_name_y | |
|---|---|---|---|---|---|
| 0 | 4 | Alice | Aoni | Billy | Bonder |
| 1 | 5 | Ayoung | Atiches | Brian | Black |
步驟9 找到 data1 和 data2 合并之后的所有匹配結果
In [288]:
# 運行以下代碼 pd.merge(data1, data2, on='subject_id', how='outer')
Out[288]:
| subject_id | first_name_x | last_name_x | first_name_y | last_name_y | |
|---|---|---|---|---|---|
| 0 | 1 | Alex | Anderson | NaN | NaN |
| 1 | 2 | Amy | Ackerman | NaN | NaN |
| 2 | 3 | Allen | Ali | NaN | NaN |
| 3 | 4 | Alice | Aoni | Billy | Bonder |
| 4 | 5 | Ayoung | Atiches | Brian | Black |
| 5 | 6 | NaN | NaN | Bran | Balwner |
| 6 | 7 | NaN | NaN | Bryce | Brice |
| 7 | 8 | NaN | NaN | Betty | Btisan |
練習6-統計
探索風速資料

步驟1 匯入必要的庫
In [289]:
# 運行以下代碼 import pandas as pd import datetime
步驟2 從以下地址匯入資料
In [290]:
import pandas as pd
In [35]:
# 運行以下代碼 path6 = "./exercise_data/wind.data" # wind.data
步驟3 將資料作存盤并且設定前三列為合適的索引
In [292]:
import datetime
In [293]:
# 運行以下代碼 data = pd.read_table(path6, sep = "\s+", parse_dates = [[0,1,2]]) data.head()
Out[293]:
| Yr_Mo_Dy | RPT | VAL | ROS | KIL | SHA | BIR | DUB | CLA | MUL | CLO | BEL | MAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2061-01-01 | 15.04 | 14.96 | 13.17 | 9.29 | NaN | 9.87 | 13.67 | 10.25 | 10.83 | 12.58 | 18.50 | 15.04 |
| 1 | 2061-01-02 | 14.71 | NaN | 10.83 | 6.50 | 12.62 | 7.67 | 11.50 | 10.04 | 9.79 | 9.67 | 17.54 | 13.83 |
| 2 | 2061-01-03 | 18.50 | 16.88 | 12.33 | 10.13 | 11.17 | 6.17 | 11.25 | NaN | 8.50 | 7.67 | 12.75 | 12.71 |
| 3 | 2061-01-04 | 10.58 | 6.63 | 11.75 | 4.58 | 4.54 | 2.88 | 8.63 | 1.79 | 5.83 | 5.88 | 5.46 | 10.88 |
| 4 | 2061-01-05 | 13.33 | 13.25 | 11.42 | 6.17 | 10.71 | 8.21 | 11.92 | 6.54 | 10.92 | 10.34 | 12.92 | 11.83 |
步驟4 2061年?我們真的有這一年的資料?創建一個函式并用它去修復這個bug
In [294]:
# 運行以下代碼
def fix_century(x):
year = x.year - 100 if x.year > 1989 else x.year
return datetime.date(year, x.month, x.day)
# apply the function fix_century on the column and replace the values to the right ones
data['Yr_Mo_Dy'] = data['Yr_Mo_Dy'].apply(fix_century)
# data.info()
data.head()
Out[294]:
| Yr_Mo_Dy | RPT | VAL | ROS | KIL | SHA | BIR | DUB | CLA | MUL | CLO | BEL | MAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1961-01-01 | 15.04 | 14.96 | 13.17 | 9.29 | NaN | 9.87 | 13.67 | 10.25 | 10.83 | 12.58 | 18.50 | 15.04 |
| 1 | 1961-01-02 | 14.71 | NaN | 10.83 | 6.50 | 12.62 | 7.67 | 11.50 | 10.04 | 9.79 | 9.67 | 17.54 | 13.83 |
| 2 | 1961-01-03 | 18.50 | 16.88 | 12.33 | 10.13 | 11.17 | 6.17 | 11.25 | NaN | 8.50 | 7.67 | 12.75 | 12.71 |
| 3 | 1961-01-04 | 10.58 | 6.63 | 11.75 | 4.58 | 4.54 | 2.88 | 8.63 | 1.79 | 5.83 | 5.88 | 5.46 | 10.88 |
| 4 | 1961-01-05 | 13.33 | 13.25 | 11.42 | 6.17 | 10.71 | 8.21 | 11.92 | 6.54 | 10.92 | 10.34 | 12.92 | 11.83 |
步驟5 將日期設為索引,注意資料型別,應該是datetime64[ns]
In [295]:
# 運行以下代碼
# transform Yr_Mo_Dy it to date type datetime64
data["Yr_Mo_Dy"] = pd.to_datetime(data["Yr_Mo_Dy"])
# set 'Yr_Mo_Dy' as the index
data = data.set_index('Yr_Mo_Dy')
data.head()
# data.info()
Out[295]:
| RPT | VAL | ROS | KIL | SHA | BIR | DUB | CLA | MUL | CLO | BEL | MAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yr_Mo_Dy | ||||||||||||
| 1961-01-01 | 15.04 | 14.96 | 13.17 | 9.29 | NaN | 9.87 | 13.67 | 10.25 | 10.83 | 12.58 | 18.50 | 15.04 |
| 1961-01-02 | 14.71 | NaN | 10.83 | 6.50 | 12.62 | 7.67 | 11.50 | 10.04 | 9.79 | 9.67 | 17.54 | 13.83 |
| 1961-01-03 | 18.50 | 16.88 | 12.33 | 10.13 | 11.17 | 6.17 | 11.25 | NaN | 8.50 | 7.67 | 12.75 | 12.71 |
| 1961-01-04 | 10.58 | 6.63 | 11.75 | 4.58 | 4.54 | 2.88 | 8.63 | 1.79 | 5.83 | 5.88 | 5.46 | 10.88 |
| 1961-01-05 | 13.33 | 13.25 | 11.42 | 6.17 | 10.71 | 8.21 | 11.92 | 6.54 | 10.92 | 10.34 | 12.92 | 11.83 |
步驟6 對應每一個location,一共有多少資料值缺失
In [296]:
# 運行以下代碼 data.isnull().sum()
Out[296]:
RPT 6 VAL 3 ROS 2 KIL 5 SHA 2 BIR 0 DUB 3 CLA 2 MUL 3 CLO 1 BEL 0 MAL 4 dtype: int64
步驟7 對應每一個location,一共有多少完整的資料值
In [297]:
# 運行以下代碼 data.shape[0] - data.isnull().sum()
Out[297]:
RPT 6568 VAL 6571 ROS 6572 KIL 6569 SHA 6572 BIR 6574 DUB 6571 CLA 6572 MUL 6571 CLO 6573 BEL 6574 MAL 6570 dtype: int64
步驟8 對于全體資料,計算風速的平均值
In [298]:
# 運行以下代碼 data.mean().mean()
Out[298]:
10.227982360836924
步驟9 創建一個名為loc_stats的資料框去計算并存盤每個location的風速最小值,最大值,平均值和標準差
In [299]:
# 運行以下代碼 loc_stats = pd.DataFrame() loc_stats['min'] = data.min() # min loc_stats['max'] = data.max() # max loc_stats['mean'] = data.mean() # mean loc_stats['std'] = data.std() # standard deviations loc_stats
Out[299]:
| min | max | mean | std | |
|---|---|---|---|---|
| RPT | 0.67 | 35.80 | 12.362987 | 5.618413 |
| VAL | 0.21 | 33.37 | 10.644314 | 5.267356 |
| ROS | 1.50 | 33.84 | 11.660526 | 5.008450 |
| KIL | 0.00 | 28.46 | 6.306468 | 3.605811 |
| SHA | 0.13 | 37.54 | 10.455834 | 4.936125 |
| BIR | 0.00 | 26.16 | 7.092254 | 3.968683 |
| DUB | 0.00 | 30.37 | 9.797343 | 4.977555 |
| CLA | 0.00 | 31.08 | 8.495053 | 4.499449 |
| MUL | 0.00 | 25.88 | 8.493590 | 4.166872 |
| CLO | 0.04 | 28.21 | 8.707332 | 4.503954 |
| BEL | 0.13 | 42.38 | 13.121007 | 5.835037 |
| MAL | 0.67 | 42.54 | 15.599079 | 6.699794 |
步驟10 創建一個名為day_stats的資料框去計算并存盤所有location的風速最小值,最大值,平均值和標準差
In [300]:
# 運行以下代碼 # create the dataframe day_stats = pd.DataFrame() # this time we determine axis equals to one so it gets each row. day_stats['min'] = data.min(axis = 1) # min day_stats['max'] = data.max(axis = 1) # max day_stats['mean'] = data.mean(axis = 1) # mean day_stats['std'] = data.std(axis = 1) # standard deviations day_stats.head()
Out[300]:
| min | max | mean | std | |
|---|---|---|---|---|
| Yr_Mo_Dy | ||||
| 1961-01-01 | 9.29 | 18.50 | 13.018182 | 2.808875 |
| 1961-01-02 | 6.50 | 17.54 | 11.336364 | 3.188994 |
| 1961-01-03 | 6.17 | 18.50 | 11.641818 | 3.681912 |
| 1961-01-04 | 1.79 | 11.75 | 6.619167 | 3.198126 |
| 1961-01-05 | 6.17 | 13.33 | 10.630000 | 2.445356 |
步驟11 對于每一個location,計算一月份的平均風速
注意,1961年的1月和1962年的1月應該區別對待
In [301]:
# 運行以下代碼
# creates a new column 'date' and gets the values from the index
data['date'] = data.index
# creates a column for each value from date
data['month'] = data['date'].apply(lambda date: date.month)
data['year'] = data['date'].apply(lambda date: date.year)
data['day'] = data['date'].apply(lambda date: date.day)
# gets all value from the month 1 and assign to janyary_winds
january_winds = data.query('month == 1')
# gets the mean from january_winds, using .loc to not print the mean of month, year and day
january_winds.loc[:,'RPT':"MAL"].mean()
Out[301]:
RPT 14.847325 VAL 12.914560 ROS 13.299624 KIL 7.199498 SHA 11.667734 BIR 8.054839 DUB 11.819355 CLA 9.512047 MUL 9.543208 CLO 10.053566 BEL 14.550520 MAL 18.028763 dtype: float64
步驟12 對于資料記錄按照年為頻率取樣
In [302]:
# 運行以下代碼
data.query('month == 1 and day == 1')
Out[302]:
| RPT | VAL | ROS | KIL | SHA | BIR | DUB | CLA | MUL | CLO | BEL | MAL | date | month | year | day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yr_Mo_Dy | ||||||||||||||||
| 1961-01-01 | 15.04 | 14.96 | 13.17 | 9.29 | NaN | 9.87 | 13.67 | 10.25 | 10.83 | 12.58 | 18.50 | 15.04 | 1961-01-01 | 1 | 1961 | 1 |
| 1962-01-01 | 9.29 | 3.42 | 11.54 | 3.50 | 2.21 | 1.96 | 10.41 | 2.79 | 3.54 | 5.17 | 4.38 | 7.92 | 1962-01-01 | 1 | 1962 | 1 |
| 1963-01-01 | 15.59 | 13.62 | 19.79 | 8.38 | 12.25 | 10.00 | 23.45 | 15.71 | 13.59 | 14.37 | 17.58 | 34.13 | 1963-01-01 | 1 | 1963 | 1 |
| 1964-01-01 | 25.80 | 22.13 | 18.21 | 13.25 | 21.29 | 14.79 | 14.12 | 19.58 | 13.25 | 16.75 | 28.96 | 21.00 | 1964-01-01 | 1 | 1964 | 1 |
| 1965-01-01 | 9.54 | 11.92 | 9.00 | 4.38 | 6.08 | 5.21 | 10.25 | 6.08 | 5.71 | 8.63 | 12.04 | 17.41 | 1965-01-01 | 1 | 1965 | 1 |
| 1966-01-01 | 22.04 | 21.50 | 17.08 | 12.75 | 22.17 | 15.59 | 21.79 | 18.12 | 16.66 | 17.83 | 28.33 | 23.79 | 1966-01-01 | 1 | 1966 | 1 |
| 1967-01-01 | 6.46 | 4.46 | 6.50 | 3.21 | 6.67 | 3.79 | 11.38 | 3.83 | 7.71 | 9.08 | 10.67 | 20.91 | 1967-01-01 | 1 | 1967 | 1 |
| 1968-01-01 | 30.04 | 17.88 | 16.25 | 16.25 | 21.79 | 12.54 | 18.16 | 16.62 | 18.75 | 17.62 | 22.25 | 27.29 | 1968-01-01 | 1 | 1968 | 1 |
| 1969-01-01 | 6.13 | 1.63 | 5.41 | 1.08 | 2.54 | 1.00 | 8.50 | 2.42 | 4.58 | 6.34 | 9.17 | 16.71 | 1969-01-01 | 1 | 1969 | 1 |
| 1970-01-01 | 9.59 | 2.96 | 11.79 | 3.42 | 6.13 | 4.08 | 9.00 | 4.46 | 7.29 | 3.50 | 7.33 | 13.00 | 1970-01-01 | 1 | 1970 | 1 |
| 1971-01-01 | 3.71 | 0.79 | 4.71 | 0.17 | 1.42 | 1.04 | 4.63 | 0.75 | 1.54 | 1.08 | 4.21 | 9.54 | 1971-01-01 | 1 | 1971 | 1 |
| 1972-01-01 | 9.29 | 3.63 | 14.54 | 4.25 | 6.75 | 4.42 | 13.00 | 5.33 | 10.04 | 8.54 | 8.71 | 19.17 | 1972-01-01 | 1 | 1972 | 1 |
| 1973-01-01 | 16.50 | 15.92 | 14.62 | 7.41 | 8.29 | 11.21 | 13.54 | 7.79 | 10.46 | 10.79 | 13.37 | 9.71 | 1973-01-01 | 1 | 1973 | 1 |
| 1974-01-01 | 23.21 | 16.54 | 16.08 | 9.75 | 15.83 | 11.46 | 9.54 | 13.54 | 13.83 | 16.66 | 17.21 | 25.29 | 1974-01-01 | 1 | 1974 | 1 |
| 1975-01-01 | 14.04 | 13.54 | 11.29 | 5.46 | 12.58 | 5.58 | 8.12 | 8.96 | 9.29 | 5.17 | 7.71 | 11.63 | 1975-01-01 | 1 | 1975 | 1 |
| 1976-01-01 | 18.34 | 17.67 | 14.83 | 8.00 | 16.62 | 10.13 | 13.17 | 9.04 | 13.13 | 5.75 | 11.38 | 14.96 | 1976-01-01 | 1 | 1976 | 1 |
| 1977-01-01 | 20.04 | 11.92 | 20.25 | 9.13 | 9.29 | 8.04 | 10.75 | 5.88 | 9.00 | 9.00 | 14.88 | 25.70 | 1977-01-01 | 1 | 1977 | 1 |
| 1978-01-01 | 8.33 | 7.12 | 7.71 | 3.54 | 8.50 | 7.50 | 14.71 | 10.00 | 11.83 | 10.00 | 15.09 | 20.46 | 1978-01-01 | 1 | 1978 | 1 |
步驟13 對于資料記錄按照月為頻率取樣
In [303]:
# 運行以下代碼
data.query('day == 1')
Out[303]:
| RPT | VAL | ROS | KIL | SHA | BIR | DUB | CLA | MUL | CLO | BEL | MAL | date | month | year | day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yr_Mo_Dy | ||||||||||||||||
| 1961-01-01 | 15.04 | 14.96 | 13.17 | 9.29 | NaN | 9.87 | 13.67 | 10.25 | 10.83 | 12.58 | 18.50 | 15.04 | 1961-01-01 | 1 | 1961 | 1 |
| 1961-02-01 | 14.25 | 15.12 | 9.04 | 5.88 | 12.08 | 7.17 | 10.17 | 3.63 | 6.50 | 5.50 | 9.17 | 8.00 | 1961-02-01 | 2 | 1961 | 1 |
| 1961-03-01 | 12.67 | 13.13 | 11.79 | 6.42 | 9.79 | 8.54 | 10.25 | 13.29 | NaN | 12.21 | 20.62 | NaN | 1961-03-01 | 3 | 1961 | 1 |
| 1961-04-01 | 8.38 | 6.34 | 8.33 | 6.75 | 9.33 | 9.54 | 11.67 | 8.21 | 11.21 | 6.46 | 11.96 | 7.17 | 1961-04-01 | 4 | 1961 | 1 |
| 1961-05-01 | 15.87 | 13.88 | 15.37 | 9.79 | 13.46 | 10.17 | 9.96 | 14.04 | 9.75 | 9.92 | 18.63 | 11.12 | 1961-05-01 | 5 | 1961 | 1 |
| 1961-06-01 | 15.92 | 9.59 | 12.04 | 8.79 | 11.54 | 6.04 | 9.75 | 8.29 | 9.33 | 10.34 | 10.67 | 12.12 | 1961-06-01 | 6 | 1961 | 1 |
| 1961-07-01 | 7.21 | 6.83 | 7.71 | 4.42 | 8.46 | 4.79 | 6.71 | 6.00 | 5.79 | 7.96 | 6.96 | 8.71 | 1961-07-01 | 7 | 1961 | 1 |
| 1961-08-01 | 9.59 | 5.09 | 5.54 | 4.63 | 8.29 | 5.25 | 4.21 | 5.25 | 5.37 | 5.41 | 8.38 | 9.08 | 1961-08-01 | 8 | 1961 | 1 |
| 1961-09-01 | 5.58 | 1.13 | 4.96 | 3.04 | 4.25 | 2.25 | 4.63 | 2.71 | 3.67 | 6.00 | 4.79 | 5.41 | 1961-09-01 | 9 | 1961 | 1 |
| 1961-10-01 | 14.25 | 12.87 | 7.87 | 8.00 | 13.00 | 7.75 | 5.83 | 9.00 | 7.08 | 5.29 | 11.79 | 4.04 | 1961-10-01 | 10 | 1961 | 1 |
| 1961-11-01 | 13.21 | 13.13 | 14.33 | 8.54 | 12.17 | 10.21 | 13.08 | 12.17 | 10.92 | 13.54 | 20.17 | 20.04 | 1961-11-01 | 11 | 1961 | 1 |
| 1961-12-01 | 9.67 | 7.75 | 8.00 | 3.96 | 6.00 | 2.75 | 7.25 | 2.50 | 5.58 | 5.58 | 7.79 | 11.17 | 1961-12-01 | 12 | 1961 | 1 |
| 1962-01-01 | 9.29 | 3.42 | 11.54 | 3.50 | 2.21 | 1.96 | 10.41 | 2.79 | 3.54 | 5.17 | 4.38 | 7.92 | 1962-01-01 | 1 | 1962 | 1 |
| 1962-02-01 | 19.12 | 13.96 | 12.21 | 10.58 | 15.71 | 10.63 | 15.71 | 11.08 | 13.17 | 12.62 | 17.67 | 22.71 | 1962-02-01 | 2 | 1962 | 1 |
| 1962-03-01 | 8.21 | 4.83 | 9.00 | 4.83 | 6.00 | 2.21 | 7.96 | 1.87 | 4.08 | 3.92 | 4.08 | 5.41 | 1962-03-01 | 3 | 1962 | 1 |
| 1962-04-01 | 14.33 | 12.25 | 11.87 | 10.37 | 14.92 | 11.00 | 19.79 | 11.67 | 14.09 | 15.46 | 16.62 | 23.58 | 1962-04-01 | 4 | 1962 | 1 |
| 1962-05-01 | 9.62 | 9.54 | 3.58 | 3.33 | 8.75 | 3.75 | 2.25 | 2.58 | 1.67 | 2.37 | 7.29 | 3.25 | 1962-05-01 | 5 | 1962 | 1 |
| 1962-06-01 | 5.88 | 6.29 | 8.67 | 5.21 | 5.00 | 4.25 | 5.91 | 5.41 | 4.79 | 9.25 | 5.25 | 10.71 | 1962-06-01 | 6 | 1962 | 1 |
| 1962-07-01 | 8.67 | 4.17 | 6.92 | 6.71 | 8.17 | 5.66 | 11.17 | 9.38 | 8.75 | 11.12 | 10.25 | 17.08 | 1962-07-01 | 7 | 1962 | 1 |
| 1962-08-01 | 4.58 | 5.37 | 6.04 | 2.29 | 7.87 | 3.71 | 4.46 | 2.58 | 4.00 | 4.79 | 7.21 | 7.46 | 1962-08-01 | 8 | 1962 | 1 |
| 1962-09-01 | 10.00 | 12.08 | 10.96 | 9.25 | 9.29 | 7.62 | 7.41 | 8.75 | 7.67 | 9.62 | 14.58 | 11.92 | 1962-09-01 | 9 | 1962 | 1 |
| 1962-10-01 | 14.58 | 7.83 | 19.21 | 10.08 | 11.54 | 8.38 | 13.29 | 10.63 | 8.21 | 12.92 | 18.05 | 18.12 | 1962-10-01 | 10 | 1962 | 1 |
| 1962-11-01 | 16.88 | 13.25 | 16.00 | 8.96 | 13.46 | 11.46 | 10.46 | 10.17 | 10.37 | 13.21 | 14.83 | 15.16 | 1962-11-01 | 11 | 1962 | 1 |
| 1962-12-01 | 18.38 | 15.41 | 11.75 | 6.79 | 12.21 | 8.04 | 8.42 | 10.83 | 5.66 | 9.08 | 11.50 | 11.50 | 1962-12-01 | 12 | 1962 | 1 |
| 1963-01-01 | 15.59 | 13.62 | 19.79 | 8.38 | 12.25 | 10.00 | 23.45 | 15.71 | 13.59 | 14.37 | 17.58 | 34.13 | 1963-01-01 | 1 | 1963 | 1 |
| 1963-02-01 | 15.41 | 7.62 | 24.67 | 11.42 | 9.21 | 8.17 | 14.04 | 7.54 | 7.54 | 10.08 | 10.17 | 17.67 | 1963-02-01 | 2 | 1963 | 1 |
| 1963-03-01 | 16.75 | 19.67 | 17.67 | 8.87 | 19.08 | 15.37 | 16.21 | 14.29 | 11.29 | 9.21 | 19.92 | 19.79 | 1963-03-01 | 3 | 1963 | 1 |
| 1963-04-01 | 10.54 | 9.59 | 12.46 | 7.33 | 9.46 | 9.59 | 11.79 | 11.87 | 9.79 | 10.71 | 13.37 | 18.21 | 1963-04-01 | 4 | 1963 | 1 |
| 1963-05-01 | 18.79 | 14.17 | 13.59 | 11.63 | 14.17 | 11.96 | 14.46 | 12.46 | 12.87 | 13.96 | 15.29 | 21.62 | 1963-05-01 | 5 | 1963 | 1 |
| 1963-06-01 | 13.37 | 6.87 | 12.00 | 8.50 | 10.04 | 9.42 | 10.92 | 12.96 | 11.79 | 11.04 | 10.92 | 13.67 | 1963-06-01 | 6 | 1963 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1976-07-01 | 8.50 | 1.75 | 6.58 | 2.13 | 2.75 | 2.21 | 5.37 | 2.04 | 5.88 | 4.50 | 4.96 | 10.63 | 1976-07-01 | 7 | 1976 | 1 |
| 1976-08-01 | 13.00 | 8.38 | 8.63 | 5.83 | 12.92 | 8.25 | 13.00 | 9.42 | 10.58 | 11.34 | 14.21 | 20.25 | 1976-08-01 | 8 | 1976 | 1 |
| 1976-09-01 | 11.87 | 11.00 | 7.38 | 6.87 | 7.75 | 8.33 | 10.34 | 6.46 | 10.17 | 9.29 | 12.75 | 19.55 | 1976-09-01 | 9 | 1976 | 1 |
| 1976-10-01 | 10.96 | 6.71 | 10.41 | 4.63 | 7.58 | 5.04 | 5.04 | 5.54 | 6.50 | 3.92 | 6.79 | 5.00 | 1976-10-01 | 10 | 1976 | 1 |
| 1976-11-01 | 13.96 | 15.67 | 10.29 | 6.46 | 12.79 | 9.08 | 10.00 | 9.67 | 10.21 | 11.63 | 23.09 | 21.96 | 1976-11-01 | 11 | 1976 | 1 |
| 1976-12-01 | 13.46 | 16.42 | 9.21 | 4.54 | 10.75 | 8.67 | 10.88 | 4.83 | 8.79 | 5.91 | 8.83 | 13.67 | 1976-12-01 | 12 | 1976 | 1 |
| 1977-01-01 | 20.04 | 11.92 | 20.25 | 9.13 | 9.29 | 8.04 | 10.75 | 5.88 | 9.00 | 9.00 | 14.88 | 25.70 | 1977-01-01 | 1 | 1977 | 1 |
| 1977-02-01 | 11.83 | 9.71 | 11.00 | 4.25 | 8.58 | 8.71 | 6.17 | 5.66 | 8.29 | 7.58 | 11.71 | 16.50 | 1977-02-01 | 2 | 1977 | 1 |
| 1977-03-01 | 8.63 | 14.83 | 10.29 | 3.75 | 6.63 | 8.79 | 5.00 | 8.12 | 7.87 | 6.42 | 13.54 | 13.67 | 1977-03-01 | 3 | 1977 | 1 |
| 1977-04-01 | 21.67 | 16.00 | 17.33 | 13.59 | 20.83 | 15.96 | 25.62 | 17.62 | 19.41 | 20.67 | 24.37 | 30.09 | 1977-04-01 | 4 | 1977 | 1 |
| 1977-05-01 | 6.42 | 7.12 | 8.67 | 3.58 | 4.58 | 4.00 | 6.75 | 6.13 | 3.33 | 4.50 | 19.21 | 12.38 | 1977-05-01 | 5 | 1977 | 1 |
| 1977-06-01 | 7.08 | 5.25 | 9.71 | 2.83 | 2.21 | 3.50 | 5.29 | 1.42 | 2.00 | 0.92 | 5.21 | 5.63 | 1977-06-01 | 6 | 1977 | 1 |
| 1977-07-01 | 15.41 | 16.29 | 17.08 | 6.25 | 11.83 | 11.83 | 12.29 | 10.58 | 10.41 | 7.21 | 17.37 | 7.83 | 1977-07-01 | 7 | 1977 | 1 |
| 1977-08-01 | 4.33 | 2.96 | 4.42 | 2.33 | 0.96 | 1.08 | 4.96 | 1.87 | 2.33 | 2.04 | 10.50 | 9.83 | 1977-08-01 | 8 | 1977 | 1 |
| 1977-09-01 | 17.37 | 16.33 | 16.83 | 8.58 | 14.46 | 11.83 | 15.09 | 13.92 | 13.29 | 13.88 | 23.29 | 25.17 | 1977-09-01 | 9 | 1977 | 1 |
| 1977-10-01 | 16.75 | 15.34 | 12.25 | 9.42 | 16.38 | 11.38 | 18.50 | 13.92 | 14.09 | 14.46 | 22.34 | 29.67 | 1977-10-01 | 10 | 1977 | 1 |
| 1977-11-01 | 16.71 | 11.54 | 12.17 | 4.17 | 8.54 | 7.17 | 11.12 | 6.46 | 8.25 | 6.21 | 11.04 | 15.63 | 1977-11-01 | 11 | 1977 | 1 |
| 1977-12-01 | 13.37 | 10.92 | 12.42 | 2.37 | 5.79 | 6.13 | 8.96 | 7.38 | 6.29 | 5.71 | 8.54 | 12.42 | 1977-12-01 | 12 | 1977 | 1 |
| 1978-01-01 | 8.33 | 7.12 | 7.71 | 3.54 | 8.50 | 7.50 | 14.71 | 10.00 | 11.83 | 10.00 | 15.09 | 20.46 | 1978-01-01 | 1 | 1978 | 1 |
| 1978-02-01 | 27.25 | 24.21 | 18.16 | 17.46 | 27.54 | 18.05 | 20.96 | 25.04 | 20.04 | 17.50 | 27.71 | 21.12 | 1978-02-01 | 2 | 1978 | 1 |
| 1978-03-01 | 15.04 | 6.21 | 16.04 | 7.87 | 6.42 | 6.67 | 12.29 | 8.00 | 10.58 | 9.33 | 5.41 | 17.00 | 1978-03-01 | 3 | 1978 | 1 |
| 1978-04-01 | 3.42 | 7.58 | 2.71 | 1.38 | 3.46 | 2.08 | 2.67 | 4.75 | 4.83 | 1.67 | 7.33 | 13.67 | 1978-04-01 | 4 | 1978 | 1 |
| 1978-05-01 | 10.54 | 12.21 | 9.08 | 5.29 | 11.00 | 10.08 | 11.17 | 13.75 | 11.87 | 11.79 | 12.87 | 27.16 | 1978-05-01 | 5 | 1978 | 1 |
| 1978-06-01 | 10.37 | 11.42 | 6.46 | 6.04 | 11.25 | 7.50 | 6.46 | 5.96 | 7.79 | 5.46 | 5.50 | 10.41 | 1978-06-01 | 6 | 1978 | 1 |
| 1978-07-01 | 12.46 | 10.63 | 11.17 | 6.75 | 12.92 | 9.04 | 12.42 | 9.62 | 12.08 | 8.04 | 14.04 | 16.17 | 1978-07-01 | 7 | 1978 | 1 |
| 1978-08-01 | 19.33 | 15.09 | 20.17 | 8.83 | 12.62 | 10.41 | 9.33 | 12.33 | 9.50 | 9.92 | 15.75 | 18.00 | 1978-08-01 | 8 | 1978 | 1 |
| 1978-09-01 | 8.42 | 6.13 | 9.87 | 5.25 | 3.21 | 5.71 | 7.25 | 3.50 | 7.33 | 6.50 | 7.62 | 15.96 | 1978-09-01 | 9 | 1978 | 1 |
| 1978-10-01 | 9.50 | 6.83 | 10.50 | 3.88 | 6.13 | 4.58 | 4.21 | 6.50 | 6.38 | 6.54 | 10.63 | 14.09 | 1978-10-01 | 10 | 1978 | 1 |
| 1978-11-01 | 13.59 | 16.75 | 11.25 | 7.08 | 11.04 | 8.33 | 8.17 | 11.29 | 10.75 | 11.25 | 23.13 | 25.00 | 1978-11-01 | 11 | 1978 | 1 |
| 1978-12-01 | 21.29 | 16.29 | 24.04 | 12.79 | 18.21 | 19.29 | 21.54 | 17.21 | 16.71 | 17.83 | 17.75 | 25.70 | 1978-12-01 | 12 | 1978 | 1 |
216 rows × 16 columns
練習7-可視化
探索泰坦尼克災難資料
步驟1 匯入必要的庫
In [304]:
# 運行以下代碼 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np %matplotlib inline
步驟2 從以下地址匯入資料
In [36]:
# 運行以下代碼 path7 = '../input/pandas_exercise/pandas_exercise/exercise_data/train.csv' # train.csv
步驟3 將資料框命名為titanic
In [306]:
# 運行以下代碼 titanic = pd.read_csv(path7) titanic.head()
Out[306]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
步驟4 將PassengerId設定為索引
In [307]:
# 運行以下代碼
titanic.set_index('PassengerId').head()
Out[307]:
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
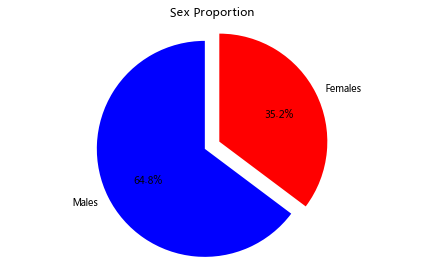
步驟5 繪制一個展示男女乘客比例的扇形圖
In [308]:
# 運行以下代碼
# sum the instances of males and females
males = (titanic['Sex'] == 'male').sum()
females = (titanic['Sex'] == 'female').sum()
# put them into a list called proportions
proportions = [males, females]
# Create a pie chart
plt.pie(
# using proportions
proportions,
# with the labels being officer names
labels = ['Males', 'Females'],
# with no shadows
shadow = False,
# with colors
colors = ['blue','red'],
# with one slide exploded out
explode = (0.15 , 0),
# with the start angle at 90%
startangle = 90,
# with the percent listed as a fraction
autopct = '%1.1f%%'
)
# View the plot drop above
plt.axis('equal')
# Set labels
plt.title("Sex Proportion")
# View the plot
plt.tight_layout()
plt.show()
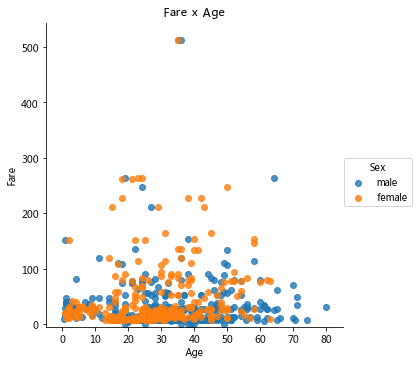
步驟6 繪制一個展示船票Fare, 與乘客年齡和性別的散點圖
In [309]:
# 運行以下代碼 # creates the plot using lm = sns.lmplot(x = 'Age', y = 'Fare', data = titanic, hue = 'Sex', fit_reg=False) # set title lm.set(title = 'Fare x Age') # get the axes object and tweak it axes = lm.axes axes[0,0].set_ylim(-5,) axes[0,0].set_xlim(-5,85)
Out[309]:
(-5, 85)
步驟7 有多少人生還?
In [310]:
# 運行以下代碼 titanic.Survived.sum()
Out[310]:
342
步驟8 繪制一個展示船票價格的直方圖
In [311]:
# 運行以下代碼
# sort the values from the top to the least value and slice the first 5 items
df = titanic.Fare.sort_values(ascending = False)
df
# create bins interval using numpy
binsVal = np.arange(0,600,10)
binsVal
# create the plot
plt.hist(df, bins = binsVal)
# Set the title and labels
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.title('Fare Payed Histrogram')
# show the plot
plt.show()
行業資料:添加即可領取PPT模板、簡歷模板、行業經典書籍PDF,
面試題庫:歷年經典,熱乎的大廠面試真題,持續更新中,添加獲取,
學習資料:含Python、爬蟲、資料分析、演算法等學習視頻和檔案,添加獲取
交流加群:大佬指點迷津,你的問題往往有人遇到過,技識訓助交流,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/300248.html
標籤:python