代碼操作展示:
開發環境:
windows10
python3.6
開發工具:
pycharm
chromedriver
庫:
selenium、os、csv
很多人學習python,不知道從何學起, 很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手, 很多已經做案例的人,卻不知道如何去學習更加高深的知識, 那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼! QQ群:701698587 歡迎加入,一起討論 一起學習!
代碼全解

安裝插件
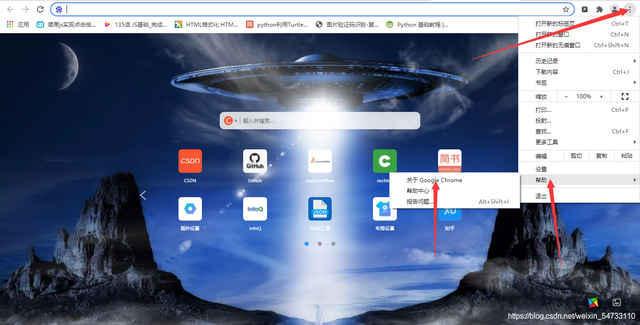
首先要安裝webdriver插件,本文以谷歌瀏覽器為例,點開谷歌瀏覽器,點擊右上角三個點,然后點擊幫助,然后點擊關于Google Chrome,查看瀏覽器的版本,然后點擊網址
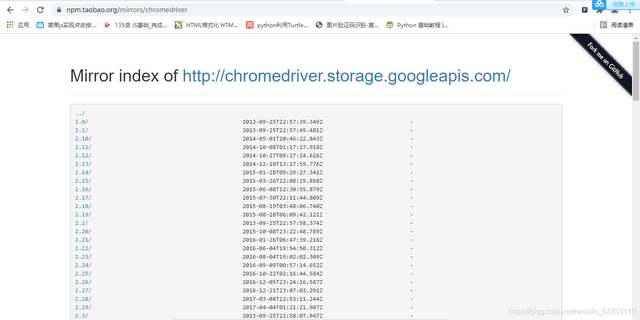
http://npm.taobao.org/mirrors/chromedriver
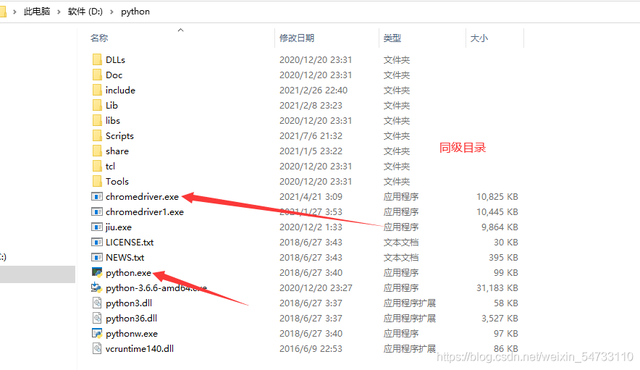
尋找自己瀏覽器對應的版本進行下載,下載之后將chromedriver.exe的檔案最好放在你python解釋器的同級目錄下
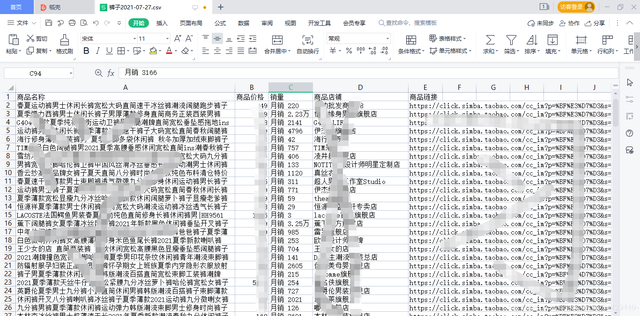
本文采用自動化獲取商品資訊
start_url = 'https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&keyword=&clk1=b563659abe93a96a4e4c136b8d38b209&upsId=b563659abe93a96a4e4c136b8d38b209&spm=a2e0b.20350158.31919782.1&pnum=0’
1.打開網址是這樣的
2.在搜索框中輸入要搜索的商品名稱,并點擊搜索
self.driver.find_element_by_id('J_search_key').send_keys(self.keyword) self.driver.find_element_by_class_name('submit').click()
3.跳轉網頁之后,進行滑鼠自動化滾輪操作
for i in range(1, 11): js = r'scrollTo(0, {})'.format(600 * i) self.driver.execute_script(js) time.sleep(1)
4.決議得到商品資料
li_list = self.driver.find_elements_by_xpath('//div[@]/ul') for li in li_list: name = li.find_elements_by_xpath(r'//li[@]/a/div[' r'@]/span') price = li.find_elements_by_xpath(r'//li[@]/a/div[' r'@]/span[2]') xiaoliang = li.find_elements_by_xpath(r'li[@]/a/div[' r'@]/div[2]') vendor = li.find_elements_by_xpath(r'//*[@id="mx_5"]/ul/li/a/div[3]/div') link = li.find_elements_by_xpath(r'//li[@]/a')
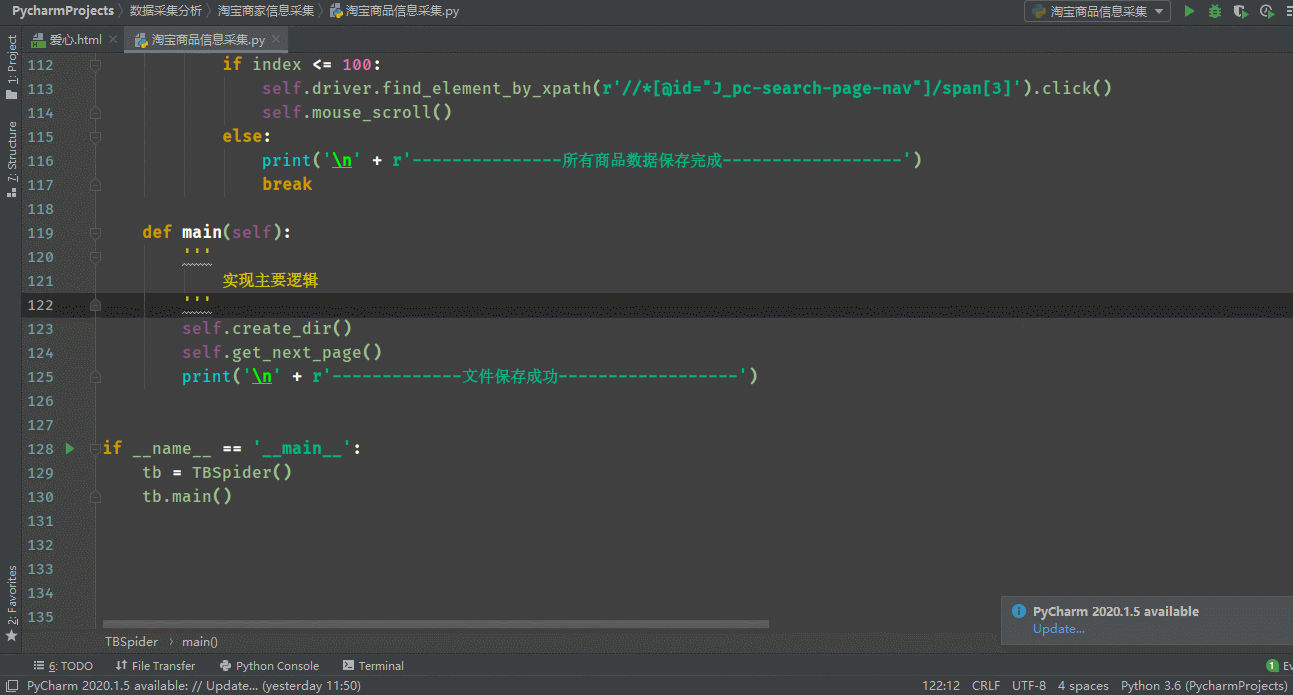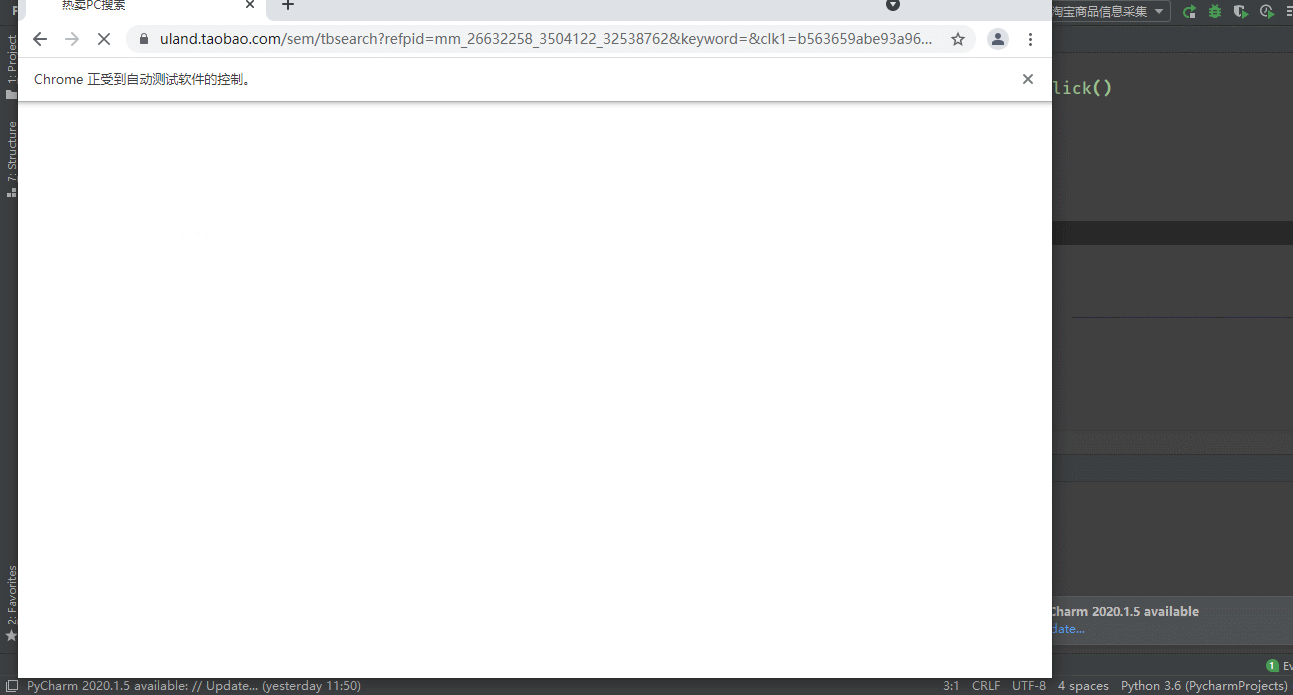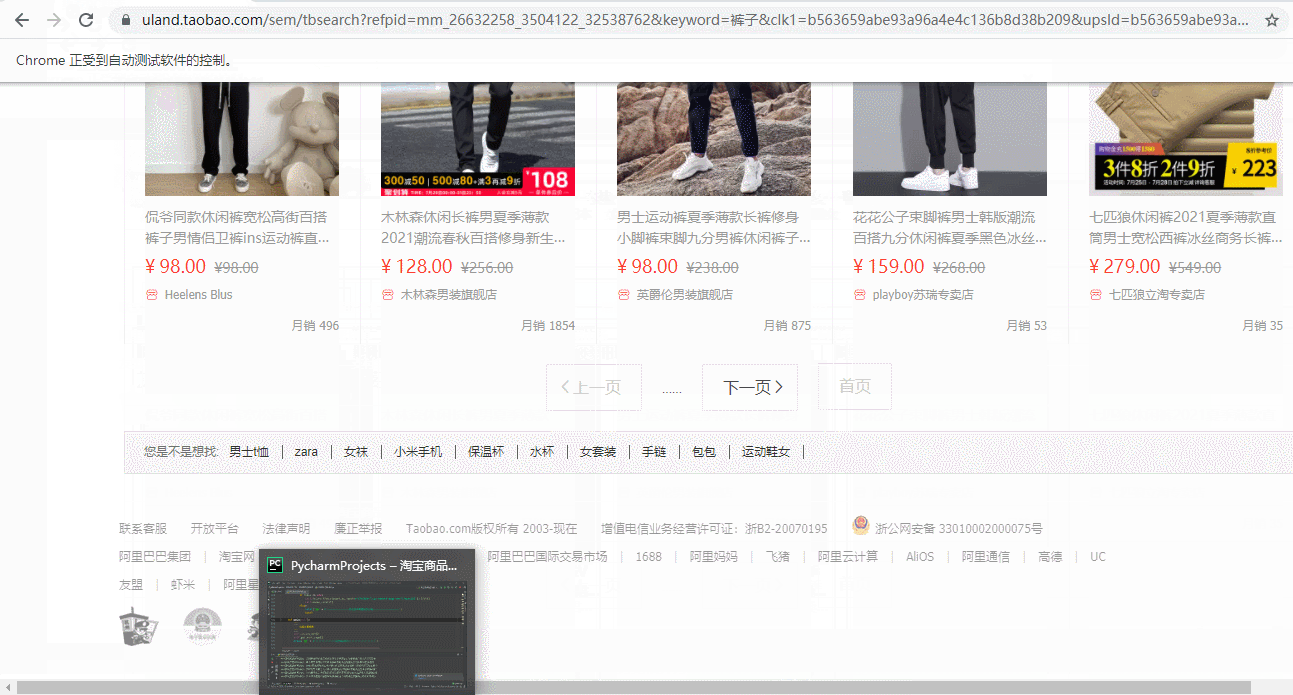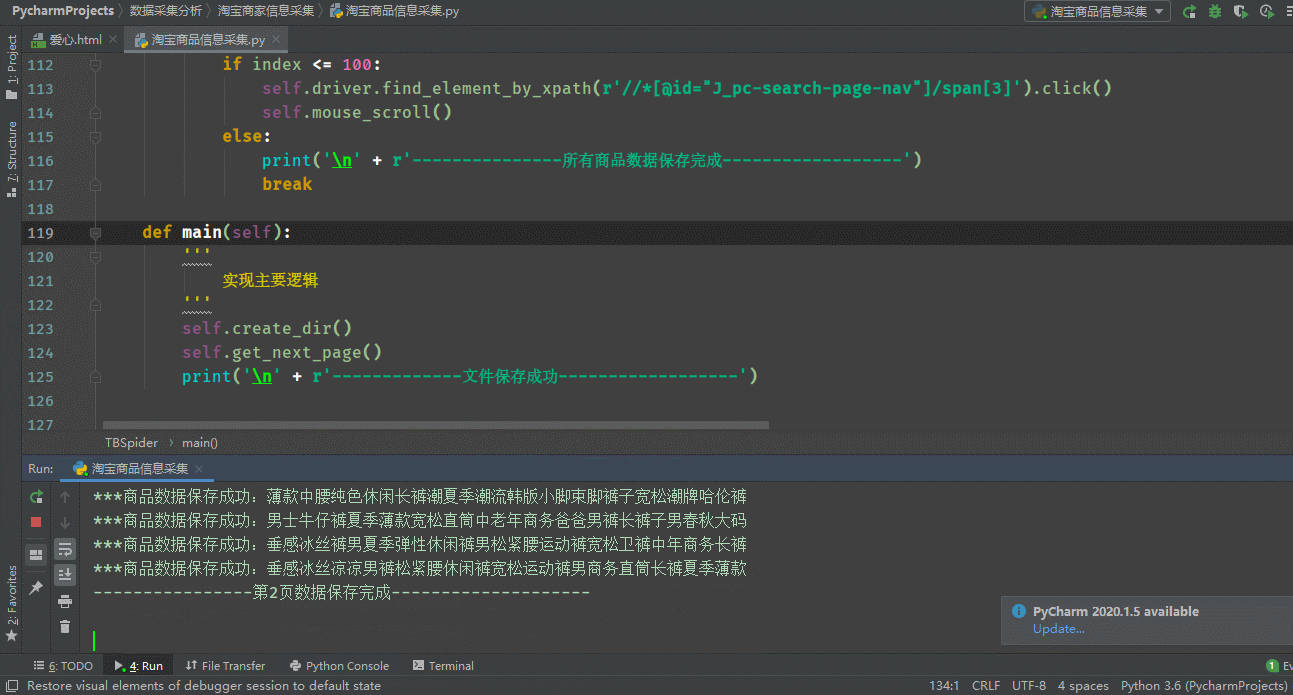
5.保存資料
with open(r'./{}/{}.csv'.format('商品資訊資料', self.file_name), 'a+', newline='', encoding='gbk') as file_csv: csv_writer = csv.writer(file_csv, delimiter=',') csv_writer.writerow([name, price, xiaoliang, vendor, link]) print(r'***商品資料保存成功:{}'.format(name))
6.定位翻頁,翻頁之后進行滾輪操作
self.driver.find_element_by_xpath(r'//*[@id="J_pc-search-page-nav"]/span[3]').click() self.mouse_scroll()
7.實作主要邏輯
self.create_dir()
self.get_next_page()
原始碼展示:
# !/usr/bin/nev python # -*-coding:utf8-*- import time, os, csv, datetime from selenium import webdriver class TBSpider(object): def __init__(self): self.count = 1 self.keyword = input(r'請輸入要查詢的淘寶商品資訊名稱:') self.file_name = self.keyword + datetime.datetime.now().strftime('%Y-%m-%d') self.driver = webdriver.Chrome(executable_path=r'chromedriver.exe的路徑') def create_dir(self): ''' 創建檔案夾 ''' if not os.path.exists(r'./{}'.format('商品資訊資料')): os.mkdir(r'./{}'.format('商品資訊資料')) self.write_header() def write_header(self): ''' 寫入csv頭部資訊 ''' if not os.path.exists(r'./{}.csv'.format(r'***商品資料保存成功:{}'.format(self.keyword))): csv_header = ['商品名稱', '商品價格', '銷量', '商品店鋪', '商品鏈接'] with open(r'./{}/{}.csv'.format('商品資訊資料', self.file_name), 'w', newline='', encoding='gbk') as file_csv: csv_writer_header = csv.DictWriter(file_csv, csv_header) csv_writer_header.writeheader() self.request_start_url() def request_start_url(self): ''' 請求起始url ''' self.driver.get('https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&keyword=&clk1=b563659abe93a96a4e4c136b8d38b209&upsId=b563659abe93a96a4e4c136b8d38b209&spm=a2e0b.20350158.31919782.1&pnum=0') self.driver.maximize_window() self.driver.implicitly_wait(10) self.search_goods() def search_goods(self): ''' 輸入商品關鍵字 ''' print('\n' + r'----------------正在搜索商品資訊:{}--------------------'.format(self.keyword) + '\n') self.driver.find_element_by_id('J_search_key').send_keys(self.keyword) self.driver.find_element_by_class_name('submit').click() time.sleep(3) self.mouse_scroll() def mouse_scroll(self): ''' 滑鼠滑輪滾動,實作懶加載程序 ''' print(r'----------------正在請求第{}頁資料--------------------'.format(self.count) + '\n') for i in range(1, 11): js = r'scrollTo(0, {})'.format(600 * i) # js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %s' % (i / 20) self.driver.execute_script(js) time.sleep(1) self.get_goods_info() def get_goods_info(self): ''' 決議得到商品資訊欄位 ''' li_list = self.driver.find_elements_by_xpath('//div[@]/ul') for li in li_list: name = li.find_elements_by_xpath(r'//li[@]/a/div[' r'@]/span') price = li.find_elements_by_xpath(r'//li[@]/a/div[' r'@]/span[2]') xiaoliang = li.find_elements_by_xpath(r'li[@]/a/div[' r'@]/div[2]') vendor = li.find_elements_by_xpath(r'//*[@id="mx_5"]/ul/li/a/div[3]/div') link = li.find_elements_by_xpath(r'//li[@]/a') for a, b, c, d, e in zip(name, price, xiaoliang, vendor, link): f = a.text g = b.text h = c.text i = d.text.replace('', '') j = e.get_attribute('href') self.save_data(f, g, h, i, j) def save_data(self, name, price, xiaoliang, vendor, link): ''' 寫入csv檔案主體資訊 ''' try: with open(r'./{}/{}.csv'.format('商品資訊資料', self.file_name), 'a+', newline='', encoding='gbk') as file_csv: csv_writer = csv.writer(file_csv, delimiter=',') csv_writer.writerow([name, price, xiaoliang, vendor, link]) print(r'***商品資料保存成功:{}'.format(name)) except Exception as e: pass def get_next_page(self): ''' 實作回圈請求 ''' time.sleep(4) for index in range(2, 101): print(r'----------------第{}頁資料保存完成--------------------'.format(self.count) + '\n') time.sleep(4) self.count += 1 if index <= 100: self.driver.find_element_by_xpath(r'//*[@id="J_pc-search-page-nav"]/span[3]').click() self.mouse_scroll() else: print('\n' + r'---------------所有商品資料保存完成------------------') break def main(self): ''' 實作主要邏輯 ''' self.create_dir() self.get_next_page() print('\n' + r'-------------檔案保存成功------------------') if __name__ == '__main__': tb = TBSpider() tb.main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/300658.html
標籤:其他
上一篇:將百度萬年歷存入自己的資料庫