在銀行日常作業中經常會碰到非標準格式的貸款合同、非標保函等等法律性檔案,這些檔案需要提交法務部門審核后才能使用,對比兩個檔案異同的這種小作業,如果人工來做是比較耗時耗力的,但使用點小代碼就能省不少力,還不會出錯,反正不管什么單位,要對比檔案就交給python來做:
difflib 模塊
>>> import difflib
>>> [_ for _ in dir(difflib) if _[0]<'Z' or _[0]>'a']
['Differ', 'HtmlDiff', 'IS_CHARACTER_JUNK', 'IS_LINE_JUNK',
'Match', 'SequenceMatcher', 'context_diff', 'diff_bytes',
'get_close_matches', 'ndiff', 'restore', 'unified_diff']
>>> docx 模塊
>>> import docx
>>> [_ for _ in dir(docx) if _[0]<'Z' or _[0]>'a']
['Document', 'ImagePart', 'RT', 'blkcntnr', 'compat', 'dml',
'document', 'enum', 'exceptions', 'image', 'opc', 'oxml',
'package', 'parts', 'section', 'settings', 'shape',
'shared', 'styles', 'text']
>>> 部分函式的使用簡介如下:
文本對比 difflib.Differ
>>> text1 = '''Python 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
https://blog.csdn.net/boysoft2002/article/details/120257133
Python 不自己試試,還真猜不出遞回函式的時間復雜度!
https://blog.csdn.net/boysoft2002/article/details/120242318
'''
>>> text2 = '''PYTHON 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
https://blog.CSDN.net/boysoft2002/article/details/120257133
Python 真猜不出遞回函式的時間復雜度!
https://blog.csdn.net/boysoft2002/article/details/120242318///
'''
>>> a = text1.splitlines(keepends=True)
>>> b = text2.splitlines(keepends=True)
>>> c = difflib.Differ()
>>> print(''.join(list(c.compare(a,b))))
- Python 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
? ^^^^^
+ PYTHON 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
? ^^^^^
- https://blog.csdn.net/boysoft2002/article/details/120257133
? ^^^^
+ https://blog.CSDN.net/boysoft2002/article/details/120257133
? ^^^^
- Python 不自己試試,還真猜不出遞回函式的時間復雜度!
? -------
+ Python 真猜不出遞回函式的時間復雜度!
- https://blog.csdn.net/boysoft2002/article/details/120242318
+ https://blog.csdn.net/boysoft2002/article/details/120242318///
? +++
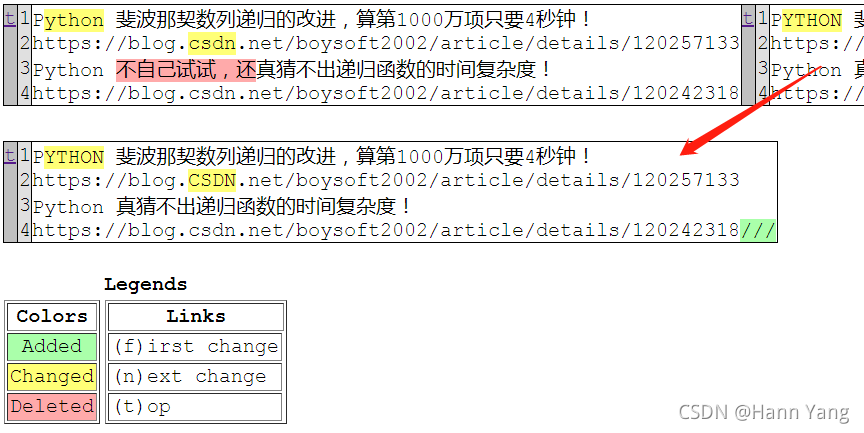
>>> 符號含義說明
“-” 包含在第一個序列行中,但不包含在第二個序列行中
“+” 包含在第二個序列行中,但不包含在第一個序列行中
" " 兩個序列行一致
“?” 標志兩個序列行存在增量差異
“^” 標志出兩個序列行存在的差異字符
超文本對比報告 difflib.HtmlDiff
>>> text1 = '''Python 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
https://blog.csdn.net/boysoft2002/article/details/120257133
Python 不自己試試,還真猜不出遞回函式的時間復雜度!
https://blog.csdn.net/boysoft2002/article/details/120242318
'''
>>> text2 = '''PYTHON 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
https://blog.CSDN.net/boysoft2002/article/details/120257133
Python 真猜不出遞回函式的時間復雜度!
https://blog.csdn.net/boysoft2002/article/details/120242318///
'''
>>> a = text1.splitlines(keepends=True)
>>> b = text2.splitlines(keepends=True)
>>> d = difflib.HtmlDiff()
>>> html = d.make_file(a,b)
>>> with open('difReport.html','w',encoding='utf-8') as f: f.write(html)
3223
>>> import os; os.startfile('difReport.html')
>>> 打開的html檔案效果:
檔案對比相似度 difflib.SequenceMatcher
>>> a = '''Python 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
https://blog.csdn.net/boysoft2002/article/details/120257133
Python 不自己試試,還真猜不出遞回函式的時間復雜度!
https://blog.csdn.net/boysoft2002/article/details/120242318
'''
>>> b = '''PYTHON 斐波那契數列遞回的改進,算第1000萬項只要4秒鐘!
https://blog.CSDN.net/boysoft2002/article/details/120257133
Python 真猜不出遞回函式的時間復雜度!
https://blog.csdn.net/boysoft2002/article/details/120242318///
'''
>>> import difflib
>>> difflib.SequenceMatcher(None,a,b).ratio()*100
92.3076923076923
>>> Word檔案轉文本 docx.Document
def doc2txt(docxFile):
x,doc='',docx.Document(docxFile)
try:
for i in doc.paragraphs:x+=i.text
return x.replace('\t','').replace(' ','')
except:
return ''綜合以上知識,就能做做小應用可以給日常的作業提高不少效率,運行效果,代碼略:
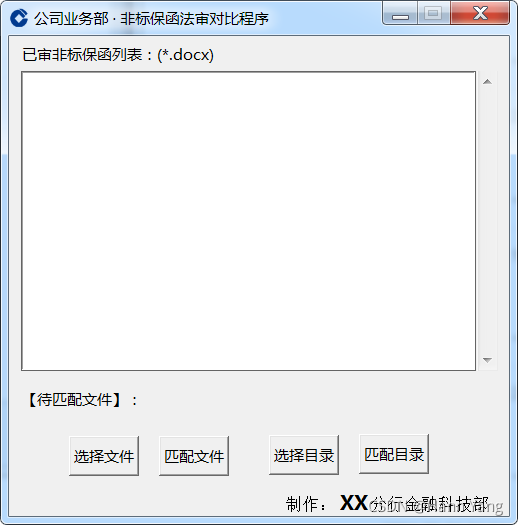
-- All done!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/300749.html
標籤:python
上一篇:基于Spring Boot開發的薪資管理系統,拿來做畢設也太爽了吧!
下一篇:??資料可視化??:基于 Echarts + Python 實作的大屏范例【13】國慶黃金周旅游監測???來了~