個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
1.pycharm專業版無限期申請
1.1 Python安裝與第一個Python程式
1.2 Python基礎知識
1.3 Python最重要的三大陳述句詳解
1.4 函式與模塊
附源代碼
1.pycharm專業版無限期申請
主要通過pycharm編輯器進行撰寫代碼,如果是學生黨,可以直接申請無限期使用pycharm專業版,下面是申請方式:
JetBrains開發工具免費提供學生和教師使用,取得授權后只需要使用相同的 JetBrains 帳號就可以激活其他產品,不需要重復申請,
1. 獲得(學生郵箱)教育郵箱
作為學生, 我們在入學時學校已經給了我們教育郵箱, 只是大多數人都不知道罷了, 郵箱為:

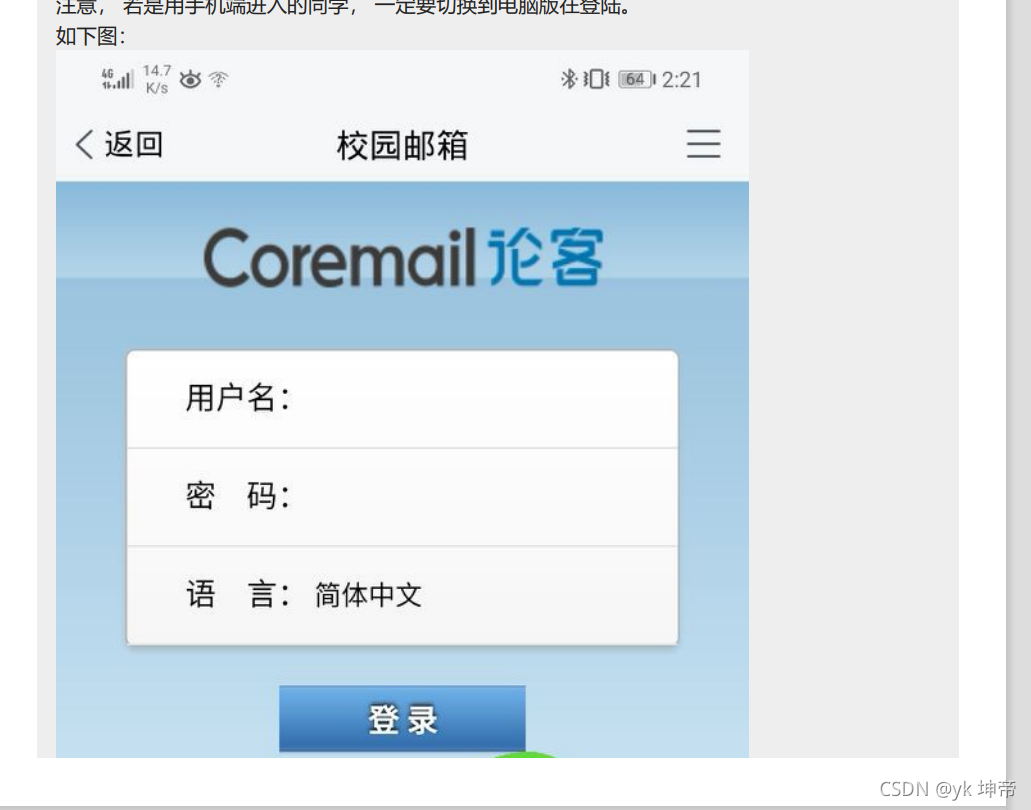
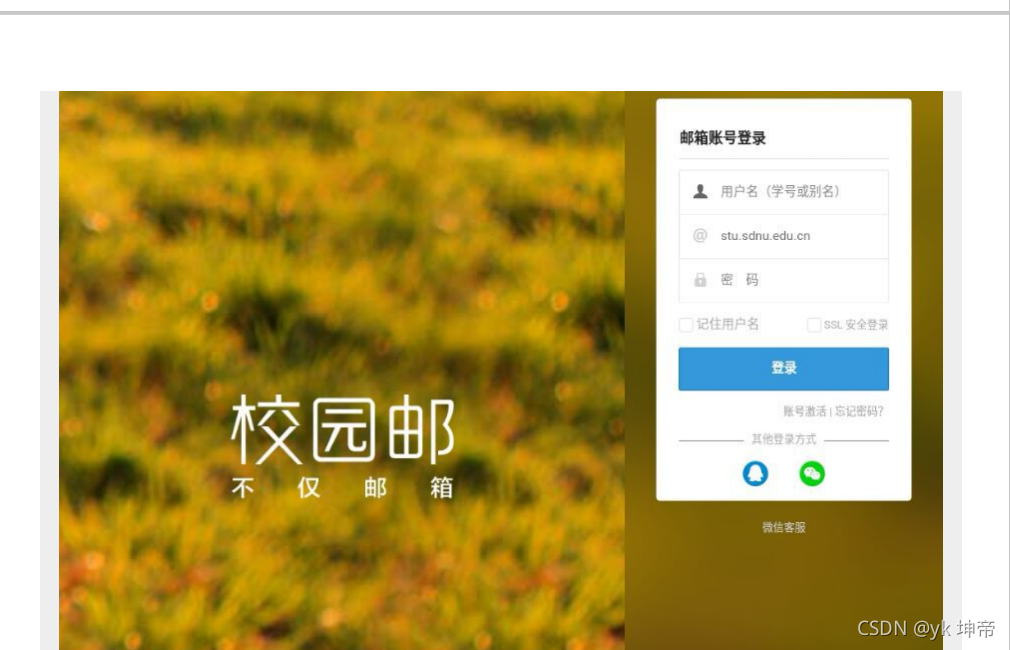
如何登陸呢, 這里附上山師學生郵箱官網, 點擊下面鏈接登陸即可 http://mail.stu.sdnu.edu.cn/
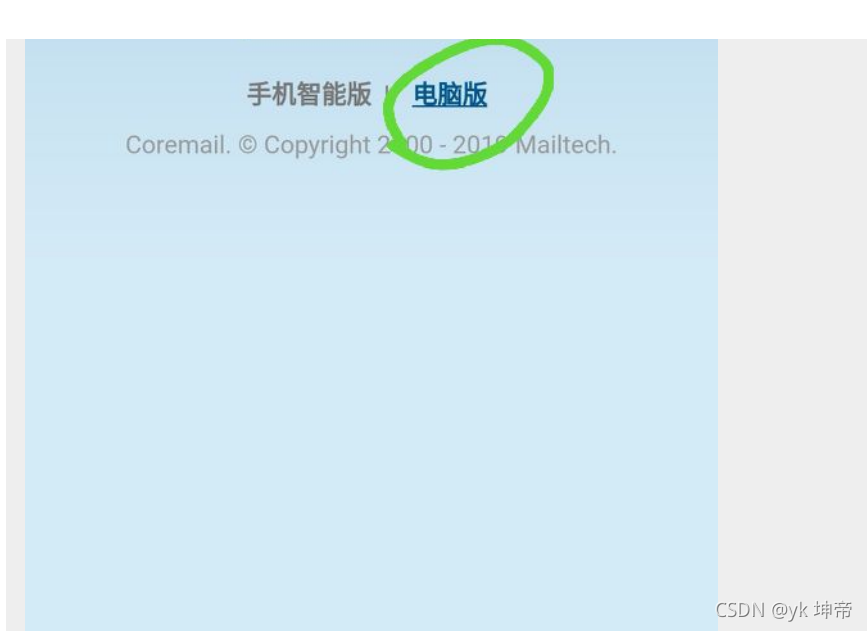
注意, 若是用手機端進入的同學, 一定要切換到電腦版在登陸, 如下圖:
2. 申請試用Jetbrains試用
當你擁有了你的學生郵箱, 就可以申請試用啦,
- 進入Jetbrains官網 https://account.jetbrains.com/login , 用自己的學生郵箱注冊賬號 (有時候Jetbrains官網相應的比較慢~請耐心等待) 若看不清下圖請右擊在新視窗打開~

- 點擊sign up后,官方會發一封確認驗證郵件到你的郵箱上, 有時候過好幾分鐘才會發過來, 請耐心等待一下吧,收到郵件設定好賬號密碼, 然后進入下一步~ 2. 進入 https://www.jetbrains.com/shop/eform/students, 開始填寫資料,(有時候Jetbrains官網相應的比較慢~請耐心等待)
個人公眾號 yk 坤帝
后臺回復 郵箱申請 獲取完整資源
1.1 Python安裝與第一個Python程式
Python 是 Anaconda 的一個發新版本,安裝好了 Anaconda就相當于安裝好了Python,
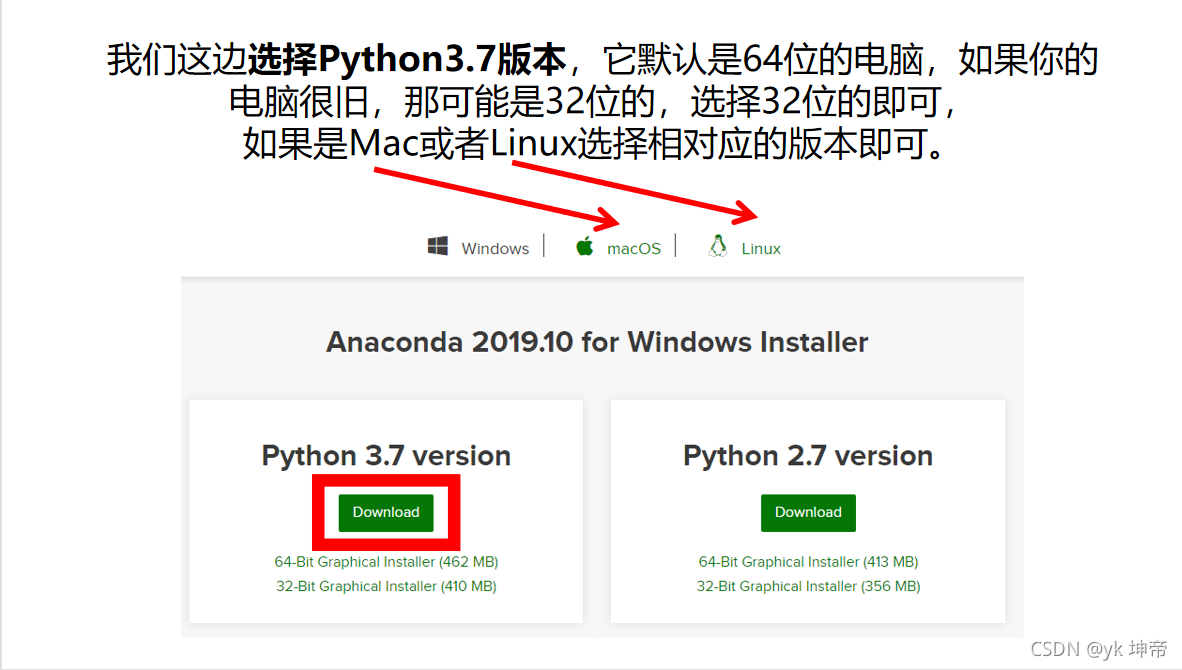
Anaconda 的官網下載地址 https://www.anaconda.com/download/ ,或者直接網頁搜索Anaconda,進入官網,選擇下載即可,
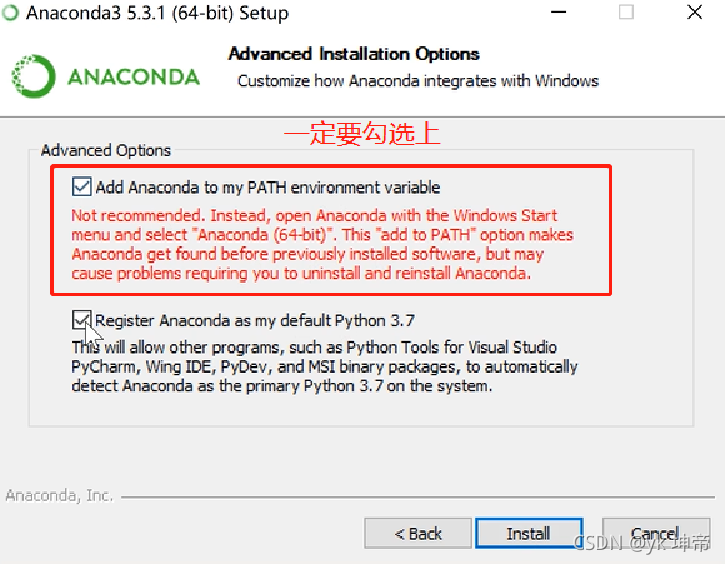
安裝到下圖這一步的時候,一定要把第一個勾給勾選上,因為這個對于初學者來說,就相當于自動配置好了環境變數,不然還得麻煩手動配置,
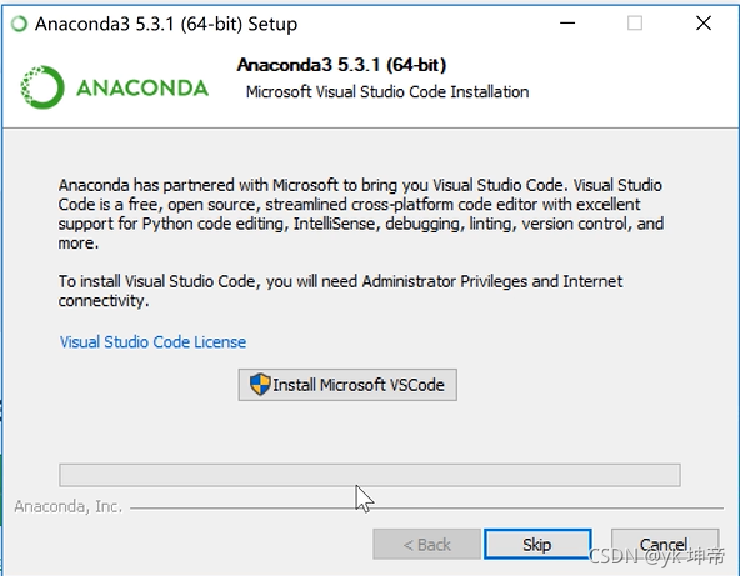
然后一直點Next,下面這一步是否安裝額外內容選擇skip即可,
其他一直選擇Next即可,最后點擊Finish,那Python就安裝完成啦,
Spyder打開方法如下:
電腦左下角打開Anaconda,點擊Spyder即可,
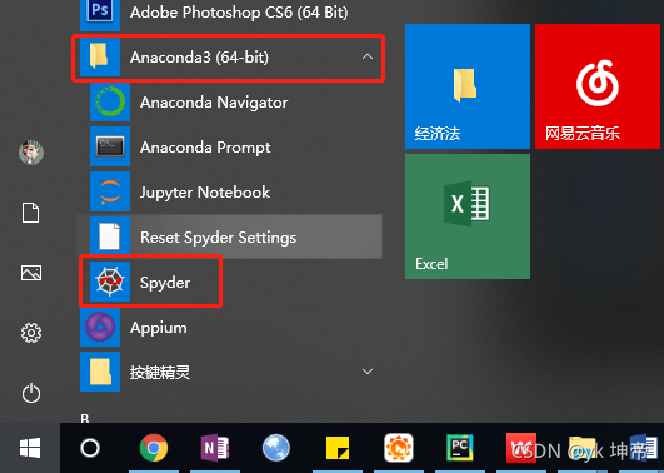
Spyder顯示如下界面:
1.其中左邊紅色框是寫代碼的地方
2.右邊紅色框則是輸出代碼結果的地方
3.上方的綠色的箭頭則是運行代碼的標志
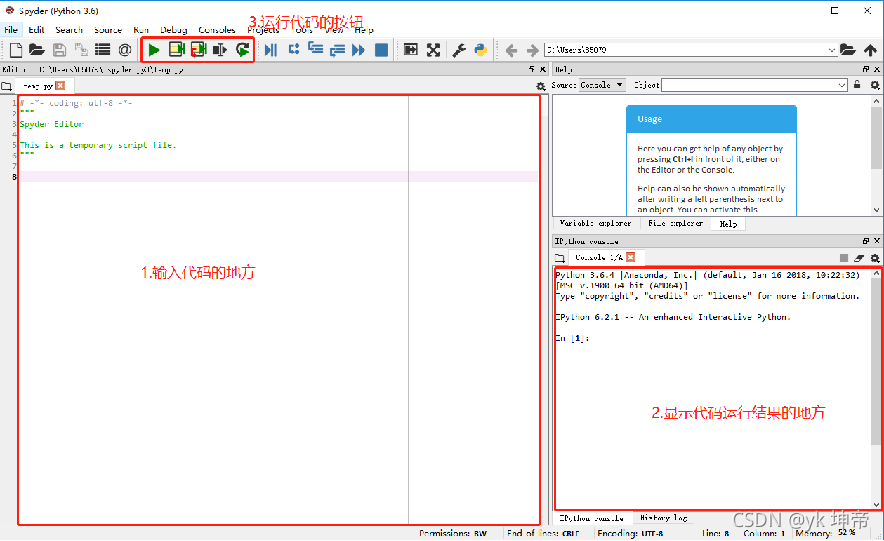
下面就讓我們來寫第一個Python程式吧,在左邊輸入代碼的地方,在英文模式下輸入:
print (‘hello world’)
然后點擊上方綠色的運行按鈕,在Spyder里,也可以按F5來運行程式,
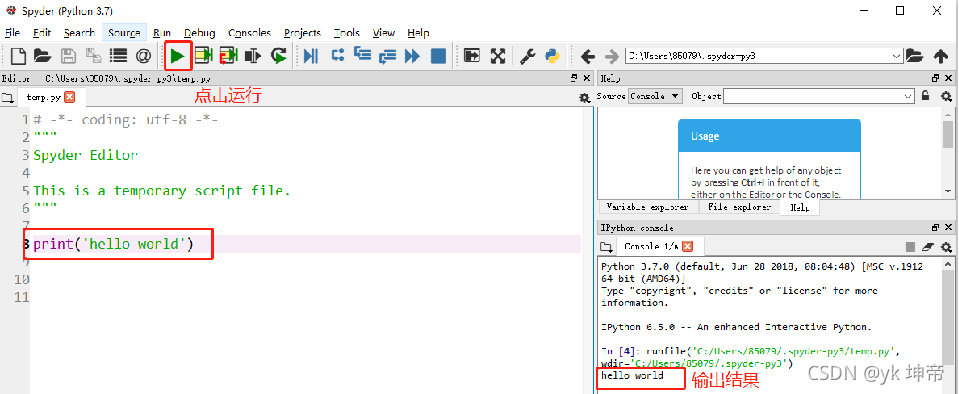
注意:輸入時候必須切換到英文模式,其中單引號,雙引號在Python中沒有區別,
補充:編譯器Pycharm安裝(推薦安裝)
我們之后的教學大多都是使用Pycharm來進行講解,Pycharm 和Spyder的功能是大致相同的,如果不想安裝Pycharm,可以跳過這一步,
注意:第一次運行Pycharm的時候Index緩沖的時間較長,以后就好多了,
到官網 :http://www.jetbrains.com/pycharm/download/#section=windows 下載PyCharm安裝包,我們選擇免費版(Community)就完全夠用了,
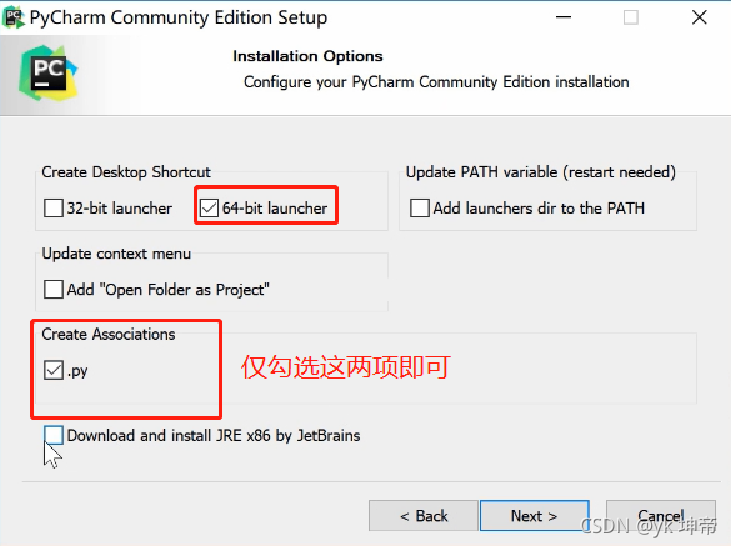
下載完后,雙擊就可以安裝了,安裝程序中,一直選擇Next和Install即可,其中這一頁選擇下面兩項即可,
之后一直點擊Next一直到最后的Finish(結束)出現之后點擊Finish即可,
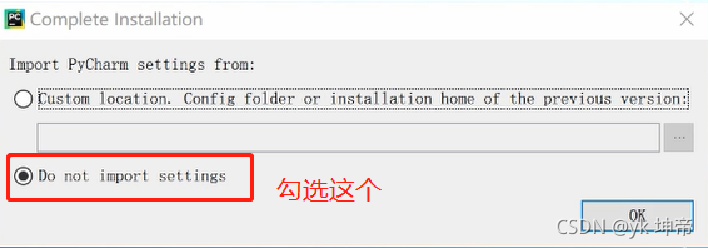
按完Finish之后的第一步:這個勾選“Do not import settings“
第二步:選擇頁面風格,建議選擇默認的黑色風格,
第三步:選擇輔助工具,直接跳過,啥也不需要選,
第四步:點擊“Create New Project”創建Python檔案,
第五步:檔案進行命名,這一步千萬記得點開Project Interpreter,勾選Existing interpreter,
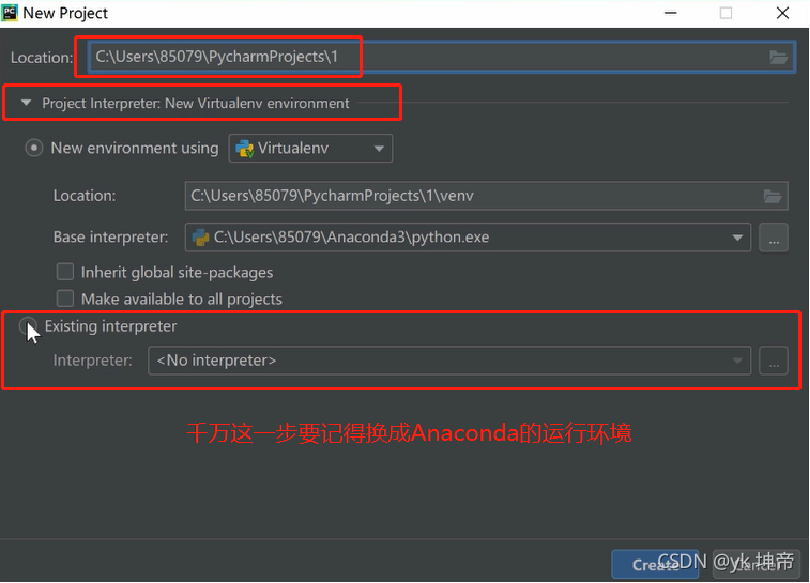
然后點擊最右邊的 ,如下圖:在彈出的頁面中選擇System Interpreter, 可以看到Interpreter變成了Anaconda3\Python.exe,選擇OK,

回到專案創建頁面后,點擊Create即可創建新的Python Project
第六步:關閉官方小技巧提示,等待最下面的Index緩沖完畢,它緩沖的程序其實是在配置你Python的運行環境,
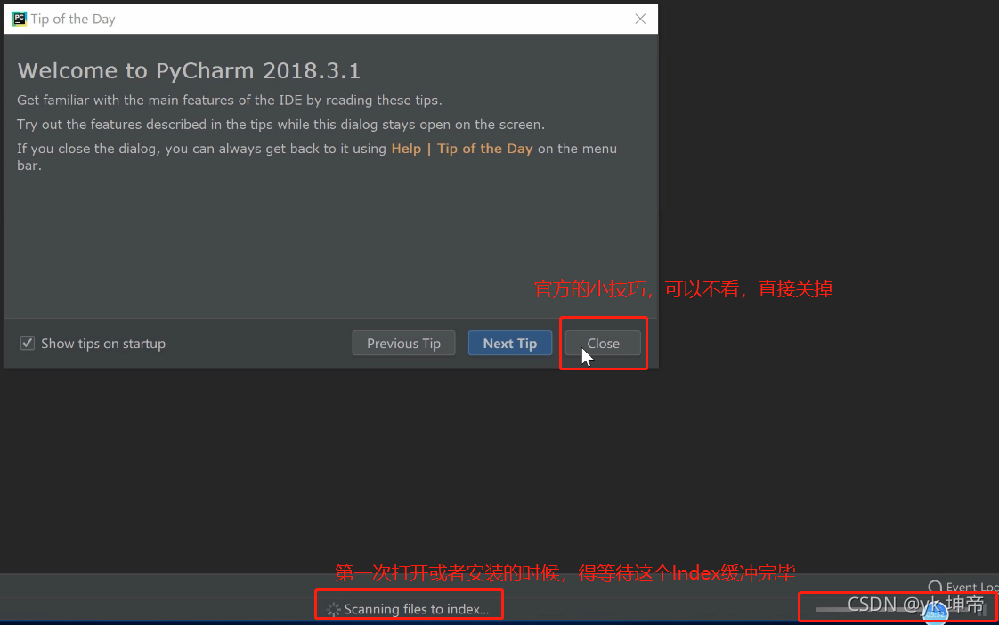
等到最下面的那個Index已經緩沖完畢后,我們可以進行下一步,
第七步:創建Python檔案,如下圖,點擊之前創建的專案檔案夾,然后右鍵,點擊New,選擇Python File,
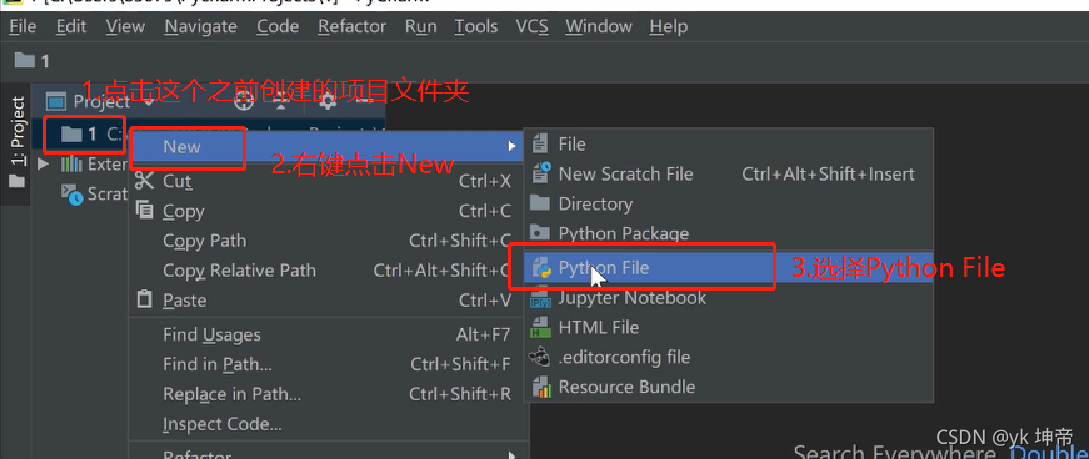
將新的Python檔案命名為 hello world,
你之后如果要新建檔案的話,可以在File里面選擇New Project,如下圖所示:
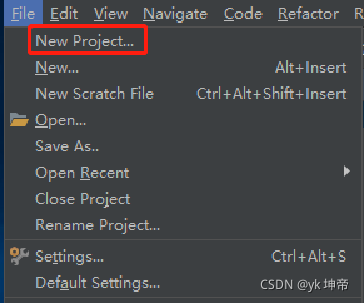
然后重復上訴步驟,注意在選Project Interpreter的時候勾選Existing interpreter,
第八步:在英文模式下輸入print(‘hello world’)
其中單引號雙引號沒有區別 (和Spyder一樣)
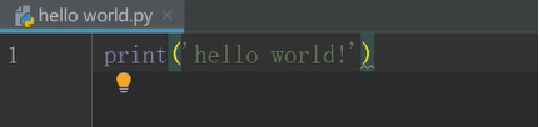
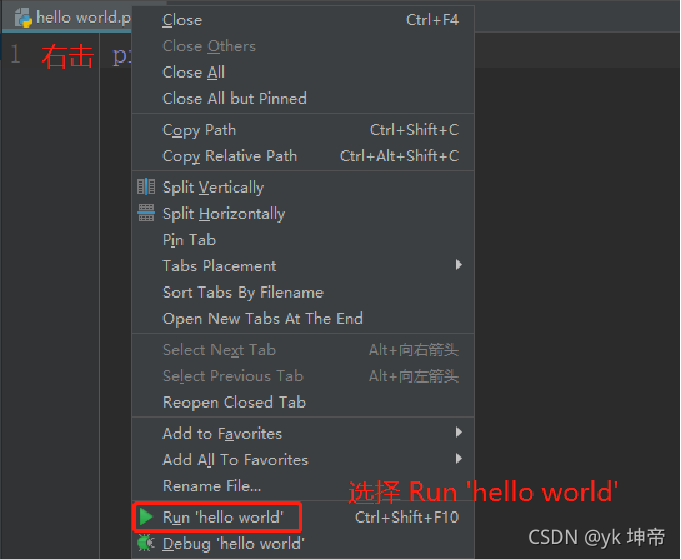
我們在上或者代碼輸入框內右擊,選擇Run ‘hello world’,
你也可以通過點擊界面右上角的綠色運行按鈕 ,
運行程式,或者按住快捷鍵 Ctrl+ Shift + F10也可以運行程式,
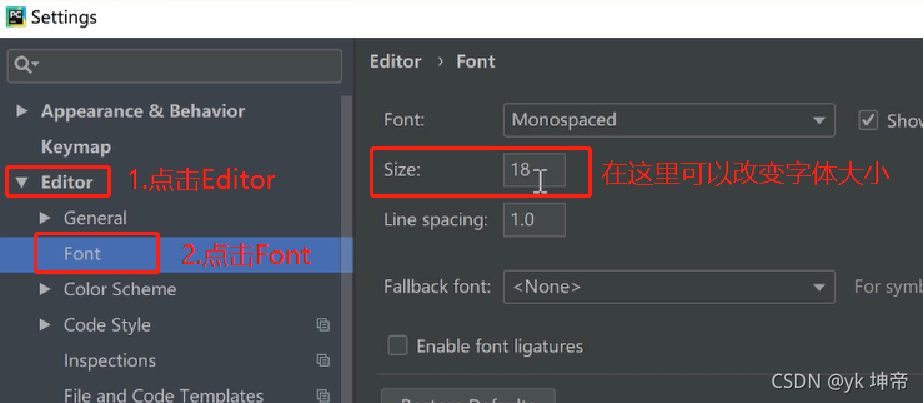
改變字的大小:
大家先點擊File,選擇下圖的Settings,
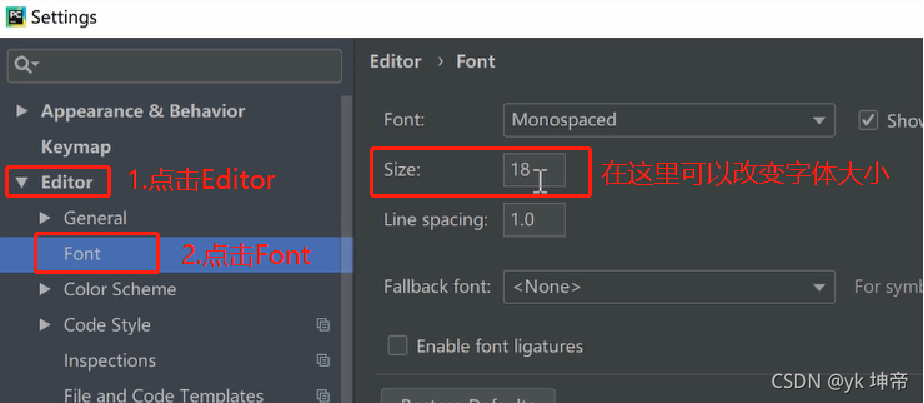
選擇Settings中的Editor,選擇Font,如下圖所示,在右邊的Size里可以調節顯示字體的大小以及行間距,
1.2.1 變數、行、縮進與注釋
(1) 變數
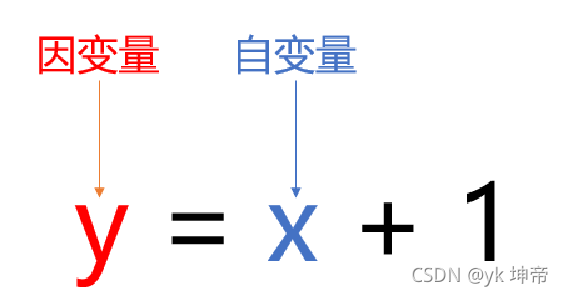
關于變數的命名:大家盡量用字母a,b,c,a_1,b_1等,或者自己創建的字符,不要用系統自帶的函式來命名,比如說不要用print來命名,寫成print = 1,這樣程式就會頭疼了,
使用 “= + ? × ÷ > < ” :
輸入下面的程式:

運行的結果:
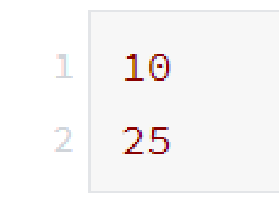
如果我們不打出 print(x)和 print(y), python只會保存x 和 y的結果,并不會顯示結果
(2) 行
在Python中,一般來說,很少用逗號或者分號,代碼都是一行一行寫的,所以每寫完一句,在句尾,我們按一下Enter鍵,就可以進行換行,
(3)縮進 (縮進快捷鍵是Tab鍵)
在if,for,while等陳述句中都會使用到縮進
代碼的輸入法和中文翻譯:


在第3行和第5行的print前面就必須要有縮進,否則Python會報錯
注意:如果你要減少縮進,那么按住Shift +Tab鍵的話就可以撤銷原來的縮進,你可以選擇一片區域,按住Tab鍵進行縮進練習,再按住Shift + Tab鍵撤銷原來的縮進
(4) 注釋
Python回不運動你的注釋,注釋在程式中大多是做個提示的作用,
注釋有兩個方式:

你可以輸入#或者‘’‘,或者在Pycharm中,注釋的快捷鍵是Ctrl + /;在Spyder中,注釋的快捷鍵為Ctrl + 1,
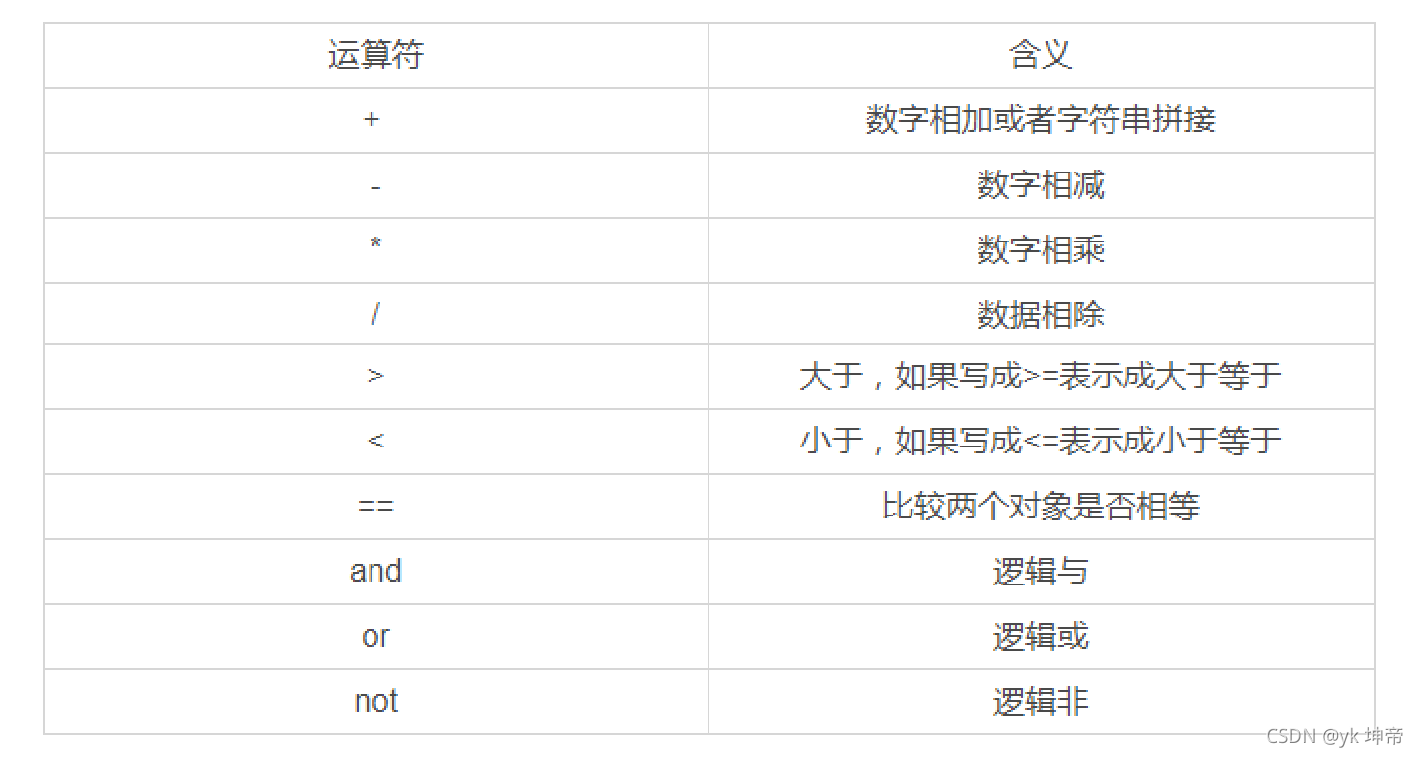
1.2.4運算子介紹與實踐
1.4.1 函式的定義與呼叫
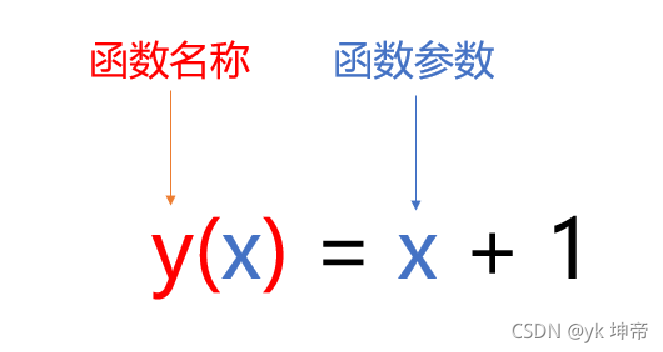

上面的函式Python代碼寫法是左邊的例子第一行和第二行,
第三行的意思是讓 x=1
彈出的結果回是:x+1=(1)+1=2
例子:

彈出結果改不了,因為沒有辦法改變x的價值:

(3) len()函式
Length 的縮寫是len(): 意思是長度,
主要功能是統計串列元素個數
地下給大家做了一個示范:

(4) replace()函式
Replace:意思是代替
主要功能是替換你想替換的內容
低下給大家做了一個示范:

彈出的結果:

1.2.1 變數、行、縮進與注釋
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 1 變數
x = 10
print(x)
x = x + 15
print(x)
# 2 行
# 代碼都是一行一行寫的
# 3 縮進,先不用管這個什么意思,之后會講,只要知道在if和else后面那個陳述句要有個縮進,按Tab鍵快速縮進
x = 10
if x > 0:
print('正數')
else:
print('負數')
# 4 注釋
'''
兩種注釋的方法:
1.#后的內容是注釋的內容,# 是shift + 3按出來的
2.三個單引號左右包著
'''
# 這之后是注釋內容,快捷鍵在pycharm里是ctrl + /,在spyder里是ctrl + 1
'''這里面是注釋內容'''
1.2.2 資料型別-數字與字串
# =============================================================================
# 1.2.2 資料型別-數字與字串
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 不同型別的資料不可以相加,下面的內容會報錯,我把它注釋掉了
# a = 1 + '1'
# print(a)
a = 1
print(type(a))
a = '1'
print(type(a))
# 將數字轉換成字串
a = 1
b = str(a) # 將數字轉換成字串,并賦值給變數b
c = b + '1'
print(c)
# 將字串轉換成數字
a = '1'
b = int(a) # 將字串轉換成數字,并賦值給變數b
c = b + 1
print(c)
1.2.3 串列與字典
# =============================================================================
# 1.2.3 串列與字典
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# # 串列
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
print(class1)
list1 = [1, '123', [1, 2, 3]]
print(list1)
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
for i in class1: # 這個for陳述句之后會重點講,這邊大家先運行看看效果即可
print(i)
# 統計串列的元素個數的函式:len函式
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = len(class1)
print(a)
# 調取一個串列元素的方法
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = class1[1]
print(a)
# 選取多個串列元素的方法:串列切片
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = class1[1:4]
print(a)
b = class1[1:] # 選取從第二個元素到最后
c = class1[-3:] # 選取從串列倒數第三個元素到最后
d = class1[:-2] # 選取倒數第二個元素前的所有元素(因為左閉右開,所以不包含倒數第二個元素)
print(b)
print(c)
print(d)
# 串列增加元素的辦法:append方法,這個先了解下即可
score = []
score.append(80)
print(score)
score = []
score.append(80)
score.append(90)
score.append(70)
print(score)
# 串列轉換成字串,這個先了解下即可,很遠之后才用的上
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = ",".join(class1)
print(a)
'''字典,關于字典這個知識,先了解下即可'''
# 字典名["鍵名"]提取值
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
score = class1['王二麻子']
print(score)
# 遍歷字典內容1
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
for i in class1: # 這個i代表的是字典中的鍵,也就是丁一、王二麻子等
print(i)
print(class1[i])
# 遍歷字典內容2
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
for i in class1:
print(i + ':' + str(class1[i])) # 注意要str把85等數字轉換成字串,才能進行字串拼接
# 遍歷字典內容3
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
a = class1.items()
print(a)
'''元組和集合(了解即可)'''
# 元組 其實和串列基本一樣,區別在于元組里的元素不可修改,及包圍的括號為小括號
a = ('丁一', '王二', '張三', '李四', '趙五') # 這就是個元組,是不是和串列很像呢
print(a[1:3])
# 集合
a = ['丁一', '丁一', '王二', '張三', '李四', '趙五']
print(set(a)) # 通過set()函式可以獲得一個集合,集合一個主要特點,就是用來去重,結果為:{'丁一', '王二', '趙五', '張三', '李四'}
1.2.4 運算子介紹與實踐
# =============================================================================
# 1.2.4 運算子介紹與實踐
# =============================================================================
# 1 算術運算子:+ 、-、*、/
a = 'hello'
b = 'world'
c = a + ' ' + b
print(c)
# 2 比較運算子: > , <, ==
score = -10
if score < 0:
print('該新聞是負面新聞,錄入資料庫')
a = 1
b = 2
if a == b: # 注意這邊是兩個等號
print('a和b相等')
else:
print('a和b不相等')
# 3 邏輯運算子:not,and,or
score = -10
year = 2018
if (score < 0) and (year == 2018):
print('錄入資料庫')
else:
print('不錄入資料庫')
1.3.1 if陳述句
# =============================================================================
# 1.3.1 if陳述句
# =============================================================================
score = 100
year = 2018
if (score < 0) and (year == 2018):
print('錄入資料庫')
else:
print('不錄入資料庫')
score = 85
if score >= 60:
print('及格')
else:
print('不及格')
# 多種情況,這個用到的較少,了解即可
score = 55
if score >= 80:
print('優秀')
elif (score >= 60) and (score < 80):
print('及格')
else:
print('不及格')
1.3.2 for陳述句
# =============================================================================
# 1.3.2 for陳述句
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
for i in class1:
print(i)
# 這個i只是個代號,可以換成任何別的內容
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
for haha in class1:
print(haha)
# for和range函式合用
for i in range(3):
print('hahaha')
'''
總結
(1)對于"for i in 區域"來說,如果說這個區域是一個串列,那么那個i就表示這個串列里的每一個元素;
(2)對于"for i in 區域"來說,如果說這個區域是一個range(n),那么那個i就表示0到n -1這n個數字,之前提到過,python中序號都是從0開始的,所以這邊也是從0開始,到n - 1結束,
(3)對于"for i in 區域"來說,若區域是一個字典,那么i就表示字典的鍵名;
'''
# 注意python中序號都是從0開始的
for i in range(5):
print(i)
# 在實戰中的應用
title = ['標題1', '標題2', '標題3', '標題4', '標題5']
for i in range(len(title)): # len(title)表示一個有多少個新聞,這里是5;這里的i就表示數字0-4
print(str(i+1) + '.' + title[i]) # 這個其實把字串進行一個拼接
1.3.3 while陳述句
# =============================================================================
# 1.3.3 while陳述句
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
a = 1
while a < 3:
print(a)
a = a + 1 # 或者寫成 a += 1,+=是一種偷懶的寫法
# while True在爬蟲實戰中用于24小時不間斷爬取,在第7講將會詳細講解
while True:
print('hahaha')
1.3.4 try except例外處理陳述句
# =============================================================================
# 1.3.4 try except例外處理陳述句
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
try:
print(1 + 'a')
except:
print('主代碼運行失敗')
# 下面為實戰中的演示
try:
# 這里是百度新聞爬取的代碼
print(1 + '1')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是百度新聞爬取的代碼,之后第五第七章會講
print(1 + 'a')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是新浪財經新聞爬取的代碼,之后爬蟲進階課會講
print('新浪財經新聞爬取成功')
except:
print('新浪財經新聞爬取失敗')
try:
# 這里是微信推文爬取的代碼,之后爬蟲進階課會講
print('微信推文爬取成功')
except:
print('微信推文爬取失敗')
1.4.1函式的定義與呼叫
# =============================================================================
# 1.4.1函式的定義與呼叫
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 定義及呼叫函式
def y(x):
print(x+1)
y(1) # 呼叫函式
def y(x):
print(x+1)
y(1) # 第一次呼叫函式
y(2) # 第二次呼叫函式
y(3) # 第三次呼叫函式
# 傳入兩個引數
def y(x, z):
print(x + z + 1)
y(1, 2)
# 有時候不需要引數也可以定義函式,這個了解即可
def y():
x = 1
print(x+1)
y() # 呼叫函式
# 函式在實戰中的應用展示
def baidu(company):
# 這里是具體爬蟲代碼,之后會講
print(company + 'completed!')
companys = ['華能信托', '阿里巴巴', '百度集團', '騰訊', '京東', '萬科', '華為集團']
for i in companys:
baidu(i)
'''
復習:
對于"for i in 區域"來說,如果說這個區域是一個串列,那么那個i就表示這個串列里的每一個元素;
'''
1.4.2 函式回傳值、作用域
# =============================================================================
# 1.4.2 函式回傳值、作用域
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 這里的company只是個代號,你可以換成任何東西,比如keyword,cat,dog都可以,注意函式內容里的company也要相應改變
def baidu(keyword):
# 這里是具體爬蟲代碼,第七章會講
print(keyword + 'completed!')
companys = ['華能信托', '阿里巴巴', '百度', '騰訊', '京東', '萬科', '建設銀行']
for i in companys:
baidu(i)
'''2.回傳值'''
def y(x):
return(x+1)
y(1)
'''return相當于看不見的print,它是把原來該print的值賦值給了y(x)這個函式,學術點的說法就是該函式的回傳值為:x+1'''
def y(x):
return(x+1)
a = y(1)
print(a) # 這樣才能把 y(1) 列印出來,或者直接寫print(y1)
# 在實戰中的應用
def baidu(keyword):
# 這里是具體爬蟲代碼,之后講
return(keyword + 'completed!')
a = baidu('華能信托')
print(a)
# return不加括號也是可以的
def baidu(keyword):
# 這里是具體爬蟲代碼,第七章會講
return keyword + 'completed!' #這里把括號去掉了
a = baidu('華能信托')
print(a)
'''3.變數作用域(了解即可)'''
x = 1
def y(x):
x = x + 1
print(x)
y(3)
print(x)
# 其實函式引數只是個代號,可以換成任何內容
x = 1
def y(z):
z = z + 1
print(z)
y(3)
print(x)
1.4.3 一些重要的基本函式介紹
# =============================================================================
# 1.4.3 一些重要的基本函式介紹
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 1 print函式,記得加括號即可,快捷方式,寫pri的時候按一下tab鍵會自動變成print()
print('hello world')
print(1, 'hello', [1, 2, '123']) # 通過逗號,也可以同時列印多個內容(可以是不同型別的資料),會通過空格自動分隔
print(str(1) + 'hello') # 如果通過+號字串拼接,則需要是同樣是字串型別
# 2 str函式與int函式 - 字串與數字轉換
score = 85
print('A公司今日評分為' + str(score) + '分,') # 不加str就成了字串與數字相加會報錯的
score = '85'
score = int(score) # 不加int的話,下面字串'85'和數字80沒法比較
if score > 80:
print('OK')
# 2 len函式
# len函式可以統計串列里元素的個數
title = ['標題1', '標題2', '標題3', '標題4', '標題5']
href = ['網址1', '網址2', '網址3', '網址4', '網址5']
for i in range(len(title)): # len(title)表示一個有多少個新聞,這里是5
href[i] = 'www.baidu.com/' + href[i] # 這個其實就相當于 a = a + 1
print(str(i+1) + '.' + title[i]) # 這個其實把字串進行一個拼接
print(href[i])
# len函式還可以統計字串個數
a = '123華小智abcd'
print(len(a))
# 4 replace函式 - 替換你想替換的內容
a ='<em>阿里巴巴</em>電商脫貧成“教材” 累計培訓逾萬名縣域干部'
a = a.replace('<em>','')
a = a.replace('</em>','')
print(a)
# 5 strip函式 - 洗掉空白符
a =' 華能信托2018年上半年行業綜合排名位列第5 '
a = a.strip()
print(a)
# 6 split函式 - 分割字串
a = '2018年12月12日 08:07'
a = a.split(' ')[0]
print(a)
# 注意,split分割完是一個串列
a = '2018年12月12日 08:07'
a = a.split(' ')
print(a)
# 7 例外處理函式try except函式,其實應該叫例外處理陳述句,后來調整到1.3.4小節了
try:
print(1 + 'a')
except:
print('主代碼運行失敗')
try:
# 這里是百度新聞爬取的代碼
print(1 + '1')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是百度新聞爬取的代碼,之后第五第七章會講
print(1 + 'a')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是新浪財經新聞爬取的代碼,之后爬蟲進階課會講
print('新浪財經新聞爬取成功')
except:
print('新浪財經新聞爬取失敗')
try:
# 這里是微信推文爬取的代碼,之后爬蟲進階課會講
print('微信推文爬取成功')
except:
print('微信推文爬取失敗')
1.4.4 Python庫與模塊介紹
# =============================================================================
# 1.4.4 Python庫與模塊介紹
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 顯示時間的一種方式
import time
print(time.strftime("%Y/%m/%d"))
# 顯示時間的另一種方式
from datetime import datetime
print(datetime.now())
# 上面的代碼也可以這么寫,不一定要寫成from import
import datetime
print(datetime.datetime.now())
# 嘗試獲取百度首頁的網頁源代碼,可以把這個網址換成別的試試看
import requests
url = 'https://www.baidu.com/'
res = requests.get(url).text
print(res)
# 獲取Python官網首頁的網頁源代碼
import requests
url = 'https://www.python.org'
res = requests.get(url).text
# print(res) # 獲取到的內容較多,感興趣的讀者可以將注釋取消看看運行結果,小技巧:按Ctrl+/可以添加和取消注釋
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/300755.html
標籤:python
上一篇:2021年9月世界編程語言排行
下一篇:Python中的字串介紹(上)