1.2.1 變數、行、縮進與注釋
1.2.2 資料型別-數字與字串
1.2.3 串列與字典
1.2.4 運算子介紹與實踐
1.3.1 if陳述句
1.3.2 for陳述句
1.3.3 while陳述句
1.3.4 try except例外處理陳述句
1.4.1函式的定義與呼叫
1.4.2 函式回傳值、作用域
1.4.3 一些重要的基本函式介紹
1.4.4 Python庫與模塊介紹
2.2.1 我的第一個網頁
2.2.3 逐漸完善的網頁
2.3.1 獲取百度新聞網頁源代碼
2.4.1 正則運算式之findall
2.4.2 正則運算式之非貪婪匹配1
2.4.3 正則運算式之非貪婪匹配2
2.4.4 正則運算式之換行
2.4.5 正則運算式之小知識點補充
1.2.1 變數、行、縮進與注釋
# =============================================================================
# 1.2.1 變數、行、縮進與注釋
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融基礎 獲取源代碼
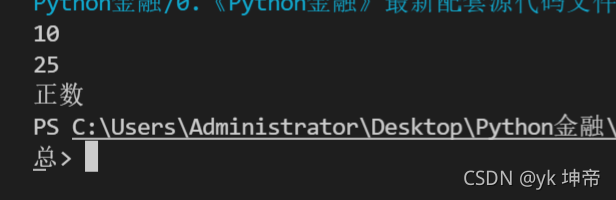
# 1 變數
x = 10
print(x)
x = x + 15
print(x)
# 2 行
# 代碼都是一行一行寫的
# 3 縮進,先不用管這個什么意思,之后會講,只要知道在if和else后面那個陳述句要有個縮進,按Tab鍵快速縮進
x = 10
if x > 0:
print('正數')
else:
print('負數')
# 4 注釋
'''
兩種注釋的方法:
1.#后的內容是注釋的內容,# 是shift + 3按出來的
2.三個單引號左右包著
'''
# 這之后是注釋內容,快捷鍵在pycharm里是ctrl + /,在spyder里是ctrl + 1
'''這里面是注釋內容'''
1.2.2 資料型別-數字與字串
# =============================================================================
# 1.2.2 資料型別-數字與字串
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融基礎 獲取源代碼
# 不同型別的資料不可以相加,下面的內容會報錯,我把它注釋掉了
# a = 1 + '1'
# print(a)
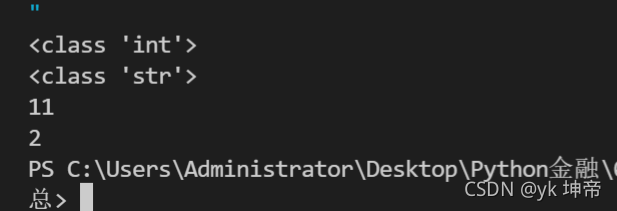
a = 1
print(type(a))
a = '1'
print(type(a))
# 將數字轉換成字串
a = 1
b = str(a) # 將數字轉換成字串,并賦值給變數b
c = b + '1'
print(c)
# 將字串轉換成數字
a = '1'
b = int(a) # 將字串轉換成數字,并賦值給變數b
c = b + 1
print(c)
1.2.3 串列與字典
# =============================================================================
# 1.2.3 串列與字典
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融基礎 獲取源代碼
# # 串列
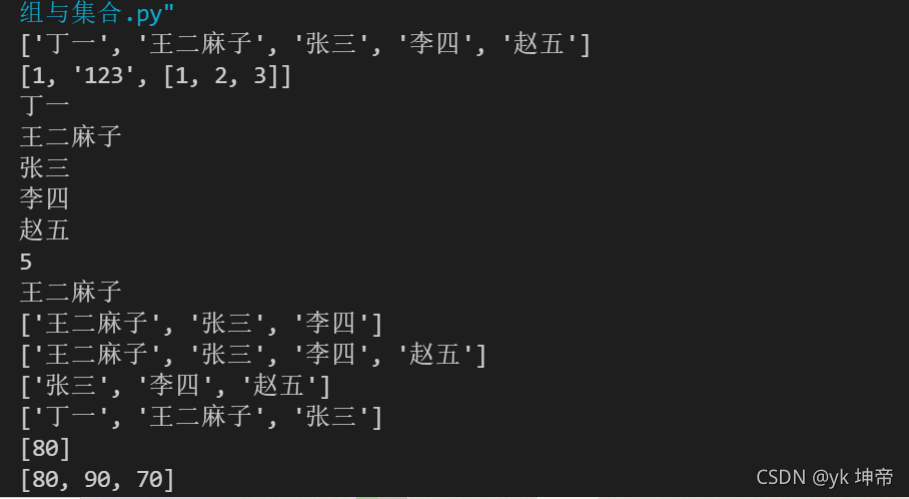
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
print(class1)
list1 = [1, '123', [1, 2, 3]]
print(list1)
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
for i in class1: # 這個for陳述句之后會重點講,這邊大家先運行看看效果即可
print(i)
# 統計串列的元素個數的函式:len函式
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = len(class1)
print(a)
# 調取一個串列元素的方法
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = class1[1]
print(a)
# 選取多個串列元素的方法:串列切片
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = class1[1:4]
print(a)
b = class1[1:] # 選取從第二個元素到最后
c = class1[-3:] # 選取從串列倒數第三個元素到最后
d = class1[:-2] # 選取倒數第二個元素前的所有元素(因為左閉右開,所以不包含倒數第二個元素)
print(b)
print(c)
print(d)
# 串列增加元素的辦法:append方法,這個先了解下即可
score = []
score.append(80)
print(score)
score = []
score.append(80)
score.append(90)
score.append(70)
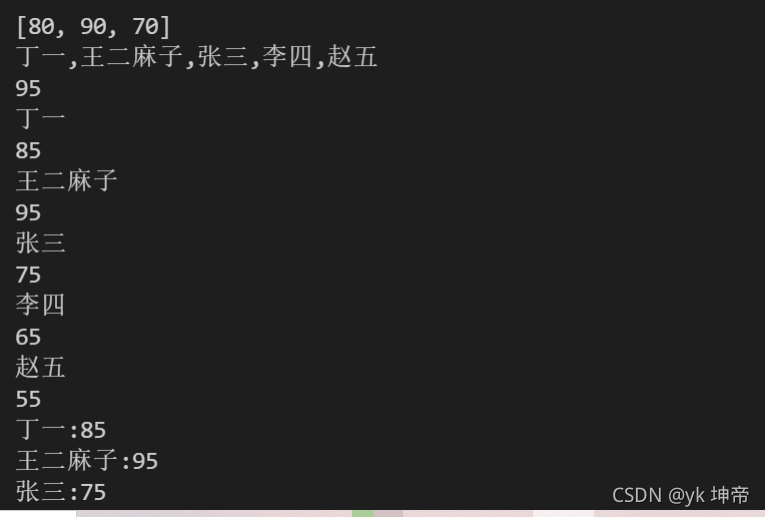
print(score)
# 串列轉換成字串,這個先了解下即可,很遠之后才用的上
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
a = ",".join(class1)
print(a)
'''字典,關于字典這個知識,先了解下即可'''
# 字典名["鍵名"]提取值
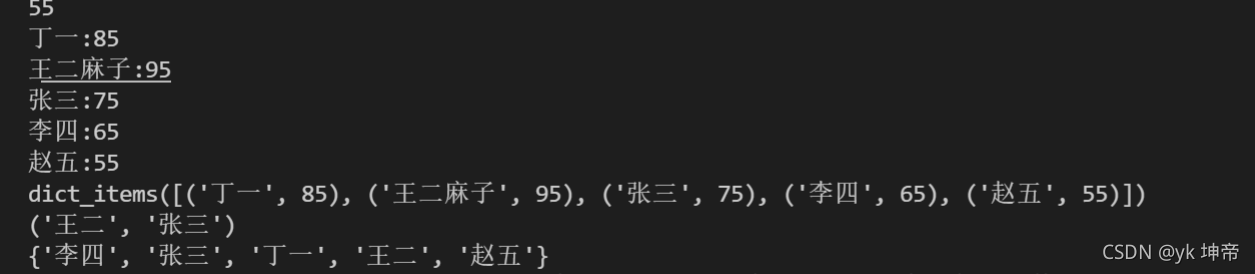
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
score = class1['王二麻子']
print(score)
# 遍歷字典內容1
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
for i in class1: # 這個i代表的是字典中的鍵,也就是丁一、王二麻子等
print(i)
print(class1[i])
# 遍歷字典內容2
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
for i in class1:
print(i + ':' + str(class1[i])) # 注意要str把85等數字轉換成字串,才能進行字串拼接
# 遍歷字典內容3
class1 = {'丁一': 85, '王二麻子': 95, '張三': 75, '李四': 65, '趙五': 55}
a = class1.items()
print(a)
'''元組和集合(了解即可)'''
# 元組 其實和串列基本一樣,區別在于元組里的元素不可修改,及包圍的括號為小括號
a = ('丁一', '王二', '張三', '李四', '趙五') # 這就是個元組,是不是和串列很像呢
print(a[1:3])
# 集合
a = ['丁一', '丁一', '王二', '張三', '李四', '趙五']
print(set(a)) # 通過set()函式可以獲得一個集合,集合一個主要特點,就是用來去重,結果為:{'丁一', '王二', '趙五', '張三', '李四'}
1.2.4 運算子介紹與實踐
# =============================================================================
# 1.2.4 運算子介紹與實踐
# =============================================================================
# 1 算術運算子:+ 、-、*、/
a = 'hello'
b = 'world'
c = a + ' ' + b
print(c)
# 2 比較運算子: > , <, ==
score = -10
if score < 0:
print('該新聞是負面新聞,錄入資料庫')
a = 1
b = 2
if a == b: # 注意這邊是兩個等號
print('a和b相等')
else:
print('a和b不相等')
# 3 邏輯運算子:not,and,or
score = -10
year = 2018
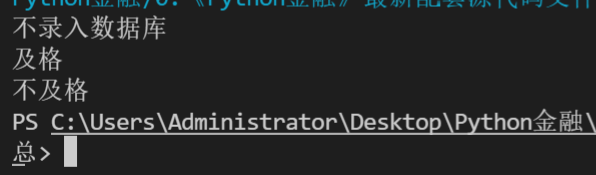
if (score < 0) and (year == 2018):
print('錄入資料庫')
else:
print('不錄入資料庫')
1.3.1 if陳述句
# =============================================================================
# 1.3.1 if陳述句
# =============================================================================
score = 100
year = 2018
if (score < 0) and (year == 2018):
print('錄入資料庫')
else:
print('不錄入資料庫')
score = 85
if score >= 60:
print('及格')
else:
print('不及格')
# 多種情況,這個用到的較少,了解即可
score = 55
if score >= 80:
print('優秀')
elif (score >= 60) and (score < 80):
print('及格')
else:
print('不及格')
1.3.2 for陳述句
# =============================================================================
# 1.3.2 for陳述句
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
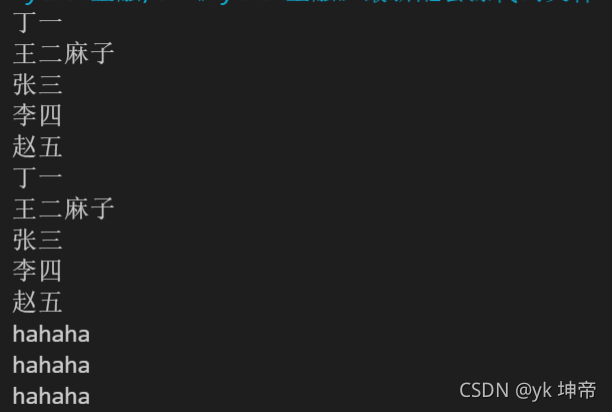
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
for i in class1:
print(i)
# 這個i只是個代號,可以換成任何別的內容
class1 = ['丁一', '王二麻子', '張三', '李四', '趙五']
for haha in class1:
print(haha)
# for和range函式合用
for i in range(3):
print('hahaha')
'''
總結
(1)對于"for i in 區域"來說,如果說這個區域是一個串列,那么那個i就表示這個串列里的每一個元素;
(2)對于"for i in 區域"來說,如果說這個區域是一個range(n),那么那個i就表示0到n -1這n個數字,之前提到過,python中序號都是從0開始的,所以這邊也是從0開始,到n - 1結束,
(3)對于"for i in 區域"來說,若區域是一個字典,那么i就表示字典的鍵名;
'''
# 注意python中序號都是從0開始的
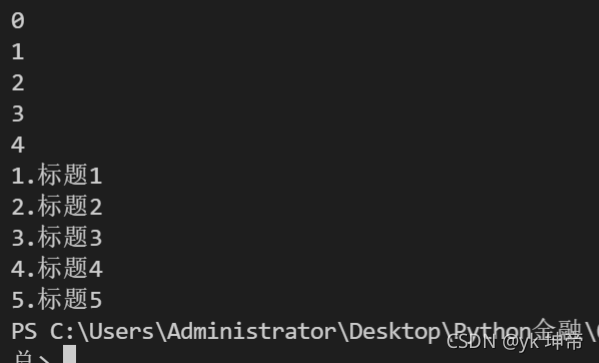
for i in range(5):
print(i)
# 在實戰中的應用
title = ['標題1', '標題2', '標題3', '標題4', '標題5']
for i in range(len(title)): # len(title)表示一個有多少個新聞,這里是5;這里的i就表示數字0-4
print(str(i+1) + '.' + title[i]) # 這個其實把字串進行一個拼接
1.3.3 while陳述句
# =============================================================================
# 1.3.3 while陳述句
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
a = 1
while a < 3:
print(a)
a = a + 1 # 或者寫成 a += 1,+=是一種偷懶的寫法
# while True在爬蟲實戰中用于24小時不間斷爬取,在第7講將會詳細講解
while True:
print('hahaha')

1.3.4 try except例外處理陳述句
# =============================================================================
# 1.3.4 try except例外處理陳述句
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
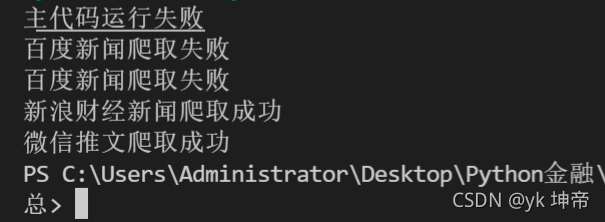
try:
print(1 + 'a')
except:
print('主代碼運行失敗')
# 下面為實戰中的演示
try:
# 這里是百度新聞爬取的代碼
print(1 + '1')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是百度新聞爬取的代碼,之后第五第七章會講
print(1 + 'a')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是新浪財經新聞爬取的代碼,之后爬蟲進階課會講
print('新浪財經新聞爬取成功')
except:
print('新浪財經新聞爬取失敗')
try:
# 這里是微信推文爬取的代碼,之后爬蟲進階課會講
print('微信推文爬取成功')
except:
print('微信推文爬取失敗')
1.4.1函式的定義與呼叫
# =============================================================================
# 1.4.1函式的定義與呼叫
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 定義及呼叫函式
def y(x):
print(x+1)
y(1) # 呼叫函式
def y(x):
print(x+1)
y(1) # 第一次呼叫函式
y(2) # 第二次呼叫函式
y(3) # 第三次呼叫函式
# 傳入兩個引數
def y(x, z):
print(x + z + 1)
y(1, 2)
# 有時候不需要引數也可以定義函式,這個了解即可
def y():
x = 1
print(x+1)
y() # 呼叫函式
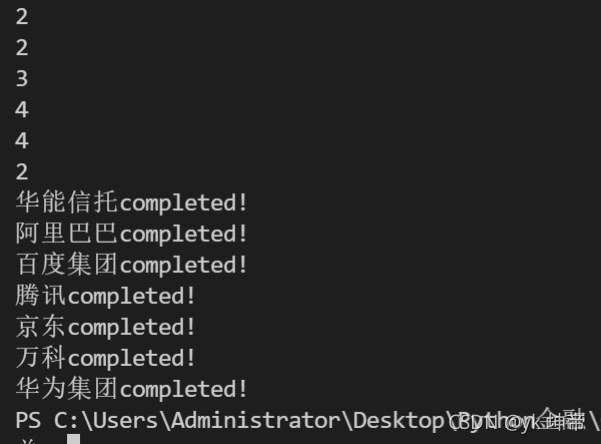
# 函式在實戰中的應用展示
def baidu(company):
# 這里是具體爬蟲代碼,之后會講
print(company + 'completed!')
companys = ['華能信托', '阿里巴巴', '百度集團', '騰訊', '京東', '萬科', '華為集團']
for i in companys:
baidu(i)
'''
復習:
對于"for i in 區域"來說,如果說這個區域是一個串列,那么那個i就表示這個串列里的每一個元素;
'''
1.4.2 函式回傳值、作用域
# =============================================================================
# 1.4.2 函式回傳值、作用域
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 這里的company只是個代號,你可以換成任何東西,比如keyword,cat,dog都可以,注意函式內容里的company也要相應改變
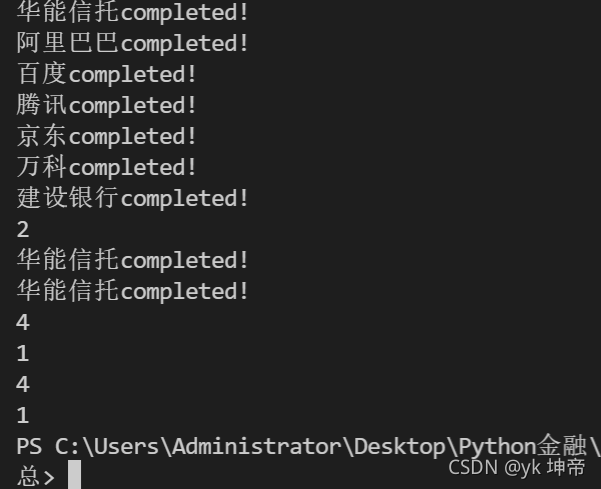
def baidu(keyword):
# 這里是具體爬蟲代碼,第七章會講
print(keyword + 'completed!')
companys = ['華能信托', '阿里巴巴', '百度', '騰訊', '京東', '萬科', '建設銀行']
for i in companys:
baidu(i)
'''2.回傳值'''
def y(x):
return(x+1)
y(1)
'''return相當于看不見的print,它是把原來該print的值賦值給了y(x)這個函式,學術點的說法就是該函式的回傳值為:x+1'''
def y(x):
return(x+1)
a = y(1)
print(a) # 這樣才能把 y(1) 列印出來,或者直接寫print(y1)
# 在實戰中的應用
def baidu(keyword):
# 這里是具體爬蟲代碼,之后講
return(keyword + 'completed!')
a = baidu('華能信托')
print(a)
# return不加括號也是可以的
def baidu(keyword):
# 這里是具體爬蟲代碼,第七章會講
return keyword + 'completed!' #這里把括號去掉了
a = baidu('華能信托')
print(a)
'''3.變數作用域(了解即可)'''
x = 1
def y(x):
x = x + 1
print(x)
y(3)
print(x)
# 其實函式引數只是個代號,可以換成任何內容
x = 1
def y(z):
z = z + 1
print(z)
y(3)
print(x)
1.4.3 一些重要的基本函式介紹
# =============================================================================
# 1.4.3 一些重要的基本函式介紹
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 1 print函式,記得加括號即可,快捷方式,寫pri的時候按一下tab鍵會自動變成print()
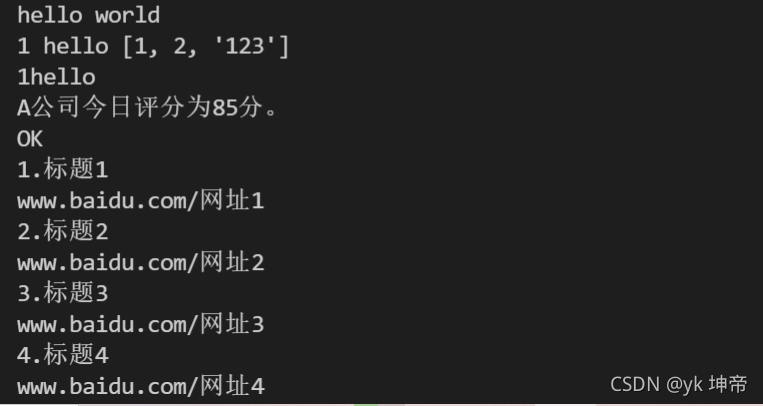
print('hello world')
print(1, 'hello', [1, 2, '123']) # 通過逗號,也可以同時列印多個內容(可以是不同型別的資料),會通過空格自動分隔
print(str(1) + 'hello') # 如果通過+號字串拼接,則需要是同樣是字串型別
# 2 str函式與int函式 - 字串與數字轉換
score = 85
print('A公司今日評分為' + str(score) + '分,') # 不加str就成了字串與數字相加會報錯的
score = '85'
score = int(score) # 不加int的話,下面字串'85'和數字80沒法比較
if score > 80:
print('OK')
# 2 len函式
# len函式可以統計串列里元素的個數
title = ['標題1', '標題2', '標題3', '標題4', '標題5']
href = ['網址1', '網址2', '網址3', '網址4', '網址5']
for i in range(len(title)): # len(title)表示一個有多少個新聞,這里是5
href[i] = 'www.baidu.com/' + href[i] # 這個其實就相當于 a = a + 1
print(str(i+1) + '.' + title[i]) # 這個其實把字串進行一個拼接
print(href[i])
# len函式還可以統計字串個數
a = '123華小智abcd'
print(len(a))
# 4 replace函式 - 替換你想替換的內容
a ='<em>阿里巴巴</em>電商脫貧成“教材” 累計培訓逾萬名縣域干部'
a = a.replace('<em>','')
a = a.replace('</em>','')
print(a)
# 5 strip函式 - 洗掉空白符
a =' 華能信托2018年上半年行業綜合排名位列第5 '
a = a.strip()
print(a)
# 6 split函式 - 分割字串
a = '2018年12月12日 08:07'
a = a.split(' ')[0]
print(a)
# 注意,split分割完是一個串列
a = '2018年12月12日 08:07'
a = a.split(' ')
print(a)
# 7 例外處理函式try except函式,其實應該叫例外處理陳述句,后來調整到1.3.4小節了
try:
print(1 + 'a')
except:
print('主代碼運行失敗')
try:
# 這里是百度新聞爬取的代碼
print(1 + '1')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是百度新聞爬取的代碼,之后第五第七章會講
print(1 + 'a')
print('百度新聞爬取成功')
except:
print('百度新聞爬取失敗')
try:
# 這里是新浪財經新聞爬取的代碼,之后爬蟲進階課會講
print('新浪財經新聞爬取成功')
except:
print('新浪財經新聞爬取失敗')
try:
# 這里是微信推文爬取的代碼,之后爬蟲進階課會講
print('微信推文爬取成功')
except:
print('微信推文爬取失敗')
1.4.4 Python庫與模塊介紹
# =============================================================================
# 1.4.4 Python庫與模塊介紹
# =============================================================================
個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
# 顯示時間的一種方式
import time
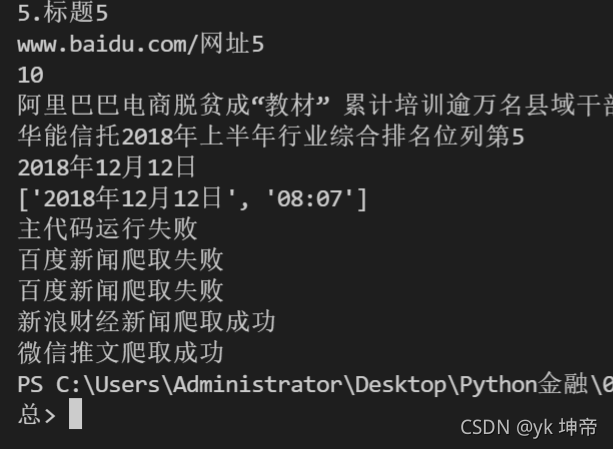
print(time.strftime("%Y/%m/%d"))
# 顯示時間的另一種方式
from datetime import datetime
print(datetime.now())
# 上面的代碼也可以這么寫,不一定要寫成from import
import datetime
print(datetime.datetime.now())
# 嘗試獲取百度首頁的網頁源代碼,可以把這個網址換成別的試試看
import requests
url = 'https://www.baidu.com/'
res = requests.get(url).text
print(res)
# 獲取Python官網首頁的網頁源代碼
import requests
url = 'https://www.python.org'
res = requests.get(url).text
# print(res) # 獲取到的內容較多,感興趣的讀者可以將注釋取消看看運行結果,小技巧:按Ctrl+/可以添加和取消注釋
2.2.1 我的第一個網頁
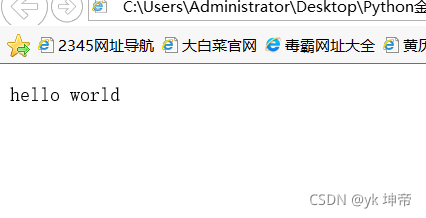
<!DOCTYPE html>
<html>
<p>hello world</p>
</html>
2.2.3 逐漸完善的網頁
<!DOCTYPE html>
<html>
<body>
<h1>���?��� 1</h1>
<p>���?���1���?</p>
<h2>���?��� 2</h2>
<a href="https://www.baidu.com">���?����?�����</a>
</body>
</html>

2.3.1 獲取百度新聞網頁源代碼
# =============================================================================
# 2.3.1 獲取百度新聞網頁源代碼
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融爬蟲 獲取源代碼
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
2.4.1 正則運算式之findall
# =============================================================================
# 2.4.1 正則運算式之findall
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融爬蟲 獲取源代碼
import re
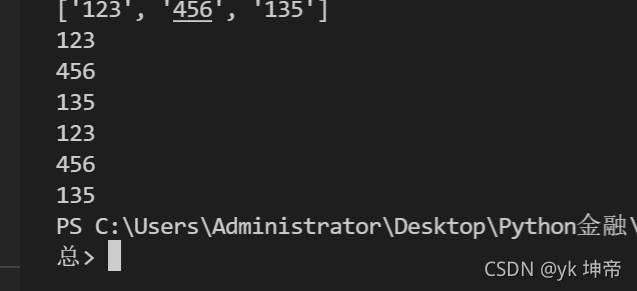
content = 'Hello 123 world 456 華小智Python基礎教學135'
result = re.findall('\d\d\d',content)
print(result)
# 注意獲取到的是一個串列
print(result[0])
print(result[1])
print(result[2])
# 更簡單的遍歷方法,其中len表示串列長度,range(n)表示0到n-1
for i in range(len(result)):
print(result[i])
2.4.2 正則運算式之非貪婪匹配1
# =============================================================================
# 2.4.2 正則運算式之非貪婪匹配1
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融爬蟲 獲取源代碼
# 非貪婪匹配之(.*?) 簡單示例1
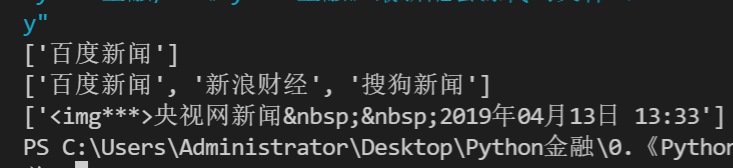
import re
res = '文本A百度新聞文本B'
source = re.findall('文本A(.*?)文本B', res)
print(source)
# 非貪婪匹配之(.*?) 簡單示例2 注意獲取到的結果是一個串列
import re
res = '文本A百度新聞文本B,新聞標題文本A新浪財經文本B,文本A搜狗新聞文本B新聞網址'
p_source = '文本A(.*?)文本B'
source = re.findall(p_source, res)
print(source)
# 非貪婪匹配之(.*?) 實戰演練
import re
res = '<p class="c-author"><img***>央視網新聞 2019年04月13日 13:33</p>'
p_info = '<p class="c-author">(.*?)</p>'
info = re.findall(p_info, res)
print(info)
2.4.3 正則運算式之非貪婪匹配2
# =============================================================================
# 2.4.3 正則運算式之非貪婪匹配2
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融爬蟲 獲取源代碼
# 非貪婪匹配之.*? 簡單示例
import re
res = '<h3>文本C<變化的網址>文本D新聞標題</h3>'
p_title = '<h3>文本C.*?文本D(.*?)</h3>'
title = re.findall(p_title, res)
print(title)
# 非貪婪匹配之.*? 實戰演練
import re
res = '<h3 class="c-title"><a href="網址" data-click="{一堆英文}"><em>阿里巴巴</em>代碼競賽現全球首位AI評委 能為代碼質量打分</a>'
p_title = '<h3 class="c-title">.*?>(.*?)</a>'
title = re.findall(p_title, res)
print(title)

2.4.4 正則運算式之換行
# =============================================================================
# 2.4.4 正則運算式之換行
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融爬蟲 獲取源代碼
import re
res = '''<h3 class="c-title">
<a href="https://baijiahao.baidu.com/s?id=1631161702623128831&wfr=spider&for=pc"
data-click="{
一堆我們不關心的英文
}"
target="_blank"
>
<em>阿里巴巴</em>代碼競賽現全球首位AI評委 能為代碼質量打分
</a>
'''
p_href = '<h3 class="c-title">.*?<a href="(.*?)"'
p_title = '<h3 class="c-title">.*?>(.*?)</a>'
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
print(href)
print(title)
# 清除換行符號
for i in range(len(title)):
title[i] = title[i].strip()
print(title)

2.4.5 正則運算式之小知識點補充
# =============================================================================
# 2.4.5 正則運算式之小知識點補充
# =============================================================================
# 個人公眾號 yk 坤帝
# 后臺回復 python金融爬蟲 獲取源代碼
# 1 re.sub()方法實作批量替換
# 1.1 傳統方法-replace()函式
title = ['<em>阿里巴巴</em>代碼競賽現全球首位AI評委 能為代碼質量打分']
title[0] = title[0].replace('<em>','')
title[0] = title[0].replace('</em>','')
print(title[0])
# 1.2 re.sub()方法
import re
title = ['<em>阿里巴巴</em>代碼競賽現全球首位AI評委 能為代碼質量打分']
title[0] = re.sub('<.*?>', '', title[0])
print(title[0])
# 2 中括號[ ]的用法:使在中括號里的內容不再有特殊含義
company = '*華能信托'
company1 = re.sub('[*]', '', company)
print(company1)

個人公眾號 yk 坤帝
后臺回復 python金融基礎 獲取源代碼
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/301288.html
標籤:python