高并發記憶體池
- 1. 需求分析
- 1.1 直接使用new/delete、malloc/free存在的問題
- 1.2 定長記憶體池的優點和缺點
- 1.3高并發記憶體池要解決的問題
- 2. 總體設計思路
- 3. 申請流程
- 4. 釋放流程
- 5. 細節剖析
- 5.1 ThreadCache
- 5.2 CentralCache
- 5.3 PageCache
- 5.4 PageMap
- 6. 性能測驗
- 7. 專案不足及擴展學習
- 8. Gitee原碼鏈接
- 9. 擴展補充和參考Blog鏈接
1. 需求分析
池化技術是計算機中的一種設計模式,記憶體池是常見的池化技術之一,它能夠有效的提高記憶體的申請和釋放效率以及記憶體碎片等問題,但是傳統的記憶體池也存在一定的缺陷,高并發記憶體池相對于普通的記憶體池它有自己的獨特之處,解決了傳統記憶體池存在的一些問題,
1.1 直接使用new/delete、malloc/free存在的問題
new/delete用于c++中動態記憶體管理而malloc/free在c++和c中都可以使用,本質上new/delete底層封裝了malloc/free,無論是上面的那種記憶體管理方式,都存在以下兩個問題:
- 效率問題:頻繁的在堆上申請和釋放記憶體必然需要大量時間,降低了程式的運行效率,對于一個需要頻繁申請和釋放記憶體的程式來說,頻繁呼叫new/malloc申請記憶體,delete/free釋放記憶體都需要花費系統時間,頻繁的呼叫必然會降低程式的運行效率,
- 記憶體碎片:經常申請小塊記憶體,會將物理記憶體“切”得很碎,導致記憶體碎片,申請記憶體的順序并不是釋放記憶體的順序,因此頻繁申請小塊記憶體必然會導致記憶體碎片,造成“有記憶體但是申請不到大塊記憶體”的現象,
1.2 定長記憶體池的優點和缺點
針對直接使用new/delete、malloc/free存在的問題,定長記憶體池的設計思路是:預先開辟一塊大記憶體,程式需要記憶體時直接從該大塊記憶體中“拿”一塊,提高申請和釋放記憶體的效率,同時直接分配大塊記憶體還減少了記憶體碎片問題,
- 優點:簡單粗暴,分配和釋放的效率高,解決實際中特定場景下的問題有效,
- 缺點:功能單一,只能解決定長的記憶體需求,另外占著記憶體沒有釋放,
對于STL中的空間配置器就是采用的這種方式,當申請小于128位元組的記憶體就是用定長記憶體池,當超過時,就直接使用malloc和free
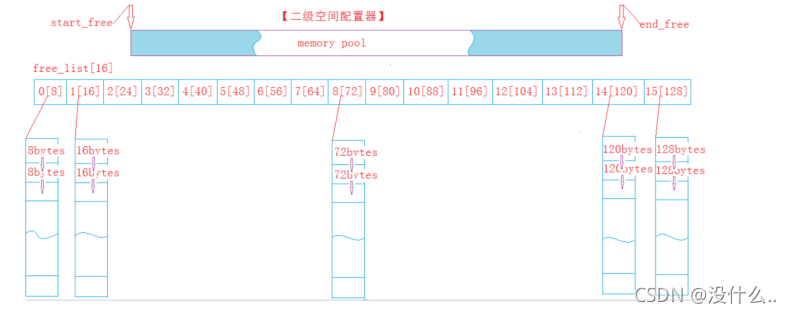
定長記憶體時詳解鏈接:https://blog.csdn.net/MEANSWER/article/details/118343707
1.3高并發記憶體池要解決的問題
基于以上原因,設計高并發記憶體池需要解決以下三個問題:
- 效率問題
- 記憶體碎片問題
- 多執行緒并發場景下的記憶體釋放和申請的鎖競爭問題,
2. 總體設計思路
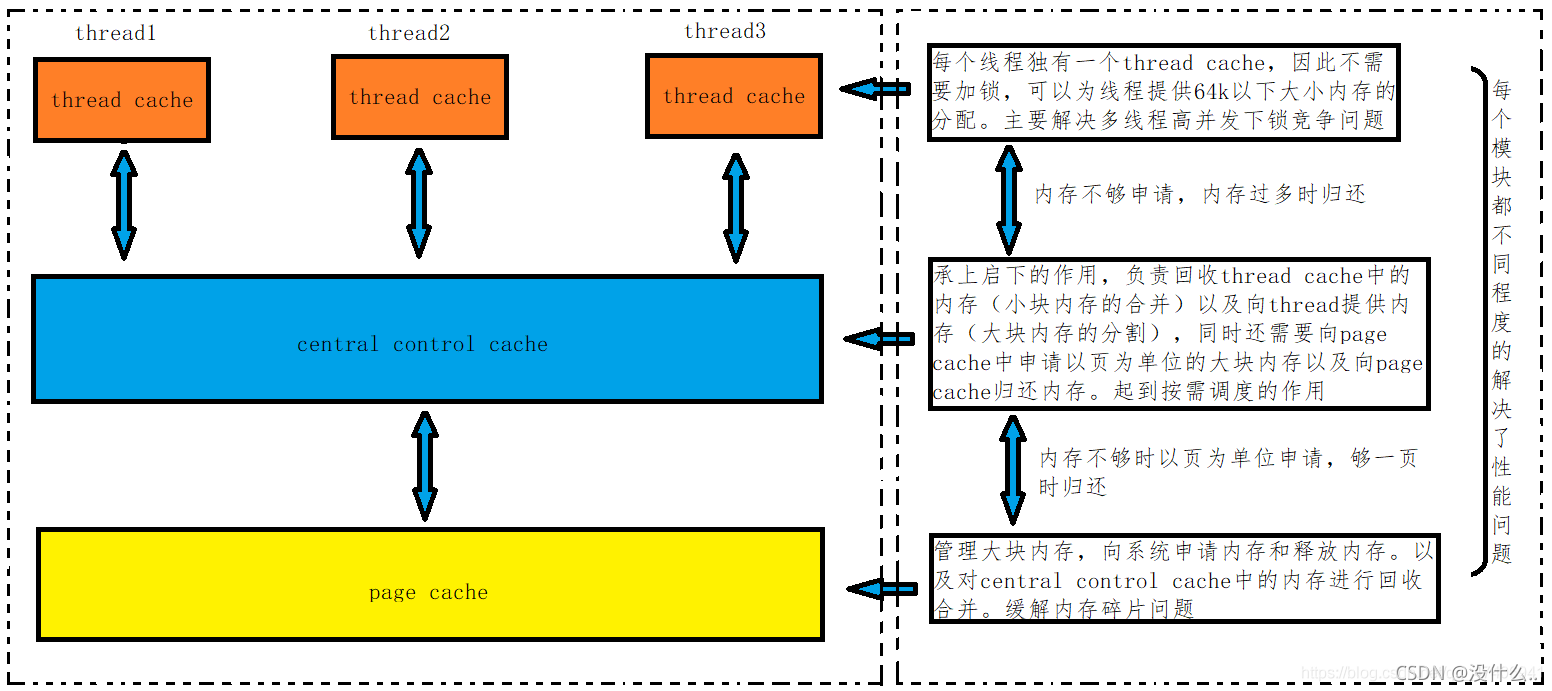
高并發記憶體池整體框架由以下三部分組成,各部分的功能如下:
- 執行緒快取(ThreadCache):每個執行緒獨有執行緒快取,主要解決多執行緒下高并發運行場景執行緒之間的鎖競爭問題,執行緒快取模塊可以為執行緒提供小于64k記憶體的分配,并且多個執行緒并發運行不需要加鎖,
執行緒從這里申請記憶體不需要加鎖,每個執行緒獨享一個ThreadCache,這也就是這個并發記憶體池高效的地方(這就是tcmalloc名字的本質來源,在這里具體的實作采用的是TLS(thread local storage 本地執行緒存盤,可以理解為每個執行緒獨有的全域變數,但是是本地的))),(本質上ThreadCache里面就是由hash映射的定長的記憶體桶) - 中心快取(CentralCache):中心快取是所有執行緒所共享,thread cache是按需從central cache中獲取的物件,central cache周期性的回收thread cache中的物件,避免一個執行緒占用了太多的記憶體,而其他執行緒的記憶體吃緊,達到記憶體分配在多個執行緒中更均衡的按需調度的目的,central cache是存在競爭的,所以從這里取記憶體物件是需要加鎖,(比如說一個執行緒Thread Cache下的8位元組映射的自由鏈表過長,就需要還回Central Cache,但是此時另外的一個執行緒Thread Cache下8位元組的自由鏈表沒有了,就需要向Central Cache要,此時就需要加鎖,因為這種情況很少會出現)不過一般情況下在這里取記憶體物件的效率非常高,所以這里競爭不會很激烈,
- 頁快取(PageCache):以頁為單位申請記憶體,為中心控制快取提供大塊記憶體,當中心控制快取中沒有記憶體物件時,可以從page cache中以頁為單位按需獲取大塊記憶體,同時page cache還會回收central control cache的記憶體進行合并緩解記憶體碎片問題,
注:怎么實作每個執行緒都擁有自己唯一的執行緒快取呢?
- TLS分為靜態的和動態的:
靜態詳解鏈接:https://blog.csdn.net/evilswords/article/details/8191230
動態詳解鏈接:https://blog.csdn.net/yusiguyuan/article/details/22938671
3. 申請流程
我們的并發記憶體池專案對外只暴露兩個介面,對于申請的介面就是ConcurrentAlloc(),如果申請的記憶體大于64KB,直接走的就是PageCache所提供的的NewSpan(),但是走這個也有可能有兩種情況,一種是介于16頁——128頁之間,一開始就會直接的申請上來一塊128頁的記憶體然后進行切分,回傳你需要的那一部分,大于128頁直接呼叫VirtualAlloc進行向系統申請記憶體,如果是小于64KB,那么就會走ThreadCache所提供的Allocate()介面,計算出要找哪一個索引下標的freelist,如果有就直接回傳,沒有則會調會FetchFromCentralCache(),通過你要的記憶體size計算出需要給你回傳的批量個數(慢啟動方式)以及實際上真正能給你回傳的數量呼叫CentralCache的FetchRangeObj(),但是有可能CentralCache中的SpanList[i]下沒有Span或者記憶體都被用完了,所以首先就是得到塊有記憶體的Span,呼叫GetOneSpan()介面,如果該Span中的list不為nullptr說明還有記憶體,如果為空就需要向PageCache要一塊Span,呼叫NewSpan()介面,計算索引看PageCache下是否有合適的頁,如果沒有則需要向后找,在沒有就只能向系統直接申請一塊128頁的記憶體,然后進行切分了,由于CentralCache中的Span都是切好的,所以在得到這個新的頁的時候,也應該按照對應的記憶體大小將他切分好然后在回傳CentralCache
4. 釋放流程
一塊塊記憶體還回來掛接在ThreadCache中對應的FreeList中,當其中一個FreeList掛接的太長的時候就需要進行歸還給CentralCache(這里選擇歸還的條件就是自由鏈表中的記憶體個數Size大于MaxSize),從該FreeList中取出MaxSize個記憶體歸還到CentralCache,但是每一塊小記憶體都可能來自于不同的Span(根據每一塊的小記憶體的起始地址算出它所對應的頁號,然后還有一個map可以通過頁號找到所對應的Span,那么就可以確保每一塊小記憶體都歸還給當初所切出來的Span中),在CentralCache中的每一個大塊Span里面有一個usecount,如果為0的時候,說明分給ThreadCache的記憶體就都還回來了,那么為了能夠合成更大的頁,就需要再把該Span還回PageCache中,每一個大塊的Span里面都有一個PageID(頁號)和頁數,那么就可以進行在PageCache中進行前后的搜索,找到是否還有大塊的Span沒有使用然后進行合并,成為更大的頁,
5. 細節剖析
5.1 ThreadCache
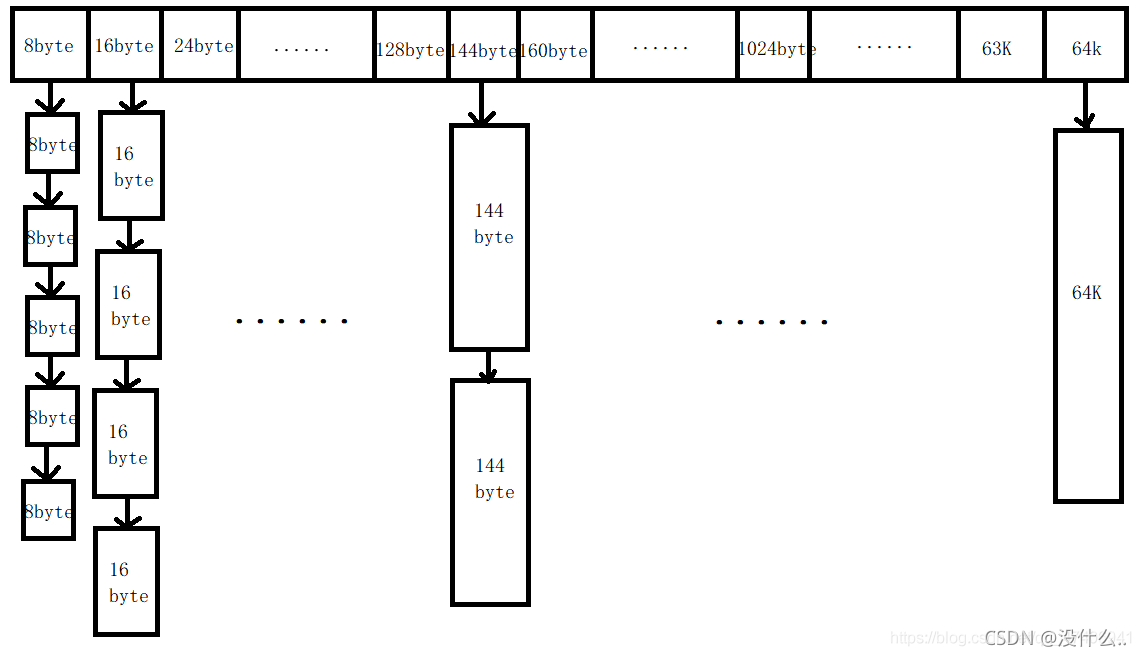
ThreadCache的主要功能就是為每一個執行緒提供64K以下大小記憶體的申請,為了方便管理,需要提供一種特定的管理模式,來保存未分配的記憶體以及被釋放回來的記憶體,以方便記憶體的二次利用,這里的管理通常采用將不同大小的記憶體映射在哈希表中,鏈接起來,而記憶體分配的最小單位是位元組,64k = 102464Byte如果按照一個位元組一個位元組的管理方式進行管理,至少也得需要102464大小的哈希表對不同大小的記憶體進行映射,為了減少哈希表長度,這里采用不同段的記憶體使用不同的記憶體對齊規則,將浪費率保持在1%~12%之間,具體結構如下:

具體說明如下:
- 為了將記憶體碎片浪費保持在12%左右,這里使用不同的對齊數進行對齊,
- 0 ~ 128采用8位元組對齊,129 ~ 1024采用16位元組對齊,1025 ~ 8 * 1024采用128位元組對齊, 8 * 1024~64*1024采用1024位元組對齊;記憶體碎片浪費率分別為:7/8,15/144,127/1152,1023/8 * 1024 + 1024均在12%左右(除了第一塊按照8位元組對齊的浪費率),同時,8位元組對齊時需要[0,15]共16個哈希映射;16位元組對齊需要[16,71]共56個哈希映射;128位元組對齊需要[72,127]共56個哈希映射;1024位元組對齊需要[128,184]共56個哈希映射,
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
// 計算映射的哪一個自由鏈表桶
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
// 每個區間有多少個鏈
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128){
return _Index(bytes, 3);
}
else if (bytes <= 1024){
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8192){
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 65536){
return _Index(bytes - 8192, 10) + group_array[2] + group_array[1] + group_array[0];
}
assert(false);
return -1;
}
ThreadCache.h
#pragma once
#include "Common.h"
class ThreadCache
{
public:
// 申請和釋放記憶體物件
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
// 從中心快取獲取物件
void* FetchFromCentralCache(size_t index, size_t size);
// 釋放物件時,鏈表過長時,回收記憶體回到中心快取
void ListTooLong(FreeList& list, size_t size);
private:
FreeList _freeLists[NFREELISTS];
};
static __declspec(thread) ThreadCache* tls_threadcache = nullptr;
申請記憶體:
- 當記憶體申請size<=64k時在ThreadCache中申請記憶體,計算size在自由鏈表中的位置,如果自由鏈表中有記憶體時,直接從FistList[i]中Pop一下物件,時間復雜度是O(1),且沒有鎖競爭,
- 當FreeList[i]中沒有物件時,則批量從CentralCache中獲取一定數量的記憶體,回傳一個記憶體并將剩余的批量申請上來的記憶體插入到對應的自由鏈表中,
釋放記憶體:
- 當釋放記憶體小于64k時將記憶體釋放回ThreadCache,計算size在自由鏈表中的位置,將物件Push到FreeList[i].
- 當鏈表的長度過長,則回收一部分記憶體到CentralCache,
5.2 CentralCache
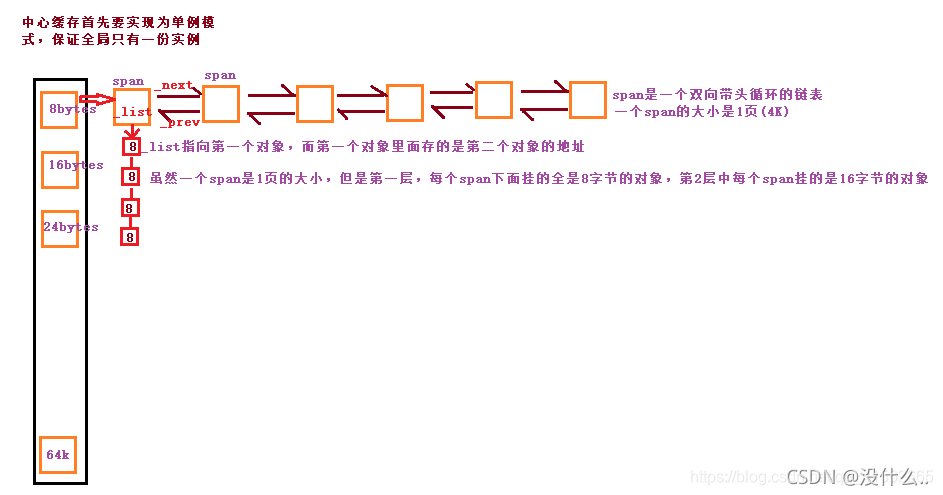
- CentralCache本質是哈希映射的SpanList物件構建的陣列,而SpanList使用的是雙向帶頭回圈鏈表,為的就是能夠更好的插入和洗掉效率更高
- 每一個SpanList后面所掛接的Span,都是為了ThreadCache中特定大小記憶體服務的
- 這里需要注意的是,每一個執行緒都有一個Threadcache,但是Centralcache只有一個,主要就是起到承上啟下的作用,并且需要加鎖,但是力度不需要那么大,加的是桶鎖(當一個執行緒訪問的是CentralCache中8位元組映射的地方,那么另一個執行緒是可以訪問16位元組內的Span的,也就一定程度提高了效率)
- 為了保證全域只有唯一的CentralCache,這個類被可以設計成了單例模式
Centralcache作為Threadcache和Pagecache的橋梁,起到承上啟下的作用,它需要向Threadcache提供切割好的小塊記憶體,同時他還需要回收Threadcache中的過多記憶體,在分配給其他其他Threadcache使用,起到資源調度的作用,如果Centralcache中的span已經完全由Threadcache歸還回來還需要向下層交付,以便合成更大的頁,解決記憶體碎片的問題它的結構如下:
CentralCache.h
#pragma once
#include "Common.h"
//CentralCache是要加鎖的,但是鎖的力度不需要太大,只需要加一個桶鎖,因為只有多個執行緒同時取一個Span
//要保證CentralCache和PageCache物件都是全域唯一的,所以直接使用單例模式
//且這里使用的是餓漢模式---一開始就進行創建(main函式之前就進行了創建)
class CentralCache
{
public:
//回傳指標揮著參考都是可以的
static CentralCache* GetInstance()
{
return &_inst;
}
// 從中心快取獲取一定數量的物件給thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t n, size_t byte_size);
// 從SpanList或者page cache獲取一個span
Span* GetOneSpan(SpanList& list, size_t byte_size);
// 將一定數量的物件釋放到span跨度
void ReleaseListToSpans(void* start, size_t byte_size);
private:
SpanList _spanLists[NFREELISTS]; // 按對齊方式映射 這里的span被切過了,并且有一部分小物件已經切分出去了
private:
CentralCache() = default;
CentralCache(const CentralCache&) = delete;
CentralCache& operator=(const CentralCache&) = delete;
static CentralCache _inst;
};
申請記憶體:
- 一開始當ThreadCache中FreeList下沒有掛接記憶體時,就會批量向CentralCache申請一些記憶體(由于就近原則,在申請了某一大小的記憶體之后,我們有理由他還會再次申請,但是如果一次就只回傳一個,那么下次來還需要再次進入CentralCache中,而這個是會加鎖的,勢必會影響申請的效率,所以就一次回傳“批量”記憶體)
- 但是如果這個“批量”是一個固定的大小,那么萬一他就只是要這一次,那么回傳給ThreadCache的多余記憶體勢必就造成了浪費,所以這里采用了一種慢啟動的方式進行回傳,一開始就回傳一個,隨著你要的次數的增加,他也就會逐漸給你回傳更多
- 但是當進入CentralCache中發現對應的SpanList中的Span也沒有足夠的記憶體時,就需要向PageCache申請一塊Span,根據你要的記憶體大小,來考慮給你回傳的頁的大小(比如說你只需要8位元組的記憶體,那么回傳一頁就足夠了,因為已經可以切割出來很多塊了,但是當你是要一個64K的記憶體時,就給你回傳2頁,這樣來進行控制)
- 從PageCache中回傳來的大塊Span是完整,但是在CentralCache中的Span都是已經被切割好并且被分出去一部分的Span,在Span內有一個freelist,用來管理已經切割好的小塊記憶體,如果分配一塊小記憶體給ThreadCache,就++_usecount,
釋放記憶體:
- 當ThreadCache中的某一個FreeList下的記憶體掛接過長或者執行緒銷毀,則會將記憶體釋放回CentralCache中的,但是由于記憶體歸還的時間順序等都是不知道的,所以每一個歸還回來的小塊記憶體是不知道屬于CentralCache中SpanList中的哪一個Span的,所以開始的時候采用的是使用map<PageID,Span*>構建一個映射,通過還回來的地址右移PAGE_SHIFT(頁的大小),就可以算出屬于哪一個頁,找到該SpanList中對應的Span(這個地方是要修改的,最終設計不是這樣,要改為基數樹)
- 當_usecount減到0時則表示所有物件都回到了span,則將Span需要釋放回PageCache,為的是能夠合出更大的頁,減少記憶體碎片問題,PageCache中會對前后搜索空閑頁進行合并,
5.3 PageCache
Pagecache是以頁為單位進行記憶體管理的,它是將不同頁數的記憶體利用哈希進行映射,最多映射128頁記憶體,具體結構如下:
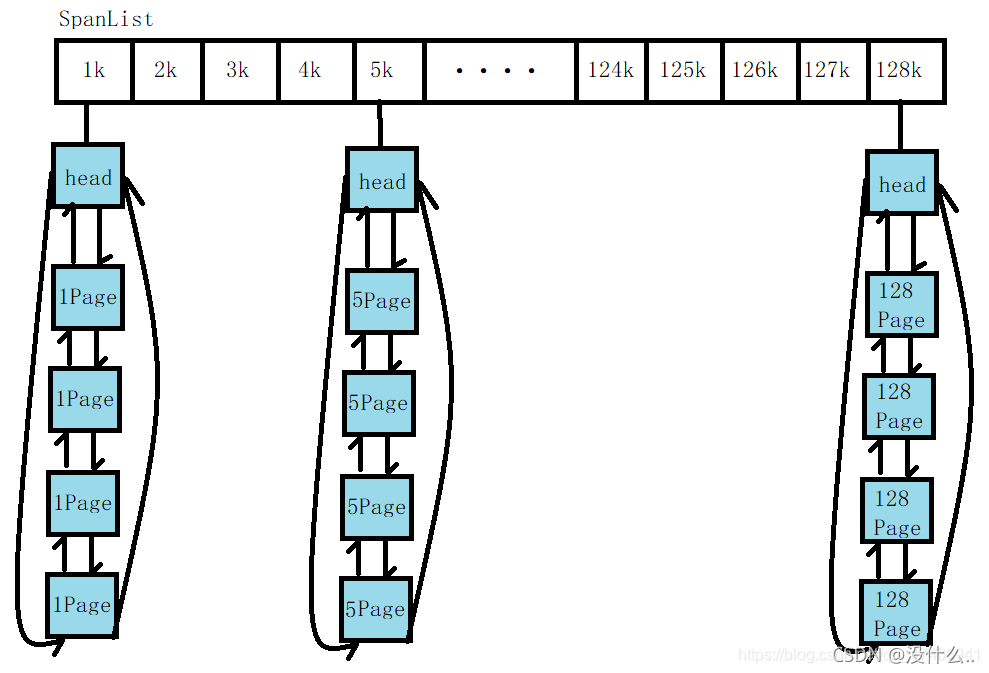
PageCache.h
#pragma once
#include "Common.h"
#include "PageMap.h"
class PageCache
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
// 向系統申請k頁記憶體掛到自由鏈表
void* SystemAllocPage(size_t k);
Span* NewSpan(size_t k);
//獲取從物件到span的映射
Span* MapObjectToSpan(void* obj);
void ReleaseSpanToPageCache(Span* span);
private:
SpanList _spanList[NPAGES]; // 按頁數映射
//std::map<PageID, Span*> _idSpanMap; //這里是有可能多個頁都映射同一個Span的
//tcmalloc 基數樹 效率更高
TCMalloc_PageMap2<32-PAGE_SHIFT> _idSpanMap;
std::recursive_mutex _mtx;
private:
PageCache() = default;
PageCache(const PageCache&) = delete;
PageCache& operator=(const PageCache&) = delete;
static PageCache _sInst;
};
申請流程:
- 對于申請介于16頁和128頁之間記憶體,也會走PageCache中提供的一個介面NewSpan(),會把這塊記憶體依舊封裝成一個Span,為的就是還回來的時候能夠直接將其掛接在PageCache中,那么下一次申請大塊記憶體就不需要向系統申請了,也算提高了效率
- 正常的申請記憶體流程,ThreadCache沒有了,向CacheCache要,CentralCache中也沒有合適的Span的時候,就需要向PageCache要,根據單個記憶體Size的大小計算出你需要的頁數,然后就去PageCache中對應的SpanList中找是否有合適的,如果沒有那就向后繼續找,如果找到了就把這個更大的頁切割為我需要的頁數和剩余的頁數掛接在對應的SpanList中,如果PageCache中后面也沒有更大的,此時就直接向系統申請一塊128頁的記憶體,然后進行切割(這里代碼實作使用的是子函式呼叫,相當于遞回了,所以在這里面加鎖的時候使用的是STL中的recursive_mutex鎖)
釋放流程:
- 當是介于16頁和128頁記憶體的,釋放回來的直接歸還給PageCache中對應的SpanList
- 如果是CentralCache中還回來的Span,首先就是對該Span進行一個清理作業,將他里面的freelist置為nullptr,因為PageCache中的Span都是大塊且沒有別切割過的,還要檢查前后存在沒有使用的頁,如果有就繼續進行合并,為的是能夠合出更大的頁,減少記憶體碎片的問題(但是這里還有一點就是,如果已經128頁了,也就沒有必要在繼續進行合并了,因為PageCache中也沒有能掛下該大塊記憶體的位置)
Page Cache向系統申請記憶體時,前邊我們說過每次直接申請128頁的記憶體,這里需要說明的是,我們的專案中不能出現任和STL中的資料結構和庫函式,因此這里申請記憶體直接采用系統呼叫VirtualAlloc,下面對VirtualAlloc詳細解釋:
函式宣告如下:
LPVOID VirtualAlloc{
LPVOID lpAddress, // 要分配的記憶體區域的地址
DWORD dwSize, // 分配的大小
DWORD flAllocationType, // 分配的型別
DWORD flProtect // 該記憶體的初始保護屬性
};
引數說明:
- LPVOID lpAddress, 分配記憶體區域的地址,當你使用VirtualAlloc來提交一塊以前保留的記憶體塊的時候,lpAddress引數可以用來識別以前保留的記憶體塊,如果這個引數是NULL,系統將會決定分配記憶體區域的位置,并且按64-KB向上取整(roundup),
- SIZE_T dwSize, 要分配或者保留的區域的大小,這個引數以位元組為單位,而不是頁,系統會根據這個大小一直分配到下頁的邊界DWORD
- flAllocationType, 分配型別 ,你可以指定或者合并以下標志:MEM_COMMIT,MEM_RESERVE和MEM_TOP_DOWN,
- DWORD flProtect 指定了被分配區域的訪問保護方式
VirtualAlloc詳解鏈接:https://baike.baidu.com/item/VirtualAlloc/1606859?fr=aladdin
5.4 PageMap
- 首先對于PageCache中所提供的一個MapObjectSpan()介面來說,這是一個對外暴露的介面,別人是可以任意的查看,并且不需要進入到PageCache中,但是保不準在高并發的場景下有另外一個執行緒將其對應關系進行了修改,所以這個介面是要加鎖的,加完鎖以后就發現,本來性能還不錯,一下子變得很差,然后通過VS自帶的性能分析工具進行檢查發現這個介面由于頻繁呼叫,但是還加了鎖導致的,然后通過看tcmalloc的原碼,發現人家在設計這一塊的時候是沒有加鎖的,使用的是一個基數樹結構
- 其實可以把基數樹看成多階哈希的結構,對于32位平臺下,最多可以申請到100多萬頁的記憶體,但是由于虛擬地址空間的分布,排除掉代碼段,初始化未初始化等空間以及最上層的內核區,其實真正能申請到的記憶體也就是堆那一塊的記憶體,所以如果直接使用哈希的直接定制法,那么勢必會導致有大量的最前面和最后面所映射的空間造成浪費,所以對于通過Object找到Span采用了一個兩層的基數樹,第一層開了32的空間(里面不存資料,存的是指向下一層的指標),那么相當于每個空間就有2的15次方頁要在這一塊進行映射,如果沒有使用到這2的15次方內的頁,則就不會開底下的這層空間,如果使用了,則開底下的這層空間,然后找到相對應的位置存上所對應的Span(其實就是取了這塊記憶體地址的后20位,15-19位用在找第一層的位置,0-14位用來找所對應底下的頁映射的位置),這里就是想要通過頁號找到對應的Span
- 我們還想要通過頁號找到對應的該Span中freelist上掛接記憶體的大小,目的就是為了能夠在呼叫ConcurrentFree的時候能夠直接傳釋放記憶體的地址,不需要再傳他的大小,通過分析可以發現,在高并發的場景下,首先給PageCache加鎖,然后一個執行緒從PageCache中申請了一塊Span,需要將他切好,在回傳給CentralCache,那么此時是不可能有執行緒能夠訪問到這塊Span中的地址的,因為他還在PageCache,并且還沒有切好呢,怎么可能訪問到這里面的記憶體,當一個執行緒來讀這塊Span中的freelist下掛接記憶體的大小時,是不可能有執行緒能夠對他已經切分好的size進行修改的,針對這個使用了一個一層的基數樹,目的就是能夠通過Span獲得Size,
基數樹詳解鏈接:https://blog.csdn.net/weixin_36145588/article/details/78365480
6. 性能測驗
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
//創建nworks個執行緒
std::vector<std::thread> vthread(nworks);
size_t malloc_costtime = 0;
size_t free_costtime = 0;
//每個執行緒回圈依次
for (size_t k = 0; k < nworks; ++k)
{
//鋪貨k
vthread[k] = std::thread([&, k]() {
std::vector<void*> v;
v.reserve(ntimes);
//執行rounds輪次
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
//每輪次執行ntimes次
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(malloc(16));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += end1 - begin1;
free_costtime += end2 - begin2;
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u個執行緒并發執行%u輪次,每輪次malloc %u次: 花費:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u個執行緒并發執行%u輪次,每輪次free %u次: 花費:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u個執行緒并發malloc&free %u次,總計花費:%u ms\n",
nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}
// 單輪次申請釋放次數 執行緒數 輪次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
size_t malloc_costtime = 0;
size_t free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(hcAlloc(16));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
hcFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += end1 - begin1;
free_costtime += end2 - begin2;
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u個執行緒并發執行%u輪次,每輪次concurrent alloc %u次: 花費:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u個執行緒并發執行%u輪次,每輪次concurrent dealloc %u次: 花費:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u個執行緒并發concurrent alloc&dealloc %u次,總計花費:%u ms\n",
nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}
int main()
{
cout << "==========================================================" << endl;
BenchmarkMalloc(100000, 4, 10);
cout << endl << endl;
BenchmarkConcurrentMalloc(100000, 4, 10);
cout << "==========================================================" << endl;
return 0;
}
該函式使用了C++11庫里面的thread和lambda運算式,一共4個執行緒,每個執行緒申請釋放記憶體10000次一共執行4輪來對比庫里面的malloc和free
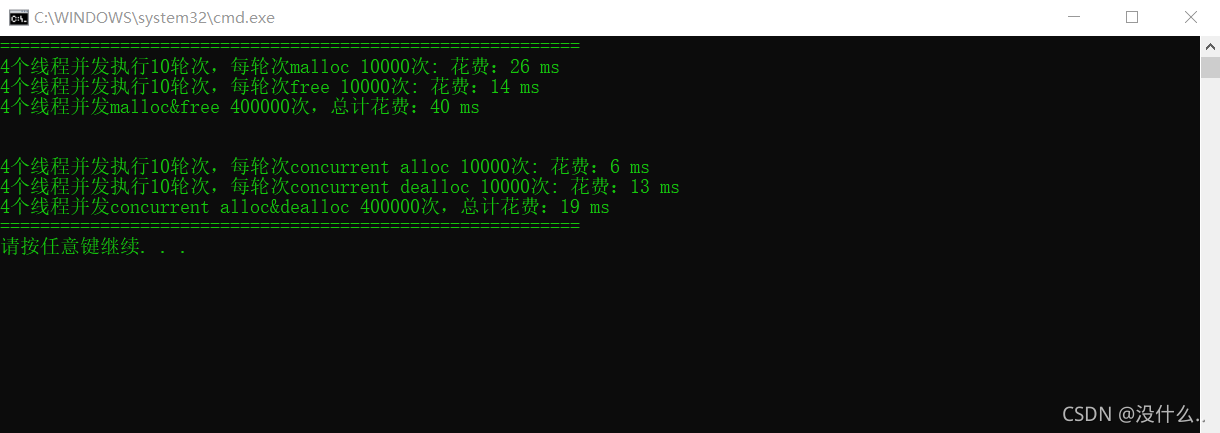
在release版本下,我們所寫的并發記憶體池專案申請和釋放記憶體的確是要更好一些的,
7. 專案不足及擴展學習
-專案的獨立性不足:
- 不足:①當前實作的專案中我們并沒有完全脫離malloc,比如在記憶體池自身資料結構的管理中,如SpanList中的span等結構,我們還是使用的new Span這樣的操作,new的底層使用的是malloc,所以沒有完全脫離malloc,②按理來說連thread、mutex等庫里面的也不可以使用,因為你不確定是否他們的庫里實作使用了new或者malloc申請記憶體③如果此時threadCache銷毀了,如果他還有記憶體怎么辦?
- 解決方案:①專案中增加一個定長的ObjectPool的物件池,物件池的記憶體直接使用brk(Linux平臺)、VirarulAlloc(Windows平臺)等向系統申請,new Span替換成物件池申請記憶體,這樣就完全脫離的malloc,替換掉malloc,(頻繁申請的小塊記憶體入span使用物件池申請空間,大塊記憶體使用:VirtualAlloc),②針對上面的第三點會造成耽誤記憶體還回CentralCache,導致小頁無法合大,注冊一個執行緒結束后回呼清理ThreadCache的記憶體函式,③不同平臺替換方式不同, 基于unix的系統上的glibc,使用了weak alias的方式替換,具體來說是因為這些入口函式都被定義成了weak symbols,再加上gcc支持 alias attribute,所以替換就變成了這種通用形式:void* malloc(size_t size) THROW attribute__ ((alias (tc_malloc))),因此所有malloc的呼叫都跳轉到了tc_malloc的實作④有些平臺不支持這樣的東西,需要使用hook的鉤子技術來做,
- GCC attribute 之weak,alias屬性(實際上就是當我們呼叫malloc的時候,他會自動跳轉到我們自己實作的tc_malloc)
https://blog.csdn.net/BingoAmI/article/details/78683906 - 有些平臺不支持這樣的東西,需要使用hook的鉤子技術來做,詳解鏈接:
https://www.cnblogs.com/feng9exe/p/6015910.html
8. Gitee原碼鏈接
ConcurrentMemoryPool原碼鏈接: https://gitee.com/meanswer/concurrent-memory-pool
9. 擴展補充和參考Blog鏈接
- Linux行程分配記憶體的兩種方式–brk() 和mmap()詳解(這篇文章寫的很好)鏈接:https://www.cnblogs.com/vinozly/p/5489138.html
- 能不能把threadCache和CentralCache合并?角度:CentralCache的核心作用就是承上啟下,CentralCache里面用的是桶鎖,效率更高,
a.CentralCache均衡多個執行緒之間的同一大小的記憶體需求
b. 他的Span都是至少有部分在用的,區分PageCache都是大塊完整
c.它實作的是桶鎖,因為一個span只會給一個桶用,不會再桶之間流動,效率更高,如果沒有他的話,PageCache是一把大鎖,因為PageCache中的span需要切小和合大,會再多個映射桶之間流動, - 幾個記憶體池庫的對比鏈接:https://blog.csdn.net/junlon2006/article/details/77854898
- tcmalloc原始碼學習鏈接:https://www.cnblogs.com/persistentsnail/p/3442185.html
- TCMALLOC 原始碼閱讀鏈接:https://blog.csdn.net/math715/article/details/80654167
- malloc原理詳解鏈接:https://blog.csdn.net/hudazhe/article/details/79535220
- malloc函式實作原理鏈接:https://blog.csdn.net/yeditaba/article/details/53443792
- 參考C++實作高并發記憶體池Blog鏈接: link.
- 鏈接: link.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/301502.html
標籤:java