python爬蟲高效爬取某趣閣小說
這次的代碼是根據我之前的 筆趣閣爬取 的基礎上修改的,因為使用的是自己的ip,所以在請求每個章節的時候需要設定sleep(4~5)才不會被封ip,那么在計算保存的時間,每個章節會花費6-7秒,如果爬取一部較長的小說時,時間會特別的長,所以這次我使用了代理ip,這樣就可以不需要設定睡眠時間,直接大量訪問,
一,獲取免費ip
關于免費ip,我選擇的是站大爺,因為免費ip的壽命很短,所以盡量要使用實時的ip,這里我專門使用getip.py來獲取免費ip,代碼會爬取最新的三十個ip,并以字典的形式回傳兩種,如{’http‘:’ip‘},{’https‘:’ip‘}

!!!!!!這里是另寫了一個py檔案,后續正式寫爬蟲的時候會呼叫,
import requests
from lxml import etree
from time import sleep
def getip():
base_url = 'https://www.zdaye.com'
url = 'https://www.zdaye.com/dayProxy.html'
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"
}
res = requests.get(url, headers=headers)
res.encoding = "utf-8"
dom = etree.HTML(res.text)
sub_urls = dom.xpath('//h3[@class ="thread_title"]/a/@href')
sub_pages =[]
for sub_url in sub_urls:
for i in range(1, 11):
sub_page = (base_url + sub_url).rstrip('.html') + '/' + str(i) + '.html'
sub_pages.append(sub_page)
http_list = []
https_list = []
for sub in sub_pages[:3]:
sub_res = requests.get(sub, headers=headers)
sub_res.encoding = 'utf-8'
sub_dom = etree.HTML(sub_res.text)
ips = sub_dom.xpath('//tbody/tr/td[1]/text()')
ports = sub_dom.xpath('//tbody/tr/td[2]/text()')
types = sub_dom.xpath('//tbody/tr/td[4]/text()')
sleep(3)
sub_res.close()
for ip,port,type in zip(ips, ports,types):
proxies_http = {}
proxies_https= {}
http = 'http://' + ip + ':' + port
https = 'https://' + ip + ':' + port
#分別存盤http和https兩種
proxies_http['http'] = http
http_list.append(proxies_http)
proxies_https['https'] = https
https_list.append(proxies_https)
return http_list,https_list
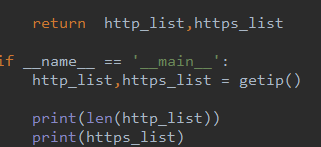
if __name__ == '__main__':
http_list,https_list = getip()
print(http_list)
print(https_list)
二,完整代碼放在最后后面了,這里的 from getip import getip 就是前面獲取ip部分,
這里我收集數十個常用的請求頭,將它們與三十個IP隨機組合,共可以得到300個左右的組合,
這里我定義了三個函式用于實作功能,
biquge_get()函式:輸入搜索頁面的url,關于搜索的實作是修改url中的kw,在main函式中有體現,
--------------------------回傳書籍首頁的url和書名,
get_list()函式:輸入biquge_get回傳的url,
---------------------回傳每個章節的url集合,
info_get()函式:輸入url,ip池,請求頭集,書名,
---------------------將每次的資訊保存到本地,
info_get()函式中我定義四個變數a,b,c,d用于判斷每個章節是否有資訊回傳,在代碼中有寫足夠清晰的注釋,
這里我講一下我的思路,在for回圈中,我回圈的是章節長度的十倍,a,b,c的初始值都是0,
通過索引,url=li_list[a]可以請求每個章節內容,a的自增實作跳到下一個url,但是在大量的請求中也會有無法訪問的情況,所以在回傳的資訊 ’ text1 ‘ 為空的情況a-=1,那么在下一次回圈是依舊會訪問上次沒有結果的url,

這里我遇到了一個坑,我在測驗爬取的時候會列印a的值用于觀察,出現它一直列印同一個章節數‘340’直到回圈結束的情況,此時我以為是無法訪問了,后來我找到網頁對照,發現這個章節本來就沒有內容,是空的,所以程式會一直卡在這里,所以我設定了另外兩個變數b,c,
1,使用變數b來存放未變化的a,若下次回圈b與a相等,說明此次請求沒有成功,c++,因為某些頁面本身存在錯誤沒有資料,則需要跳過,
2,若c大于10,說明超過十次的請求,都因為一些緣由失敗了,則a++,跳過這一章節,同時變數d減一,避免后續跳出回圈時出現索引錯誤

最后是變數d,d的初始值設定為章節長度,d = len(li_list),a增加到與d相同時說明此時li_list的所有url都使用完了,那么就需要跳出回圈,
然后就是將取出的資料保存了,

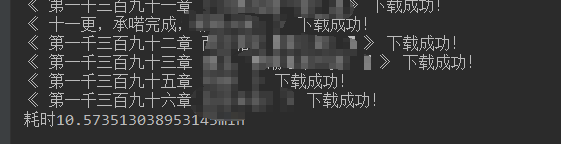
最后測驗,一共1676章,初始速度大概一秒能下載兩章內容左右,

爬取完成,共計用了10分鐘左右,
import requests
from lxml import etree
from getip import getip
import random
import time
headers= {
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"
}
'''
kw輸入完成搜索,列印所有的搜索結果
回傳選擇的書籍的url
'''
def biquge_get(url):
book_info = []
r = requests.get(url =url,
headers = headers,
timeout = 20
)
r.encoding = r.apparent_encoding
html = etree.HTML(r.text)
# 獲取搜索結果的書名
bookname = html.xpath('//td[@class = "odd"]/a/text()')
bookauthor = html.xpath('//td[@class = "odd"]/text()')
bookurl = html.xpath('//td[@class = "odd"]/a/@href')
print('搜索結果如下:\n')
a = 1
b = 1
for i in bookname:
print(str(a) + ':', i, '\t作者:', bookauthor[int(b - 1)])
book_info.append([str(a),i,bookurl[a-1]])
a = a + 1
b = b + 2
c = input('請選擇你要下載的小說(輸入對應書籍的編號):')
book_name = str(bookname[int(c) - 1])
print(book_name, '開始檢索章節')
url2 = html.xpath('//td[@class = "odd"]/a/@href')[int(c) - 1]
r.close()
return url2,book_name
'''
輸入書籍的url,回傳每一章節的url
'''
def get_list(url):
r = requests.get(url = url,
headers = headers,
timeout = 20)
r.encoding = r.apparent_encoding
html = etree.HTML(r.text)
# 決議章節
li_list = html.xpath('//*[@id="list"]/dl//a/@href')[9:]
return li_list
#請求頭集
user_agent = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52"]
'''
引數:url,ip池,請求頭集,書名
'''
def info_get(li_list,ip_list,headers,book_name):
print('共計'+str(len(li_list))+'章')
'''
a,用于計數,成功請求到html并完成后續的存寫資料才會繼續請求下一個url
b,在回圈中存放未經過資訊回傳存盤判斷的a,用于與下一次回圈的a作比較,判斷a是否有變化
c,若超過10次b=a,c會自增,則說明應該跳過此章節,同時d減一
d,章節長度
'''
a = 0
b = 0
c = 0
d = len(li_list)
fp = open('./'+str(book_name)+'.txt', 'w', encoding='utf-8')
#這里回圈了10倍次數的章節,防止無法爬取完所有的資訊,
for i in range(10*len(li_list)):
url = li_list[a]
#判斷使用http還是https
if url[4:5] == "s":
proxies = random.choice(ip_list[0])
else:
proxies = random.choice(ip_list[1])
try:
r = requests.get(url=url,
headers={'User-Agent': random.choice(headers)},
proxies=proxies,
timeout=5
)
r.encoding = r.apparent_encoding
r_text = r.text
html = etree.HTML(r_text)
try:
title = html.xpath('/html/body/div/div/div/div/h1/text()')[0]
except:
title = html.xpath('/html/body/div/div/div/div/h1/text()')
text = html.xpath('//*[@id="content"]/p/text()')
text1 = []
for i in text:
text1.append(i[2:])
'''
使用變數b來存放未變化的a,若下次回圈b與a相等,說明此次請求沒有成功,c++,因為某些頁面本身存在錯誤沒有資料,則需要跳過,
若c大于10,說明超過十次的請求,都因為一些緣由失敗了,則a++,跳過這一章節,同時變數d減一,避免后續跳出回圈時出現索引錯誤
'''
if b == a:
c += 1
if c > 10:
a += 1
c = 0
d -=1
b = a
#a+1,跳到下一個url,若沒有取出資訊則a-1.再次請求,若有資料回傳則保存
a+=1
if len(text1) ==0:
a-=1
else:
fp.write('第'+str(a+1)+'章'+str(title) + ':\n' +'\t'+str(','.join(text1) + '\n\n'))
print('《'+str(title)+'》','下載成功!')
r.close()
except EnvironmentError as e:
pass
# a是作為索引在li_list中取出對應的url,所以最后a的值等于li_list長度-1,并以此為判斷標準是否跳出回圈,
if a == d:
break
fp.close()
if __name__ == '__main__':
kw = input('請輸入你要搜索的小說:')
url = f'http://www.b520.cc/modules/article/search.php?searchkey={kw}'
bookurl,book_name = biquge_get(url)
li_list = get_list(bookurl)
ip_list = getip()
t1 = time.time()
info_get(li_list,ip_list,user_agent,book_name)
t2 = time.time()
print('耗時'+str((t2-t1)/60)+'min')
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/301968.html
標籤:python