Lucene 是 apache 旗下的一個頂級專案,是一個開源的全文檢索引擎工具包;本文主要介紹 Lucene 基本概念及基本使用,文中使用到的軟體版本:Lucene 8.9.0、jdk1.8.0_181,
1、簡介
1.1、全文檢索
全文檢索是一種將檔案中所有文本與檢索項匹配的檢索方法,它可以根據需要獲得全文中有關章、節、段、句、詞等資訊,計算機程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時根據建立的索引查找,類似于通過字典的部首字表查字的程序,
經過幾年的發展,全文檢索從最初的字串匹配程式已經演進到能對超大文本、語音、影像、活動影像等非結構化資料進行綜合管理的大型軟體,
主要應用領域:搜索引擎(百度,搜狗)、站內搜索(微博搜索)、電商網站(京東,淘寶),
1.2、普通資料庫搜索的缺陷
資料庫使用 like 關鍵字來搜索,有如下缺陷:
1、沒有通過高效的索引方式,所以查詢的速度在大量資料的情況下是很慢,
2、搜索效果比較差,只能對用戶輸入的完整關鍵字首尾位進行模糊匹配;用戶搜索的結果誤多輸入一個字符,可能就導致查詢出的結果遠離用戶的預期,
1.2、Lucene
1.2.1、Lucene 是什么
Lucene 是 Apache 旗下的一個開源的全文檢索引擎工具包,它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分文本分析引擎(英文與德文兩種西方語言),Lucene 的目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實作全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎,Lucene提供了一個簡單卻強大的應用程式介面,能夠做全文索引和搜尋,
1.2.2、Lucene 與搜索引擎的區別
全文檢索系統是按照全文檢索理論建立起來的用于提供全文檢索服務的軟體系統,全文檢索系統是一個可以運行的系統,包括建立索引、處理查詢回傳結果集、增加索引、優化索引結構等功能,例如:百度搜索、淘寶網商品搜索,
搜索引擎是全文檢索技術最主要的一個應用,例如:百度,搜索引擎起源于傳統的資訊全文檢索理論,即計算機程式通過掃描每一篇文章中的每一個詞,建立以詞為單位的倒排檔案,檢索程式根據檢索詞在每一篇文章中出現的頻率,對包含這些檢索詞的文章進行排序,最后輸出排序的結果,全文檢索技術是搜索引擎的核心支撐技術,
Lucene 和搜索引擎不同,Lucene 是一套用 Java 寫的全文檢索的工具包,為應用程式提供了很多個 API 介面,可以簡單理解為是一套實作全文檢索的類別庫,搜索引擎是一個全文檢索系統,它是一個能夠單獨運行的軟體,
2、使用
2.1、引入依賴
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>8.9.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>8.9.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>8.9.0</version> </dependency> <dependency> <groupId>com.jianggujin</groupId> <artifactId>IKAnalyzer-lucene</artifactId> <version>8.0.0</version> </dependency>
2.2、創建索引
2.2.1、創建索引程序
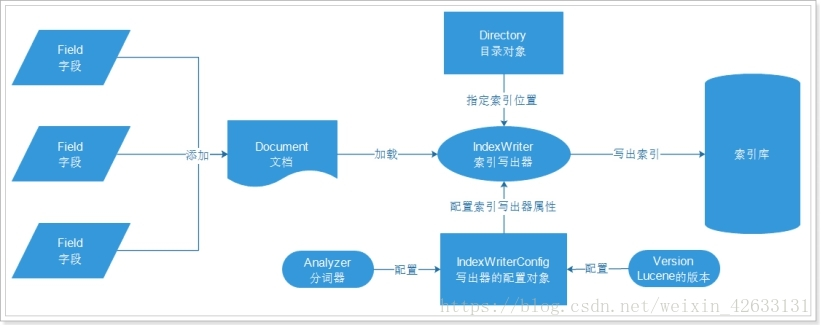
檔案(Document):可理解為資料庫表中一條記錄
欄位(Field):可理解為資料庫表中的一個欄位
目錄物件(Directory):物理存盤位置
寫出器的配置物件:需要分詞器
2.2.2、代碼實作
/** * 創建索引 * @throws Exception */ @Test public void createIndex() throws Exception { Document document = new Document(); document.add(new LongPoint("id", 123456)); //存盤用 document.add(new StoredField("id", 123456)); //排序用 document.add(new NumericDocValuesField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "靜夜思", Field.Store.YES)); document.add(new TextField("about", "字太白", Field.Store.NO)); document.add(new TextField("success", "創造了古代浪漫主義文學高峰、歌行體和七絕達到后人難及的高度", Field.Store.YES)); Document document2 = new Document(); document2.add(new LongPoint("id", 123457)); //存盤用 document2.add(new StoredField("id", 123457)); //排序用 document2.add(new NumericDocValuesField("id", 123457)); document2.add(new IntPoint("age", 21)); document2.add(new StringField("name", "杜甫", Field.Store.YES)); document2.add(new TextField("poems", "登高", Field.Store.YES)); document2.add(new TextField("about", "字子美", Field.Store.NO)); document2.add(new TextField("success", "唐代偉大的現實主義文學作家,唐詩思想藝術的集大成者", Field.Store.YES)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); //添加檔案 indexWriter.addDocument(document); indexWriter.addDocument(document2); indexWriter.commit(); indexWriter.close(); }
2.3、查詢索引
2.3.1、通用查詢方法
通過 Query 物件來查詢索引:
private void query(Query query) throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); //查詢前10條資料 TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "條資料"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); //logger.info(document.toString()); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } }
2.3.2、詞條查詢
/** * 詞條查詢 * Term(詞條)是搜索的最小單位,不可再分詞,值必須是字串, */ @Test public void termQuery() throws IOException { Query query = new TermQuery(new Term("name", "李白")); query(query); }
2.3.3、通配符查詢
/** * 通配符查詢 * ? 代表任意一個字符 * * 代表任意多個字符 * @throws IOException */ @Test public void wildcardQuery() throws IOException { Query query = new WildcardQuery(new Term("name", "李?")); query(query); }
2.3.4、模糊查詢
/** * 模糊查詢 * 允許用戶輸錯,可以設定錯誤的最大編輯距離 * @throws IOException */ @Test public void fuzzyQuery() throws IOException { //"李百"->"李白",只需修改一次,故可以搜索到資料;"里百"則搜索不到資料 Query query = new FuzzyQuery(new Term("name", "里百"), 1); query(query); }
2.3.5、數值查詢
/** * 數值查詢 * @throws IOException */ @Test public void numberQuery() throws IOException { //精確查詢 Query query = LongPoint.newExactQuery("id", 123456); query(query); //符圍查詢 query = LongPoint.newRangeQuery("id", 123L, 12345678L); query(query); }
2.3.6、組合查詢
/** * 組合查詢 * Occur.MUST:必須滿足,相當于and * Occur.SHOULD:應該滿足,但是不滿足也可以,相當于or * Occur.MUST_NOT:必須不滿足,相當于not */ @Test public void booleanQuery() throws IOException { Query query1 = new TermQuery(new Term("name", "李白")); Query query2 = new TermQuery(new Term("name", "杜甫")); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); }
2.3.7、權重查詢
/** * 設定查詢權重,影響查詢結果排序 * @throws IOException */ @Test public void boostQuery() throws IOException { Query query1 = new BoostQuery(new TermQuery(new Term("name", "李白")), 1.5f); Query query2 = new BoostQuery(new TermQuery(new Term("name", "杜甫")), 1.6f); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); }
2.3.8、分詞查詢
/** * 分詞查詢 * @throws Exception */ @Test public void queryParserQuery() throws Exception { QueryParser queryParser = new QueryParser("name", new IKAnalyzer()); Query query = queryParser.parse("李白和杜甫"); query(query); //多欄位查詢 MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(new String[]{"name", "about"}, new IKAnalyzer()); query = multiFieldQueryParser.parse("李白和子美"); query(query); }
2.4、洗掉索引
/** * 洗掉索引 * 洗掉匹配的檔案,更新或洗掉檔案對應的索引,更新是更新索引與檔案的對關系 * @throws IOException */ @Test public void deleteIndex() throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.deleteDocuments(new Term("name", "李白")); //indexWriter.deleteAll(); indexWriter.commit(); indexWriter.close(); }
2.5、更新索引
/** * 更新索引,會先洗掉索引,再添加索引 * 相當于 deleteIndex() 和 createIndex() * @throws IOException */ @Test public void updateIndex() throws IOException { Document document = new Document(); document.add(new LongPoint("id", 123456)); document.add(new StoredField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "望天門山", Field.Store.YES)); document.add(new TextField("about", "號青蓮居士", Field.Store.NO)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.updateDocument(new Term("name", "李白"), document); indexWriter.commit(); indexWriter.close(); }
2.6、高亮顯示
/** * 高亮顯示,增加html標簽,根據需要針對標簽設定自定義的樣式 * @throws Exception */ @Test public void highlighter() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文學"); TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "條資料"); Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>"); QueryScorer queryScorer = new QueryScorer(query); Highlighter highlighter = new Highlighter(formatter, queryScorer); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); String success = document.get("success"); String successHL = highlighter.getBestFragment(new IKAnalyzer(), "success", success); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), successHL, scoreDoc.score); } }
2.7、排序
/** * 排序 * @throws Exception */ @Test public void sort() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文學"); Sort sort = new Sort(new SortField("id", SortField.Type.LONG, false)); TopDocs topDocs = indexSearcher.search(query, 10, sort); logger.info("本次搜索共找到" + topDocs.totalHits.value + "條資料"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } }
2.8、完整代碼
上面例子的完整代碼:


package com.abc.demo.general.lucene; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.document.*; import org.apache.lucene.index.*; import org.apache.lucene.queryparser.classic.MultiFieldQueryParser; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.*; import org.apache.lucene.search.highlight.Formatter; import org.apache.lucene.search.highlight.Highlighter; import org.apache.lucene.search.highlight.QueryScorer; import org.apache.lucene.search.highlight.SimpleHTMLFormatter; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.IOException; import java.nio.file.Paths; /** * Lucene 使用列子 */ public class LuceneCase { private static Logger logger = LoggerFactory.getLogger(LuceneCase.class); /** * 創建索引 * @throws Exception */ @Test public void createIndex() throws Exception { Document document = new Document(); document.add(new LongPoint("id", 123456)); //存盤用 document.add(new StoredField("id", 123456)); //排序用 document.add(new NumericDocValuesField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "靜夜思", Field.Store.YES)); document.add(new TextField("about", "字太白", Field.Store.NO)); document.add(new TextField("success", "創造了古代浪漫主義文學高峰、歌行體和七絕達到后人難及的高度", Field.Store.YES)); Document document2 = new Document(); document2.add(new LongPoint("id", 123457)); //存盤用 document2.add(new StoredField("id", 123457)); //排序用 document2.add(new NumericDocValuesField("id", 123457)); document2.add(new IntPoint("age", 21)); document2.add(new StringField("name", "杜甫", Field.Store.YES)); document2.add(new TextField("poems", "登高", Field.Store.YES)); document2.add(new TextField("about", "字子美", Field.Store.NO)); document2.add(new TextField("success", "唐代偉大的現實主義文學作家,唐詩思想藝術的集大成者", Field.Store.YES)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); //添加檔案 indexWriter.addDocument(document); indexWriter.addDocument(document2); indexWriter.commit(); indexWriter.close(); } /** * 詞條查詢 * Term(詞條)是搜索的最小單位,不可再分詞,值必須是字串, */ @Test public void termQuery() throws IOException { Query query = new TermQuery(new Term("name", "李白")); query(query); } /** * 通配符查詢 * ? 代表任意一個字符 * * 代表任意多個字符 * @throws IOException */ @Test public void wildcardQuery() throws IOException { Query query = new WildcardQuery(new Term("name", "李?")); query(query); } /** * 模糊查詢 * 允許用戶輸錯,可以設定錯誤的最大編輯距離 * @throws IOException */ @Test public void fuzzyQuery() throws IOException { //"李百"->"李白",只需修改一次,故可以搜索到資料;"里百"則搜索不到資料 Query query = new FuzzyQuery(new Term("name", "里百"), 1); query(query); } /** * 數值查詢 * @throws IOException */ @Test public void numberQuery() throws IOException { //精確查詢 Query query = LongPoint.newExactQuery("id", 123456); query(query); //符圍查詢 query = LongPoint.newRangeQuery("id", 123L, 12345678L); query(query); } /** * 組合查詢 * Occur.MUST:必須滿足,相當于and * Occur.SHOULD:應該滿足,但是不滿足也可以,相當于or * Occur.MUST_NOT:必須不滿足,相當于not */ @Test public void booleanQuery() throws IOException { Query query1 = new TermQuery(new Term("name", "李白")); Query query2 = new TermQuery(new Term("name", "杜甫")); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); } /** * 設定查詢權重,影響查詢結果排序 * @throws IOException */ @Test public void boostQuery() throws IOException { Query query1 = new BoostQuery(new TermQuery(new Term("name", "李白")), 1.5f); Query query2 = new BoostQuery(new TermQuery(new Term("name", "杜甫")), 1.6f); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); } /** * 分詞查詢 * @throws Exception */ @Test public void queryParserQuery() throws Exception { QueryParser queryParser = new QueryParser("name", new IKAnalyzer()); Query query = queryParser.parse("李白和杜甫"); query(query); //多欄位查詢 MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(new String[]{"name", "about"}, new IKAnalyzer()); query = multiFieldQueryParser.parse("李白和子美"); query(query); } private void query(Query query) throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); //查詢前10條資料 TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "條資料"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); //logger.info(document.toString()); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } } /** * 洗掉索引 * 洗掉匹配的檔案,更新或洗掉檔案對應的索引,更新是更新索引與檔案的對關系 * @throws IOException */ @Test public void deleteIndex() throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.deleteDocuments(new Term("name", "李白")); //indexWriter.deleteAll(); indexWriter.commit(); indexWriter.close(); } /** * 更新索引,會先洗掉索引,再添加索引 * 相當于 deleteIndex() 和 createIndex() * @throws IOException */ @Test public void updateIndex() throws IOException { Document document = new Document(); document.add(new LongPoint("id", 123456)); document.add(new StoredField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "望天門山", Field.Store.YES)); document.add(new TextField("about", "號青蓮居士", Field.Store.NO)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.updateDocument(new Term("name", "李白"), document); indexWriter.commit(); indexWriter.close(); } /** * 高亮顯示,增加html標簽,根據需要針對標簽設定自定義的樣式 * @throws Exception */ @Test public void highlighter() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文學"); TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "條資料"); Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>"); QueryScorer queryScorer = new QueryScorer(query); Highlighter highlighter = new Highlighter(formatter, queryScorer); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); String success = document.get("success"); String successHL = highlighter.getBestFragment(new IKAnalyzer(), "success", success); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), successHL, scoreDoc.score); } } /** * 排序 * @throws Exception */ @Test public void sort() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文學"); Sort sort = new Sort(new SortField("id", SortField.Type.LONG, false)); TopDocs topDocs = indexSearcher.search(query, 10, sort); logger.info("本次搜索共找到" + topDocs.totalHits.value + "條資料"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } } }LuceneCase.java
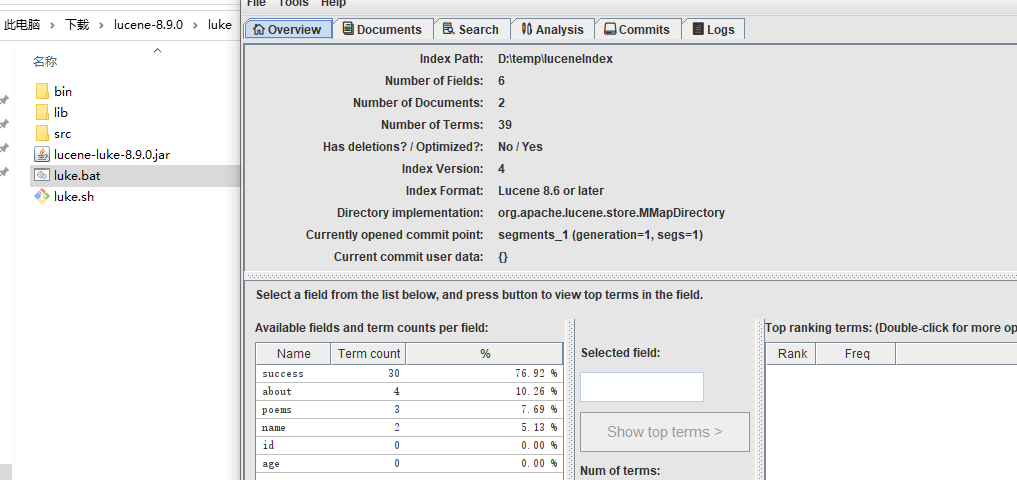
2.9、Luke 工具查看索引
下載的 Lucene 包里包含了 Luke 工具,運行 $LUCENE_HOME/luke/luke.bat,即可打開工具,選擇索引目錄后即可查看索引了:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/302065.html
標籤:Java