文章目錄
- Python 二級等考(第三季)精品題5
- 單項選擇題
- 第一題
- 第二題
- 第三題
- 第四題
- 第五題
- 第六題
- 第七題
- 第八題
- 第九題
- 第十題
- 第十一題
- 第十二題
- 第十三題
- 第十四題
- 第十五題
- 第十六題
- 第十七題
- 第十八題
- 第十九題
- 第二十題
- 第二十一題
- 第二十二題
- 第二十三題
- 第二十四題
- 第二十五題
- 第二十六題
- 第二十七題
- 第二十八題
- 第二十九題
- 第三十題
- 第三十一題
- 第三十二題
- 第三十三題
- 第三十四題
- 第三十五題
- 第三十六題
- 第三十七題
- 第三十八題
- 第三十九題
- 第四十題
- 程式設計題
- 第一題
- 第二題
- 第三題
- 第四題
- 第五題
- 第六題
Python 二級等考(第三季)精品題5
單項選擇題
第一題

第二題
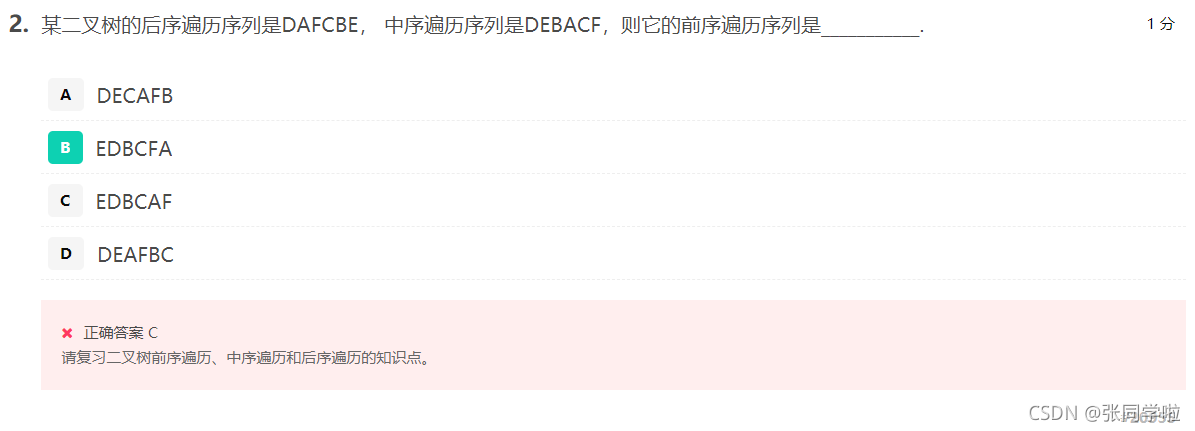
第三題
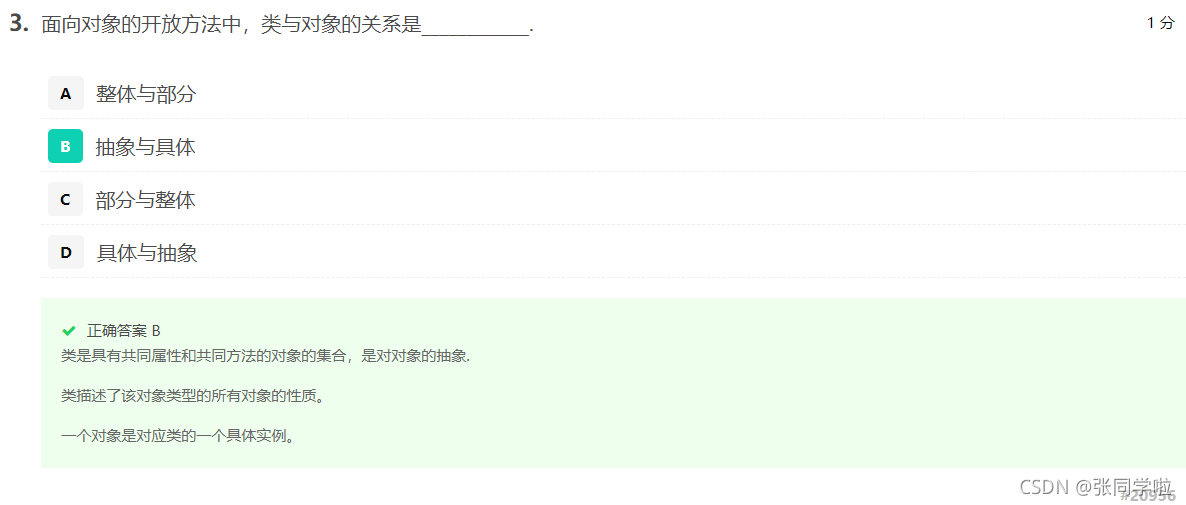
第四題

第五題
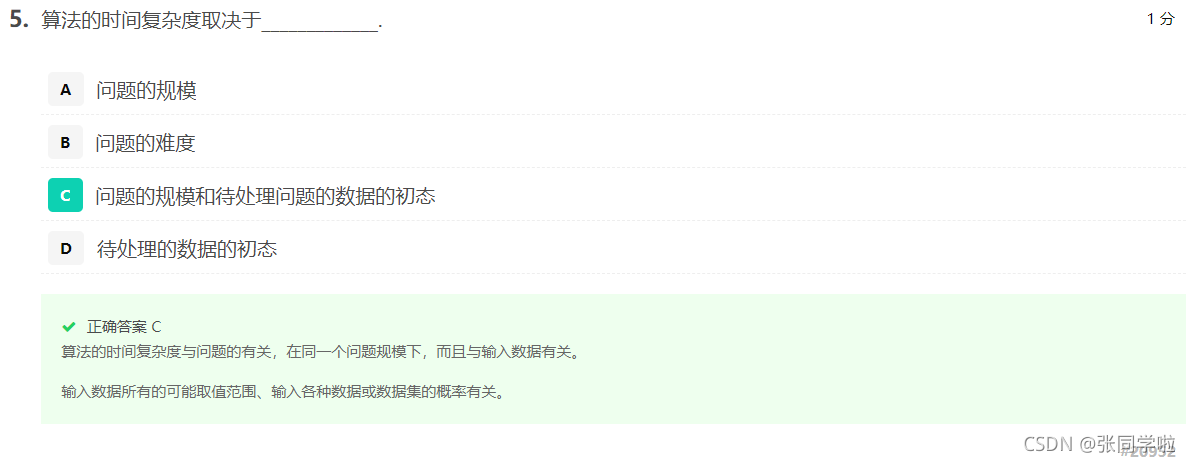
第六題
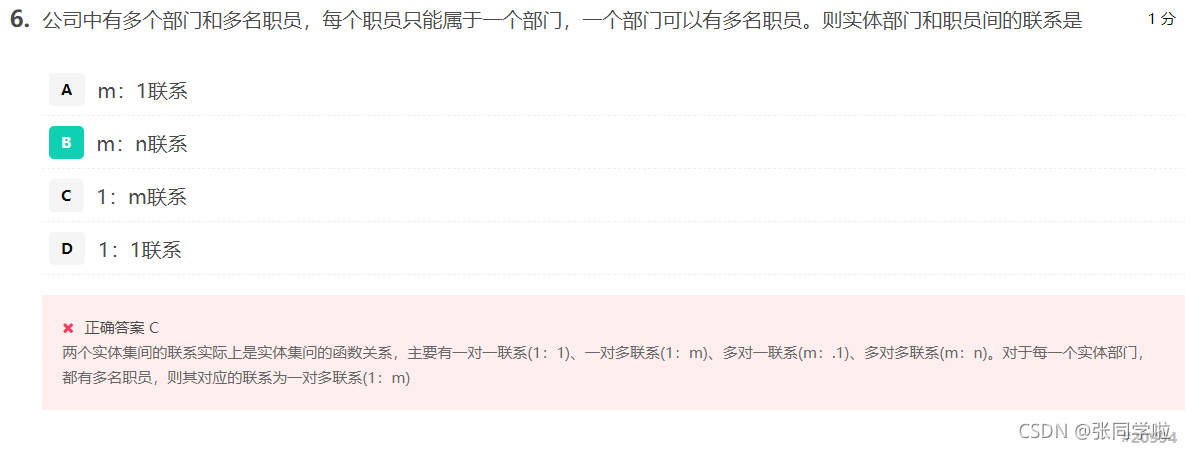
第七題
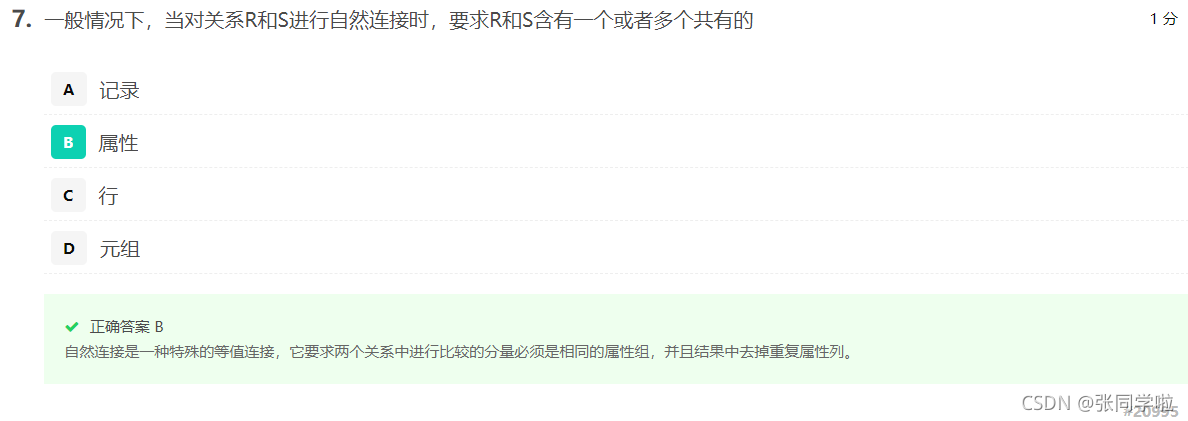
第八題
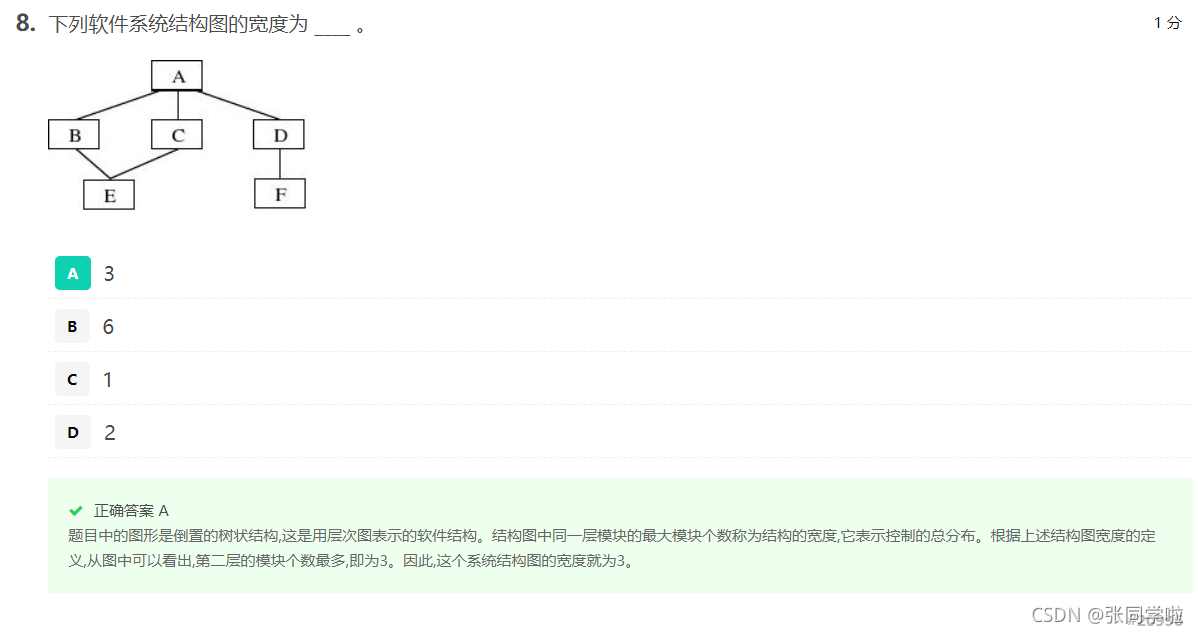
第九題

第十題
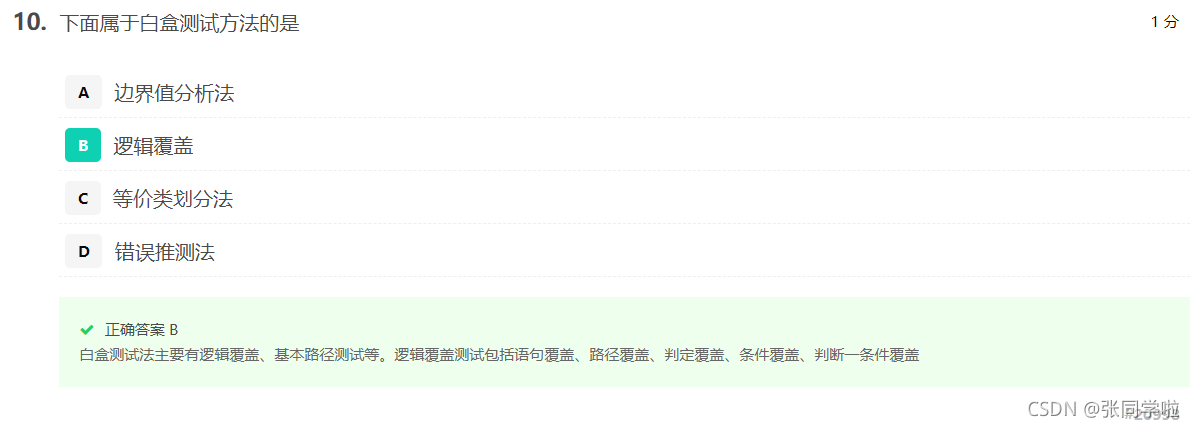
第十一題
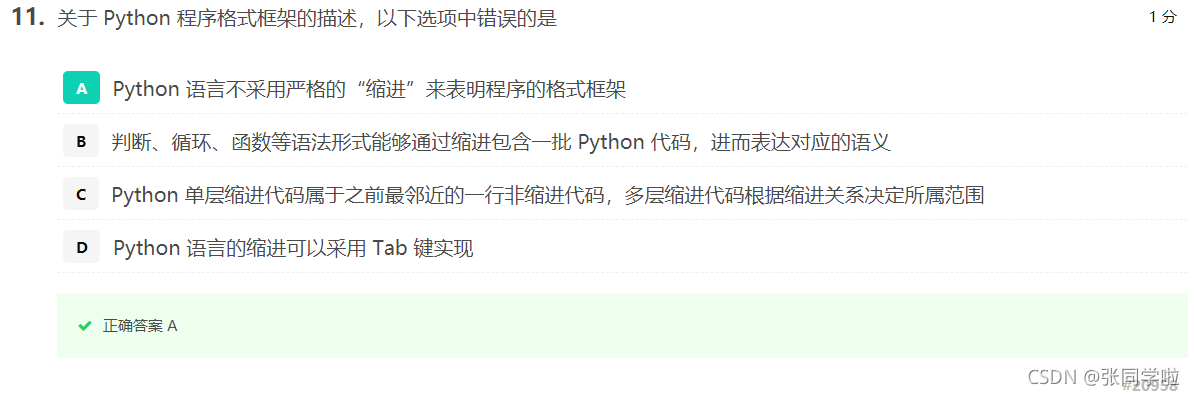
第十二題

第十三題

第十四題

第十五題
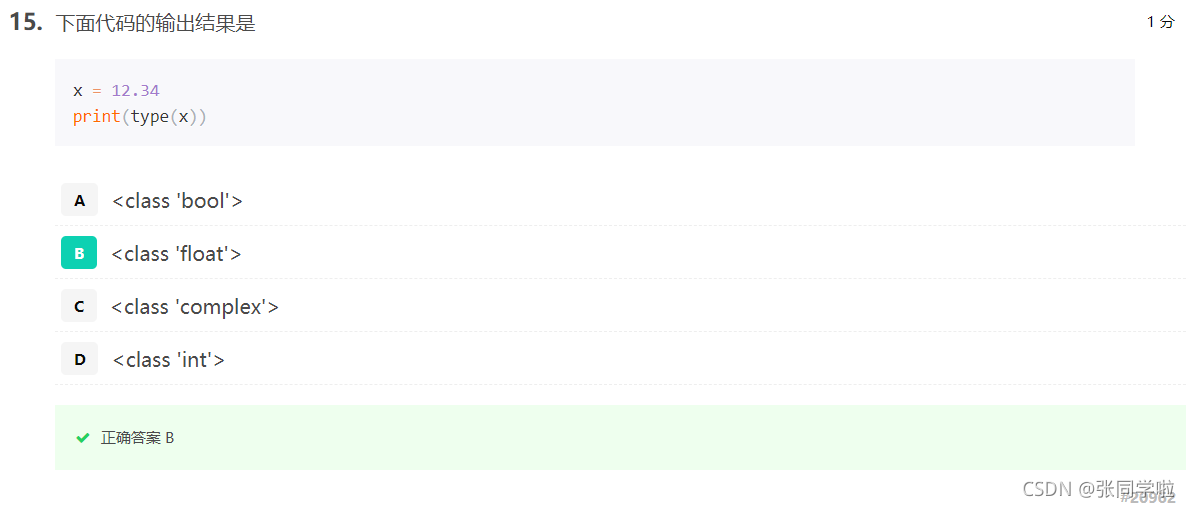
第十六題

第十七題
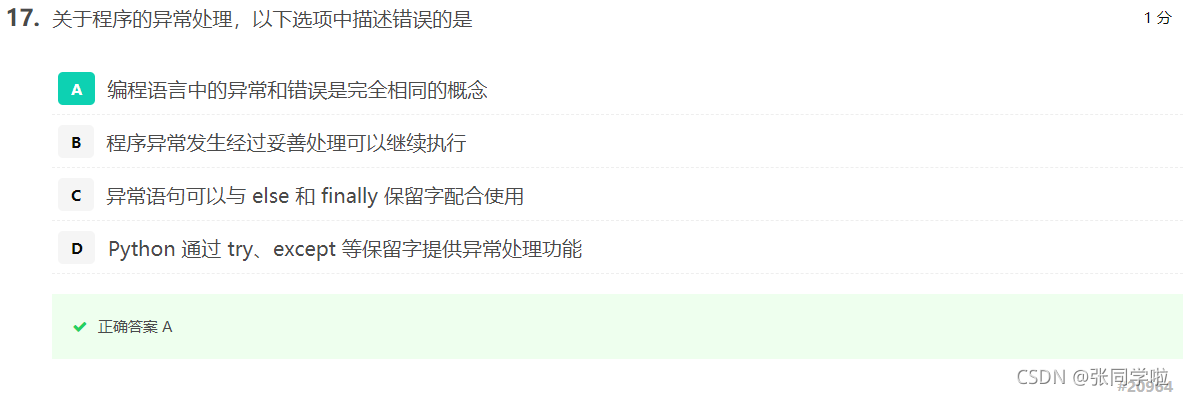
第十八題
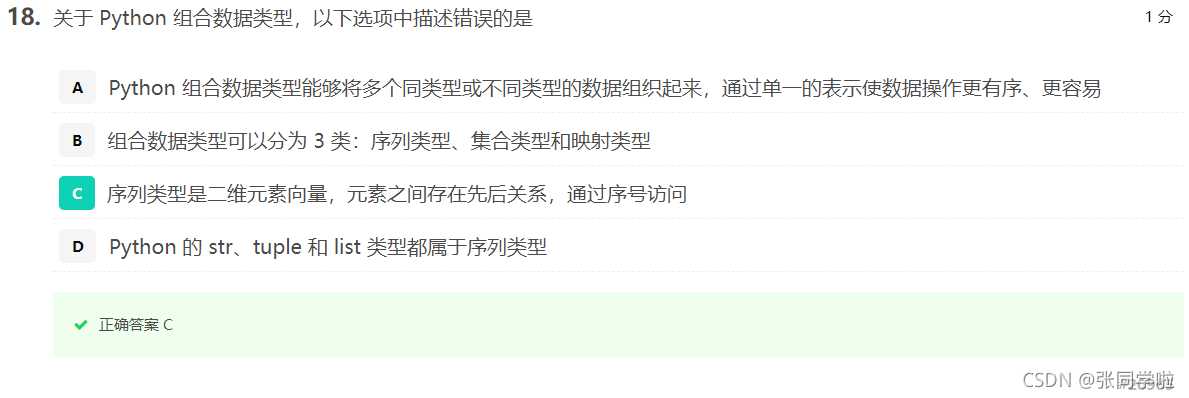
第十九題

第二十題
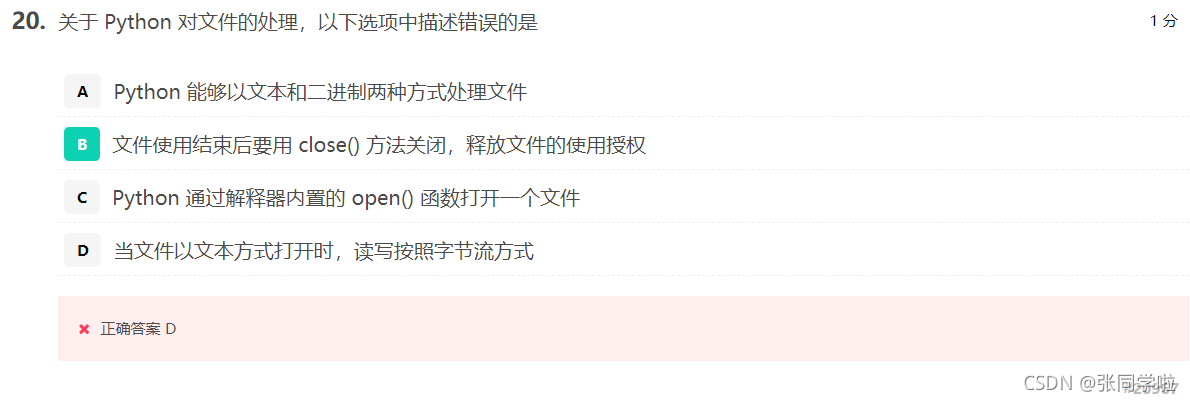
第二十一題

第二十二題

第二十三題

第二十四題

第二十五題

第二十六題
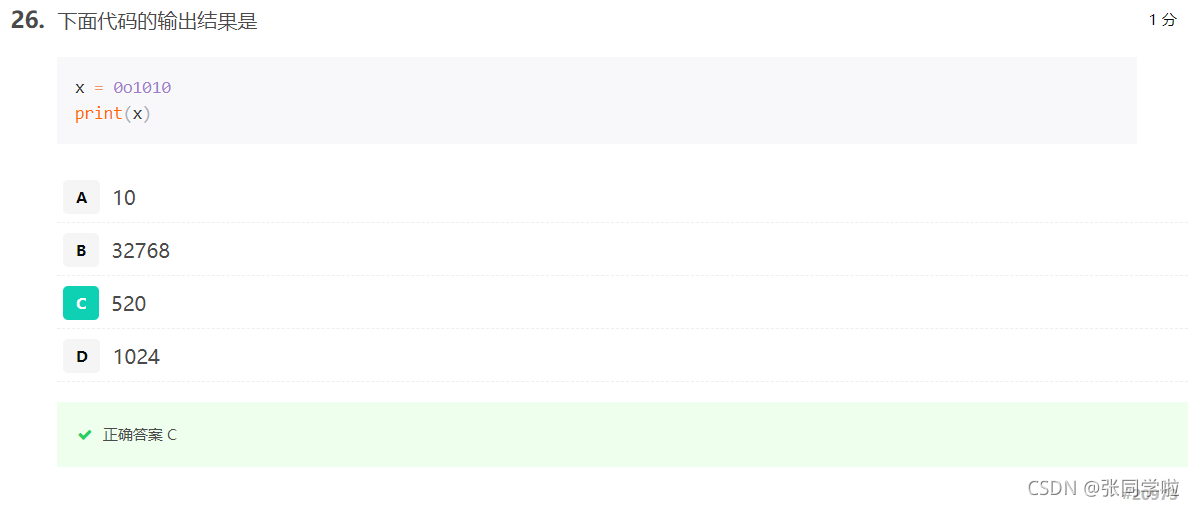
第二十七題
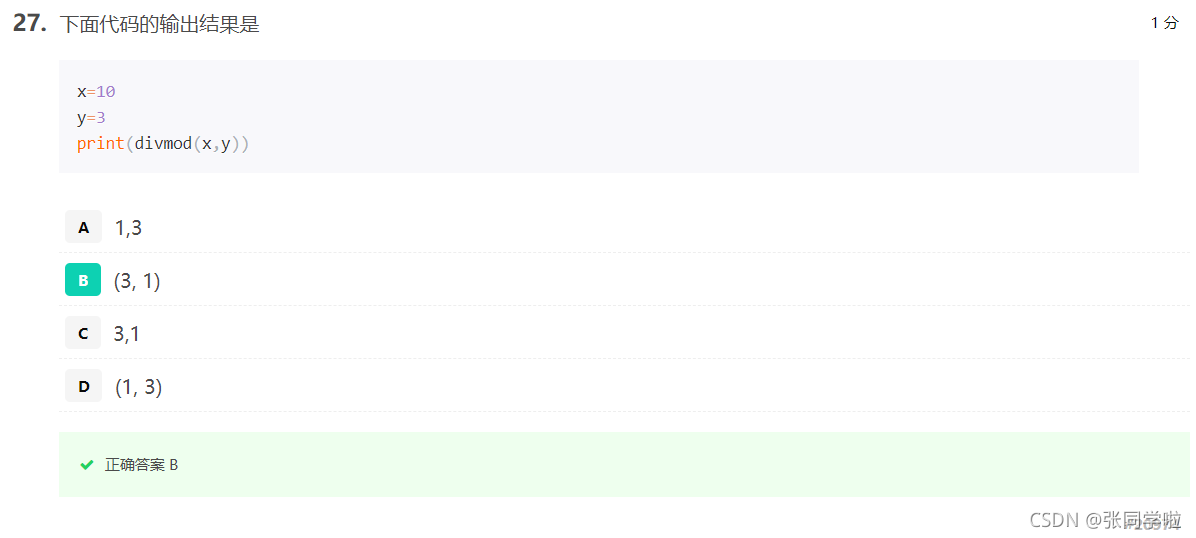
第二十八題
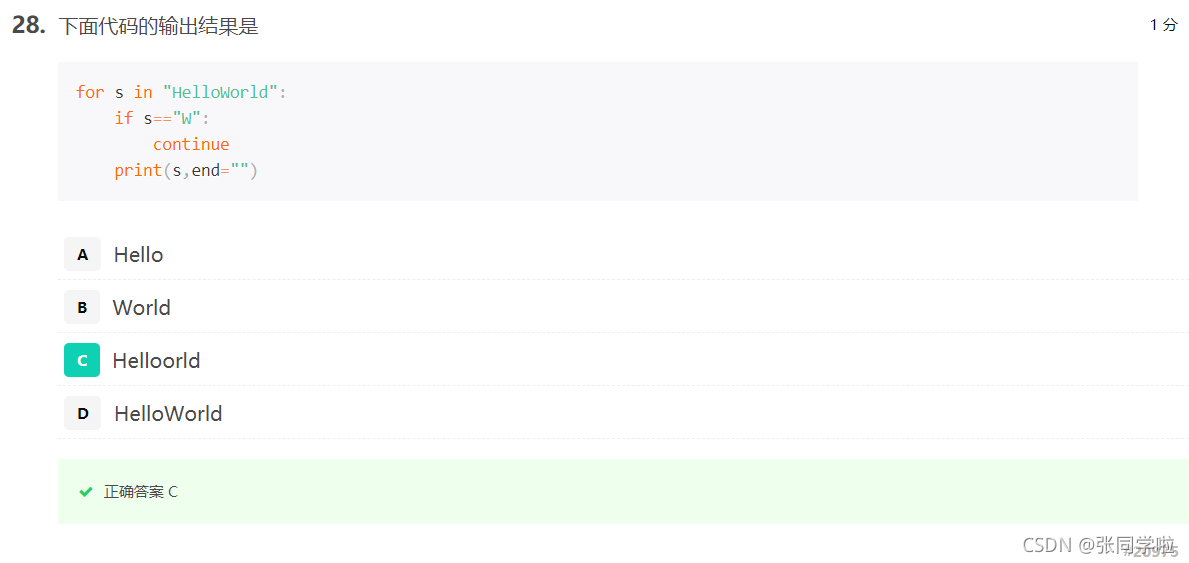
第二十九題

第三十題
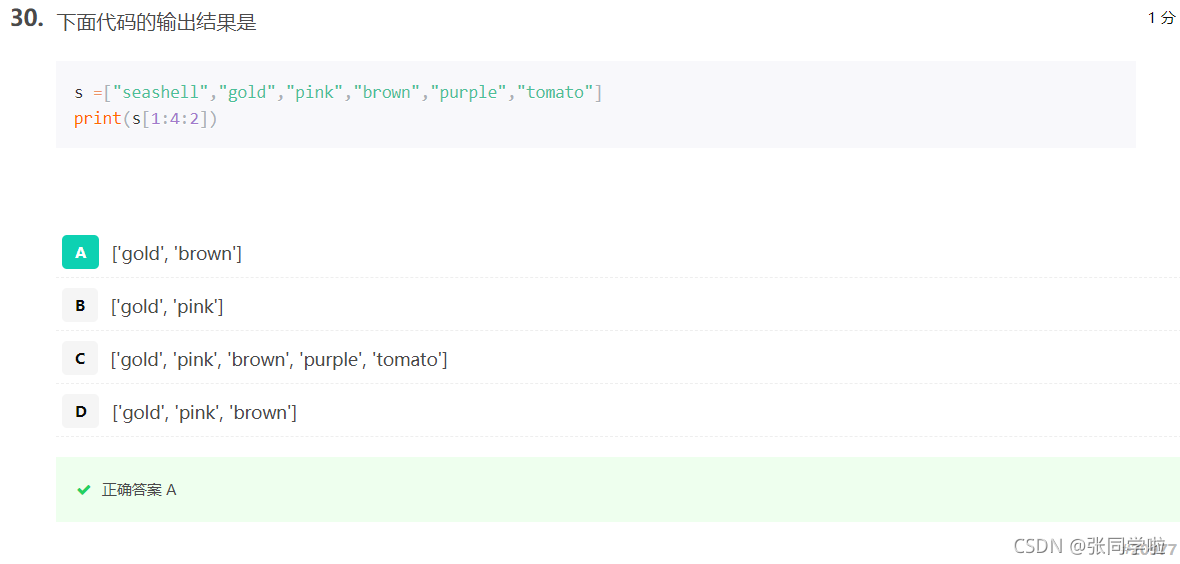
第三十一題

第三十二題
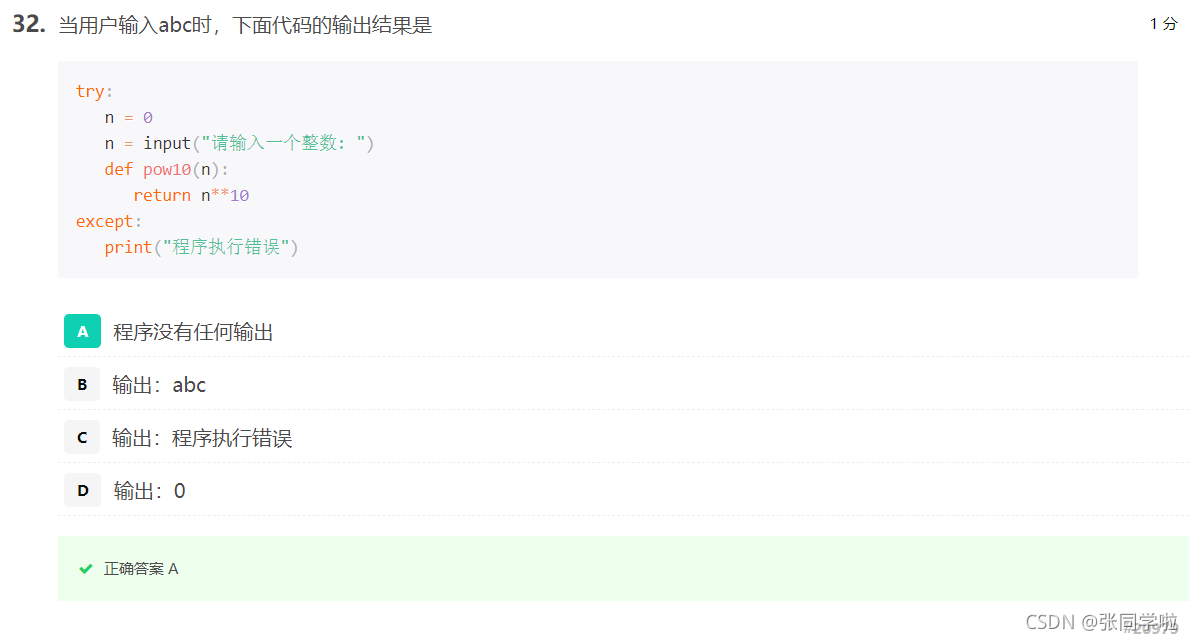
第三十三題
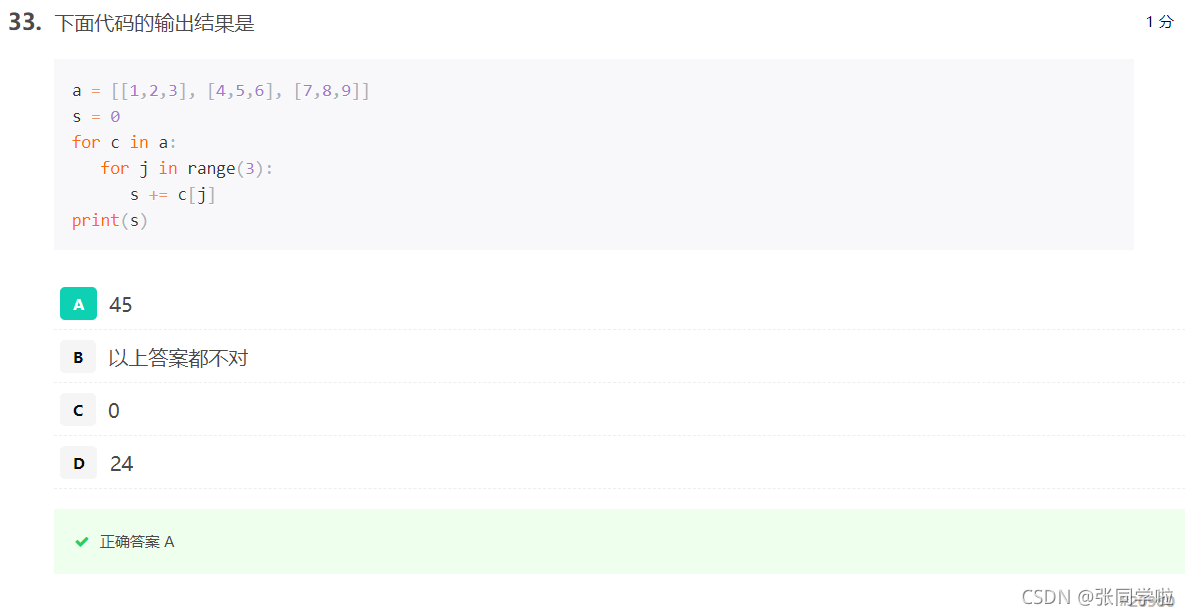
第三十四題

第三十五題
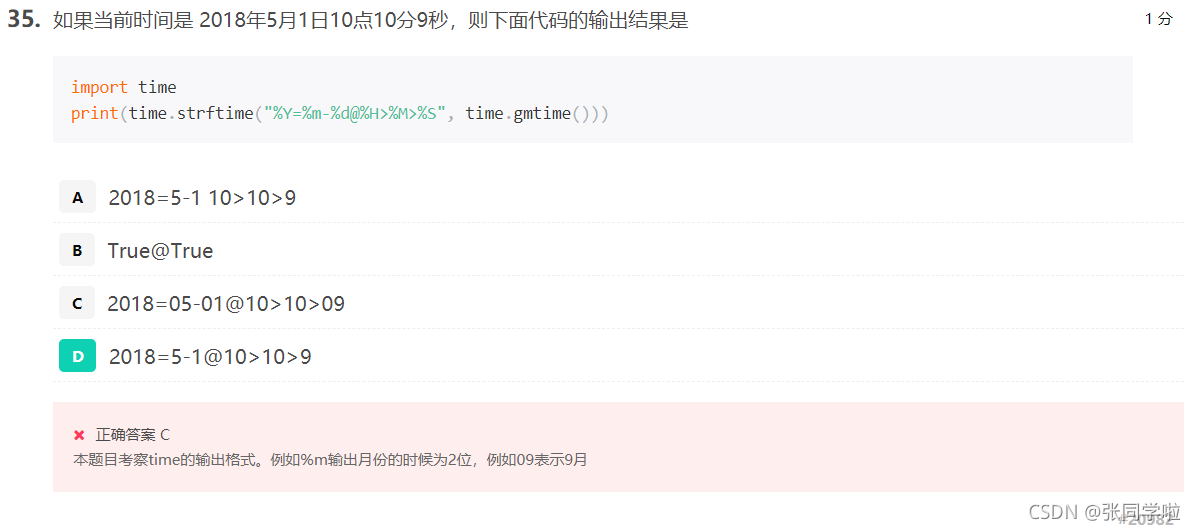
第三十六題
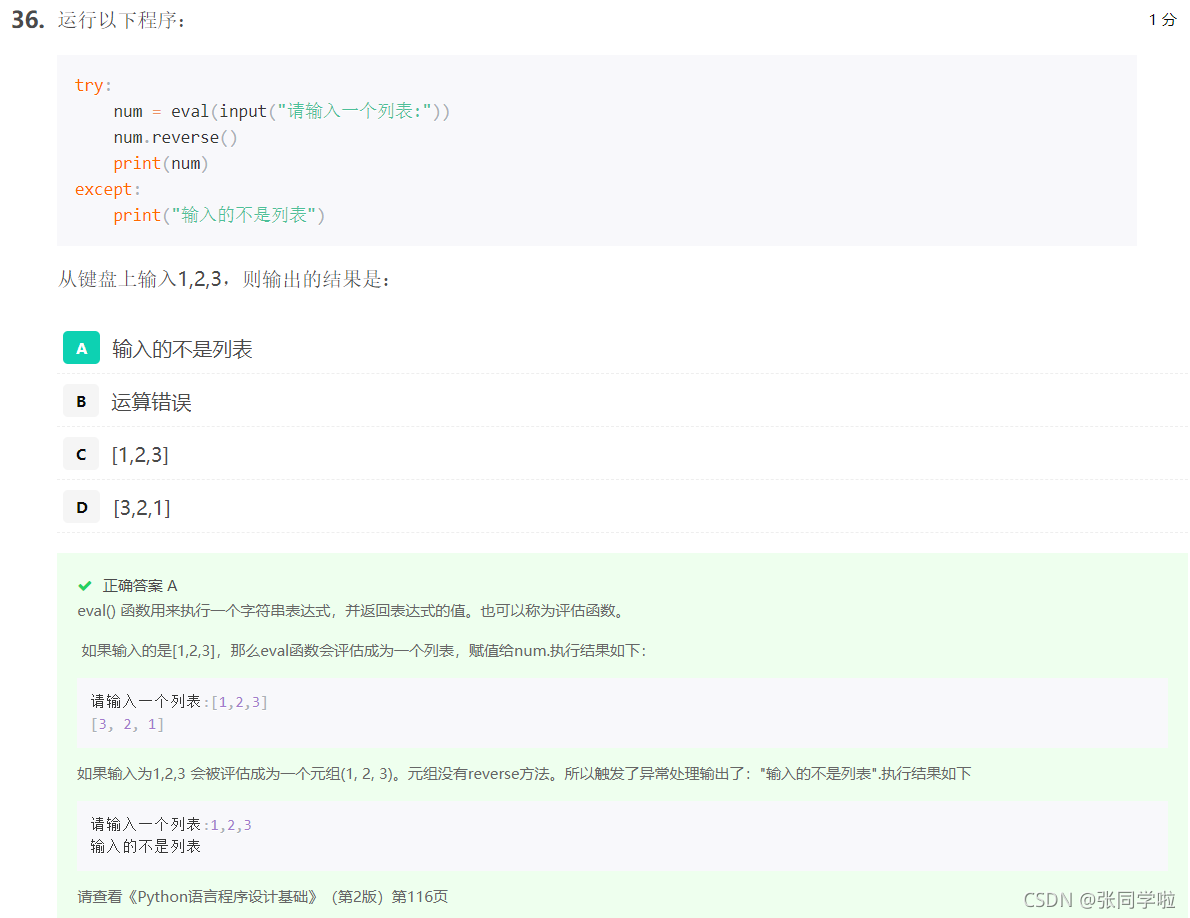
第三十七題
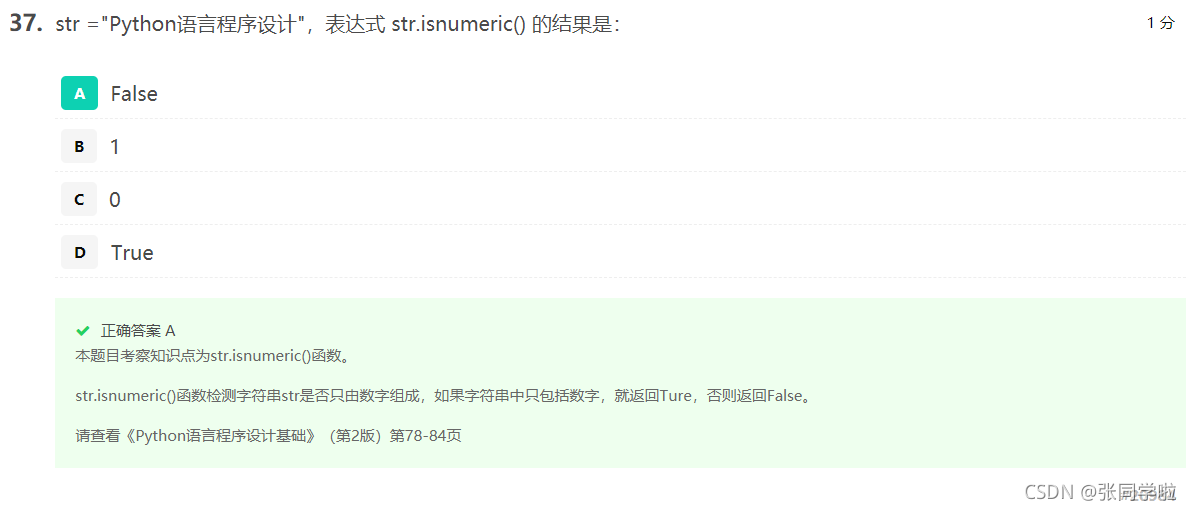
第三十八題
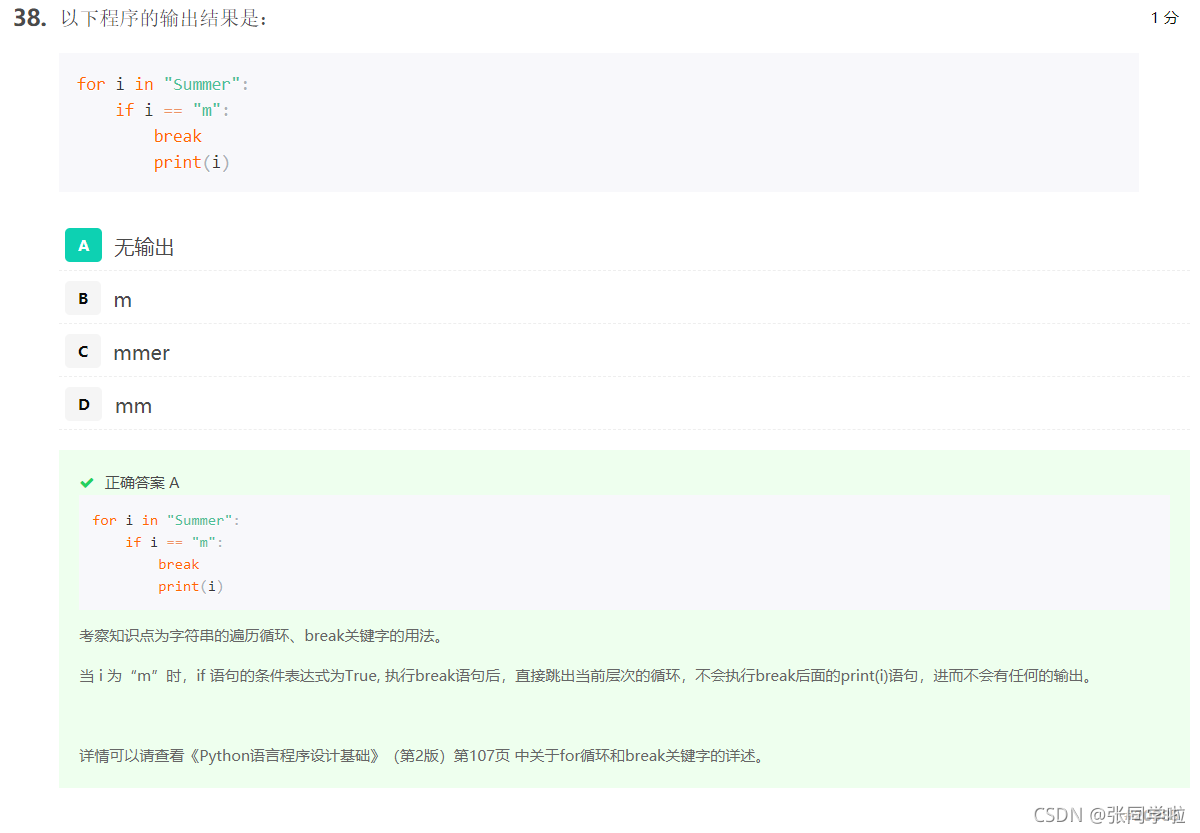
第三十九題
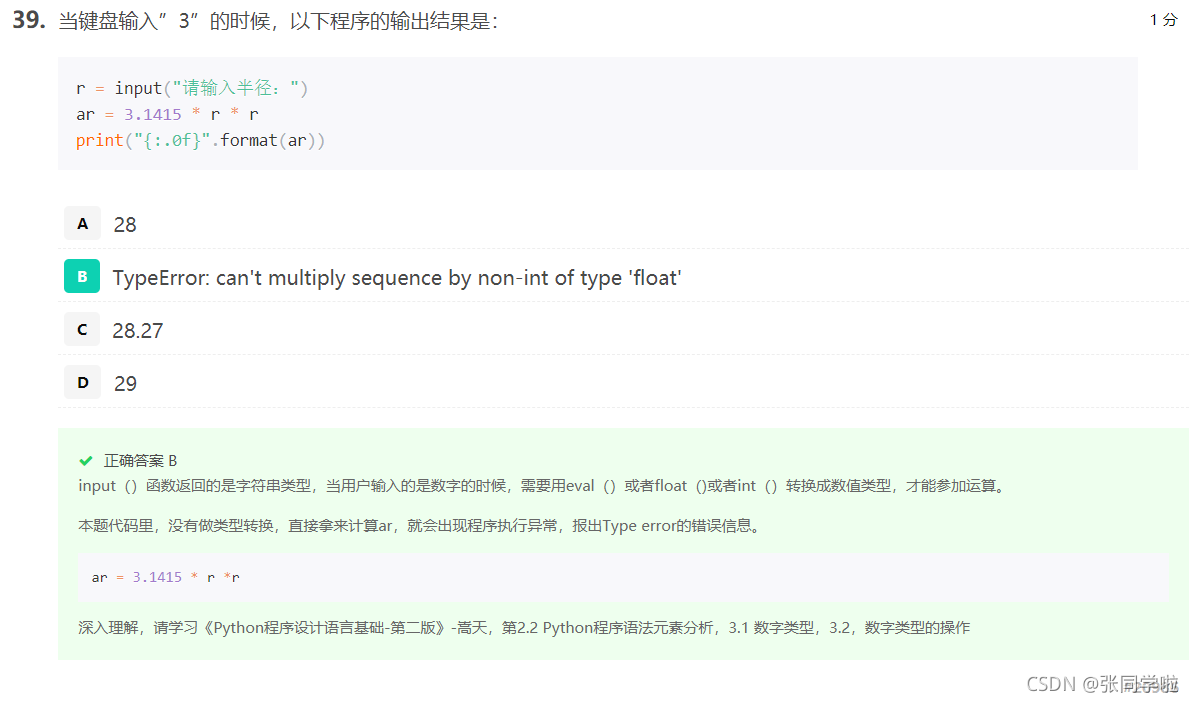
第四十題
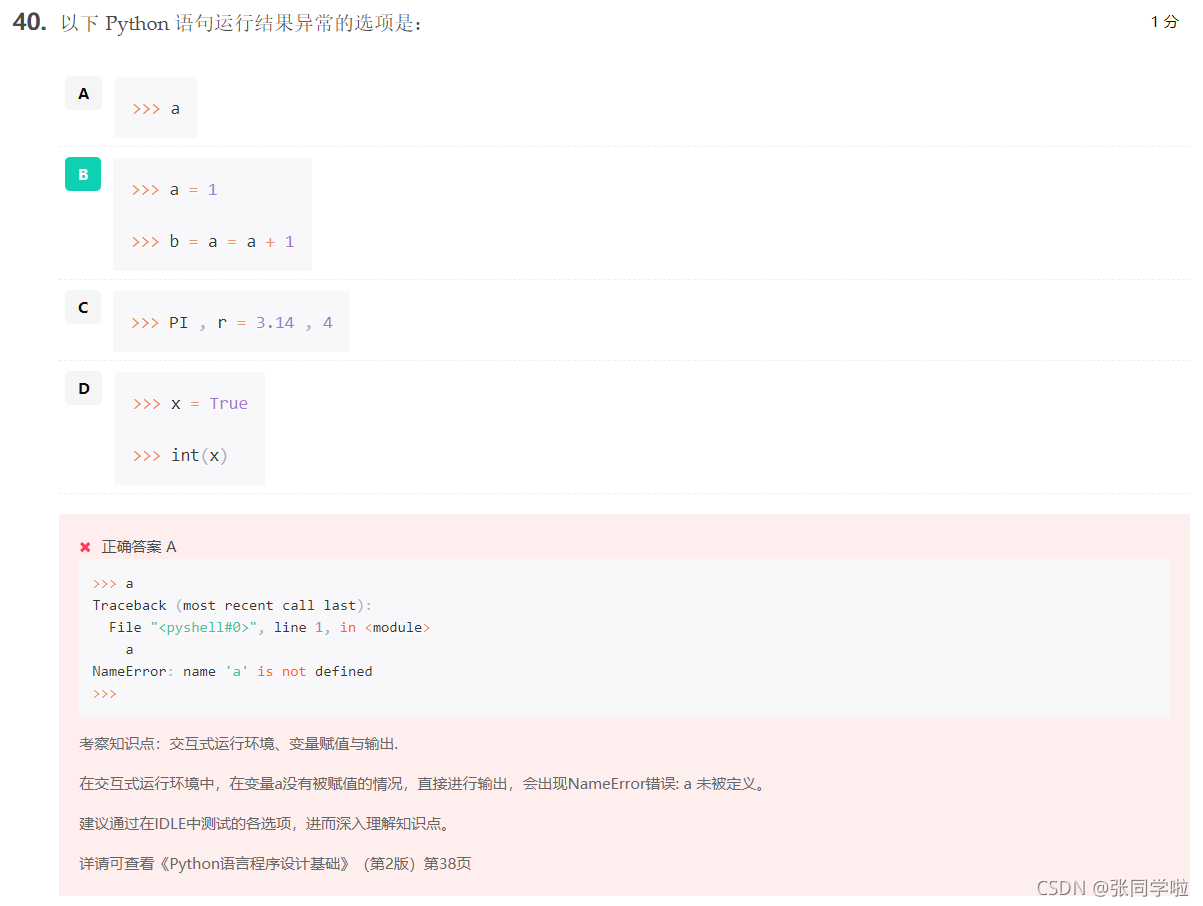
程式設計題
第一題
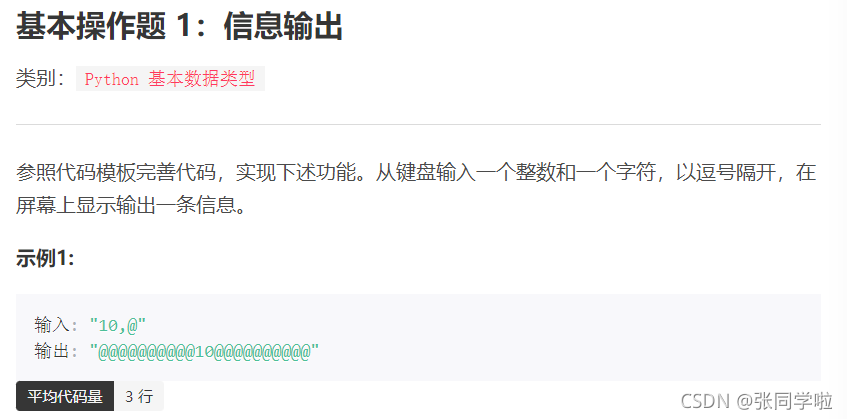
#解法一
ls= input().split(',') #將從鍵盤上輸入的用逗號隔開的字串轉換為串列
#例如輸入:10,@
#ls為['10', '@']
#ls[0]為'10' ,eval(ls[0])*2+len(ls[0])運算式值為22
#ls[1]為'@'
print(ls[0].center(eval(ls[0])*2+len(ls[0]),ls[1]))
#'10'.center(22,"@")即為輸出結果,考察字串的center方法
#str.center(x,y) 會用字串str構造一個新的字串,
#新的字串長度是x, 兩邊填充y,此處的x是數字,y是填充字符
# str:'10'
# x:22
# y:"@"
#輸出結果為"@@@@@@@@@@10@@@@@@@@@@"
'''
參考講解:
1. 理解 input 的結果是回傳一個字串
2. split 是字串的方法,能夠以逗號把字串分割成串列,但串列的元素都是字串
3. 用 ls[0] 和 ls[1] 分別取得輸入的數字和后面的符號
4. 題目要求用一行運算式來解決這個問題,所以增加了難度
5. 此時要想起來用字串的操作方法 center,問題就迎刃而解了,這個方法 str.center(x,y) 會用字串 str 構造一個新的字串,新的字串長度是 x , 兩邊填充 y,此處的 x 是數字,y 是字符
6. 要記得 ls[0] 里的 10 是一個字串,所以要記得用 eval 把它變成數字,乘 2,加上 10 自己的長度,就得到了所需的 x;y 就是 ls[1] 里的字符
7. 這道題關鍵是深入理解,并靈活運用 center
'''
#解法二
ls= input().split(',')
print(eval(ls[0])*ls[1]+ ls[0] + eval(ls[0])*ls[1])
第二題
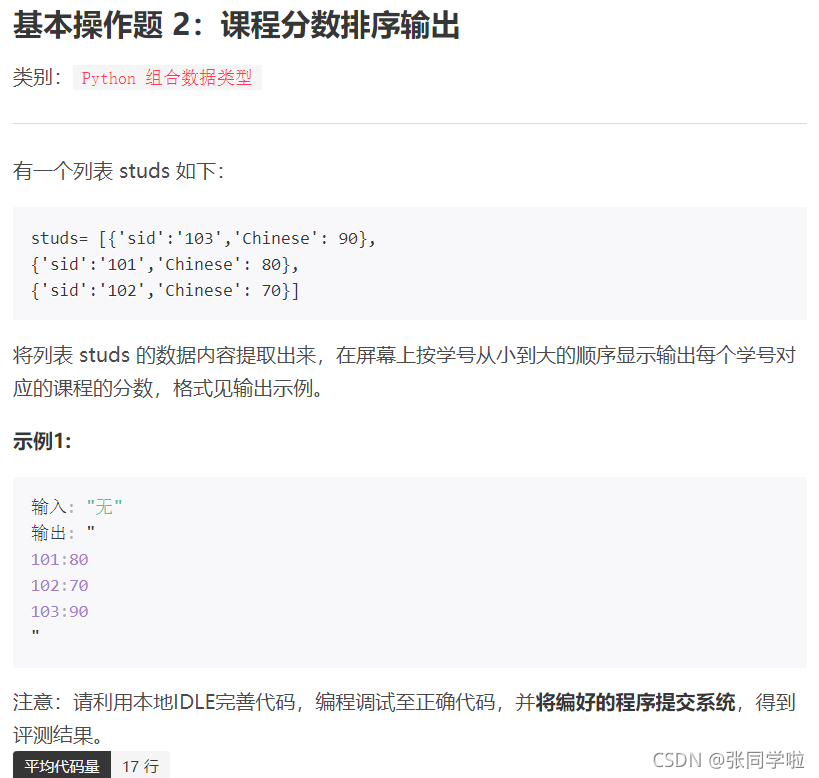
#studs串列中的元素是字典
studs= [{'sid':'103','Chinese': 90},
{'sid':'101','Chinese': 80},
{'sid':'102','Chinese': 70}]
scores = {}
for stud in studs:
sv = stud.items() #sv被賦值為二維串列,形如[('sid','103'),('Chinese',90)]
for it in sv:
if it[0] == 'sid': #第一次訪問:it = ('sid','103')
k = it[1] # k = '103'
else: #第二次訪問:it = ('Chinese',90) it[1] = 90
scores[k] = it[1] #scores["103"] = 90
so = list(scores.items()) #形如:[('103':90),('101':80),...]
so.sort(key = lambda x:x[0],reverse = False) #按學號進行排序
for l in so:
print('{}:{}'.format(l[0],l[1])) #遍歷輸出排序后結果
'''
要點:
1. 字典作為元素,定義在串列里,用串列的遍歷就可以從中提取出來
2. 提取出來的元素直接就是字典,因此可以用 items()直接獲取,形成鍵值對物件集合 sv;
3. 對鍵值對物件集合sv遍歷,就可以以元組it的方式訪問其中的每一對鍵值對,sv = stud.items(),是第一個空的答案;
4. 題目要求提取學生的學號,所以需要比較鍵it[0]是否是'sid',是則將學號it[1]提取出來作為新的字典scores的鍵k;不是則將成績提取出來作為新字典scores的值,scores[k] = v,是第二個空的答案
5. 經過對studs串列里的各條字典處理完之后,新的scores字典就全部生成,
6. 題目要求按學號從小到大的順序輸出學號和成績,所以需要對字典的鍵值對內容items()提取到串列so里,此處是第三個空的答案:so = list(scores.items())
7. 用Lambda函式進行排序,這個不在考試范圍里,所以代碼模板直接給出陳述句;
8. 對排好序的串列輸出每組串列,
'''
第三題
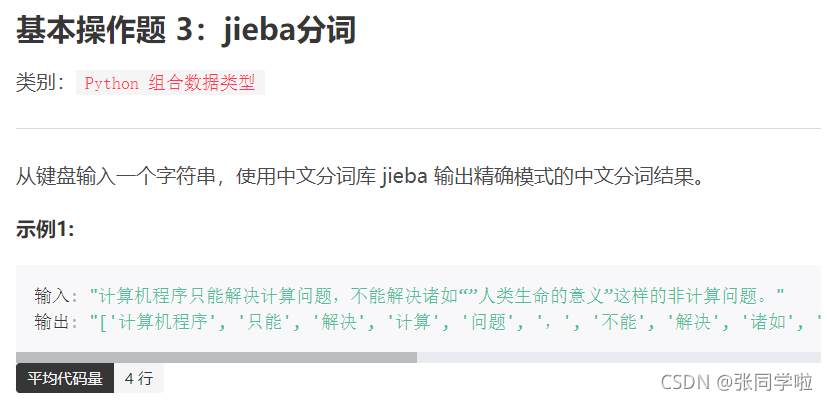
#代碼如下:
import jieba
Tempstr = input()
ls = jieba.lcut(Tempstr)
print(ls)
第四題

#代碼如下:
r = 10
dr = 50
head = 90
for i in range (4):
turtle.pendown()
turtle.circle(r)
r += dr
turtle.penup()
turtle.seth(-head)
turtle.fd(dr)
turtle.seth(0)
turtle.done()
第五題

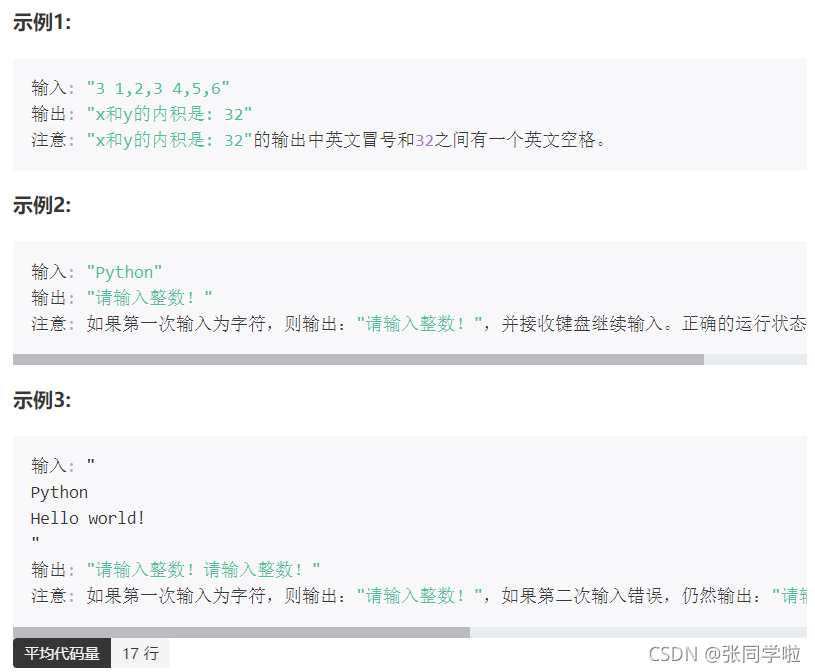
flag = 1
while flag:
try:
n = eval(input())
xin = input().split(',')
yin = input().split(',')
flag =0
sum = 0
for i in range(n):
sum += int(xin[i]) * int(yin[i])
print("x和y的內積是:", sum)
except:
print("請輸入整數!")
flag =1
第六題


#代碼如下:
jl = [[],[],[],[],[]] # 定義空的二維串列jl,例如:
#jl[1]用于存放左臂高壓值:[104,154,131,...]
#jl[2]用于存放左臂低壓值:[82,88,82,...]
#jl[3]用于存放右臂高壓值:[136,155,139,...]
#jl[4]用于存放右臂低壓值:[90,85,74,...]
zyc = [] #存放左臂壓差值串列[22,66,...]
yyc = [] #存放右臂壓差值串列[46,60,...]
#用with陳述句打開xueyajilu.txt檔案
with open("xueyajilu.txt", 'r',encoding='utf-8') as fi:
for l in fi: #對檔案中的每一行內容進行處理
if len(l): #過濾空行
lls = l.split(',')
#print(l.split(','))
#例如第一行的lls:['2018/7/2 6:00', '140', '82', '136', '90']
#注意第一列是時間,不需要,跳過
for i in range(1,5): #i從1開始,就是為了跳過第一列時間
jl[i].append(eval(lls[i])) #構建二維串列jl
zyc.append(eval(lls[1])- eval(lls[2])) #左臂壓差:左臂高壓值 - 左臂低壓值
yyc.append(eval(lls[3])- eval(lls[4])) #右臂壓差:右臂高壓值 - 右臂低壓值
cnt = len(zyc) #記錄條數
res = [] #構建對比表
res.append(list(("高壓最大值",max(jl[1]),max(jl[3]))))
#"高壓最大值"、左臂高壓最大值和右臂高壓最大值構建串列增加到res[0]
res.append(list(("低壓最大值",max(jl[2]),max(jl[4]))))
#"低壓最大值"、左臂低壓最大值和右臂低壓最大值構建串列增加到res[1]
res.append(list(("壓差平均值",sum(zyc)//cnt,sum(yyc)//cnt)))
#"壓差平均值"、左臂高低壓差平均值和右臂高低壓差平均值構建串列增加到res[2] //:取整除 - 回傳商的整數部分(向下取整)
res.append(list(("高壓平均值",sum(jl[1])//cnt,sum(jl[3])//cnt)))
#"高壓平均值"、左臂高壓平均值和右臂高壓平均值構建串列增加到res[3] //:取整除 - 回傳商的整數部分(向下取整)
res.append(list(("低壓平均值",sum(jl[2])//cnt,sum(jl[4])//cnt)))
#"低壓平均值"、左臂低壓平均值和右臂低壓平均值構建串列增加到res[4] //:取整除 - 回傳商的整數部分(向下取整)
print('{0:<10}{1:<10}{2:<10}'.format("對比項", "左臂", "右臂")) #輸出標題行
for r in range(len(res)):
print('{0:<10}{1:<10}{2:<10}'.format(res[r][0],res[r][1],res[r][2]))
#輸出左右臂的高壓最大值、低壓最大值、壓差平均值、高壓平均值、低壓平均值
輸出結果:
對比項 左臂 右臂
高壓最大值 168 155
低壓最大值 93 90
壓差平均值 62 60
高壓平均值 147 141
低壓平均值 85 81
要點:
1. 這道題的關鍵問題是把資料按照列的方式來處理
2. 參考答案給出的是一般思路,把檔案里讀出來的資料分別按列的方式,拷貝到一維串列中去,對一維串列進行各種max,min,sum,len操作
3. 其次,是當列數有些多的時候,程式看起來很冗余,需要做一些優化合并
4. 前四個計算公式類似的,放到一個二維串列里,加個回圈結構,就可以把四條陳述句縮成一條
5. 顯示輸出要求像表格一樣輸出,又要比較高效率,就引入了一個二維串列,把要輸出的行頭和內容,變成串列,再加到二維串列中去
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/302238.html
標籤:python
上一篇:掃碼登錄的簡單實作