教你用python爬取王者榮耀英雄皮膚圖片,并將圖片保存在各自英雄的檔案夾中,(附原始碼)
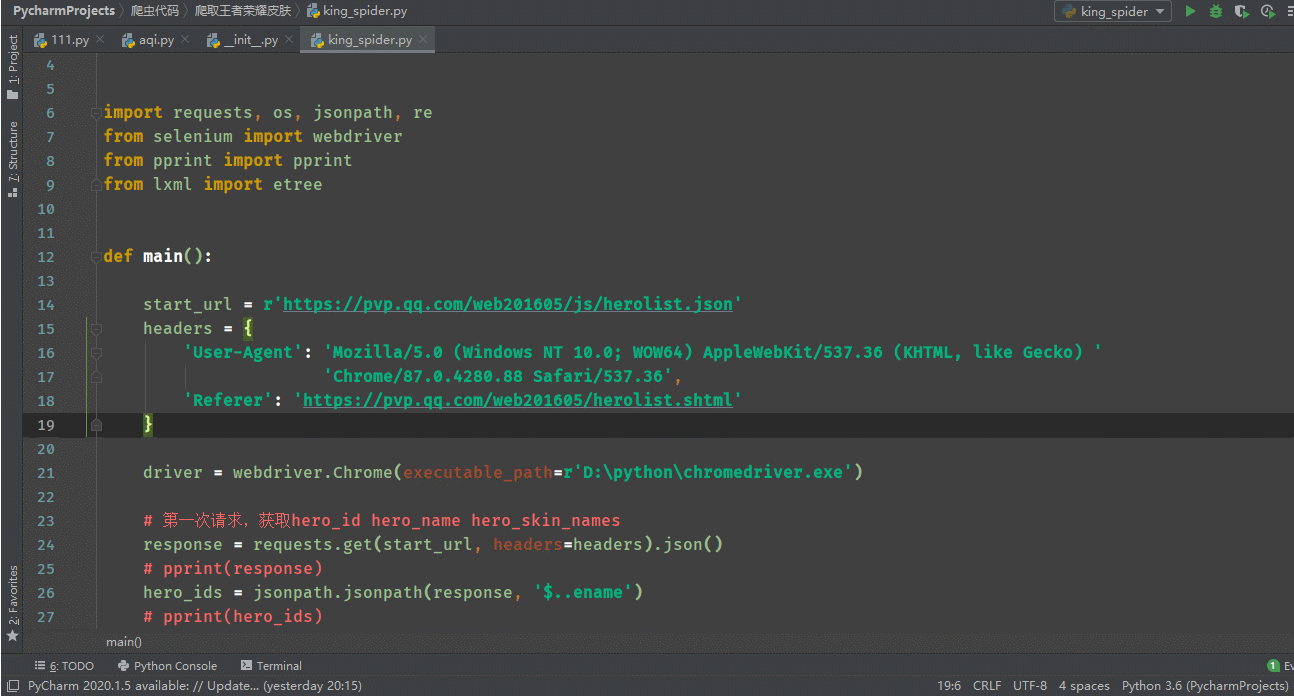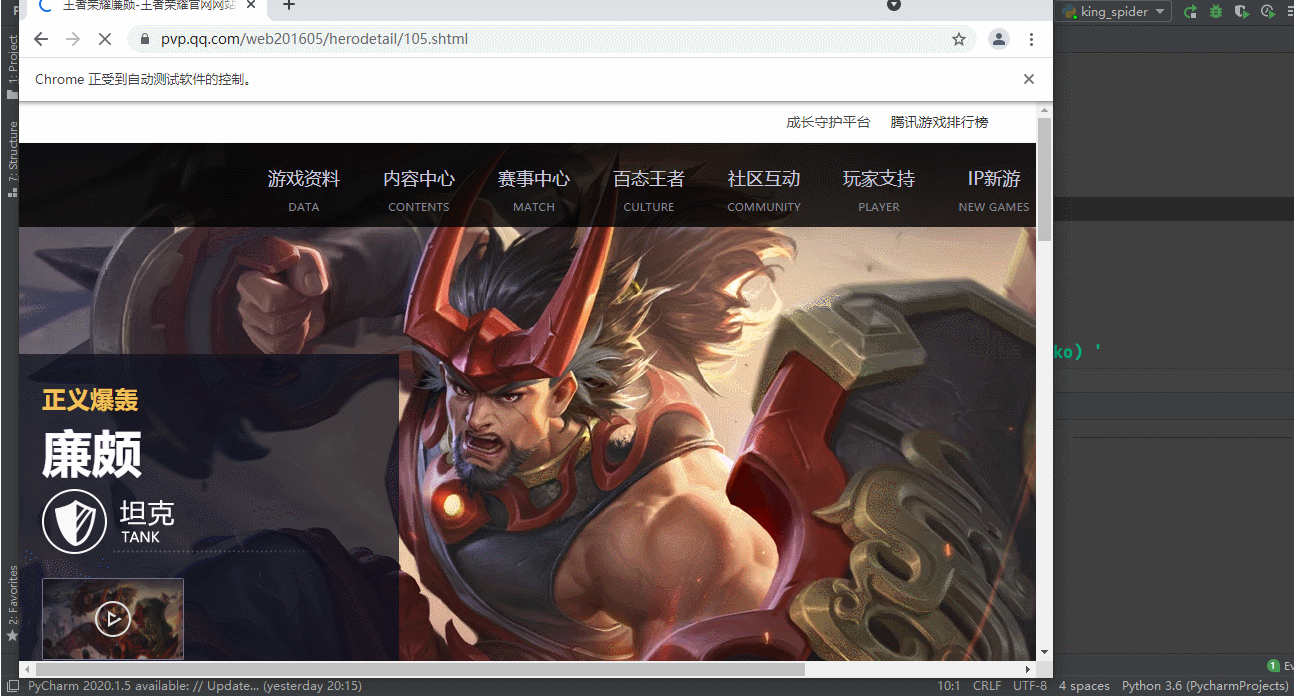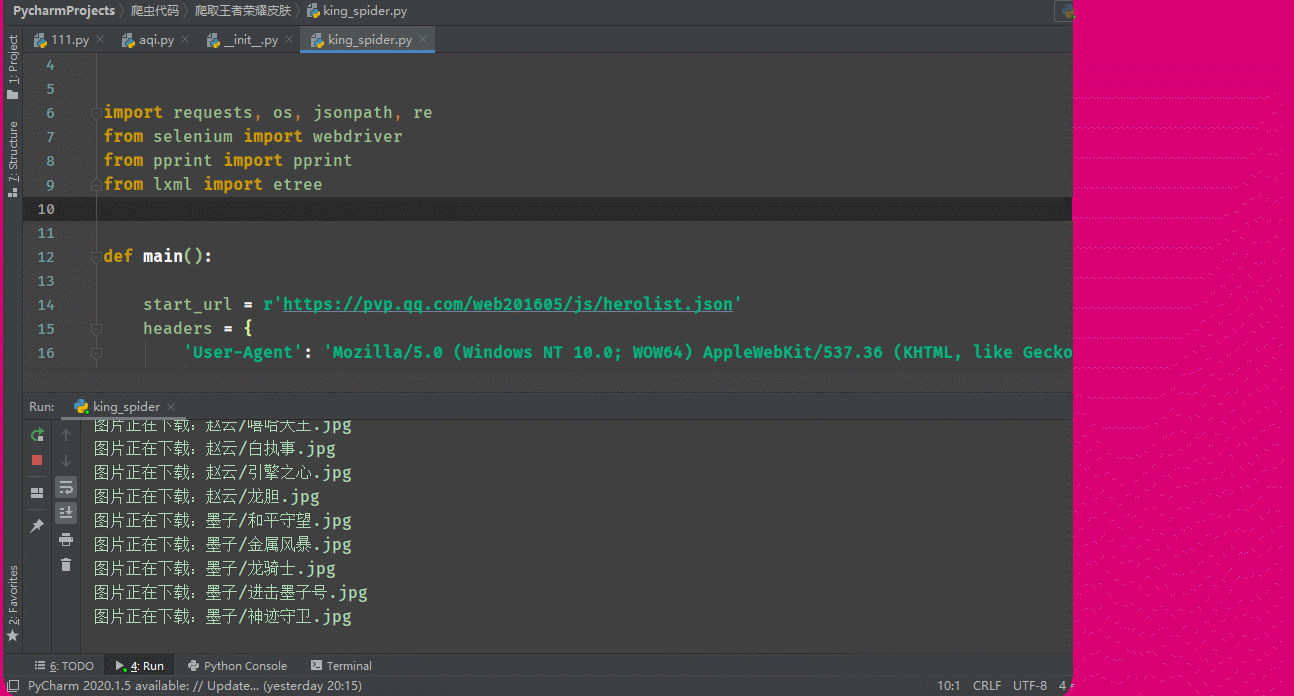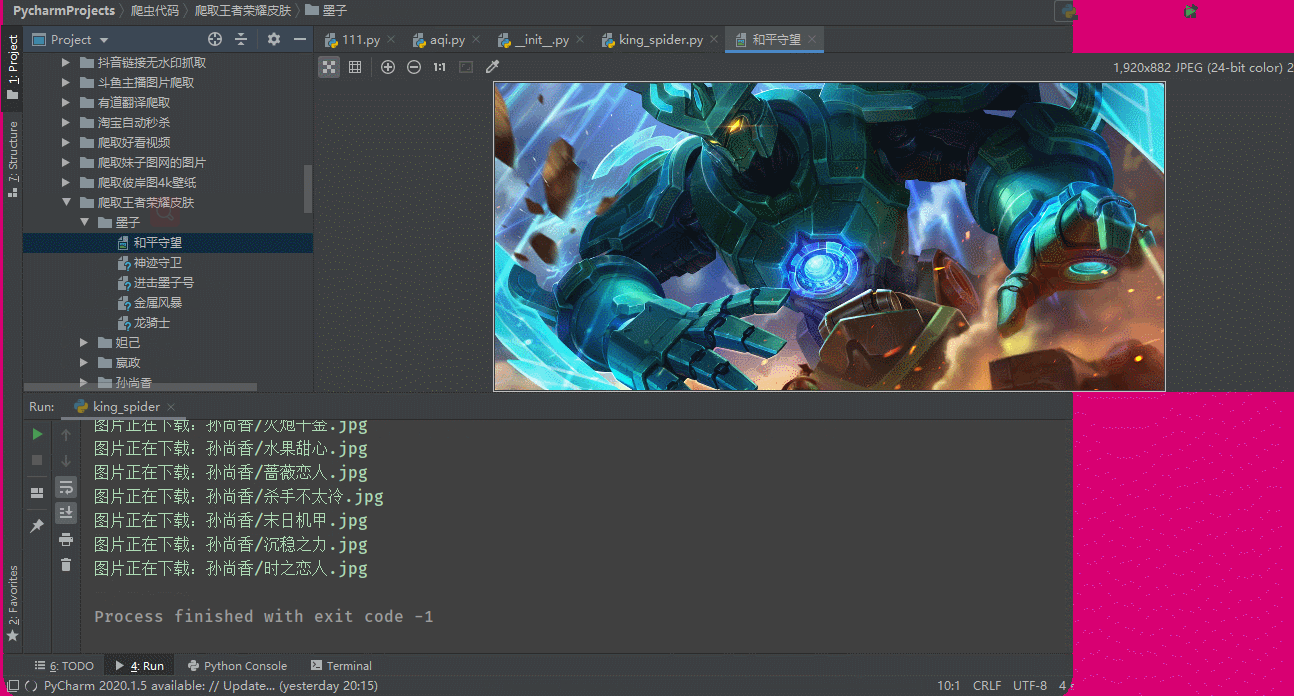
代碼展示:
保存在各自的檔案夾中
很多人學習python,不知道從何學起, 很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手, 很多已經做案例的人,卻不知道如何去學習更加高深的知識, 那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼! QQ群:701698587 歡迎加入,一起討論 一起學習!
美么?

讓我們開始爬蟲之路
開發環境
windows 10
python3.6
開發工具
pycharm
webdriver
庫
os,re,lxml,jsonpath
打開王者榮耀官網點擊游戲資料
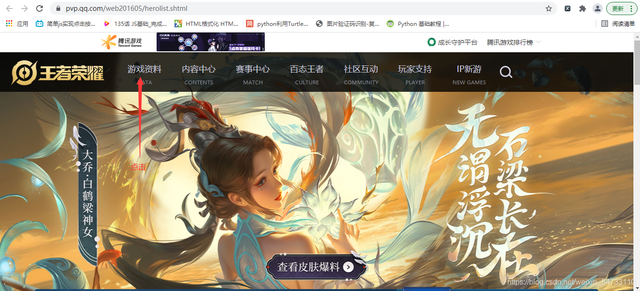
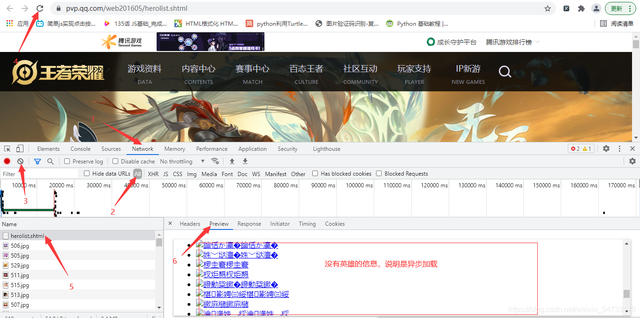
判斷是同步加載還是異步加載, 可以確定為異步加載
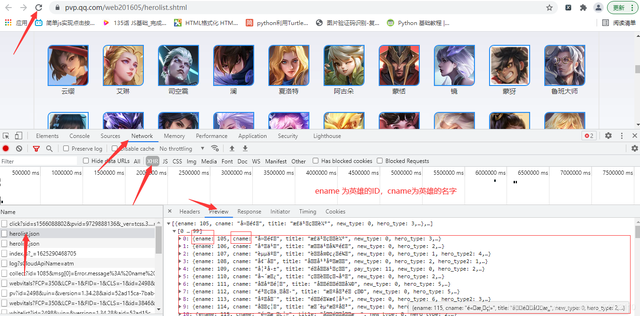
點擊XHR繼續抓包,ename為英雄的ID,cname為英雄的名字
jsonpath獲取
# 第一次請求,獲取hero_id hero_name
response = requests.get(start_url, headers=headers).json()
# pprint(response)
hero_ids = jsonpath.jsonpath(response, '$..ename')
# pprint(hero_ids)
hero_names = jsonpath.jsonpath(response, '$..cname')
# pprint(hero_names)
構造英雄地址
hero_info_url = r’https://pvp.qq.com/web201605/herodetail/{}.shtml’.format(hero_id)
driver訪問每一個英雄地址,獲取原始碼,etree決議,xpath提取hero_skin_names,hero_skin_urls
for hero_name, hero_id in zip(hero_names, hero_ids):
hero_info_url = r'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(hero_id)
# 發送英雄詳情頁請求得到 hero_info_content
driver.get(hero_info_url)
# 獲取頁面原始碼
hero_info_content = driver.page_source
# 決議網頁
hero_info_content_str = etree.HTML(hero_info_content)
# 提取 hero_skin_names hero_skin_urls
hero_skin_names = hero_info_content_str.xpath(r'//ul[@]/@data-imgname')[
0].split('|')
hero_skin_urls = hero_info_content_str.xpath(r'//ul[@]//img/@data-imgname')
遍歷hero_skin_urls地址,獲取圖片的二進制資料,最后進行保存,創建英雄的檔案夾,將皮膚圖片保存在各自的檔案夾中
# 補全hero_skin_url地址
hero_skin_url = r'https:'+hero_skin_url
# 獲取圖片的二進制資訊
img_content = requests.get(hero_skin_url, headers=headers).content
try:
# 創建檔案夾
if not os.path.exists('./{}'.format(hero_name)):
os.mkdir(r'./{}'.format(hero_name))
with open(r'./{}/{}.jpg'.format(hero_name, hero_skin_name), 'wb')as f:
f.write(img_content)
print('圖片正在下載:{}/{}.jpg'.format(hero_name, hero_skin_name))
except Exception as e:
continue
在執行時本來是以requests庫進行獲取英雄頁面的原始碼,但是發生報錯,報錯原因是因為編碼問題,所以采用webdriver訪問每個英雄頁面,driver.page_source獲取原始碼,然后進行資料提取,
原始碼展示
# !/usr/bin/nev python
# -*-coding:utf8-*-
import requests, os, jsonpath, re
from selenium import webdriver
from pprint import pprint
from lxml import etree
def main():
start_url = r'https://pvp.qq.com/web201605/js/herolist.json'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36',
'Referer': 'https://pvp.qq.com/web201605/herolist.shtml'
}
driver = webdriver.Chrome(executable_path=r'D:\python\chromedriver.exe')
# 第一次請求,獲取hero_id hero_name hero_skin_names
response = requests.get(start_url, headers=headers).json()
# pprint(response)
hero_ids = jsonpath.jsonpath(response, '$..ename')
# pprint(hero_ids)
hero_names = jsonpath.jsonpath(response, '$..cname')
# pprint(hero_names)
for hero_name, hero_id in zip(hero_names, hero_ids):
hero_info_url = r'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(hero_id)
# 發送英雄詳情頁請求得到 hero_info_content
driver.get(hero_info_url)
# 獲取頁面原始碼
hero_info_content = driver.page_source
# lxml決議
hero_info_content_str = etree.HTML(hero_info_content)
# 提取 hero_skin_names hero_skin_urls
hero_skin_names = hero_info_content_str.xpath(r'//ul[@]/@data-imgname')[
0].split('|')
hero_skin_urls = hero_info_content_str.xpath(r'//ul[@]//img/@data-imgname')
# hero_skin_name進行替換不必要的資訊
for hero_skin_name, hero_skin_url in zip(hero_skin_names, hero_skin_urls):
suffix_notation = re.findall(r'&\d.?', hero_skin_name)[0]
hero_skin_name = hero_skin_name.replace(suffix_notation, '')
# 補全hero_skin_url地址
hero_skin_url = r'https:'+hero_skin_url
# 獲取圖片的二進制資訊
img_content = requests.get(hero_skin_url, headers=headers).content
try:
# 創建檔案夾
if not os.path.exists('./{}'.format(hero_name)):
os.mkdir(r'./{}'.format(hero_name))
with open(r'./{}/{}.jpg'.format(hero_name, hero_skin_name), 'wb')as f:
f.write(img_content)
print('圖片正在下載:{}/{}.jpg'.format(hero_name, hero_skin_name))
except Exception as e:
continue
if __name__ == '__main__':
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/302364.html
標籤:其他