愛美之心人皆有之,正所謂窈窕淑女君子好逑,美好敲代碼的一天從好看的桌面壁紙開始,好看的桌面壁紙從美女壁紙開始,今天給大家帶來福利啦,爬取美女圖片作為桌面壁紙!【防止有人捶我打擦邊球,都是正經的圖片,自己想歪了是你的事,僅供學習交流】
采集目標
網址:36壁紙
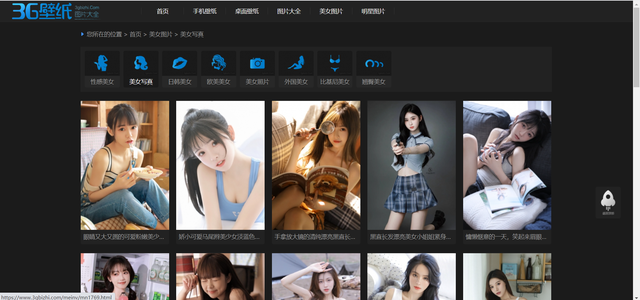
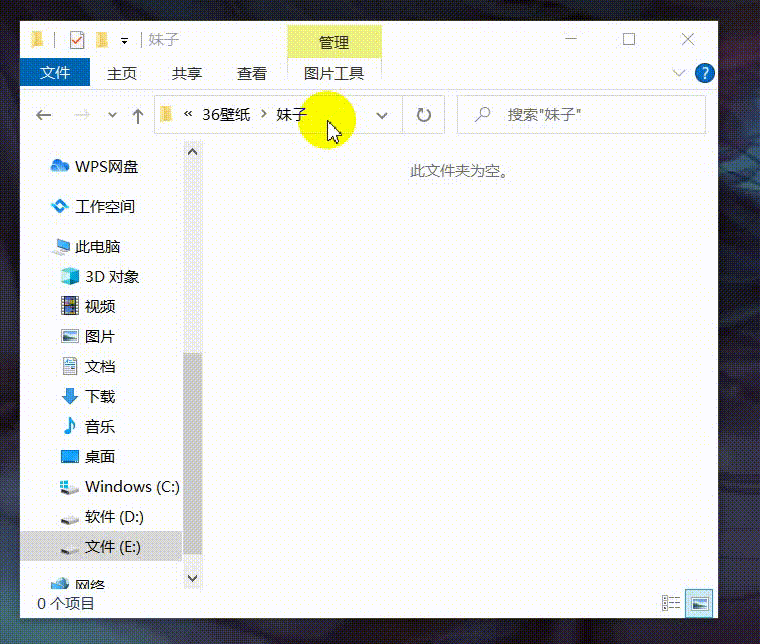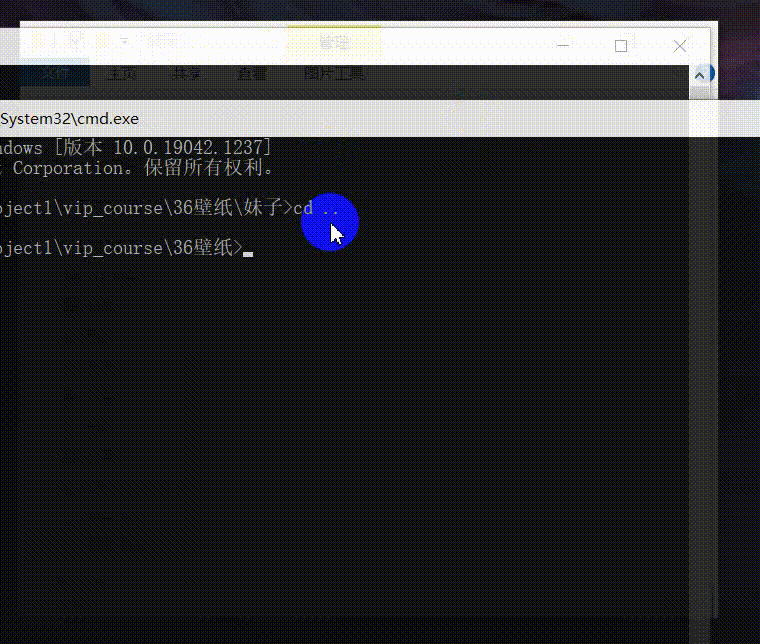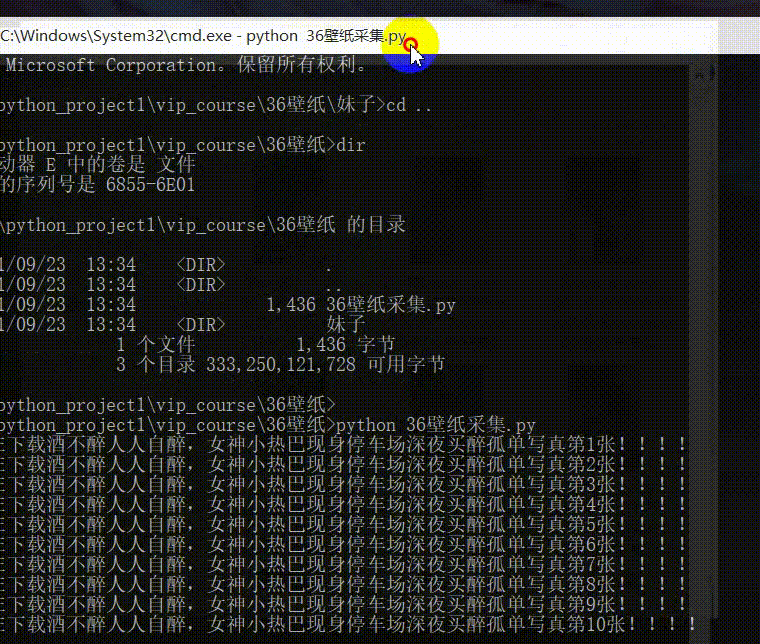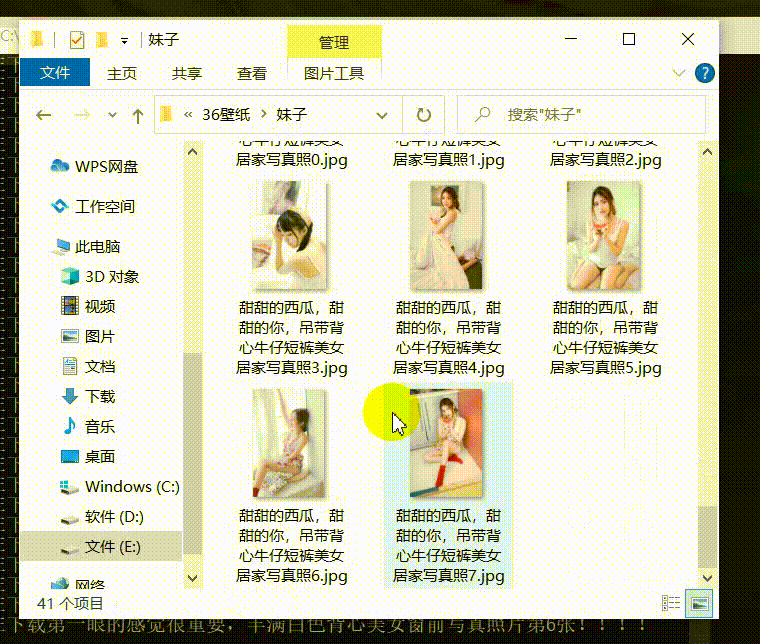
展示效果
工具使用
開發工具:pycharm 開發環境:python3.7, Windows10 使用工具包:requests, lxml
很多人學習python,不知道從何學起, 很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手, 很多已經做案例的人,卻不知道如何去學習更加高深的知識, 那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼! QQ群:701698587 歡迎加入,一起討論 一起學習!
專案思路決議
獲取網頁資料首先需要分辨資料是靜態資料還是動態資料檢驗方法在網頁源代碼搜索你需要資料的關鍵字,要是有的話就是靜態資料,沒有的話就是動態資料,當前網頁資料加載方式是通過url換頁,通過回圈的方式加載頁面資料,使用requests發送網路請求獲取當前網頁資料,通過xpath語法定位到網頁鏈接請求
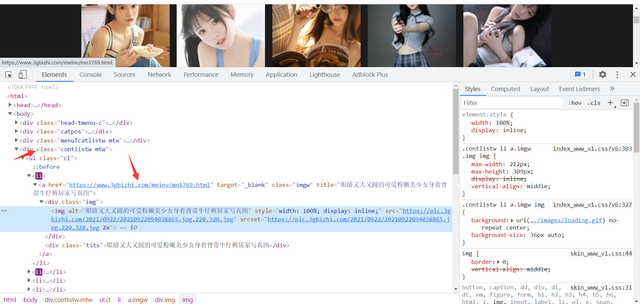
記住在這里提取的資料是html鏈接我們要的一大批資料在詳情頁面

提取出當前網頁所有的詳情頁面鏈接,xpath提取的資料為串列,回圈取出每個資料依次發送請求
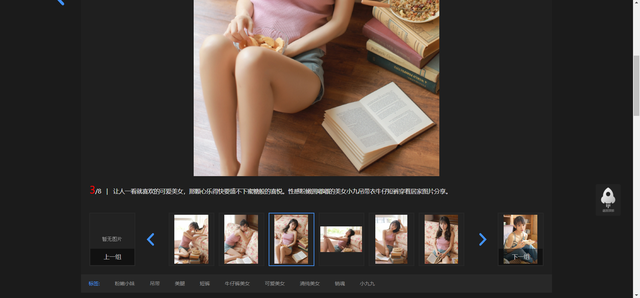
我們要獲取的圖片都在這里按照同樣的方法使用xpath方式進行定位獲取到所以詳細圖片的位置
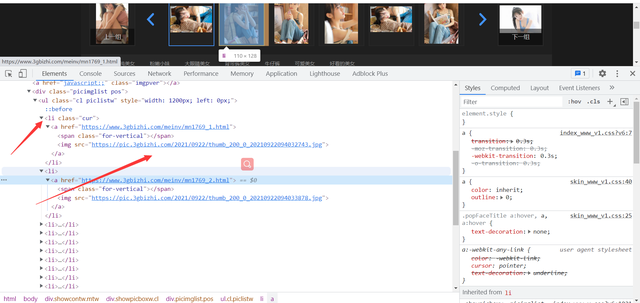

獲取到全部圖片地址,這個圖片需要注意的是是縮略圖我們需要找出縮略圖和大圖url的區別
https://pic.3gbizhi.com/2021/0922/20210922094032743.jpg
https://pic.3gbizhi.com/2021/0922/thumb_200_0_20210922094032743.jpg縮略圖比大圖多了thumb_200_0_ 進行分割在進行拼接,對圖片的發送網路請求獲取到詳細的圖片資料,在進行保存
簡易原始碼分享
import requests
from lxml import etree
headers = {
?
'Cookie': 'Hm_lvt_c8263f264e5db13b29b03baeb1840f60=1632291839,1632373348; Hm_lpvt_c8263f264e5db13b29b03baeb1840f60=1632373697',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
?
for i in range(2, 3):
url = f'https://www.3gbizhi.com/meinv/xgmn_{i}.html'
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
href_list = html.xpath('//div[@]//ul[@]/li/a/@href')
title_list = html.xpath('//div[@]//ul[@]/li/a/@title')
for href, title in zip(href_list, title_list):
res = requests.get(href, headers=headers)
html_data = https://www.cnblogs.com/pythonQqun200160592/p/etree.HTML(res.text)
img_url_list = html_data.xpath('//div[@]/ul/li/a/img/@src')
print(img_url_list)
num = 0
for img_url in img_url_list:
img_url = ''.join(img_url.split('thumb_200_0_'))
result = requests.get(img_url, headers=headers).content
with open('妹子/' + title + str(num) + '.jpg', 'wb')as f:
f.write(result)
num += 1
print(f'正在下載{title}第{num}張!!!!')轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/303217.html
標籤:Python
上一篇:MyBatis筆記:動態SQL