Python 自動化 這一專欄,將以目的為導向,以簡化或自動化完成作業任務為目標,將Python運用于實踐中,解決實際問題,以激發讀者對這門腳本語言的學習興趣,在開始Python自動化相關實戰的學習前,建議對 Python基礎 以及 Python 爬蟲 的相關知識展開一定的學習與了解,對此博客已開設相關專欄,可點擊直達,
往期內容提要:
- 【Python基礎】 動態HTML處理之Selenium與PhantomJS
- 【Python基礎】 機器視覺與機器影像識別之Tesseract
- 【Python自動化】 selenium之驗證碼識別
- 【Python自動化】 selenium之網課學習自動化
- 【Python自動化】 selenium之檔案批量下載(本文)
- 【Python實戰】疫情期間每日健康報送任務的自動化處理
- 【Python實戰】教務管理系統:成績、課表查詢介面設計及搶課、監控功能實作
“檔案下載”無論是在網路爬蟲,還是自動化領域,都是最為常見的需求,此前作者曾在 《教務管理系統:成績、課表查詢介面設計及搶課、監控功能實作》 一文中,在圖形驗證碼的識別中首先就介紹了進行了實戰展示,在這一篇文章中,將對檔案下載作出一個相對系統的概括與總結,
一般而言,檔案下載可以通過兩個方式實作,其一, 發包收包解決;其二,selenium解決,
針對第一種方法,曾在 《教務管理系統:成績、課表查詢介面設計及搶課、監控功能實作》 一文中予以過展示,基本邏輯在于構造get請求,發包后儲存回傳結果,
url = '手動打碼/Image.aspx'
def get_pic():
# 驗證碼請求頭
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"cookie": "varPartNewsManage.aspx=10"
}
re_pic = requests.get(url, headers=headers)
response = re_pic.content
file = "C:\\Users\\john\\Desktop\\1\\" + ".png"
playFile = open(file, 'wb')
playFile.write(response)
playFile.close()
此外,通過selenium方式解放雙手,實作檔案批量下載在實戰中也是較為常見的方法,接下來將以網課夢魘——“超星學習通”課程音頻下載為例,介紹如何利用selenium實作網課檔案批量下載,
環境所需必要模塊:
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.common.exceptions import TimeoutException, WebDriverException
from datetime import datetime
from time import sleep
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
檔案下載基本步驟梳理:
- 訪問目標站點
- 獲取下載源
- 指定存盤路徑
- 實作下載
一、訪問目標站點
目標站點的訪問方法可參見往期Python自動化文章 《【Python自動化】登陸與識別》,而文章舉例站點“超星學習通”的URL作為教師分享鏈接,無需登陸驗證,URL格式如下:
http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx
因此,僅需要簡單呼叫webdriver,實作目標站點的訪問:
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome()
browser = webdriver.Chrome(chrome_options=chrome_options)
url_list = [
"http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx1",
"http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx2",
"http://apps.wh.chaoxing.com/screen/vclass/view/xxxxx-xxxxx-xxxxx-xxxxx-xxxxxxxxxx3"
]
browser.get(url_list[0])
# browser.maximize_window()
wait = WebDriverWait(browser,10,0.5)
二、獲取下載源
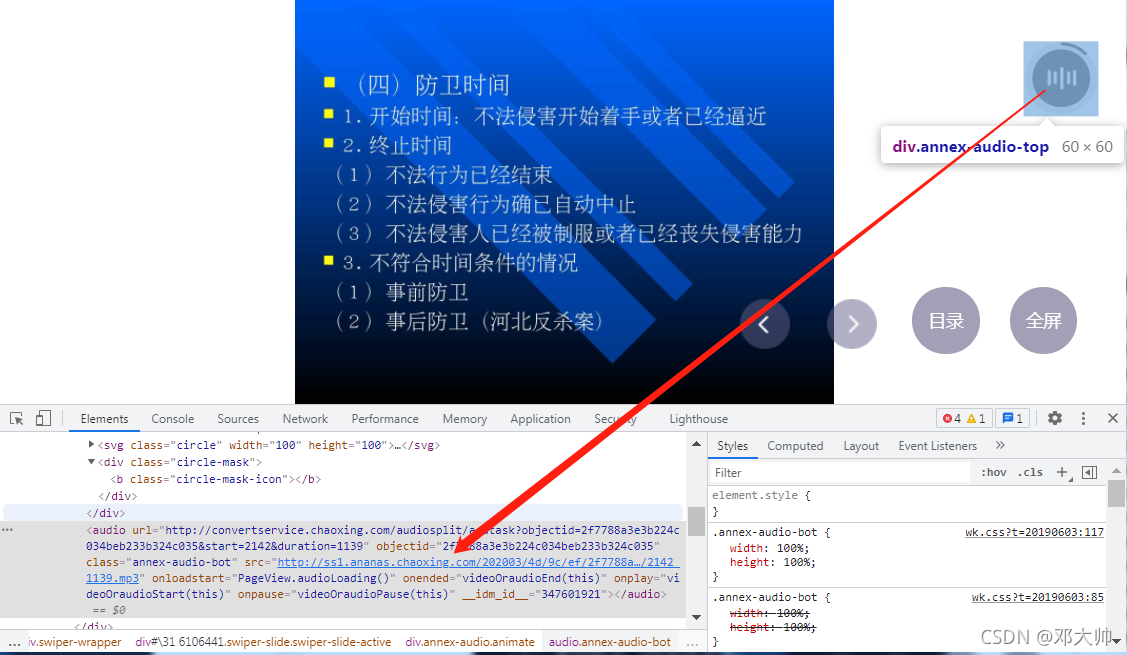
首先通過開發者模式定位音頻元素,在能夠獲取單頁音頻檔案直鏈的基礎上,采用遍歷的方式獲取全站檔案直鏈,
link = WebDriverWait(browser, 10).until(lambda x: x.find_elements_by_xpath("//audio"))
list=[]
list_count = 0
for i in link:
list.append(i.get_attribute('src'))
#print(list)
#print(type(list))
browser.quit()

三、指定存盤路徑并實作下載
z = []
for i in list:
time = datetime.now().strftime('%H-%M-%S----')
data = requests.get(i, stream=True)
z.append(time)
with open('C:\\Users\\john\\Desktop\\1\\' + time + i[-8:-5] + '.mp3', 'wb') as f:
for j in data.iter_content(chunk_size=512):
f.write(j)
print(i + '寫出完畢!')
print("一共 {} 個,下載完成 {} 個 ".format(len(list),len(z)))
其中存盤檔案的命名方式多樣,這里選擇時間戳的方式為音頻排序:


至此,本文也就進入尾聲了,本文的撰寫來自于開發中的一點心得體會,主要目的在于通過實踐提高讀者Python學習興趣,解決實際問題,供對這一領域感興趣的讀者以參考借鑒,希望本文能夠起到拋磚引玉之效,也歡迎大家的批評交流,
如果您有任何疑問或者好的建議,期待你的留言、評論與關注!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/303595.html
標籤:python