大家好,我是小小明,
![]()
受CSDN官方邀請,前來測評《python 技能樹》 ,活動地址:https://bbs.csdn.net/topics/600937310
XDM,一起來測評,一起來拿獎吧!獎品多多,福利多多噢~
首先,我們打開內測技能樹頁面:
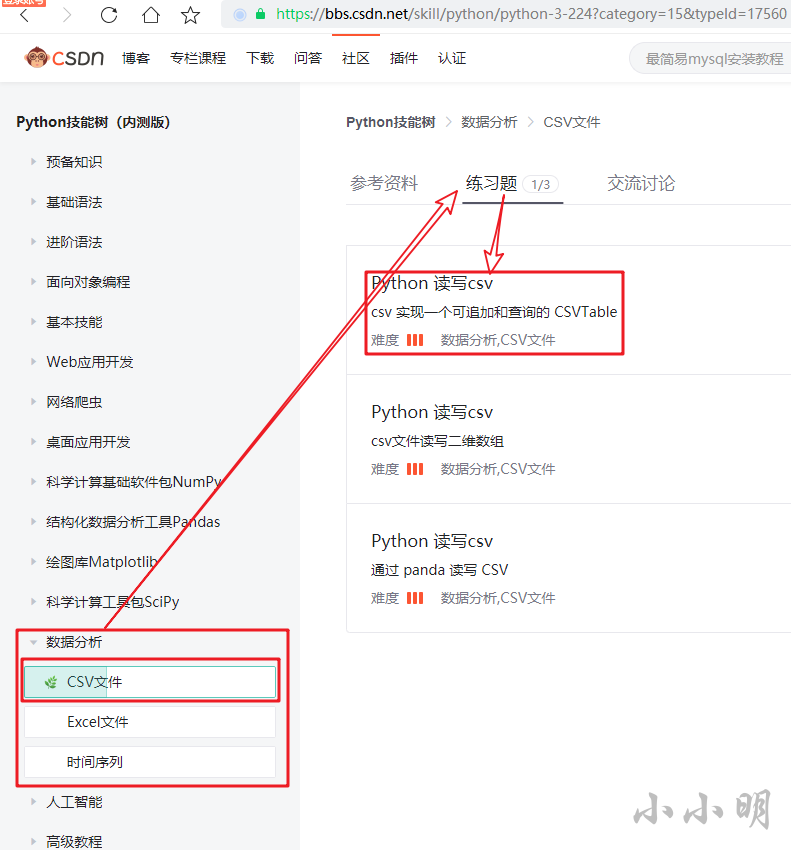
眾所周知,jupyter是資料分析領域最常用的工具,所以我直接進入資料分析版塊,
雖然目前看到選項過于單薄,但是不耽誤我們玩玩csdn的jupyter,
下面我們就點開第一個模塊的第一題開始玩玩吧:
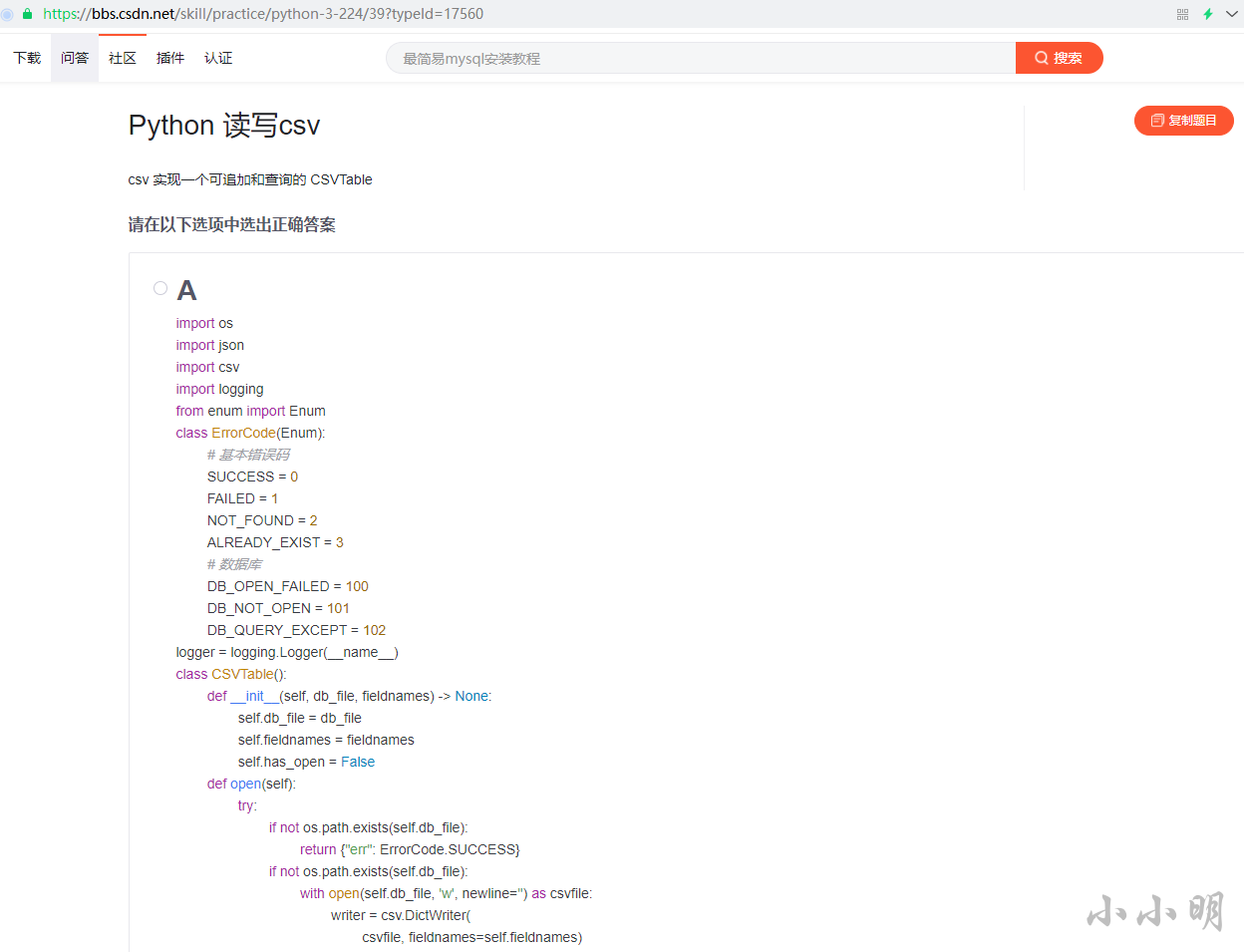
我去,雖然只是一道選擇題,但實在是已經嚇死寶寶了,這代碼也太長了點,那么先隨便選個試試:
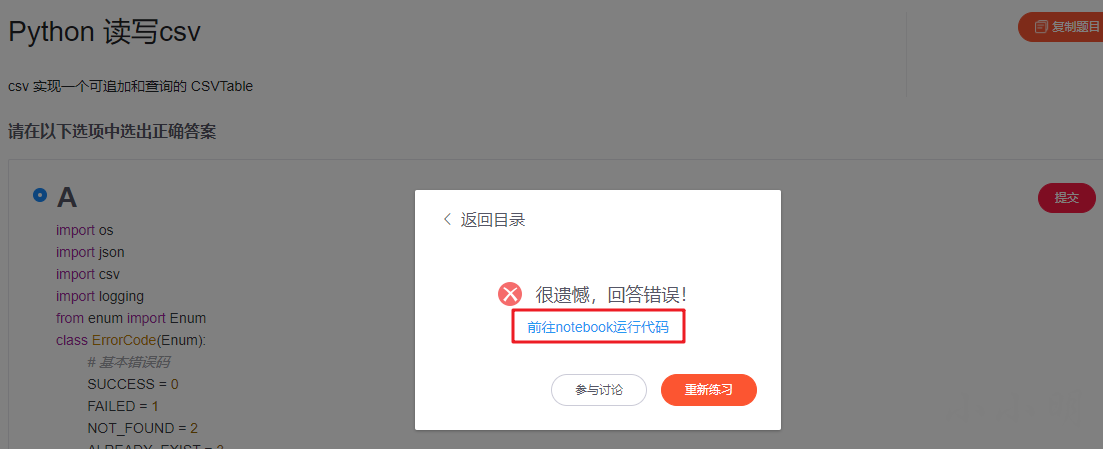
嘿嘿,選擇A點提交后,在線Jupyter的入口就出現了,看我怎么跑代碼干翻你這道 《大家來找茬》 的題目,
點擊前往就出現了,服務啟動的頁面:
等待啟動完畢后,就進入到了JupyterNoteBook的開發頁面:
作為一名資深jupyter玩家,這點功能和插件顯然是不滿足要求的,下面我們看看如何安裝一些插件:
給JupyterNoteBook安裝插件
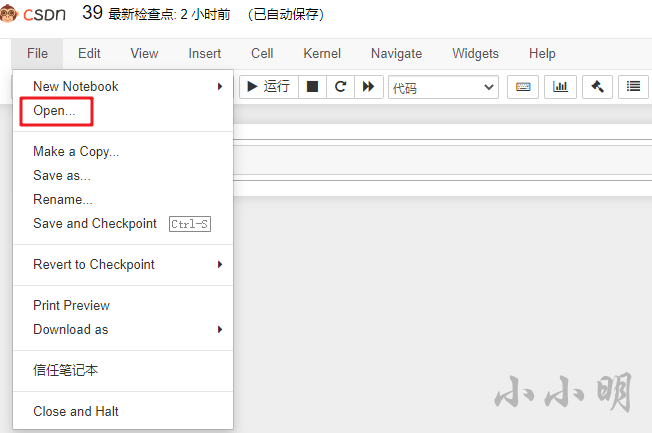
首先點擊open:
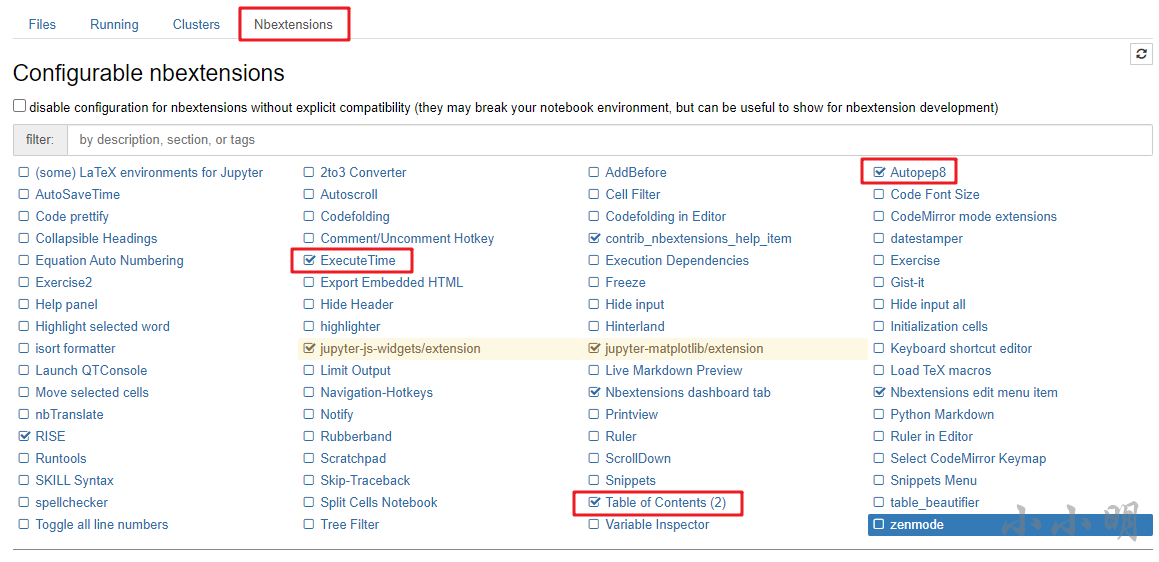
然后進入Nbextensions插件選項卡,我將我最需要的三個插件打勾:
對于Autopep8這玩意,我們需要pip裝點庫,回到前面的代碼界面執行:
!pip install autopep8
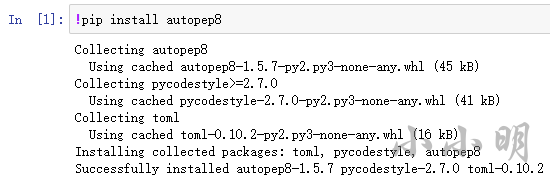
這是因為我上次使用時已經下載過有快取,所以直接就安裝好了,
安裝完成后重繪網頁剛才選擇的插件就會生效,然后給代碼框加個默認行號顯示:
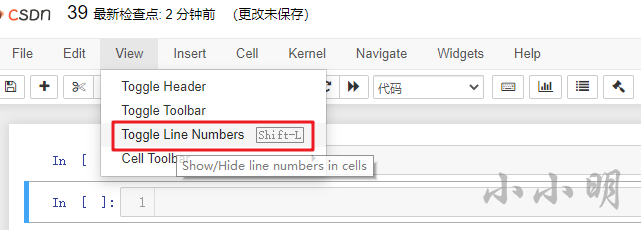
展開目錄
點開目錄按鈕后,就可以編輯Markdown文本:
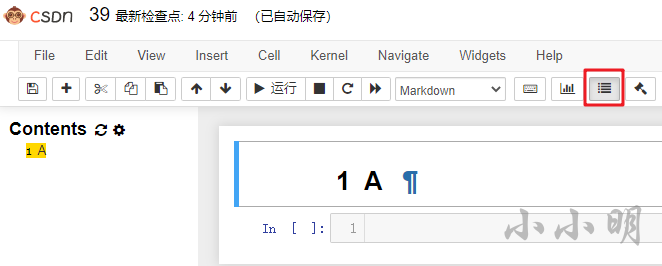
如何將一個代碼節點轉換為Markdown節點呢? 按下快捷鍵H即可打開快捷鍵選單:
這意味著,只需要記住H快捷鍵,其他快捷鍵都通過這個面板隨時查詢,
可以看到按下ESC退出進入命令列模式后,按下快捷鍵M即可將其轉換為Markdown文本節點,數字快捷鍵1~6即可將將其轉換對應等級的標題,
復制代碼并運行
點擊右上角的復制按鈕即可復制代碼:
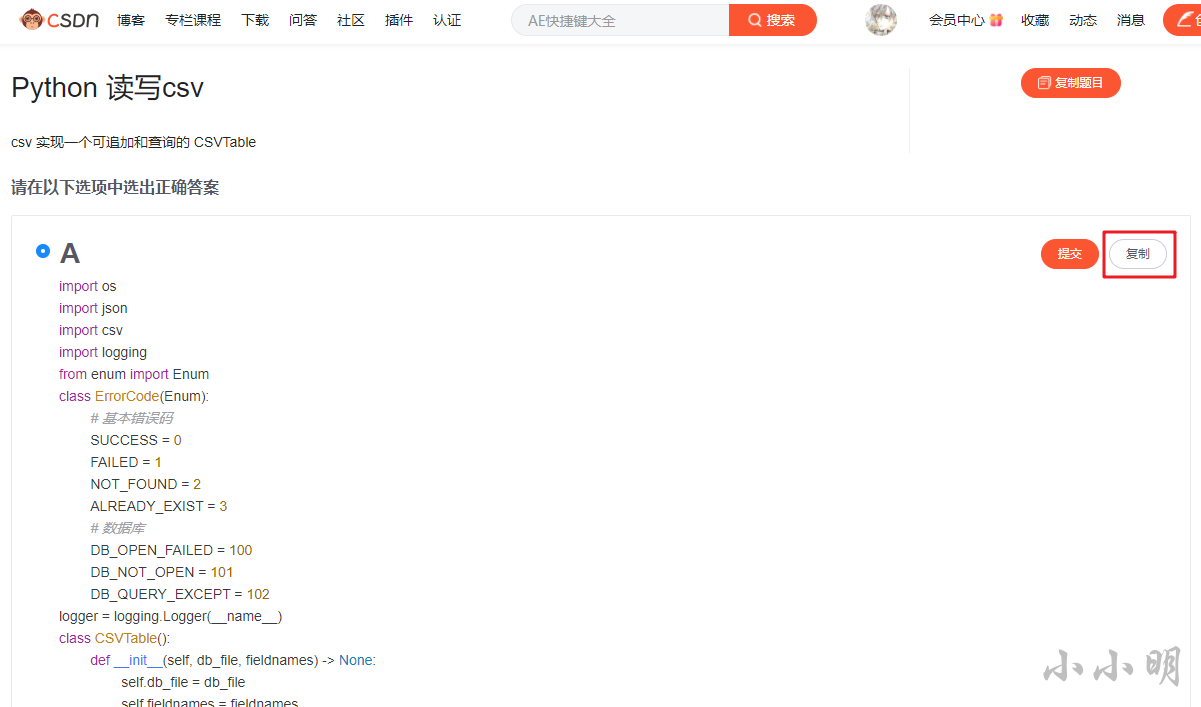
然后粘貼到JupyterNotebook中:
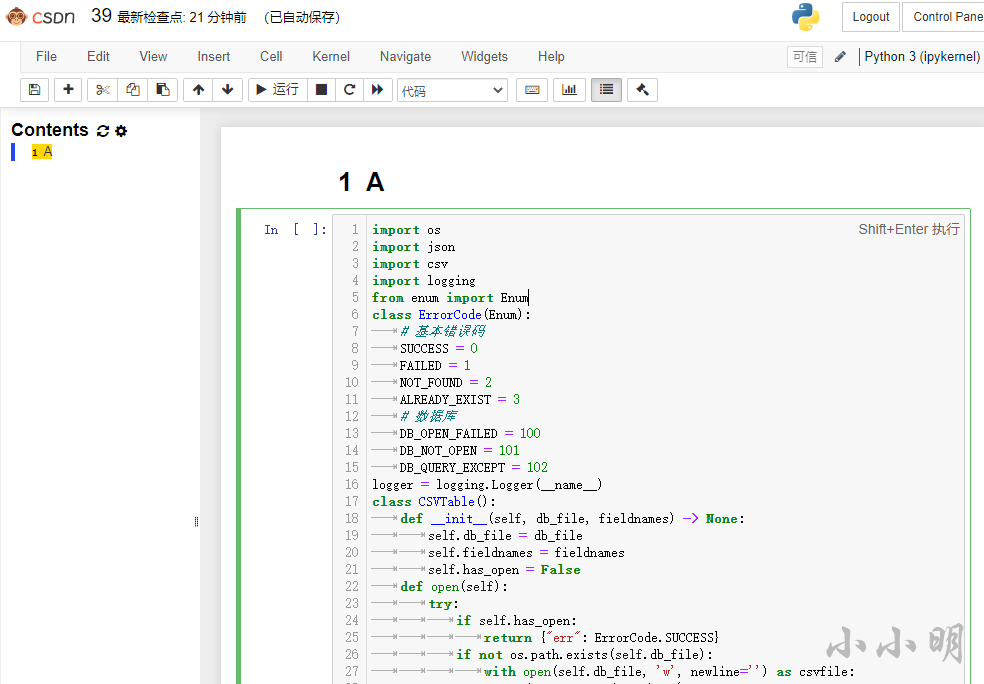
粘貼完,代碼是這種使用制表符\t縮進的形式,現在按下快捷鍵Ctrl+L即可啟動autopep8代碼格式化:
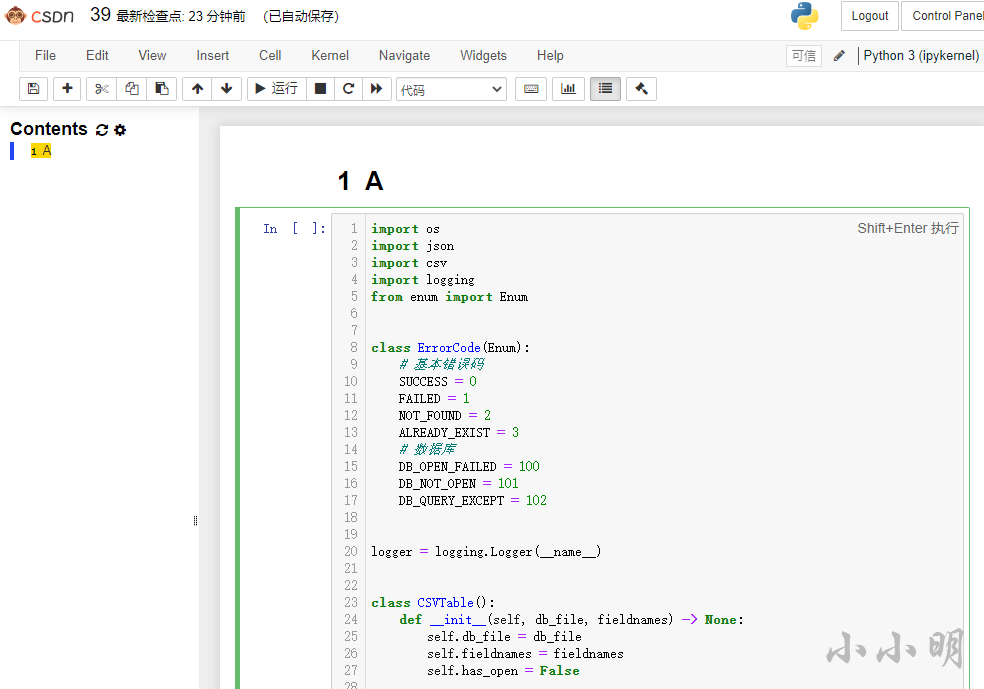
可以看到格式化之后的代碼都是空格縮進的形式,
根據右上角的提示即可運行代碼,運行后:
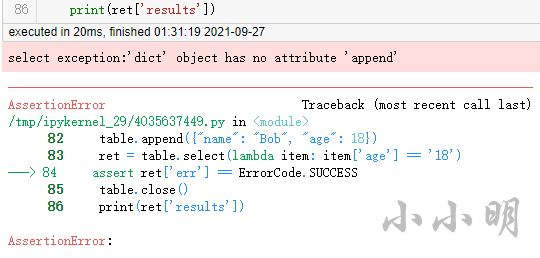
報錯,顯然我們可以排除A選項,
三種運行方式的快捷鍵見Cell選單:
分別表示只運行當前單元格、運行并選擇下一個單元格 和 運行并向下插入一個單元格,
大家可以都試試,感受一下區別,
復制B選項的代碼并運行后也報錯:
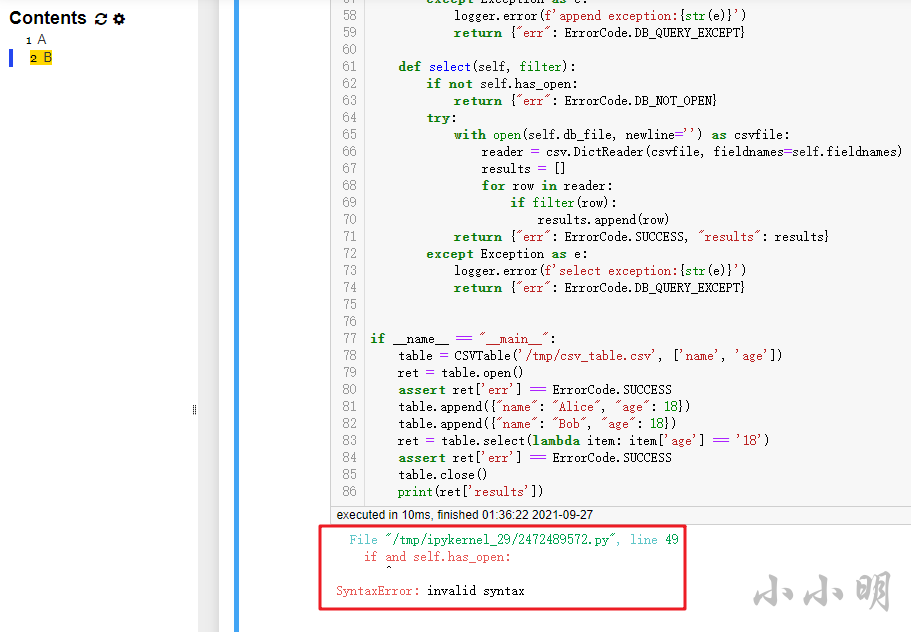
運氣比較好已經排除兩個選項了,繼續干C和D:
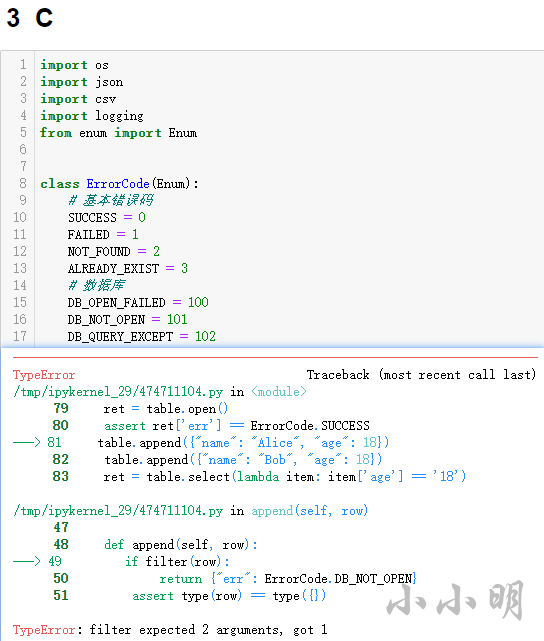
D選項居然正確了:
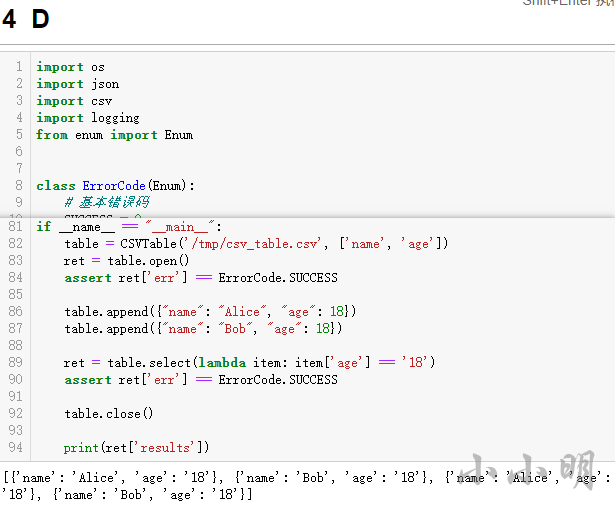
咱們就選個D試一下?
?Good,回答正確了:
差異代碼檢測
下面我們繼續下一題:

這次代碼終于簡化多了,這次全部復制粘貼到jupyter運行后發現,A和C報錯,B和D正確運行,

對于B和D這兩個選項的代碼,我看了好幾眼還真看不出區別在哪里,太像 《大家來找茬》 的找茬游戲了,
不過沒有關系,咱們有JupyterNotebook來運行Python代碼,標準庫difflib讓差異無處遁形:
import difflib
text1 = """import csv
def dump_list(file, list):
with open(file, 'w', newline='') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=' ',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
for row in list:
spamwriter.writerow(row)
def load_list(file):
with open(file, 'r', newline='') as csvfile:
spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
for row in spamreader:
yield row
if __name__ == "__main__":
rows = [
['Spam'] * 5 + ['Baked Beans'],
['Spam', 'Lovely Spam', 'Wonderful Spam']
]
list_file = '/tmp/list.csv'
dump_list(list_file, rows)
rows = load_list(list_file)
for row in rows:
for cell in row:
print(cell)"""
text2 = """import csv
def dump_list(file, list):
with open(file, 'w', newline='') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=' ',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
for row in list:
spamwriter.writerow(row)
def load_list(file):
with open(file, 'r', newline='') as csvfile:
spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
for row in spamreader:
yield row
if __name__ == "__main__":
rows = [
['Spam'] * 5 + ['Baked Beans'],
['Spam', 'Lovely Spam', 'Wonderful Spam']
]
list_file = '/tmp/list.csv'
dump_list(list_file, rows)
rows = load_list(list_file)
for row in rows:
while cell in row:
print(cell)"""
def diff_compare(text1, text2, diff_out="diff_result.html", max_width=30, numlines=0, show_all=False):
text1 = [row.rstrip() for row in text1.splitlines(keepends=True)]
text2 = [row.rstrip() for row in text2.splitlines(keepends=True)]
d = difflib.HtmlDiff(wrapcolumn=max_width)
with open(diff_out, 'w', encoding="u8") as f:
f.write(d.make_file(text1, text2, context=not show_all, numlines=numlines))
diff_compare(text1, text2, numlines=3)
運行后,打開生成的html檔案:
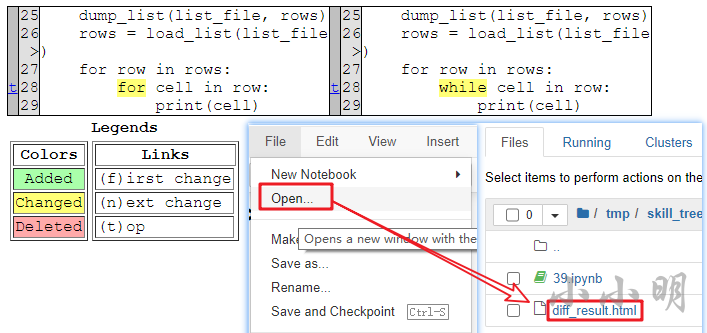
原來差異在一個選項是for,一個選項是while,當然選for的這個選項啦,
也可以使用IPython.display.HTML直接在jupyter中顯示網頁,代碼:
from IPython.display import HTML
def diff_compare(text1, text2, diff_out="diff_result.html", max_width=70, numlines=0, show_all=False):
text1 = [row for row in text1.splitlines(keepends=True)]
text2 = [row for row in text2.splitlines(keepends=True)]
d = difflib.HtmlDiff(wrapcolumn=max_width)
return d.make_file(text1, text2, context=not show_all, numlines=numlines)
diff_html = diff_compare(text1, text2, numlines=1)
HTML(diff_html)
效果:
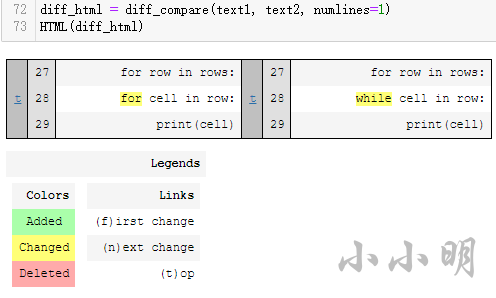
直接在單元格下方展示差異情況,
總體測評
以上就是個人體驗Jupyter notebook的全程序,個人感徑訓是挺方便的,幾乎跟本地自己安裝的Jupyter一樣的用,想裝啥插件也都可以直接裝,
不過,我有點想吐槽這個題,根本就不是技術題啊,純粹就是PK技術達標的情況下誰的眼力好啊,
不過呢,咱們還是可以通過代碼差異查找軟體,找出差異后進行對比分析,從而快速解題,代碼差異查找除了使用我上面所用的代碼還可以使用Beyond Compare這個軟體,
最后感謝CSDN,這個Jupyter服務雖然還處于VIP內測階段,但是已經挺好用了,相信未來還會越來越好,等未來正式發布的時候,一定非常好用后,沒有VIP的用戶們也可以使用該功能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/303599.html
標籤:python
上一篇:《正規軍的Python進階之路|Python技能樹測評》
下一篇:樹狀陣列小結