一、專案背景
隨著科技的不斷進步與發展,資料呈現爆發式的增長,各行各業對于資料的依賴越來越強,與資料打交道在所難免,而社會對于“資料”方面的人才需求也在不斷增大,因此了解當下企業究竟需要招聘什么樣的人才?需要什么樣的技能?不管是對于在校生,還是對于求職者來說,都顯得十分必要,
很多人學習python,不知道從何學起,
很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手,
很多已經做案例的人,卻不知道如何去學習更加高深的知識,
那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!
QQ群:701698587
歡迎加入,一起討論 一起學習!
對于一名小白來說,想要入門資料分析,首先要了解目前社會對于資料相關崗位的需求情況,基于這一問題,本文針對前程無憂招聘網站,利用python爬取了其全國范圍內大資料、資料分析、資料挖掘、機器學習、人工智能等與資料相關的崗位招聘資訊,并通過Tableau可視化工具分析比較了不同行業的崗位薪資、用人需求等情況;以及不同行業、崗位的知識、技能要求等,
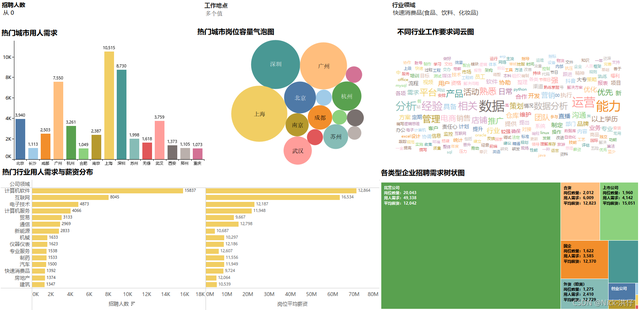
可視化分析效果圖示例:
二、資料爬取
爬取欄位:崗位名稱、公司名稱、薪資水平、作業經驗、學歷需求、作業地點、招聘人數、發布時間、公司型別、公司規模、行業領域、福利待遇、職位資訊;
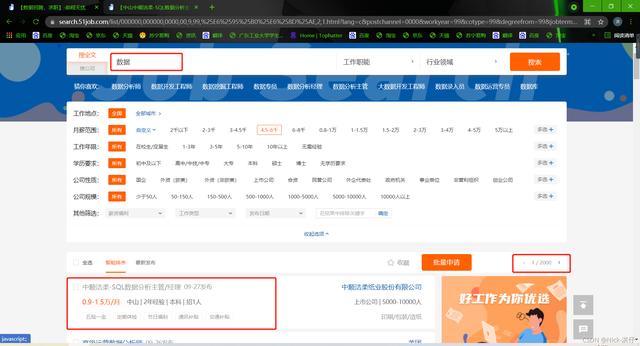
說明:在前程無憂招聘網站中,我們在搜索框中輸入“資料”兩個字進行搜索發現,共有2000個一級頁面,其中每個頁面包含50條崗位資訊,因此總共有約100000條招聘資訊,當點擊一級頁面中每個崗位資訊時,頁面會跳轉至相應崗位的二級頁面,二級頁面中即包含我們所需要的全部欄位資訊;
一級頁面如下:
二級頁面如下:
- 爬取思路:先針對一級頁面爬取所有崗位對應的二級頁面鏈接,再根據二級頁面鏈接遍歷爬取相應崗位資訊;
- 開發環境:python3、Spyder
1、相關庫的匯入與說明
import json
import requests
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
from selenium.webdriver import ChromeOptions由于前程無憂招聘網站的反爬機制較強,采用動態渲染+限制ip訪問頻率等多層反爬,因此在獲取二級頁面鏈接時需借助json進行決議,本文對于二級頁面崗位資訊的獲取采用selenium模擬瀏覽器爬取,同時通過代理IP的方式,每隔一段時間換一次請求IP以免觸發網站反爬機制,
2、獲取二級頁面鏈接
1)分析一級頁面url特征
# 第一頁URL的特征
"https://search.51job.com/list/000000,000000,0000,00,9,99,資料,2,1.html?"
# 第二頁URL的特征
"https://search.51job.com/list/000000,000000,0000,00,9,99,資料,2,2.html?"
# 第三頁URL的特征
"https://search.51job.com/list/000000,000000,0000,00,9,99,資料,2,3.html?"通過觀察不同頁面的URL可以發現,不同頁面的URL鏈接只有“.html”前面的數字不同,該數字正好代表該頁的頁碼 ,因此只需要構造字串拼接,然后通過for回圈陳述句即可構造自動翻頁,
2)構建一級url庫
url1 = []
for i in range(2000):
url_pre = "https://search.51job.com/list/000000,000000,0000,00,9,99,資料,2,%s" % (1+i) #設定自動翻頁
url_end = ".html?"
url_all = url_pre + url_end
url1.append(url_all)
print("一級URL庫創建完畢")3)爬取所有二級url鏈接
url2 = []
j = 0
for url in url1:
j += 1
re1 = requests.get(url , headers = headers,proxies= {'http':'tps131.kdlapi.com:15818'},timeout=(5,10)) #通過proxies設定代理ip
html1 = etree.HTML(re1.text)
divs = html1.xpath('//script[@type = "text/javascript"]/text()')[0].replace('window.__SEARCH_RESULT__ = ',"")
js = json.loads(divs)
for i in range(len(js['engine_jds'])):
if js['engine_jds'][i]['job_href'][0:22] == "https://jobs.51job.com":
url2.append(js['engine_jds'][i]['job_href'])
else:
print("url例外,棄用") #剔除例外url
print("已爬取"+str(j)+"頁")
print("成功爬取"+str(len(url2))+"條二級URL")注意:爬取二級URL鏈接時發現并非爬取的所有鏈接都是規范的,會存在少部分例外URL,這會對后續崗位資訊的爬取造成干擾,因此需要利用if條件陳述句對其進行剔除,
3、獲取崗位資訊并保存
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--proxy-server=http://tps131.kdlapi.com:15818') #設定代理ip
driver = webdriver.Chrome(options=option)
for url in url2:
co = 1
while co == 1:
try:
driver.get(url)
wait = WebDriverWait(driver,10,0.5)
wait.until(EC.presence_of_element_located((By.ID,'topIndex')))
except:
driver.close()
driver = webdriver.Chrome(options=option)
co = 1
else:
co = 0
try:
福利待遇 = driver.find_elements_by_xpath('//div[@class = "t1"]')[0].text
崗位名稱 = driver.find_element_by_xpath('//div[@class = "cn"]/h1').text
薪資水平 = driver.find_element_by_xpath('//div[@class = "cn"]/strong').text
職位資訊 = driver.find_elements_by_xpath('//div[@class = "bmsg job_msg inbox"]')[0].text
公司型別 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[0].text
公司規模 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[1].text
公司領域 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[2].text
公司名稱 = driver.find_element_by_xpath('//div[@class = "com_msg"]/a/p').text
作業地點 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[0]
作業經驗 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[1]
學歷要求 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[2]
招聘人數 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[3]
發布時間 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[4]
except:
福利待遇 = "nan"
崗位名稱 = "nan"
薪資水平 = "nan"
職位資訊 = "nan"
公司型別 = "nan"
公司規模 = "nan"
公司領域 = "nan"
公司名稱 = "nan"
作業地點 = "nan"
作業經驗 = "nan"
學歷要求 = "nan"
招聘人數 = "nan"
發布時間 = "nan"
print("資訊提取例外,棄用")
finally:
info = {
"崗位名稱" : 崗位名稱,
"公司名稱" : 公司名稱,
"薪資水平" : 薪資水平,
"作業經驗" : 作業經驗,
"學歷要求" : 學歷要求,
"作業地點" : 作業地點,
"招聘人數" : 招聘人數,
"發布時間" : 發布時間,
"公司型別" : 公司型別,
"公司規模" : 公司規模,
"公司領域" : 公司領域,
"福利待遇" : 福利待遇,
"職位資訊" : 職位資訊
}
jobs_info.append(info)
df = pd.DataFrame(jobs_info)
df.to_excel(r"E:\python爬蟲\前程無憂招聘資訊.xlsx") 在爬取并剔除例外資料之后,最終得到了90000多條完整的資料做分析,但經過觀察發現,所爬取的資料并非全都與“資料”崗位相關聯,實際上,前程無憂招聘網站上與“資料”有關的只有幾百頁,而我們爬取了2000頁的所有資料,因此在后面進行資料處理時需要把無關的資料剔除掉,在爬取前根據對代碼的測驗發現,有些崗位欄位在進行爬取時會出現錯位,從而導致資料存盤失敗,為了不影響后面代碼的執行,這里設定了“try-except”進行例外處理,同時使用while回圈陳述句在服務器出現請求失敗時關閉模擬瀏覽器并進行重新請求,
三、資料清洗
1、資料讀取、去重、空值處理
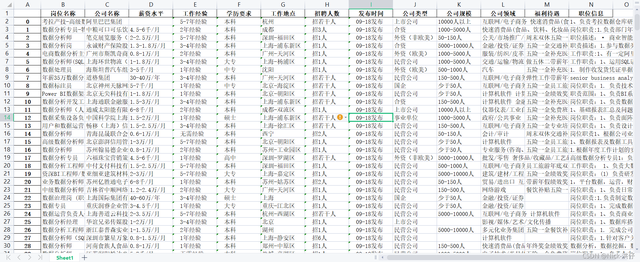
在獲取了所需資料之后,可以看出資料較亂,并不利于我們進行分析,因此在分析前需要對資料進行預處理,得到規范格式的資料才可以用來最終做可視化資料展示,
獲取的資料截圖如下:
1)相關庫匯入及資料讀取
#匯入相關庫
import pandas as pd
import numpy as np
import jieba
#讀取資料
df = pd.read_excel(r'E:\python爬蟲\前程無憂招聘資訊.xlsx',index_col=0)2)資料去重與控制處理
- 對于重復值的定義,我們認為一個記錄的公司名稱和崗位名稱一致時,即可看作是重復值,因此利用drop_duplicates()函式剔除所有公司名稱和崗位名稱相同的記錄并保留第一個記錄,
- 對于空值處理,只洗掉所有欄位資訊都為nan的記錄,
#去除重復資料
df.drop_duplicates(subset=['公司名稱','崗位名稱'],inplace=True)
#空值洗掉
df[df['公司名稱'].isnull()]
df.dropna(how='all',inplace=True)2、“崗位名稱”欄位預處理
1)”崗位名稱“欄位預覽
首先我們對“崗位名稱”的格式進行調整,將其中所有大寫英文字母統一轉換為小寫,例如將"Java"轉換為"java",然后對所有崗位做一個頻次統計,統計結果發現“崗位名稱”欄位很雜亂,且存在很多與“資料”無關的崗位,因此要對資料做一個篩選,
df['崗位名稱'] = df['崗位名稱'].apply(lambda x:x.lower())
counts = df['崗位名稱'].value_counts() 2)構建關鍵詞,篩選名稱
首先我們列出與“資料”崗位“有關的一系列關鍵詞,然后通過count()與for陳述句對所有記錄進行統計判斷,如果包含任一關鍵詞則保留該記錄,如果不包含則洗掉該欄位,
#構建目標關鍵詞
target_job = ['演算法','開發','分析','工程師','資料','運營','運維','it','倉庫','統計']
#篩選目標資料
index = [df['崗位名稱'].str.count(i) for i in target_job]
index = np.array(index).sum(axis=0) > 0
job_info = df[index]3)崗位名稱標準化處理
基于前面對“崗位名稱”欄位的統計情況,我們定義了目標崗位串列job_list,用來替換統一相近的崗位名稱,之后,我們將“資料專員”、“資料統計”統一歸為“資料分析”,
job_list = ['資料分析',"資料統計","資料專員",'資料挖掘','演算法','大資料','開發工程師','運營',
'軟體工程','前端開發','深度學習','ai','資料庫','倉庫管理','資料產品','客服',
'java','.net','andrio','人工智能','c++','資料管理',"測驗","運維","資料工程師"]
job_list = np.array(job_list)
def Rename(x,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info['崗位名稱'] = job_info['崗位名稱'].apply(Rename)
job_info["崗位名稱"] = job_info["崗位名稱"].apply(lambda x:x.replace("資料專員","資料分析"))
job_info["崗位名稱"] = job_info["崗位名稱"].apply(lambda x:x.replace("資料統計","資料分析"))統一之后的“崗位名稱”如下圖所示:
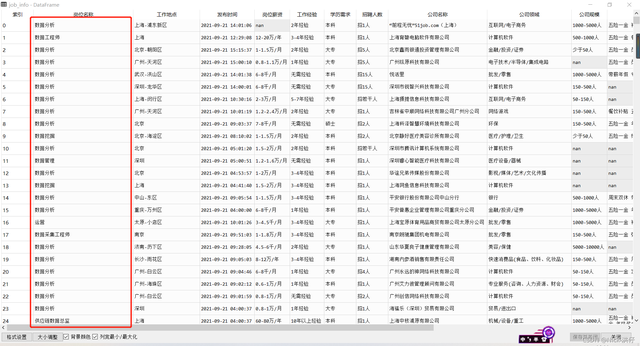
3、“崗位薪資”欄位預處理
對于“崗位薪資”欄位的處理,重點在于對其單位格式轉換,在簡單觀察該欄位后發現,其存在“萬/年”、“萬/月”、“千/月”等不同單位,因此需要對其做一個統一換算,將資料格式統一轉換為“元/月”,并根據最高工資與最低工資求出平均值,
job_info['崗位薪資'].value_counts()
#剔除例外資料
index1 = job_info["崗位薪資"].str[-1].isin(["年","月"])
index2 = job_info["崗位薪資"].str[-3].isin(["萬","千"])
job_info = job_info[index1 & index2]
#計算平均工資
job_info['平均薪資'] = job_info['崗位薪資'].astype(str).apply(lambda x:np.array(x[:-3].split('-'),dtype=float))
job_info['平均薪資'] = job_info['平均薪資'].apply(lambda x:np.mean(x))
#統一工資單位
job_info['單位'] = job_info['崗位薪資'].apply(lambda x:x[-3:])
def con_unit(x):
if x['單位'] == "萬/月":
z = x['平均薪資']*10000
elif x['單位'] == "千/月":
z = x['平均薪資']*1000
elif x['單位'] == "萬/年":
z = x['平均薪資']/12*10000
return int(z)
job_info['平均薪資'] = job_info.apply(con_unit,axis=1)
job_info['單位'] = '元/月'說明:首先我們對該欄位進行統計預覽,之后做一個資料篩選剔除例外單位與空值記錄,再計算出每個欄位的平均工資,接著定義一個函式,將格式換算為“元/月”,得到最終的“平均薪資”欄位,
4、“公司規模”欄位預處理
對于“公司規模”欄位的處理較簡單,只需要定義一個if條件陳述句將其格式做一個轉換即可,
job_info['公司規模'].value_counts()
def func(x):
if x == '少于50人':
return "<50"
elif x == '50-150人':
return "50-150"
elif x == '150-500人':
return '150-500'
elif x == '500-1000人':
return '500-1000'
elif x == '1000-5000人':
return '1000-5000'
elif x == '5000-10000人':
return '5000-10000'
elif x == '10000人以上':
return ">10000"
else:
return np.nan
job_info['公司規模'] = job_info['公司規模'].apply(func)5、“職位資訊”欄位預處理
job_info['職位資訊'] = job_info['職位資訊'].apply(lambda x:x.split('職能類別')[0])
with open(r"E:\python爬蟲\資料處理\停用詞表.txt",'r',encoding = 'utf8') as f:
stopword = f.read()
stopword = stopword.split()
#對“職業資訊”欄位進行簡單處理,去除無意義的文字,構造jieba分詞
job_info['職位資訊'] = job_info['職位資訊'].apply(lambda x:x.lower()).apply(lambda x:"".join(x)).apply(lambda x:x.strip()).apply(jieba.lcut).apply(lambda x:[i for i in x if i not in stopword])
#按照行業進行分類,求出每一個行業下各關鍵詞的詞頻統計,以便于后期做詞云圖
cons = job_info['公司領域'].value_counts()
industries = pd.DataFrame(cons.index,columns=['行業領域'])
industry = pd.DataFrame(columns=['分詞明細','行業領域'])
for i in industries['行業領域']:
words = []
word = job_info['職位資訊'][job_info['公司領域'] == i]
word.dropna(inplace=True)
[words.extend(str(z).strip('\'[]').split("\', \'")) for z in word]
df1 = pd.DataFrame({'分詞明細':words,
'行業領域':i})
industry = industry.append(df1,ignore_index=True)
industry = industry[industry['分詞明細'] != "\\n"]
industry = industry[industry['分詞明細'] != ""]
#剔除詞頻小于300的關鍵詞
count = pd.DataFrame(industry['分詞明細'].value_counts())
lst = list(count[count['分詞明細'] >=300].index)
industry = industry[industry['分詞明細'].isin(lst)]
#資料存盤
industry.to_excel(r'E:\python爬蟲\資料處理\詞云.xlsx') 6、其它欄位預處理
“作業地點”欄位:該欄位有”市-區“和”市“兩種格式,如”廣州-天河“與”廣州“,因此需要統一轉換為”市“的格式;
“公司領域”欄位:每個公司的行業欄位可能會有多個行業標簽,我們默認以第一個作為改公司的行業標簽;
“招聘人數”欄位:由于某些公司崗位沒有具體招聘人數,因此我們默認以最低需求為標準,將“招若干人”改為“招1人”,以便于后面統計分析;
其它欄位:對于其他幾個欄位格式只存在一些字串空格問題,因此只需要對其進行去除空格即可,
#作業地點欄位處理
job_info['作業地點'] = job_info['作業地點'].apply(lambda x:x.split('-')[0])
#公司領域欄位處理
job_info['公司領域'] = job_info['公司領域'].apply(lambda x:x.split('/')[0])
a = job_info['公司領域'].value_counts()
#招聘人數欄位處理
job_info['招聘人數'] = job_info['招聘人數'].apply(lambda x:x.replace("若干","1").strip()[1:-1])
#作業經驗與學歷要求欄位處理
job_info['作業經驗'] = job_info['作業經驗'].apply(lambda x:x.replace("無需","1年以下").strip()[:-2])
job_info['學歷需求'] = job_info['學歷需求'].apply(lambda x:x.split()[0])
#公司福利欄位處理
job_info['公司福利'] = job_info['公司福利'].apply(lambda x:str(x).split())7、資料存盤
我們針對清洗干凈后的資料另存為一個檔案,對源資料不做修改,
job_info.to_excel(r'E:\python爬蟲\前程無憂(已清洗).xlsx')四、Tableau資料可視化展示
1、崗位數量城市分布氣泡圖
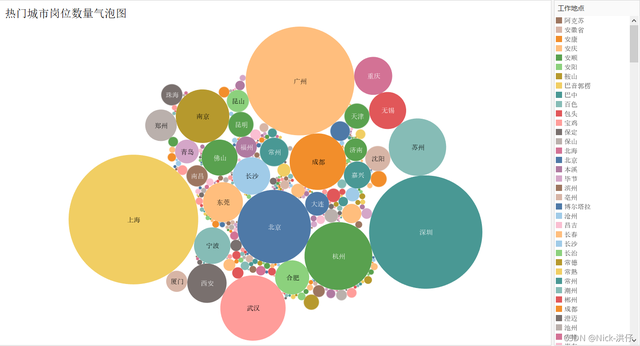
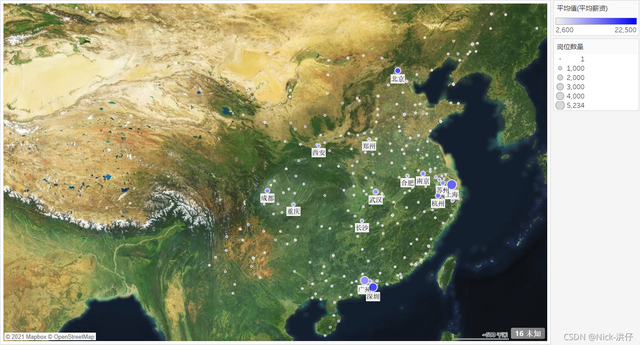
結論分析:從氣泡圖中可以看出,“資料”相關崗位數量較高的城市有:上海、深圳、廣州、北京、杭州、武漢等,
2、熱門城市用人需求Top15
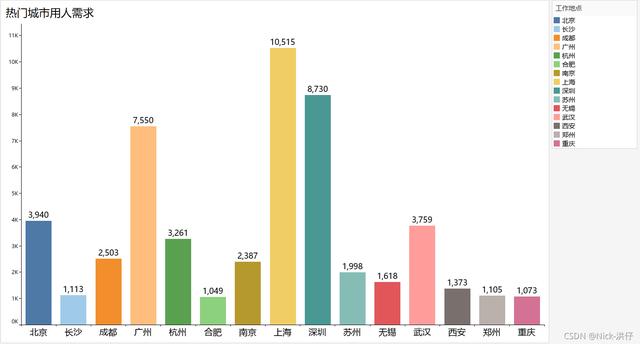
結論分析:通過條形圖可以看出,“資料”相關崗位用人需求達1000人以上的城市有15個,需求由高到低依次為:上海、深圳、廣州、北京、武漢、杭州、成都、南京、蘇州、無錫、西安、長沙、鄭州、重慶,其中上海用人需求高達10000人,
3、用人需求Top15行業及其薪資情況
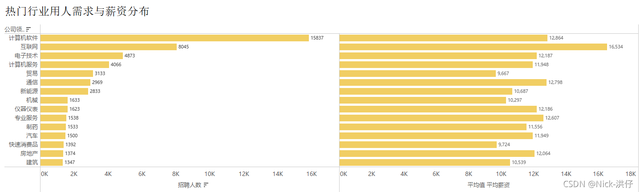
結論分析:從不同行業的用人需求與薪資對比可知,用人需求排名前4的行業分別:計算機軟體、互聯網、電子技術、計算機服務;平均薪資排名前4的行業分別為:互聯網、計算機軟體、通信、專業服務,可以發現,“資料”相關崗位在計算機領域需求大,薪資高,前景好,
4、各型別企業崗位需求樹狀分布圖
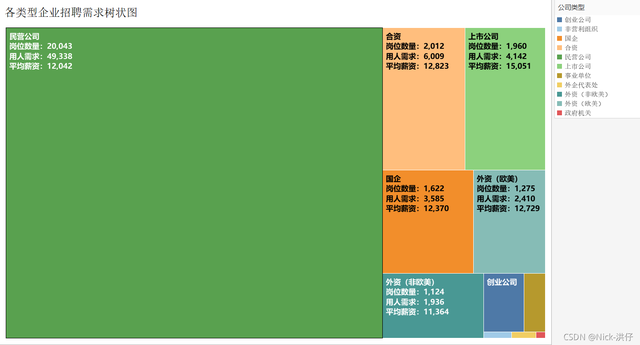
結論分析:在發布的眾多崗位需求資訊中,以民營公司為主,其崗位數量、用人需求極高,但薪資待遇一般,而上市公司的崗位數量一般,但薪資待遇好,
5、經驗學歷與薪資需求突出顯示表
注:顏色深淺表示薪資高低,數字表示招聘人數
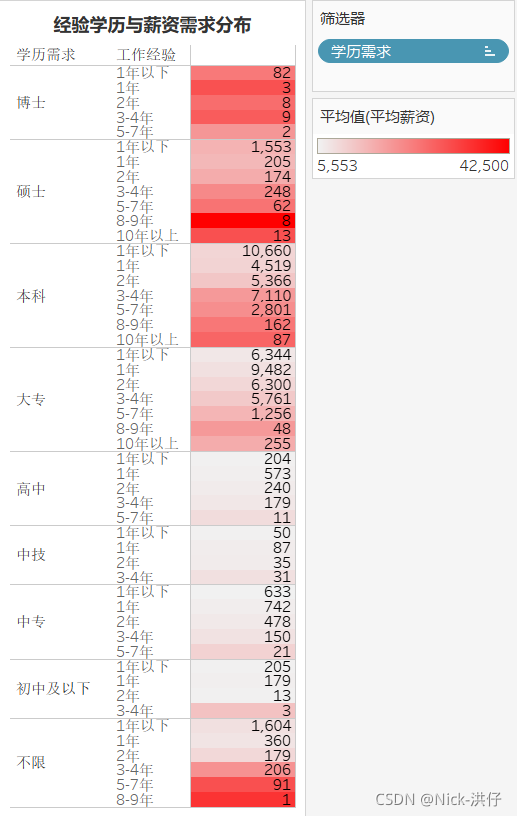
結論分析:根據突出顯示表可以發現,在學歷要求方面,大專與本科生需求量較大;經驗要求方面,3年以下相關經驗的崗位占大多數,而薪資方面,學歷越高,經驗越豐富則薪資越高,因此可以判斷資料分析行業還是一個較新興的行業,目前行業的基礎崗位較多,且具有豐富經驗的專家較少,
6、不同行業知識、技能要求詞云圖
1)傳統制造業

2) 計算機相關行業

3)服務行業

結論分析:上圖通過列舉了傳統制造業、計算機相關行業以及服務業三個行業進行對比分析,三個行業對于“資料”相關崗位作業要求的共同點都是注重相關的行業經驗及資料處理等能力,而計算機相關行業對于技術如開發、資料庫、系統維護等編程能力要求較高,傳統制造業和服務行業則更側重于業務分析、管理、團隊合作綜合型能力等,
6、崗位數量與薪資水平地理分布
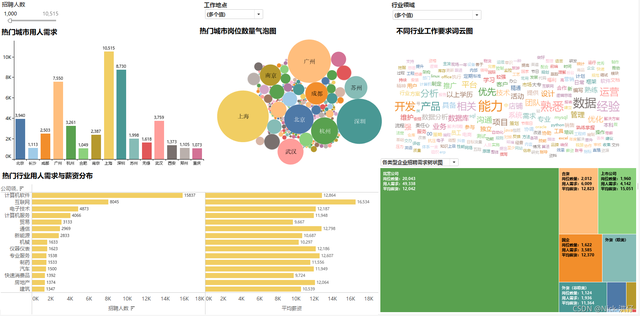
7、可視化看板最終展示結果
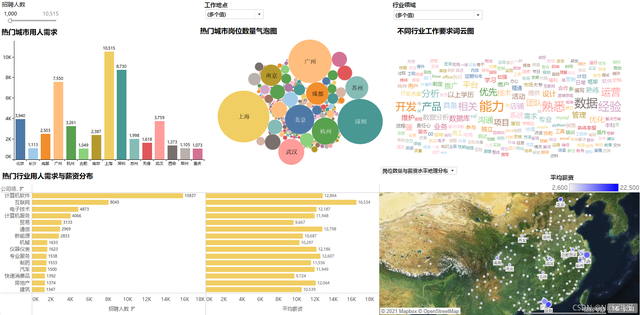
五、源代碼
1、爬蟲源代碼
import json
import requests
import pandas as pd
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
url1 = []
url2 = []
jobs_info = []
for i in range(2000):
url_pre = "https://search.51job.com/list/000000,000000,0000,00,9,99,資料,2,%s" % (1+i) #頁面跳轉
url_end = ".html?"
url_all = url_pre + url_end
url1.append(url_all)
print("一級URL庫創建完畢")
#從json中提取資料并加載
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'Connection': 'close',
'Host': 'search.51job.com'}
j = 0
for url in url1:
j += 1
re1 = requests.get(url , headers = headers,proxies= {'http':'tps131.kdlapi.com:15818'},timeout=(5,10))
html1 = etree.HTML(re1.text)
divs = html1.xpath('//script[@type = "text/javascript"]/text()')[0].replace('window.__SEARCH_RESULT__ = ',"")
js = json.loads(divs)
for i in range(len(js['engine_jds'])):
if js['engine_jds'][i]['job_href'][0:22] == "https://jobs.51job.com":
url2.append(js['engine_jds'][i]['job_href'])
else:
print("url例外,棄用")
print("已決議"+str(j)+"頁")
print("成功提取"+str(len(url2))+"條二級URL")
#爬取崗位資料
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--proxy-server=http://tps131.kdlapi.com:15818')
driver = webdriver.Chrome(options=option)
for url in url2:
co = 1
while co == 1:
try:
#設定IP代理
driver.get(url)
wait = WebDriverWait(driver,10,0.5)
wait.until(EC.presence_of_element_located((By.ID,'topIndex')))
except:
driver.close()
driver = webdriver.Chrome(options=option)
co = 1
else:
co = 0
try:
福利待遇 = driver.find_elements_by_xpath('//div[@class = "t1"]')[0].text
崗位名稱 = driver.find_element_by_xpath('//div[@class = "cn"]/h1').text
薪資水平 = driver.find_element_by_xpath('//div[@class = "cn"]/strong').text
職位資訊 = driver.find_elements_by_xpath('//div[@class = "bmsg job_msg inbox"]')[0].text
公司型別 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[0].text
公司規模 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[1].text
公司領域 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[2].text
公司名稱 = driver.find_element_by_xpath('//div[@class = "com_msg"]/a/p').text
作業地點 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[0]
作業經驗 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[1]
學歷要求 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[2]
招聘人數 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[3]
發布時間 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[4]
except:
福利待遇 = "nan"
崗位名稱 = "nan"
薪資水平 = "nan"
職位資訊 = "nan"
公司型別 = "nan"
公司規模 = "nan"
公司領域 = "nan"
公司名稱 = "nan"
作業地點 = "nan"
作業經驗 = "nan"
學歷要求 = "nan"
招聘人數 = "nan"
發布時間 = "nan"
print("資訊提取例外,棄用")
finally:
info = {
"崗位名稱" : 崗位名稱,
"公司名稱" : 公司名稱,
"薪資水平" : 薪資水平,
"作業經驗" : 作業經驗,
"學歷要求" : 學歷要求,
"作業地點" : 作業地點,
"招聘人數" : 招聘人數,
"發布時間" : 發布時間,
"公司型別" : 公司型別,
"公司規模" : 公司規模,
"公司領域" : 公司領域,
"福利待遇" : 福利待遇,
"職位資訊" : 職位資訊
}
jobs_info.append(info)
df = pd.DataFrame(jobs_info)
df.to_excel(r"E:\python爬蟲\前程無憂招聘資訊.xlsx") 2、資料預處理原始碼
import pandas as pd
import numpy as np
import jieba
#資料讀取
df = pd.read_excel(r'E:\python爬蟲\前程無憂招聘資訊.xlsx',index_col=0)
#資料去重與空值處理
df.drop_duplicates(subset=['公司名稱','崗位名稱'],inplace=True)
df[df['招聘人數'].isnull()]
df.dropna(how='all',inplace=True)
#崗位名稱欄位處理
df['崗位名稱'] = df['崗位名稱'].apply(lambda x:x.lower())
counts = df['崗位名稱'].value_counts()
target_job = ['演算法','開發','分析','工程師','資料','運營','運維','it','倉庫','統計']
index = [df['崗位名稱'].str.count(i) for i in target_job]
index = np.array(index).sum(axis=0) > 0
job_info = df[index]
job_list = ['資料分析',"資料統計","資料專員",'資料挖掘','演算法','大資料','開發工程師',
'運營','軟體工程','前端開發','深度學習','ai','資料庫','倉庫管理','資料產品',
'客服','java','.net','andrio','人工智能','c++','資料管理',"測驗","運維","資料工程師"]
job_list = np.array(job_list)
def Rename(x,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info['崗位名稱'] = job_info['崗位名稱'].apply(Rename)
job_info["崗位名稱"] = job_info["崗位名稱"].apply(lambda x:x.replace("資料專員","資料分析"))
job_info["崗位名稱"] = job_info["崗位名稱"].apply(lambda x:x.replace("資料統計","資料分析"))
#崗位薪資欄位處理
index1 = job_info["崗位薪資"].str[-1].isin(["年","月"])
index2 = job_info["崗位薪資"].str[-3].isin(["萬","千"])
job_info = job_info[index1 & index2]
job_info['平均薪資'] = job_info['崗位薪資'].astype(str).apply(lambda x:np.array(x[:-3].split('-'),dtype=float))
job_info['平均薪資'] = job_info['平均薪資'].apply(lambda x:np.mean(x))
#統一工資單位
job_info['單位'] = job_info['崗位薪資'].apply(lambda x:x[-3:])
job_info['公司領域'].value_counts()
def con_unit(x):
if x['單位'] == "萬/月":
z = x['平均薪資']*10000
elif x['單位'] == "千/月":
z = x['平均薪資']*1000
elif x['單位'] == "萬/年":
z = x['平均薪資']/12*10000
return int(z)
job_info['平均薪資'] = job_info.apply(con_unit,axis=1)
job_info['單位'] = '元/月'
#作業地點欄位處理
job_info['作業地點'] = job_info['作業地點'].apply(lambda x:x.split('-')[0])
#公司領域欄位處理
job_info['公司領域'] = job_info['公司領域'].apply(lambda x:x.split('/')[0])
#招聘人數欄位處理
job_info['招聘人數'] = job_info['招聘人數'].apply(lambda x:x.replace("若干","1").strip()[1:-1])
#作業經驗與學歷要求欄位處理
job_info['作業經驗'] = job_info['作業經驗'].apply(lambda x:x.replace("無需","1年以下").strip()[:-2])
job_info['學歷需求'] = job_info['學歷需求'].apply(lambda x:x.split()[0])
#公司規模欄位處理
job_info['公司規模'].value_counts()
def func(x):
if x == '少于50人':
return "<50"
elif x == '50-150人':
return "50-150"
elif x == '150-500人':
return '150-500'
elif x == '500-1000人':
return '500-1000'
elif x == '1000-5000人':
return '1000-5000'
elif x == '5000-10000人':
return '5000-10000'
elif x == '10000人以上':
return ">10000"
else:
return np.nan
job_info['公司規模'] = job_info['公司規模'].apply(func)
#公司福利欄位處理
job_info['公司福利'] = job_info['公司福利'].apply(lambda x:str(x).split())
#職位資訊欄位處理
job_info['職位資訊'] = job_info['職位資訊'].apply(lambda x:x.split('職能類別')[0])
with open(r"E:\C++\停用詞表.txt",'r',encoding = 'utf8') as f:
stopword = f.read()
stopword = stopword.split()
job_info['職位資訊'] = job_info['職位資訊'].apply(lambda x:x.lower()).apply(lambda x:"".join(x)).apply(lambda x:x.strip()).apply(jieba.lcut).apply(lambda x:[i for i in x if i not in stopword])
cons = job_info['公司領域'].value_counts()
industries = pd.DataFrame(cons.index,columns=['行業領域'])
industry = pd.DataFrame(columns=['分詞明細','行業領域'])
for i in industries['行業領域']:
words = []
word = job_info['職位資訊'][job_info['公司領域'] == i]
word.dropna(inplace=True)
[words.extend(str(z).strip('\'[]').split("\', \'")) for z in word]
df1 = pd.DataFrame({'分詞明細':words,
'行業領域':i})
industry = industry.append(df1,ignore_index=True)
industry = industry[industry['分詞明細'] != "\\n"]
industry = industry[industry['分詞明細'] !=