JDK 8 中的 HashMap 是用陣列+鏈表+紅黑樹實作的,我們要想往 HashMap 中放資料或者取資料,就需要確定資料在陣列中的下標,
先把資料的鍵進行一次 hash:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
再做一次取模運算確定下標:
i = (n - 1) & hash
哈希表這樣的資料結構容易產生兩個問題:
- 陣列的容量過小,經過哈希計算后的下標,容易出現沖突;
- 陣列的容量過大,導致空間利用率不高,
加載因子是用來表示 HashMap 中資料的填滿程度:
加載因子 = 填入哈希表中的資料個數 / 哈希表的長度
這就意味著:
- 加載因子越小,填滿的資料就越少,哈希沖突的幾率就減少了,但浪費了空間,而且還會提高擴容的觸發幾率;
- 加載因子越大,填滿的資料就越多,空間利用率就高,但哈希沖突的幾率就變大了,
好難!!!!
這就必須在“哈希沖突”與“空間利用率”兩者之間有所取舍,盡量保持平衡,誰也不礙著誰,
我們知道,HashMap 是通過拉鏈法來解決哈希沖突的,
為了減少哈希沖突發生的概率,當 HashMap 的陣列長度達到一個臨界值的時候,就會觸發擴容(可以點擊鏈接查看 HashMap 的擴容機制),擴容后會將之前小陣列中的元素轉移到大陣列中,這是一個相當耗時的操作,
這個臨界值由什么來確定呢?
臨界值 = 初始容量 * 加載因子
一開始,HashMap 的容量是 16:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
加載因子是 0.75:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
也就是說,當 16*0.75=12 時,會觸發擴容機制,
為什么加載因子會選擇 0.75 呢?為什么不是0.8、0.6呢?
這跟統計學里的一個很重要的原理——泊松分布有關,
是時候上維基百科了:
泊松分布,是一種統計與概率學里常見到的離散概率分布,由法國數學家西莫恩·德尼·泊松在1838年時提出,它會對隨機事件的發生次數進行建模,適用于涉及計算在給定的時間段、距離、面積等范圍內發生隨機事件的次數的應用情形,
阮一峰老師曾在一篇博文中詳細的介紹了泊松分布和指數分布,大家可以去看一下,
鏈接:https://www.ruanyifeng.com/blog/2015/06/poisson-distribution.html
具體是用這么一個公式來表示的,
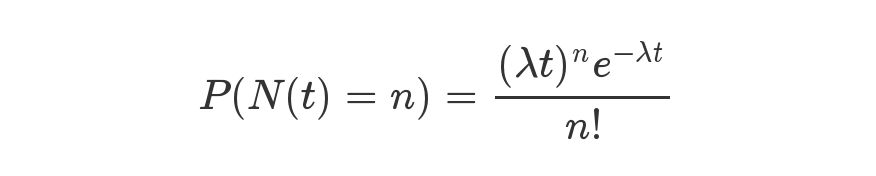
等號的左邊,P 表示概率,N表示某種函式關系,t 表示時間,n 表示數量,
在 HashMap 的 doc 檔案里,曾有這么一段描述:
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used. Ideally, under random hashCodes, the frequency of
nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a
parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because of
resizing granularity. Ignoring variance, the expected
occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
大致的意思就是:
因為 TreeNode(紅黑樹)的大小約為鏈表節點的兩倍,所以我們只有在一個拉鏈已經拉了足夠節點的時候才會轉為tree(參考TREEIFY_THRESHOLD),并且,當這個hash桶的節點因為移除或者擴容后resize數量變小的時候,我們會將樹再轉為拉鏈,如果一個用戶的資料的hashcode值分布得很均勻的話,就會很少使用到紅黑樹,
理想情況下,我們使用隨機的hashcode值,加載因子為0.75情況,盡管由于粒度調整會產生較大的方差,節點的分布頻率仍然會服從引數為0.5的泊松分布,鏈表的長度為 8 發生的概率僅有 0.00000006,
雖然這段話的本意更多的是表示 jdk 8中為什么拉鏈長度超過8的時候進行了紅黑樹轉換,但提到了 0.75 這個加載因子——但這并不是為什么加載因子是 0.75 的答案,
為了搞清楚到底為什么,我看到了這篇文章:
參考鏈接:https://segmentfault.com/a/1190000023308658
里面提到了一個概念:二項分布(二哥概率論沒學好,只能簡單說一說),
在做一件事情的時候,其結果的概率只有2種情況,和拋硬幣一樣,不是正面就是反面,
為此,我們做了 N 次實驗,那么在每次試驗中只有兩種可能的結果,并且每次實驗是獨立的,不同實驗之間互不影響,每次實驗成功的概率都是一樣的,
以此理論為基礎,我們來做這樣的實驗:我們往哈希表中扔資料,如果發生哈希沖突就為失敗,否則為成功,
我們可以設想,實驗的hash值是隨機的,并且經過hash運算的鍵都會映射到hash表的地址空間上,那么這個結果也是隨機的,所以,每次put的時候就相當于我們在扔一個16面(我們先假設默認長度為16)的骰子,扔骰子實驗那肯定是相互獨立的,碰撞發生即扔了n次有出現重復數字,
然后,我們的目的是啥呢?
就是擲了k次骰子,沒有一次是相同的概率,需要盡可能的大些,一般意義上我們肯定要大于0.5(這個數是個理想數,但是我是能接受的),
于是,n次事件里面,碰撞為0的概率,由上面公式得:
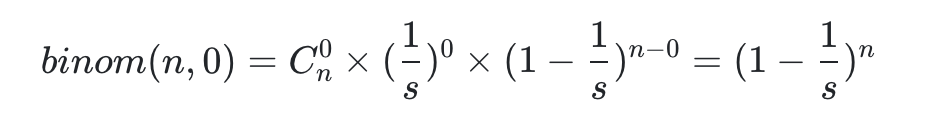
這個概率值需要大于0.5,我們認為這樣的hashmap可以提供很低的碰撞率,所以:
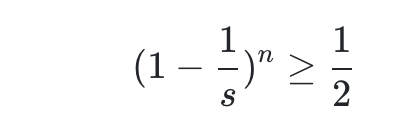
這時候,我們對于該公式其實最想求的時候長度s的時候,n為多少次就應該進行擴容了?而負載因子則是 n / s n/s n/s的值,所以推導如下:

所以可以得到
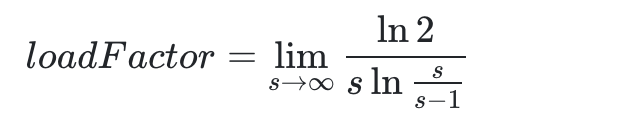
其中
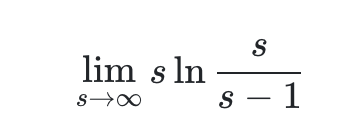
這就是一個求 ∞?0函式極限問題,這里我們先令
s
=
m
+
1
(
m
→
∞
)
s = m+1(m \to \infty)
s=m+1(m→∞)則轉化為
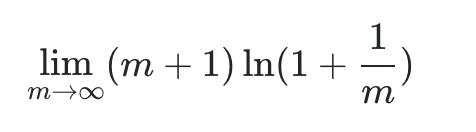
我們再令 x = 1 m ( x → 0 ) x = \frac{1}{m} (x \to 0) x=m1?(x→0) 則有,

所以,
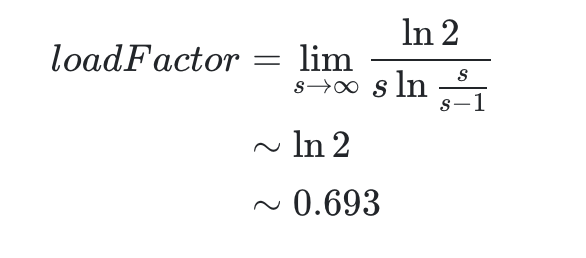
考慮到 HashMap的容量有一個要求:它必須是2的n 次冪(這個之前的文章講過了,點擊鏈接回去可以再溫故一下),當加載因子選擇了0.75就可以保證它與容量的乘積為整數,
16*0.75=12
32*0.75=24
除了 0.75,0.5~1 之間還有 0.625(5/8)、0.875(7/8)可選,從中位數的角度,挑 0.75 比較完美,另外,維基百科上說,拉鏈法(解決哈希沖突的一種)的加載因子最好限制在 0.7-0.8以下,超過0.8,查表時的CPU快取不命中(cache missing)會按照指數曲線上升,
綜上,0.75 是個比較完美的選擇,
本文 GitHub 上已同步,有 GitHub 賬號的小伙伴,記得給二哥安排一波 star 呀!沖 GitHub 的 trending 榜單,求求各位了,
GitHub 地址:https://github.com/itwanger/toBeBetterJavaer
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/303870.html
標籤:java