這里寫目錄標題
- 整型資料在記憶體中的存盤
- 預備知識
- 原碼、反碼、補碼
- 大小端介紹
- 定義:
- 為什么要有大小端?
- 設計一個程式判斷大小端
- 針對整型資料存盤的練習題
- 1、此代碼段輸出結果是?
- 分析
- 2、求出下面程式的輸出結果
- 分析
- 4、求程式輸出結果
- 分析
- 5、繼續求程式輸出結果
- 分析
- 6、求程式輸出結果
- 分析
- 7求程式段結果
- 分析
整型資料在記憶體中的存盤
預備知識
原碼、反碼、補碼
計算機中的有符號數有三種表示方式,即原碼、反碼和補碼
三種表示方法各不相同,
原碼:直接將二進制按照正負數的形式翻譯成二進制即可
反碼:原碼符號位不變,其余位取反
補碼:反碼+1
正數的原碼反碼補碼相同
大小端介紹
定義:
大端(存盤)模式:資料的低位保存在記憶體的高地址中,資料的高位保存在記憶體的低地址中
小端(存盤)模式:資料的低位保存在記憶體的低地址中,資料的高位保存在記憶體的高地址中
為什么要有大小端?
在計算機系統中,以位元組為單位,每個地址單元都對應著一個位元組,一個位元組為8bit,對于位數大于8位的處理器來說,由于暫存器寬度大于一個位元組,那么必然存在著一個如何將多個位元組安排的問題,因此就導致了大端存盤模式和小端存盤模式,
設計一個程式判斷大小端
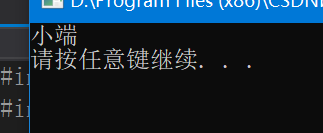
int check_sys()
{
int i = 1;
return (*(char*)&i);//首先取到i的地址,強轉為char*,再對其解參考
}
int main()
{
int ret = check_sys();
if (ret)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
system("pause");
return 0;
}
針對整型資料存盤的練習題
1、此代碼段輸出結果是?
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
分析
a,b,c三個變數的初始化值都為-1;
-1的補碼:1111 1111 1111 1111 1111 1111 1111 1111
對于a和b來說,char型別和signed char型別一樣,故而輸出的結果也一樣,
首先,記憶體中存盤的是-1的補碼,由于char型別只占一個位元組,故而在寫入記憶體是發生截斷,記憶體中存盤的為二進制序列1111 1111,
輸出函式以“%d”的形式列印,而從記憶體中取出來的資料為1111 1111,所以要發生整形提升,位元位由原來的8位提升到32位,整型提升時高位補1還是補0需要看自身型別,a,b為有符號數,故而補1,
所以此時二進制序列變為1111 1111 1111 1111 1111 1111 1111 1111,而又因為資料是按照“%d”(有符號數)列印,看最高位為1,所以說這個二進制序列為結果的補碼,我們將其轉換為原碼后結果為:1000 0000 0000 0000 0000 0000 0000 0001,對應我們十進制的-1,所以,a,b的輸出結果均為-1,
對于變數c來說,它的型別為unsigned char,根據前面的思路,資料在寫入記憶體時進行了一樣的操作,而從記憶體取資料時就有所差異了!
取出來的資料依舊是二進制序列1111 1111,發生整形提升時高位補1還是 補0需要看自身型別,由于c是無符號數,所以補0,
也就是說,此時的二進制序列從為 0000 0000 0000 0000 0000 0000 1111 1111,又因為資料是按照“%d”(有符號數)列印,看最高位為0,所以此時的二進制序列就是對應的結果,也就是十進制的255,
綜上所述,輸出的結果是:a=-1,b=-1,c=255

2、求出下面程式的輸出結果
#include <stdio.h>
int main()
{
char a = -128;
char b = 128;
printf("%u\t%u\n",a,b);
return 0;
}
分析
-128 的補碼為:1111 1111 1111 1111 1111 1111 1000 0000
128的補碼為: 0000 0000 0000 0000 0000 0000 1000 0000
將該資料寫入記憶體時,由于a,b的型別均為 char,所以會發生截斷,只將1000 0000存入a中,1000 0000存入b中,
取資料時:將二進制序列1000 0000從記憶體中取出,由于要以“%u”的形式輸出,所以需要對a和b都要做整形提升,
由于a,b的自身型別為char,有符號型別且1000 0000高位為1,所以高位補1,形成新的二進制序列為1111 1111 1111 1111 1111 1111 1000 0000
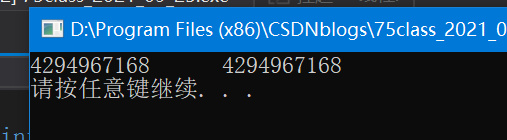
輸出函式以“%u”輸出,為無符號型別,所以新的二進制序列即為最終結果!對應十進制的4,294,967,168

4、求程式輸出結果
int i = -20;
unsigned int j = 10;
printf("%d\n",i+j);
分析
按照補碼的形式進行計算,最后格式化為有符號整數
-20的補碼為:1111 1111 1111 1111 1111 1111 1110 1100,
10的補碼為:0000 0000 0000 0000 0000 0000 0000 1010
二者相加的二進制序列為:1111 1111 1111 1111 1111 1111 1111 0110
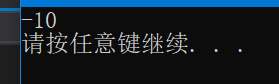
以“%d”輸出,二進制序列符號位為1,說以是負數,說明此二進制序列為最終結果的補碼,所以將其進行轉換,最終結果為:1000 0000 0000 0000 0000 0000 0000 1010,對應十進制的-10,
相應地,這里也間接說明,兩個型別不一致的資料做運算時,要發生隱式型別準換,只有型別一致時,才可以進行預算,
5、繼續求程式輸出結果
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n",i);
}
分析
對于此題來說,首先,變數i的型別是無符號整型資料,for回圈中的條件判斷為i>=0,運算式左右兩邊的型別不一致,所以要發生隱式型別轉換,
當i逐次遞減,減到0的時候,下一次理應為-1,此時從記憶體中讀取出來i的二進制序列為:1111 1111 1111 1111 1111 1111 1111 1111,但是i的型別為無符號整型資料,所以此二進制序列就是最終結果,也就是說此時i的值變成了unsigned int 的最大值;也就是說,每次i遞減到0的時候,下一次就會變成unsigned int 的最大值,
綜上,此程式代碼為死回圈,具體輸出結果是:
9 8 7 6 5 4 3 2 1 0 4294967295 …0 4294967295…0無限回圈,
6、求程式輸出結果
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}
分析
陣列a的容量為1000,每一個元素型別為char,for 回圈做的操作是對陣列的 每一個單元重新賦值,最后輸出的值是strlen(a)
stelen():求字串長度,以‘\0’(實際存盤為數字0)作為結束標志,不包括‘\0’在內,
也就是說,此題的主要問題在于回圈經歷多少次之后,對陣列單元的賦值為0???
我們知道,char型別的資料取值范圍為[-128~127],也就是說,只要 -1-i 的值在此范圍內,就是合法的,
i = 0---->a[i] = -1
i = 1---->a[i] = -2
以此類推
i=127------>a[i] = -128、
i = 128----->a[i] = -129??? 很明顯出錯了,超出了char的范圍,
-129補碼:1111 1111 1111 1111 1111 1111 0111 1111
由于陣列型別為char型別,故而發生截斷,得到新的二進制序列為0111 1111,重新寫回陣列a時,判斷最高位為0,所以此二進制序列就是最終結果,對應十進制的的127.
也就是說,
i = 128 時----->a[i] = 127
由此可以看出,i不斷遞增的程序中,a[i]的資料內容從-1遞減到-128然后由-128變成127,再由127遞減到0,
這總共經歷了128+128-1(最后一個0不包括在內)長度
所以最終結果為:255
7求程式段結果
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}
分析
對于回圈變數i:它的型別為unsigned char ,取值范圍為[0~255]
當i的值為255時,合法,再加1理應為256,對應的原碼為1 0000 0000,補碼和原碼一致,但是在存入時要發生截斷,存入的資料實際為0000 0000,對應十進制的0
綜上所述:此代碼段的結果是發生死回圈,因為i 的值從0增長到255再變成0,然后再到255,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/303995.html
標籤:python