一、前言
作者:tiezhu
本人和賬號作者是朋友,以后將會公用此賬號發布文章,也是一個學習爬蟲的小白
此篇文章僅供學習交流,切勿用于其他用途,否則后果自負!
二、程序分析
需要使用的庫
import base64
import requests
import re
import os
import http.cookiejar as cookielib
# import pickle
import execjs
import time
import json
from PIL import Image
from urllib import parse
首先進入到微博的主頁:
https://weibo.com/
很多人學習python,不知道從何學起, 很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手, 很多已經做案例的人,卻不知道如何去學習更加高深的知識, 那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼! QQ群:701698587 歡迎加入,一起討論 一起學習!
之后按下F12開始咱們的抓包程序
輸入賬號密碼,點擊登錄
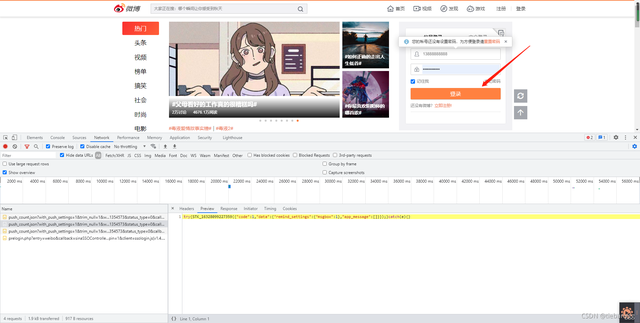
當然這里的賬號密碼,各位要輸入自己正確的,之后會來到二維碼掃碼登錄頁面
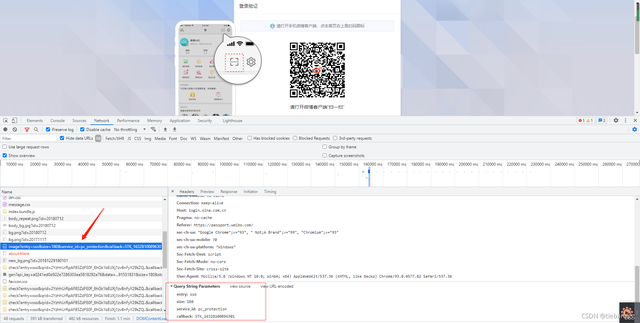
很容易的就會找到包含二維碼的api
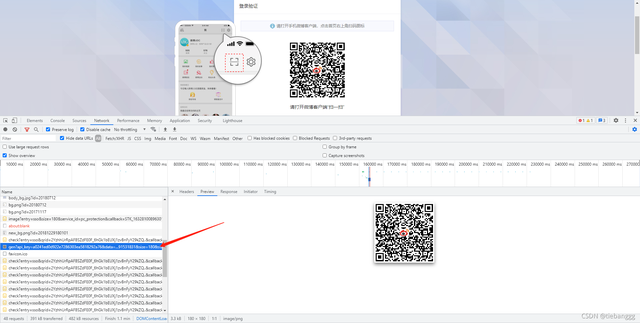
那我們是不是就可以請求這個介面來獲取二維碼,使用微博app掃碼進行登錄了呢
但是這個介面是需要很多引數的,必須找到這些引數的來源,才能獲取下來二維碼
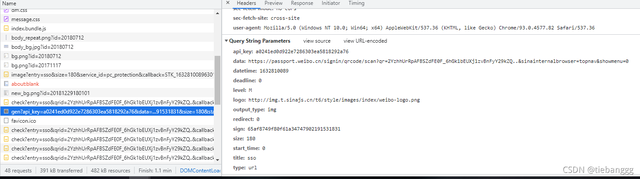
當然這些引數是肯定需要生成的,這個時候就可以繼續看一下其他的包
會看到這個里面有一個image的url,剛好是咱們需要的二維碼
還有一個qrid,這個時候我們是不知道這個引數是干嘛用的,咱們對它有個印象即可,沒準后面需要呢?
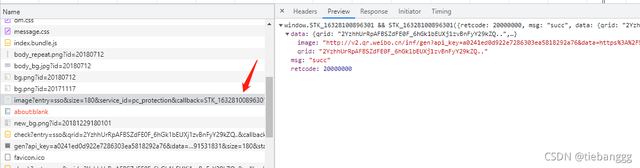
當然這個介面也是需要傳參的,只不過我反復試了幾次之后只有STK_后面的數字變了
網頁分析多了之后,一眼就知道是時間戳了,其他的沒有變化
到這里我們就可以開寫寫咱們的代碼了,當然各位可以直接提取image里面的url,
我這里是通過拼接方式來獲取的url,當然全域是需要是要使用session()保持會話的,
在開頭寫下s = requests.session()
部分代碼如下:
def image(self):
'''獲取二維碼,進行掃碼驗證登錄'''
params = {
'entry': 'sso',
'size': '180',
'service_id': 'pc_protection',
'callback': 'STK_'+str(time.time()*10000)
}
res = s.get(self.image_url,headers = self.headers,params = params)
api_key = re.search('.*?api_key=(.*)"', res.text).group(1)
qrid = re.search('.*?"qrid":"(.*)?",', res.text).group(1)
# qrid 是獲取掃描二維碼狀態url的重要引數
self.qrid = qrid
print(res.text, '\n', api_key, '\n', qrid)
這里我把url以及qrid都獲取下來了,運行結果:

下一步,就可以使用這個url來獲取二維碼圖片保存,上下兩段代碼在同一個函式里面
并且掃碼進行登錄了
代碼如下:
#拼接二維碼圖片url
img = 'https://v2.qr.weibo.cn/inf/gen?api_key='
img_url = img + str(api_key)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
cha_page = s.get(img_url,headers = headers)
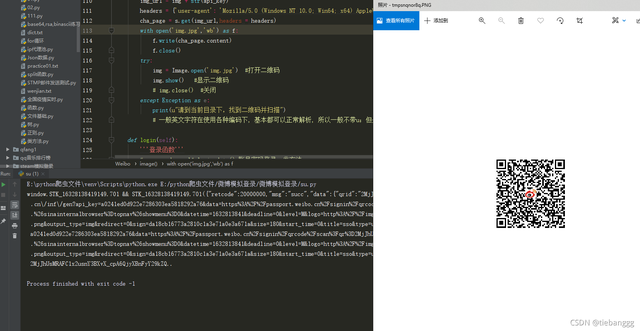
with open('img.jpg','wb') as f:
f.write(cha_page.content)
f.close()
try:
img = Image.open('img.jpg') #打開二維碼
img.show() #顯示二維碼
# img.close() #關閉
except Exception as e:
print(u"請到當前目錄下,找到二維碼并掃描")
# 一般英文字符在使用各種編碼下, 基本都可以正常決議, 所以一般不帶u;但是中文, 必須表明所需編碼, 否則一旦編碼轉換就會出現亂碼,
這個時候二維碼就被我們下載下來了
這個時候我們又要繼續分析這個二維碼的狀態了,繼續回到網頁來
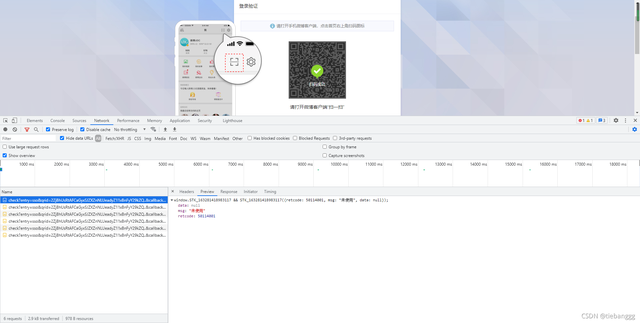
清空一下,會看到一直有資料在重繪,點擊看一下,
msg顯示"未使用"
retcode: 50114001
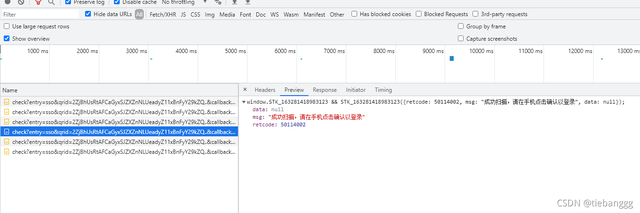
這個時候使用微博app,對二維碼進行掃碼,下面又重繪了,
msg顯示"成功掃描,請在手機點擊確認以登錄"
retcode: 50114002
這個時候我們就可以知道,這個網頁一直在重繪二維碼的狀態,是掃碼了還是未掃碼
或者二維碼失效的狀態了,我們來分析一下這個url里面包含有什么

哎,這里面有一個qrid 的引數,是不是就是上面我們取出來的qrid呢
entry引數是不變的
最后一個就是一個15位的時間戳
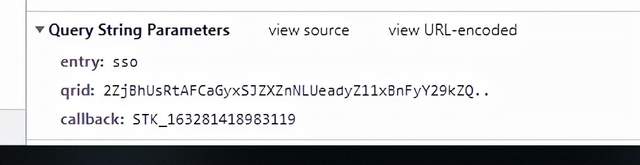
那么這些引數我們都可以拿到之后,是不是就可以判斷二維碼的狀態了
使用While回圈一直重繪判斷里面的retcode,回傳的資料是不規則的json資料
使用正則把里面的資料取出來,才會正常顯示字體
里面的數值分表代表:
50114001:二維碼未掃描狀態
50114002:二維碼已掃描未確認狀態
20000000:二維碼已確認狀態
50114004:二維碼已失效
附上判斷代碼:
url = 'https://login.sina.com.cn/sso/qrcode/check?entry=sso&qrid={}&callback=STK_{}'
while 1:
'''掃描二維碼登錄,每隔1秒請求一次掃碼狀態'''
response = s.get(url.format(self.qrid,str(time.time()*100000)),headers = self.headers)
print(response.text)
data = https://www.cnblogs.com/pythonQqun200160592/archive/2021/09/29/re.search('.*?\((.*)\)',response.text).group(1)
data_js = json.loads(data)
'''
50114001:二維碼未掃描狀態
50114002:二維碼已掃描未確認狀態
20000000:二維碼已確認狀態
50114004:二維碼已失效
'''
print(data_js)
if '50114001' in str(data_js['retcode']):
print('二維碼未使用,請掃碼!')
elif '50114002' in str(data_js['retcode']):
print('已掃碼,請點擊確認登錄!')
elif '50114004' in str(data_js['retcode']):
print('該二維碼已失效,請重新運行程式!')
elif '20000000' in str(data_js['retcode']):
print('登錄成功!')
alt = data_js['data']['alt']
# print(alt)
break
else:
print('其他情況',str(data_js['retcode']))
time.sleep(1)
運行結果:
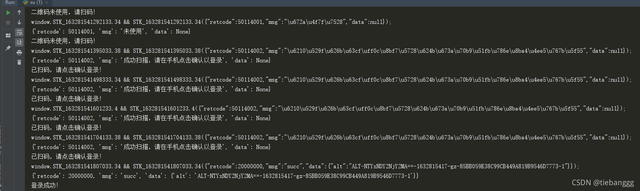
可以清楚的看到,我們在沒有使用微博app掃碼,以及掃碼成功,以及點擊確認登錄的狀態了
但是登錄成功的時候會發現回傳的資料里面多了一個 alt 的東西
這個又是干嘛的呢,我們現在也不知道,可以先記一下,順便取出來
這個時候又要去抓包了,看一下掃碼登錄之后,會出現些什么
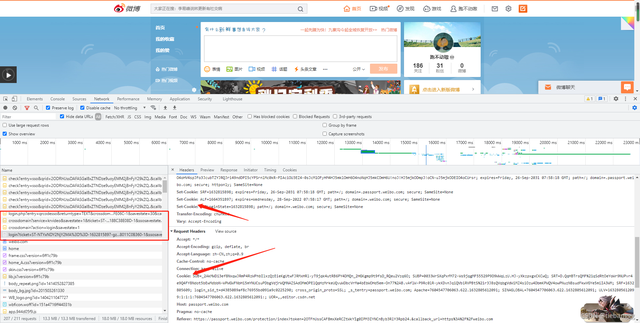
這個時候我們就登錄上來了,可以看到有四個url里面都或多或少的包含有
set-cookies 或者是cookie
接下來就是依次訪問這些url可以得到cookie了,不過這四個url怎么來的呢
我們接著來分析,先看第一個,可以發現url里面有這個alt的引數
上面我們提前取出來了,以及其他的引數,都是固定的,最后一個STK_跟15位的時間戳

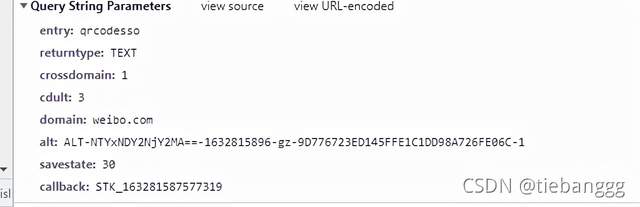
那我們這個時候就可以構造這個url,先請求一下,看看回傳了什么資料
部分代碼如下:
alturl = 'https://login.sina.com.cn/sso/login.php?entry=qrcodesso&returntype=TEXT&crossdomain=1&cdult=3&domain=weibo.com&alt={}&savestate=30&callback=STK_{}'
response = s.get(alturl.format(alt,str(time.time()*100000)),headers = self.headers)
print(response.text)
data = https://www.cnblogs.com/pythonQqun200160592/archive/2021/09/29/re.search('.*\((.*)\);',response.text).group(1)
print(data)
data_js = json.loads(data)
print(data_js)
登錄之后是可以看見咱的用戶名以及uid的,運行結果如下:

第一次輸出人眼是看不懂的,這就是不規則json顯示的,第二次通過正則取出 {} 里面的資料時候就會清楚的顯示了,那這個時候就會發現有3個url了
和前面擁有cookie和set-cookies的url是一樣的
那這樣就方便明了了,咱們直接分別請求這三個URL之后就可以獲取到cookie了
值得注意的是,第二個url后面需要加上 ‘&action=login’ 才正確
接下來就是使用s.cookies.save()來保存cookie了
也可以使用pickle,不過這個我用不來
import http.cookiejar as cookielib
# import pickle
先創建一個cookies.txt來作為存盤,寫入的是字串
代碼如下:
def get_cookies(self):
'''獲取cookies,創建一個txt檔案保存'''
alt = self.login()
if not os.path.exists('cookies.txt'):
with open("cookies.txt", 'w') as f:
f.write("")
s.cookies = cookielib.LWPCookieJar(filename='cookies.txt')
alturl = 'https://login.sina.com.cn/sso/login.php?entry=qrcodesso&returntype=TEXT&crossdomain=1&cdult=3&domain=weibo.com&alt={}&savestate=30&callback=STK_{}'
response = s.get(alturl.format(alt,str(time.time()*100000)),headers = self.headers)
print(response.text)
data = https://www.cnblogs.com/pythonQqun200160592/archive/2021/09/29/re.search('.*\((.*)\);',response.text).group(1)
print(data)
data_js = json.loads(data)
print(data_js)
uid = data_js['uid']
nick = data_js['nick']
print('賬戶名:'+nick,'\n','uid:'+uid)
crossDomainUrlList = data_js['crossDomainUrlList']
print(crossDomainUrlList)
#依次訪問另外三個url
s.get(crossDomainUrlList[0],headers = self.headers)
s.get(crossDomainUrlList[1] + '&action=login', headers=self.headers)
s.get(crossDomainUrlList[2], headers=self.headers)
s.cookies.save()
這里我們就可以獲取cookie下來了
那我們使用的時候可以把字串改成字典,用parmas拼接url
轉成字典代碼如下;
def cookie_dict(self):
'''加載cookies'''
self.get_cookies()
cookies = cookielib.LWPCookieJar('cookies.txt')
cookies.load(ignore_discard=True, ignore_expires=True)
# 將cookie轉成字典
cookie_dict = requests.utils.dict_from_cookiejar(cookies)
print('cookies字典:', cookie_dict)
return cookie_dict
運行如下:

到此咱們的整個分析程序結束了,或許還有一些小細節沒有說清楚,這個呢需要大家練習的時候慢慢去發現,另外cookiejar的具體用法,大家可以自行百度
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/304169.html
標籤:其他