文章目錄:
1.看看關于LinkedList原始碼開頭的注釋
2.LinkedList中的屬性
3.LinkedList中的方法
3.1 push、offer方法
3.2 添加元素的一系列add方法
3.3 linkFirst方法
3.4 linkLast方法
3.5 linkBefore方法
3.6 移除元素的一系列remove方法
3.7 unlinkFirst方法
3.8 unlinkLast方法
3.9 unlink方法
3.10 獲取元素的get、getFirst、getLast方法
3.11 size方法
3.12 push、peek、peekFirst、peekLast方法
3.13 pop、poll、pollFirst、pollLast方法
3.14 set方法
3.15 contains方法
3.16 clear方法
1.看看關于LinkedList原始碼開頭的注釋
* Doubly-linked list implementation of the {@code List} and {@code Deque} * interfaces. Implements all optional list operations, and permits all * elements (including {@code null}). * * <p>All of the operations perform as could be expected for a doubly-linked * list. Operations that index into the list will traverse the list from * the beginning or the end, whichever is closer to the specified index. * * <p><strong>Note that this implementation is not synchronized.</strong> * If multiple threads access a linked list concurrently, and at least * one of the threads modifies the list structurally, it <i>must</i> be * synchronized externally. (A structural modification is any operation * that adds or deletes one or more elements; merely setting the value of * an element is not a structural modification.) This is typically * accomplished by synchronizing on some object that naturally * encapsulates the list.從這段注釋中,我們可以得知 LinkedList 是通過一個雙向鏈表來實作的,它允許插入所有元素,包括 null,同時,它是執行緒不同步的,
- LinkedList集合底層結構是帶頭尾指標的雙向鏈表,
- LinkedList是非執行緒安全的,
- LinkedList集合中存盤元素的特點:有序可重復,元素帶有下標,從0開始,以1遞增,
- LinkedList集合的優點:在指定位置插入/洗掉元素的效率較高;缺點:查找元素的效率不如ArrayList,
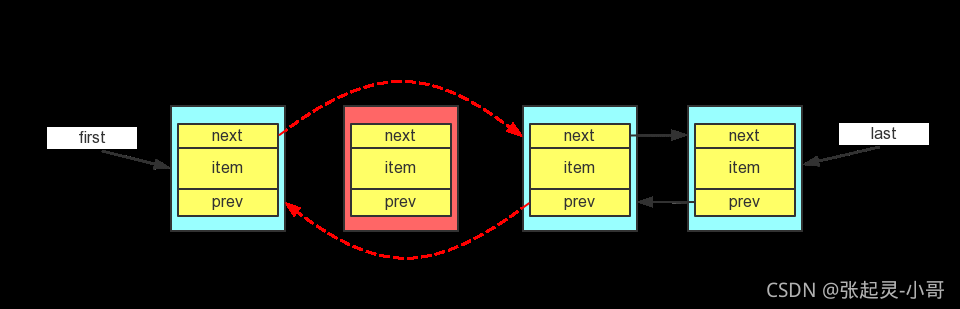
如果對雙向鏈表這個 資料結構很熟悉的話,學習 LinkedList 就沒什么難度了,下面是雙向鏈表的結構:
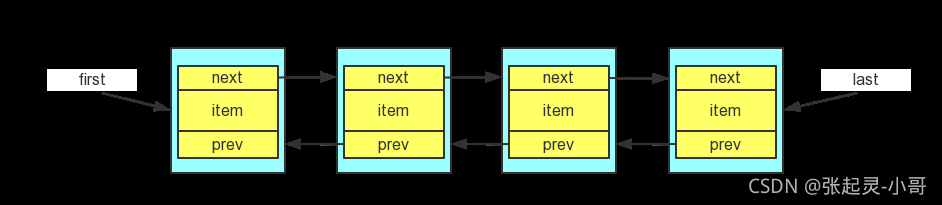
雙向鏈表每個結點除了資料域之外,還有一個前指標和后指標,分別指向前驅結點和后繼結點(如果有前驅/后繼的話),另外,雙向鏈表還有一個 first 指標,指向頭節點;和 last 指標,指向尾節點,
2.LinkedList中的屬性
//雙向鏈表中結點個數
transient int size = 0;
//指向頭結點的指標
transient Node<E> first;
//指向尾結點的指標
transient Node<E> last;關于LinkedList中的Node節點結構,它其實是在 LinkedList 里定義的一個靜態內部類,它表示鏈表每個節點的結構,包括一個資料域 item,一個后置指標 next,一個前置指標 prev,
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}3.LinkedList中的方法
3.1 push、offer方法
push、offer方法內部都是呼叫的相應的add方法,所以直接看下面的add方法原始碼決議,
public void push(E e) {
addFirst(e);
}
public boolean offer(E e) {
return add(e);
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public boolean offerLast(E e) {
addLast(e);
return true;
}3.2 添加元素的一系列add方法
在LinkedList集合原始碼中,添加元素很多時候都會用到 add、addFirst、addLast 這幾個,而查看原始碼發現,這幾個方法的內部實際上都呼叫了 linkFirst、linkLast 、linkBefore 這三個方法,
public boolean add(E e) {
linkLast(e);
return true;
}
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}所以下面著重來說一下 linkFirst、linkLast 、linkBefore 這三個方法,
3.3 linkFirst方法
對于鏈表這種資料結構來說,添加元素的操作無非就是在表頭/表尾插入元素,又或者是在指定位置插入元素,因為 LinkedList 有頭指標和尾指標,所以在表頭或表尾進行插入元素只需要 O(1) 的時間,而在指定位置插入元素則需要先遍歷一下鏈表,所以復雜度為 O(n),
而linkFirst表面上翻譯就是 鏈表首位,也就是在表頭添加元素,其原始碼及添加元素分析程序如下:
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
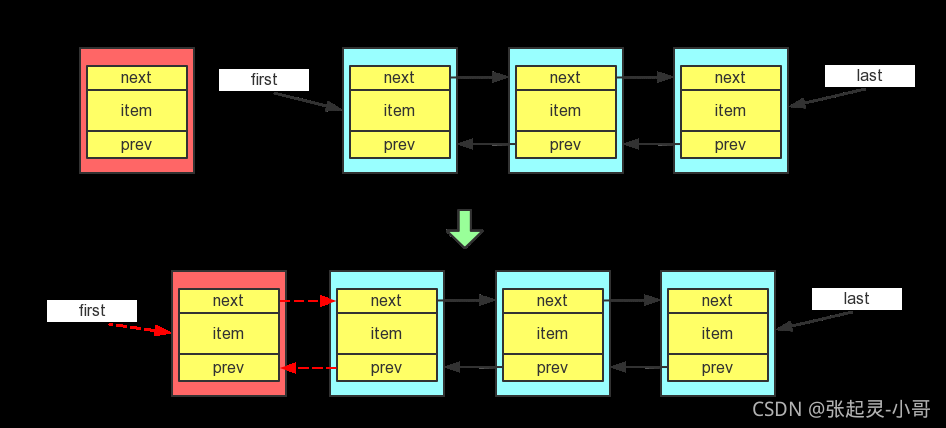
}當我們向雙向鏈表的表頭插入一個結點 e 時,這個結點的前驅指標肯定是 null,那么在插入之后,這個 e 結點的后繼指標是什么呢?(在e插入之前,原先的表頭結點就是表頭結點,在e插入到原表頭的前面成為了新的表頭之后,此時原表頭結點不就是當前e結點的后繼結點了嗎?所以e結點的后繼指標自然也就指向了原表頭結點,所以這里e的后繼指標就是最初鏈表的頭指標first),所以要在插入之前先獲取到頭指標 f = first,然后將頭指標對應的結點修改為新插入的結點e(newNode),對應原始碼的前三行,
而這個if判斷的是:如果在插入之前鏈表的頭指標為空(換句話說,當前鏈表中沒有元素,e結點插入之后只有這一個元素),那么此時e結點肯定既是頭結點、也是尾結點啊,所以這里將 last 尾結點修改為剛剛插入的 e 結點,
下面的else是說:當前鏈表中有多個元素了話,當你在某個結點x之前新插入一個結點e,那么結點x的后繼部分肯定沒有變化,變化的是它的前驅部分,前驅指標所指內容就變成了 新插入的結點e,即 f.prev = newNode,
3.4 linkLast方法
這個方法和 linkFirst 差不多的,無非是一個在表頭插入元素,一個在表尾插入元素,
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
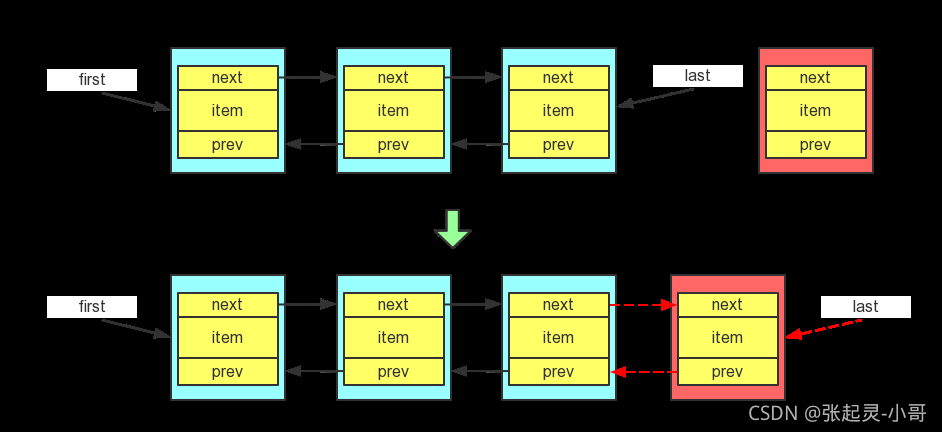
}首先插入之前,先獲取一下原表尾結點的內容(l = last),然后插入新的結點e,這個結點e的后繼指標肯定是 null(因為此時它成了鏈表的表尾結點),而它的前驅指標指向的就應該是上一個表尾結點 l,所以新表尾結點e的內容就是(l,e,null),然后更新雙向鏈表的尾指標 last 為新插入的結點newNode,
下面的if判斷的是:如果在插入之前獲取的尾指標 l 為空(也就是說當前鏈表中沒有元素),那么新插入一個元素之后,這個元素肯定既是頭結點、也是尾結點,所以這里將它的頭指標也更新為 newNode,
else說的是:當插入之前鏈表中有多個元素,那么在表尾新插入一個元素之后,還要最終修改一下原表尾結點的后繼指標,讓它指向新的表尾結點,
3.5 linkBefore方法
上面兩個方法分別都是在表頭、表尾插入元素,那么現在該說一下在中間某個隨機位置插入元素的方法了,原始碼如下:
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
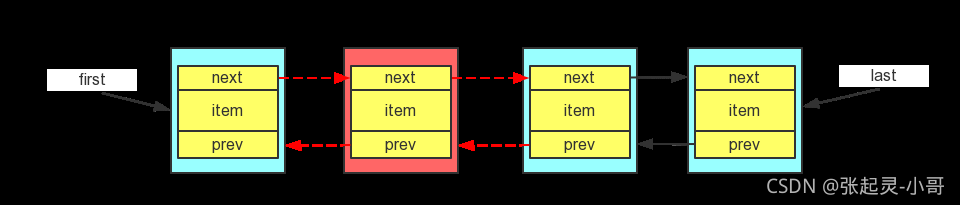
}對應原始碼來說,這里要插入的結點就是 e,e要插入到 succ 結點的前面,同時位于 pred 結點的后面,而在插入之前(succ的前驅就是pred),所以先獲取到這個前驅結點 pred,然后修改e結點的內容(pred,e,succ),那么此時 succ 的前驅就變成了 e,所以更新 succ 的前驅指標指向 newNode,
if判斷的是:如果插入之前succ結點的前驅指標pred為空,也就是說此時succ是表頭結點,那么e插入之后,它就成了新的表頭結點,所以這里讓first頭指標指向newNode,
else則是說插入之前鏈表中有多個元素,那么在succ指定結點的前面插入新的結點之后,還要修改succ原前驅節點pred的后繼指標,使其指向剛插入的e結點newNode,
3.6 移除元素的一系列remove方法
在LinkedList集合原始碼中,移除元素很多時候都會用到 remove、removeFirst、removeLast 這幾個,而查看原始碼發現,這幾個方法的內部實際上都呼叫了 unlinkFirst、unlinkLast 、unlink 這三個方法,unlink方法中的node方法是對鏈表進行遍歷的,
public E remove() {
return removeFirst();
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}所以下面著重來說一下 unlinkFirst、unlinkLast 、unlink 這三個方法,
3.7 unlinkFirst方法
洗掉操作與添加操作大同小異,需要把當前節點的前驅節點的后繼修改為當前節點的后繼,以及當前節點的后繼結點的前驅修改為當前節點的前驅,
unlinkFirst方法是在表頭進行元素的洗掉,首先做的是將要洗掉元素的item值保存到一個臨時變數element中,最侄訓傳,同時將要洗掉元素的后繼指標保存到next臨時指標中,然后將元素洗掉(即 f.item=null,f.next=null,因為洗掉元素位于表頭,所以 f.prev 本身就是 null),洗掉之后鏈表中的第二個元素就成為了新的表頭,所以修改 first 頭指標使其指向之前保存的 next 臨時指標(頭指標指向后一個結點),
if判斷的是:如果next為空,意思是說所洗掉元素的后繼指標如果為空(又因為該方法是在表頭進行元素洗掉),所以此時鏈表中僅存的這個結點被洗掉了,那么整個鏈表就清空了,所以尾指標 last 就為空了,
else說的是:洗掉之前鏈表中存在多個元素,那么當頭結點被洗掉之后,原先頭結點之后的那個結點就成了新的頭結點,所以這個新的頭結點的頭指標肯定是null,所以 next.prev=null,
最侄訓傳的是被洗掉元素的item值,
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}3.8 unlinkLast方法
這個方法和上面的差不多,上面的是在表頭進行元素的洗掉,這個是在表尾進行元素的洗掉,
同樣是先保存這個表尾結點的 item 值、prev前驅指標(因為后繼指標本身為 null 無需保存),之后將 item、prev 置為 null,當前表尾結點被洗掉之后,它前面的那個結點就成了新的表尾結點,所以需要將鏈表的 last 尾指標指向原表尾結點的前驅結點(last=prev),
if判斷的是:如果要洗掉的表尾結點的前驅為null,則說明此時鏈表中只有這一個結點,洗掉之后,鏈表清空,所以將鏈表的頭指標修改為 null,
else說的是:洗掉之前鏈表中有多個元素,將當前表尾結點洗掉之后,那么它前面的那個結點成了新的表尾結點,所以這個新的表尾結點的后繼指標肯定為 null,即 prev.next=null,
最侄訓傳的是被洗掉元素的item值,
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}3.9 unlink方法
上面兩個方法分別是在表頭、表尾洗掉,這個方法則是在鏈表中的任何一個位置進行元素的洗掉,
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}首先還是先獲取要洗掉元素的item值、next后繼指標、prev前驅指標,保存到三個區域變數中,
第一個 if/else:如果前驅指標為null,那么意味著洗掉的是表頭結點,洗掉之后,新的表頭結點為原表頭結點的next后繼結點,所以將鏈表的頭指標修改指向原表頭結點的next后繼指標,如果前驅指標不為 null,意味著在鏈表中間某個位置進行洗掉操作,需要先修改一下被洗掉結點的前驅節點的后繼指標,使其指向被洗掉結點的后繼指標;之后避免指標沖突,將被洗掉結點的前驅指標置為null(切斷被洗掉結點的前驅指標這條線),
第二個 if/else:如果后繼指標為null,那么意味著洗掉的是表尾結點,洗掉之后,新的表尾結點為原表尾結點的prev前驅結點,所以將鏈表的尾指標修改指向原表尾結點的prev前驅指標,如果后繼指標不為 null,意味著在鏈表中間某個位置進行洗掉操作,第一個if/else已經切斷了被洗掉結點的前驅線路,這里還需要修改一下被洗掉結點的后繼節點的前驅指標,使其指向被洗掉結點的前驅指標;之后避免指標沖突,將被洗掉結點的后繼指標置為null(切斷被洗掉結點的后繼指標這條線),最后將被洗掉結點的item值也置為null,
最侄訓傳的是被洗掉元素的item值,
3.10 獲取元素的get、getFirst、getLast方法
在LinkedList集合原始碼中,獲取元素很多時候都會用到 get、getFirst、getLast 這幾個,
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}getFirst方法:獲取雙向鏈表中的第一個元素,首先就是拿到當前鏈表的頭指標所指向的頭結點,如果為空,則拋出沒有這個元素例外;不為空直接就回傳表頭結點的item值,
getLast方法:獲取雙向鏈表中的最后一個元素,首先就是拿到當前鏈表的尾指標所指向的尾結點,如果為空,則拋出沒有這個元素例外;不為空直接就回傳表尾結點的item值,
而在get方法的原始碼中,第一行所做的是進行集合下標是否越界的判斷,這里不再多說了,主要是它第二行呼叫了一個node方法,原始碼如下:👇👇👇
因為get方法是隨機的獲取鏈表中的一個元素,下標為index,那么這個node方法就是幫助get方法完成了對鏈表的遍歷程序,如果獲取元素的索引下標小于鏈表長度/2,則從表頭開始遍歷,每遍歷一次就修改一下當前結點的后繼指標,直到遍歷到指定元素為止;反之則從表尾開始遍歷,每遍歷一次就修改一下當前結點的前驅指標,直到遍歷到指定元素為止,
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}3.11 size方法
回傳雙向鏈表的大小(元素個數),
public int size() {
return size;
}3.12 push、peek、peekFirst、peekLast方法
這三個方法就是獲取雙向鏈表中的第一個元素、最后一個元素,(這原始碼分析好理解,我就不再多說了)
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}3.13 pop、poll、pollFirst、pollLast方法
pop方法內部呼叫了removeFirst方法,而removeFirst方法內部呼叫了unlinkFirst方法,
這三個方法poll、pollFirst、pollLast就是移除雙向鏈表中的第一個元素、最后一個元素,它們的方法內部實際上就是呼叫了unlinkFirst、unlinkLast方法,上面已經說過了,
public E pop() {
return removeFirst();
}
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
3.14 set方法
這個方法非常簡單,就是替換指定索引下標位置的元素的item值,同時回傳它的舊值,
首先還是進行鏈表下標是否越界的判斷,然后呼叫node方法對鏈表進行遍歷(查找到要替換的那個元素結點),找到之后將該結點的item值保存一下,然后替換,最后回傳該結點的舊值,
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}3.15 contains方法
判斷集合中是否包含某個元素,如果包含在indexOf方法中回傳對應的索引下標,在contains方法中回傳相應的布林值,
public boolean contains(Object o) {
return indexOf(o) != -1;
}public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}3.16 clear方法
清空集合中的全部元素,從雙向鏈表的頭指標開始遍歷,每遍歷一次,首先獲取當前結點的后繼指標指向的結點,然后將當前結點的三要素(前驅、值、后繼)置為null,然后更新遍歷中心元素為下一個結點next,直至遍歷結束,最后鏈表清空,就將頭指標first、尾指標last修改為null,長度size清零,
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/304316.html
標籤:java
下一篇:真菜雞的保研之路(從未設想之路)