前言:
一個月前,博主在學過python(一年前)、會一點網路(能按F12)的情況下,憑著熱血和興趣,開始了python爬蟲的學習,一路過來走了相當多彎路,但是前不久終于成功了!!!(淚目)
經過一個月的學習,博主我感覺CSDN上圖片爬取教程確實詳細且方法繁多,但大都偏公式化或者不夠貼近小白,且本小白也親身經歷了整個從小白到爬蟲初入門的程序,因此就斗膽在CSDN上開一個欄目,以我的python圖片爬蟲全實作程序為例,以期用更簡單、清晰、詳盡的方式來幫助更多小白應對更大多數的爬蟲實際問題,
第一次寫blog真的十分激動!!!希望大家多多鼓勵點贊,過路大神多多指教,寫得不對的地方請直接指出!!!
本欄目大致會分為4章(有空馬上更)分別是:
- 環境配置+基礎知識
- 獲取圖片地址+根據地址下載圖片
- 翻頁+反爬+完整代碼
- 爬蟲實戰案例:爬取網站商品資訊
正文:
博主本人用的是window10系統、python3.8(需要add to path)和pycharm
所謂之所以要基于selenium庫爬蟲,是因為現在網頁大部分由JavaScript語言所寫,特點是動態加載網路元素,網路元素經過瀏覽器渲染才向用戶顯示(表現為在網頁右鍵查看原始碼和按F12調出開發者工具看到的網路元素不盡相同),用requests庫不能實作爬蟲,而selenium庫能模擬用戶使用瀏覽器,能很好地處理絕大多數的網路爬蟲,本文開始幾個篇章以圖片爬蟲為例,后面附一個爬取京東iPhone價格、商品名稱、評論、店鋪資訊的實體,
開始前,我想說看視頻是最最快的學習方法,個人是在B站學到了requests庫實戰和selenium庫實戰(兩個視頻都是我看過那么多最詳細最好的,鏈接【1】【2】我放在下面),期間在網路基礎和瀏覽器知識這一塊也參考了紫書《python網路爬蟲權威指南》,還有關于網路想要深入了解的同學可以看鏈接【3】,
新手警告:剛開始爬蟲建議用IDLE!!!
新手警告:剛開始爬蟲建議用IDLE!!!
新手警告:剛開始爬蟲建議用IDLE!!!
(selenium庫查找不到元素就會報錯容易把心態搞崩,建議一步步在IDLE上執行,最后適當加上time.sleep()復制到pycharm)
- 【1】Python爬蟲實戰教程:批量爬取某網站圖片_嗶哩嗶哩_bilibili
- 【2】Python爬蟲+反爬蟲實戰【資料爬取+資料決議+scrapy+selenium+反爬蟲】_嗶哩嗶哩_bilibili
- 【3】HTML 教程 | 菜鳥教程
一、環境
01瀏覽器環境
from selenium import webdriver
driver = webdriver.Chrome()#用谷歌瀏覽器
#driver = webdriver.Edge()#用Microsoft Edge
#driver = webdriver.PhantomJS()#用無頭瀏覽器- 用selenium庫爬蟲需要用到driver,也就是可供selenium庫使用的瀏覽器.exe,呼叫的時候如上
- 下載對應瀏覽器可在CSDN查找就可,附帶教程很詳細(搜索:‘“selenium庫webdriver+瀏覽器名稱”)
- 所謂無頭瀏覽器就是不顯示界面的瀏覽器,但可以通過截圖了解狀態
注意:
- 下載webdriver時需選擇和自己當前瀏覽器的版本一致
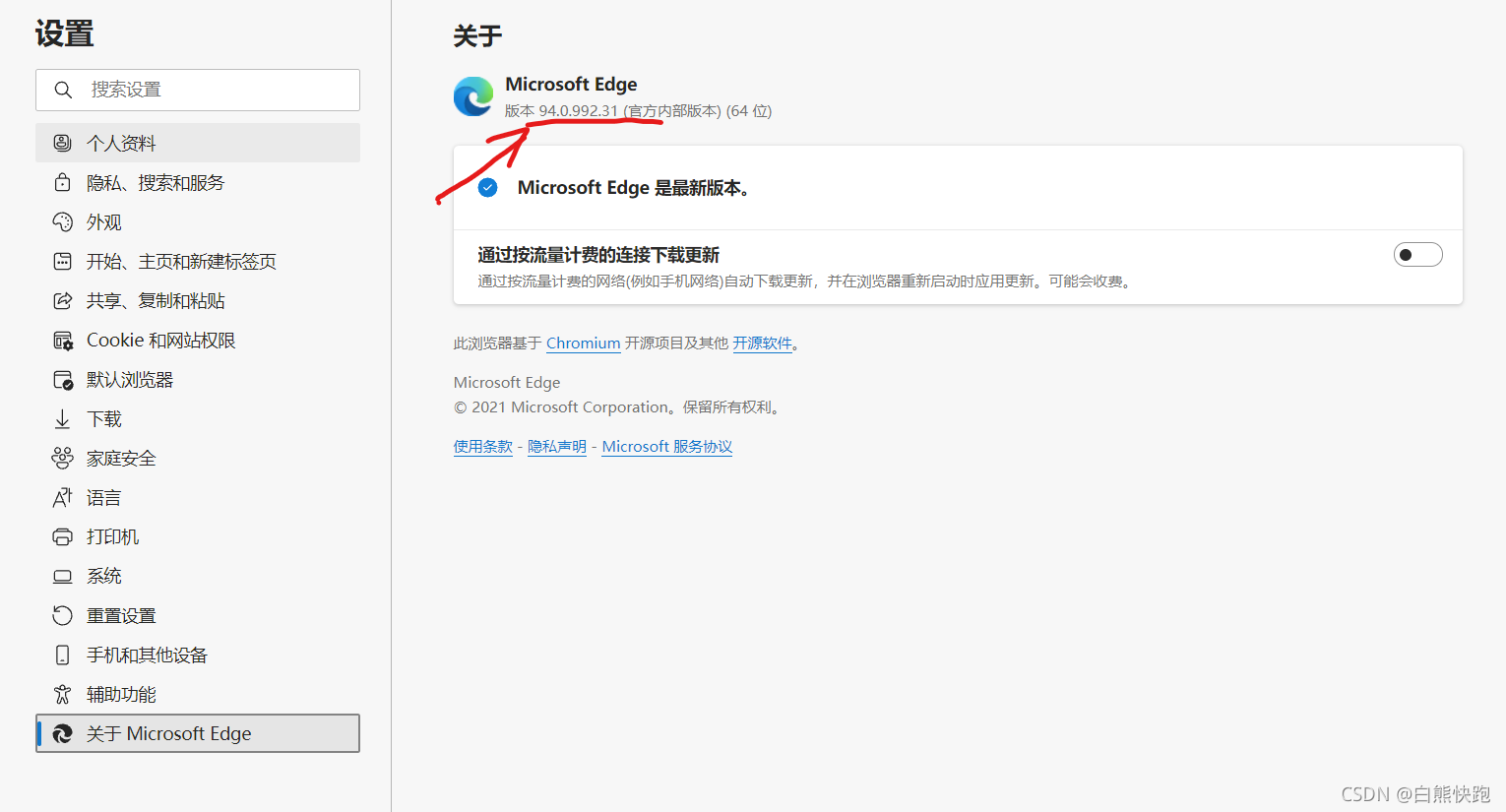
2. 下載后的瀏覽器.exe直接拖動到python所在地址,python所在地址可直接window鍵+R,再輸入cmd調出命令列視窗輸入“where python”就找到python路徑了,
然后就可正常使用webdriver了,
02下載外部庫
也是在命令列視窗,先輸入python看下python是否正常加到path
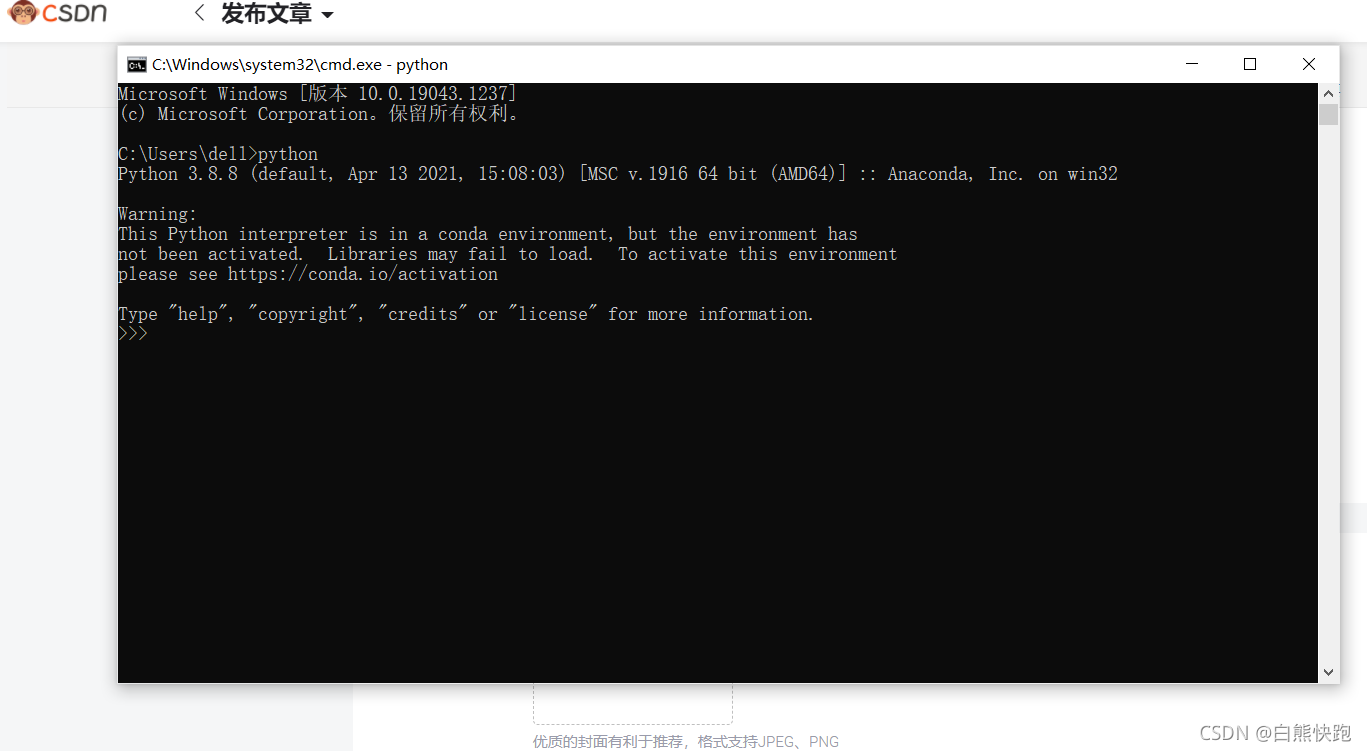
然后先輸入“quit()”退出python,再依次輸入“pip install selenium”,“pip install requests”,如出現“...install successfully”不報錯就是安裝成功(warning不用管)、
注意:如果報錯可以改成“pip3 install selenium”,“pip3 install requests”
二、基礎知識
這里比較重要的是字串操作和網頁知識(主要是一些快捷鍵)
01字串操作
主要用到的功能是截取、相加(也就是拼接),以及format函式(可用于字串拼接)和split函式(用于選取字串內容),需要用的時候去CSDN查看即可,在爬取圖片時一般用于修正圖片地址和創建圖片名稱
02陣列知識
主要用到選取元素和遍歷
03通過requests庫從圖片地址下載圖片
其實是一組模塊,和創建檔案模塊一起使用(后面的bloc會說的)
04網頁基礎知識
重點說說網頁基礎知識,爬蟲中很需要實時根據網頁內容改變爬取方法,
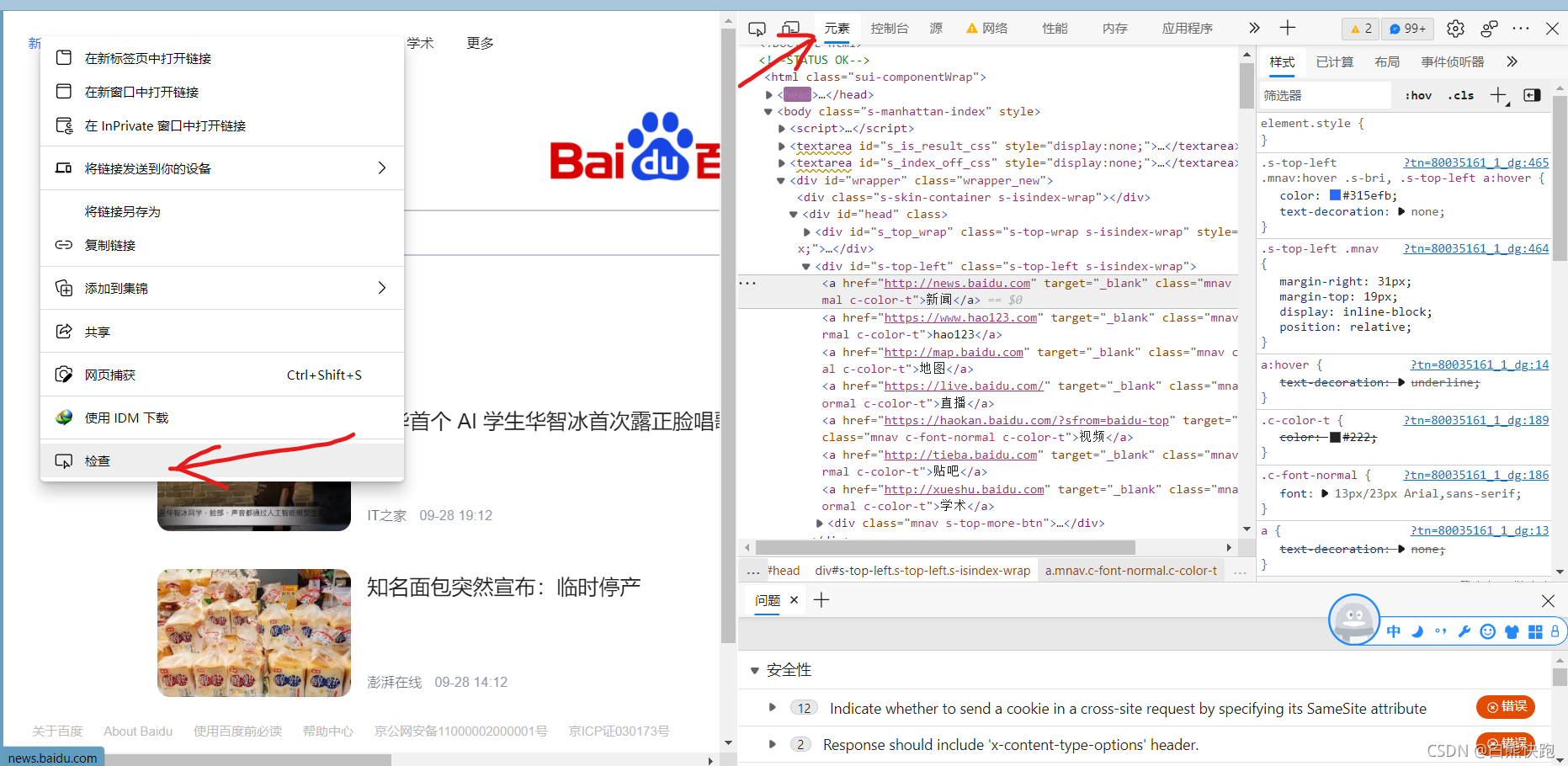
- 首先需要的是開發者工具,有的同學可以直接按F12調出,有的需要手動按一按,我們需要點擊右邊的“元素”,然后在頁面中選擇一個元素右鍵點擊“檢查”,就可以找到對應的代碼,
2.然后具體說說網頁元素
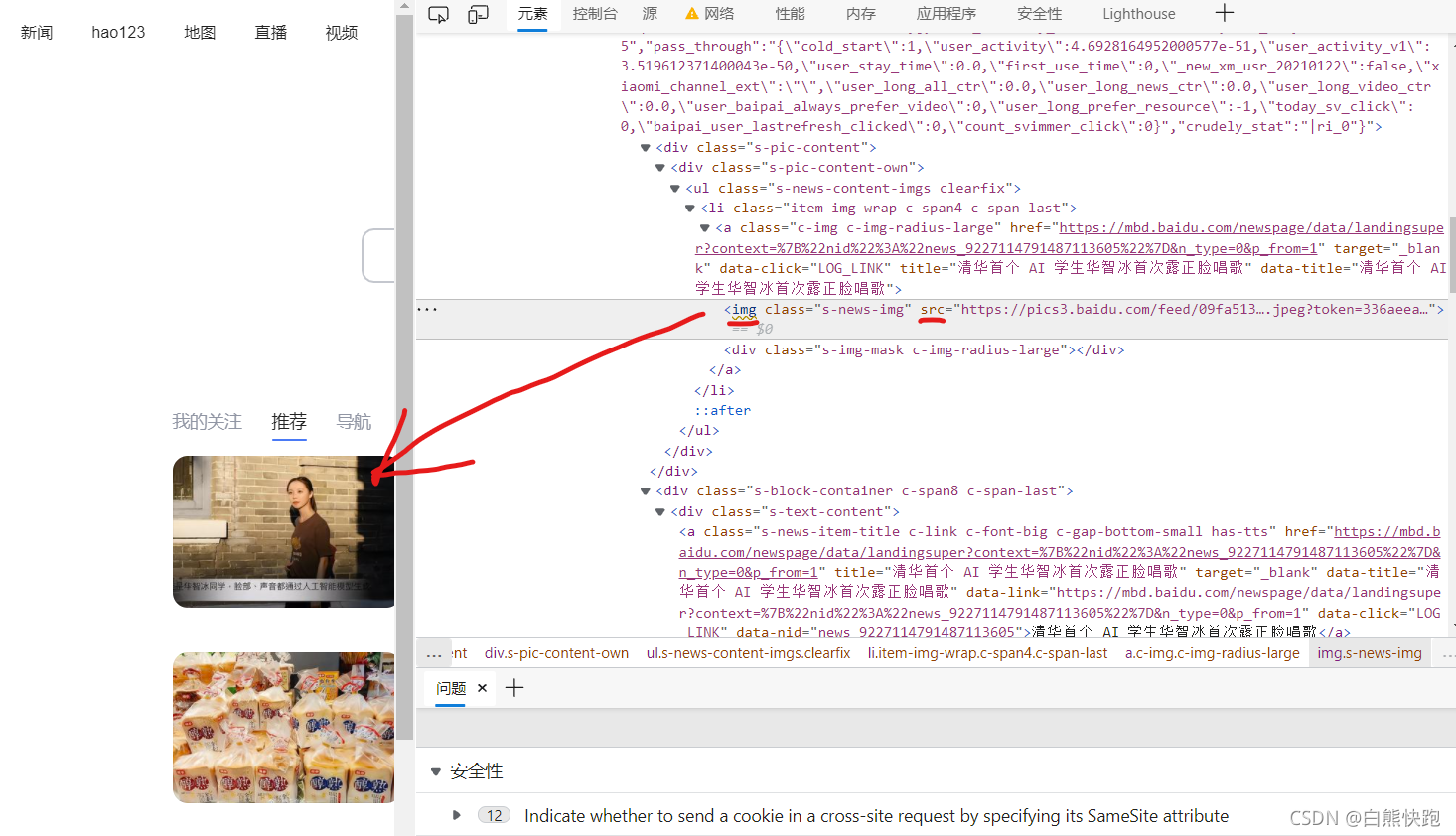
- 節點的名稱有的叫div,有的叫a,有的叫img,
- 我們所需的要素也有一個名稱,有的叫class,有的叫id,有的叫src,
- 這些節點里面的要素有一個值(比如class=“”里面的東西),網頁上所有的元素,都存放在這一個個值中,通過這些要素的值,我們可以尋找到特定的節點;也可以根據值的名稱,在節點里獲取這個值
- 我們所需的圖片地址,一般就是img節點的src要素的值(如下圖)
注意:
- 在開發者工具中可按Ctrl+F查找需要的網頁元素
- “元素”的左邊按鈕可把頁面從電腦模式切換成手機模式,再左邊按鈕按動后劃過網頁元素會自動跳到對應代碼
下一篇獲取圖片地址+根據地址下載圖片是重頭戲,喜歡的朋友請追更,
碼字不易求點贊!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/304331.html
標籤:python
上一篇:python字串的基本語法