文章目錄
- 情景再現
- 本文關鍵詞
- 挑個“軟柿子”
- 單頁爬取
- 資料處理
- 翻頁操作
- 擼代碼
- 主調度函式
- 頁面抓取函式
- 決議保存函式
- 可視化
- 顏色分布
- 評價詞云圖
- ??原始碼獲取方式??
情景再現
今日天氣尚好,女友忽然欲買文胸,但不知何色更美,遂命吾剖析何色買者益眾,為點議,事后而獎勵之,
本文關鍵詞
協程并發😊、IP被封😳、IP代理😏、代理被封😭、一種植物🌿
挑個“軟柿子”
打開京東,直接搜 【文胸】,挑個評論最多的
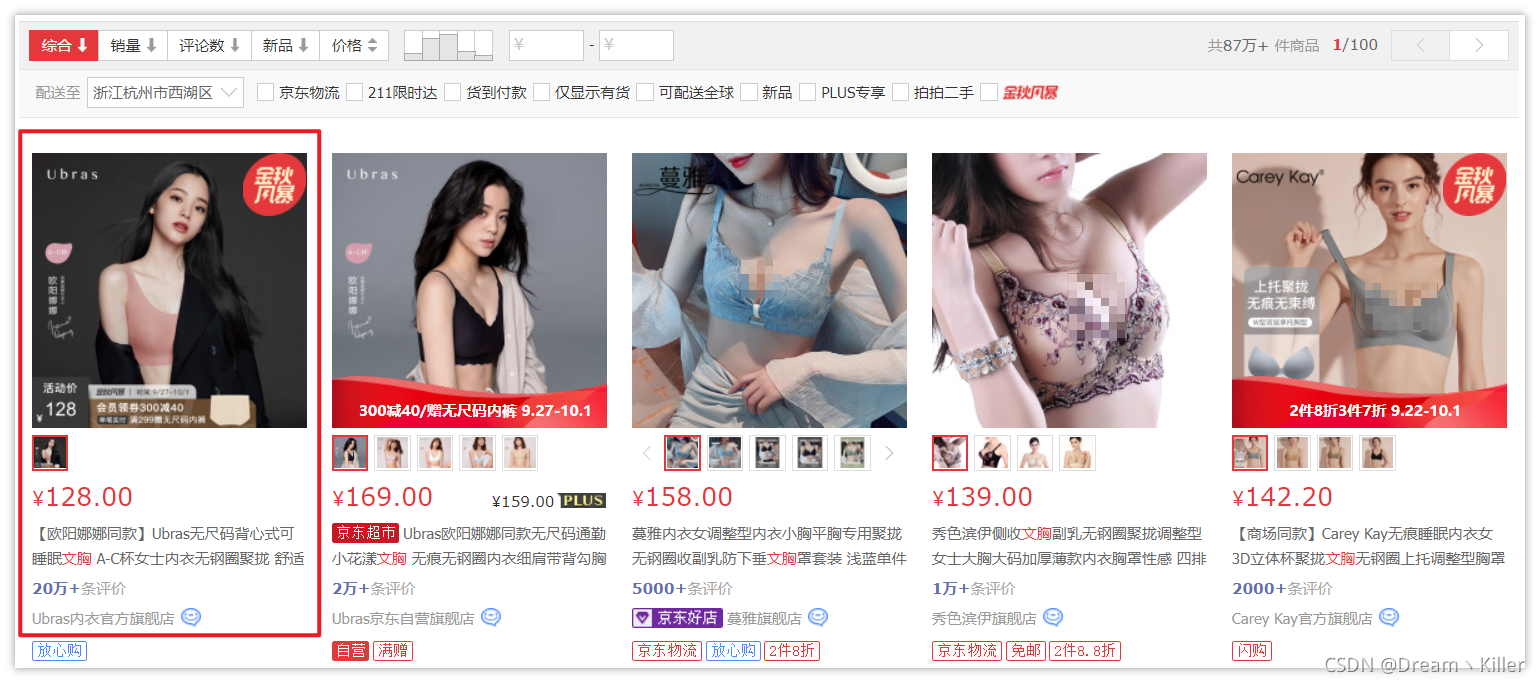
進入詳情頁,往下滑,可以看到商品介紹啥的,同時商品評價也在這里,
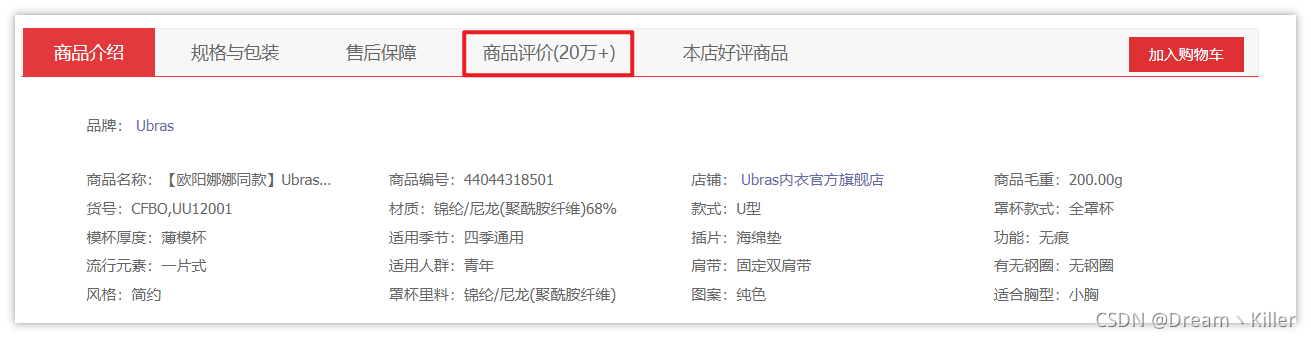
接下來重頭戲,F12 打開 開發者工具,選擇 Network,然后點擊全部評價,抓取資料包,
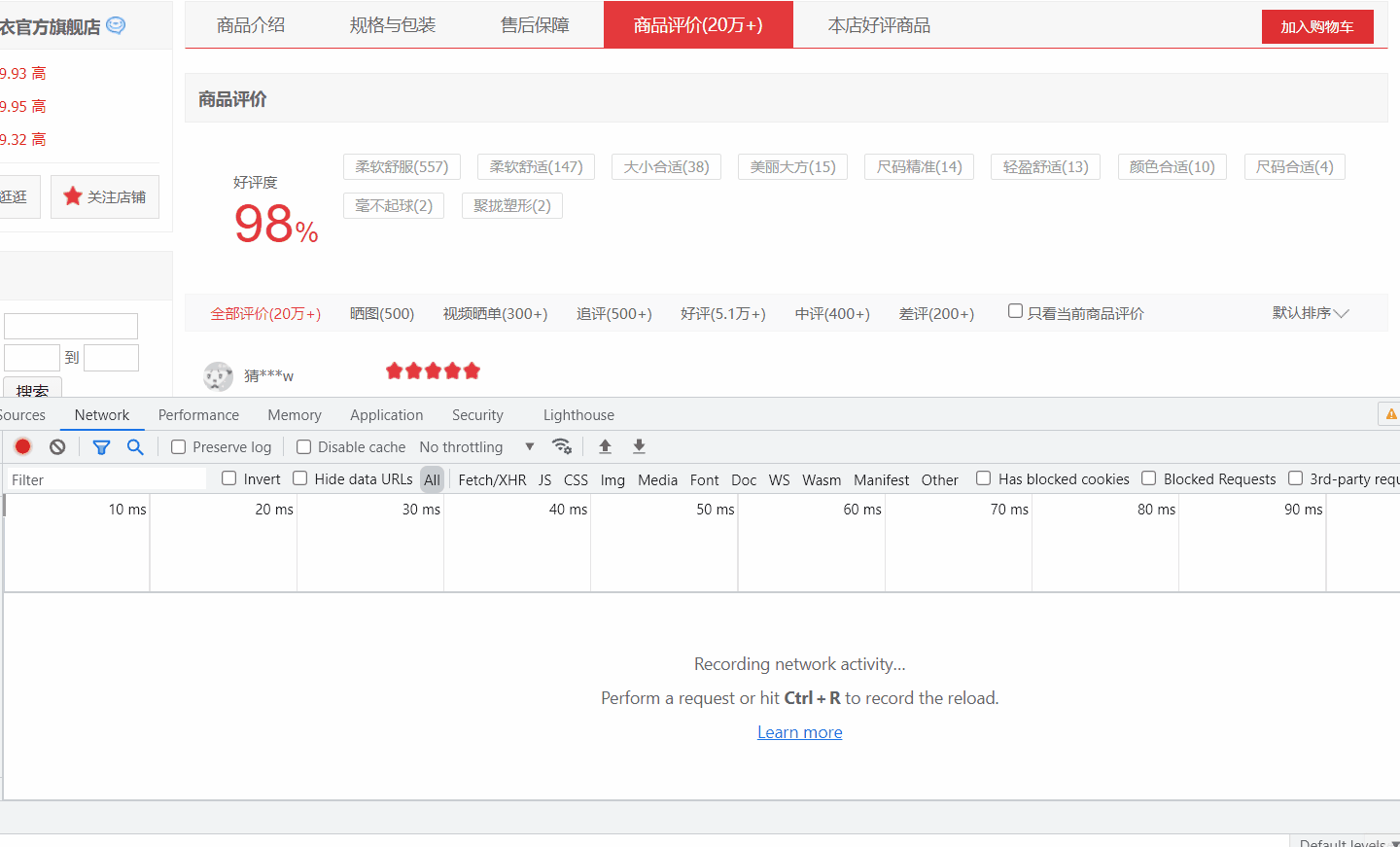
將 url 打開,發現確實是評論資料,
單頁爬取
那我們先寫個小 demo 來嘗試爬取這頁的代碼,看看有沒有什么問題,
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'callback':'fetchJSON_comment98',
'productId':'35152509650',
'score':'0',
'sortType':'6',
'page': '5',
'pageSize':'10',
'isShadowSku':'0',
'rid':'0',
'fold':'1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
page_text = requests.get(url=url, headers=headers, params=params).text
page_text
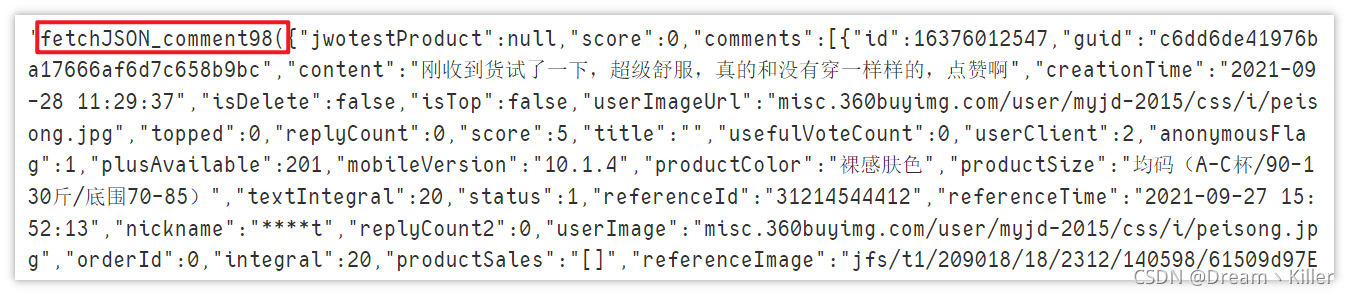
資料處理
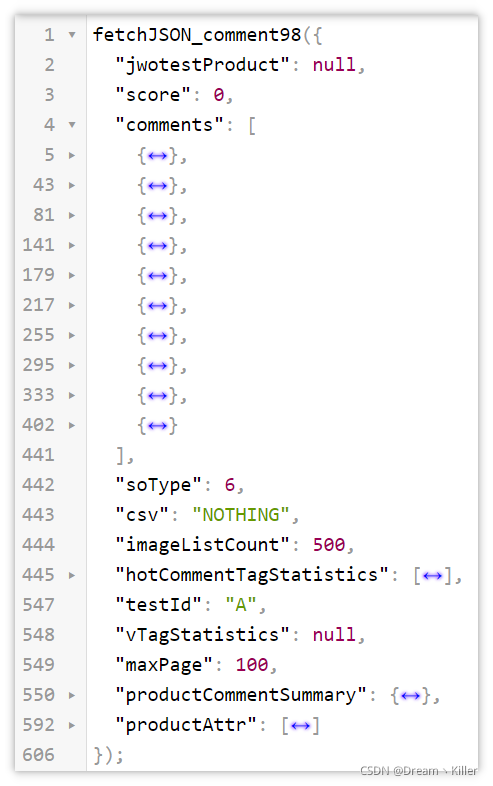
資料是獲取了,但前面多了一些沒用的字符(后面也有),很明顯不能直接轉成 json 格式,需要處理一下,
page_text = page_text[20: len(page_text) - 2]
data = json.loads(page_text)
data
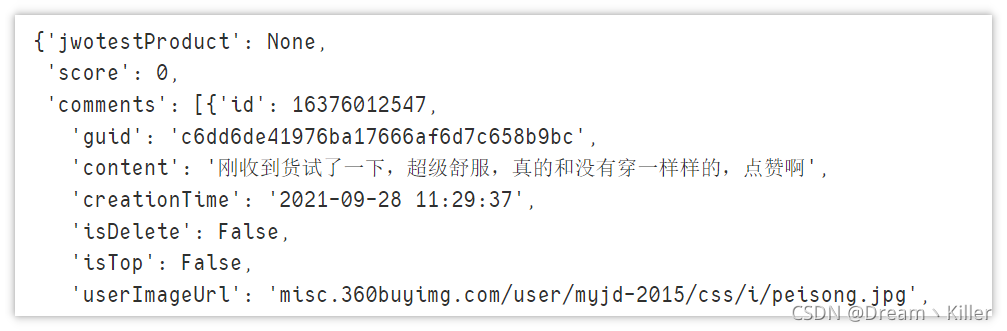
現在資料格式處理好了,可以上手決議資料,提取我們所需要的部分,這里我們只提取 id(評論id)、color(產品顏色)、comment(評價)、time(評價時間),
import pandas as pd
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
df
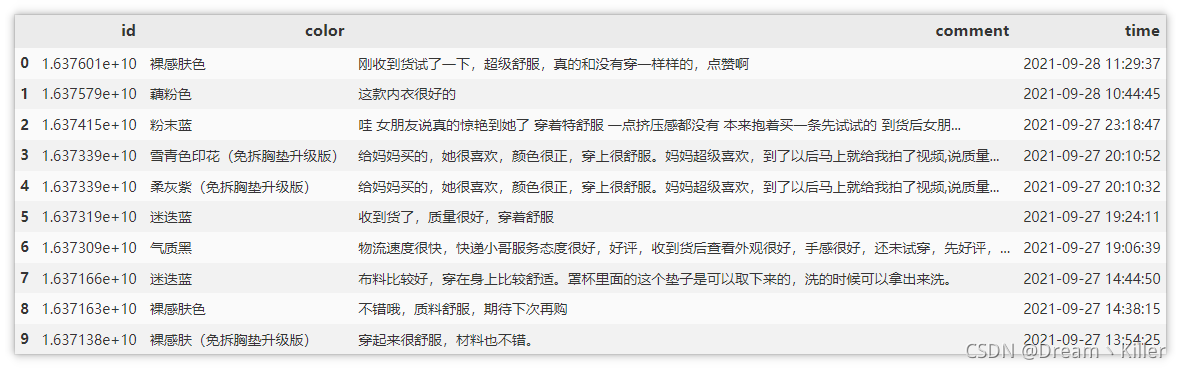
翻頁操作
那么接下來就要尋找翻頁的關鍵了,下面用同樣的方法獲取第二頁、第三頁的url,進行對比,
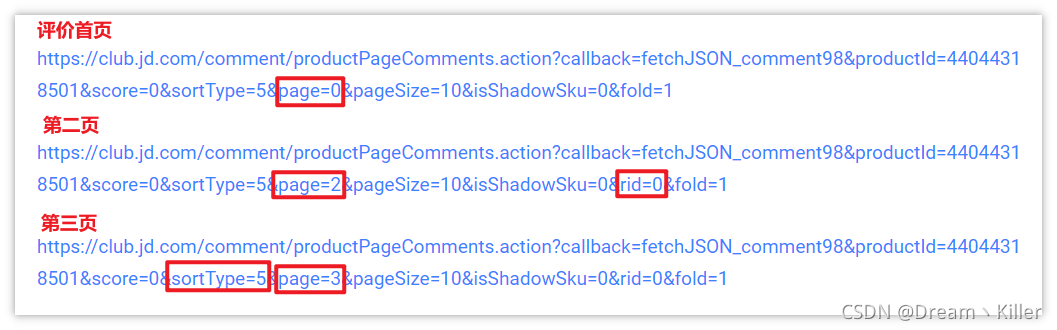
簡單分析一下,page 欄位是頁數,翻頁會用到,值得注意的是 sortType,字面意思是排序型別,猜測排序方式可能是:熱度、時間等,經過測驗發現 sortType=5 肯定不是按時間排序的,應該是熱度,我們要獲取按時間排序的,這樣后期比較好處理,然后試了幾個值,最后確定當 sortType=6 時是按評價時間排序,圖中最后還有個 rid=0 ,不清楚什么作用,我爬取兩個相同的url(一個加 rid 一個不加),測驗結果是相同的,所以不用管它,
擼代碼
先寫爬取結果:開始想爬 10000 條評價,結果請求過多IP涼了,從IP池整了丶代理,也沒頂住,拼死拼活整了1000條,時間不夠,如果時間和IP充足,隨便爬,經過測驗發現這個IP封鎖時間不會超過一天,第二天我跑了一下也有資料,下面看看主要的代碼,
主調度函式
設定爬取的 url 串列,windows 環境下記得限制并發量,不然報錯,將爬取的任務添加到 tasks 中,掛起任務,
async def main(loop):
# 獲取url串列
page_list = list(range(0, 1000))
# 限制并發量
semaphore = asyncio.Semaphore(500)
# 創建任務物件并添加到任務串列中
tasks = [loop.create_task(get_page_text(page, semaphore)) for page in page_list]
# 掛起任務串列
await asyncio.wait(tasks)
頁面抓取函式
抓取方法和上面講述的基本一致,只不過換成 aiohttp 進行請求,對于SSL證書的驗證也已設定,程式執行后直接進行決議保存,
async def get_page_text(page, semaphore):
async with semaphore:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'callback': 'fetchJSON_comment98',
'productId': '35152509650',
'score': '0',
'sortType': '6',
'page': f'{page}',
'pageSize': '10',
'isShadowSku': '0',
# 'rid': '0',
'fold': '1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, proxy='http://' + choice(proxy_list), headers=headers, params=params,
timeout=4) as response:
# 遇到IO請求掛起當前任務,等IO操作完成執行之后的代碼,當協程掛起時,事件回圈可以去執行其他任務,
page_text = await response.text()
# 未成功獲取資料時,更換ip繼續請求
if response.status != 200:
continue
print(f"第{page}頁爬取完成!")
break
except Exception as e:
print(e)
# 捕獲例外,繼續請求
continue
return parse_page_text(page_text)
決議保存函式
將 json 資料決議以追加的形式保存到 csv 中,
def parse_page_text(page_text):
page_text = page_text[20: len(page_text) - 2]
data = json.loads(page_text)
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
header = False if Path.exists(Path('評價資訊.csv')) else True
df.to_csv('評價資訊.csv', index=False, mode='a', header=header)
print('已保存')
可視化
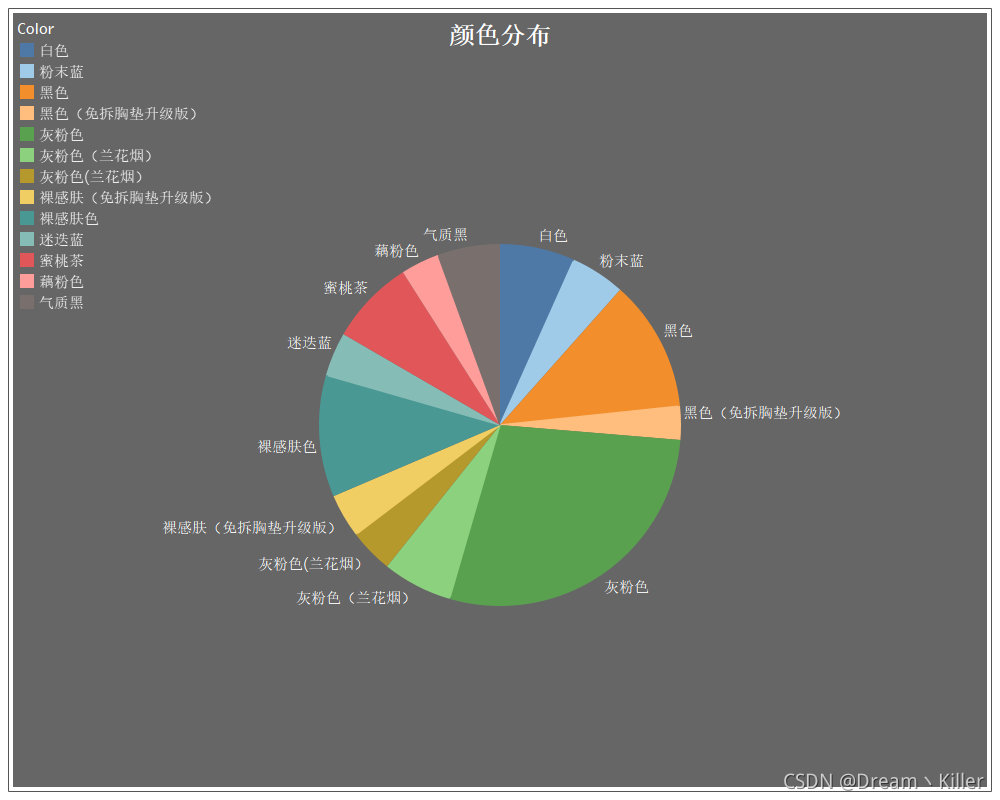
顏色分布
排名前三分別是灰粉色、黑色、裸感膚色,多的不說,自己體會哈,
評價詞云圖
可以看出評價的關鍵詞大多是對上身感覺的一些描述,穿著舒服當然是第一位的~

完結撒花,該向女朋友匯報作業了~
??往期精彩,不容錯過??
總結篇
??兩萬字,50個pandas高頻操作【圖文并茂,值得收藏】??
??吐血總結《Mysql從入門到入魔》,圖文并茂(建議收藏)??
工具篇
??Python實用小工具之制作酷炫二維碼(有界面、附原始碼)??
??Python實用工具之制作證件照(有界面、附原始碼)??
??女朋友桌面檔案雜亂無章?氣得我用Python給她做了一個檔案整理工具??
??原始碼獲取方式??
別忘記點贊哦~

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/304335.html
標籤:python