作者:Richard_Yi
來源:https://ricstudio.top/archives/es-lucene-reverted-index
"All problems in computer science can be solved by another level of indirection.”
– David J. Wheeler
“計算機世界就是 trade-off 的藝術”

一、前言
最近接觸的幾個專案都使用到了 Elasticsearch (以下簡稱 ES ) 來存盤資料和對資料進行搜索分析,就對 ES 進行了一些學習,本文整理自我自己的一次技術分享,
本文不會關注 ES 里面的分布式技術、相關 API 的使用,而是專注分享下 ”ES 如何快速檢索“ 這個主題上面,這個也是我在學習之前對 ES 最感興趣的部分,
本文大致包括以下內容:
- 關于搜索
-
- 傳統關系型資料庫和 ES 的差別
- 搜索引擎原理
- 細究倒排索引
- 倒排索引具體是個什么樣子的(posting list -> term dic -> term index)
- 關于 postings list 的一些巧技 (FOR、Roaring Bitmaps)
- 如何快速做聯合查詢?
二、關于搜索
先設想一個關于搜索的場景,假設我們要搜索一首詩句內容中帶“前”字的古詩,
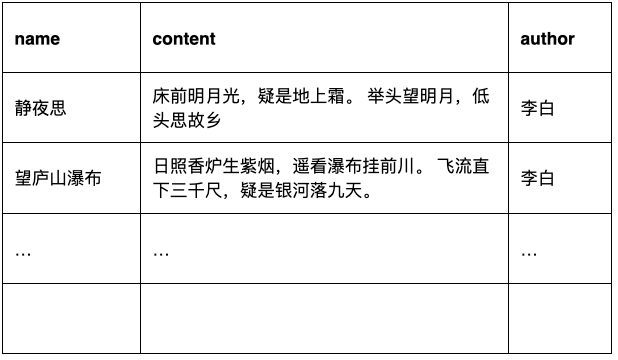
用 傳統關系型資料庫和 ES 實作會有什么差別?
如果用像 MySQL 這樣的 RDBMS 來存盤古詩的話,我們應該會去使用這樣的 SQL 去查詢
select name from poems where content like "%前%";
這種我們稱為順序掃描法,需要遍歷所有的記錄進行匹配,
不但效率低,而且不符合我們搜索時的期望,比如我們在搜索“ABCD"這樣的關鍵詞時,通常還希望看到"A","AB","CD",“ABC”的搜索結果,
于是乎就有了專業的搜索引擎,比如我們今天的主角 -- ES,另外,ES 系列面試題和答案全部整理好了,微信搜索?Java技術堆疊,在后臺發送:面試,?可以在線閱讀,
搜索引擎原理
搜索引擎的搜索原理簡單概括的話可以分為這么幾步,
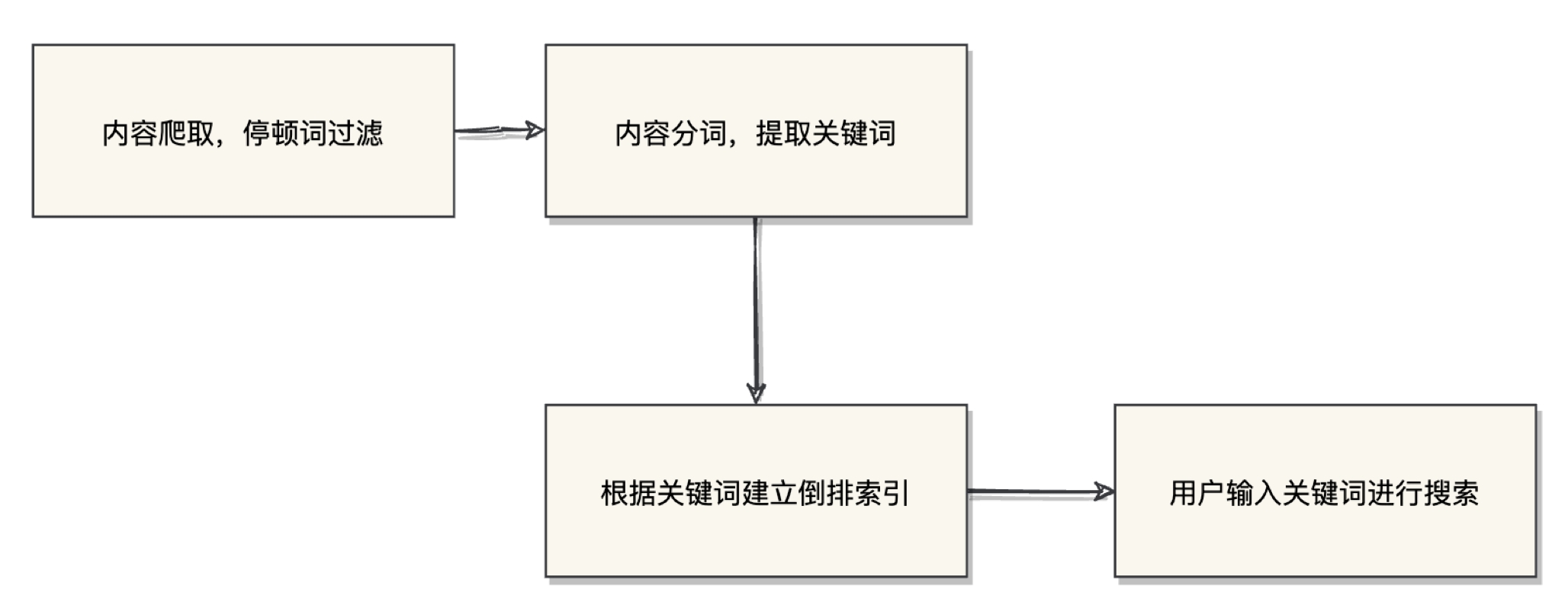
-
內容爬取,停頓詞過濾
比如一些無用的像"的",“了”之類的語氣詞/連接詞
-
內容分詞,提取關鍵詞
-
根據關鍵詞建立倒排索引
-
用戶輸入關鍵詞進行搜索
這里我們就引出了一個概念,也是我們今天的要剖析的重點 - 倒排索引,也是 ES 的核心知識點,
如果你了解 ES 應該知道,ES 可以說是對 Lucene 的一個封裝,里面關于倒排索引的實作就是通過 lucene 這個 jar 包提供的 API 實作的,所以下面講的關于倒排索引的內容實際上都是 lucene 里面的內容,
三、倒排索引
首先我們還不能忘了我們之前提的搜索需求,先看下建立倒排索引之后,我們上述的查詢需求會變成什么樣子,
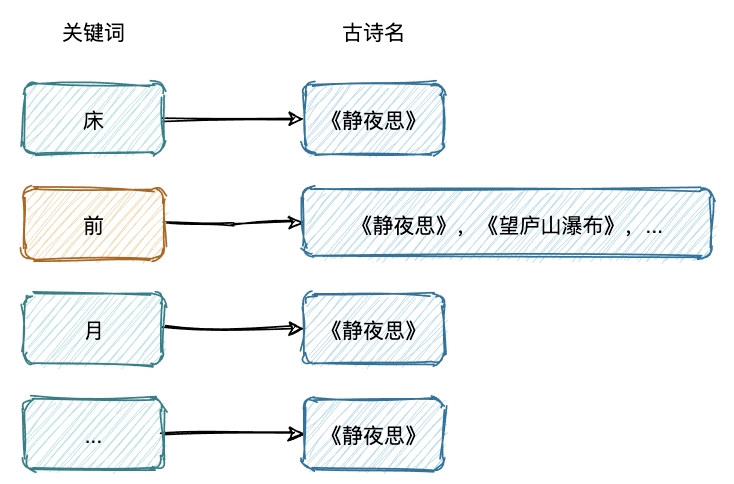
這樣我們一輸入“前”,借助倒排索引就可以直接定位到符合查詢條件的古詩,
當然這只是一個很大白話的形式來描述倒排索引的簡要作業原理,在 ES 中,這個倒排索引是具體是個什么樣的,怎么存盤的等等,這些才是倒排索引的精華內容,
1. 幾個概念
在進入下文之前,先描述幾個前置概念,
term
關鍵詞這個東西是我自己的講法,在 ES 中,關鍵詞被稱為 term,
postings list
還是用上面的例子,{靜夜思, 望廬山瀑布}是 "前" 這個 term 所對應串列,在 ES 中,這些被描述為所有包含特定 term 檔案的 id 的集合,由于整型數字 integer 可以被高效壓縮的特質,integer 是最適合放在 postings list 作為檔案的唯一標識的,ES 會對這些存入的檔案進行處理,轉化成一個唯一的整型 id,
再說下這個 id 的范圍,在存盤資料的時候,在每一個 shard 里面,ES 會將資料存入不同的 segment,這是一個比 shard 更小的分片單位,這些 segment 會定期合并,在每一個 segment 里面都會保存最多 2^31 個檔案,每個檔案被分配一個唯一的 id,從0到(2^31)-1,
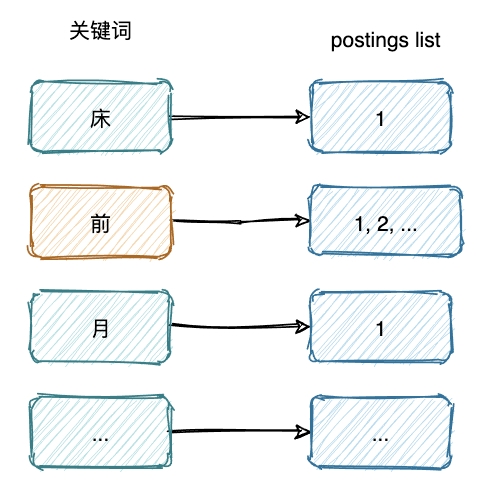
相關的名詞都是 ES 官方檔案給的描述,后面參考材料中都可以找到出處,
2. 索引內部結構
上面所描述的倒排索引,僅僅是一個很粗糙的模型,真的要在實際生產中使用,當然還差的很遠,
在實際生產場景中,比如 ES 最常用的日志分析,日志內容進行分詞之后,可以得到多少的 term?
那么如何快速的在海量 term 中查詢到對應的 term 呢?遍歷一遍顯然是不現實的,
term dictionary
于是乎就有了 term dictionary,ES 為了能快速查找到 term,將所有的 term 排了一個序,二分法查找,是不是感覺有點眼熟,這不就是 MySQL 的索引方式的,直接用 B+樹建立索引詞典指向被索引的資料,
term index
但是問題又來了,你覺得 Term Dictionary 應該放在哪里?肯定是放在記憶體里面吧?磁盤 io 那么慢,就像 MySQL 索引就是存在記憶體里面了,
但是如果把整個 term dictionary 放在記憶體里面會有什么后果呢?
記憶體爆了...
別忘了,ES 默認可是會對全部 text 欄位進行索引,必然會消耗巨大的記憶體,為此 ES 針對索引進行了深度的優化,在保證執行效率的同時,盡量縮減記憶體空間的占用,
于是乎就有了 term index,
Term index 從資料結構上分類算是一個“Trie 樹”,也就是我們常說的字典樹,這是一種專門處理字串匹配的資料結構,用來解決在一組字串集合中快速查找某個字串的問題,
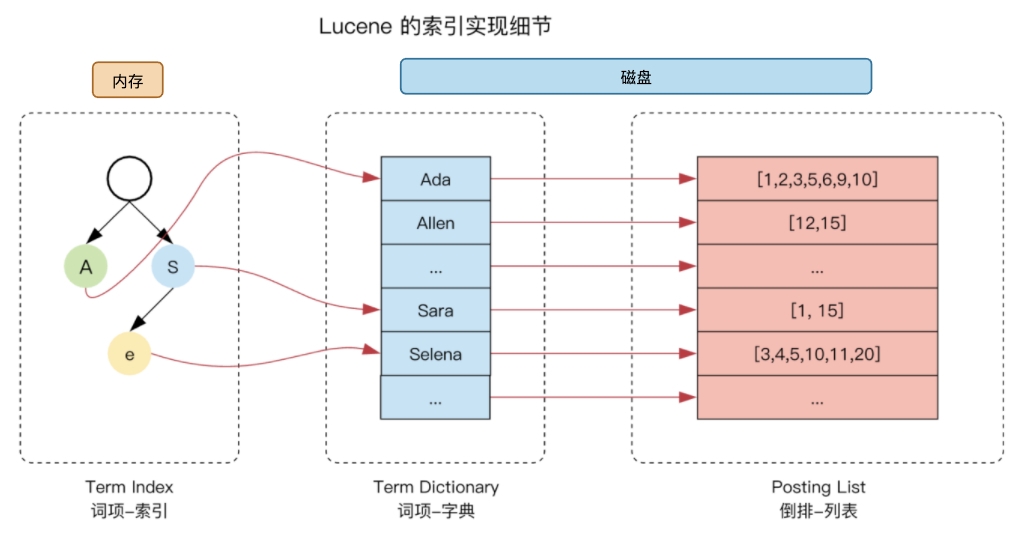
這棵樹不會包含所有的 term,它包含的是 term 的一些前綴(這也是字典樹的使用場景,公共前綴),通過 term index 可以快速地定位到 term dictionary 的某個 offset,然后從這個位置再往后順序查找,就想右邊這個圖所表示的,(怎么樣,像不像我們查英文字典,我們定位 S 開頭的第一個單詞,或者定位到 Sh 開頭的第一個單詞,然后再往后順序查詢)
lucene 在這里還做了兩點優化,一是 term dictionary 在磁盤上面是分 block 保存的,一個 block 內部利用公共前綴壓縮,比如都是 Ab 開頭的單詞就可以把 Ab 省去,二是 term index 在記憶體中是以 FST(finite state transducers)的資料結構保存的,
FST 有兩個優點:
- 空間占用小,通過對詞典中單詞前綴和后綴的重復利用,壓縮了存盤空間
- 查詢速度快,O(len(str)) 的查詢時間復雜度,
OK,現在我們能得到 lucene 倒排索引大致是個什么樣子的了,
四、關于 postings list 的一些巧技
在實際使用中,postings list 還需要解決幾個痛點,
- postings list 如果不進行壓縮,會非常占用磁盤空間,
- 聯合查詢下,如何快速求交并集(intersections and unions)
對于如何壓縮,可能會有人覺得沒有必要,”posting list 不是已經只存盤檔案 id 了嗎?還需要壓縮?”,但是如果在 posting list 有百萬個 doc id 的情況,壓縮就顯得很有必要了,(比如按照朝代查詢古詩?),至于為啥需要求交并集,ES 是專門用來搜索的,肯定會有很多聯合查詢的需求吧 (AND、OR),
按照上面的思路,我們先將如何壓縮,
1. 壓縮
Frame of Reference
在 lucene 中,要求 postings lists 都要是有序的整形陣列,這樣就帶來了一個很好的好處,可以通過 增量編碼(delta-encode)這種方式進行壓縮,
比如現在有 id 串列 [73, 300, 302, 332, 343, 372],轉化成每一個 id 相對于前一個 id 的增量值(第一個 id 的前一個 id 默認是 0,增量就是它自己)串列是[73, 227, 2, 30, 11, 29],在這個新的串列里面,所有的 id 都是小于 255 的,所以每個 id 只需要一個位元組存盤,
實際上 ES 會做的更加精細,
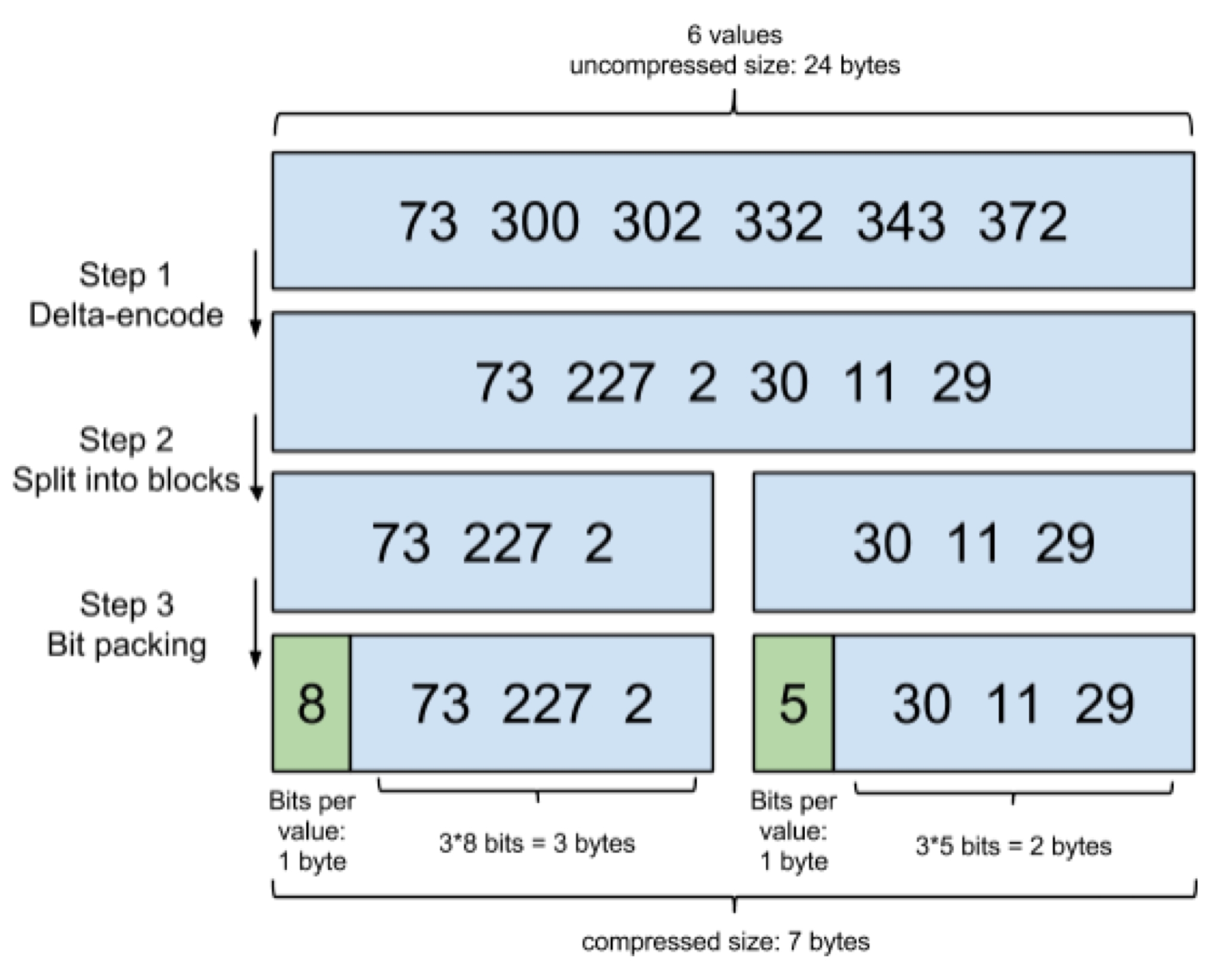
它會把所有的檔案分成很多個 block,每個 block 正好包含 256 個檔案,然后單獨對每個檔案進行增量編碼,計算出存盤這個 block 里面所有檔案最多需要多少位來保存每個 id,并且把這個位數作為頭資訊(header)放在每個 block 的前面,這個技術叫 Frame of Reference,
上圖也是來自于 ES 官方博客中的一個示例(假設每個 block 只有 3 個檔案而不是 256),
FOR 的步驟可以總結為:

進過最后的位壓縮之后,整型陣列的型別從固定大小 (8,16,32,64 位)4 種型別,擴展到了[1-64] 位共 64 種型別,
通過以上的方式可以極大的節省 posting list 的空間消耗,提高查詢性能,不過 ES 為了提高 filter 過濾器查詢的性能,還做了更多的作業,那就是快取,
Roaring Bitmaps (for filter cache)
在 ES 中,可以使用 filters 來優化查詢,filter 查詢只處理檔案是否匹配與否,不涉及檔案評分操作,查詢的結果可以被快取,
對于 filter 查詢,es 提供了 filter cache 這種特殊的快取,filter cache 用來存盤 filters 得到的結果集,快取 filters 不需要太多的記憶體,它只保留一種資訊,即哪些檔案與 filter 相匹配,同時它可以由其它的查詢復用,極大地提升了查詢的性能,
我們上面提到的 Frame Of Reference 壓縮演算法對于 postings list 來說效果很好,但對于需要存盤在記憶體中的 filter cache 等不太合適,
filter cache 會存盤那些經常使用的資料,針對 filter 的快取就是為了加速處理效率,對壓縮演算法要求更高,
對于這類 postings list,ES 采用不一樣的壓縮方式,那么讓我們一步步來,
首先我們知道 postings list 是 Integer 陣列,具有壓縮空間,
假設有這么一個陣列,我們第一個壓縮的思路是什么?用位的方式來表示,每個檔案對應其中的一位,也就是我們常說的位圖,bitmap,
它經常被作為索參考在資料庫、查詢引擎和搜索引擎中,并且位操作(如 and 求交集、or 求并集)之間可以并行,效率更好,
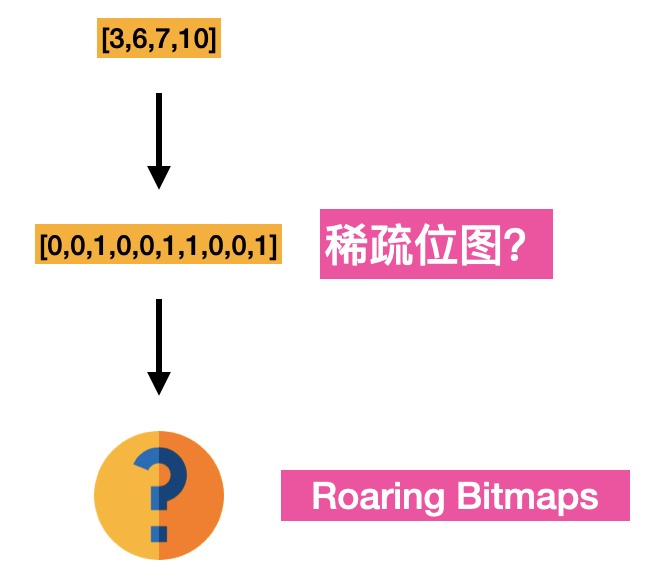
但是,位圖有個很明顯的缺點,不管業務中實際的元素基數有多少,它占用的記憶體空間都恒定不變,也就是說不適用于稀疏存盤,業內對于稀疏位圖也有很多成熟的壓縮方案,lucene 采用的就是roaring bitmaps,
我這里用簡單的方式描述一下這個壓縮程序是怎么樣,
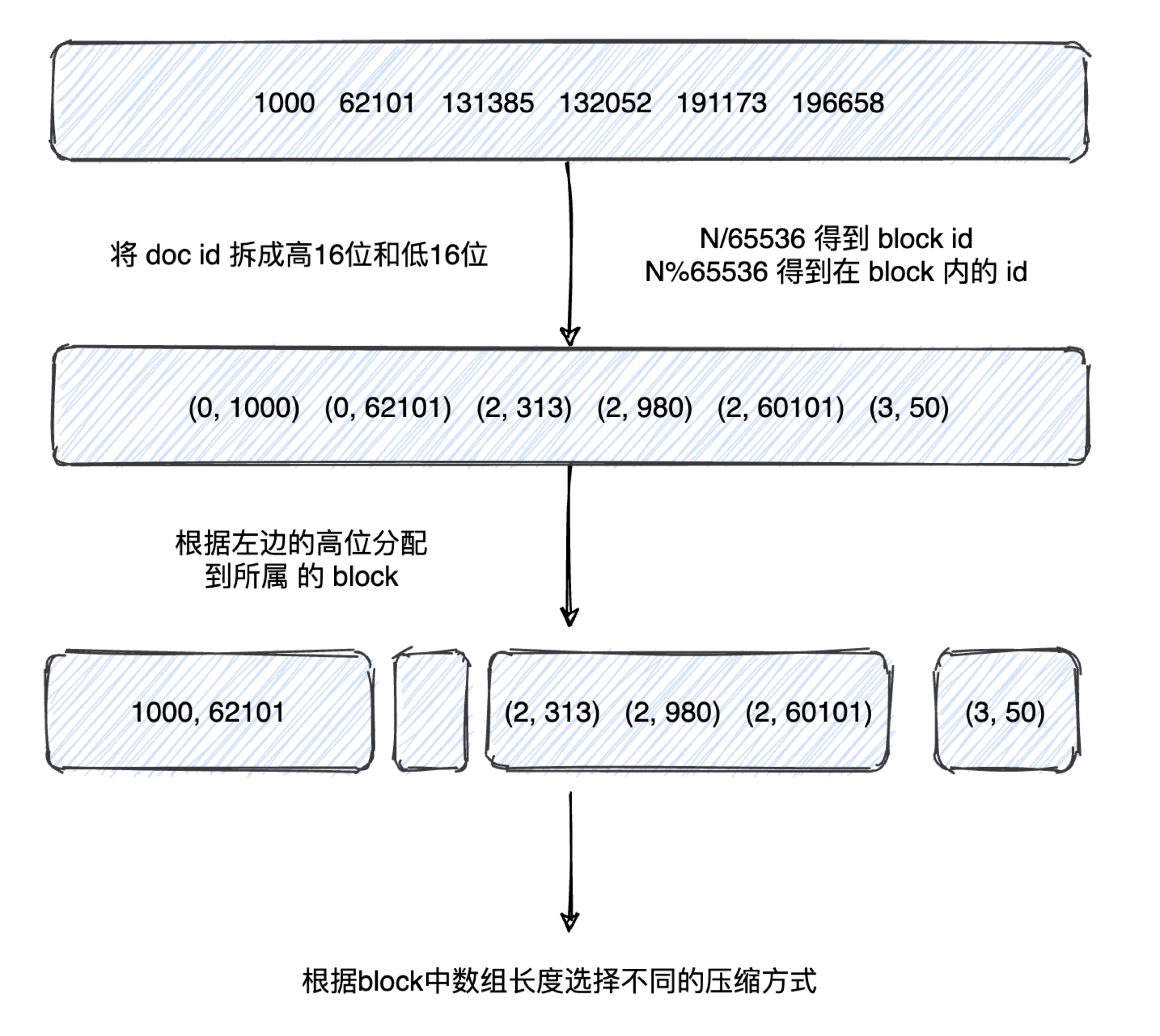
將 doc id 拆成高 16 位,低 16 位,對高位進行聚合 (以高位做 key,value 為有相同高位的所有低位陣列),根據低位的資料量 (不同高位聚合出的低位陣列長度不相同),使用不同的 container(資料結構) 存盤,
- len<4096 ArrayContainer 直接存值
- len>=4096 BitmapContainer 使用 bitmap 存盤
分界線的來源:value 的最大總數是為2^16=65536. 假設以 bitmap 方式存盤需要 65536bit=8kb,而直接存值的方式,一個值 2 byte,4K 個總共需要2byte*4K=8kb,所以當 value 總量 <4k 時,使用直接存值的方式更節省空間,
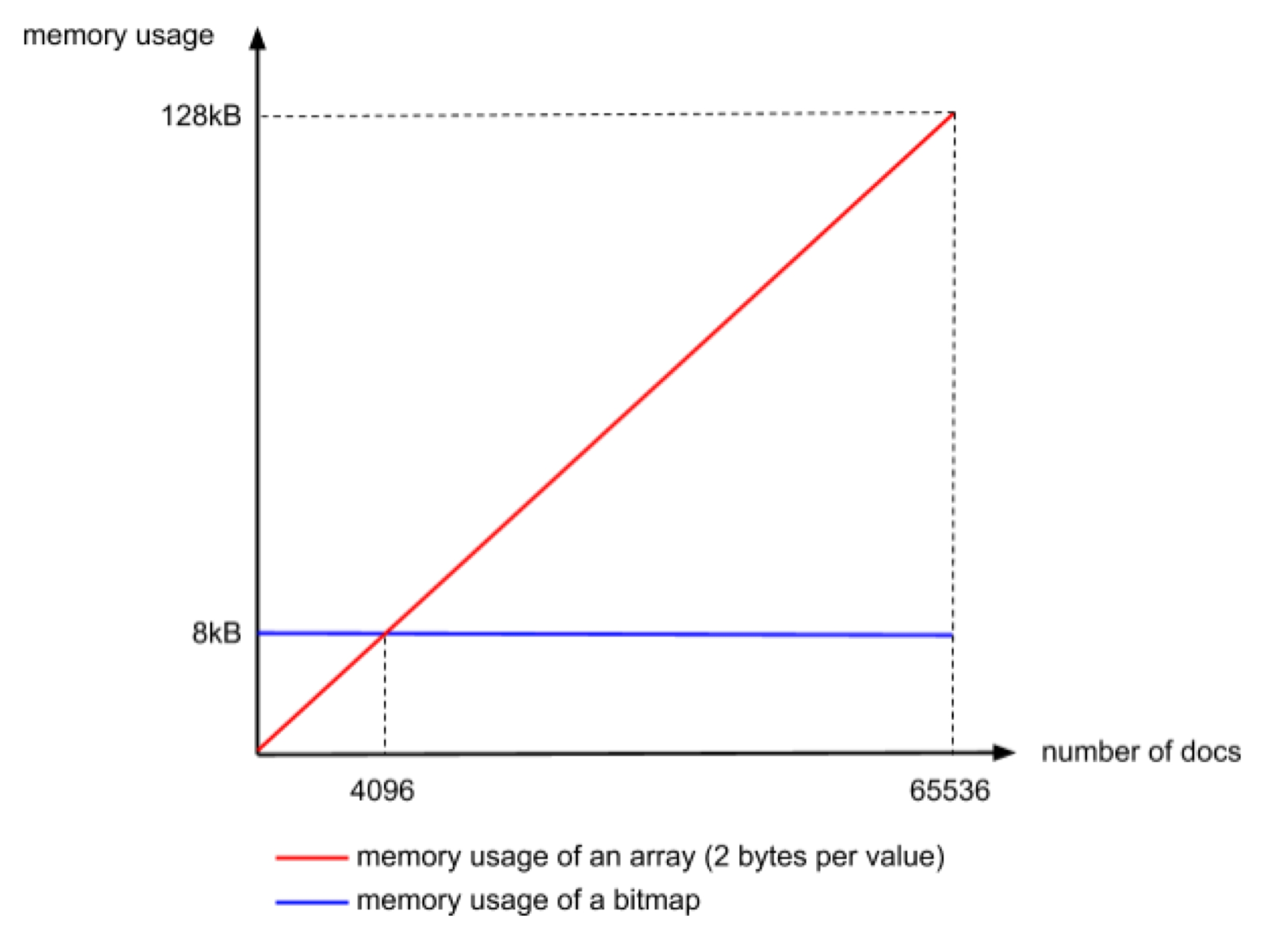
空間壓縮主要體現在:
- 高位聚合 (假設資料中有 100w 個高位相同的值,原先需要
100w*2byte,現在只要1*2byte) - 低位壓縮
缺點就在于位操作的速度相對于原生的 bitmap 會有影響,
這就是 trade-off 呀,平衡的藝術,
2. 聯合查詢
講完了壓縮,我們再來講講聯合查詢,
先講簡單的,如果查詢有 filter cache,那就是直接拿 filter cache 來做計算,也就是說位圖來做 AND 或者 OR 的計算,
如果查詢的 filter 沒有快取,那么就用 skip list 的方式去遍歷磁盤上的 postings list,
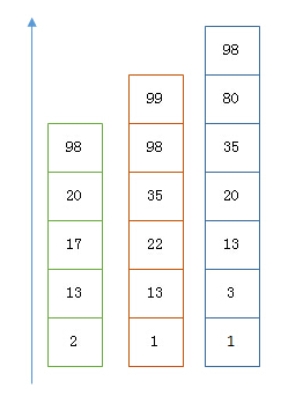
以上是三個 posting list,我們現在需要把它們用 AND 的關系合并,得出 posting list 的交集,首先選擇最短的 posting list,逐個在另外兩個 posting list 中查找看是否存在,最后得到交集的結果,遍歷的程序可以跳過一些元素,比如我們遍歷到綠色的 13 的時候,就可以跳過藍色的 3 了,因為 3 比 13 要小,
用 skip list 還會帶來一個好處,還記得前面說的嗎,postings list 在磁盤里面是采用 FOR 的編碼方式存盤的
會把所有的檔案分成很多個 block,每個 block 正好包含 256 個檔案,然后單獨對每個檔案進行增量編碼,計算出存盤這個 block 里面所有檔案最多需要多少位來保存每個 id,并且把這個位數作為頭資訊(header)放在每個 block 的前面,
因為這個 FOR 的編碼是有解壓縮成本的,利用 skip list,除了跳過了遍歷的成本,也跳過了解壓縮這些壓縮過的 block 的程序,從而節省了 cpu,
五、總結
下面我們來做一個技術總結(感覺有點王剛老師的味道??)
- 為了能夠快速定位到目標檔案,ES 使用倒排索引技術來優化搜索速度,雖然空間消耗比較大,但是搜索性能提高十分顯著,
- 為了能夠在數量巨大的 terms 中快速定位到某一個 term,同時節約對記憶體的使用和減少磁盤 io 的讀取,lucene 使用 "term index -> term dictionary -> postings list" 的倒排索引結構,通過 FST 壓縮放入記憶體,進一步提高搜索效率,
- 為了減少 postings list 的磁盤消耗,lucene 使用了 FOR(Frame of Reference)技術壓縮,帶來的壓縮效果十分明顯,
- ES 的 filter 陳述句采用了 Roaring Bitmap 技術來快取搜索結果,保證高頻 filter 查詢速度的同時降低存盤空間消耗,
- 在聯合查詢時,在有 filter cache 的情況下,會直接利用位圖的原生特性快速求交并集得到聯合查詢結果,否則使用 skip list 對多個 postings list 求交并集,跳過遍歷成本并且節省部分資料的解壓縮 cpu 成本
Elasticsearch 的索引思路
將磁盤里的東西盡量搬進記憶體,減少磁盤隨機讀取次數 (同時也利用磁盤順序讀特性),結合各種壓縮演算法,用及其苛刻的態度使用記憶體,
所以,對于使用 Elasticsearch 進行索引時需要注意:
- 不需要索引的欄位,一定要明確定義出來,因為默認是自動建索引的
- 同樣的道理,對于 String 型別的欄位,不需要 analysis 的也需要明確定義出來,因為默認也是會 analysis 的
- 選擇有規律的 ID 很重要,隨機性太大的 ID(比如 Java 的 UUID) 不利于查詢
最后說一下,技術選型永遠伴隨著業務場景的考量,每種資料庫都有自己要解決的問題(或者說擅長的領域),對應的就有自己的資料結構,而不同的使用場景和資料結構,需要用不同的索引,才能起到最大化加快查詢的目的,
這篇文章講的雖是 Lucene 如何實作倒排索引,如何精打細算每一塊記憶體、磁盤空間、如何用詭譎的位運算加快處理速度,但往高處思考,再類比一下 MySQL,你就會發現,雖然都是索引,但是實作起來,截然不同,籠統的來說,b-tree 索引是為寫入優化的索引結構,當我們不需要支持快速的更新的時候,可以用預先排序等方式換取更小的存盤空間,更快的檢索速度等好處,其代價就是更新慢,就像 ES,
希望本篇文章能給你帶來一些識訓~
參考檔案:
- https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps
- https://www.elastic.co/cn/blog/found-elasticsearch-from-the-bottom-up
- http://blog.mikemccandless.com/2014/05/choosing-fast-unique-identifier-uuid.html
- https://www.infoq.cn/article/database-timestamp-02
- https://zhuanlan.zhihu.com/p/137574234
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2021最新版)
2.別在再滿屏的 if/ else 了,試試策略模式,真香!!
3.臥槽!Java 中的 xx ≠ null 是什么新語法?
4.Spring Boot 2.5 重磅發布,黑暗模式太炸了!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/304440.html
標籤:Java
下一篇:🙈全套Java教程_Java基礎入門教程,零基礎小白自學Java必備教程🐱?🏍008 # 第八單元 面向物件思想 #