??前面的話??
大家好!在C語言中,有個叫“自定義型別”玩意,它究竟是什么呢?其實,就是字面意思,可以自己定義的型別就是自定義型別,具體說就是我們熟知的結構體,列舉,位段,聯合體(共用體),
👋Hi~ o( ̄▽ ̄)ブ這里是豬豬程式員
👀 很高興見到你O(∩_∩)O! 🌱 現在正在發芽中…
🎉歡迎關注🔎點贊👍收藏??留言📝
📌本文由豬豬原創,CSDN首發!📆首發時間:🌼2021年10月1日🌼
💞? 博主水平有限,如果發現錯誤,一定要及時告知作者哦 o( ̄︶ ̄)o!感謝感謝!
📫博主的碼云 gitee,平常博主寫的程式代碼都在里面,
C語言自定義型別的介紹
- 🌱 1.結構體
- 🍀🍀1.1結構體概述
- 🌼🌼🌼1.1.1結構體概念
- 🌼🌼🌼1.1.2 結構體的宣告與使用
- 🌼🌼🌼1.1.3匿名結構體的宣告及使用
- 🌼🌼🌼1.1.4 結構體的自參考
- 🍀🍀 1.2結構體對齊及其大小計算
- 🌼🌼🌼1.2.1偏移量
- 🌼🌼🌼1.2.2結構體大小計算
- 🌼🌼🌼1.2.3修改默認對齊數
- 🌼🌼🌼1.2.4結構體傳參
- 🍀🍀 1.3結構體與位段
- 🌼🌼🌼1.3.1位段
- 🌼🌼🌼1.3.2位段實作結構體
- 🌱2.列舉
- 🍀🍀 2.1列舉概述
- 🌼🌼🌼2.1.1列舉概念
- 🌼🌼🌼2.1.2列舉的宣告與使用
- 🍀🍀 2.2列舉大小計算
- 🍀🍀 2.3列舉與宏的區別
- 🌱3.聯合體
- 🍀🍀 3.1聯合體概述
- 🌼🌼🌼3.1.1聯合體概念
- 🌼🌼🌼3.1.2聯合體的宣告與使用
- 🌼🌼🌼3.1.3聯合體判斷大小端存盤
- 🍀🍀 3.2聯合體大小計算
🌱 1.結構體
🍀🍀1.1結構體概述
🌼🌼🌼1.1.1結構體概念
結構體(struct)是由一系列具有相同型別或不同型別的資料構成的資料集合,也叫結構,它就將不同型別的資料存放在一起,作為一個整體進行處理,
🌼🌼🌼1.1.2 結構體的宣告與使用
🌼結構體的宣告:
struct Book
{
char name[20];
char author[20];
int price;
};
這個宣告描述了一個由兩個字符陣列和一個int變陣列成的結構體,
它將這些變數封裝成一個整體,代表了一本書(含有書名,作者名,價格),
但是注意,它并沒有創建一個實際的資料物件,而是描述了一個組成這類物件的元素,
因此,我們有時候也將結構體宣告叫做模板,因為它勾勒出資料該如何存盤,并沒有實體化資料物件,
🌼結構體的使用(一共3種創建方法)
- 用結構體創建全域變數
struct Book
{
char name[20];
char author[20];
int price;
}b1,b2;
struct Book b1;
這里創建的b1,b2,b3 是完全等價的,都是全域變數,
- 用結構體創建區域變數
struct Book
{
char name[20];
char author[20];
int price;
};
int main()
{
struct Book b4;
return 0;
}
在main函式中創建的結構體變數就是區域變數
🌼結構體變數的定義和初始化
🌱1. 初始化:定義變數的同時賦初值,
🌱2. 結構體的初始化要使用大括號,
struct Stu //型別宣告
{
char name[15];//名字
int age; //年齡
};
struct Stu s = {"zhangsan", 20};//初始化
🌱3. 結構體嵌套初始化:
在結構體中又包含了一個結構體
struct Point
{
int x;
int y;
}p1 = { 1,2 }, p2 = {3,4};
struct Point p3 = { 5,6 };
struct Node
{
int data;
struct Point p;
struct Node* next;
char name[20];
}n1 = {10, {4,5}, NULL};
struct Node n2 = {20, {5, 6}, NULL, "zhangsan"};
🌱4. 對于嵌套結構體的訪問
struct Point
{
int x;
int y;
}p1 = { 1,2 }, p2 = { 3,4 };
struct Point p3 = { 5,6 };
struct S
{
int data;
struct Point p;
char name[20];
}n1 = { 10, {4,5}, };
struct S n2 = { 20, {5, 6}, "zhangsan" };
int main()
{
struct Point p4 = {1,2};
struct S s = { 20,{7,8} };
printf("%d", s.data);
printf("%d %d", s.p.x, s.p.y);
return 0;
}
🌱5. 對于結構體變數中的整型陣列如何回圈列印:
struct S
{
int a[10];
}n1 = { {1,2,3} };
int main()
{
int i = 0;
struct S s = { {7,8,9} };
for (i = 0; i < 10; i++)
{
printf("%d ", s.a[i]);
}
return 0;
}
🌼🌼🌼1.1.3匿名結構體的宣告及使用
struct
{
int a;
char c;
double b;
}s1,s2;
匿名結構體可以無結構體的名字,要創建變數的時候只能在大括號的后面直接創建s1,s2,
匿名結構體只能使用一次,
struct
{
int a;
char c;
double b;
}s1,s2;//第一個
struct
{
int a;
char c;
double b;
}*ps;//第二個
int main()
{
ps = &s1;
return 0;
}
以上創建了兩個匿名的結構體型別,但編譯器會認為他們是不同的,因此第二個結構體創建的匿名結構體指標無法指向第一個匿名結構體,
非法賦值使編譯器報錯,
🌼🌼🌼1.1.4 結構體的自參考
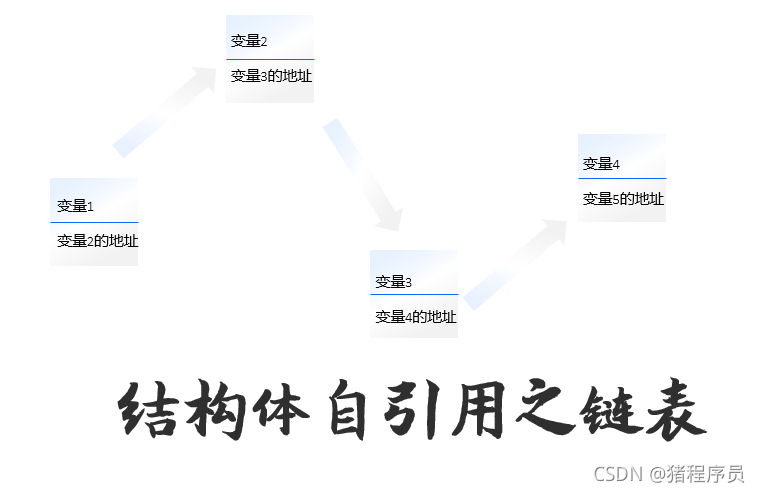
鏈表就如同車鏈子一樣,head指向第一個元素:第一個元素又指向第二個元素;……,直到最后一個元素,該元素不再指向其它元素,它稱為“表尾”,而鏈表的實作就需要用到結構體的自參考,
struct Node
{
int data;
struct Node* n;
};
上述創建了一個鏈表,data是資料域,n為指標域,
結構體自參考:能夠找到通過地址找到自己同型別的下一個結點,
🌼🌼練習一:
struct Node
{
int data;
struct Node next;
};
//可行否?
如果可以,那sizeof(struct Node)是多少?
這樣不行,會造成死回圈,因為無法確定結構體的大小
🌼🌼練習二:
typedef struct
{
int data;
Node* next;
}Node;
//這樣寫代碼,可行否?
分析如下:定義了一個匿名結構體,并且用typedef將這個匿名結構體重命名為Node,但Node的產生必須要先在記憶體中創建一個int型,和Node指標大小的記憶體空間,但是此時還未重命名,所有是錯誤的
正確寫法:
typedef struct Node
{
int data;
struct Node* next;
}Node;
🍀🍀 1.2結構體對齊及其大小計算
🌼🌼🌼1.2.1偏移量
定義:把存盤單元的實際地址與其所在段的段地址之間的距離稱為段內偏移,也稱為"有效地址或偏移量",
先簡單舉個例子來說:
創建的s1 和s2 結構體變數的記憶體大小是多少呢:
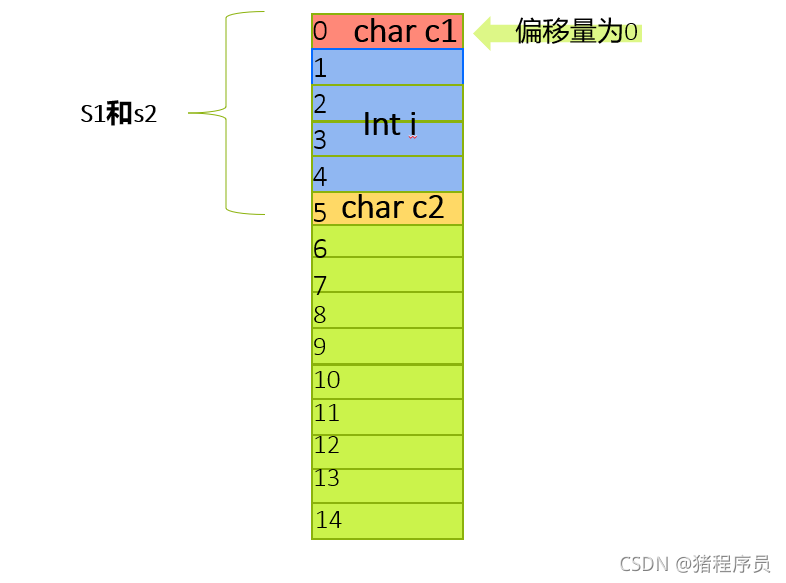
struct S1
{
char c1;
int i;
char c2;
};
struct S2
{
char c1;
char c2;
int i;
};
int main()
{
struct S1 s1 = { 'x',100,'y'};
struct S2 s2 = { 'x','y'100};
printf("%d", sizeof(struct S1)); //12
printf("%d", sizeof(struct S2)); //8
return 0;
}
結果發現兩者的記憶體大小不同,原因是因為涉及了記憶體對齊,
🌱記憶體對齊的規則
- 結構體第一個成員永遠放在結構體變數偏移量為0的地址處,
- 其他成員變數要對齊到某個數字(對齊數)的整數倍的地址處,
對齊數 = 編譯器默認的一個對齊數 與 該成員大小的較小值,
VS中默認的值為8 - 結構體總大小為最大對齊數(每個成員變數都有一個對齊數)的整數倍,
- 如果嵌套了結構體的情況,嵌套的結構體對齊到自己的最大對齊數的整數倍處,結構體的整
體大小就是所有最大對齊數(含嵌套結構體的對齊數)的整數倍,
🌱為什么存在記憶體對齊?
-
平臺原因(移植原因):
不是所有的硬體平臺都能訪問任意地址上的任意資料的;某些硬體平臺只能在某些地址處取某些特
定型別的資料,否則拋出硬體例外, -
性能原因:
資料結構(尤其是堆疊)應該盡可能地在自然邊界上對齊,
原因在于,為了訪問未對齊的記憶體,處理器需要作兩次記憶體訪問;而對齊的記憶體訪問僅需要一次訪
問, -
總體來說:
結構體的記憶體對齊是拿空間來換取時間的做法,
🌼🌼🌼1.2.2結構體大小計算
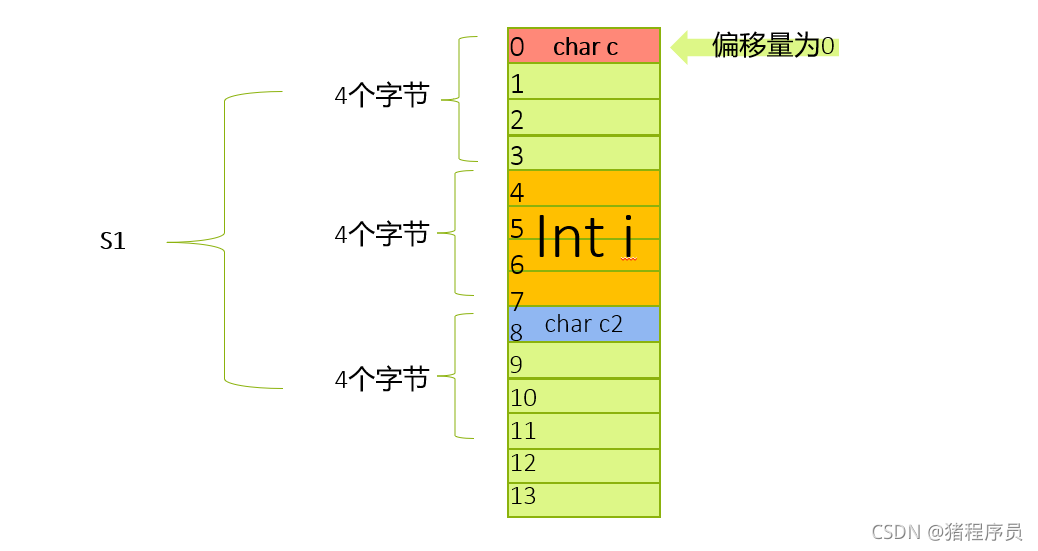
🌱對于S1來說:
struct S1
{
char c1;
int i;
char c2;
};
3個變數最大的占4個位元組,而VS的默認對齊數是8,因此該結構體的默認對齊數是4
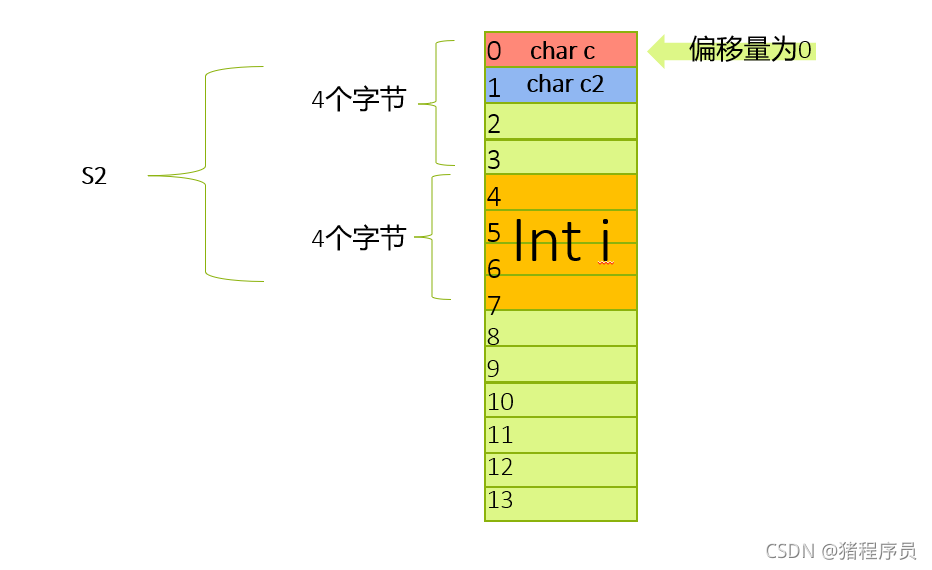
🌱對于S1來說:
struct S2
{
char c1;
char c2;
int i;
};
🌱練習一:
struct S3
{
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S3));
分析:
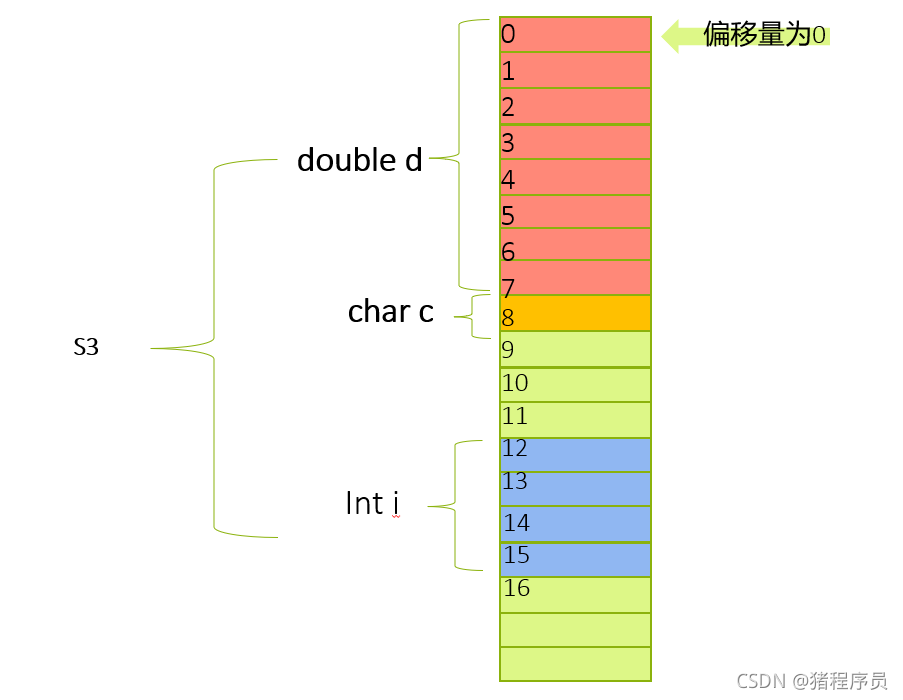
因此一共16個位元組
🌼🌼🌼1.2.3修改默認對齊數
我們使用#pragma修改默認對齊數
#include <stdio.h>
#pragma pack(8) //設定默認對齊數為8
struct S1
{
char c1;
int i;
char c2;
};
#pragma pack() //取消設定的默認對齊數,還原為默認
#pragma pack(1) //設定默認對齊數為1
struct S2
{
char c1;
int i;
char c2;
};
#pragma pack() //取消設定的默認對齊數,還原為默認
int main()
{
//輸出的結果是什么?
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
分析:
此時因為默認對齊數被設定成1,最小值,因此所有的對齊數都為1,相當于取消記憶體對齊,無空間浪費,
🌱百度筆試題:
寫一個宏,計算結構體中某變數相對于首地址的偏移,并給出說明
考察: offsetof 宏的實作
在 <stddef.h> 中定義了個 offsetof(s,m)宏,這個宏用來取得結構體中元素的偏移量很方便,下面是此宏的具體定義:
#define offsetof(s, m) (size_t)&(((s *)0)->m)
offsetof(s, m) 其中,s 是結構體名,m 是它的一個成員,s 和 m 同是宏 offsetof() 的形參,這個宏回傳的是結構體 s 的成員 m 在結構體中的偏移地址,
(s *)0 : 這里的用法實際上是欺騙了編譯器,使編譯器認為 “0” 就是一個指向 s 結構體的指標(地址),即 s 結構體就是位于 0x0 這個地址處,
(s *)0-> m :指向這個結構體的 m 元素,
&((s *)0)->m : 表示 m 元素的地址,這里,如上面所說,因為編譯器認為結構體 s 被認為是處于 0x0 地址處,所以 m 的地址自然的就是 m 在 s 中的偏移地址了,
最后將這個偏移值轉化為 size_t 型別,
#include<stdio.h>
#include<stddef.h>
#define offsetof(s, m) (size_t)&(((s *)0)->m)
struct S
{
char c1;
int a;
char c2;
};
int main()
{
printf("%u\n", offsetof(struct S, c1)); //0
printf("%u\n", offsetof(struct S, a)); //4
printf("%u\n", offsetof(struct S, c2)); //8
return 0;
}
🌼🌼🌼1.2.4結構體傳參
struct S {
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
//結構體傳參
void print1(struct S s) {
printf("%d\n", s.num);
}
//結構體地址傳參
void print2(struct S* ps) {
printf("%d\n", ps->num);
}
int main()
{
print1(s); //傳結構體
print2(&s); //傳地址
return 0;
}
- 上面的 print1 和 print2 函式哪個好些?
答案是:首選print2函式, - 原因:
函式傳參的時候,引數是需要壓堆疊,會有時間和空間上的系統開銷,
如果傳遞一個結構體物件的時候,結構體過大,引數壓堆疊的的系統開銷比較大,所以會導致性能
的下降, - 結論:
結構體傳參的時候,要傳結構體的地址,
🍀🍀 1.3結構體與位段
🌼🌼🌼1.3.1位段
位段的宣告和結構是類似的,有兩個不同:
- 位段的成員必須是 int、unsigned int 或signed int ,
- 位段的成員名后邊有一個冒號和一個數字,
- 位段可以節省空間,
int _a:2;表示_a只需要2個位元位
比如:下方的A就是一個位段型別,那位段A的大小是多少?
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
};
printf("%d\n", sizeof(struct A));
🌱分析:
- 位段一次開辟一個整型(4位元組==32位元位)
- _a + _b + _c一共用了17個位元位,之后的_c不夠用了,于是又開辟了4個位元組
- 因此一共8個位元組
🌱總結
- 位段的成員可以是 int unsigned int signed int 或者是 char (屬于整形家族)型別
- 位段的空間上是按照需要以4個位元組( int )或者1個位元組( char )的方式來開辟的,
- 位段涉及很多不確定因素,位段是不跨平臺的,注重可移植的程式應該避免使用位段,
🌼🌼🌼1.3.2位段實作結構體
🌱練習:
以下的空間是如何開辟的?
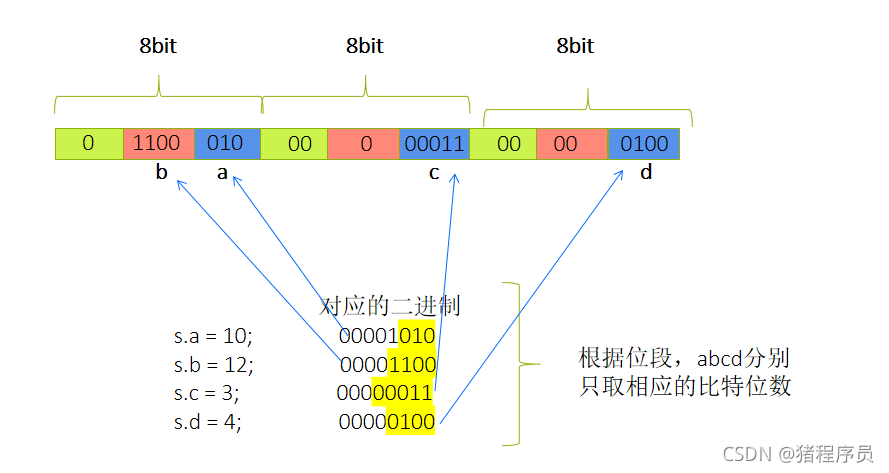
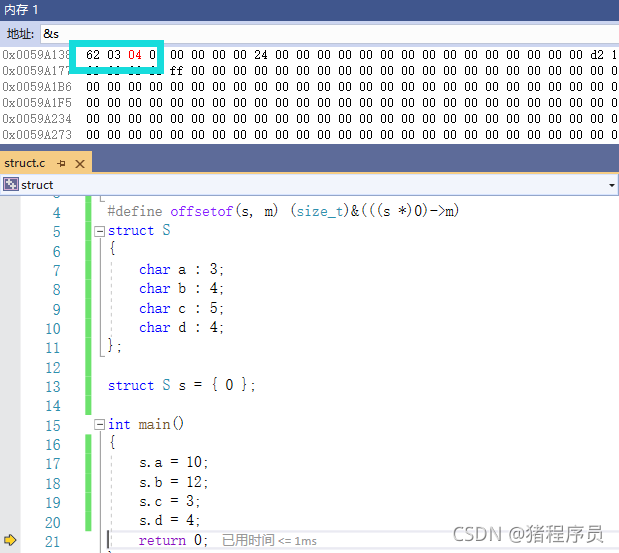
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
分析:
- 由于是char位段,因此是一個位元組一個位元組開辟的

🌱位段的跨平臺問題
- int 位段被當成有符號數還是無符號數是不確定的,
- 位段中最大位的數目不能確定,(16位機器最大16,32位機器最大32,寫成27,在16位機
器會出問題, - 位段中的成員在記憶體中從左向右分配,還是從右向左分配標準尚未定義,
- 當一個結構包含兩個位段,第二個位段成員比較大,無法容納于第一個位段剩余的位時,是
舍棄剩余的位還是利用,這是不確定的,
🌱總結:
跟結構相比,位段可以達到同樣的效果,但是可以很好的節省空間,但是有跨平臺的問題存在,
🌱2.列舉
🍀🍀 2.1列舉概述
🌼🌼🌼2.1.1列舉概念
列舉:就是一一列舉,
列舉常量:{ }中的內容是列舉型別的可能取值,就叫列舉常量 ,
列舉常量都是有值的,默認從0開始,一次遞增1,當然在定義的時候也可以賦初值,
比如我們現實生活中:
- 一周的星期一到星期日是有限的7天,可以一一列舉,
- 性別有:男、女、保密,也可以一一列舉,
- 月份有12個月,也可以一一列舉
🌼🌼🌼2.1.2列舉的宣告與使用
enum Color//顏色
{
RED,
GREEN,
BLUE
};
int main()
{
printf("%d ", RED); //0
printf("%d ", GREEN); //1
printf("%d ", BLUE); //2
return 0;
}
以上定義的 enum Day , enum Sex , enum Color 都是列舉型別,
🌱亦可以自己對列舉初始化:
enum Color//顏色
{
RED=5,
GREEN=8,
BLUE
};
🌱列舉型別的使用
enum Color//顏色
{
RED=1,
GREEN=2,
BLUE=4
};
enum Color clr = GREEN;//只能拿列舉常量給列舉變數賦值,才不會出現型別的差異,
clr = 5; //這樣不行
🍀🍀 2.2列舉大小計算
列舉變數的大小,即列舉型別所占記憶體的大小,列舉型別變數都占4位元組,
enum A
{
QSW,
BSW,
CWS
}a;
int main()
{
printf("%d\n", sizeof(a));
return 0;
}
🍀🍀 2.3列舉與宏的區別
使用列舉定義的列舉常量是有型別的,為列舉型別,而使用#define宏是替換,并沒有列舉型別這種性質,
🌱 列舉的優點
- 增加代碼的可讀性和可維護性
- 和#define定義的識別符號比較列舉有型別檢查,更加嚴謹,
- 防止了命名污染(封裝)
- 便于除錯
- 使用方便,一次可以定義多個常量
🌱3.聯合體
🍀🍀 3.1聯合體概述
🌼🌼🌼3.1.1聯合體概念
聯合:也是一種特殊的自定義型別
這種型別定義的變數也包含一系列的成員,特征是這些成員公用同一塊空間(所以聯合也叫共用體),
//聯合型別的宣告
union Un
{
char c;
int i;
};
//聯合變數的定義
union Un un;
//計算連個變數的大小
🌼🌼🌼3.1.2聯合體的宣告與使用
//聯合型別的宣告
union Un
{
char c;
int i;
};
//聯合變數的定義
union Un un;
//計算連個變數的大小
printf("%d\n", sizeof(un));
🌼分析:列印的結果是4個位元組
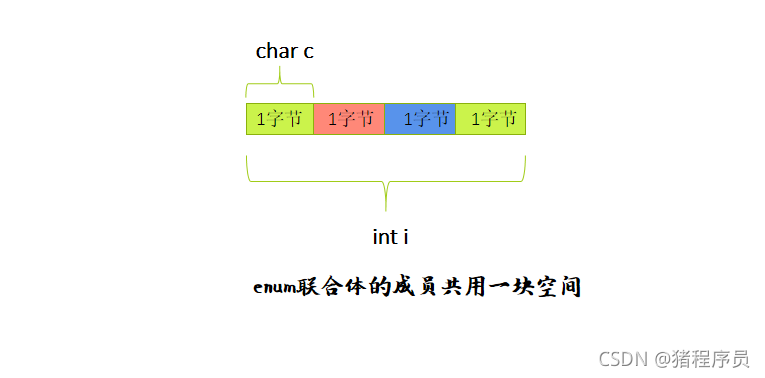
🌼聯合的成員是共用同一塊記憶體空間的,這樣一個聯合變數的大小,至少是最大成員的大小
(因為聯合至少得有能力保存最大的那個成員),
union Un
{
char c;
int i;
};
union Un u;
int main()
{
printf("%p ", &u);
printf("%p ", &(u.c));
printf("%p ", &(u.i));
return 0;
}
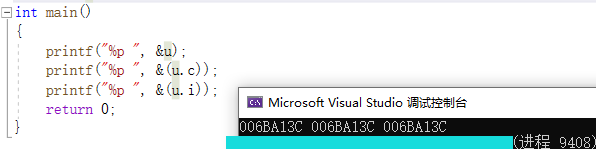
🌼🌼🌼3.1.3聯合體判斷大小端存盤
🌱關于大小端:
記憶體中存盤這兩個位元組有兩種方法:
- 小端位元組序:將低序位元組存盤在起始地址,
- 大端位元組序:將高序位元組存盤在起始地址,

🌱方法一:未使用聯合體
int main()
{
int a = 1;
char* pc = (char*)&a;//強制型別轉化取的是低位的資料
if (*pc == 1)
{
printf("小端");
}
else
printf("大端");
return 0;
}
🌱方法二:使用聯合體
int main()
{
union U
{
char c;
int i;
};
u.i = 1;
if (u.c == 1)
{
printf("小端");
}
else
printf("大端");
return 0;
}
🍀🍀 3.2聯合體大小計算
- 聯合的大小至少是最大成員的大小,
- 當最大成員大小不是最大對齊數的整數倍的時候,就要對齊到最大對齊數的整數倍,
union Un1
{
char c[5];
int i;
};
union Un2
{
short c[7];
int i;
};
//下面輸出的結果是什么?
printf("%d\n", sizeof(union Un1));
printf("%d\n", sizeof(union Un2));
🌱分析
- 對于Un1來說,其對齊數是4,而char[5]占據了5個位元組,超過了4,因此結果為8
- Un2來說,其對齊數是4,而short[7]占據了14個位元組,超過了12,因此結果為16
覺得文章寫得不錯的老鐵們,點贊評論關注走一波!謝謝啦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/304742.html
標籤:java
上一篇:CSDN系結GitHub詳細步驟,完成后可以得勛章哦,親們國慶假期愉快!
下一篇:資料結構--堆疊和佇列的使用