此文章撰寫于國慶假期,以此紀念,祝大家萬事大吉,心想事成,家和萬事興!國慶快樂!
目錄
微信公眾號爬蟲的基本原理
爬蟲的基本原理
爬蟲的基本流程
HTTP 請求格式
HTTP 回應格式
使用 Requests 實作一個簡單網頁爬蟲
安裝 requests
GET 請求
POST 請求
自定義請求頭
引數傳遞
設定超時
設定代理
Session
小試牛刀
使用 Fiddler 抓包分析公眾號請求程序
Fiddler 配置
Android 手機代理配置
小結
抓取第一篇微信公眾號文章
微信公眾號爬蟲的基本原理
網上關于爬蟲的教程多如牛毛,但很少有看到微信公眾號爬蟲教程,要有也是基于搜狗微信的,不過搜狗提供的資料有諸多弊端,比如文章鏈接是臨時的,文章沒有閱讀量等指標,所以我想寫一個比較系統的關于如何通過手機客戶端利用 Python 爬微信公眾號文章的教程,并對公眾號文章做資料分析,為更好的運營公眾號提供決策,
爬蟲的基本原理
所謂爬蟲就是一個自動化資料采集工具,你只要告訴它要采集哪些資料,丟給它一個 URL,就能自動地抓取資料了,其背后的基本原理就是爬蟲程式向目標服務器發起 HTTP 請求,然后目標服務器回傳回應結果,爬蟲客戶端收到回應并從中提取資料,再進行資料清洗、資料存盤作業,
爬蟲的基本流程
爬蟲流程也是一個 HTTP 請求的程序,以瀏覽器訪問一個網址為例,從用戶輸入 URL 開始,客戶端通過 DNS 決議查詢到目標服務器的 IP 地址,然后與之建立 TCP 連接,連接成功后,瀏覽器構造一個 HTTP 請求發送給服務器,服務器收到請求之后,從資料庫查到相應的資料并封裝成一個 HTTP 回應,然后將回應結果回傳給瀏覽器,瀏覽器對回應內容進行資料決議、提取、渲染并最終展示在你面前,
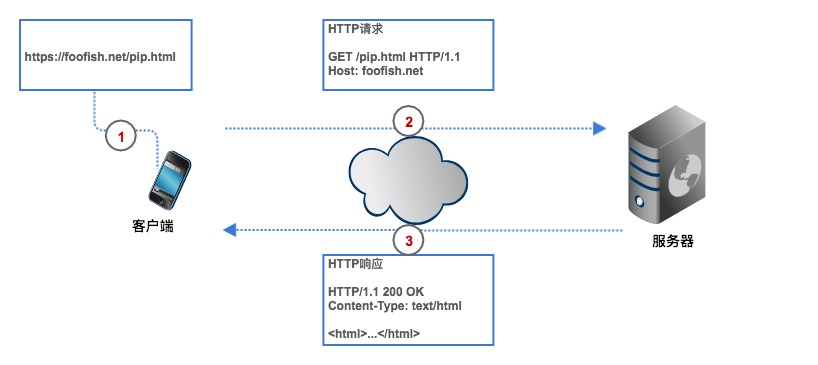
HTTP 協議的請求和回應都必須遵循固定的格式,只有遵循統一的 HTTP 請求格式,服務器才能正確決議不同客戶端發的請求,同樣地,服務器遵循統一的回應格式,客戶端才得以正確決議不同網站發過來的回應,
HTTP 請求格式
HTTP 請求由請求行、請求頭、空行、請求體組成,
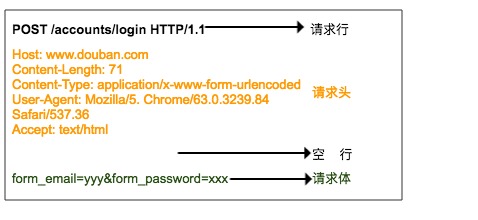
請求行由三部分組成:
- 第一部分是請求方法,常見的請求方法有 GET、POST、PUT、DELETE、HEAD
- 第二部分是客戶端要獲取的資源路徑
- 第三部分是客戶端使用的 HTTP 協議版本號
請求頭是客戶端向服務器發送請求的補充說明,比如 User-Agent 向服務器說明客戶端的身份,
請求體是客戶端向服務器提交的資料,比如用戶登錄時需要提高的賬號密碼資訊,請求頭與請求體之間用空行隔開,請求體并不是所有的請求都有的,比如一般的GET都不會帶有請求體,
上圖就是瀏覽器登錄豆瓣時向服務器發送的HTTP POST 請求,請求體中指定了用戶名和密碼,
HTTP 回應格式
HTTP 回應格式與請求的格式很相似,也是由回應行、回應頭、空行、回應體組成,
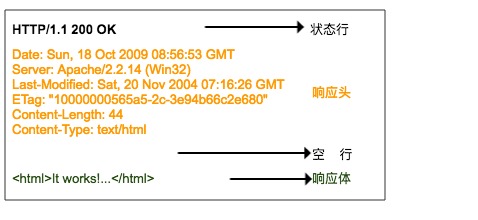
回應行也包含三部分,分別是服務端的 HTTP 版本號、回應狀態碼、狀態說明,回應狀態碼常見有 200、400、404、500、502、304 等等,一般以 2 開頭的表示服務器正常回應了客戶端請求,4 開頭表示客戶端的請求有問題,5 開頭表示服務器出錯了,沒法正確處理客戶端請求,狀態碼說明就是對該狀態碼的一個簡短描述,
第二部分就是回應頭,回應頭與請求頭對應,是服務器對該回應的一些附加說明,比如回應內容的格式是什么,回應內容的長度有多少、什么時間回傳給客戶端的、甚至還有一些 Cookie 資訊也會放在回應頭里面,
第三部分是回應體,它才是真正的回應資料,這些資料其實就是網頁的 HTML 源代碼,
使用 Requests 實作一個簡單網頁爬蟲
Python 提供了非常多工具去實作 HTTP 請求,但第三方開源庫提供的功能更豐富,你無需從 socket 通信開始寫,比如使用Pyton內建模塊 urllib 請求一個 URL 代碼示例如下:
import ssl from urllib.request;
import Request from urllib.request;
import urlopen context = ssl._create_unverified_context()
# HTTP 請求
request = Request(url="https://foofish.net/pip.html", method="GET", headers={"Host": "foofish.net"}, data=None) # HTTP 回應
response = urlopen(request, context=context) headers = response.info() # 回應頭
content = response.read() # 回應體
code = response.getcode() # 狀態碼發起請求前首先要構建請求物件 Request,指定 url 地址、請求方法、請求頭,這里的請求體 data 為空,因為你不需要提交資料給服務器,所以你也可以不指定,urlopen 函式會自動與目標服務器建立連接,發送 HTTP 請求,該函式的回傳值是一個回應物件 Response,里面有回應頭資訊,回應體,狀態碼之類的屬性,
但是,Python 提供的這個內建模塊過于低級,需要寫很多代碼,使用簡單爬蟲可以考慮 Requests,Requests 在GitHub 有近30k的Star,是一個很Pythonic的框架,先來簡單熟悉一下這個框架的使用方式
安裝 requests
pip install requestsGET 請求
>>> r = requests.get("https://httpbin.org/ip")
>>> r
<Response [200]> # 回應物件
>>> r.status_code # 回應狀態碼 200
>>> r.content # 回應內容
'{\n "origin": "183.237.232.123"\n}\n'POST 請求
>>> r = requests.post('http://httpbin.org/post', data = {'key':'value'})自定義請求頭
這個經常會用到,服務器反爬蟲機制會判斷客戶端請求頭中的User-Agent是否來源于真實瀏覽器,所以,我們使用Requests經常會指定UA偽裝成瀏覽器發起請求
>>> url = 'https://httpbin.org/headers'
>>> headers = {'user-agent': 'Mozilla/5.0'}
>>> r = requests.get(url, headers=headers)引數傳遞
很多時候URL后面會有一串很長的引數,為了提高可讀性,requests 支持將引數抽離出來作為方法的引數(params)傳遞過去,而無需附在 URL 后面,例如請求 url http://bin.org/get?key=val ,可使用
>>> url = "http://httpbin.org/get"
>>> r = requests.get(url, params={"key":"val"})
>>> r.url u'http://httpbin.org/get?key=val'指定Cookie
Cookie 是web瀏覽器登錄網站的憑證,雖然 Cookie 也是請求頭的一部分,我們可以從中剝離出來,使用 Cookie 引數指定
>>> s = requests.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
>>> s.text
u'{\n "cookies": {\n "from-my": "browser"\n }\n}\n'設定超時
當發起一個請求遇到服務器回應非常緩慢而你又不希望等待太久時,可以指定 timeout 來設定請求超時時間,單位是秒,超過該時間還沒有連接服務器成功時,請求將強行終止,
r = requests.get('https://google.com', timeout=5)設定代理
一段時間內發送的請求太多容易被服務器判定為爬蟲,所以很多時候我們使用代理IP來偽裝客戶端的真實IP,
import requests
proxies = { 'http': 'http://127.0.0.1:1080', 'https': 'http://127.0.0.1:1080', }
r = requests.get('http://www.kuaidaili.com/free/', proxies=proxies, timeout=2)Session
如果想和服務器一直保持登錄(會話)狀態,而不必每次都指定 cookies,那么可以使用 session,Session 提供的API和 requests 是一樣的,
import requests
s = requests.Session()
s.cookies = requests.utils.cookiejar_from_dict({"a": "c"})
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'小試牛刀
現在我們使用Requests完成一個爬取知乎專欄用戶關注串列的簡單爬蟲為例,找到任意一個專欄,打開它的關注串列,用 Chrome 找到獲取粉絲串列的請求地址:https://www.zhihu.com/api/v4/columns/pythoneer/followers?include=data%5B%2A%5D.follower_count%2Cgender%2Cis_followed%2Cis_following&limit=10&offset=20, 我是怎么找到的?就是逐個點擊左側的請求,觀察右邊是否有資料出現,那些以 .jpg,js,css 結尾的靜態資源可直接忽略,
現在我們用 Requests 模擬瀏覽器發送請求給服務器,寫程式前,我們要先分析出這個請求是怎么構成的,請求URL是什么?請求頭有哪些?查詢引數有哪些?只有清楚了這些,你才好動手寫代碼,掌握分析方法很重要,否則一頭霧水,
回到前面那個URL,我們發現這個URL是獲取粉絲串列的介面,然后再來詳細分析一下這個請求是怎么構成的,
- 請求URL:https://www.zhihu.com/api/v4/columns/pythoneer/followers
- 請求方法:GET
- user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
- 查詢引數:
- include: data[*].follower_count,gender,is_followed,is_following
- offset: 0
- limit: 10
利用這些請求資料我們就可以用requests這個庫來構建一個請求,通過Python代碼來抓取這些資料,
import requests
class SimpleCrawler:
def crawl(self, params=None):
# 必須指定UA,否則知乎服務器會判定請求不合法
url = "https://www.zhihu.com/api/v4/columns/pythoneer/followers"
# 查詢引數
params = {"limit": 20,
"offset": 0,
"include": "data[*].follower_count, gender, is_followed, is_following"}
headers = {
"authority": "www.zhihu.com",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
}
response = requests.get(url, headers=headers, params=params)
print("請求URL:", response.url)
# 你可以先將回傳的回應資料列印出來,拷貝到 http://www.kjson.com/jsoneditor/ 分析其結構,
print("回傳資料:", response.text)
# 決議回傳的資料
for follower in response.json().get("data"):
print(follower)
if __name__ == '__main__':
SimpleCrawler().crawl()這就是一個最簡單的基于 Requests 的單執行緒知乎專欄粉絲串列的爬蟲,requests 非常靈活,請求頭、請求引數、Cookie 資訊都可以直接指定在請求方法中,回傳值 response 如果是 json 格式可以直接呼叫json()方法回傳 python 物件,關于 Requests 的更多使用方法可以參考官方檔案:Requests: HTTP for Humans? — Requests 2.26.0 documentation
使用 Fiddler 抓包分析公眾號請求程序
上一節我們熟悉了 Requests 基本使用方法,配合 Chrome 瀏覽器實作了一個簡單爬蟲,但因為微信公眾號的封閉性,微信公眾平臺并沒有對外提供 Web 端入口,只能通過手機客戶端接收、查看公眾號文章,所以,為了窺探到公眾號背后的網路請求,我們需要借以代理工具的輔助,
HTTP代理工具又稱為抓包工具,主流的抓包工具 Windows 平臺有 Fiddler,macOS 有 Charles,阿里開源了一款工具叫 AnyProxy,它們的基本原理都是類似的,就是通過在手機客戶端設定好代理IP和埠,客戶端所有的 HTTP、HTTPS 請求就會經過代理工具,在代理工具中就可以清晰地看到每個請求的細節,然后可以分析出每個請求是如何構造的,弄清楚這些之后,我們就可以用 Python 模擬發起請求,進而得到我們想要的資料,
Fiddler 下載地址是 Download Fiddler Web Debugging Tool for Free by Telerik,安裝包就 4M 多,在配置之前,首先要確保你的手機和電腦在同一個局域網,如果不在同一個局域網,你可以買個隨身WiFi,在你電腦上搭建一個極簡無線路由器,安裝程序一路點擊下一步完成就可以了,
Fiddler 配置
選擇 Tools > Fiddler Options > Connections
Fiddler 默認的埠是使用 8888,如果該埠已經被其它程式占用了,你需要手動更改,勾選 Allow remote computers to connect,其它的選擇默認配置就好,配置更新后記得重啟 Fiddler,一定要重啟 Fiddler,否則代理無效,
接下來你需要配置手機,我們以 Android 設備為例,現在假設你的手機和電腦已經在同一個局域網(只要連的是同一個路由器就在同局域網內),找到電腦的 IP 地址,在 Fiddler 右上角有個 Online 圖示,滑鼠移過去就能看到IP了,你也可以在CMD視窗使用 ipconfig 命令查看到
Android 手機代理配置
進入手機的 WLAN 設定,選擇當前所在局域網的 WiFi 鏈接,設定代理服務器的 IP 和埠,我這是以小米設備為例,其它 Android 手機的配置程序大同小異,
測驗代理有沒有設定成功可以在手機瀏覽器訪問你配置的地址:http://192.168.31.236:8888/ 會顯示 Fiddler 的回顯頁面,說明配置成功,
現在你打開任意一個HTTP協議的網站都能看到請求會出現在 Fiddler 視窗,但是 HTTPS 的請求并沒有出現在 Fiddler 中,其實還差一個步驟,需要在 Fiddler 中激活 HTTPS 抓取設定,在 Fiddler 選擇 Tools > Fiddler Options > HTTPS > Decrypt HTTPS traffic, 重啟 Fiddler,
為了能夠讓 Fiddler 截取 HTTPS 請求,客戶端都需要安裝且信任 Fiddler 生成的 CA 證書,否則會出現“網路出錯,輕觸螢屏重新加載:-1200”的錯誤,在瀏覽器打開 Fiddler 回顯頁面 http://192.168.31.236:8888/ 下載 FiddlerRoot certificate,下載并安裝證書,并驗證通過,
iOS下載安裝完成之后還要從 設定->通用->關于本機->證書信任設定 中把 Fiddler 證書的開關打開
Android 手機下載保存證書后從系統設定里面找到系統安全,從SD卡安裝證書,如果沒有安裝證書,打開微信公眾號的時候會彈出警告,
至此,所有的配置都完成了,現在打開微信隨便選擇一個公眾號,查看公眾號的所有歷史文章串列,微信在2018年6月份對 iOS 版本的微信以及部分 Android 版微信針對公眾號進行了大幅調整,改為現在的資訊流方式,現在要獲取某個公眾號下面「所有文章串列」大概需要經過以下四個步驟:
如果你的微信版本還不是資訊流方式展示的,那么應該是Android版本(微信采用的ABTest,不同的用戶呈現的方式不一樣)
同時觀察 Fiddler 主面板
進入「全部訊息」頁面時,在 Fiddler 上已經能看到有請求進來了,說明公眾號的文章走的都是HTTP協議,這些請求就是微信客戶端向微信服務器發送的HTTP請求,
注意:第一次請求「全部訊息」的時候你看到的可能是一片空白:
在Fiddler或Charles中看到的請求資料是這樣的:
這個時候你要直接從左上角叉掉重新進入「全部訊息」頁面,
現在簡單介紹一下這個請求面板上的每個模塊的意義,
這樣說明這個請求被微信服務器判定為一次非法的請求,這時你可以叉掉該頁面重新進入「全部訊息」頁面,不出意外的話就能正常看到全部文章串列了,同時也能在Fiddler中看到正常的資料請求了,
我把上面的主面板劃分為 7 大塊,你需要理解每塊的內容,后面才有可能會用 Python 代碼來模擬微信請求,
1、服務器的回應結果,200 表示服務器對該請求回應成功
2、請求協議,微信的請求協議都是基 于HTTPS 的,所以前面一定要配置好,不然你看不到 HTTPS 的請求,
3、微信服務器主機名
4、請求路徑
5、請求行,包括了請求方法(GET),請求協議(HTTP/1.1),請求路徑(/mp/profile_ext...后面還有很長一串引數) 6、包括Cookie資訊在內的請求頭,
7、微信服務器回傳的回應資料,我們分別切換成 TextView 和 WebView 看一下回傳的資料是什么樣的,
TextView 模式下的預覽效果是服務器回傳的 HTML 源代碼
WebView 模式是 HTML 代碼經過渲染之后的效果,其實就是我們在手機微信中看到的效果,只不過因為缺乏樣式,所以沒有手機上看到的美化效果,
如果服務器回傳的是 Json格式或者是 XML,你還可以切換到對應的頁面預覽查看,
小結
配置好Fiddler的幾個步驟主要包括指定監控的埠,開通HTTPS流量解密功能,同時,客戶端需要安裝CA證書,下一節我們基于Requests模擬像微信服務器發起請求,
抓取第一篇微信公眾號文章
打開微信歷史訊息頁面,我們從 Fiddler 看到了很多請求,為了找到微信歷史文章的介面,我們要逐個查看 Response 回傳的內容,最后發現第 11 個請求 "https://mp.weixin.qq.com/mp/profile_ext?action=home..." 就是我們要尋找的(我是怎么找到的呢?這個和你的經驗有關,你可以點擊逐個請求,看看回傳的Response內容是不是期望的內容)
確定微信公眾號的請求HOST是 mp.weixin.qq.com 之后,我們可以使用過濾器來過濾掉不相關的請求,
爬蟲的基本原理就是模擬瀏覽器發送 HTTP 請求,然后從服務器得到回應結果,現在我們就用 Python 實作如何發送一個 HTTP 請求,這里我們使用 requests 庫來發送請求,
創建一個 Pycharm 專案
我們使用 Pycharm 作為開發工具,你也可以使用其它你熟悉的工具,Python 環境是 Python3(推薦使用 Python3.6),先創建一個專案 weixincrawler
現在我們來撰寫一個最粗糙的版本,你需要做兩件事:
- 1:找到完整URL請求地址
- 2:找到完整的請求頭(headers)資訊,Headers里面包括了cookie、User-agent、Host 等資訊,
我們直接從 Fiddler 請求中拷貝 URL 和 Headers, 右鍵 -> Copy -> Just Url/Headers Only
最終拷貝出來的URL很長,它包含了很多的引數:
url = "https://mp.weixin.qq.com/mp/profile_ext" \
"?action=home" \
"&__biz=MjM5MzgyODQxMQ==" \
"&scene=124" \
"&devicetype=android-24" \
"&version=26051633&lang=zh_CN" \
"&nettype=WIFI&a8scene=3" \
"&pass_ticket=MXADI5SFjXvX7DFPRuUEJhWHEWvRha2x1Re%2BoJkveUxIonMfnxY1kM9cOPmm6JRx" \
"&wx_header=1"暫且不去分析(猜測)每個引數的意義,也不知道那些引數是必須的,總之我把這些引數全部提取出來,然后把 Headers 拷貝出來,發現 Fiddler 把 請求行、回應行、回應頭都包括進來了,我們只需要中間的請求頭部分,
因為 requests.get 方法里面的 headers 引數必須是字典物件,所以,先要寫個函式把剛剛拷貝的字串轉換成字典物件,
def headers_to_dict(headers):
"""
將字串
'''
Host: mp.weixin.qq.com
Connection: keep-alive
Cache-Control: max-age=
'''
轉換成字典物件
{
"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Cache-Control":"max-age="
}
:param headers: str
:return: dict
"""
headers = headers.split("\n")
d_headers = dict()
for h in headers:
if h:
k, v = h.split(":", 1)
d_headers[k] = v.strip()
return d_headers
最終 v0.1 版本出來了,不出意外的話,公眾號歷史文章資料就在 response.text 中,如果回傳的內容非常短,而且title標簽是<title>驗證</title>,那么說明你的請求引數或者請求頭有誤,最有可能的一種請求就是 Headers 里面的 Cookie 欄位過期,從手機微信端重新發起一次請求獲取最新的請求引數和請求頭試試,
# v0.1
def crawl():
url = "https://mp.weixin.qq.com/..." # 省略了
headers = """ # 省略了
Host: mp.weixin.qq.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
"""
headers = headers_to_dict(headers)
response = requests.get(url, headers=headers, verify=False)
print(response.text)
最后,我們順帶把回應結果另存為html檔案,以便后面重復使用,分析里面的內容
with open("weixin_history.html", "w", encoding="utf-8") as f:
f.write(response.text)用瀏覽器打開 weixin_history.html 檔案,查看該頁面的源代碼,搜索微信歷史文章標題的關鍵字 "11月贈書"(就是我以往發的文章),你會發現,歷史文章封裝在叫 msgList 的陣列中(實際上該陣列包裝在字典結構中),這是一個 Json 格式的資料,但是里面還有 html 轉義字符需要處理
接下來我們就來寫一個方法提取出歷史文章資料,分三個步驟,首先用正則提取資料內容,然后 html 轉義處理,最終得到一個串列物件,回傳最近發布的10篇文章,
def extract_data(html_content):
"""
從html頁面中提取歷史文章資料
:param html_content 頁面源代碼
:return: 歷史文章串列
"""
import re
import html
import json
rex = "msgList = '({.*?})'"
pattern = re.compile(pattern=rex, flags=re.S)
match = pattern.search(html_content)
if match:
data = match.group(1)
data = html.unescape(data)
data = json.loads(data)
articles = data.get("list")
for item in articles:
print(item)
return articles
最終提取出來的資料總共有10條,就是最近發表的10條資料,我們看看每條資料回傳有哪些欄位,
article = {'app_msg_ext_info':
{'title': '11月贈書,總共10本,附Python書單',
'copyright_stat': 11,
'is_multi': 1,
'content': '',
'author': '劉志軍',
'subtype': 9,
'del_flag': 1,
'fileid': 502883895,
'content_url': 'http:\\/\\/mp.weixin.qq.com...',
''
'digest': '十一月份贈書福利如期而至,更多驚喜等著你',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\...',
'multi_app_msg_item_list': [{'fileid': 861719336,
'content_url': 'http:\\/\\/mp.weixin.qq.com',
'content': '', 'copyright_stat': 11,
'cover': 'http:\\/\\/mmbiz.qpic.cn',
'del_flag': 1,
'digest': '多數情況下,人是種短視的動物',
'source_url': '',
'title': '羅胖60秒:諾貝爾獎設立時,為何會被罵?',
'author': '羅振宇'
}],
'source_url': 'https:\\/\\/github.com\'
},
'comm_msg_info': {'datetime': 1511827200,
'status': 2,
'id': 1000000161,
'fakeid': '2393828411',
'content': '',
'type': 49}}
comm_msg_info.datetime,app_msg_ext_info中的欄位資訊就是第一篇文章的欄位資訊,分別對應:
- title:文章標題
- content_url:文章鏈接
- source_url:原文鏈接,有可能為空
- digest:摘要
- cover:封面圖
- datetime:推送時間
后面幾篇文章以串列的形式保存在 multi_app_msg_item_list 欄位中,
到此,公眾號文章的基本資訊就抓到了,但也僅僅只是公眾號的前10條推送,
資源來源于網路,純屬分享,不做商業用途,如若侵犯了您的權益和利益,請告知洗掉,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/304766.html
標籤:python