前前后后,小孟已經幫助很多的小伙伴挺近了大廠,
1,專科的粉絲拿到了阿里的offer,小孟直呼不可思議
2,??專科出身拿到阿里offer,小孟直呼666!【付硬核面試】??
3,大三下學期掛科,大四奮發圖強,拿到阿里offer???????
我是農村出來的娃,從程式員到專案主管到產品經理,到現在公司出任CEO!技術改變了我的命運,
我身邊越來越多的朋友,從農村出來到現在在大城市安身立命,甚至在一線城市買車買房,有的已經成為大廠的Leader,年薪200w+,
所以關注我,不迷路,小孟擁有極光的互聯網關系,可以找我內推各個大廠,
極度的說明了,只要努力,一切皆有可能!
技術改變世界,知識改變命運!
兄弟們,雞湯已經喝完了,讓我們開干!

前面已經分享了很多的面試題和專案:
前面的話,已經分享了SpringBoot的相關知識,例如:
1,Java基礎大全,幫你省去2w的培訓費
2,SpringBoot一天快速入門,超級肝貨!【一】
3,SpringBoot一天快速入門,超級肝貨!【二】
4,SpringBoot與分布式
5,肝完了,總結了SpringBoot與快取的知識點,快速掌握
6,一天掌握資料結構和演算法面試題,吊打面試官
7,整理了一周的Spring面試大全【含答案】
8,三天肝完設計模式的面試題,面試再不怕設計模式的問題了???????
9,Mysql面試大全???????
10,演算法學習大全
當然也分享了很多的SpringBoot的專案,這些專案真的很肝!
1,基于springboot的在線教育系統分享
2,基于springboot的活動管理小程式系統分享
3,基于springcloud的微服務專案分享【視頻教程+原始碼】
4,擼完這個springboot專案,我對boot輕車熟路【視頻教程+原始碼】
今天復習Redis面試,Redis作為快取系統,面試基本是常問的,因此必須要搞,

目錄
1,什么是Redis
2,Redis和Memecache有什么區別?
3,Redis和Mysql的區別:
4,為什么要用reids,不用不行嗎?
5,Redis為什么是單執行緒的?單執行緒可以處理高并發嗎?
6,為什么Redis 6.0 之后改多執行緒呢?
7,Redis的五種型別有那些?
8,Redis常見的功能有哪些?
9,Redis的優缺點有哪些
10,說說快取穿透,快取雪崩以及快取擊穿?
11,說一下Redis的持久化機制,
12,MySQL 里有 1000w 資料,redis 中只存 10w 的資料,如何保證 redis 中的資料都 是熱點資料?
13,說下Redis的淘汰策略?
14,請講一下Redis的應用場景?
15,如何實作Redis的高可用?
1,什么是Redis
簡單來說 redis 就是一個資料庫,不過與傳統資料庫不同的是 redis 的資料是存在記憶體中的,所以存寫速度非常快,因此 redis 被廣泛應用于快取方向,
另外,redis 也經常用來做分布式鎖,redis 提供了多種資料型別來支持不同的業務場景,除此之外,redis 支持事務 、持久化、LUA腳本、LRU驅動事件、多種集群方案,
最主要的Redis就是快取應用!
2,Redis和Memecache有什么區別?
對于 redis 和 Memecache的區別有下面四點,
a.redis支持更豐富的資料型別(支持更復雜的應用場景):Redis不僅僅支持簡單的k/v型別的資料,同時還提供list,set,zset,hash等資料結構的存盤,memcache支持簡單的資料型別,String,
b.Redis支持資料的持久化,可以將記憶體中的資料保持在磁盤中,重啟的時候可以再次加載進行使用,而Memecache把資料全部存在記憶體之中,
c.集群模式:memcached沒有原生的集群模式,需要依靠客戶端來實作往集群中分片寫入資料;但是 redis 目前是原生支持 cluster 模式的,
d.Memcached是多執行緒,非阻塞IO復用的網路模型;Redis使用單執行緒的多路 IO 復用模型,
3,Redis和Mysql的區別:
redis: 記憶體型非關系資料庫,資料保存在記憶體中,速度快
mysql:關系型資料庫,資料保存在磁盤中,檢索的話,會有一定的Io操作,訪問速度相對慢
4,為什么要用reids,不用不行嗎?
主要從“高性能”和“高并發”這兩點來看待這個問題,在這兩種情況下Redis非常的快,
首先看一下高性能:
假如用戶第一次訪問資料庫中的某些資料,這個程序會比較慢,因為是從硬碟上讀取的,將該用戶訪問的資料存在數快取中,這樣下一次再訪問這些資料的時候就可以直接從快取中獲取了,操作快取就是直接操作記憶體,所以速度相當快,如果資料庫中的對應資料改變的之后,同步改變快取中相應的資料即可!
最重要的就是在高并發的時候,Redis非常的快,
直接操作快取能夠承受的請求是遠遠大于直接訪問資料庫的,所以我們可以考慮把資料庫中的部分資料轉移到快取中去,這樣用戶的一部分請求會直接到快取這里而不用經過資料庫,
那么Redis為啥這么快呢?聽小孟道來,
如果簡單的解釋就是:
首先,采用了多路復用io阻塞機制然后,資料結構簡單,操作節省時間,并且,Redis自身的事件處理模型將epoll中的連接、讀寫、關閉都轉換為事件,不在網路I/O上浪費過多的時間,最后,運行在記憶體中,Redis直接自己構建了VM機制 ,不會像一般的系統會呼叫系統函式處理,自然速度快,
5,Redis為什么是單執行緒的?單執行緒可以處理高并發嗎?
Redis的瓶頸不是cpu的運行速度,而往往是網路帶寬和機器的記憶體大小,再說了,單執行緒切換開銷小,容易實作既然單執行緒容易實作,而且CPU不會成為瓶頸,那就順理成章地采用單執行緒的方案了,
當然可以處理高并發,Redis不就實作了嗎?
6,為什么Redis 6.0 之后改多執行緒呢?
上面說了Redis是單執行緒的,Redis6.0之前Redis都是單執行緒的,就是處理客戶端的資料時,讀寫都由一個順序串行的主執行緒處理,
redis使用多執行緒并非是完全摒棄單執行緒,redis還是使用單執行緒模型來處理客戶端的請求,只是使用多執行緒來處理資料的讀寫和協議決議,執行命令還是使用單執行緒,
這樣做的目的是因為redis的性能瓶頸在于網路IO而非CPU,使用多執行緒能提升IO讀寫的效率,從而整體提高redis的性能,
它的執行命令操作記憶體的仍然是個單執行緒,

7,Redis的五種型別有那些?
String 整數,浮點數或者字串,使?場景:快取、計數器、共享 Session、限速,
Set 集合,通常用在興趣標簽之類的,
Zset 有序集合,通常用在排行榜之類的,
Hash 散串列,哈希結構相對于字串序列化快取資訊更加直觀,并且在更新操作上更加便捷,哈希結構相對于字串序列化快取資訊更加直觀,并且在更新操作上更加便捷,
List 串列,在 Redis 中,可以隊串列兩端插?和彈出,還可以獲取指定范圍的元素串列、獲取指定索引下的元素等,串列是?種?較靈活的資料結構,它可以充當堆疊和佇列的??,
Set用的比較多,redis的埠號通常是6379:
127.0.0.1:6379> set key1 xiaomeng1
OK
127.0.0.1:6379> set key2 xiaomeng2
OK
127.0.0.1:6379> set key3 xiaomeng3
OK
127.0.0.1:6379> set key4 xiaomeng4
OK
127.0.0.1:6379> set key5 xiaomeng5
OK
127.0.0.1:6379> set key6 xiaomeng6
OK除此之外,還有三種特殊的資料型別:
Geo:Redis3.2推出的,地理位置定位,用于存盤地理位置資訊,并對存盤的資訊進行操作,
HyperLogLog:用來做基數統計演算法的資料結構,
Bitmaps :用一個位元位來映射某個元素的狀態,在Redis中,它的底層是基于字串型別實作的,可以把bitmaps成作一個以位元位為單位的陣列,
8,Redis常見的功能有哪些?
1. 資料快取功能
2. 分布式鎖的功能
3. ?持資料持久化
4. ?持事務
5. ?持訊息佇列
9,Redis的優缺點有哪些
優點:
上面已經了列舉了Redis的很多優點:
1,讀寫非常的快,提高網站的訪問速度,Redis能讀的速度是110000次/s,寫的速度是81000次/s,強悍的一比,
2,持AOF和RDB兩種持久化方式,
3,支持較多的資料結構型別,有String、hash、set、zset等等,
4,支持主從復制,主機可以自動的將資料同步到從機,從而進行讀寫分離,
5,支持AOF和RDB的持久化方式,
缺點:
任何的事物有優點,必然有缺點,Redis也不例外,
Redis 不具備自動容錯和恢復功能,主機從機的宕機都會導致前端部分讀寫請求失敗,需要等待機器重啟或者手動切換前端的IP才能恢復,
Redis 較難支持在線擴容,在集群容量達到上限時在線擴容會變得很復雜,為避免這一問題,運維人員在系統上線時必須確保有足夠的空間,這對資源造成了很大的浪費,
10,說說快取穿透,快取雪崩以及快取擊穿?
A,快取穿透:快取穿透是指查詢一條資料庫和快取都沒有的一條資料,就會一直查詢資料庫,對資料 庫的訪問壓力就會增大,快取穿透的解決方案,再換個說法就是客戶持續向服務器發起對不存在服務器中資料的請求,客戶先在Redis中查詢,查詢不到后去資料庫中查詢,
快取穿透的如何避免:
- 快取空物件:如果?個查詢回傳的資料為空(不管是資料不存在,還是系統故障),我們仍然把這個空結果進?快取,但它的過期時間會很短,最?不超過五分鐘,
- 介面層增加校驗,對傳參進行個校驗,比如說我們的id是從1開始的,那么id<=0的直接攔截;
- 快取中取不到的資料,在資料庫中也沒有取到,這時可以將key-value對寫為key-null,這樣可以防止攻擊用戶反復用同一個id暴力攻擊
- 快取資料的過期時間設定隨機,防止同一時間大量資料過期現象發生,
- 如果快取資料庫是分布式部署,將熱點資料均勻分布在不同搞得快取資料庫中,
B,快取擊穿:就是一個很熱門的資料,突然失效,而此時大量請求到服務器資料庫中,
最好的辦法就是設定熱點資料永不過期,熱點資料快要過期時,異步執行緒去更新和設定過期時間,
此外還可以采用互斥鎖方案,
C,快取雪崩:概念上是大量資料同一時間失效,此刻無數的請求直接繞開快取,直 接請求資料庫,
造成快取雪崩的原因,有以下2種: reids宕機,可以通過構造redis集群解決! 大部分資料失效,可通過均勻設定過期時間解決,即讓過期時間相對離散一點,
11,說一下Redis的持久化機制,
Redis的持久化機制有RDB和AOF,
RDB把記憶體資料以快照的形式保存到磁盤上,其核心的配置:
save <seconds> <changes>
# save ""
save 900 1
save 300 10
save 60 10000可以進行備份和全量復制,但是無法做到實時的持久化,適合大規模的資料恢復,
RDB做不到實時的持久化,但AOF可以,采用日志的形式來記錄每個寫操作,追加到檔案中,通過重啟執行AOF來恢復資料,
Redis默認是把AOF關閉的,我們可以把它打開,no改為yes
appendonly yes
AOF資料的完整性和一致性更高,
但是,因為AOF記錄的內容多,檔案會越來越大,資料恢復也會越來越慢,
基于以上分析,若只打算用Redis 做快取,可以關閉持久化,
若打算使用Redis 的持久化,建議RDB和AOF都開啟,其實RDB更適合做資料的備份,留一后手,AOF出問題了,還有RDB,所以還是要根據不同的需求,去做不同的操作,
12,MySQL 里有 1000w 資料,redis 中只存 10w 的資料,如何保證 redis 中的資料都 是熱點資料?
redis 記憶體資料集大小上升到一定大小的時候,就會施行資料淘汰策略,其實面試除了考察 Redis,大廠對于底層、分布式、微服務考察很多!
13,說下Redis的淘汰策略?
Redis的淘汰策略有8種,分別為:noeviction,volatile-lru,volatile-lfu,volatile-ttl,volatile-random,allkeylru,allkeys-lfu,allkeys-random
14,請講一下Redis的應用場景?
我們都知道Redis最主要的就是快取,在網站中應用最廣泛,可以很明顯的提高訪問的速度,減少資料庫的壓力!和memcached相比,redis更加的強悍,因為提供了豐富的資料結構,還提供了RDB和AOF等持久化機制,通常運用在如下場景:
15,如何實作Redis的高可用?
一般有三種模式,分別為主從模式(Replication-Sentinel模式)、哨兵模式、集群模式,
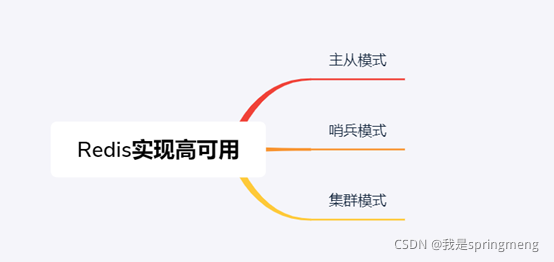
主從模式:
主從模式是部署多臺服務器,有主節點和從節點,主節點負責讀寫,從節點負責讀,
首先是master和slave的連接,然后會將自身的資料復制給slave,
如果maser和slave斷開連接后重新連接,只獲取在斷開連接期間內丟失的命令流,
如果無法同步,slave 會請求進行全量重同步,
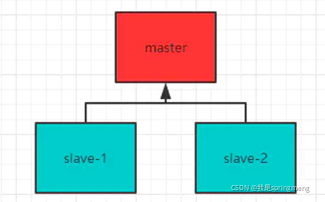
Redis Sentinel(哨兵):
哨兵是社區版本推出的原生高可用解決方案,為什么要提供哨兵?
在主從模式中,主節點發什么問題時,需要人工的將從節點搞成主節點,非常的費事,而且通知應用方更新主節點的地址,更加的費事,哨兵就可以解決這個問題,
哨兵模式的搭建:
#配置埠
port 26379
#以守護行程模式啟動
daemonize yes
#日志檔案名
logfile "sentinel_26379.log"
#存放備份檔案以及日志等檔案的目錄
dir "/opt/redis/data"
#監控的IP 埠號 名稱 sentinel通過投票后認為mater宕機的數量,此處為至少2個
sentinel monitor mymaster 192.168.14.101 6379 2
#30秒ping不通主節點的資訊,主觀認為master宕機
sentinel down-after-milliseconds mymaster 30000
#故障轉移后重新主從復制,1表示串行,>1并行
sentinel parallel-syncs mymaster 1
#故障轉移開始,三分鐘內沒有完成,則認為轉移失敗
sentinel failover-timeout mymaster 180000哨兵模式的架構圖如下所示:
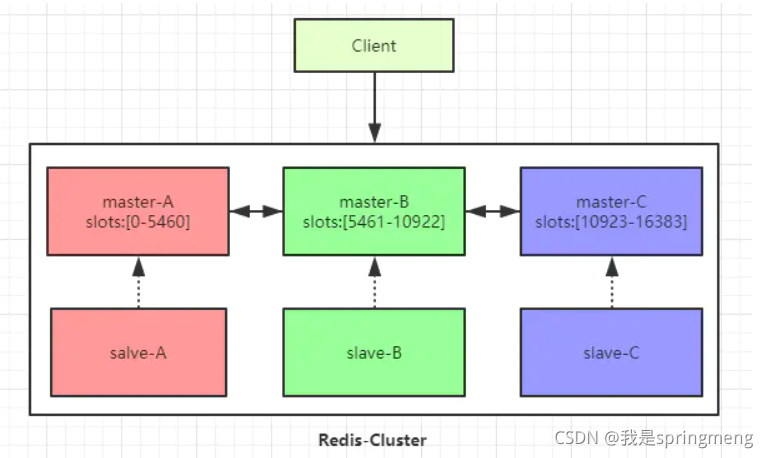
集群模式:
Redis 集群是一個提供在多個Redis節點間共享資料的程式集,對資料進行分片,也就是說每臺Redis節點上存盤不同的內容,來解決在線擴容的問題,哨兵模式基于主從模式,實作讀寫分離,它還可以自動切換,系統可用性更高,但是它每個節點存盤的資料是一樣的,浪費記憶體,并且不好在線擴容,
 ,
,
Redis Cluster有一個槽的概念,所有的鍵根據哈希函式映射到 0~16383 個整數槽內,每個節點負責維護一部分槽以及槽所映射的鍵值資料,可以直接自動跳轉到這個對應的節點上進行存取操作,
槽位的資訊存盤于每個節點中,只有master節點會被分配槽位,slave節點不會分配槽位,
參考文獻:
- http://www.redis.cn/
- 《Redis設計與實作》
為了幫助大家快速面試,整理了很多的面試干貨題和專案,
???????👇🏻 干貨可通過搜索下方 公眾號 獲取👇🏻
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305192.html
標籤:java