分布式ID
-
UUID,缺點:頁分裂占空間,
-
資料庫主鍵,缺點:改造復雜,多個庫主鍵會重復,
-
雪花演算法,性能好,缺點:時鐘回撥會重復,
?雪花演算法ID組成
-
符號位,占用1位,
-
時間戳,
-
機器ID,
-
序列號,12位,一毫秒生成4095個ID,
?分布式鎖應用場景
- 系統是一個分布式系統,集群,Java的鎖已經鎖不住,
?分布式鎖解決方案
基于Redis
setnx key value ex 10s,Redisson的lock和unlock方法,
洗掉鎖時,不是簡單的delete key,有一種情況是,我加鎖之后執行業務邏輯,設定鎖的過期時間是10s,程式執行了15s,最后的5s中,有另外的程式也可以來加鎖成功,我執行完邏輯后會洗掉其他程式的key,所以洗掉key之前先要get一下key,
上述情況,兩個程式都拿到鎖,可能造成資料不一致,所以要加一個看門狗機制,防止程式沒執行完就釋放鎖,
基于ZooKeeper
臨時節點,順序節點,
?Redis分布式死鎖如何解決
-
加鎖需釋放鎖,
-
key的過期機制,
?Redis如何做分布式鎖
假設有倆服務A和B都希望獲得鎖,執行程序如下:
- 服務A為了獲得鎖,向Redis發起如下命令:
set productid:lock 0xx903001 nx ex 30000
其中,productid是業務主鍵,“0xx903001”是隨機值,保證全域唯一,
- 服務B為了獲得鎖,向Redis發起同樣的命令:
set productid:lock 0000111 nx ex 30000
由于Redis內已經存在同名key,服務B進入回圈請求狀態,直到獲取鎖,
- 服務A業務代碼執行時長超過30s,key被洗掉,此時服務B執行,假設本次請求設定的value值為0000222,此時需要在服務A中對key進行續期,
4.服務A執行完畢,會釋放鎖,在洗掉key之前一定要判斷自己的value與Redis的value是否一致,此外,洗掉鎖涉及一系列邏輯,所以一般使用lua腳本,
?基于Zookeeper的分布式鎖
?Zookeeper和Redis做分布式鎖的區別
1.Redis只保證最終一致性,副本間的資料復制是異步進行,主從切換之后,可能有部分資料沒有復制過去,會丟失鎖,所以強一致性場景應該用zk,
2.使用zk集群的鎖原理是使用zk的臨時順序節點,每次進行鎖操作都要創建若干節點,完成后要釋放節點,效率沒有Redis高,
?滑動時間視窗演算法是什么?
? 為了解決計數器演算法的臨界值的問題,發明了滑動視窗演算法,在TCP網路通信協議中,就采用滑動時間視窗演算法來解決網路擁堵問題,
? 滑動時間視窗是將計數器演算法中的實際周期切分成多個小的時間視窗,分別在每個小的時間視窗中記錄訪問次數,然后根據時間將視窗往前滑動并洗掉過期的小時間視窗,最終只需要統計滑動視窗范圍內的小時間視窗的總的請求數即可,
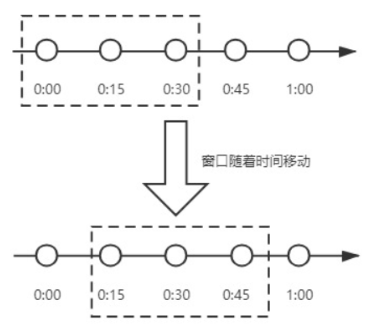
在上圖中,假設我們設定一分鐘的請求閾值是100,我們將一分鐘拆分成4個小時間視窗,這樣,每個小的時間視窗只能處理25個請求,我們用虛線方框表示滑動時間視窗,當前視窗的大小是2,也就是在視窗內最多能處理50個請求,隨著時間的推移,滑動視窗也隨著時間往前移動,比如上圖開始時,視窗是0:00到0:30的這個范圍,過了15秒后,視窗是0:15到0:45的這個范圍,視窗中的請求重新清零,這樣就很好的解決了計數器演算法的臨界值問題,
? 在滑動時間視窗演算法中,我們的小視窗劃分的越多,滑動視窗的滾動就越平滑,限流的統計就會越精確,
漏桶限流演算法是什么?
? 漏桶演算法的原理就像它的名字一樣,我們維持一個漏斗,它有恒定的流出速度,不管水流流入的速度有多快,漏斗出水的速度始終保持不變,類似于訊息中間件,不管訊息的生產者請求量有多大,訊息的處理能力取決于消費者,
? 漏桶的容量=漏桶的流出速度*可接受的等待時長,在這個容量范圍內的請求可以排隊等待系統的處理,超過這個容量的請求,才會被拋棄,
? 在漏桶限流演算法中,存在下面幾種情況:
-
當請求速度大于漏桶的流出速度時,也就是請求量大于當前服務所能處理的最大極限值時,觸發限流策略,
-
請求速度小于或等于漏桶的流出速度時,也就是服務的處理能力大于或等于請求量時,正常執行,
漏桶演算法有一個缺點:當系統在短時間內有突發的大流量時,漏桶演算法處理不了,
令牌桶限流演算法是什么?
? 令牌桶演算法,是增加一個大小固定的容器,也就是令牌桶,系統以恒定的速率向令牌桶中放入令牌,如果有客戶端來請求,先需要從令牌桶中拿一個令牌,拿到令牌,才有資格訪問系統,這時令牌桶中少一個令牌,當令牌桶滿的時候,再向令牌桶生成令牌時,令牌會被拋棄,
? 在令牌桶演算法中,存在以下幾種情況:
-
請求速度大于令牌的生成速度:那么令牌桶中的令牌會被取完,后續再進來的請求,由于拿不到令牌,會被限流,
-
請求速度等于令牌的生成速度:那么此時系統處于平穩狀態,
-
請求速度小于令牌的生成速度:那么此時系統的訪問量遠遠低于系統的并發能力,請求可以被正常處理,
令牌桶演算法,由于有一個桶的存在,可以處理短時間大流量的場景,這是令牌桶和漏桶的一個區別,
你設計微服務時遵循什么原則?
- 單一職責原則:讓每個服務能獨立,有界限的作業,每個服務只關注自己的業務,做到高內聚,
- 服務自治原則:每個服務要能做到獨立開發、獨立測驗、獨立構建、獨立部署,獨立運行,與其他服務進行解耦,
- 輕量級通信原則:讓每個服務之間的呼叫是輕量級,并且能夠跨平臺、跨語言,比如采用RESTful風格,利用訊息佇列進行通信等,
- 粒度進化原則:對每個服務的粒度把控,其實沒有統一的標準,這個得結合我們解決的具體業務問題,不要過度設計,服務的粒度隨著業務和用戶的發展而發展,
? 總結一句話,軟體是為業務服務的,好的系統不是設計出來的,而是進化出來的,
CAP定理是什么?
? CAP定理,又叫布魯爾定理,指的是:在一個分布式系統中,最多只能同時滿足一致性(Consistency)、可用性(Availability)和磁區容錯性(Partition tolerance)這三項中的兩項,
-
C:一致性(Consistency),資料在多個副本中保持一致,可以理解成兩個用戶訪問兩個系統A和B,當A系統資料有變化時,及時同步給B系統,讓兩個用戶看到的資料是一致的,
-
A:可用性(Availability),系統對外提供服務必須一直處于可用狀態,在任何故障下,客戶端都能在合理時間內獲得服務端非錯誤的回應,
-
P:磁區容錯性(Partition tolerance),在分布式系統中遇到任何網路磁區故障,系統仍然能對外提供服務,網路磁區,可以這樣理解,在分布式系統中,不同的節點分布在不同的子網路中,有可能子網路中只有一個節點,在所有網路正常的情況下,由于某些原因導致這些子節點之間的網路出現故障,導致整個節點環境被切分成了不同的獨立區域,這就是網路磁區,
我們來詳細分析一下CAP,為什么只能滿足兩個,看下圖所示:
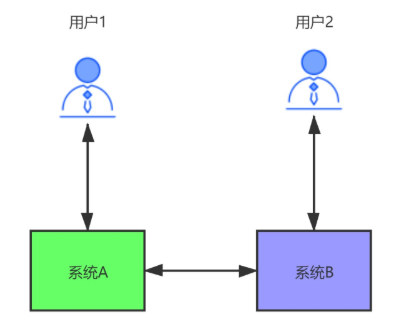
-
? 用戶1和用戶2分別訪問系統A和系統B,系統A和系統B通過網路進行同步資料,理想情況是:用戶1訪問系統A對資料進行修改,將data1改成了data2,同時用戶2訪問系統B,拿到的是data2資料,
? 但是實際中,由于分布式系統具有八大謬論:
-
網路相當可靠
-
延遲為零
-
傳輸帶寬是無限的
-
網路相當安全
-
拓撲結構不會改變
-
必須要有一名管理員
-
傳輸成本為零
-
網路同質化
我們知道,只要有網路呼叫,網路總是不可靠的,我們來一一分析,
- 當網路發生故障時,系統A和系統B沒法進行資料同步,也就是我們不滿足P,同時兩個系統依然可以訪問,那么此時其實相當于是單機系統,就不是分布式系統了,所以既然我們是分布式系統,P必須滿足,
- 當P滿足時,如果用戶1通過系統A對資料進行了修改將data1改成了data2,也要讓用戶2通過系統B正確的拿到data2,那么此時是滿足C,就必須等待網路將系統A和系統B的資料同步好,并且在同步期間,任何人不能訪問系統B(讓系統不可用),否則資料就不是一致的,此時滿足的是CP,
- 當P滿足時,如果用戶1通過系統A對資料進行了修改將data1改成了data2,也要讓系統B能繼續提供服務,那么此時,只能接受系統A沒有將data2同步給系統B(犧牲了一致性),此時滿足的就是AP,
-
? 我們在前面學過的注冊中心Eureka就是滿足 的AP,它并不保證C,而Zookeeper是保證CP,它不保證A,在生產中,A和C的選擇,沒有正確的答案,是取決于自己的業務的,比如12306,是滿足CP,因為買票必須滿足資料的一致性,不然一個座位多賣了,對鐵路運輸都是不可以接受的,
BASE理論是什么?
由于CAP中一致性C和可用性A無法兼得,eBay的架構師,提出了BASE理論,它是通過犧牲資料的強一致性,來獲得可用性,它由于如下3種特征:
-
Basically Available(基本可用):分布式系統在出現不可預知故障的時候,允許損失部分可用性,保證核心功能的可用,
-
Soft state(軟狀態):軟狀態也稱為弱狀態,和硬狀態相對,是指允許系統中的資料存在中間狀態,并認為該中間狀態的存在不會影響系統的整體可用性,即允許系統在不同節點的資料副本之間進行資料同步的程序存在延時,、
-
Eventually consistent(最終一致性):最終一致性強調的是系統中所有的資料副本,在經過一段時間的同步后,最終能夠達到一個一致的狀態,因此,最終一致性的本質是需要系統保證最終資料能夠達到一致,而不需要實時保證系統資料的強一致性,
? BASE理論并沒有要求資料的強一致性,而是允許資料在一定的時間段內是不一致的,但在最終某個狀態會達到一致,在生產環境中,很多公司,會采用BASE理論來實作資料的一致,因為產品的可用性相比強一致性來說,更加重要,比如在電商平臺中,當用戶對一個訂單發起支付時,往往會呼叫第三方支付平臺,比如支付寶支付或者微信支付,呼叫第三方成功后,第三方并不能及時通知我方系統,在第三方沒有通知我方系統的這段時間內,我們給用戶的訂單狀態顯示支付中,等到第三方回呼之后,我們再將狀態改成已支付,雖然訂單狀態在短期記憶體在不一致,但是用戶卻獲得了更好的產品體驗,
?雙寫一致性問題
先更新資料庫,再刪快取,再加上一個延遲雙刪即可,
(3)先更新資料庫,再刪快取
首先,先說一下,老外提出了一個快取更新套路,名為《Cache-Aside pattern》,其中就指出
- 失效:應用程式先從cache取資料,沒有得到,則從資料庫中取資料,成功后,放到快取中,
- 命中:應用程式從cache中取資料,取到后回傳,
- 更新:先把資料存到資料庫中,成功后,再讓快取失效,
另外,知名社交網站facebook也在論文《Scaling Memcache at Facebook》中提出,他們用的也是先更新資料庫,再刪快取的策略,
這種情況不存在并發問題么?
不是的,假設這會有兩個請求,一個請求A做查詢操作,一個請求B做更新操作,那么會有如下情形產生
(1)快取剛好失效
(2)請求A查詢資料庫,得一個舊值
(3)請求B將新值寫入資料庫
(4)請求B洗掉快取
(5)請求A將查到的舊值寫入快取
ok,如果發生上述情況,確實是會發生臟資料,
然而,發生這種情況的概率又有多少呢?
發生上述情況有一個先天性條件,就是步驟(3)的寫資料庫操作比步驟(2)的讀資料庫操作耗時更短,才有可能使得步驟(4)先于步驟(5),可是,大家想想,資料庫的讀操作的速度遠快于寫操作的(不然做讀寫分離干嘛,做讀寫分離的意義就是因為讀操作比較快,耗資源少),因此步驟(3)耗時比步驟(2)更短,這一情形很難出現,
假設,有人非要抬杠,有強迫癥,一定要解決怎么辦?
如何解決上述并發問題?
首先,給快取設有效時間是一種方案,其次,采用策略(2)里給出的異步延時洗掉策略,保證讀請求完成以后,再進行洗掉操作,
還有其他造成不一致的原因么?
有的,這也是快取更新策略(2)和快取更新策略(3)都存在的一個問題,如果刪快取失敗了怎么辦,那不是會有不一致的情況出現么,比如一個寫資料請求,然后寫入資料庫了,刪快取失敗了,這會就出現不一致的情況了,這也是快取更新策略(2)里留下的最后一個疑問,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305577.html
標籤:Java