
成長記不會介紹太對一些kafka的基礎知識,如果有需要的話,之后會有專門的《小白起步營》,成長記的默認大家對kafka的一些概念是熟知的、默認也是會基本Kafka的部署的,當然為了照顧一些小白,第一次涉及的知識我會簡單介紹和解釋的,熟悉的人就當回顧吧,簡單的事情重復做有時也是好事,
Kafka成長記會直接從三個方面開始探索,Producer、Broker、Comsumer,程序中,根據場景會使用之前ZK和JDK成長記介紹原始碼分析方法,話不多說,讓我們直接開始第一節的內容吧!
我們之前研究ZK主要是使用的場景法,找到一些核心入口開始分析的,研究Kafka的原始碼時候,我們也可以參考之前的方法,不過這次我們不直接從Broker服務端節點入手,先從Producer開始入手研究,會用到一些新的分析原始碼的思想和方法,
要想分析Kafka Producer的原始碼原理,首先肯定得有一個入口或者下手的地方,很多人使用Kafka肯定都是從一個Demo開始的,自己部署一臺Kafka,之后發送下訊息,之后在自己消費一條訊息,
KafkaProducerHelloWorld
所以我們就從最簡單的一個Kafka Producer的Demo開始,從一個KafkaProducerHelloWorld例子開始Kafka原始碼原理的探索,
HelloWorld的代碼如下:
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
/**
* @author fanmao
*/
public class KafkaProducerHelloWorld {
public static void main(String[] args) throws Exception {
//配置Kafka的一些引數
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.30.1:9092");
// 創建一個Producer實體
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 封裝一條訊息
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-key", "test-value");
// 同步方式發送訊息,會阻塞在這里,直到發送完成
// producer.send(record).get();
// 異步方式發送訊息,不阻塞,設定一個監聽回呼函式即可
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
System.out.println("訊息發送成功");
} else {
System.out.println("訊息發送例外");
}
}
});
Thread.sleep(5 * 1000);
// 退出producer
producer.close();
}
}
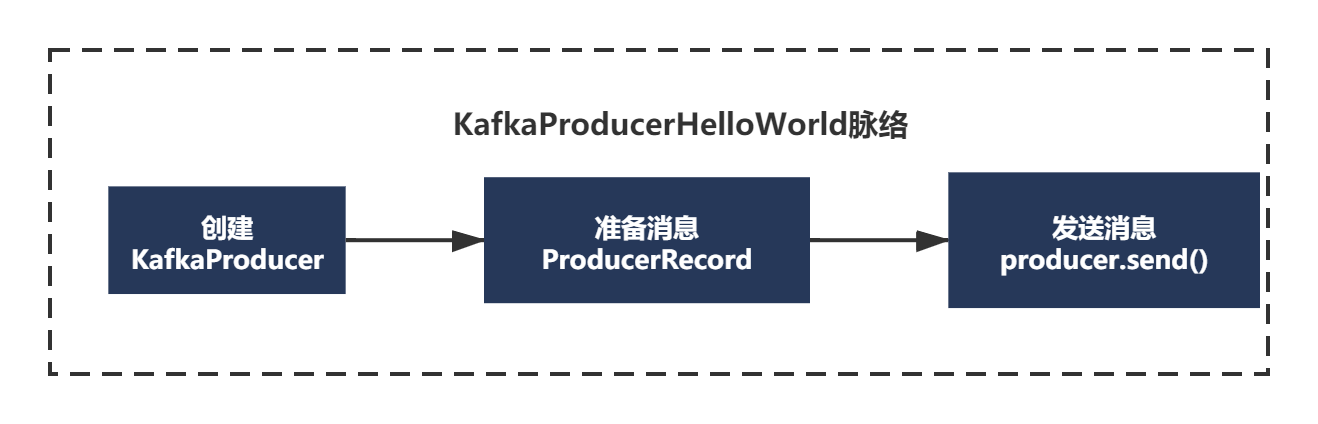
上面的代碼例子,雖然非常簡單,但是也有自己的脈絡,
1)創建KafkaProducer
2)準備訊息ProducerRecord
3)發送訊息producer.send()
簡單畫個圖:
這里多說一點,我之前在Zookeeper成長記5提到過原始碼版本的選擇和看原始碼的方式,這里我就不重復說了,直接將選擇后的結果告訴大家,我選擇的是kafka-0.10.0.1版本,
所以客戶端使用的依賴的GAV(Group-ArtifactId-Version) 是 org.apache.kafka-kafka-clients-0.10.0.1,POM如下所示:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.mfm.learn</groupId>
<artifactId>learn-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>learn-kafka</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.72</version>
</dependency>
</dependencies>
<build>
</build>
</project>
KafkaProducer的創建
上面KafkaProducerHelloWorld脈絡既然主要分了三步,那我們一步一步來看,首先就是KafkaProducer的創建,我們來一起看看它初始化什么東西?
這里問大家一個問題,這種構造方法的原始碼原理,一般分析的結果用什么方法會比較好?
沒錯,組件圖或者原始碼脈絡圖分析最容易理解了,我們只需要有個大致印象就行,方法有了,一般又會用什么思想呢?連蒙帶猜、看看注釋,猜測組件的作用,是不是?
好了讓我們來試試吧!
new KafkaProducer的代碼如下:
/**
* A producer is instantiated by providing a set of key-value pairs as configuration. Valid configuration strings
* are documented <a href="http://kafka.apache.org/documentation.html#producerconfigs">here</a>.
* @param properties The producer configs
*/
public KafkaProducer(Properties properties) {
this(new ProducerConfig(properties), null, null);
}
建構式中呼叫了一個多載的建構式,我們不著急往下看,先看下注釋,大體可以知道,這個建構式,入參是可以通過Properties設定一些引數,之后肯定是講這個引數轉換成了ProducerConfig物件進行封裝,肯定有一定的轉換方法,你還記得Zookeeper成長記中是不是也有類似的操作,封裝了一個QuorumPeerConfig物件,其實分析多了很多原始碼,你就逐漸有經驗了,更好的能駕輕就熟的分析任何一個原始碼原理了,這才是我想要讓大家學會的,而不是它如何決議,封裝成配置物件的,
我們接著分析,那么接下里就是兩條路了,看下多載的構造方法或者是 ProducerConfig是如何決議的,如下:
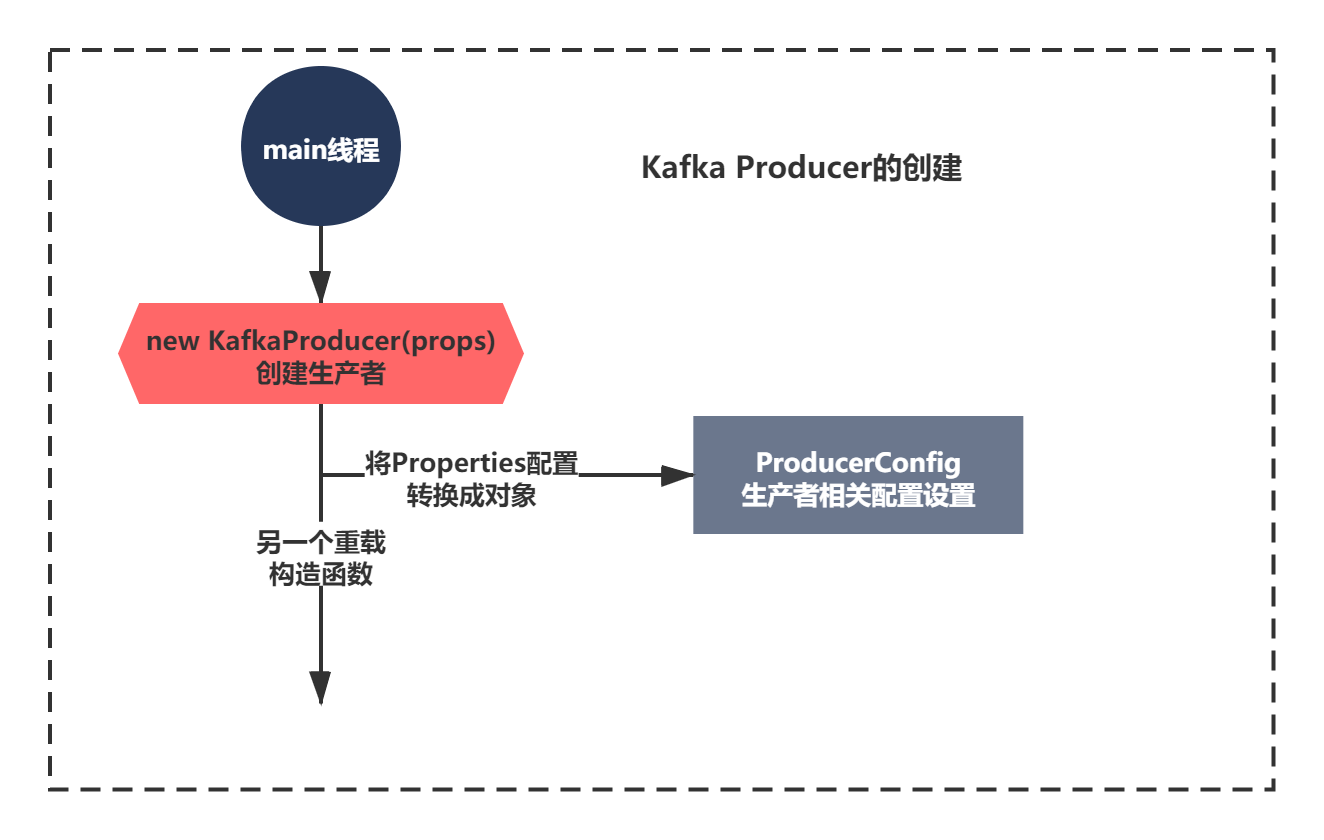
Kafka Producer 生產者的配置如何決議的?
這一節,我們就先來看看ProducerConfig是如何決議組態檔的,new ProducerConfig()的代碼如下:
/*
* NOTE: DO NOT CHANGE EITHER CONFIG STRINGS OR THEIR JAVA VARIABLE NAMES AS THESE ARE PART OF THE PUBLIC API AND
* CHANGE WILL BREAK USER CODE.
* 注意:請勿更改任何配置字串或它們的JAVA變數名,因為它們是公共API的一部分,更改將破壞用戶代碼,
*/
private static final ConfigDef CONFIG;
ProducerConfig(Map<?, ?> props) {
super(CONFIG, props);
}
這個建構式的脈絡,呼叫了一個super,竟然有一個父類,看起來比Zookeeper的配置決議封裝的多一些,不是簡單的一個QuorumPeerConfig,
而且有一個靜態變數 ConfigDef CONFIG,你肯定想知道它是個什么東西,
我們可以看下ConfigDef這個類的原始碼脈絡,看看能不能看出來什么:
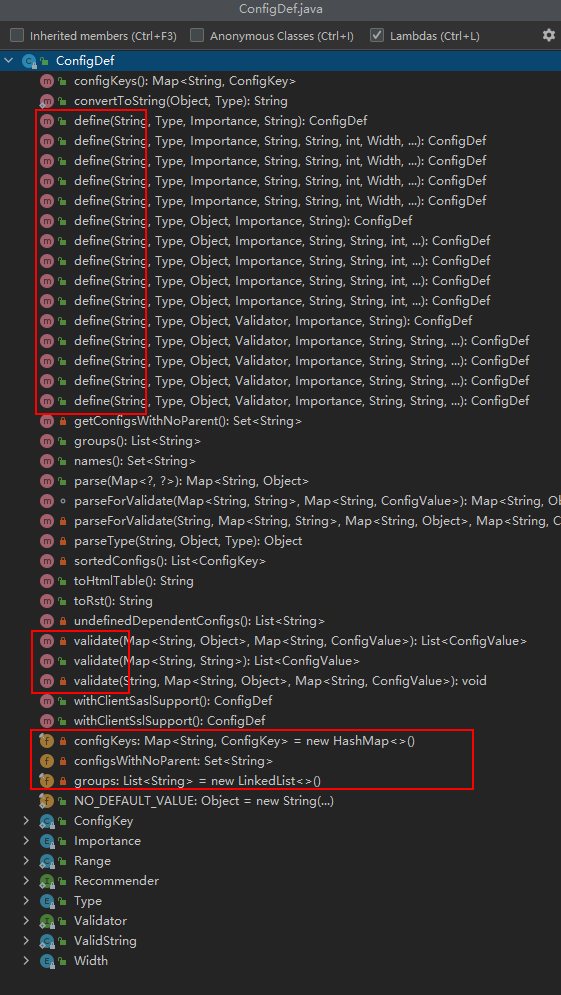
看著就是有一堆define方法、validate方法,關鍵幾個變數,比如一個Map configKeys啥的,好像感覺是放key-value配置的
比如key=bootstrap.servers , value192.168.30.:9092的,
實在猜不到,我們可以再看看ConfigDef這個類的注釋,
/**
/**
* This class is used for specifying the set of expected configurations. For each configuration, you can specify
* the name, the type, the default value, the documentation, the group information, the order in the group,
* the width of the configuration value and the name suitable for display in the UI.
* 此類用于指定期望的配置集,對于每種配置,您可以指定名稱,型別,默認值,檔案,組資訊,組中的順序,配置值的寬度和適合在UI中顯示的名稱,
*
* You can provide special validation logic used for single configuration validation by overriding {@link Validator}.
* 您可以通過覆寫{@link Validator}來提供用于單個配置驗證的特殊驗證邏輯,
*
* Moreover, you can specify the dependents of a configuration. The valid values and visibility of a configuration
* may change according to the values of other configurations. You can override {@link Recommender} to get valid
* values and set visibility of a configuration given the current configuration values.
* 此外,您可以指定配置的從屬,配置的有效值和可見性可能會根據其他配置的值而改變,您可以覆寫{@link Recommender}來獲得有效值,
* 并在給定當前配置值的情況下設定配置的可見性,
* 省略其他...
* This class can be used standalone or in combination with {@link AbstractConfig} which provides some additional
* functionality for accessing configs.
* 此類可以單獨使用,也可以與{@link AbstractConfig}結合使用,從而提供一些附加功能訪問配置的功能,
*/
通過上面的話,你應該就不難看出它的功能了,簡單的說就是封裝了key-value的配置,可以設定和校驗key-value,可以單獨使用用于訪問配置
知道了這個靜態變數的作用后,你點擊到ProducerConfig的super,進入父類的建構式:
public AbstractConfig(ConfigDef definition, Map<?, ?> originals, boolean doLog) {
/* check that all the keys are really strings */
for (Object key : originals.keySet())
if (!(key instanceof String))
throw new ConfigException(key.toString(), originals.get(key), "Key must be a string.");
this.originals = (Map<String, ?>) originals;
this.values = definition.parse(this.originals);
this.used = Collections.synchronizedSet(new HashSet<String>());
if (doLog)
logAll();
}
上面的代碼核心脈絡就一句話definition.parse(this.originals); 也就是執行了ConfigDef的parrse方法,
到這里,你想都不用想,這個方法就是轉換 Properties為ProducerConfig配置的方法了,如下圖所示:
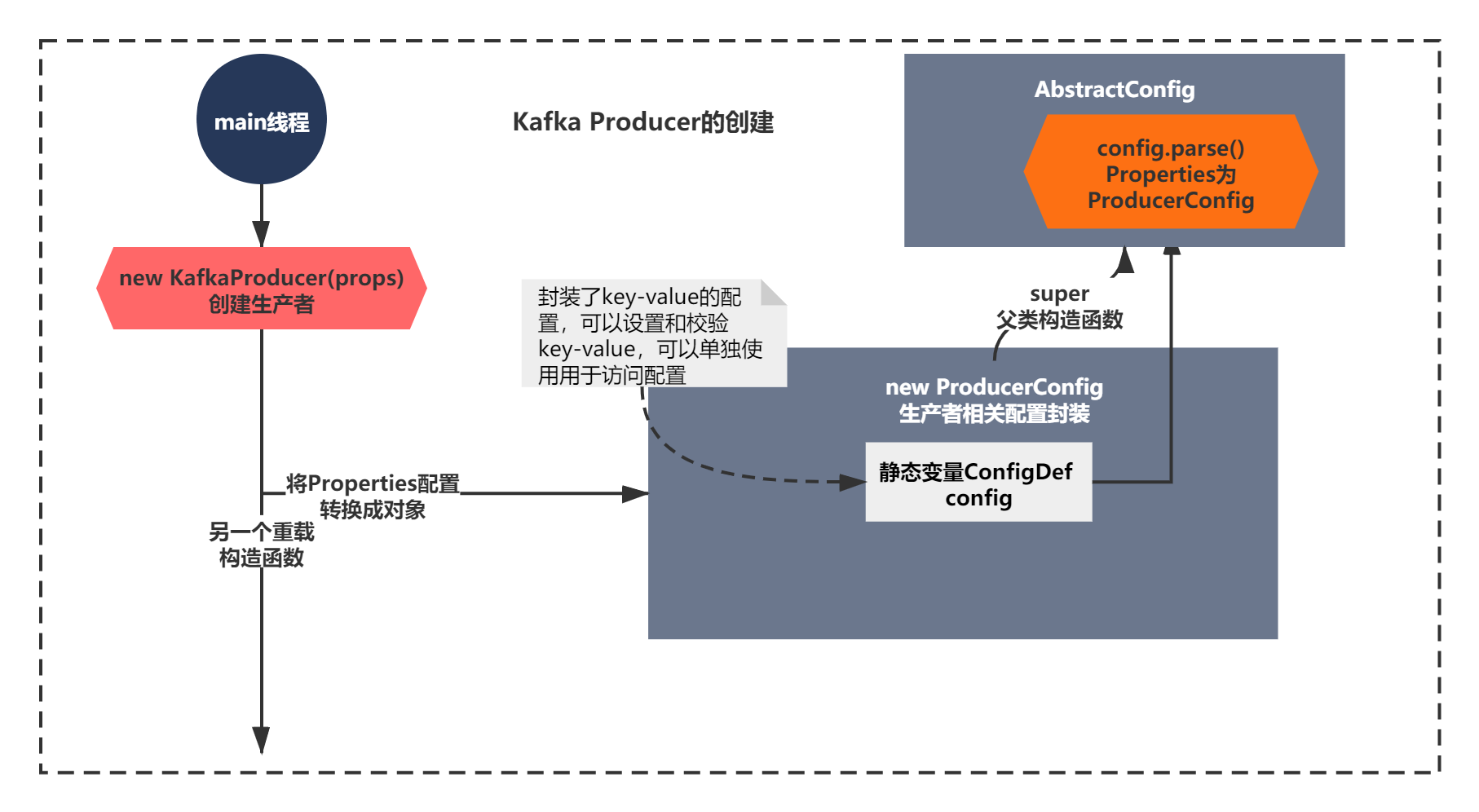
那么接下來簡單看下parse方法吧,代碼如下:
private final Map<String, ConfigKey> configKeys = new HashMap<>();
public Map<String, Object> parse(Map<?, ?> props) {
// Check all configurations are defined
List<String> undefinedConfigKeys = undefinedDependentConfigs();
if (!undefinedConfigKeys.isEmpty()) {
String joined = Utils.join(undefinedConfigKeys, ",");
throw new ConfigException("Some configurations in are referred in the dependents, but not defined: " + joined);
}
// parse all known keys
Map<String, Object> values = new HashMap<>();
for (ConfigKey key : configKeys.values()) {
Object value;
// props map contains setting - assign ConfigKey value
if (props.containsKey(key.name)) {
value = https://www.cnblogs.com/fanmao/archive/2021/10/05/parseType(key.name, props.get(key.name), key.type);
// props map doesn't contain setting, the key is required because no default value specified - its an error
} else if (key.defaultValue =https://www.cnblogs.com/fanmao/archive/2021/10/05/= NO_DEFAULT_VALUE) {
throw new ConfigException("Missing required configuration \"" + key.name + "\" which has no default value.");
} else {
// otherwise assign setting its default value
value = https://www.cnblogs.com/fanmao/archive/2021/10/05/key.defaultValue;
}
if (key.validator != null) {
key.validator.ensureValid(key.name, value);
}
values.put(key.name, value);
}
return values;
}
這段代碼直接看上去有點懵,沒關系,還是直接看的核心脈絡,
核心脈絡是一個for回圈,主要遍歷了Map<String, ConfigKey> configKey這個map,核心邏輯如下:
1)首先通過parseType確認value的型別, 之后根據ConfigKey定義的配置名稱,也就是key
2)最后將準備好的key-value配置,放入Map<String, Object> values中回傳給了AbstractConfig
這里我們就知道了最終我們配置的Producer引數,就會放入到AbstractConfig的一個Map<String,Object>中,而且Object說明配置的value是區分整數、字串之類的,比如
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.30.:9092");
就會如下圖所示:
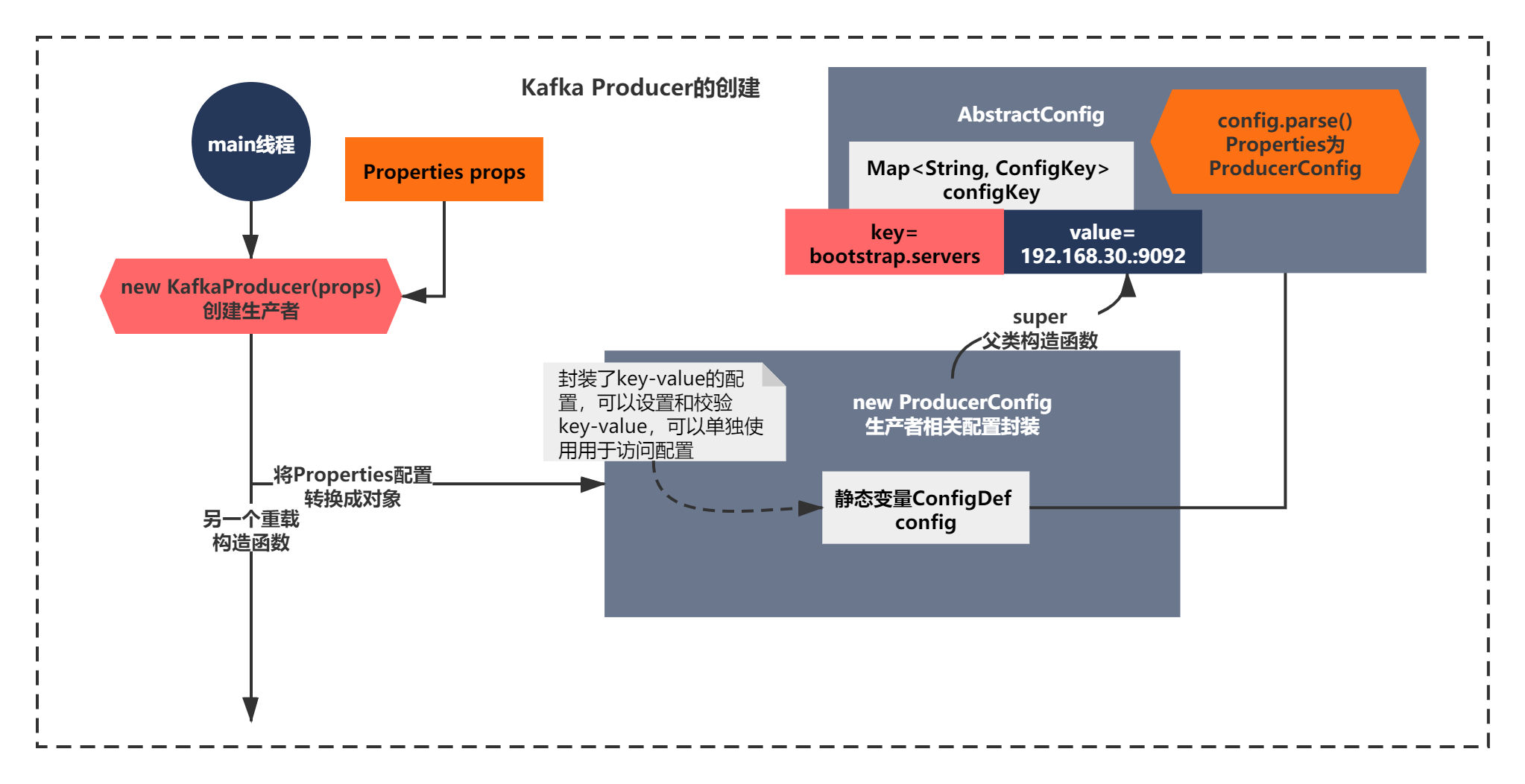
其實就是決議的Properties的整個程序了,你會發現其實也沒有多復雜,就是稍微比Zookeeper封裝的復雜點,
不過如果你細心的話,這里就有一個問題了, 上面parase方法的for回圈,回圈的Map<String, ConfigKey> configKey 是什么時候初始化的呢?
我們可以倒回去看看,
private static final ConfigDef CONFIG;
ProducerConfig(Map<?, ?> props) {
super(CONFIG, props);
}
還記得呼叫父類方法前,這個ConfigDef是子類傳遞給父類的,這個變數又是一個靜態的,要想初始化,肯定是有一段靜態初始化代碼在ProducerConfig中的,你可以找到如下的代碼:
/** <code>retries</code> */
public static final String RETRIES_CONFIG = "retries";
private static final String RETRIES_DOC = "Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error."
+ " Note that this retry is no different than if the client resent the record upon receiving the error."
+ " Allowing retries without setting <code>" + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION + "</code> to 1 will potentially change the"
+ " ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second"
+ " succeeds, then the records in the second batch may appear first.";
static {
CONFIG = new ConfigDef()
.define(BOOTSTRAP_SERVERS_CONFIG, Type.LIST, Importance.HIGH, CommonClientConfigs.BOOSTRAP_SERVERS_DOC)
.define(BUFFER_MEMORY_CONFIG, Type.LONG, 32 * 1024 * 1024L, atLeast(0L), Importance.HIGH, BUFFER_MEMORY_DOC)
.define(RETRIES_CONFIG, Type.INT, 0, between(0, Integer.MAX_VALUE), Importance.HIGH, RETRIES_DOC)
.define(ACKS_CONFIG,
Type.STRING,
"1",
in("all", "-1", "0", "1"),
Importance.HIGH,
ACKS_DOC)
.define(COMPRESSION_TYPE_CONFIG, Type.STRING, "none", Importance.HIGH, COMPRESSION_TYPE_DOC)
.define(BATCH_SIZE_CONFIG, Type.INT, 16384, atLeast(0), Importance.MEDIUM, BATCH_SIZE_DOC)
.define(TIMEOUT_CONFIG, Type.INT, 30 * 1000, atLeast(0), Importance.MEDIUM, TIMEOUT_DOC)
.define(LINGER_MS_CONFIG, Type.LONG, 0, atLeast(0L), Importance.MEDIUM, LINGER_MS_DOC)
.define(CLIENT_ID_CONFIG, Type.STRING, "", Importance.MEDIUM, CommonClientConfigs.CLIENT_ID_DOC)
.define(SEND_BUFFER_CONFIG, Type.INT, 128 * 1024, atLeast(0), Importance.MEDIUM,
// 省略其他define
.withClientSslSupport()
.withClientSaslSupport();
}
這個靜態方法的其實就是呼叫了define方法,初始化了Producer各個配置名稱、默認值還有檔案說明,最終封裝成一個map,value是ConfigKey,初始化了ConfigDef,
private final Map<String, ConfigKey> configKeys = new HashMap<>();
public static class ConfigKey {
public final String name;
public final Type type;
public final String documentation;
public final Object defaultValue;
public final Validator validator;
public final Importance importance;
public final String group;
public final int orderInGroup;
public final Width width;
public final String displayName;
public final List<String> dependents;
public final Recommender recommender;
}
這個程序雖然沒什么,但是重點就來了,默認值,也就說KafkaProducer的配置,默認值都是在這里初始化的,如果你想知道Producer的默認值,就可以看這里了,
這些引數之前公眾號的《Kafka入門系列》中都有詳細的介紹,我這里介紹了估計你也記不住,之后我們分析原始碼的時候你在慢慢理解吧,下面我摘錄了一些核心配置,供大家回憶下:
Producer核心引數:
metadata.max.age.ms 默認每隔5分鐘 會重繪下元資料
max.request.size 每個請求的最大大小(1mb)
buffer.memory 緩沖區的記憶體大小(32mb)
max.block.ms 緩沖區填滿之后或元資料拉取最大阻塞時間(60s)
request.timeout.ms 請求超時時間(30s)
batch.size 每個batch的大小默認(16kb)
linger.ms 默認為0,不延遲發送,
可以配置為10ms,10ms內還沒有湊成1個batch發送出去,必須立即發送出去
......
小結
好了今天我們就先分析到這里,下一節我們繼續分析Producer 的創建,通過組件圖和流程圖的方式看看配置決議之后,執行的多載建構式又做了那些事情呢?
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305584.html
標籤:其他