
上一節我們主要從HelloWorld開始,分析了Kafka Producer的創建,重點分析了如何決議生產者配置的原始碼原理,
public KafkaProducer(Properties properties) {
this(new ProducerConfig(properties), null, null);
}
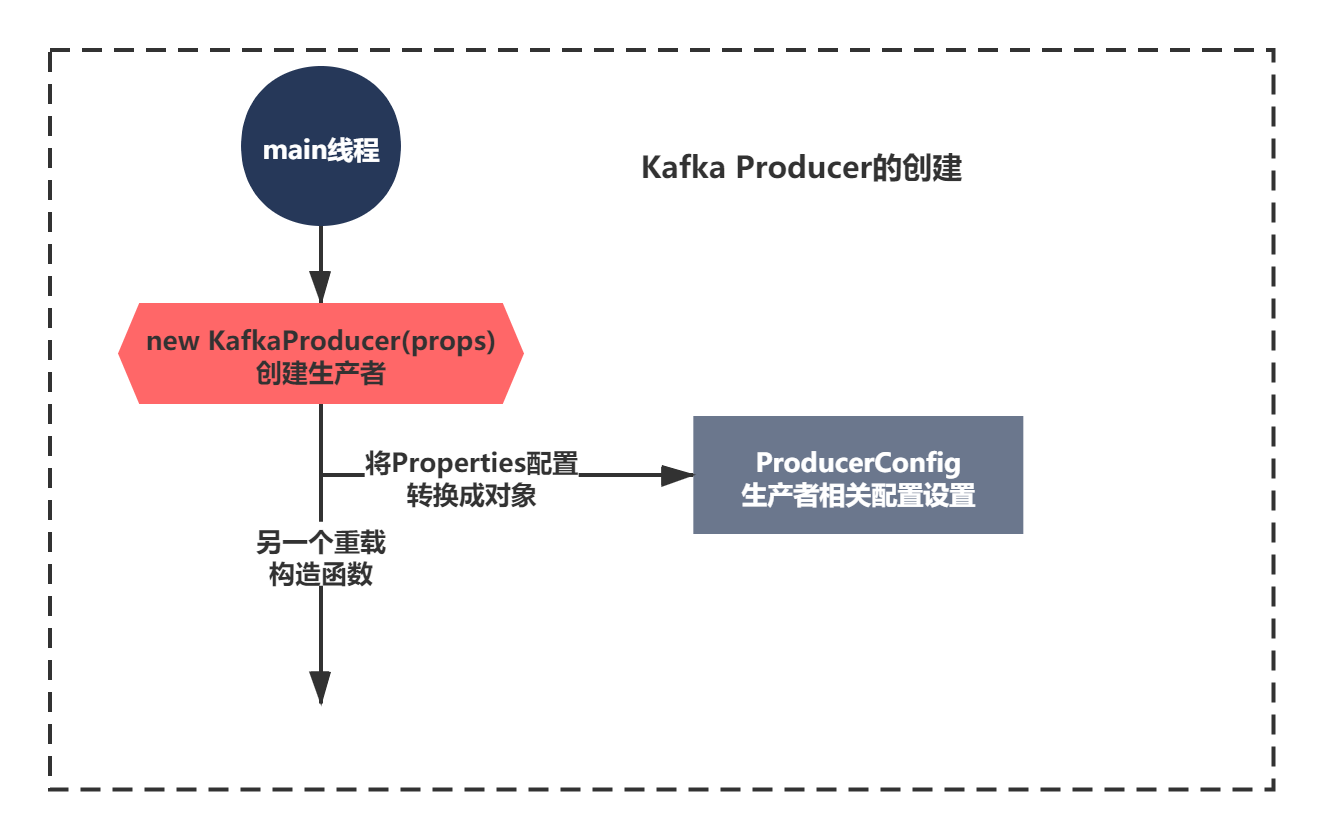
Kafka Producer的創建除了配置決議,還有關鍵的一步就是呼叫了一個多載的建構式,這一節我們就來看下它主要做了什么,
KafkaProducer初始化的哪些組件?
既然時一個關鍵組件創建,分析的建構式,我們首要做的就是分析它的代碼脈絡,看看核心的組件有哪些,畫一個組件圖先,
讓我們來看下建構式的代碼:
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
try {
log.trace("Starting the Kafka producer");
Map<String, Object> userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = new SystemTime();
clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
if (clientId.length() <= 0)
clientId = "producer-" + PRODUCER_CLIENT_ID_SEQUENCE.getAndIncrement();
Map<String, String> metricTags = new LinkedHashMap<String, String>();
metricTags.put("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.tags(metricTags);
List<MetricsReporter> reporters = config.getConfiguredInstances(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG,
MetricsReporter.class);
reporters.add(new JmxReporter(JMX_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time);
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
this.metadata = https://www.cnblogs.com/fanmao/archive/2021/10/06/new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG));
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
/* check for user defined settings.
* If the BLOCK_ON_BUFFER_FULL is set to true,we do not honor METADATA_FETCH_TIMEOUT_CONFIG.
* This should be removed with release 0.9 when the deprecated configs are removed.
*/
if (userProvidedConfigs.containsKey(ProducerConfig.BLOCK_ON_BUFFER_FULL_CONFIG)) {
log.warn(ProducerConfig.BLOCK_ON_BUFFER_FULL_CONFIG +" config is deprecated and will be removed soon. " +
"Please use " + ProducerConfig.MAX_BLOCK_MS_CONFIG);
boolean blockOnBufferFull = config.getBoolean(ProducerConfig.BLOCK_ON_BUFFER_FULL_CONFIG);
if (blockOnBufferFull) {
this.maxBlockTimeMs = Long.MAX_VALUE;
} else if (userProvidedConfigs.containsKey(ProducerConfig.METADATA_FETCH_TIMEOUT_CONFIG)) {
log.warn(ProducerConfig.METADATA_FETCH_TIMEOUT_CONFIG + " config is deprecated and will be removed soon. " +
"Please use " + ProducerConfig.MAX_BLOCK_MS_CONFIG);
this.maxBlockTimeMs = config.getLong(ProducerConfig.METADATA_FETCH_TIMEOUT_CONFIG);
} else {
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
}
} else if (userProvidedConfigs.containsKey(ProducerConfig.METADATA_FETCH_TIMEOUT_CONFIG)) {
log.warn(ProducerConfig.METADATA_FETCH_TIMEOUT_CONFIG + " config is deprecated and will be removed soon. " +
"Please use " + ProducerConfig.MAX_BLOCK_MS_CONFIG);
this.maxBlockTimeMs = config.getLong(ProducerConfig.METADATA_FETCH_TIMEOUT_CONFIG);
} else {
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
}
/* check for user defined settings.
* If the TIME_OUT config is set use that for request timeout.
* This should be removed with release 0.9
*/
if (userProvidedConfigs.containsKey(ProducerConfig.TIMEOUT_CONFIG)) {
log.warn(ProducerConfig.TIMEOUT_CONFIG + " config is deprecated and will be removed soon. Please use " +
ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
this.requestTimeoutMs = config.getInt(ProducerConfig.TIMEOUT_CONFIG);
} else {
this.requestTimeoutMs = config.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
}
this.accumulator = new RecordAccumulator(config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.totalMemorySize,
this.compressionType,
config.getLong(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
metrics,
time);
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
this.metadata.update(Cluster.bootstrap(addresses), time.milliseconds());
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config.values());
NetworkClient client = new NetworkClient(
new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), this.metrics, time, "producer", channelBuilder),
this.metadata,
clientId,
config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION),
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
config.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
this.requestTimeoutMs, time);
this.sender = new Sender(client,
this.metadata,
this.accumulator,
config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION) == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
(short) parseAcks(config.getString(ProducerConfig.ACKS_CONFIG)),
config.getInt(ProducerConfig.RETRIES_CONFIG),
this.metrics,
new SystemTime(),
clientId,
this.requestTimeoutMs);
String ioThreadName = "kafka-producer-network-thread" + (clientId.length() > 0 ? " | " + clientId : "");
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
this.errors = this.metrics.sensor("errors");
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
// load interceptors and make sure they get clientId
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
List<ProducerInterceptor<K, V>> interceptorList = (List) (new ProducerConfig(userProvidedConfigs)).getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptor.class);
this.interceptors = interceptorList.isEmpty() ? null : new ProducerInterceptors<>(interceptorList);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId);
log.debug("Kafka producer started");
} catch (Throwable t) {
// call close methods if internal objects are already constructed
// this is to prevent resource leak. see KAFKA-2121
close(0, TimeUnit.MILLISECONDS, true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t);
}
}
這個建構式的代碼還是比較都多的,不過沒關系,先掃一下它的脈絡:
1)主要是根據之前決議好的ProducerConfig物件,設定了一堆Producer的引數
2)new Metadata(),它應該算一個組件,從名字上猜測,應該是負責元資料相關的
3)new RecordAccumulator()應該也是一個組件,暫時不知道是啥意思,名字是翻譯下是記錄累加器
4)new NetworkClient()一看就是網路通信相關的組件
5)new Sender()和 new new KafkaThread() 應該是創建了Runnable,并且使用1個執行緒啟動,看著像是發送訊息的執行緒
6)new ProducerInterceptors() 貌似是攔截器相關的東西
你可以看到這個建構式,基本核心脈絡就是上面6點了,我們可以畫一個組件圖小結下:
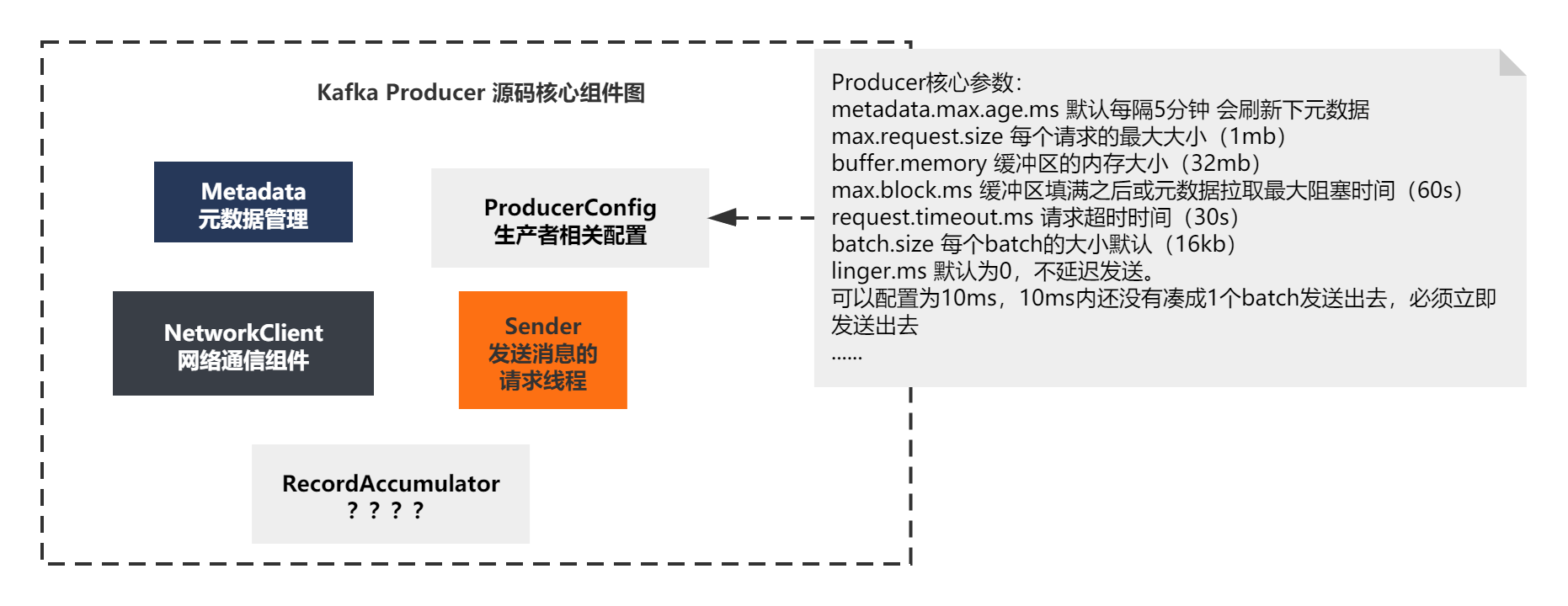
RecordAccumulator到底是什么?
知道了上面主要的組件主要有啥,RecordAccumulator這個類沒看出來是啥意思,怎么辦?看看有沒有類注釋,
/**
* This class acts as a queue that accumulates records into {@link org.apache.kafka.common.record.MemoryRecords}
* instances to be sent to the server.
* 這個類可以使用佇列記錄Records,準備待發送的資料給Server(也就是Broker)
* <p>
* The accumulator uses a bounded amount of memory and append calls will block when that memory is exhausted, unless
* this behavior is explicitly disabled.
* 當沒有被禁用時,累加器由于使用了有限的記憶體,達到上限會阻塞,
*/
public final class RecordAccumulator {
}
看過注釋后,大體知道RecordAccumulator,它是個記錄累加器,這個記錄Record其實可以看做是一條訊息的抽象封裝,也就是它是訊息累加器,通過一個記憶體佇列快取,做了一個緩沖,準備將這個資料發送給Broker,所以我們就可以稱他為發送訊息的記憶體緩沖器,
Metadata元資料到底是什么?
還有一個Metadata元資料這組件,有些人可能也不太清楚,元資料是指什么,元資料就是指描述資料,比如我mac或windows檔案的元資料,就是它的大小,位置,創建時間,修改時間等,
那KafkaProducer生產者的元資料是指什么呢?這里就要給大家回顧一個知識了:
Kafka知識回顧Tips:Topic、Partition、Record,Leader Partition、Follower Partition、Replica是什么?
這幾個是kafka管理訊息涉及的基本概念,
Topic:Kafka管理訊息的邏輯結構,Topic下可以有多個Partition,用作分布式存盤,用來支持海量資料,
Partition:多條訊息存盤結構封裝,對應到磁盤上的一個個log檔案,kafka把訊息存盤到磁盤的檔案通常稱作log,實際就是多條訊息而已,
Record:指每一條訊息的抽象封裝,
Broker通常有兩種角色,leader和follwer,為了高可用,follower是leader的副本,
Replica:副本,leader和follower的都可以算是存放訊息的一個副本,互為備份,所以replica可以指leader,也可以指follower,
回顧了這幾個基本知識,來理解元資料就好多了,
要想發送訊息給Broker,起碼得知道發送到哪里去,所以就需要描述資訊,這些描述資訊就是發送訊息需要的元資料,
Producer一般都需要從broker集群去拉取元資料,包括了Topic中的Partitions資訊,后面如果發送訊息到Topic,才知道這個Topic有哪些Partitions,哪些是Leader Partition所在的Broker,
組件圖最終如下所示:
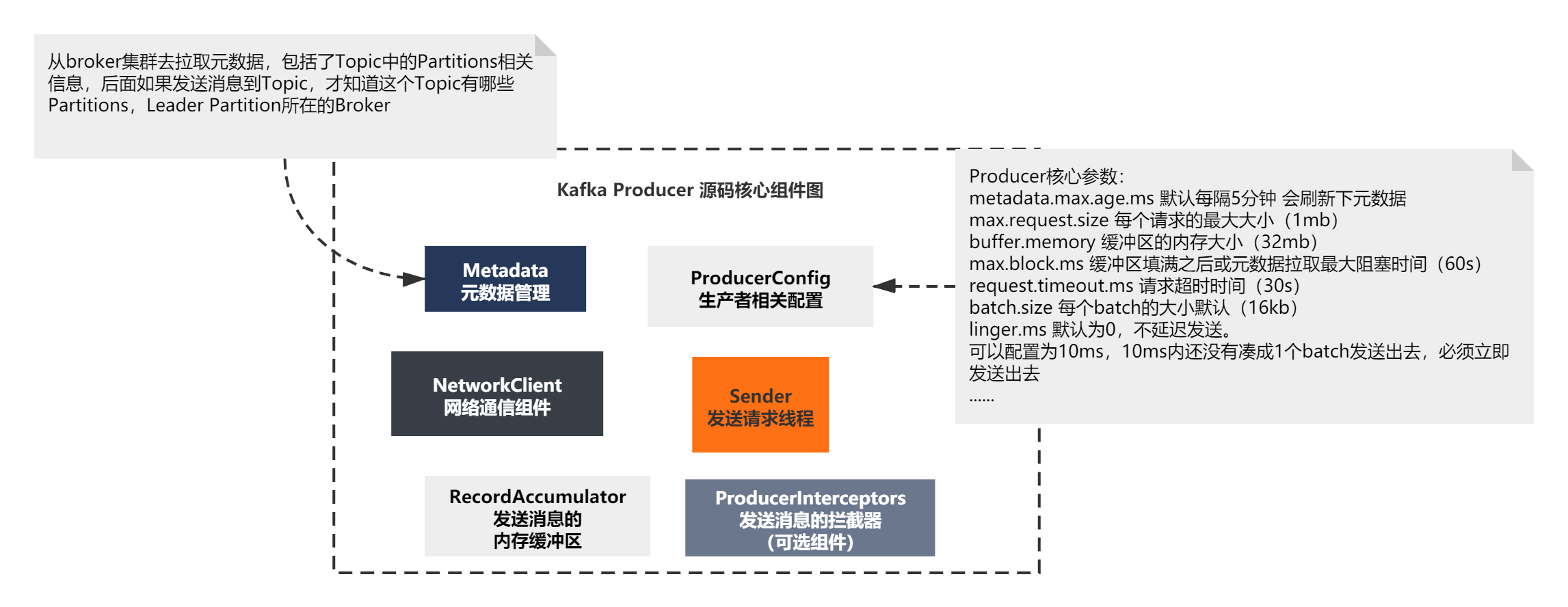
Producer核心組件—元資料Metadata剖析
既然我們知道了Producer主要初始化了上面的一些組件,那么只要搞懂上面每個組件做了什么,基本Producer的很多原理就能理解透徹了,
我們先來看下Metadata這個元資料組件做了什么,
首先Metadata的創建很簡單,如下:
/**
* Create a new Metadata instance
* @param refreshBackoffMs The minimum amount of time that must expire between metadata refreshes to avoid busy
* polling
* 元資料重繪之間必須終止的最短時間,以避免繁忙的輪詢
* @param metadataExpireMs The maximum amount of time that metadata can be retained without refresh
* 不重繪即可保留元資料的最長時間
*/
public Metadata(long refreshBackoffMs, long metadataExpireMs) {
this.refreshBackoffMs = refreshBackoffMs;
this.metadataExpireMs = metadataExpireMs;
this.lastRefreshMs = 0L;
this.lastSuccessfulRefreshMs = 0L;
this.version = 0;
this.cluster = Cluster.empty();
this.needUpdate = false;
this.topics = new HashSet<String>();
this.listeners = new ArrayList<>();
this.needMetadataForAllTopics = false;
}
這個建構式,從注釋就說明了,這個元資料物件Metadata會被定時重繪,也就是說,它應該會定時的從Broker拉取核心的元資料到Producer,
而它的脈絡就是
1)初始化了一些配置 ,根據名字和注釋基本都能從猜測出來含義
默認值就是在之前ConfigDef靜態變數初始化可以看到,
refreshBackoffMs 元資料重繪之間必須終止的最短時間,以避免繁忙的輪詢,默認100ms
metadataExpireMs ,默認是每隔5分鐘拉取一次元資料,
lastRefreshMs 最近拉取元資料的時間戳
lastSuccessfulRefreshMs 最近拉取元資料成功的時間戳
version 元資料拉取的版本
Cluster 這個比較關鍵,是元資料資訊的物件封裝
needUpdate 是否需要拉取標識
topics 記錄topic資訊的集合
listeners 元資料變更的監聽回呼
needMetadataForAllTopics 默認是一個false,暫時不知道是做什么的
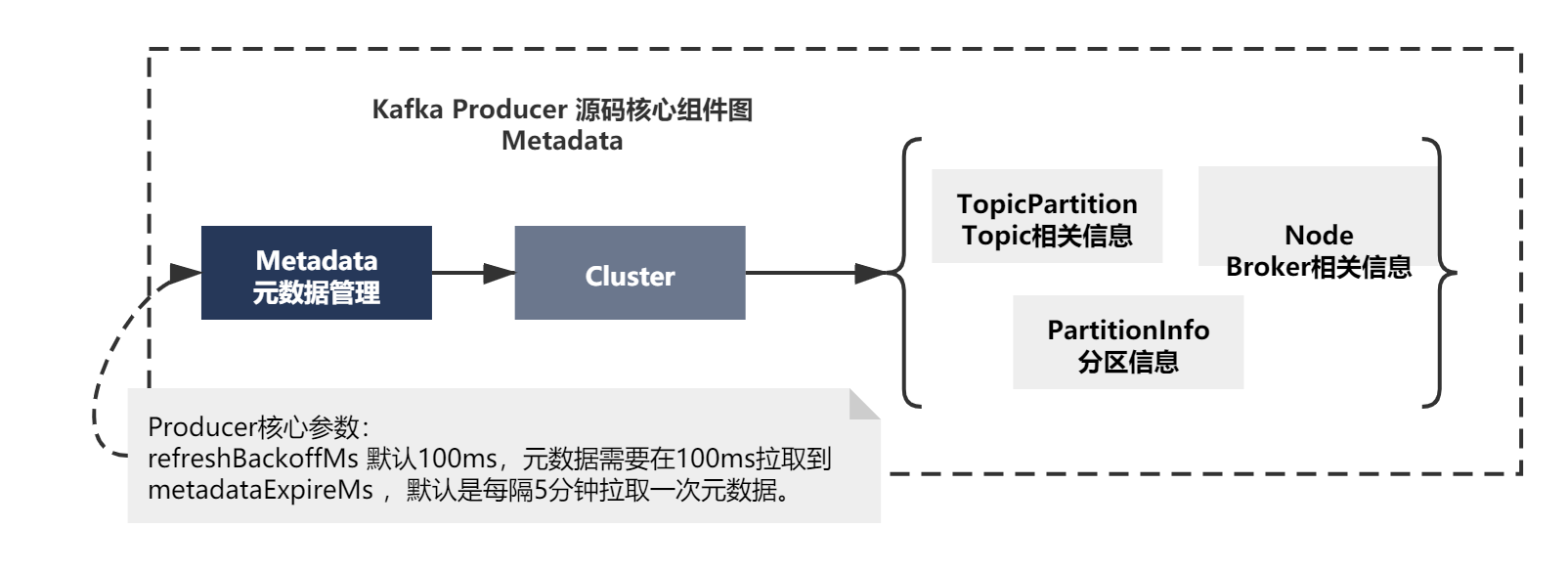
2)初始化Cluster元資料物件
上面變數中,元資料最終封裝存放在了Cluster物件中,可以看下它會放了什么資料:
/**
* A representation of a subset of the nodes, topics, and partitions in the Kafka cluster.
*/
public final class Cluster {
private final boolean isBootstrapConfigured;
//Kafka Broker節點
private final List<Node> nodes;
//沒有被授權訪問的Topic的串列
private final Set<String> unauthorizedTopics;
//TopicPartition:Topic和Partition基本關系資訊
//PartitionInfo:Partition的詳細資訊,比如資料同步進度ISR串列、Leader、Follower節點資訊等
private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition;
//每個topic有哪些磁區
private final Map<String, List<PartitionInfo>> partitionsByTopic;
//每個topic有哪些當前可用的磁區,如果某個磁區沒有leader是存活的,此時那個磁區就不可用了
private final Map<String, List<PartitionInfo>> availablePartitionsByTopic;
//每個broker上放了哪些磁區
private final Map<Integer, List<PartitionInfo>> partitionsByNode;
//broker.id -> Node
private final Map<Integer, Node> nodesById;
//省略初始化方法
}
主要就是組成了整個Kafka集群資訊,比如
Node:記錄了Kafka Broker的ip,埠等
TopicPartition:Topic和Partition基本關系資訊
PartitionInfo:Partition的詳細資訊,比如資料同步進度ISR串列、Leader、Follower節點資訊等
其他的上面我也用注釋基本都標注了他們的大致意思了,大家大體有一個印象就行,其實只要知道都是topic的元資料就行了,
上面的資訊你如果問我是怎么知道的,很簡單,我debug了下,當后面拉取到元資料后,你可以看下資料,就明白了,debug看原始碼的方法在這個場景就比較適合,我們目前也沒有下載原始碼,匯入原始碼,只需要寫一個helloWorld,通過maven自動下載jar包的原始碼,進行debug就可以分析客戶端的原始碼,
之前我提到的原始碼閱讀方法和思想,大家一定要活學活用,
所以元資料物件主要就是如下所示:
KafkaProducer創建Metadata其實并沒有多么復雜, 創建了之后做了什么呢?KafkaProducer的建構式,執行了一個metadata.update方法,
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
// 一些引數設定,省略...
this.metadata = https://www.cnblogs.com/fanmao/archive/2021/10/06/new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG));
// RecordAccumulator、NetworkClient、Sender等組件的初始化,省略...
this.metadata.update(Cluster.bootstrap(addresses), time.milliseconds());
//省略...
}
這個難道就在進行元資料拉取么?我們來看下這個update方法:
/**
* Update the cluster metadata
*/
public synchronized void update(Cluster cluster, long now) {
this.needUpdate = false;
this.lastRefreshMs = now;
this.lastSuccessfulRefreshMs = now;
this.version += 1;
for (Listener listener: listeners)
listener.onMetadataUpdate(cluster);
// Do this after notifying listeners as subscribed topics' list can be changed by listeners
this.cluster = this.needMetadataForAllTopics ? getClusterForCurrentTopics(cluster) : cluster;
notifyAll();
log.debug("Updated cluster metadata version {} to {}", this.version, this.cluster);
}
由于listeners之前初始化是空的,這個needMetadataForAllTopics引數也是false,之后直接呼叫了Metadata.notifyAll(),其實什么都沒干,沒有什么元資料拉取或者更新的操作,
最終發現,這個方法說明其實幾乎什么都沒有做,也就是說KafkaProducer創建的時候,沒有進行元資料拉取,只是初始化了一個Metadata物件,其中元資料物件Cluster的資訊默認是空的,
Metadata的整個程序的關鍵,如下圖所示:
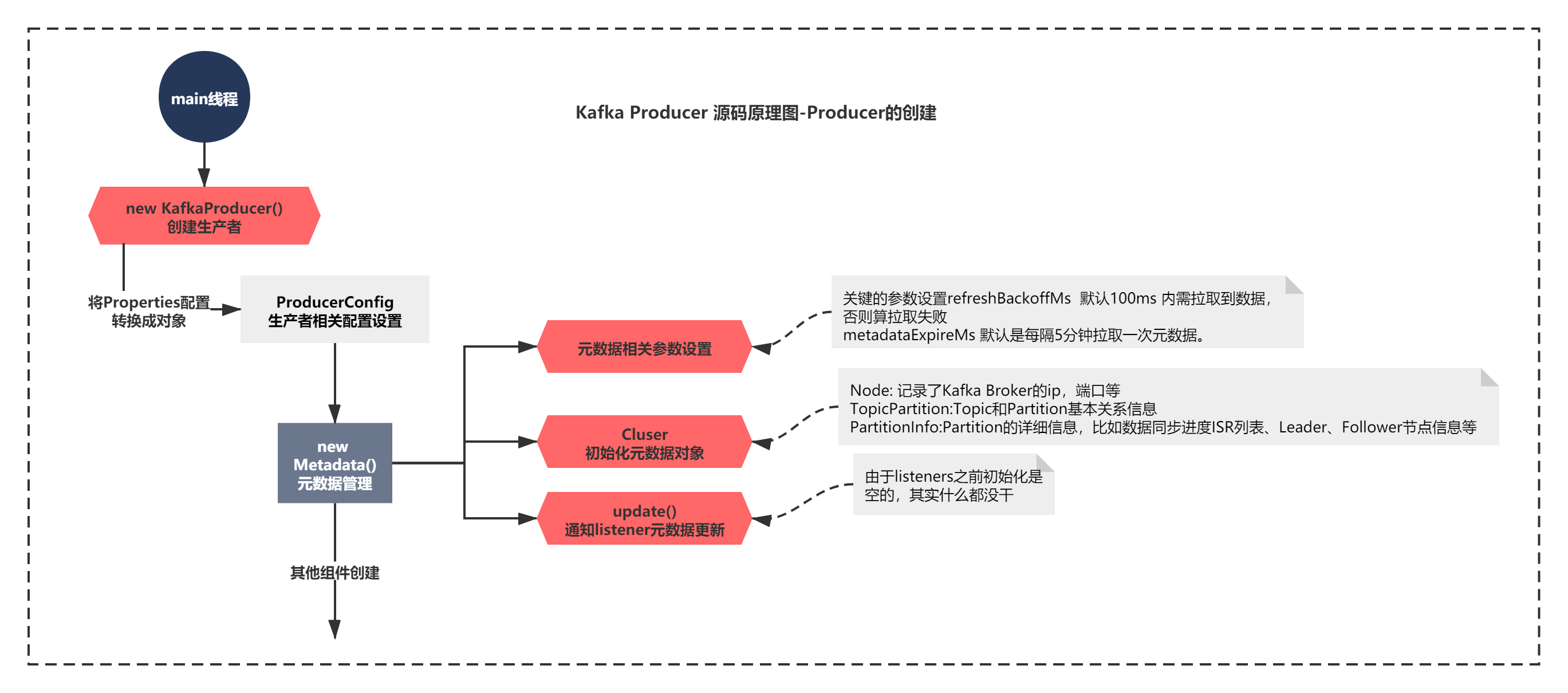
到這里,你會發現閱讀原始碼的時候,不是什么時候都是一帆風順的,會被各種分支和代碼搞得暈頭轉向,像上面的update()方法,就會迷惑你,
但此時你不要灰心,一定要縷清核心脈絡思路,多畫圖,先記錄關鍵邏輯,把這里放一放,可以嘗試繼續分析其他的場景和邏輯,當分析的邏輯和場景足夠多的時候,多重復分析幾次,你就會慢慢悟到之前不懂的邏輯,會串起來所有的邏輯的,
Producer核心組件—RecordAccumulator剖析
仔細分析過了元資料組件的創建之后,我們接著看下一個組件RecordAccumulator訊息記憶體緩沖器,
之前通過注釋我們大體知道RecordAccumulator,它是個記錄累加器,這個記錄Record其實可以看做是一條訊息的抽象封裝,也就是它是訊息累加器,通過一個記憶體佇列快取,做了一個緩沖,準備將這個資料發送給Broker,所以我們就可以稱他為發送訊息的記憶體緩沖器,
創建它的代碼主要如下:
/**
* Create a new record accumulator
*
* @param batchSize The size to use when allocating {@link org.apache.kafka.common.record.MemoryRecords} instances
* @param totalSize The maximum memory the record accumulator can use.
* @param compression The compression codec for the records
* @param lingerMs An artificial delay time to add before declaring a records instance that isn't full ready for
* sending. This allows time for more records to arrive. Setting a non-zero lingerMs will trade off some
* latency for potentially better throughput due to more batching (and hence fewer, larger requests).
* @param retryBackoffMs An artificial delay time to retry the produce request upon receiving an error. This avoids
* exhausting all retries in a short period of time.
* @param metrics The metrics
* @param time The time instance to use
*/
public RecordAccumulator(int batchSize,
long totalSize,
CompressionType compression,
long lingerMs,
long retryBackoffMs,
Metrics metrics,
Time time) {
this.drainIndex = 0;
this.closed = false;
this.flushesInProgress = new AtomicInteger(0);
this.appendsInProgress = new AtomicInteger(0);
this.batchSize = batchSize;
this.compression = compression;
this.lingerMs = lingerMs;
this.retryBackoffMs = retryBackoffMs;
this.batches = new CopyOnWriteMap<>();
String metricGrpName = "producer-metrics";
this.free = new BufferPool(totalSize, batchSize, metrics, time, metricGrpName);
this.incomplete = new IncompleteRecordBatches();
this.muted = new HashSet<>();
this.time = time;
registerMetrics(metrics, metricGrpName);
}
這個方法的脈絡其實注釋已經告訴我們了,主要就是:
1)設定了一些引數 batchSize、totalSize、retryBackoffMs、lingerMs、compression等
2)初始化了一些資料結構,比如batches是一個 new CopyOnWriteMap<>()
3)初始化了BufferPool和IncompleteRecordBatches
1)設定了一些引數 batchSize、totalSize、retryBackoffMs、lingerMs、compression等
首先是設定了一些引數 ,從上一節ConfigDef初始化可以看到默認值和基本作用
batchSize 默認是16kb,批量打包訊息發送給Broker的大小控制
totalSize 默認是32MB,表示訊息記憶體緩沖區的大小
retryBackoffMs 默認每隔100ms重試一次
lingerMs 10ms內還沒有湊成1個batch發送出去,必須立即發送出去
compression 壓縮請求方式,默認none
2)初始化了一些資料結構,比如batches是一個 new CopyOnWriteMap<>()
應該是存放Record訊息的一個集合,看著像是按照某個topic某個磁區下,存放一些訊息,用到了一個雙端佇列
batches = new ConcurrentMap<TopicPartition, Deque<RecordBatch>>()
3)初始化了BufferPool和IncompleteRecordBatches
IncompleteRecordBatches的創建比較簡單,如下:
/*
* A threadsafe helper class to hold RecordBatches that haven't been ack'd yet
*/
private final static class IncompleteRecordBatches {
private final Set<RecordBatch> incomplete;
public IncompleteRecordBatches() {
this.incomplete = new HashSet<RecordBatch>();
}
public void add(RecordBatch batch) {
synchronized (incomplete) {
this.incomplete.add(batch);
}
}
public void remove(RecordBatch batch) {
synchronized (incomplete) {
boolean removed = this.incomplete.remove(batch);
if (!removed)
throw new IllegalStateException("Remove from the incomplete set failed. This should be impossible.");
}
}
public Iterable<RecordBatch> all() {
synchronized (incomplete) {
return new ArrayList<>(this.incomplete);
}
}
}
注釋可以看出來,它是一個執行緒安全的輔助類,通過synchronized 操作HashSet保證用于保存Broker尚未確認(ack)的RecordBatches,
而new BufferPool初始化緩沖區,代碼如下:
*/
public final class BufferPool {
private final long totalMemory;
private final int poolableSize;
private final ReentrantLock lock;
private final Deque<ByteBuffer> free;
private final Deque<Condition> waiters;
private long availableMemory;
private final Metrics metrics;
private final Time time;
private final Sensor waitTime;
/**
* Create a new buffer pool
*
* @param memory The maximum amount of memory that this buffer pool can allocate
* @param poolableSize The buffer size to cache in the free list rather than deallocating
* @param metrics instance of Metrics
* @param time time instance
* @param metricGrpName logical group name for metrics
*/
public BufferPool(long memory, int poolableSize, Metrics metrics, Time time, String metricGrpName) {
this.poolableSize = poolableSize;
this.lock = new ReentrantLock();
this.free = new ArrayDeque<ByteBuffer>();
this.waiters = new ArrayDeque<Condition>();
this.totalMemory = memory;
this.availableMemory = memory;
this.metrics = metrics;
this.time = time;
this.waitTime = this.metrics.sensor("bufferpool-wait-time");
MetricName metricName = metrics.metricName("bufferpool-wait-ratio",
metricGrpName,
"The fraction of time an appender waits for space allocation.");
this.waitTime.add(metricName, new Rate(TimeUnit.NANOSECONDS));
}
主要是有一把鎖和有兩個佇列,應該是存放訊息的真正的記憶體快取區域,
整個程序如下所示:
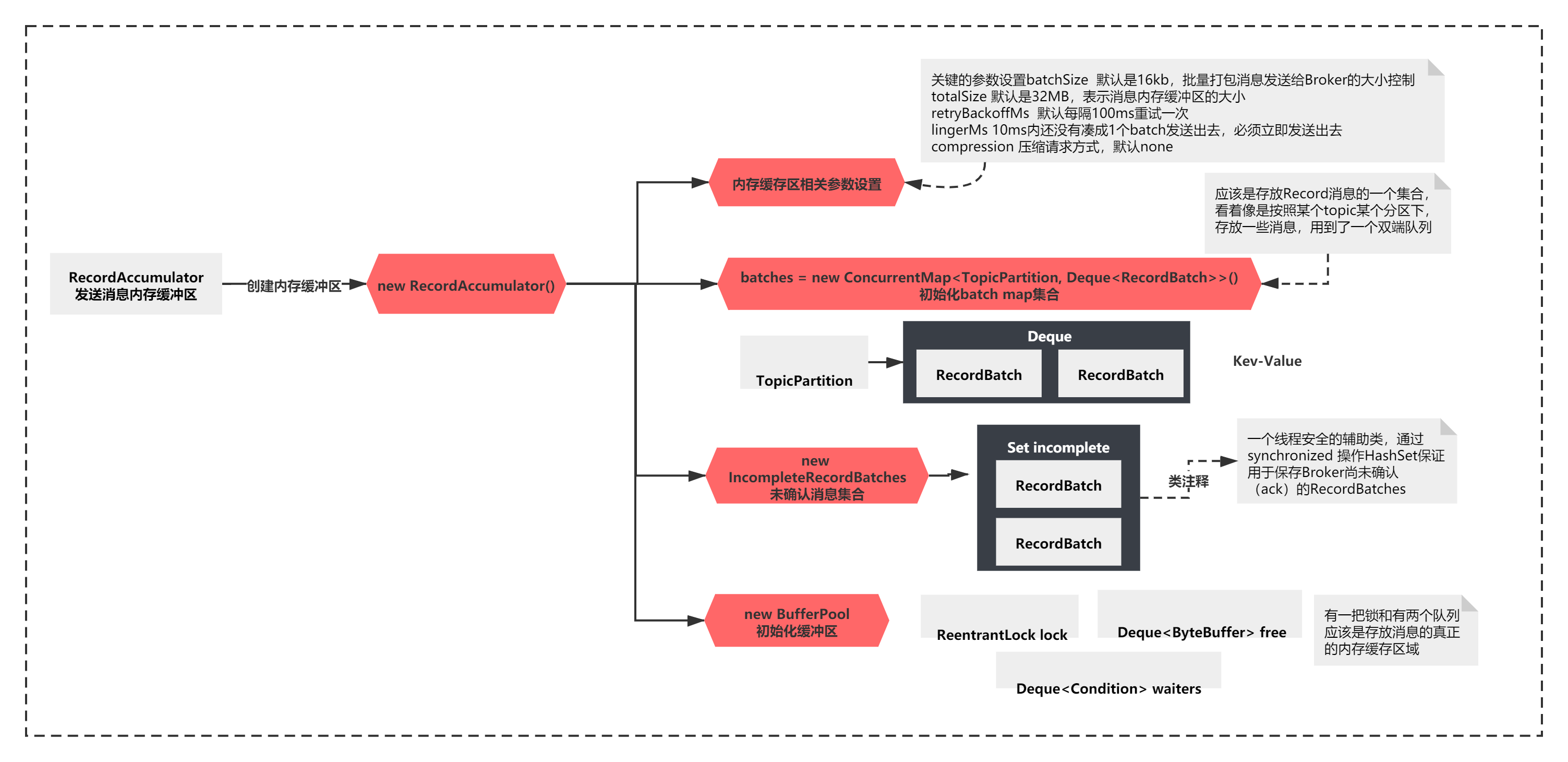
你看過這些的組件的內部結構,其實可能并不知道它們到底是干嘛的,沒關系,這里我們主要的目的本來就是初步就是對這些組件有個印象就可以了,之后分析某個組件的行為和作用的時候,才能更好的理解,
Producer核心組件—NetworkClient剖析
如果要拉去元資料或者發送訊息,首先肯定要和Broker建立連接,之前分析KafkaProducer的原始碼脈絡時,有一個網路通信組件NetworkClient,我們可以分析下這個組件怎么創建,做了哪些事情,看看元資料拉取會不會在這里呢?
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
// 一些引數設定,省略...
// RecordAccumulator、Metadata、Sender等組件的初始化,省略...
NetworkClient client = new NetworkClient(
// Kafka將原生的Selector略微包裝了下,包裝成Kafka自已的一個Selector網路通信組件
new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), this.metrics, time, "producer", channelBuilder),
this.metadata,
clientId,
config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION),
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
config.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
this.requestTimeoutMs, time);
//省略...
}
private NetworkClient(MetadataUpdater metadataUpdater,
Metadata metadata,
Selectable selector,
String clientId,
int maxInFlightRequestsPerConnection,
long reconnectBackoffMs,
int socketSendBuffer,
int socketReceiveBuffer,
int requestTimeoutMs,
Time time) {
/* It would be better if we could pass `DefaultMetadataUpdater` from the public constructor, but it's not
* possible because `DefaultMetadataUpdater` is an inner class and it can only be instantiated after the
* super constructor is invoked.
*/
if (metadataUpdater == null) {
if (metadata =https://www.cnblogs.com/fanmao/archive/2021/10/06/= null)
throw new IllegalArgumentException("`metadata` must not be null");
//更新元資料的一個組件?
this.metadataUpdater = new DefaultMetadataUpdater(metadata);
} else {
this.metadataUpdater = metadataUpdater;
}
this.selector = selector;
this.clientId = clientId;
// 已發送或正在發送但尚未收到回應的請求集
this.inFlightRequests = new InFlightRequests(maxInFlightRequestsPerConnection);
// Producer與集群中每個節點的連接狀態
this.connectionStates = new ClusterConnectionStates(reconnectBackoffMs);
this.socketSendBuffer = socketSendBuffer;
this.socketReceiveBuffer = socketReceiveBuffer;
this.correlation = 0;
this.randOffset = new Random();
this.requestTimeoutMs = requestTimeoutMs;
this.time = time;
}
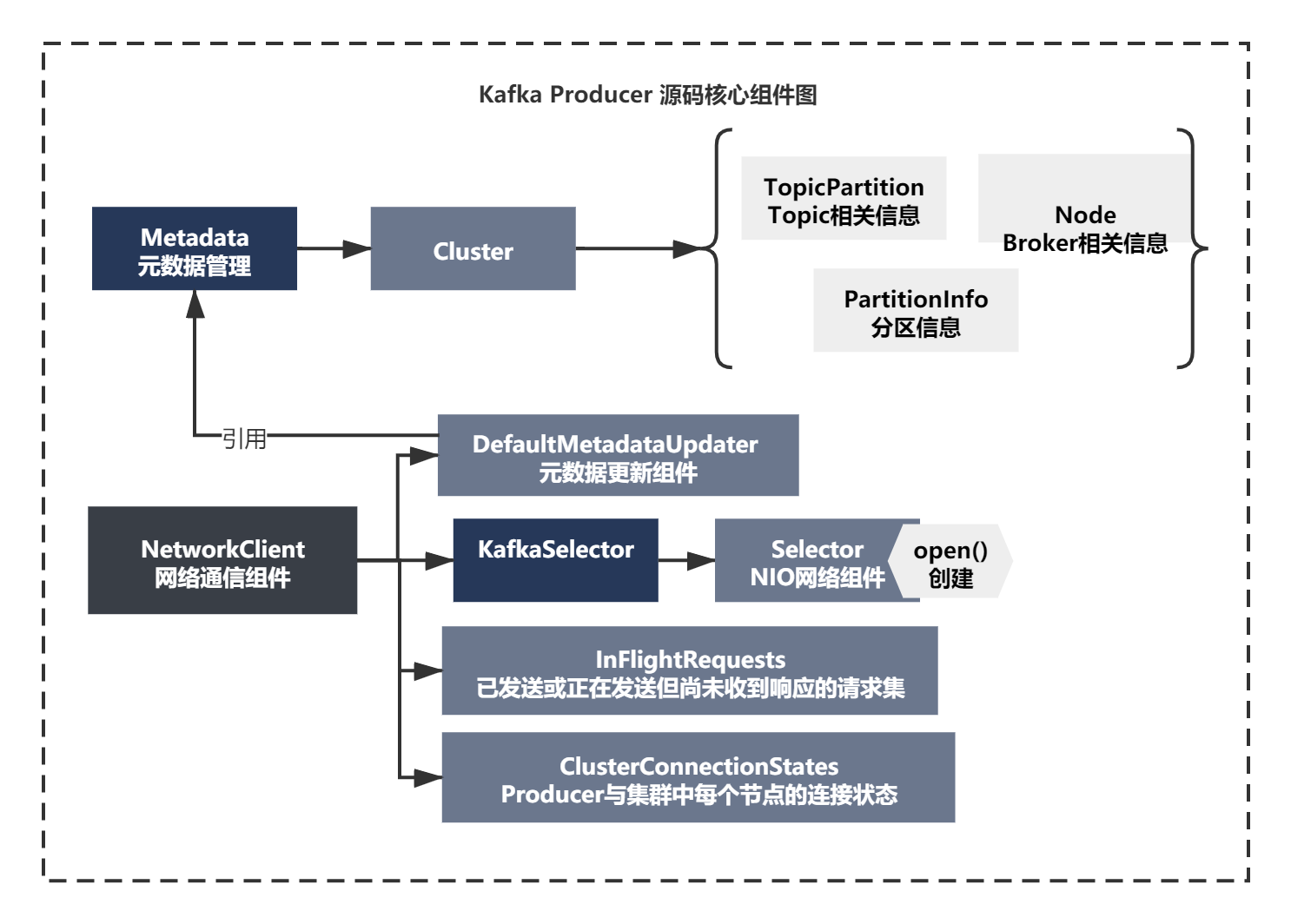
上面的NetworkClient 創建,主要是
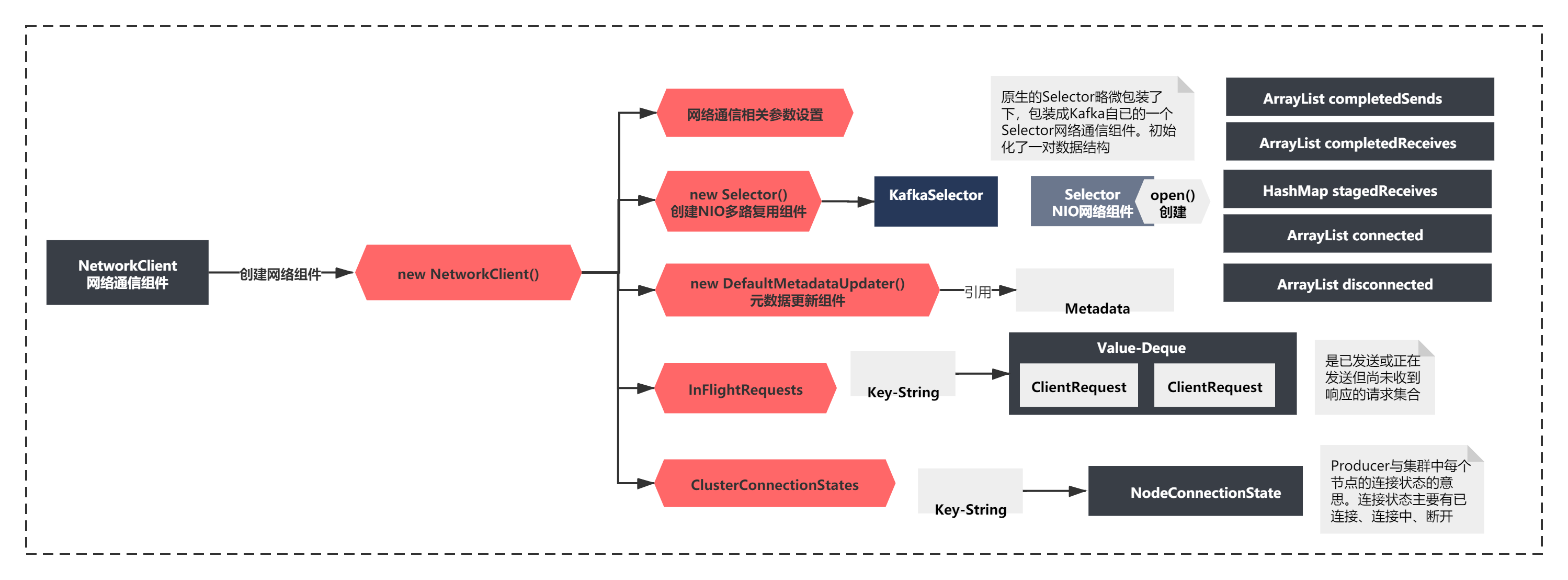
1)創建了一個Selector,Selector這個名稱,如果你熟悉Java NIO的API的話,應該不會陌生,它是NIO三大組件之一Selector、Buffer、Channel,Kafka將原生的Selector略微包裝了下,包裝成Kafka自已的一個Selector網路通信組件,
這里我不展開將NIO的原理,Selector這個組件,你可以簡單的理解為是用來監聽網路連接是否有建立和讀寫請求的,
2)設定了一堆配置引數,
3)創建了一個DefaultMetadataUpdater組件,將metadata傳遞給了它,從名字連蒙帶猜下,好像是更新元資料的一個組件,難道找到元資料拉取的邏輯了?一會可以重點關注下這個類的使用
4)創建了InFlightRequests和ClusterConnectionStates 從這兩個類的注釋我們可以看出來,InFlightRequests是已發送或正在發送但尚未收到回應的請求集,ClusterConnectionStates 是Producer與集群中每個節點的連接狀態,**
上面的NetworkClient的初始化,整個程序可以總結如下圖:
看過了創建的脈絡,下面我們看下細節(先脈絡后細節的思想),上面的資訊如果你不是一下在就能看出來的話,你就需要看下每個類的細節,確認下了,
細節1:首先是創建Selector代碼如下:
public Selector(long connectionMaxIdleMS, Metrics metrics, Time time, String metricGrpPrefix, ChannelBuilder channelBuilder) {
this(NetworkReceive.UNLIMITED, connectionMaxIdleMS, metrics, time, metricGrpPrefix, new HashMap<String, String>(), true, channelBuilder);
}
public Selector(int maxReceiveSize, long connectionMaxIdleMs, Metrics metrics, Time time, String metricGrpPrefix, Map<String, String> metricTags, boolean metricsPerConnection, ChannelBuilder channelBuilder) {
try {
//本質還是創建了一個NIO的Selector
this.nioSelector = java.nio.channels.Selector.open();
} catch (IOException e) {
throw new KafkaException(e);
}
this.maxReceiveSize = maxReceiveSize;
this.connectionsMaxIdleNanos = connectionMaxIdleMs * 1000 * 1000;
this.time = time;
this.metricGrpPrefix = metricGrpPrefix;
this.metricTags = metricTags;
this.channels = new HashMap<>();
this.completedSends = new ArrayList<>();
this.completedReceives = new ArrayList<>();
this.stagedReceives = new HashMap<>();
this.immediatelyConnectedKeys = new HashSet<>();
this.connected = new ArrayList<>();
this.disconnected = new ArrayList<>();
this.failedSends = new ArrayList<>();
this.sensors = new SelectorMetrics(metrics);
this.channelBuilder = channelBuilder;
// initial capacity and load factor are default, we set them explicitly because we want to set accessOrder = true
this.lruConnections = new LinkedHashMap<>(16, .75F, true);
currentTimeNanos = time.nanoseconds();
nextIdleCloseCheckTime = currentTimeNanos + connectionsMaxIdleNanos;
this.metricsPerConnection = metricsPerConnection;
}
可以看到,創建Kafka的Selector本質還是創建了一個NIO的Selector:java.nio.channels.Selector.open();
細節2:DefaultMetadataUpdater這個類的初始化,什么都沒做,就是參考了下Metadata
class DefaultMetadataUpdater implements MetadataUpdater {
//參考了下Metadata
/* the current cluster metadata */
private final Metadata metadata;
/* true iff there is a metadata request that has been sent and for which we have not yet received a response */
private boolean metadataFetchInProgress;
/* the last timestamp when no broker node is available to connect */
private long lastNoNodeAvailableMs;
DefaultMetadataUpdater(Metadata metadata) {
this.metadata = https://www.cnblogs.com/fanmao/archive/2021/10/06/metadata;
this.metadataFetchInProgress = false;
this.lastNoNodeAvailableMs = 0;
}
細節3:InFlightRequests的注釋的確是已發送或正在發送但尚未收到回應的請求集的意思,不理解也沒關系,后面我們會看到它使用的地方的,
/**
* The set of requests which have been sent or are being sent but haven't yet received a response
* 已發送或正在發送但尚未收到回應的請求集的意思
*/
final class InFlightRequests {
private final int maxInFlightRequestsPerConnection;
private final Map<String, Deque<ClientRequest>> requests = new HashMap<String, Deque<ClientRequest>>();
public InFlightRequests(int maxInFlightRequestsPerConnection) {
this.maxInFlightRequestsPerConnection = maxInFlightRequestsPerConnection;
}
}
細節4:ClusterConnectionStates這個類注釋也就是Producer與集群中每個節點的連接狀態的意思,連接狀態主要有已連接、連接中、斷開,
/**
* The state of our connection to each node in the cluster.
* Producer與集群中每個節點的連接狀態的意思
*
*/
final class ClusterConnectionStates {
private final long reconnectBackoffMs;
private final Map<String, NodeConnectionState> nodeState;
public ClusterConnectionStates(long reconnectBackoffMs) {
this.reconnectBackoffMs = reconnectBackoffMs;
this.nodeState = new HashMap<String, NodeConnectionState>();
}
/**
* The state of our connection to a node
*/
private static class NodeConnectionState {
ConnectionState state;
long lastConnectAttemptMs;
public NodeConnectionState(ConnectionState state, long lastConnectAttempt) {
this.state = state;
this.lastConnectAttemptMs = lastConnectAttempt;
}
public String toString() {
return "NodeState(" + state + ", " + lastConnectAttemptMs + ")";
}
}
/**
* The states of a node connection
* 連接狀態主要有已連接、連接中、斷開
*/
public enum ConnectionState {
DISCONNECTED, CONNECTING, CONNECTED
}
上面整個NeworkClient的初始化,就完成了,至于網路組件的相關引數這里先不做解釋,當使用到的時候我再給大家解釋,目前解釋了大家可能也太能理解,
整個細節,我大致整理如下圖:
Producer核心組件—Sender執行緒剖析
網路組件NeworkClient和元資料Metadata、RecordAccumulator發送訊息的記憶體緩沖器,我們都剖析了下它們的初始化程序,主要知道它們初始化了那些東西,我們總結了組件圖,記錄了關鍵資訊,我們可以繼續往下分析最后一個核心的組件Send執行緒,我們來看看它搞了哪些事情,
Sender的初始化邏輯如下所示:
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
// 一些引數設定,省略...
// RecordAccumulator、NetworkClient、Metadata等組件的初始化,省略...
this.sender = new Sender(client,
this.metadata,
this.accumulator,
config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION) == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
(short) parseAcks(config.getString(ProducerConfig.ACKS_CONFIG)),
config.getInt(ProducerConfig.RETRIES_CONFIG),
this.metrics,
new SystemTime(),
clientId,
this.requestTimeoutMs);
String ioThreadName = "kafka-producer-network-thread" + (clientId.length() > 0 ? " | " + clientId : "");
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
// 省略...
}
public Sender(KafkaClient client,
Metadata metadata,
RecordAccumulator accumulator,
boolean guaranteeMessageOrder,
int maxRequestSize,
short acks,
int retries,
Metrics metrics,
Time time,
String clientId,
int requestTimeout) {
this.client = client;
this.accumulator = accumulator;
this.metadata = https://www.cnblogs.com/fanmao/archive/2021/10/06/metadata;
this.guaranteeMessageOrder = guaranteeMessageOrder;
this.maxRequestSize = maxRequestSize;
this.running = true;
this.acks = acks;
this.retries = retries;
this.time = time;
this.clientId = clientId;
this.sensors = new SenderMetrics(metrics);
this.requestTimeout = requestTimeout;
}
public KafkaThread(final String name, Runnable runnable, boolean daemon) {
super(runnable, name);
setDaemon(daemon);
setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
log.error("Uncaught exception in " + name + ": ", e);
}
});
}
這個初始化核心脈絡很簡單,主要就是將其他組件交給了Sender去使用,
1) 設定了sender的一些核心引數
retries:重試次數,默認是0,不重試
acks:"all", "-1", "0", "1" 確認策略 默認是1,leader broker寫入成功,就算發送成功, (可能導致訊息丟失)
max.request.size:最大的請求大小 默認1mb
max.in.flight.requests.per.connection 引數默認值是5,每個Broker最多只能有5個請求是發送出去但是還沒接收到回應的(重試可能導致訊息順序錯亂)
2)參考了其他三個關鍵組件:網路組件NeworkClient和元資料Metadata、RecordAccumulator發送訊息的記憶體緩沖器
3)之后通過KafkaThread包裝了Runnable執行緒,啟動了執行緒,開始執行Sender的run方法了
整個程序如下所示:
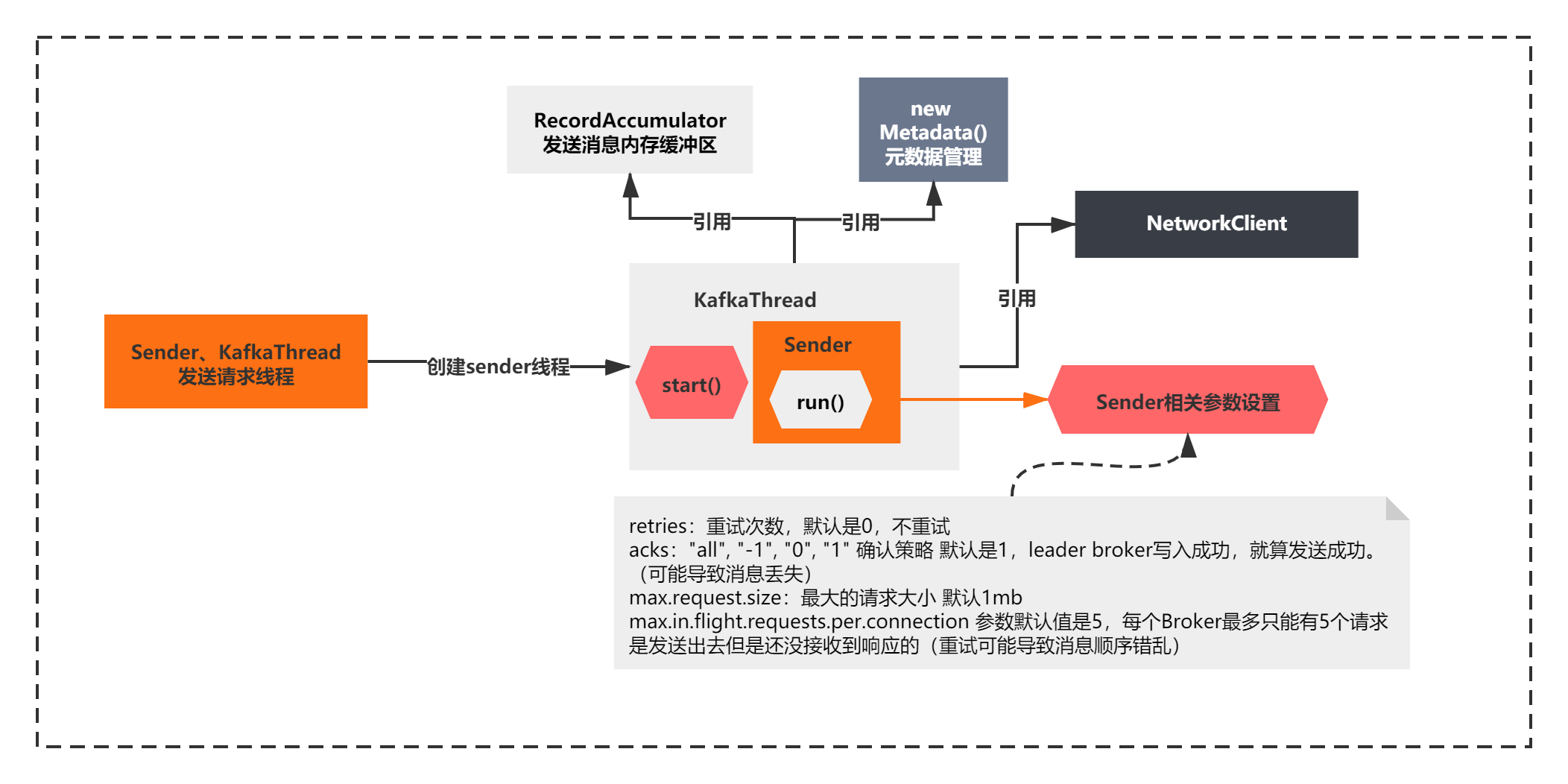
run方法的執行,不是這一節我們主要關心的了,我后面幾節會詳細分析的,
小結
最后我們小結下吧,今天我們主要熟悉了如下的內容:
KafkaProducer初始化的哪些組件
Producer核心組件—RecordAccumulator剖析
Producer核心組件—元資料Metadata剖析
Producer核心組件—NetworkClient剖析
Producer核心組件—Sender執行緒剖析
我們只是基本認識了下,每個組件是什么,主要干什么,內部主要有些什么東西,我把圖今天熟悉的只是,給大家匯總一了一張大圖:
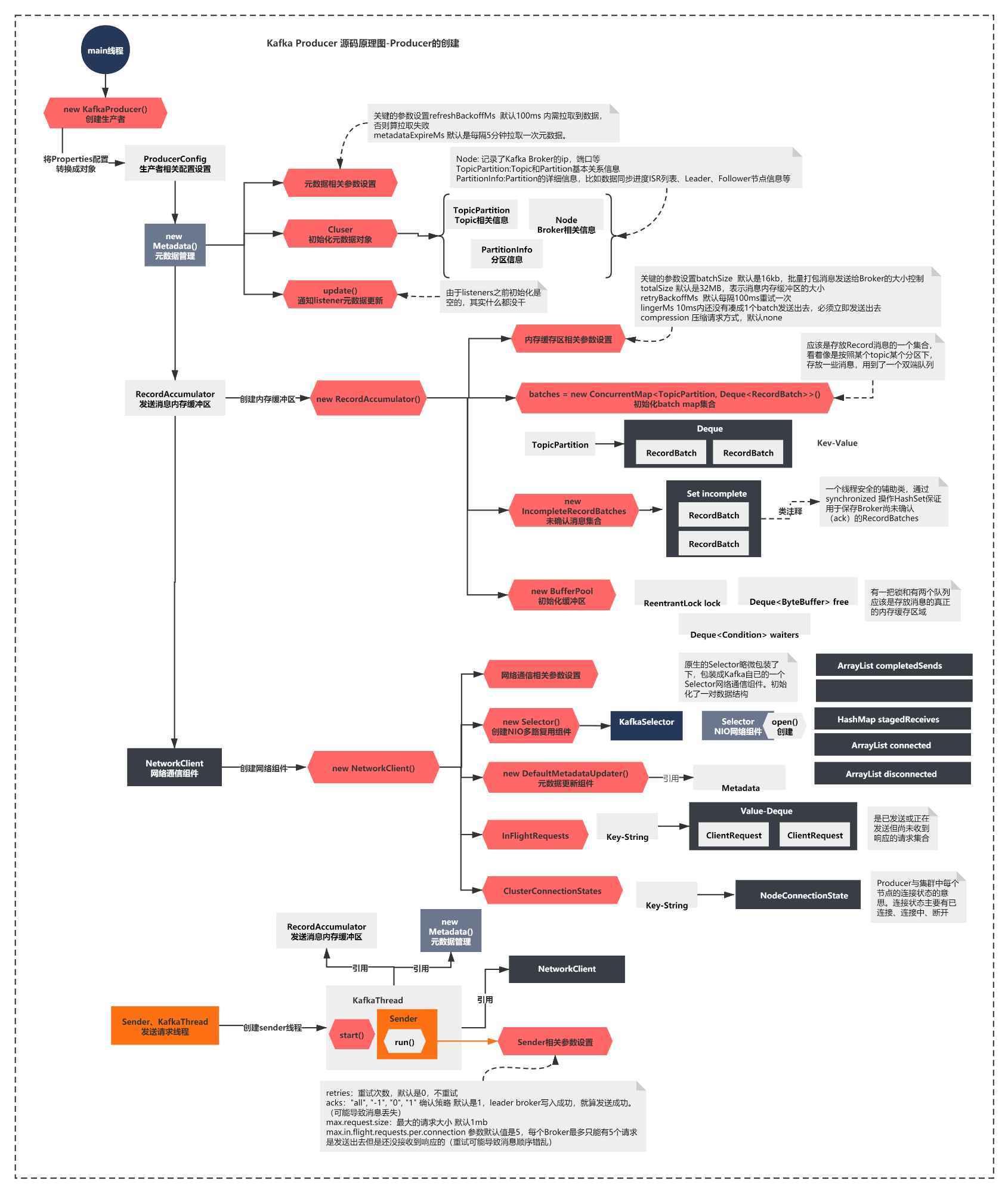
有了這張圖,后面幾節我們就來重點開始分析Kafka Prodcuer核心流程就容易很多了,比如
元資料拉取機制wait+notifyAll的靈活使用、發送訊息的路由策略
網路通信機制,基于原生NIO發送訊息機制+粘包拆包問題的巧妙解決
Producer的高吞吐:記憶體緩沖區的雙端佇列+批量打包Batch發送機制
大家敬請期待吧,好了今天就到這里,我們下節見!
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305834.html
標籤:其他