
Kafka成長記的前4節我們通過KafkaProducerHelloWorld分析了Producer配置決議、組件組成、元資料拉取原理,
但KafkaProducerHelloWorld發送訊息的代碼并沒有分析完,我們分析了如到了如下圖所示的位置:
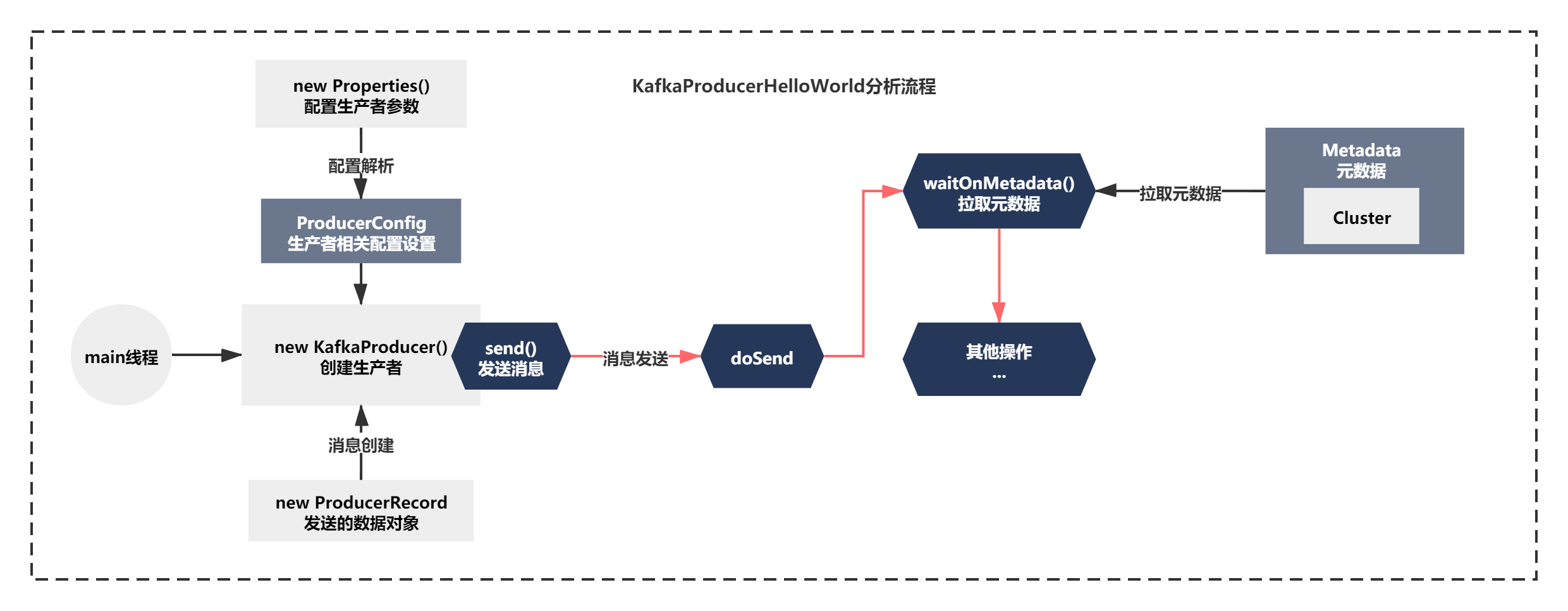
接下來,我們繼續往下分析,這一節我們主要分析下發送訊息的初步序列化和磁區路由原始碼原理,
自定義訊息的初步序列化的方式
在producer.send()執行doSend()的時候,waitOnMetadata拉取元資料成功之后脈絡是什么呢?
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// first make sure the metadata for the topic is available
long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs);
long remainingWaitMs = Math.max(0, this.maxBlockTimeMs - waitedOnMetadataMs);
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer");
}
byte[] serializedValue;
try {
serializedValue = https://www.cnblogs.com/fanmao/p/valueSerializer.serialize(record.topic(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer");
}
int partition = partition(record, serializedKey, serializedValue, metadata.fetch());
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize);
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (Exception e) {
throw e;
}
//省略其他各種例外捕獲
}
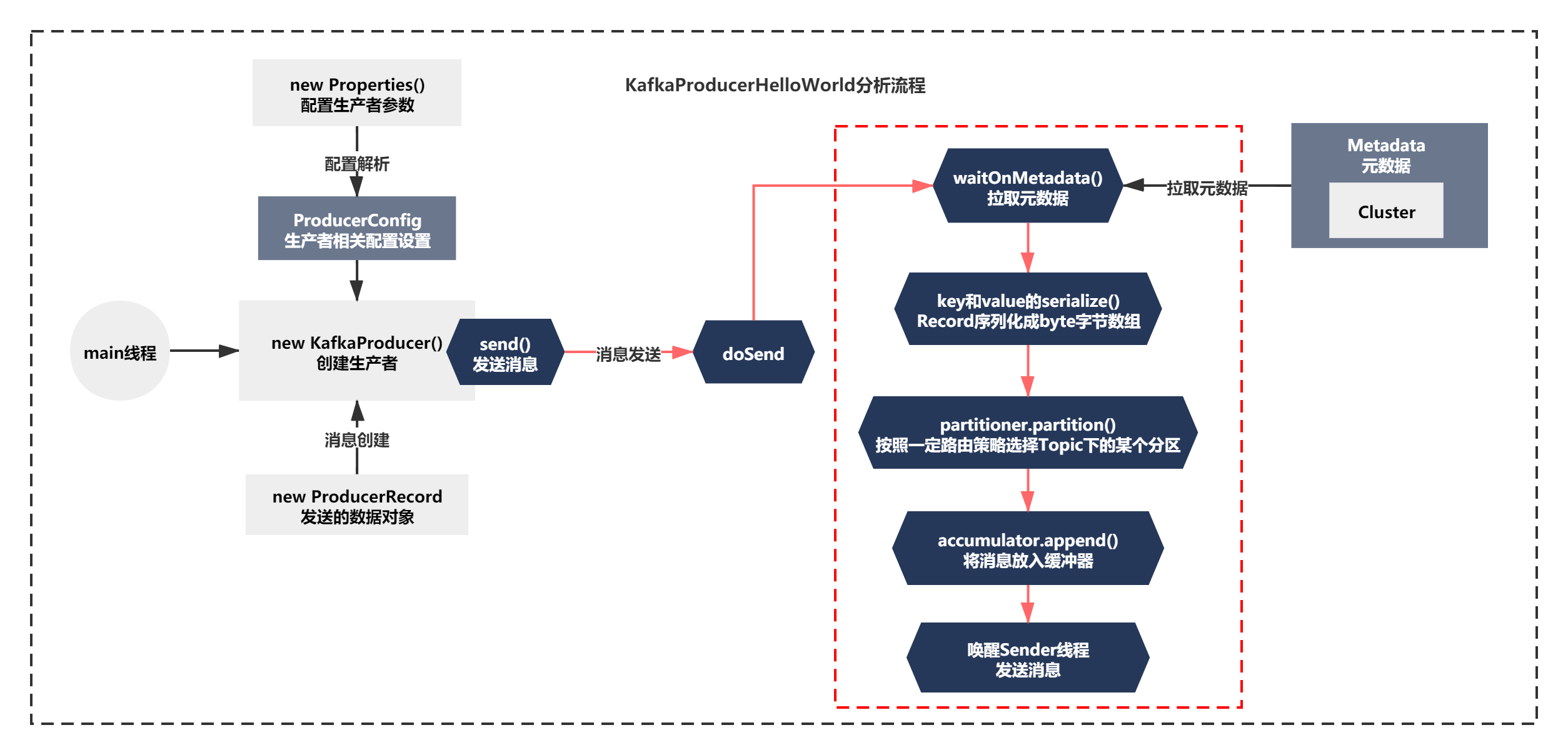
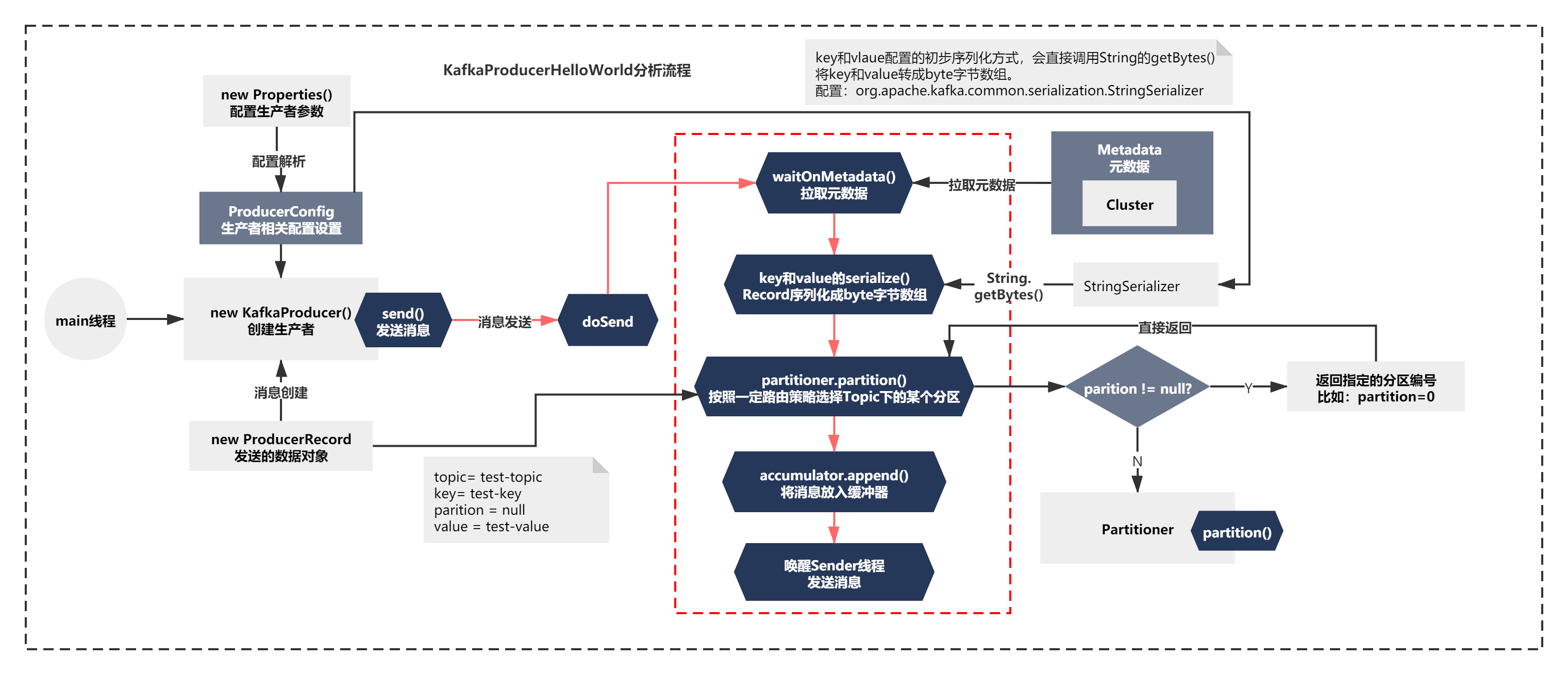
主要脈絡就是:
1)waitOnMetadata 等待元資料拉取
2)keySerializer.serialize和valueSerializer.serialize,很明顯就是將Record序列化成byte位元組陣列
3)通過partition進行路由磁區,按照一定路由策略選擇Topic下的某個磁區
4)accumulator.append將訊息放入緩沖器中
5)喚醒Sender執行緒的selector.select()的阻塞,開始處理記憶體緩沖器中的資料,
整個脈絡如下圖:
第二步執行的脈絡是使用自定義序列化器,將訊息轉換為byte[]陣列,我們就來先看下這塊的邏輯,
首先第一個問題就是,自定義的訊息序列化器哪里來的?其實是在配置引數中設定的,還記得KafkaProducerHelloWorld代碼么?
// KafkaProducerHelloWorld.java
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "mengfanmao.org:9092");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "test-key", "test-value");
producer.send(record).get();
Thread.sleep(5 * 1000);
producer.close();
}
在之前的KafkaProducerHelloWorld.java中,我們起初并沒有設定序列化引數,結果發訊息失敗,提示了如下堆疊:
Exception in thread "main" org.apache.kafka.common.config.ConfigException: Missing required configuration "key.serializer" which has no default value.
at org.apache.kafka.common.config.ConfigDef.parse(ConfigDef.java:421)
at org.apache.kafka.common.config.AbstractConfig.<init>(AbstractConfig.java:55)
at org.apache.kafka.common.config.AbstractConfig.<init>(AbstractConfig.java:62)
at org.apache.kafka.clients.producer.ProducerConfig.<init>(ProducerConfig.java:336)
at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:188)
at org.mfm.learn.kafka.KafkaProducerHelloWorld.main(KafkaProducerHelloWorld.java:20)
上面堆疊的資訊有沒有很熟悉? 提示的那些類不正是我們之前研究配置決議相關的原始碼類么?ProducerConfig、AbstractConfig、ConfigDef實在是太熟悉了,
打開原始碼ConfigDef,你會發現ConfigDef在決議組態檔時,沒有序列化配置會使得new KafkaProducer()這一步直接拋出例外,訊息發送失敗,
到這里你是不是可以略微體驗出來,閱讀原始碼的好處之一了?
接著你補充配置下序列化引數如下:
// KafkaProducerHelloWorld.java
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "mengfanmao.org:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "test-key", "test-value");
producer.send(record).get();
Thread.sleep(5 * 1000);
producer.close();
}
訊息發送成功!我們補充設定的序列化器是客戶端jar包中默認提供的StringSerializer,既然有了訊息序列化器,我們就來看看它是如何序列化的key和value的,
我們將之前第二步核心簡化,其實就是如下代碼:
//KafkaProudcer.java#doSend
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "test-key", "test-value");
keySerializer.serialize(record.topic(), record.key());
valueSerializer.serialize(record.topic(), record.value());
//StringSerializer.java
public byte[] serialize(String topic, String data) {
try {
if (data =https://www.cnblogs.com/fanmao/p/= null)
return null;
else
return data.getBytes(encoding);
} catch (UnsupportedEncodingException e) {
throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + encoding);
}
}
可以看到StringSerializer的序列化的方式非常簡單,就是呼叫String原始的getBytes()方法而已,(PS:第一個引數竟然沒有使用...)
序列化真的只是到這里為止了么?肯定不是,這個bytes[]陣列的資料肯定最終需要通過網路發送出去的,這里只是算是初步的一次序列化而已,訊息之后最終的序列化,包括具體的格式,我們之后研究Kafka使用原生Java NIO解決粘包和拆包問題時在深入研究,
起碼,這里我們可以得到如下的圖了:
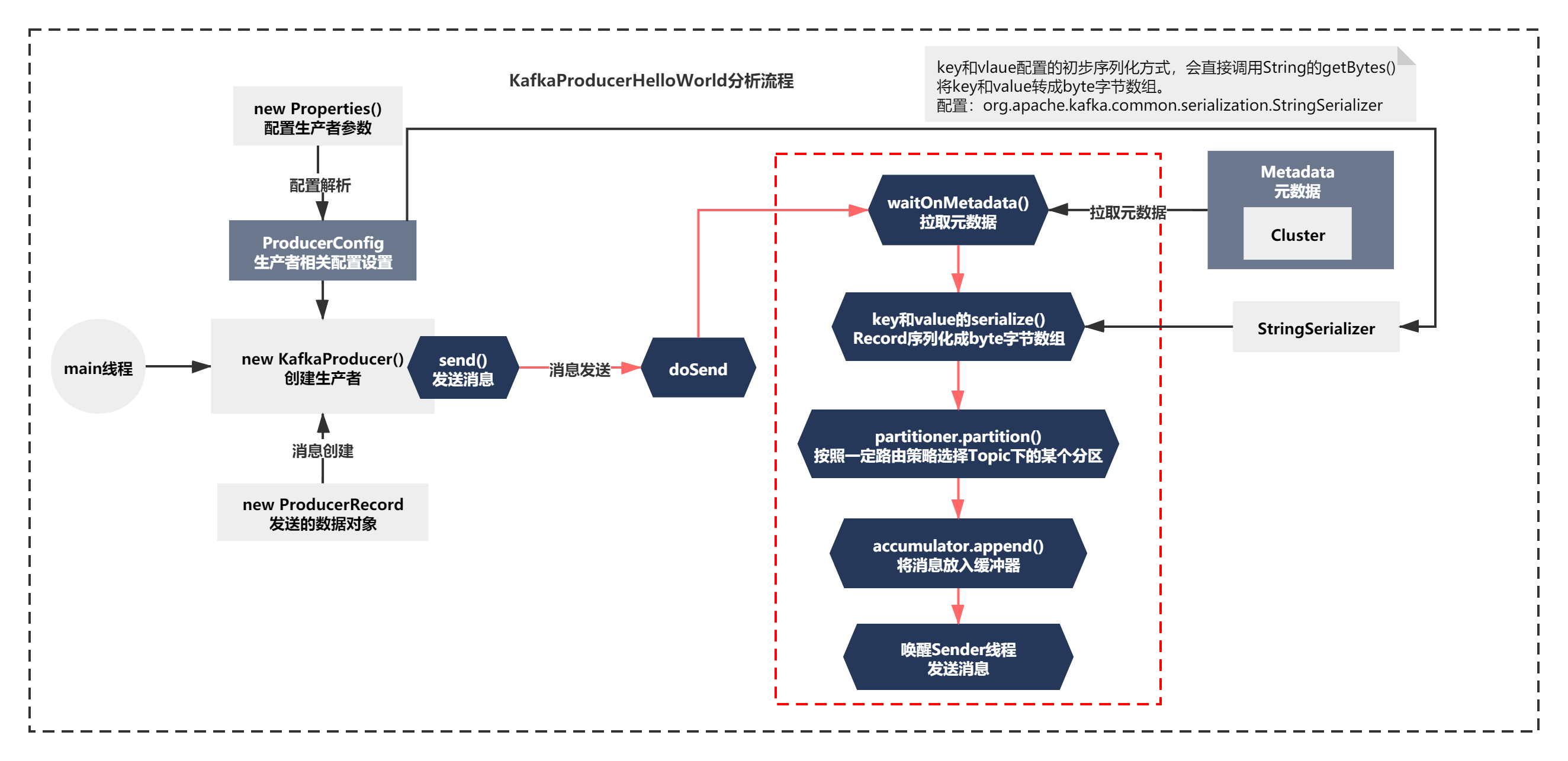
訊息基于Topic磁區路由原始碼原理
發送訊息時,拉取到元資料、初步序列化訊息為byte[]陣列,之后就是通過元資料資訊進行路由,選擇一個Topic對應的Partition發送訊息了,在路由選擇發送訊息的磁區時,用到了Metadata中的Cluster元資料,這里帶大家回顧下它的結構,
Cluster類的元資料記憶體結構回顧
List
Map nodesById,key是broker的id,value是Broker的資訊Node
Map partitionsByTopic:每個topic有哪些磁區,key是topic名稱,value是磁區資訊串列
Map availablePartitionsByTopic,每個topic有哪些當前可用的磁區,key是topic名稱,value是磁區資訊串列
Map partitionsByNode,每個broker上放了哪些磁區,key是broker的id,value是磁區資訊串列
unautorhizedTopics:沒有被授權訪問的Topic的串列,如果你的客戶端沒有被授權訪問某個Topic,訊息佇列的權限控制用的很少,這個幾乎可以忽略,
你可以斷點,看下資料,如下所示:
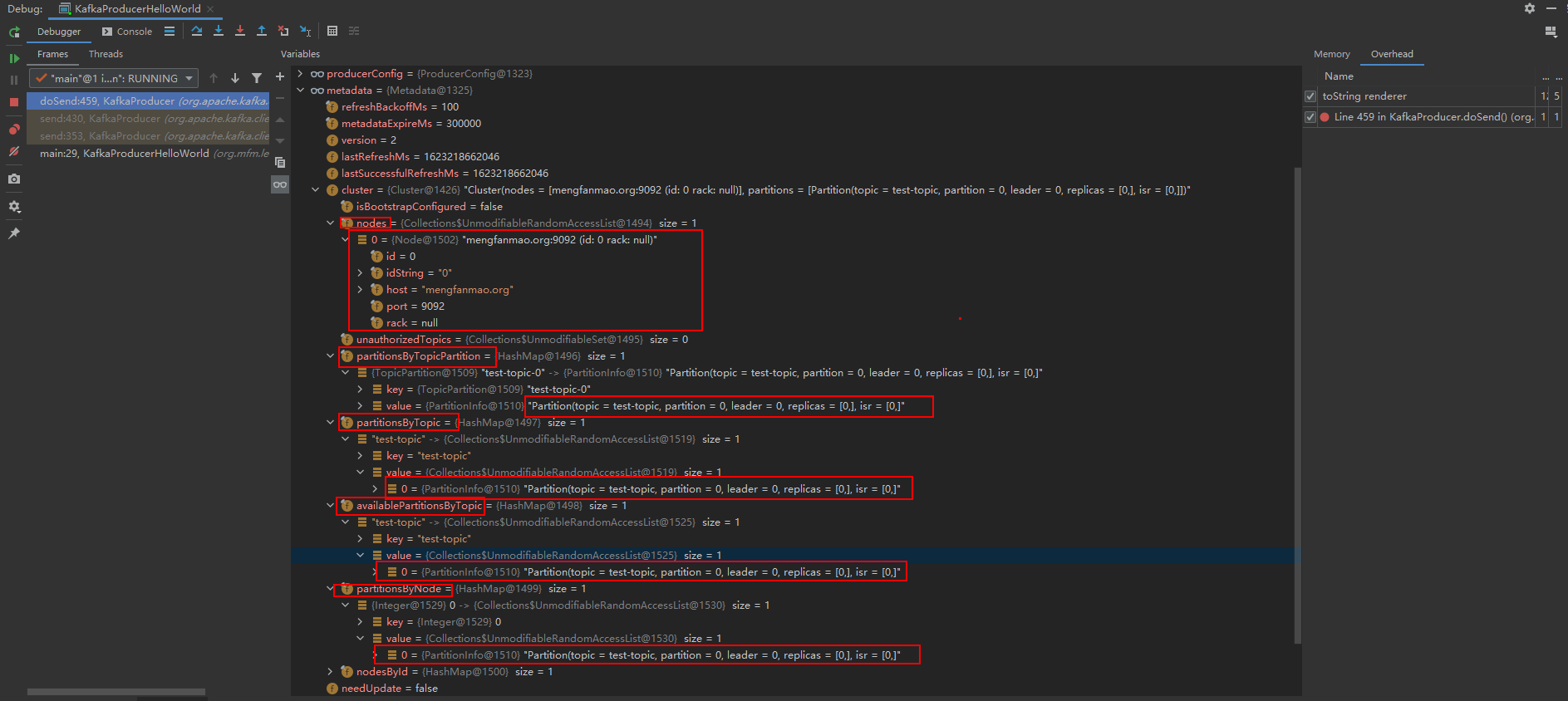
對集群元資料,你可以發現,根據不同的需求、使用和場景,采用不同的資料結構來進行存放,kafka Producer設計了不同的資料結構,其實很多時候我們是可以學習用類似這種思路寫代碼的,
回顧了元資料之后,客戶端肯定可以根據元資料資訊進行路由了,那么是如何路由的呢?代碼如下:
// KakfaProducer.java
private final Partitioner partitioner;
//#doSend()
int partitionpartition = partition(record, serializedKey, serializedValue, metadata.fetch());
//#partition()
private int partition(ProducerRecord<K, V> record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
if (partition != null) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(record.topic());
int lastPartition = partitions.size() - 1;
// they have given us a partition, use it
if (partition < 0 || partition > lastPartition) {
throw new IllegalArgumentException(String.format("Invalid partition given with record: %d is not in the range [0...%d].", partition, lastPartition));
}
return partition;
}
return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue,
cluster);
}
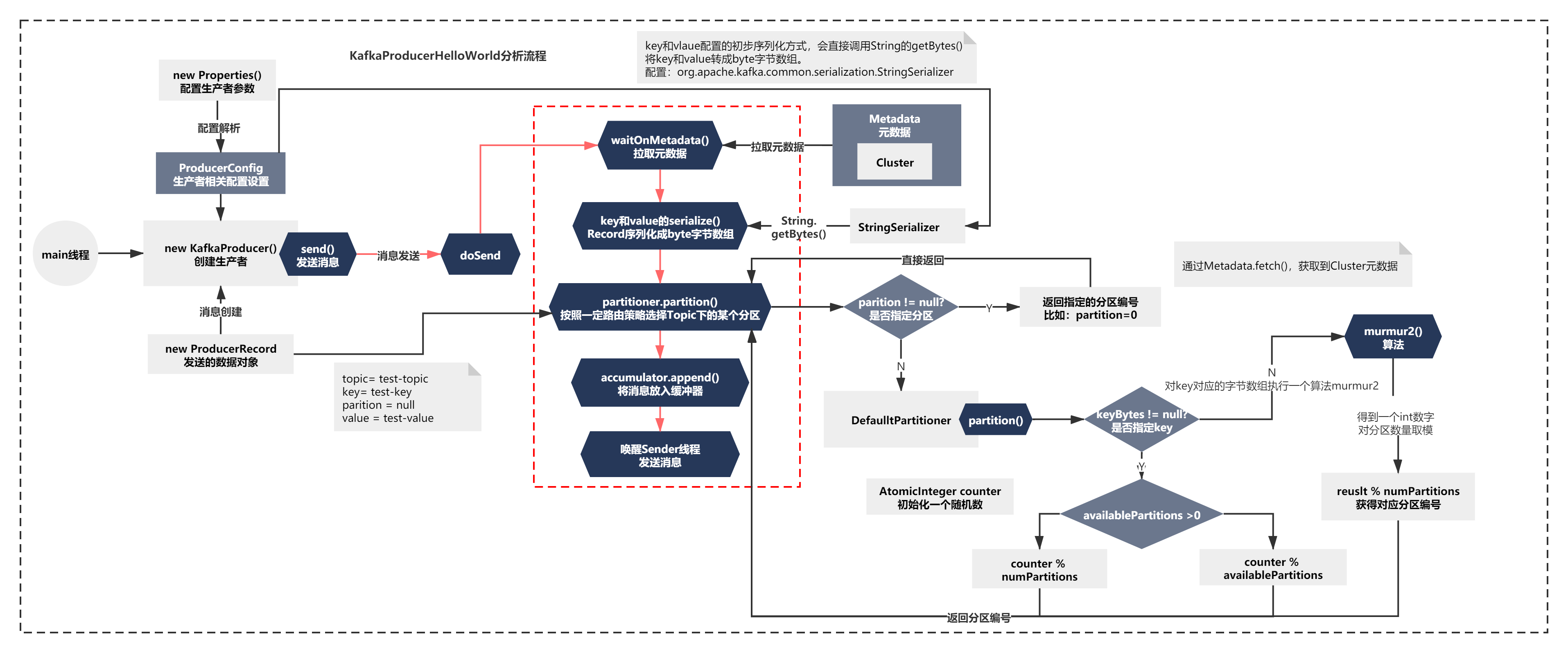
這段方法脈絡很簡單,主要就是根據record是否指定磁區partition決定:
1)如果發送的訊息record指定了磁區,使用元資料資訊Cluster校驗后,路由后的磁區就是指定的磁區編號,
2)如果發送的訊息record沒有指定磁區,使用一個Partitioner組件partition方法路由決定磁區編號,
如下圖:
上一節我們說過ProducerRecord的時間戳和磁區是可選的,默認都是null,也就是說,默認會走到Partitioner組件partition這個分支,
可是問題就來了,Partitioner這個是什么時候初始化的?
由于partitioner這個是KafkaProducer的一個成員變數,你可以搜索下它,你會發現:
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
//省略其他代碼...
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
//省略其他代碼...
}
原來是在建構式時候初始化的,它其實就是通過配置決議得到的,并且有一個默認值DefaultPartitioner,
知道了這個之后,我們來看看默認的話是如何路發送的訊息呢?
//DefaultPartitioner.java
private final AtomicInteger counter = new AtomicInteger(new Random().nextInt());
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = https://www.cnblogs.com/fanmao/p/counter.getAndIncrement();
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return DefaultPartitioner.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
這個方法脈絡主要是:
1)從元資料Cluster中的map獲取topic下對應的所有磁區和磁區數量
2)發送訊息如果沒有指定key,則從一個亂數開始,每次通過AtomicInteger遞增+1,對磁區數量或者可用磁區大小取模,獲得對應的磁區編號
3)發送訊息如果指定key,會對key對應的位元組陣列執行一個演算法murmur2,得到一個int數字,之后對磁區數量取模,獲得對應磁區編號
整個程序如下圖所示:
通過上面的路由策略,你可以發現,kafka發送的訊息,哪怕只是指定了topic都是可以的,不需要指定key和partition,不過這樣可能會導致訊息亂序,
至于如何保證kafka發送訊息的順序性,除了指定磁區和key外,其實還需要其他的配置,比如InFlightRequest的size默認是5,需要設定為1,否則重試的時候也會導致訊息亂序,這些我們后面會分析到的,
小結
今天我們主要探索了訊息的初步序列化方式、訊息的路由策略,我們簡單小結下:
1)Kafka訊息的初步序列化必須通過配置引數指定,一般使用StringSerializer,不指定會導致發送訊息失敗
2)Kafka發送的訊息,Topic必須指定,而Topic下的key和partition可選,
默認的磁區路由的策略,支持三種,指定磁區,指定磁區key,或者不指定磁區key
a.同時指定或者只指定partition,由于parttition路由的優先級高于key,會根據指定的parttition編號直接路由訊息,
b.如果只是指定key,會對key對應的位元組陣列執行一個演算法murmur2,得到一個int數字,之后對磁區數量取模,獲得對應磁區編號
c.如果都不指定,則從一個亂數開始,每次通過AtomicInteger遞增+1,對磁區數量或者可用磁區大小取模,獲得對應的磁區編號
這一節的知識比較輕松,不知道大家掌握的怎么樣了,隨著對KafkaProducer的分析,我們已經,慢慢揭開了它神秘的面紗了,后面兩節我們一起來分析下發送訊息的記憶體緩沖器的原理,如何分配記憶體區域,佇列機制+batch機制如何將訊息批量發送出去,在之后再分析下,Kakfa如何解決Java 原生NIO中的拆包和粘包的問題,基本Producer的原始碼原理就研究的差不多了,
我們下一節再見!
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/306121.html
標籤:Java
上一篇:Go語言之結構體與方法