嗨嘍~小伙伴們我又來了,
眾所周知,python在爬蟲領域有著得天獨厚的優勢,今天,咱整點有意思的應用-----用python爬取王者榮耀所有英雄皮膚圖片,
本章中,我會著重帶大家了解爬取網頁的基本流程,廢話不多說,走起......
首先,咱去王者榮耀的官網瞧瞧:王者榮耀官方網站-騰訊游戲 (建議用谷歌瀏覽器)
我們的目標是,找到英雄皮膚的url地址,如下圖,官網是這樣的:

發現圖中的紅框部分-----英雄資料,點進去看看:
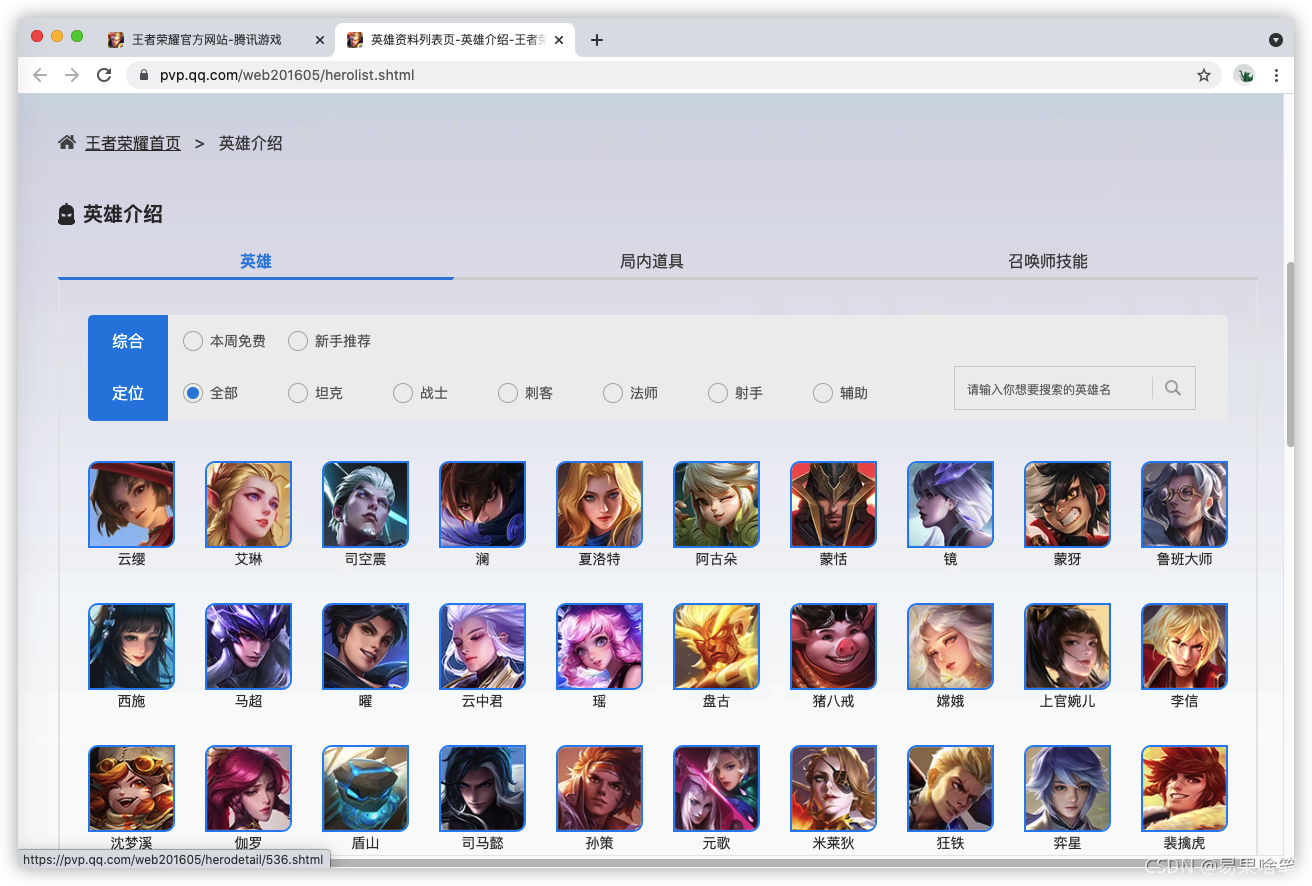
往下滑,我們可以發現好多的英雄頭像,點一個進去看看,比如貂蟬姐姐:
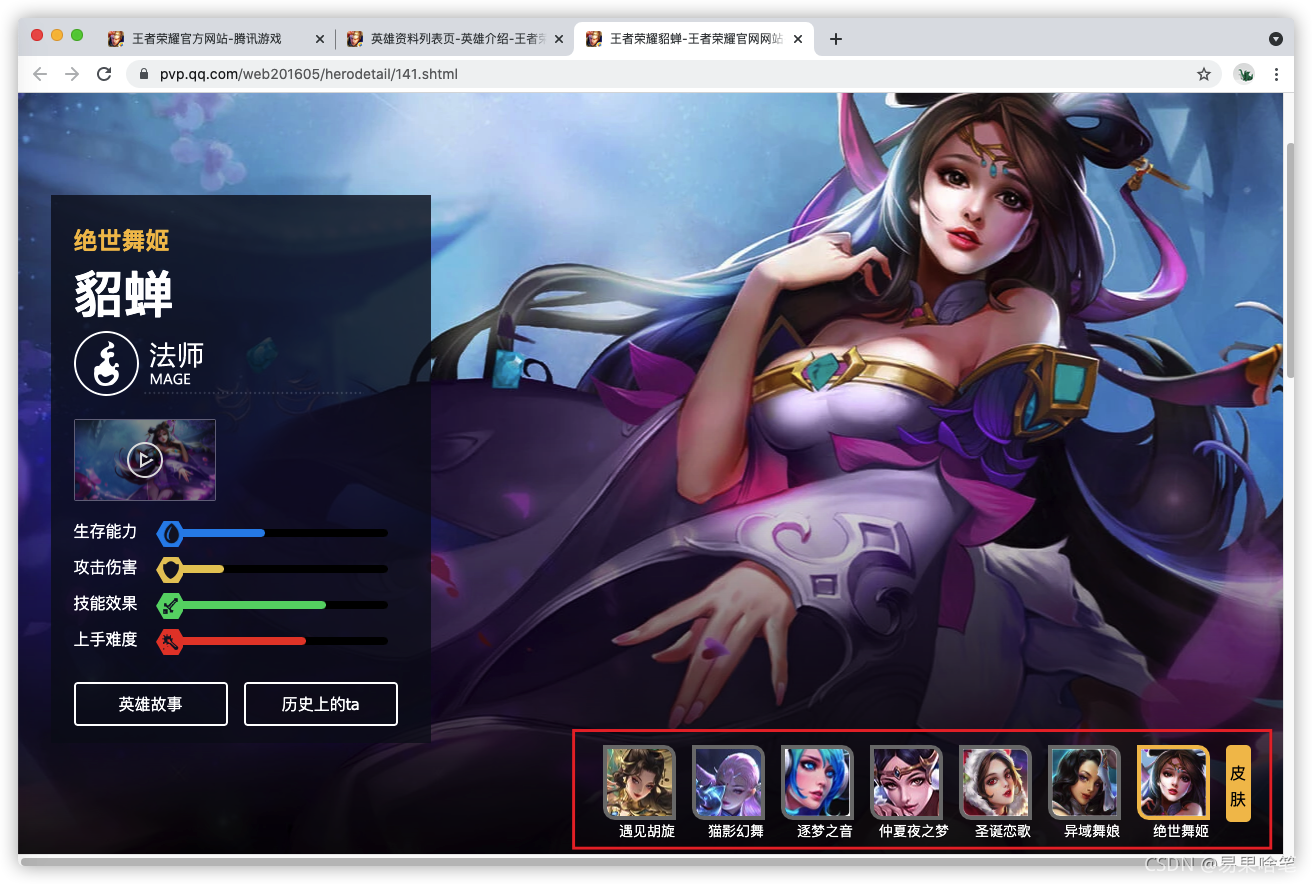
如上圖,我們看到了貂蟬的所有皮膚, 現在我們要找到這些皮膚的url地址,滑鼠放至皮膚圖片處,在谷歌瀏覽器中,按F12調出開發者工具,可以看到如下內容:
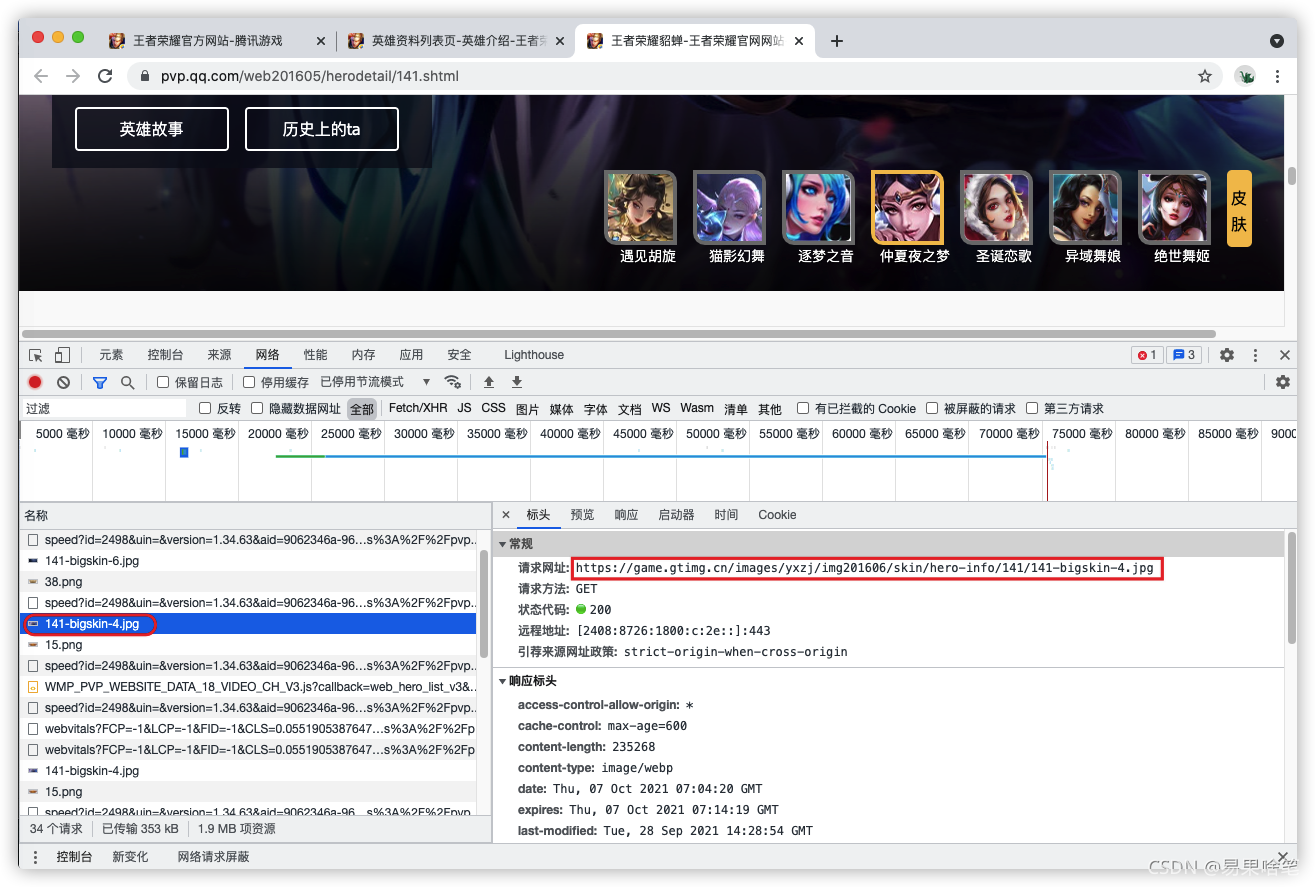
我們找到了這個皮膚的url地址:
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-7.jpg”
再換一個皮膚試試:
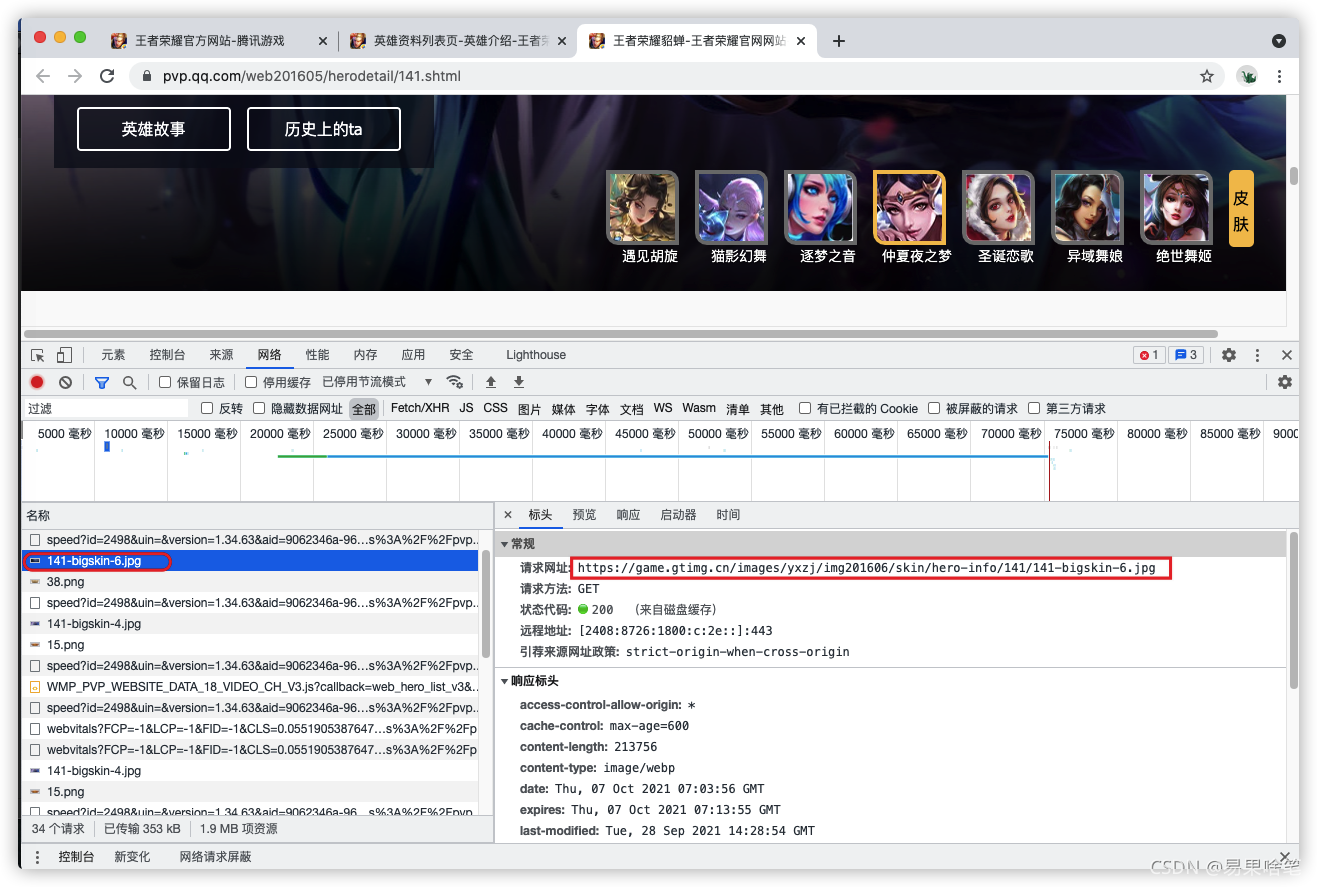
她的url地址為:
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-6.jpg”
對比這兩張皮膚圖片的url地址:
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-7.jpg”
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-6.jpg”
我們發現,這兩個url地址,僅僅是最后一個數字不同,我們猜測,這個數字應該是不同皮膚的某種編號,
接著,我們繼續看看其他英雄的皮膚圖片,如百里守約,同貂蟬的一樣,我們找到了百里的幾個皮膚的url地址如下:
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-2.jpg”
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-3.jpg”
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-4.jpg”
從這三個url地址可以發現,百里的皮膚url地址,也僅僅最后一個數字不同, 同樣,我們猜測這應該代表著百里不同皮膚的編號,
接著,我們對比一下貂蟬和百里的皮膚url地址有何不同:
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/141/141-bigskin-6.jpg”
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/196/196-bigskin-2.jpg”
我們發現,兩個英雄皮膚除了編號(最后一個數字)不同,最大的不同是 /hero-info/ 后面的整數,貂蟬的是141,而百里的是196,據此猜測,這個整數應該是代表的是英雄的編號,至此,我們猜測,所有英雄皮膚的url地址的命名路徑應該長下面這個樣子:
“https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{英雄編號}/{英雄編號}-bigskin-{皮膚編號}.jpg”
地址找到了,現在的問題是,如何找到所有英雄的編號呢?
我們繼續逛逛王者榮耀的官網,找找針對王者里的英雄還有哪些資料可以利用,幾番尋找,我們發現了一個叫 herolist.json 的檔案,
(地址為:https://pvp.qq.com/web201605/js/herolist.json ):
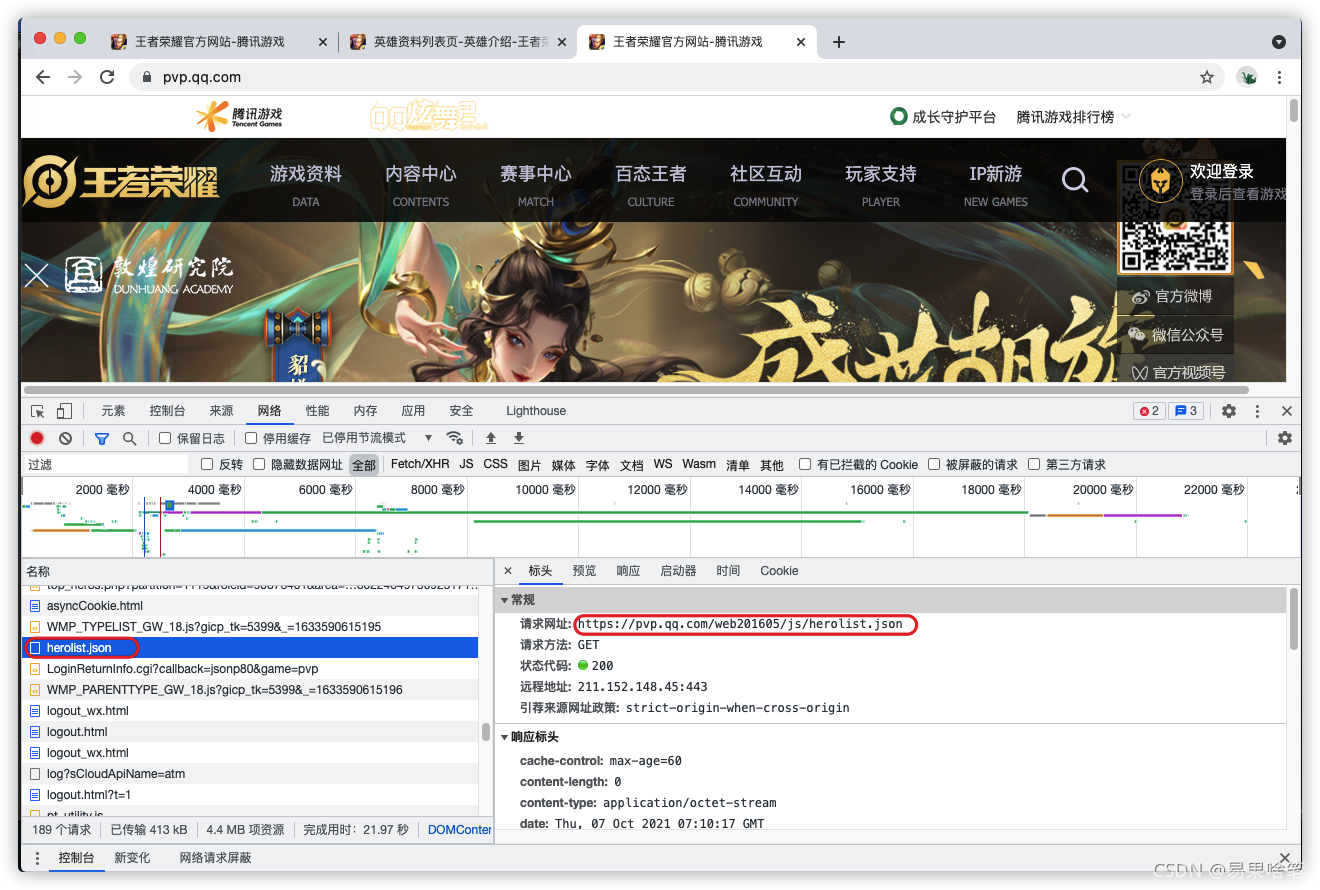
用瀏覽器打開這個json檔案,神奇的事情發生了:
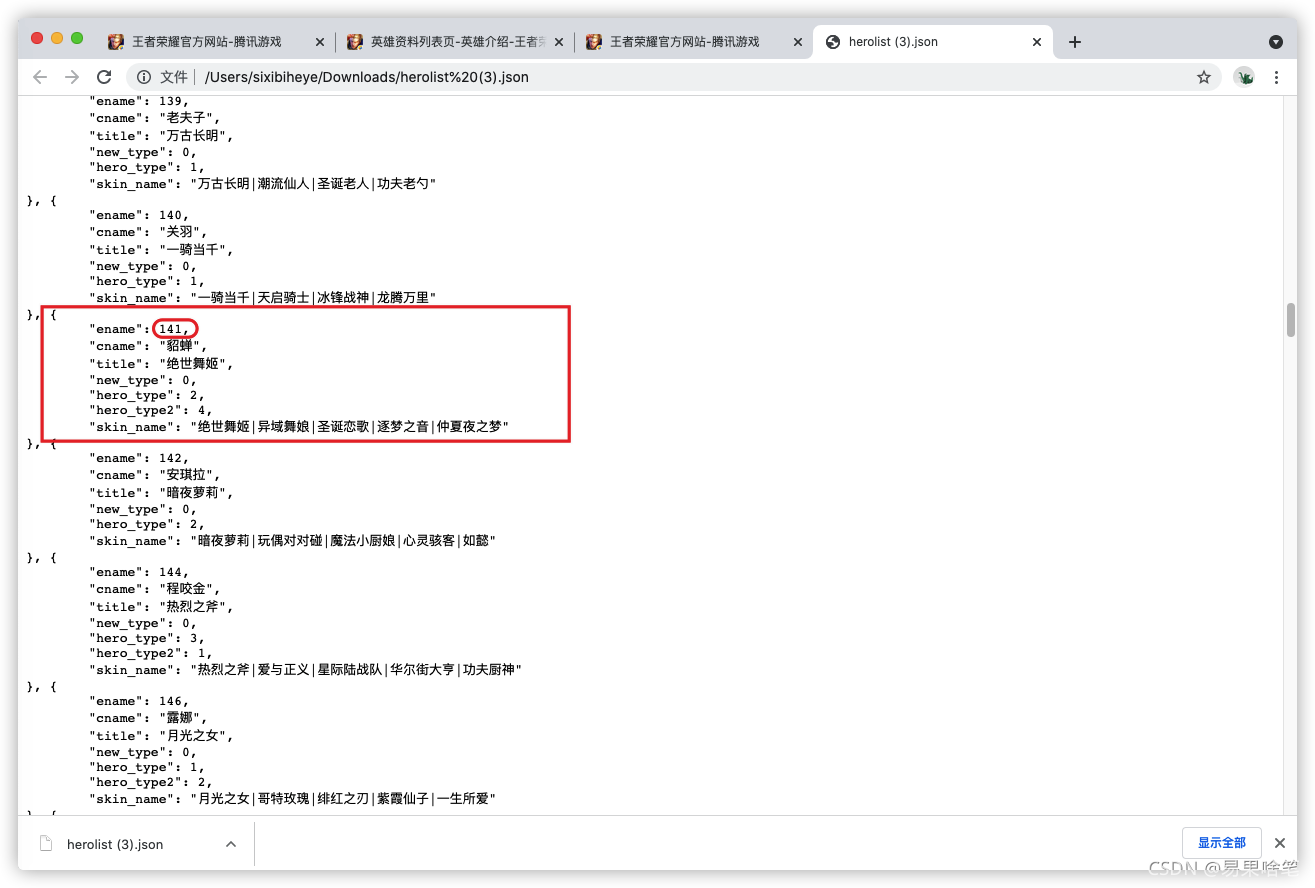
不知道大家對上圖中貂蟬的“ename”屬性的值“141”這個資料還有沒有印象,沒錯!它不正是貂蟬的編號嘛!
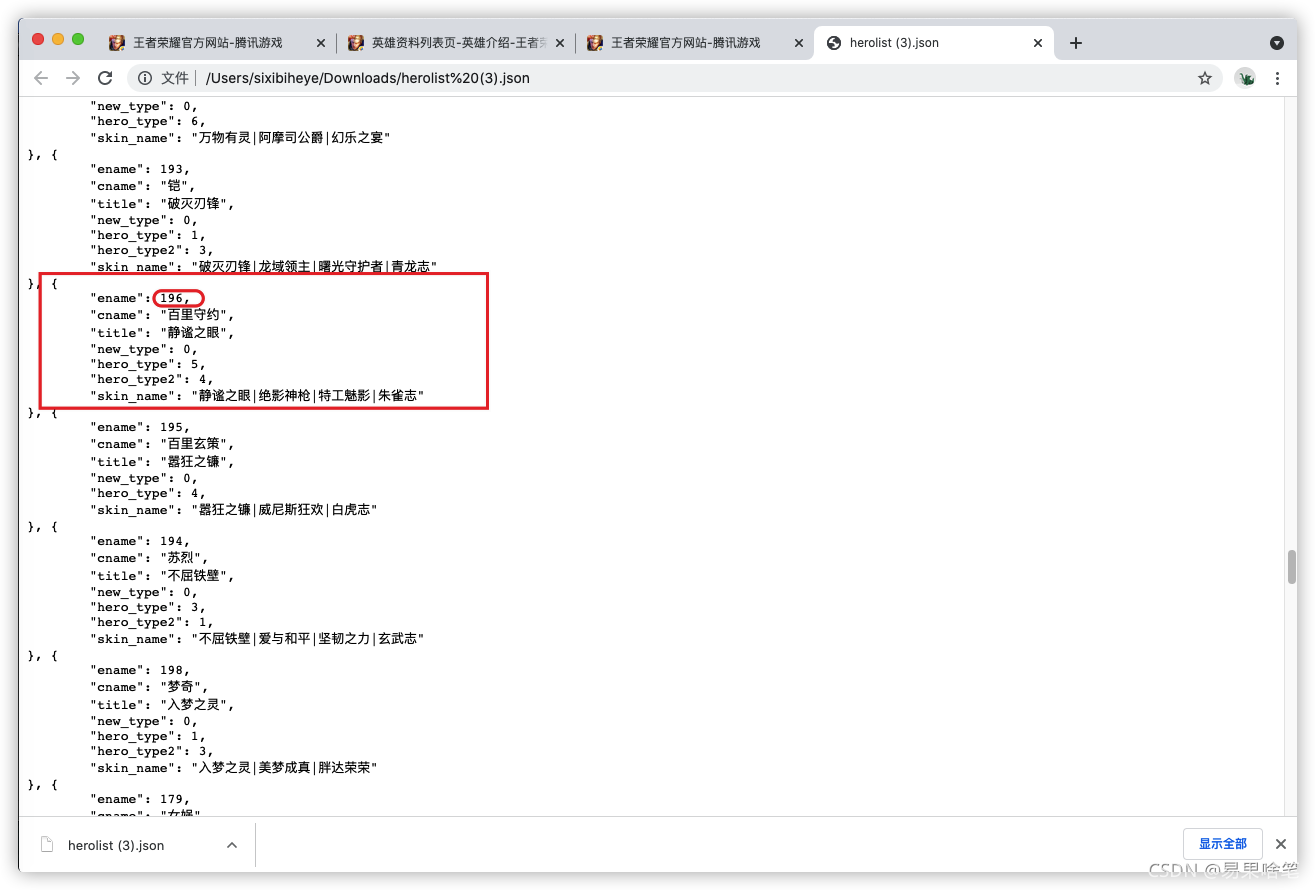
上圖中,百里的編號“196”也印證了我們的猜測,
有了上述的分析,要爬取所有英雄的皮膚圖片,就輕松多了,
在這,我們不使用 python 的 webdriver 等庫,而采用最基礎的 requests 庫來完成我們的爬取作業,代碼如下:
import requests
import os
import json
def download_wzry_hero_picture():
url1 = 'https://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url1).text # 獲取url頁面內容,此處為json文本
dict_hero_info = json.loads(response) # 將json格式的資料轉化為字典
for key in dict_hero_info: # 遍歷字典
name = key['cname'] # 英雄名字
id = key['ename'] # 英雄編號
# 如果沒有skin_name,則輸出:"無圖片"
skin_name_default = key.setdefault('skin_name', '無圖片')
print(skin_name_default)
count = skin_name_default.count('|') # 利用 count() 查詢字符出現的次數
skin_name_list = skin_name_default.split('|') # 利用 split() 分割字符回傳串列
if not os.path.exists(name): # 創建圖片保存的檔案夾
os.mkdir(name)
for i in range(1, count + 1):
# 構造英雄皮膚地址
url2 = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/%s/%s-bigskin-%d.jpg' % (id, id, i)
img = requests.get(url2) # 獲取圖片的二進制資料
print(url2)
pictName = skin_name_list[i]
# 下載并保存圖片
with open(name + '/' + pictName + '.jpg', 'wb') as f:
f.write(img.content) # 寫入圖片
print('成功下載并保存圖片~')
# 程式入口
if __name__ == '__main__':
download_wzry_hero_picture()
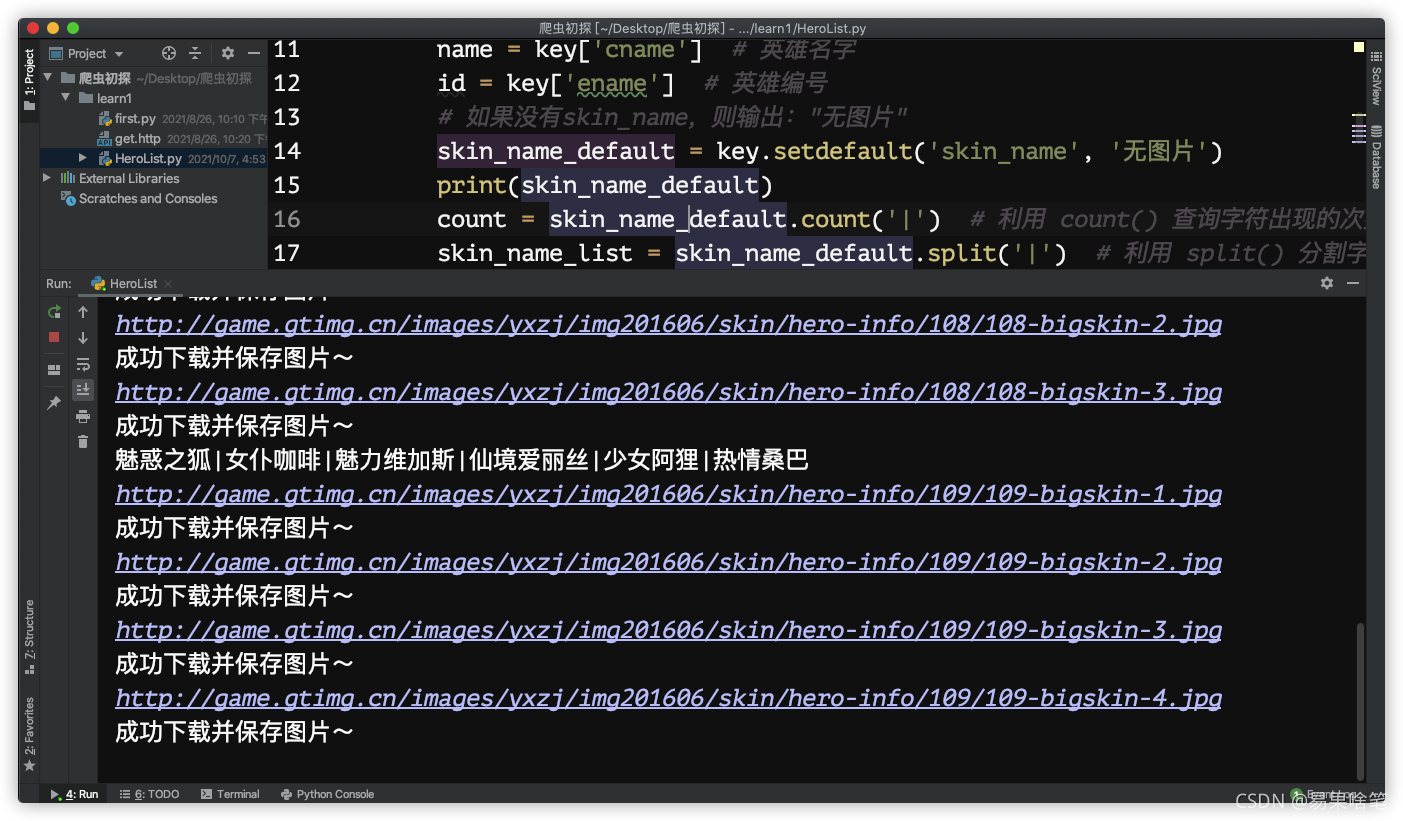
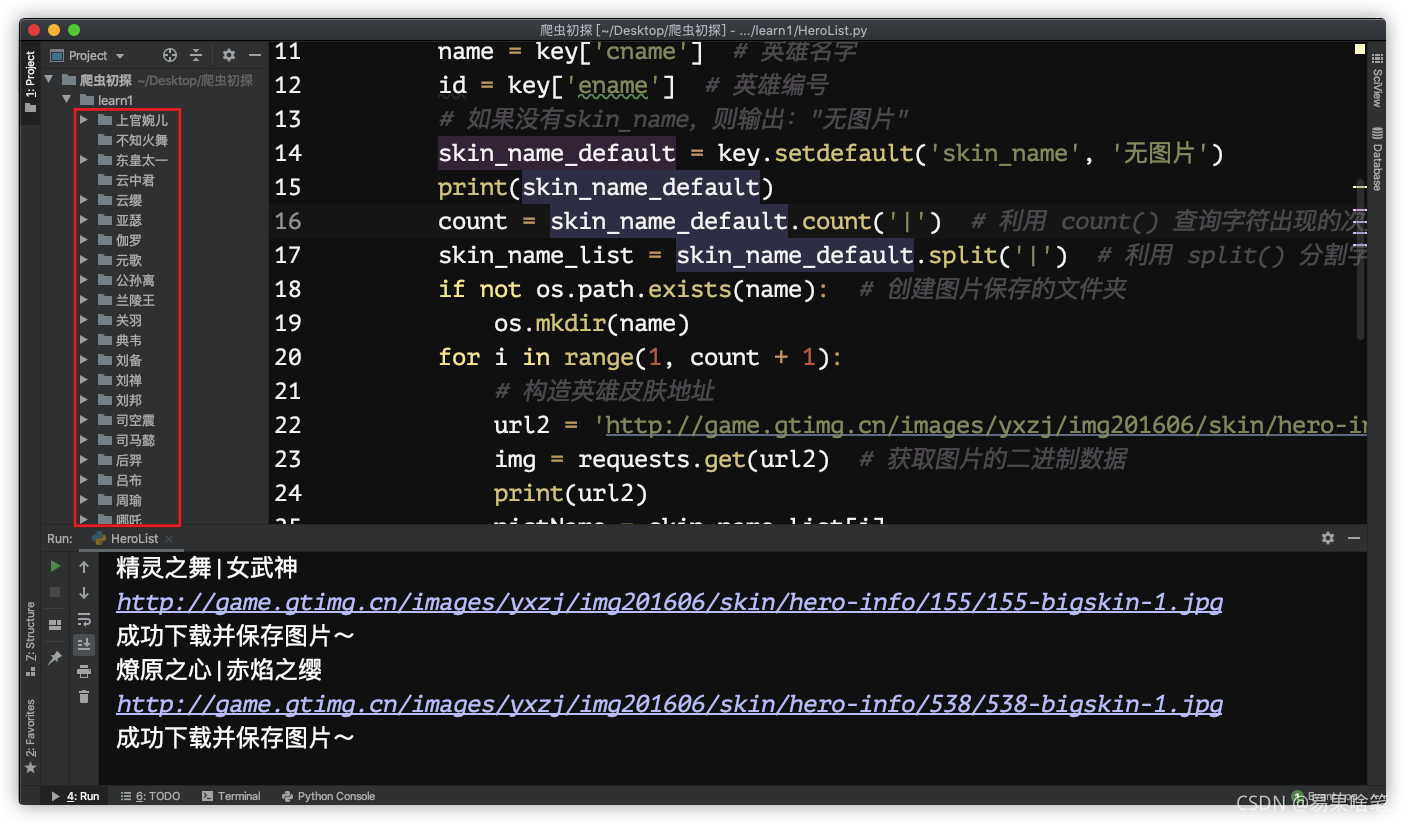
點擊運行,在控制臺可以看到下載進度:
下載完成后,在當前目錄下,我們能看到生成的所有英雄皮膚圖片的檔案夾:
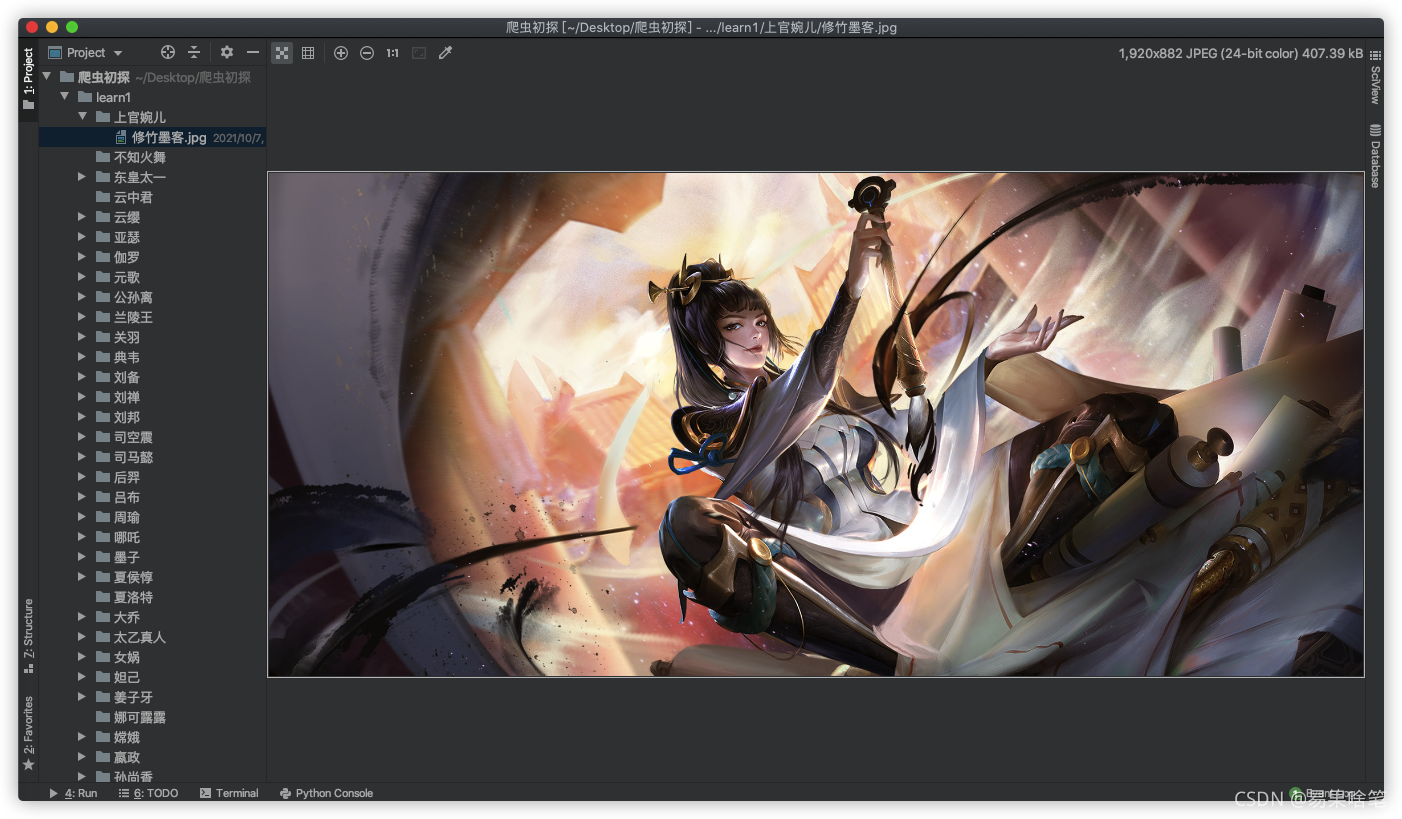
下面,就讓我們盡情的欣賞英雄們的圖片吧~
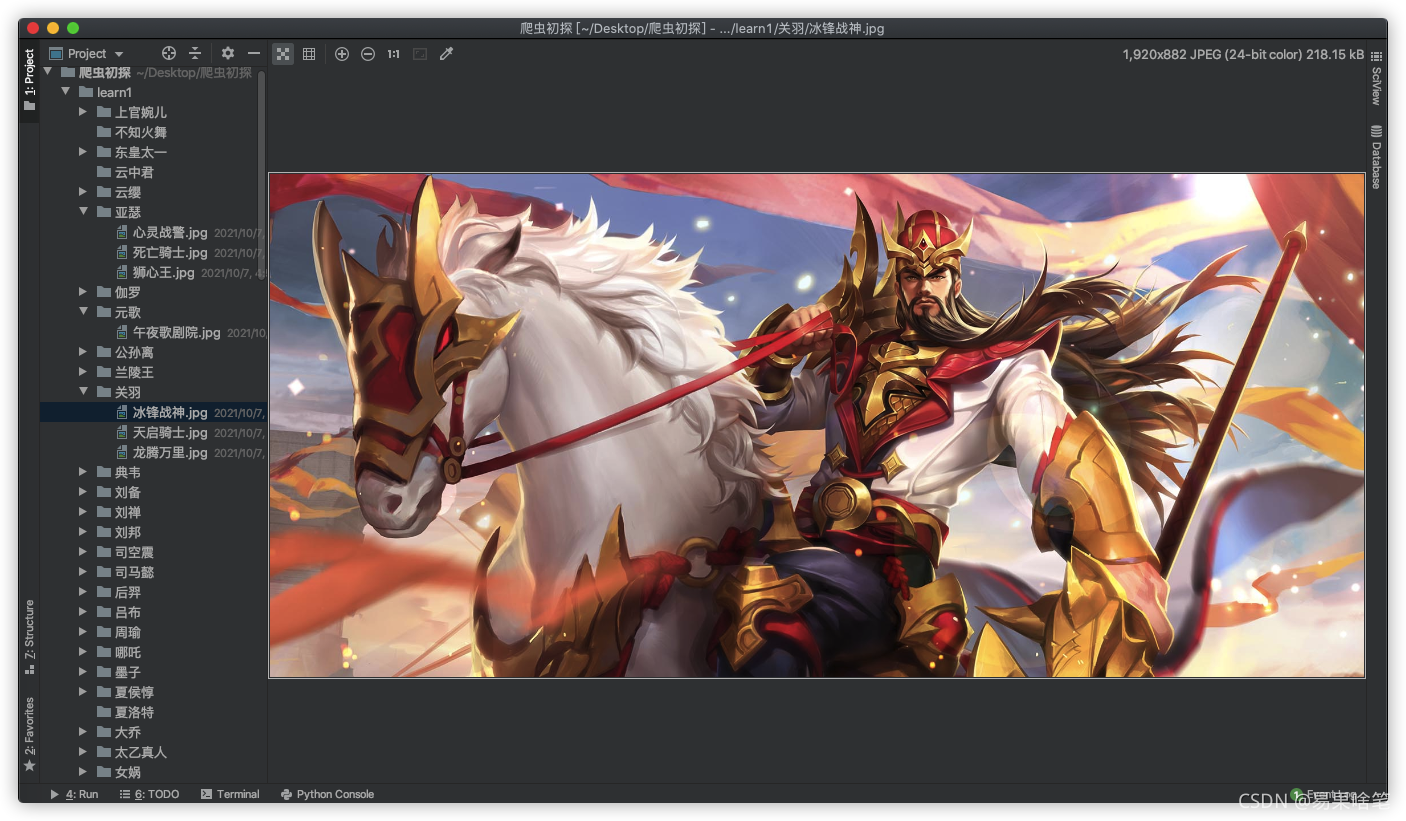
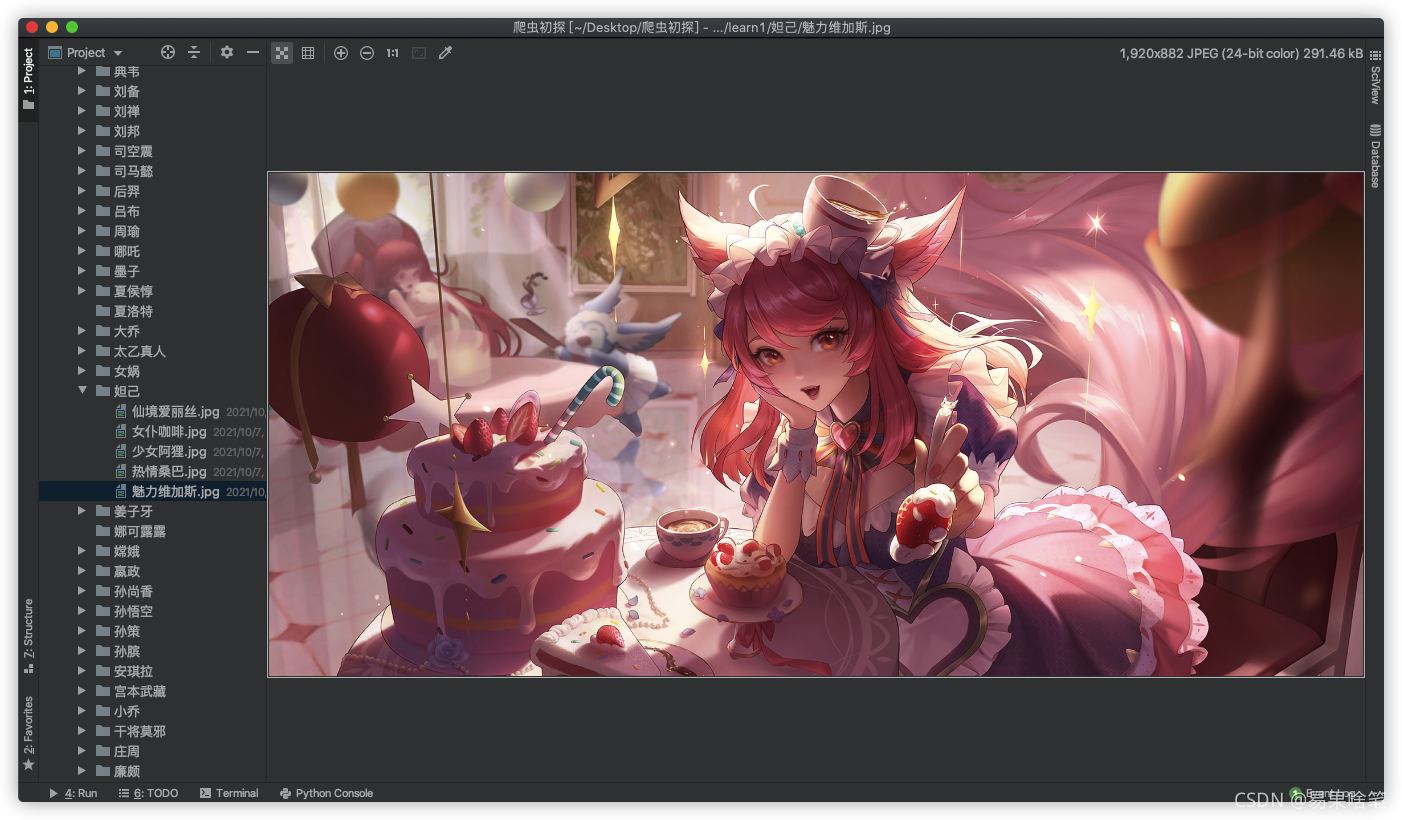
最后,喜歡的小伙伴們點個贊鼓勵支持一下吧~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/306240.html
標籤:python