目錄
- 必須看的前言
- 一、ABTest
- 實作步驟
- 假設檢驗
- 如何判斷一個樣本統計量符合什么分布?
- 不同分布的拒絕域
- 對稱型(Z分布、t分布)
- 非對稱型(卡方分布、F分布)
- 二、專案實戰
- 1 資料預處理
- 2 樣本容量檢驗
- 3 假設檢驗
- 3.1 提出零假設和備擇假設
- 3.2 確定檢驗方向
- 3.3 選定統計方法
- 3.3.1 方法一:公式計算
- 3.3.2 方法二:Python函式計算
- 3.3.3 方法三:蒙特卡洛法模擬
- 4 結論
- 結束語
必須看的前言
本文全程干貨,建議朋友們收藏后慢慢閱讀!
另外,我主頁上還有不少與ABTest和資料分析相關的博客,感興趣的朋友可以再去看看,希望能給你帶來識訓!
一、ABTest
ABTest類似于以前的對比實驗,是讓組成成分相同(相似)的群組在同一時間維度下去隨機的使用一個方案(方案A、或者B、C…),收集各組用戶體驗資料和業務資料,最后分析出哪個方案最好,
實作步驟
- 現狀分析:分析業務資料,確定當前最關鍵的改進點,
- 假設建立:根據現狀分析作出優化改進的假設,提出優化建議,
- 設定目標:設定主要目標,用來衡量各優化版本的優劣;設定輔助目標,用來評估優化版本對其他方面的影響,
- 設計開發:制作若干個優化版本的設計原型,
- 確定分流方案:使用各類ABTest平臺分配流量,初始階段,優化方案的流量設定可以較小,根據情況逐漸增加流量,注意分流時要盡可能做到沒有區別,
- 采集資料:通過各大平臺自身的資料收集系統自動采集資料,
- 分析ABTest結果:統計顯著性達到95%或以上并且維持一段時間,實驗可以結束;如果在95%以下,則可能需要延長測驗時間;如果很長時間統計顯著性不能達到95%甚至90%,則需要決定是否中止試驗或重新設計方案,
PS: 先說一下,這里的實作步驟并非權威步驟,不是一定要這么劃分,
假設檢驗
要想充分搞懂ABTest,必須理解它的原理——假設檢驗,
在一個設計適當的 ABTest中,處理 A 和處理 B 之間任何可觀測到的差異,必定是由下面兩個因素之一所導致的,
- 分配物件中的隨機可能性
- 處理 A 和處理 B 之間的真實差異
假設檢驗是對 ABTest(或任何隨機實驗)的進一步分析,意在評估隨機性是否可以合理地解釋 A 組和 B 組之間觀測到的差異,
這里需要介紹一下幾個專業術語:
- 零假設:完全歸咎于偶然性的假設,即各個處理是等同的,并且組間差異完全是由偶然性所導致的,
事實上,我們希望能證明零假設是錯誤的,并證明 A 和 B 結果之間的差異要比偶然性可能導致的差異更大, - 備擇假設:與零假設相反,即實驗者希望證實的假設,
- 單向檢驗:在假設檢驗中,只從一個方向上計數偶然性結果,簡單來講就是最終只需判斷大于或者只需判斷小于,
- 雙向檢驗:在假設檢驗中,從正反兩個方向上計數偶然性結果,
假設檢驗的基本思想是“小概率事件”原理,其統計推斷方法是帶有某種概率性質的反證法,小概率思想是指小概率事件在一次試驗中基本上不會發生,反證法思想是先提出檢驗假設,再用適當的統計方法,利用小概率原理,確定假設是否成立,對于不同的問題,檢驗的顯著性水平α不一定相同,一般認為,事件發生的概率小于0.1、0.05或0.01等,即“小概率事件”,但是,如果說你犯下第一類錯誤(即拒絕正確的假設: H 0 H_0 H0?是真,但拒絕 H 0 H_0 H0?)的成本越高,你的α值就要設定得越小,
接下來介紹假設檢驗的基本步驟:
- 提出零假設和備擇假設;
- 根據備擇假設確定檢驗方向;
簡單來說含有不等號的是雙向檢驗,反之則是單向檢驗; - 選定統計方法,根據資料的型別和特點,可分別選用Z檢驗、T檢驗,秩和檢驗和卡方檢驗等;
- 選定顯著性水平α,但記住判斷結論時不能絕對化,應注意無論接受或拒絕檢驗假設,都有判斷錯誤的可能性,
如何判斷一個樣本統計量符合什么分布?
如何選定統計方法?那就得判斷你的樣本統計量符合什么分布了,
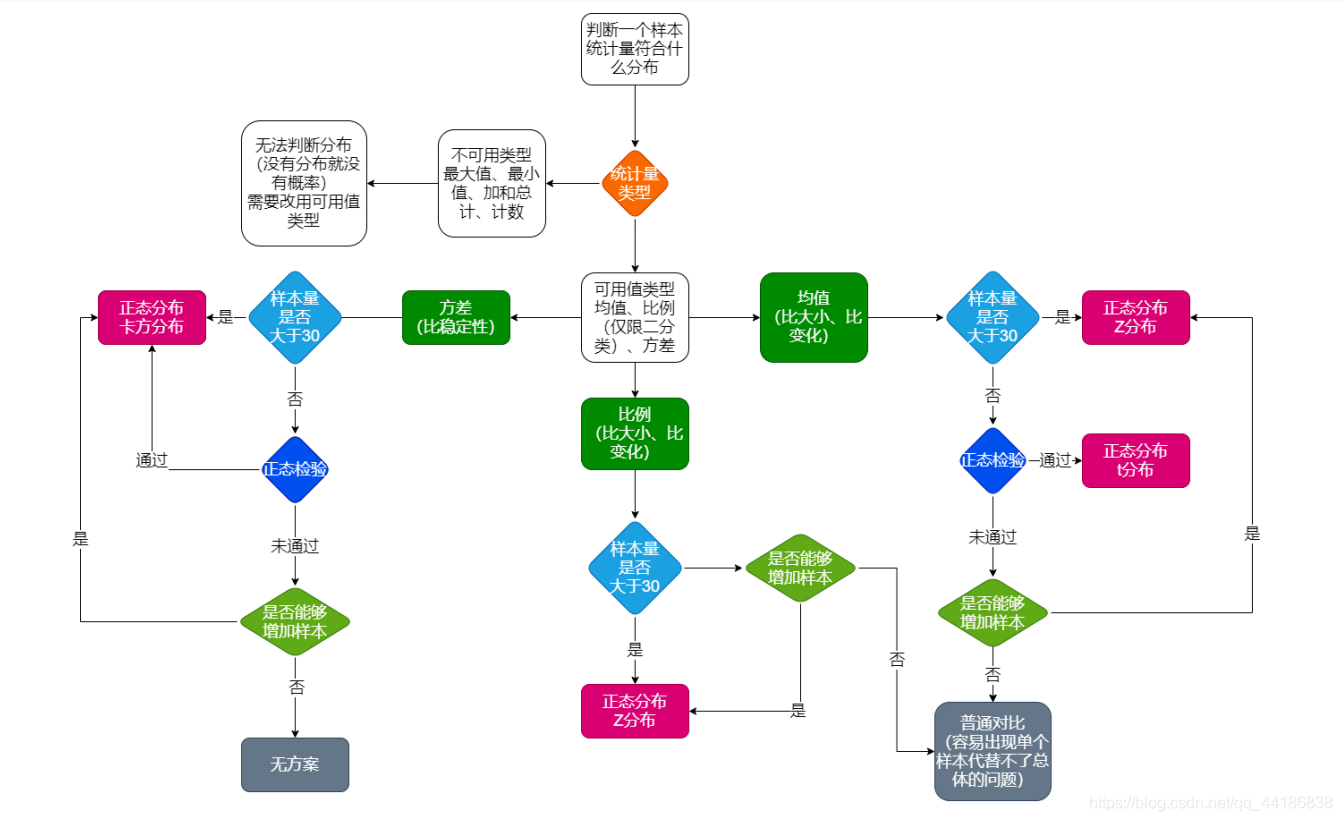
上圖就是判斷一個樣本統計量符合什么分布的流程圖,非常nice!
下面呢,則是關于Z分布,T分布,卡方分布的簡單了解,其中注意考慮多個總體問題時如何計算處理,

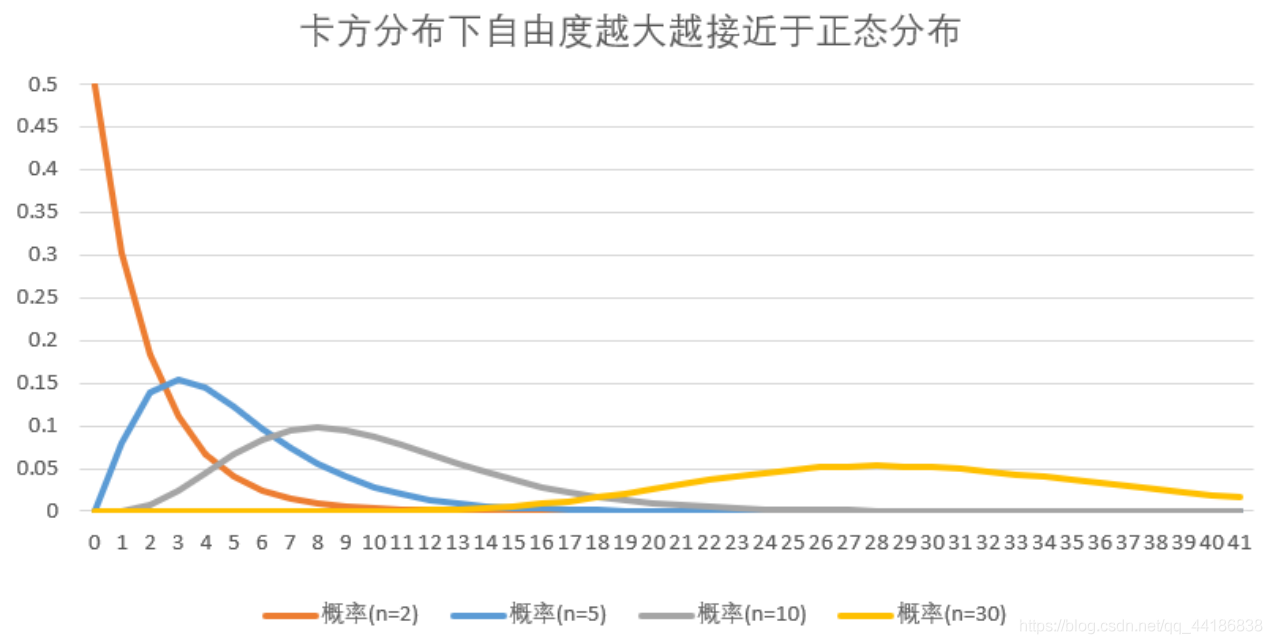
接下來再看一下這幾種分布的概率密度分布圖,
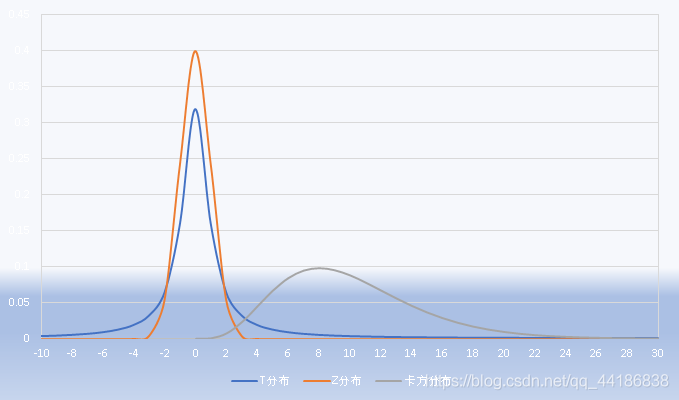
可以看出,T分布與標準正態分布(Z分布)都是以0為對稱的分布,T分布的方差大所以分布形態更扁平些,
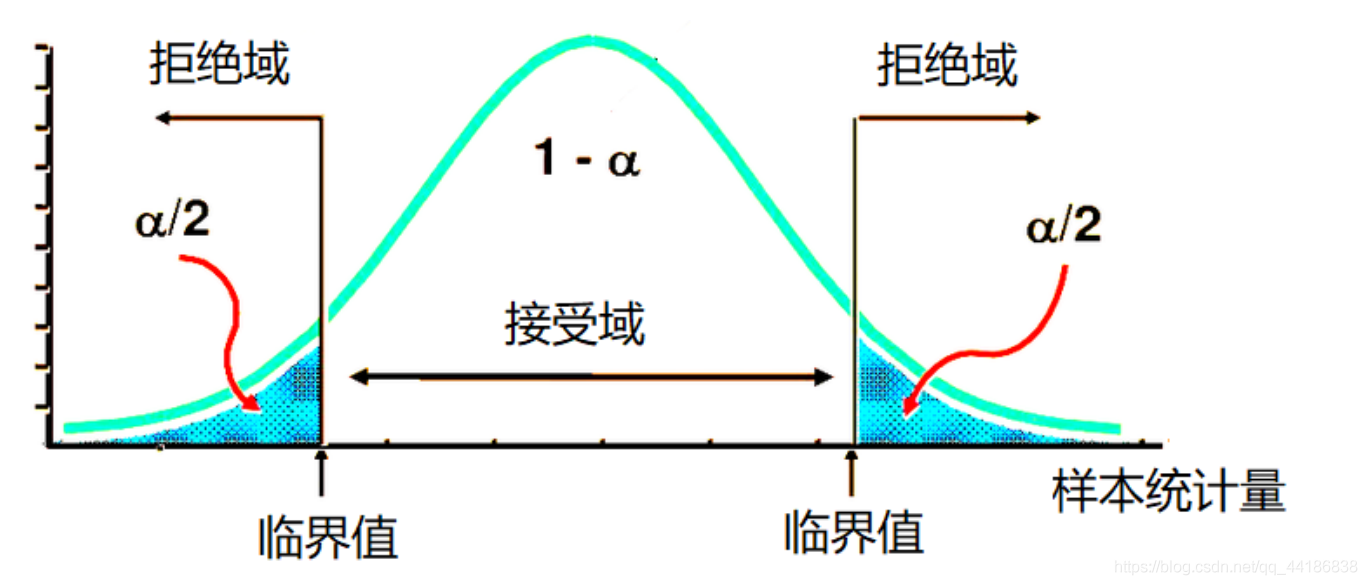
不同分布的拒絕域
對稱型(Z分布、t分布)
雙側檢驗:
單側檢驗:
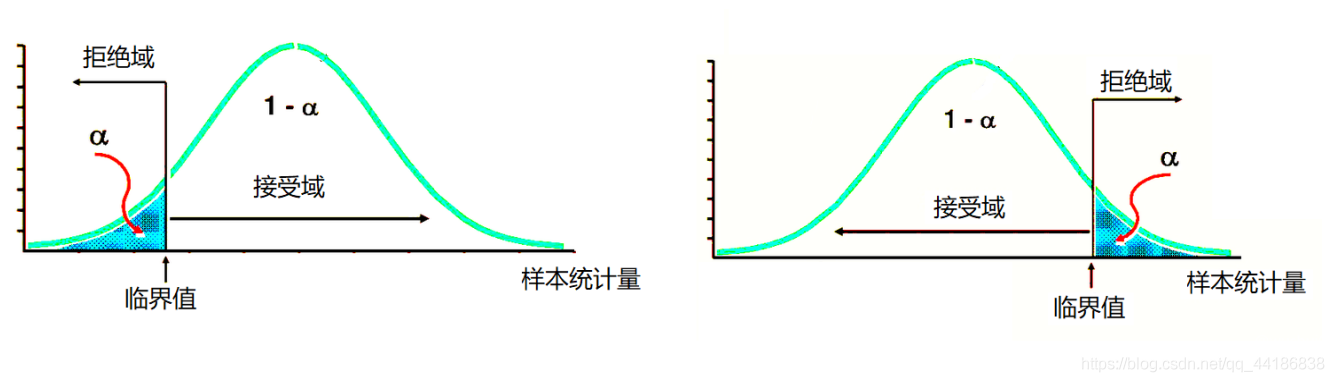
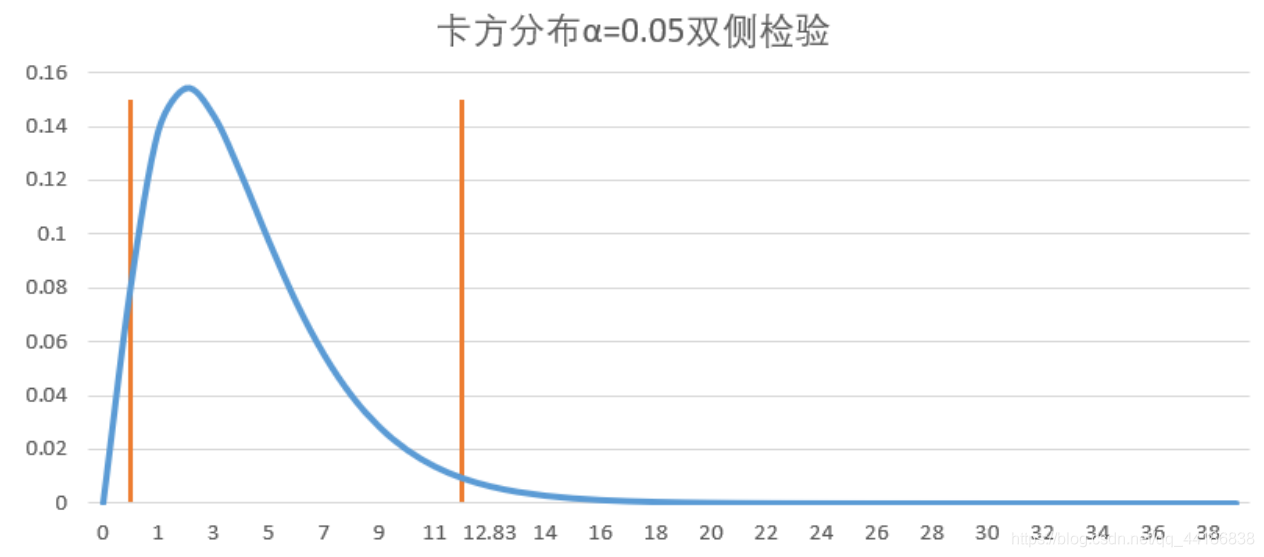
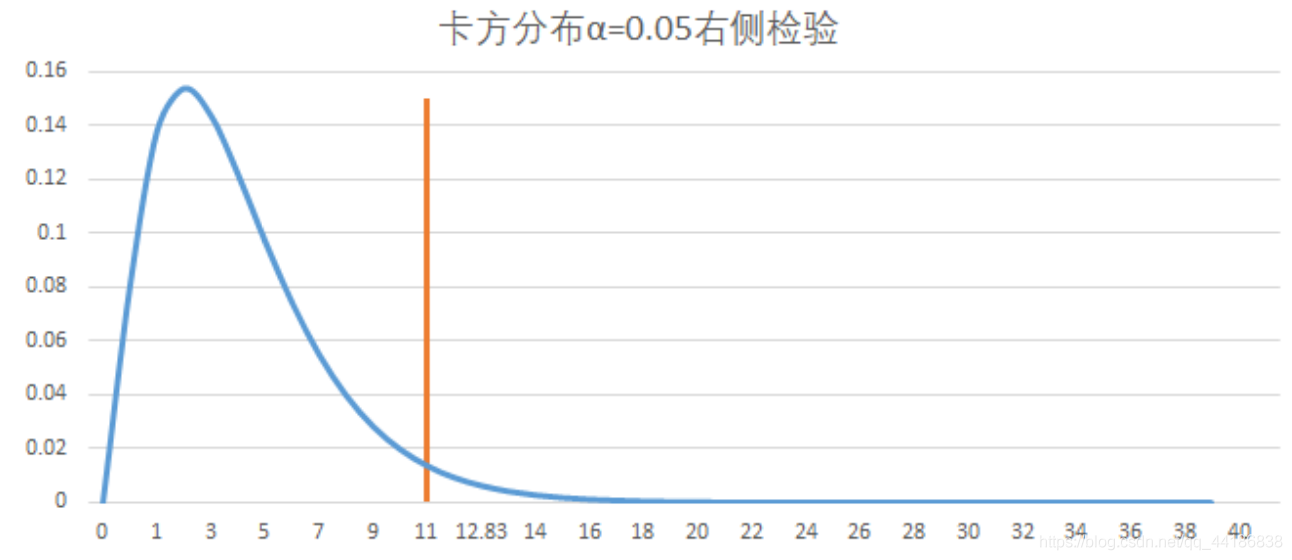
非對稱型(卡方分布、F分布)
卡方分布:
拒絕域:
(卡方分布在左側的拒絕域特別小,所以拒絕的區間的值也比較少),所以卡方檢驗的拒絕域一般
放在右側,F分布同理,
二、專案實戰
專案來源:
https://tianchi.aliyun.com/dataset/dataDetail?dataId=50893
資料介紹:
從支付寶的兩個營銷活動中收集的真實資料集,該資料集包含支付寶中的兩個商業定位活動日志,由于隱私問題,資料被采樣和脫敏,雖然該資料集的統計結果與支付寶的實際規模有偏差,但不影響解決方案的適用性,
主要提供了三個資料集:
- emb_tb_2.csv: 用戶特征資料集,
- effect_tb.csv: 廣告點擊情況資料集,
- seed_cand_tb.csv: 用戶型別資料集,
本分析報告的主要使用廣告點擊情況資料,涉及欄位如下:
- dmp_id:營銷策略編號(這里我們這么設定1為對照組,2為營銷策略一,3為營銷策略二),
- user_id:支付寶用戶ID,
- label:用戶當天是否點擊活動廣告(0:未點擊,1:點擊),
接下來正式開始實戰,
1 資料預處理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
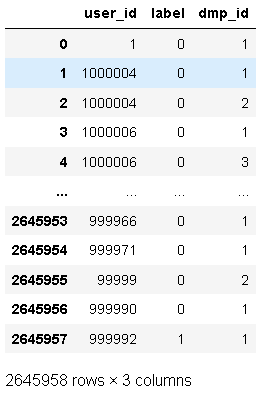
data = pd.read_csv('effect_tb.csv',header = None)
data.columns = ['dt','user_id','label','dmp_id'] # 檔案中沒有欄位名
# 日志天數屬性用不上,洗掉該列
data = data.drop(columns='dt')
data
data.info(null_counts = True)
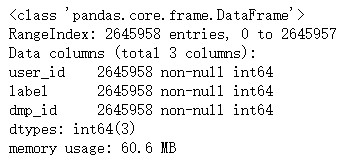
查看資料統計情況,主要是看dmp_id,
data.describe()
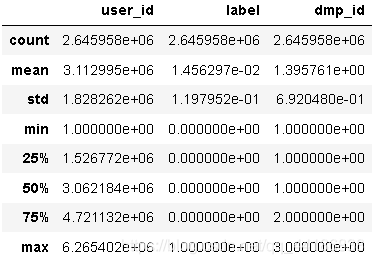
接下來查看資料重復情況,
data[data.duplicated(keep = False)]
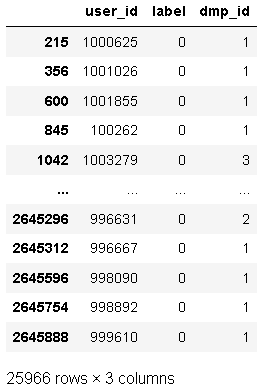
存在重復項,需要進行去重,
data = data.drop_duplicates()
# 檢查是否還有重復項
data[data.duplicated(keep = False)]

從先前操作已知資料型別正常,接下來利用透視表來看各屬性是否存在不合理情況,
data.pivot_table(index = 'dmp_id',columns = 'label',values = 'user_id',aggfunc = 'count')
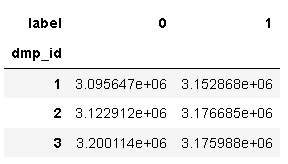
從以上看出屬性欄位無例外取值,無需進行處理,
2 樣本容量檢驗
在進行ABTest前,需檢查樣本容量是否滿足試驗所需最小值,
這里需要借助樣本量計算工具:https://www.evanmiller.org/ab-testing/sample-size.html
首先需要設定點擊率基準線以及最小提升比例,我們將對照組的點擊率設為基準線,
data[data["dmp_id"] == 1]["label"].mean()
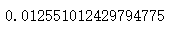
對照組的點擊率為1.26%,假設我們希望新的營銷策略能夠讓廣告點擊率至少提升一個百分點,則算得所需最小樣本量為2167,
data["dmp_id"].value_counts()
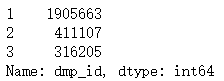
可得411107和316205遠大于2167,滿足最小樣本量需求,
3 假設檢驗
我們先查看一下這三種營銷策略的點擊率情況,
print("對照組: " ,data[data["dmp_id"] == 1]["label"].describe())
print("策略一: " ,data[data["dmp_id"] == 2]["label"].describe())
print("策略二: " ,data[data["dmp_id"] == 3]["label"].describe())
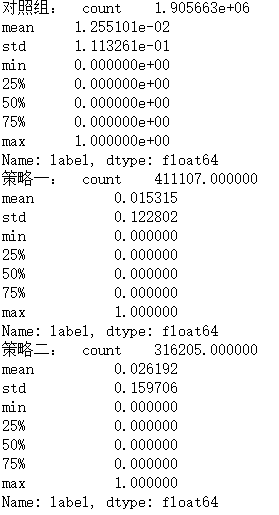
可以看到策略一和策略二相比對照組在點擊率上都有不同程度的提升,
其中策略一提升0.2個百分點,策略二提升1.3個百分點,只有策略二滿足了前面我們對點擊率提升最小值的要求,
接下來需要進行假設檢驗,看策略二點擊率的提升是否顯著,
3.1 提出零假設和備擇假設
設對照組點擊率為 p 1 p_1 p1?,策略二點擊率為 p 2 p_2 p2?,則:
- 零假設 H 0 H_0 H0?: p 1 p_1 p1?>= p 2 p_2 p2?,即 p 1 p_1 p1?- p 2 p_2 p2?>=0;
- 備擇假設 H 1 H_1 H1?: p 1 p_1 p1?< p 2 p_2 p2?,即 p 1 p_1 p1?- p 2 p_2 p2?<0,
3.2 確定檢驗方向
由備擇假設可以看出,檢驗方向為單項檢驗(左),
3.3 選定統計方法
由于樣本較大,故采用Z檢驗,此時檢驗統計量的公式如下: z = p 1 ? p 2 ( 1 n 1 + 1 n 2 ) × p c × ( 1 ? p c ) z= \frac{p_1-p_2}{\sqrt{( \frac{1}{n_1}+\frac{1}{n_2})\times p_c \times (1-p_c)}} z=(n1?1?+n2?1?)×pc?×(1?pc?) ?p1??p2??其中 p c p_c pc?為總和點擊率,
3.3.1 方法一:公式計算
# 用戶數
n1 = len(data[data.dmp_id == 1]) # 對照組
n2 = len(data[data.dmp_id == 3]) # 策略二
# 點擊數
c1 = len(data[data.dmp_id ==1][data.label == 1])
c2 = len(data[data.dmp_id ==3][data.label == 1])
# 計算點擊率
p1 = c1 / n1
p2 = c2 / n2
# 總和點擊率(點擊率的聯合估計)
pc = (c1 + c2) / (n1 + n2)
print("總和點擊率pc:", pc)
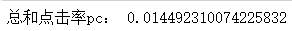
# 計算檢驗統計量z
z = (p1 - p2) / np.sqrt(pc * (1 - pc)*(1/n1 + 1/n2))
print("檢驗統計量z:", z)
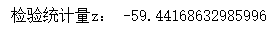
這里我去
α
\alpha
α為0.05,此時我們利用python提供的scipy模塊,查詢
α
=
0.5
\alpha=0.5
α=0.5時對應的z分位數,
from scipy.stats import norm
z_alpha = norm.ppf(0.05)
# 若為雙側,則norm.ppf(0.05/2)
z_alpha
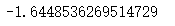
z
α
=
?
1.64
z_\alpha = -1.64
zα?=?1.64, 檢驗統計量z = -59.44,該檢驗為左側單尾檢驗,拒絕域為{z<
z
α
z_\alpha
zα?},z=-59.44落在拒絕域,
所以我們可以得出結論:在顯著性水平為0.05時,拒絕原假設,策略二點擊率的提升在統計上是顯著的,
假設檢驗并不能真正的衡量差異的大小,它只能判斷差異是否比隨機造成的更大,因此,我們在報告假設檢驗結果的同時,應給出效應的大小,對比平均值時,衡量效應大小的常見標準之一是Cohen’d,中文一般翻譯作科恩d值:
d
=
樣
本
1
平
均
值
?
樣
本
2
平
均
值
標
準
差
d=\frac{樣本_1平均值-樣本_2平均值}{標準差}
d=標準差樣本1?平均值?樣本2?平均值?
這里的標準差,由于是雙獨立樣本的,需要用合并標準差(pooled standard deviations)代替,也就是以合并標準差為單位,計算兩個樣本平均值之間相差多少,雙獨立樣本的合并標準差可以如下計算:
s
=
(
(
n
1
?
1
)
×
s
1
2
+
(
n
2
?
1
)
×
s
2
2
)
n
1
+
n
2
?
2
s=\frac{((n_1-1)\times s^2_1+(n_2-1)\times s^2_2)}{n_1+n_2-2}
s=n1?+n2??2((n1??1)×s12?+(n2??1)×s22?)?
其中s是合并標準差,n1和n2是第一個樣本和第二個樣本的大小,s1和s2是第一個和第二個樣本的標準差,減法是對自由度數量的調整,
# 合并標準差
std1 = data[data.dmp_id ==1].label.std()
std2 = data[data.dmp_id ==3].label.std()
s = np.sqrt(((n1 - 1)* std1**2 + (n2 - 1)* std2**2 ) / (n1 + n2 - 2))
# 效應量Cohen's d
d = (p1 - p2) / s
print('Cohen\'s d為:', d)
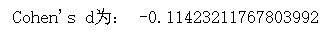
一般上Cohen’s d取值0.2-0.5為小效應,0.5-0.8中等效應,0.8以上為大效應,
3.3.2 方法二:Python函式計算
import statsmodels.stats.proportion as sp
# alternative='smaller'代表左尾
z_score, p = sp.proportions_ztest([c1, c2], [n1,n2], alternative = "smaller")
print("檢驗統計量z:",z_score,",p值:", p)
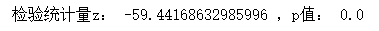
用p值判斷與用檢驗統計量z判斷是等效的,這里p值為0,同樣也拒絕零假設,
至此,我們可以給出報告:
- 對照組的點擊率為:0.0126,標準差為:0.11
- 策略二的點擊率為:0.0262,標準差為:0.16
- 獨立樣本z=-59.44,p=0,單尾檢驗(左),拒絕零假設,
- 效應量Cohen’s d= -0.11,較小,
根據前面案例,我們用的是兩個比率的z檢驗函式proportion.proportions_ztest,輸入的是兩組各自的總數和點擊率;如果是一般性的z檢驗,可以用weightstats.ztest函式,直接輸入兩組的具體數值,可參考https://www.statsmodels.org/stable/generated/statsmodels.stats.weightstats.ztest.html
import statsmodels.stats.weightstats as sw
z_score1, p_value1 = sw.ztest(data[data.dmp_id ==1].label, data[data.dmp_id ==3].label, alternative='smaller')
print('檢驗統計量z:', z_score1, ',p值:', p_value1)
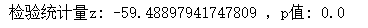
可以看到計算結果很接近,但是有點差異,因為非比率的z檢驗是不計算聯合估計的,
作為補充,我們再檢驗下策略一的點擊率提升是否顯著,
z_score, p = sp.proportions_ztest([c1, len(data[data.dmp_id ==2][data.label == 1])],[n1, len(data[data.dmp_id ==2])], alternative = "smaller")
print('檢驗統計量Z:',z_score,',p值:',p)
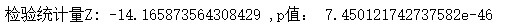
p值約為 7.450121742737582e-46,p<α,但是因為前面我們設定了對點擊率提升的最小要求(1%),這里仍然只選擇第二組策略進行推廣,
3.3.3 方法三:蒙特卡洛法模擬
蒙特卡洛法其實就是模擬法,用計算機模擬多次抽樣,獲得分布,
在零假設成立(p1>=p2)的前提下, p1=p2 為臨界情況(即零假設中最接近備擇假設的情況),如果連相等的情況都能拒絕,那么零假設的剩下部分( p1>p2)就更能夠拒絕了,
定義effect_tb.csv中樣本的總點擊率為 p_all:
p_all = data.label.mean()
print('p_all:', p_all)
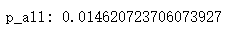
我們進行一次模擬,以 p_all 為對照組和策略二共同的點擊率,即取p_old=p_new=p_all,分別進行n_old次和n_new次二點分布的抽樣,使模擬的樣本大小同effect_tb.csv中的樣本大小相同:
choice1 = np.random.choice(2, size=n1, p=[1-p_all, p_all])
choice2 = np.random.choice(2, size=n2, p=[1-p_all, p_all])
diff = choice1.mean() - choice2.mean()
print('對照組結果:', choice1, ',策略二結果:', choice2, ',模擬的轉化率差值:', diff)
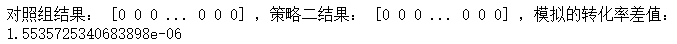
因為是隨機抽樣,所以每次模擬的點擊率差值也是不同的,多運行幾次就會發現,我們模擬出的結果很難比effect_tb.csv中樣本的點擊率差值更小,這說明了什么?
# 計算effect_tb.csv樣本的點擊率差值
data_diff = data[data["dmp_id"] == 1]["label"].mean()-data[data["dmp_id"] == 3]["label"].mean()
print('effect_tb.csv樣本的點擊率差值:', data_diff)
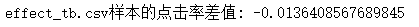
按照如上方式進行多次模擬,這里我們進行10000次,并計算出每個樣本得到的策略點擊率差值,將其存盤在diffs中:
diffs=[]
for i in range(10000):
p2_diff = np.random.choice(2,size=n2,p=[1-p_all,p_all]).mean()
p1_diff = np.random.choice(2,size=n1,p=[1-p_all,p_all]).mean()
diffs.append(p1_diff - p2_diff)
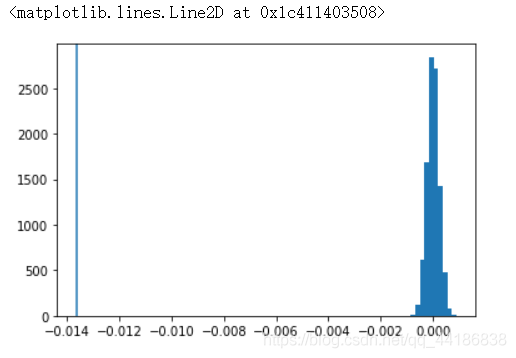
實際上每次模擬都得到了一個大小為316205的樣本,此處得到了10000個樣本,在圖上將模擬得到的diffs繪制為直方圖,將effect_tb.csv中樣本的點擊率差值繪制為豎線:
diffs = np.array(diffs)
plt.hist(diffs)
plt.axvline(data_diff)
在diffs串列的數值中,有多大比例小于effect_tb.csv中觀察到的點擊率率差值?
(diffs < data_diff).mean()
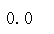
本次方法得到的答案是0,和方法二中的P值接近(一樣),
上圖的含義是,在p_old=p_new時,進行10000次模擬得到的差值中,0%的可能比effect_tb.csv中的差值更極端,說明effect_tb.csv在p_old=p_new的前提是很小概率(這次是0概率)事件,反過來說,我們只做了一次ABTest就得到了零假設中的極端情況,則零假設很有可能是不成立的,
- 現在圖中的直方圖是,若對照組和策略二的點擊率相等,隨機10000次,兩者的差值的分布,
- 因為次數夠多,根據大數定律,近似于真實的分布,
- 越靠近中間的部分,說明該數值出現的次數越多,越靠近兩側,說明該數值出現的越少,也可以說情況就越極端,
- 豎線是樣本effect_tb.csv的差值所在位置,它落在了很左側,體現在豎線左側的面積(這次為0)很小,
- 豎線左側的面積占比,即發生“豎線及豎線左側極端情況”(diff<=-0.014)的可能性,
- 也就是說,effect_tb.csv這個樣本,在對照組和策略二點擊率相等的情況下,有可能出現,但出現的可能性很小(這次為0),
- 所以反推出,對照組和策略二的點擊率很有可能不相等,
思考:
若diffs的分布就是標準正態(這里只是近似),則豎線左側的面積占比其實就是p值(左側or右側or雙側要根據備擇假設給定的方向),那p值到底要多小才算真的小?
這需要我們自己給定一個標準,這個標準其實就是 α,是犯第一類錯誤的上界,常見的取值有0.1、0.05、0.01,
- 所謂第一類錯誤,即拒真錯誤,也就是零假設為真,我們卻拒絕了,所以要取定一個 α ,并規定當p值小于 α 時,認為原假設在該顯著性水平下被拒絕,
- 還有第二類錯誤——取偽,即零假設明明是錯的,但是我們保留了零假設,拒真的可能性越小,則取偽的可能性越大,所以不能一味地取極小的α ,
4 結論
通過三種方法的計算得出,在兩種營銷策略中,策略二對廣告點擊率有顯著提升效果,且相較于對照組點擊率提升了近一倍,因而在兩組營銷策略中應選擇第二組進行推廣,
參考鳴謝:
https://baike.baidu.com/item/AB測驗/9231223?fr=aladdin
https://baike.baidu.com/item/假設檢驗
https://zhuanlan.zhihu.com/p/68019926
《面對資料科學家的實用統計學》
結束語
好文值得收藏!
推薦關注的專欄
👨?👩?👦?👦 機器學習:分享機器學習實戰專案和常用模型講解
👨?👩?👦?👦 資料分析:分享資料分析實戰專案和常用技能整理
CSDN@報告,今天也有好好學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/306435.html
標籤:python
上一篇:趣味Python題目10月8日