??蘇州程式大白一文從基礎手把手教你Python資料可視化大佬??《??記得收藏??》
- 目錄
-
🏳??🌈開講啦!!!!🏳??🌈蘇州程式大白🏳??🌈 - 🌟博主介紹
- 前言
- 資料關系可視化
- 散點圖 Scatter plots
- 折線圖強調連續性 Emphasizing continuity with line plots
- 同時顯示多了圖表
- 資料種類的可視化 Plotting with categorical data
- 散點圖 categories scatterplots
- 分布圖 Distributions of observations within categories
- 合并圖表
- 資料估計
- 圖表的大小控制
- 資料分布的可視化 Visualizing the distribution of a dataset
- 繪制單變數分布圖 Ploting univariate distributions
- 繪制雙變數分布圖 Ploting bivariate distributions
- 可視化資料集中的成對關系 Visualizing pairwise relationships in a dataset
- 線性關系的可視化 Visualizing linear relationships
- 畫線性回歸模型的方法 Functions to draw linear regression models
- 擬合不同種類的資料 Fitting different kinds of models
- 🌟作者相關的文章、資源分享🌟
目錄
| 🏳??🌈開講啦!!!!🏳??🌈蘇州程式大白🏳??🌈 |

🌟博主介紹
💂 個人主頁:蘇州程式大白
🤟作者介紹:中國DBA聯盟(ACDU)成員,CSDN全國各地程式猿(媛)聚集地管理員,目前從事工業自動化軟體開發作業,擅長C#、Java、機器視覺、底層演算法等語言,2019年成立柒月軟體作業室,
💬如果文章對你有幫助,歡迎關注、點贊、收藏(一鍵三連)和C#、Halcon、python+opencv、VUE、各大公司面試等一些訂閱專欄哦
🎗? 承接各種軟體開發專案
💅 有任何問題歡迎私信,看到會及時回復
👤 微信號:stbsl6,微信公眾號:蘇州程式大白
🎯 想加入技術交流群的可以加我好友,群里會分享學習資料
前言
環境搭建:
下載Anaconda搭建Python環境,細講可以看文章
下載類別庫Numpy, SciPy, matplotlib, pandas 和 seaborn,可以參考本文
引入需要的庫,設定一下顯示網格的樣式:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
資料關系可視化
下面我們使用seaborn最常用的方法relplot()實作散點圖scatterplot()和線圖lineplot(),
散點圖 Scatter plots
首先可以引入seaborn中自帶事例子資料集“tips”,這個資料集的屬性有:
-
時間資料 week,
-
賬單: 總消費,小費 total_bill, tips,
-
消費者性別 sex,
-
消費者是否抽煙 smoker,
-
等等…
下面很多例子使用了tips資料集,不會再特別指出
sns.set(style="darkgrid") # 設定樣式為網格
tips = sns.load_dataset("tips")
其實seaborn中有很多畫散點圖的方法其中一種是scatterplot(),使用方法是把資料集中的集合分配給方法中的屬性,這樣不同集合就會使用散點圖中不同屬性的樣式展示出來如下面實體中的色除錯性hue獲取了資料集中的smoker集合,這樣集合中的資料差異就可以通過色調的不同展示出來,其他同理,
sns.relplot(x="total_bill", y="tip", size="size",hue="smoker", palette="ch:r=-.5,l=.75", style="time",sizes=(15, 200), data=tips);
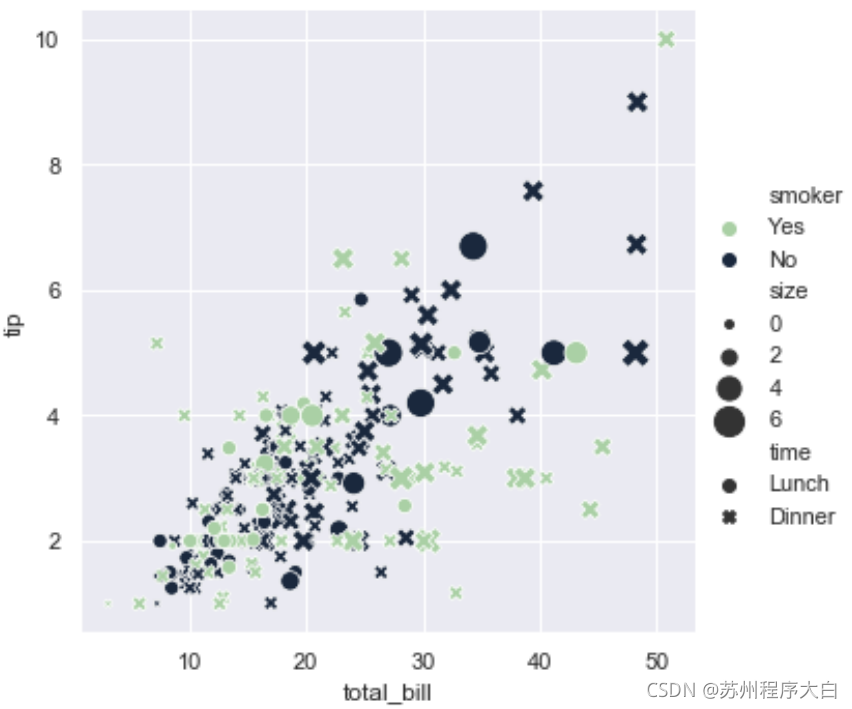
scatterplot是relplot的默認方法所以不需要單獨設定,具體屬性可以去scatterplot()的Api查看,
折線圖強調連續性 Emphasizing continuity with line plots
relplot里的第二個方法lineplot,前面說過默認方法是scatterplot所以要設定屬性kind=lineplot啟用折線圖,這個方法默認sort=true將x軸資料與y軸資料按順序對應起來,
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint",
y="signal",
hue="region",
style="event",
dashes=True, # 開啟顯示虛線
markers=True, # 顯示標記
# ci="sd" # 顯示標準偏差,默認是顯示置信區間,None關閉顯示
kind="line",
data=fmri);
這里我們引入一個新的fmri資料集,
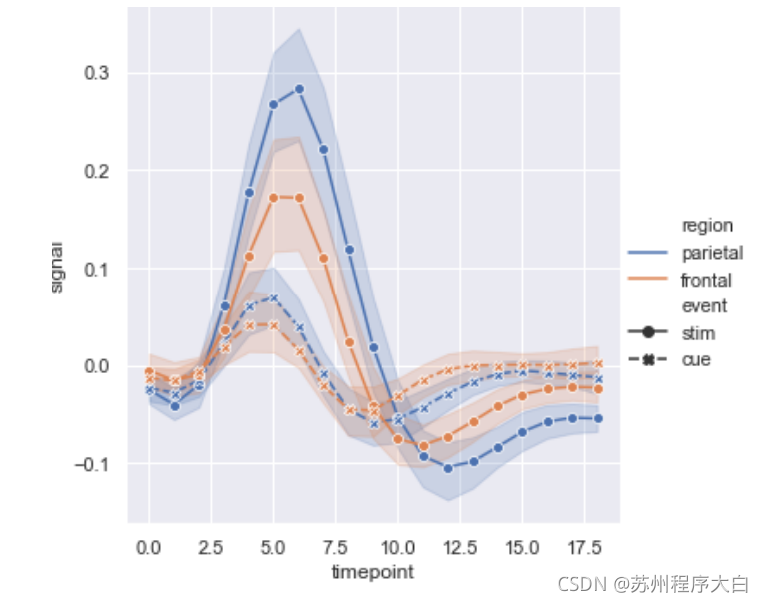
同時顯示多了圖表
用到relplot的屬性是col和col_wrap自動分行,同理也可以用row屬性設定列,
sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject",
col_wrap=5, # 設定每行顯示圖表數量
height=3, # 每個圖表的高度
kind="line",
data=fmri.query("region == 'frontal'"));
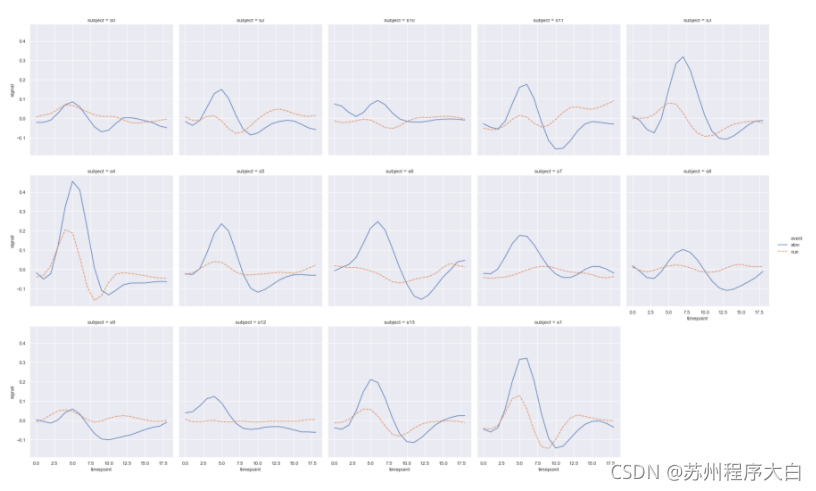
資料種類的可視化 Plotting with categorical data
對資料進行分類可視化用到的方法是catplot(),和資料關系可視化類似,catplot()也有多種分類(kind),包括散點圖(strip,swarm),分布圖(box,violin,boxen)和柱狀圖(point,bar,count),
sns.set(style="ticks", color_codes=True) #設定一下樣式
散點圖 categories scatterplots
除了種類外,散點圖能精確的顯示資料的分布,散點圖默認顯示方式是stript,例如下面的例子,
tips = sns.load_dataset("tips") #載入資料
sns.catplot(x="day", y="total_bill", data=tips);
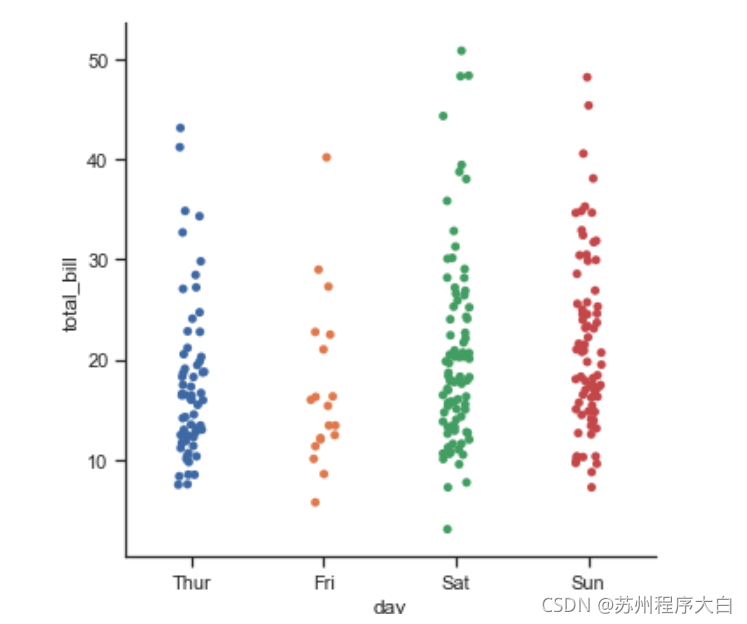
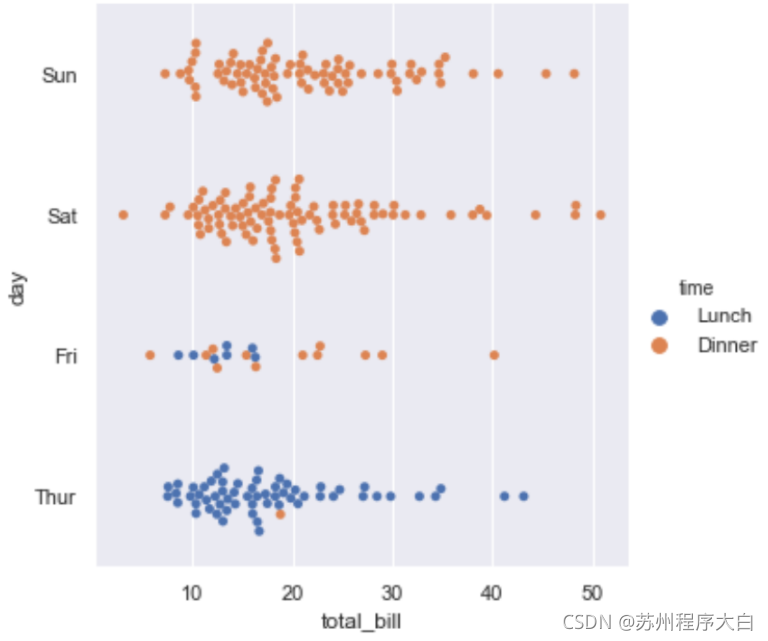
可以發現上面有些資料重疊在一起了,解決這個問題可以使用jitter屬性,也可使用另一種散點圖swarm,它自動使用演算法區分出可能重疊的資料,需要注意的是可以使用order來控制順序,下面的例子可以看出:
sns.catplot(x="total_bill", y="day", hue="time", kind="swarm", order=["Sun", "Sat","Fri","Thur"], data=tips);
分布圖 Distributions of observations within categories
資料量太大的時候,散點圖顯示不同種類的分布情況非常恐怖,所以可以使用分布圖來觀察不同種類資料的分布情況,具體代碼就不貼了,只需要更改一下kind屬性就可以了,下面分別看一下box,boxen,violin三種情況不同的顯示風格:
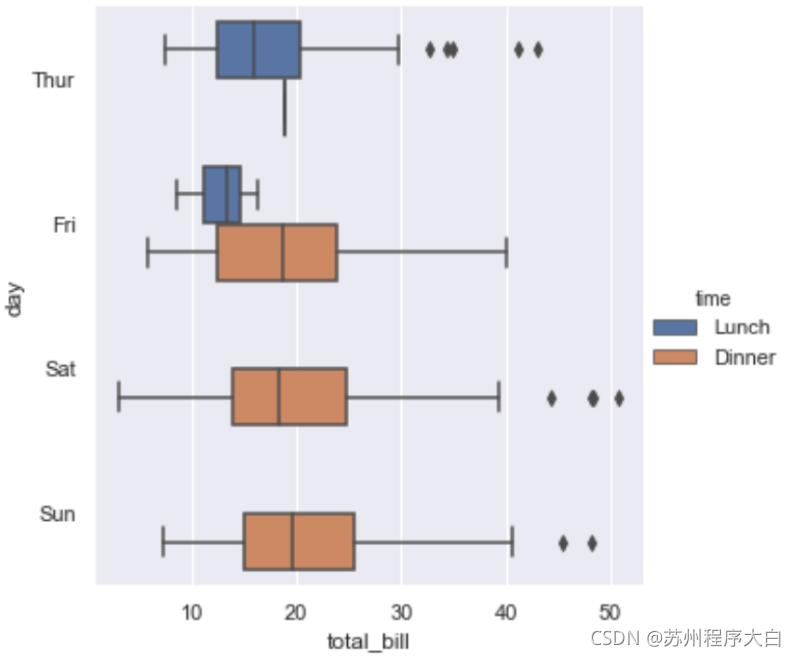
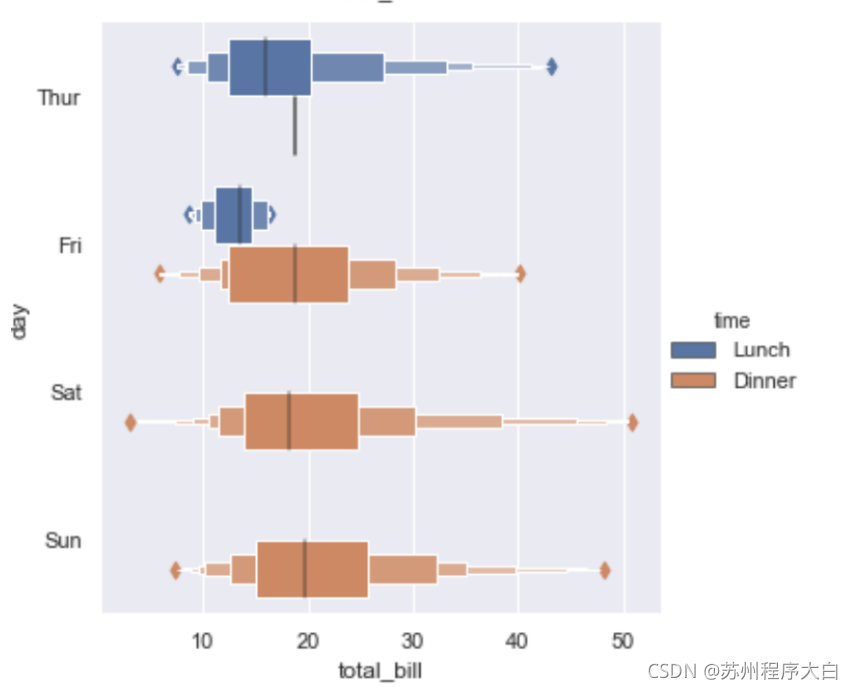
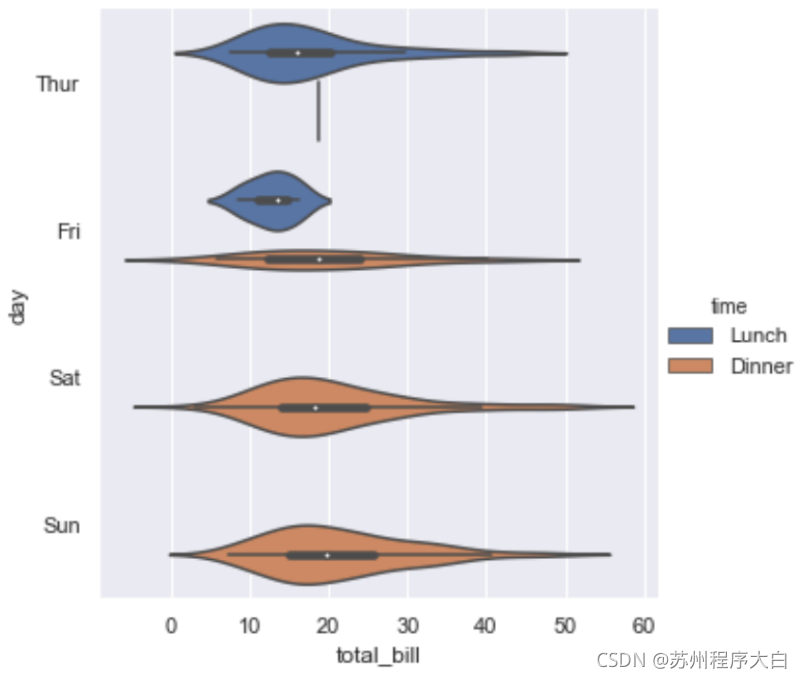
其中要重點說一下violin方法使用了KDE,因此有一些額外的屬性可以設定,具體可以查看一下api例如:
sns.catplot(x="total_bill", y="day", hue="sex",bw=.4, cut=2, inner="stick",
kind="violin", split=True, data=tips);
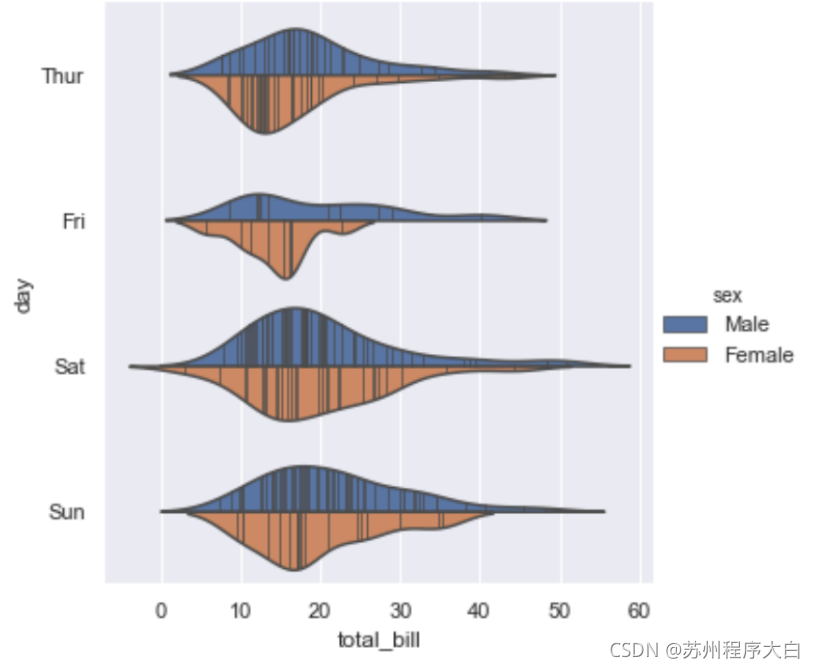
合并圖表
另外看一下如何將兩個不同型別的圖表合為一個,例如下面我們將violin和swarm型別的圖表在一張圖里展示:
g = sns.catplot(x="day", y="total_bill", kind="violin", inner=None, data=tips)
sns.swarmplot(x="day", y="total_bill", color="k", size=3, data=tips, ax=g.ax);
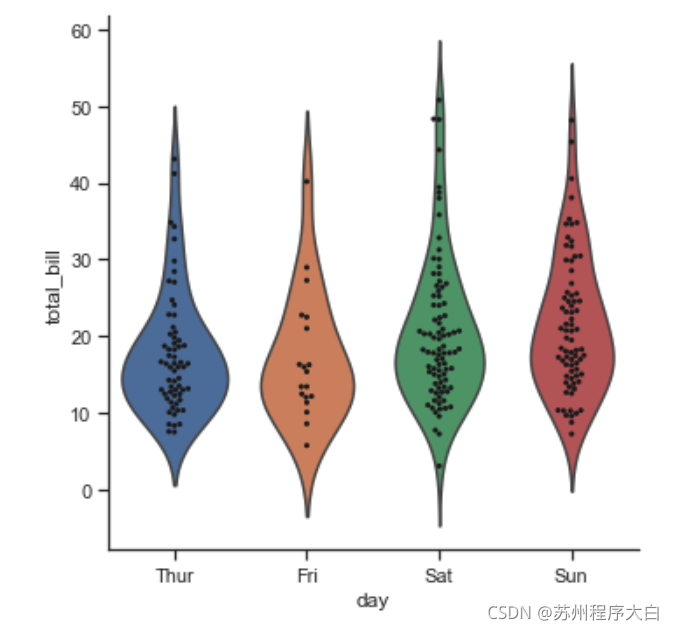
資料估計
很多情況我們是不需要特別精確的資料資訊的,只需要了解各個分類的走勢和差異性,這個時候柱狀圖bar和點狀圖point可以展示的資訊更簡潔明了,
例如這里我們引入一個新的資料集titanic來分析一下泰坦尼克號上不同倉位的乘客的生存率
titanic = sns.load_dataset("titanic")
首先下面看一下柱狀圖,這張圖是可以直觀的比較出各個倉位的生存率,需要指出的是柱狀圖的矩形邊框也可以設定顏色,
sns.catplot(x="class",
y="survived", hue="sex",
palette={"male": "g", "female": "m"}, # 設定hue屬性顯示的顏色
edgecolor=".6",
kind="bar",
data=titanic);
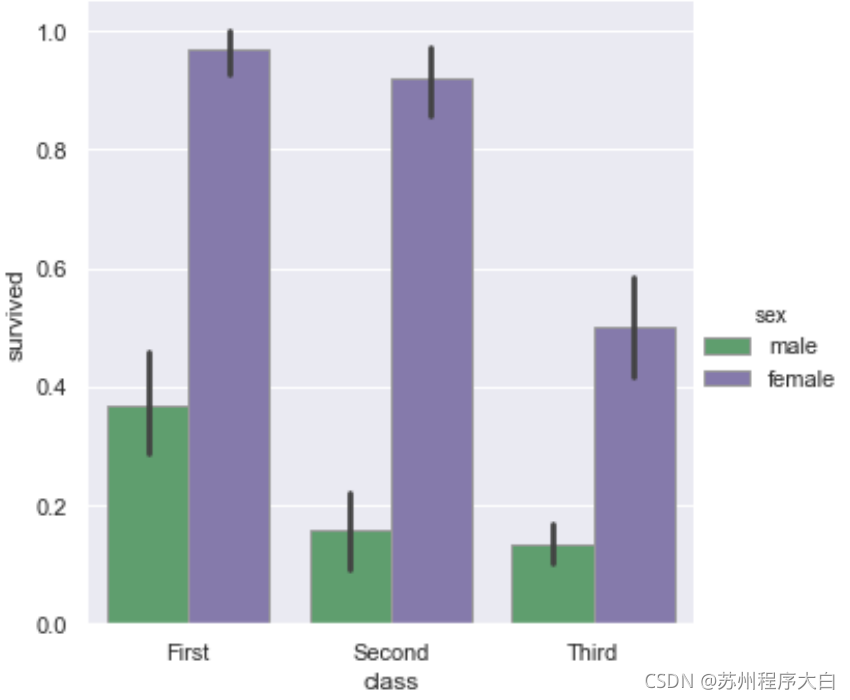
點狀圖可以設定的屬性也有很多,比如線的樣式,點的樣式等等
sns.catplot(x="class", y="survived", hue="sex",
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point", data=titanic);
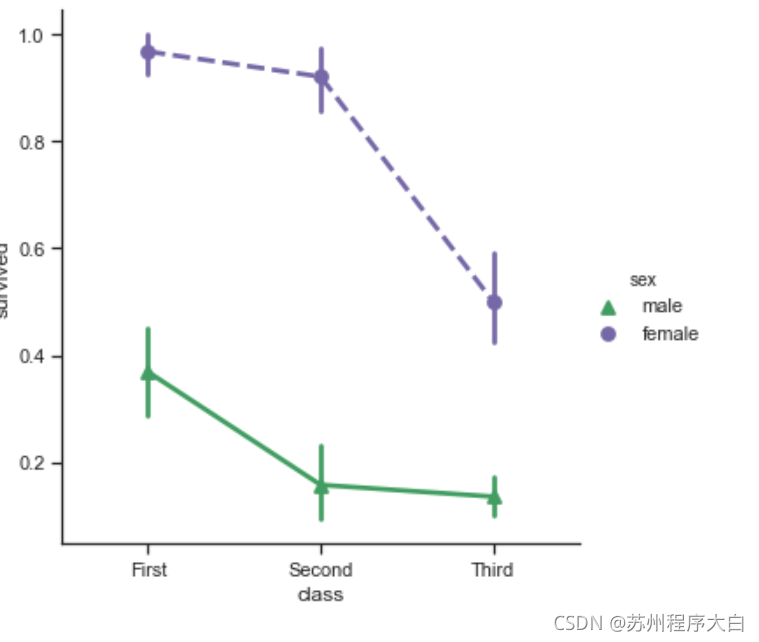
圖表的大小控制
設定圖表的大小可以使用matplotlib里的plt.subplots(figsize=(width,height))
想要改變圖表各個軸的精度可以使用set方法參照下面的實體
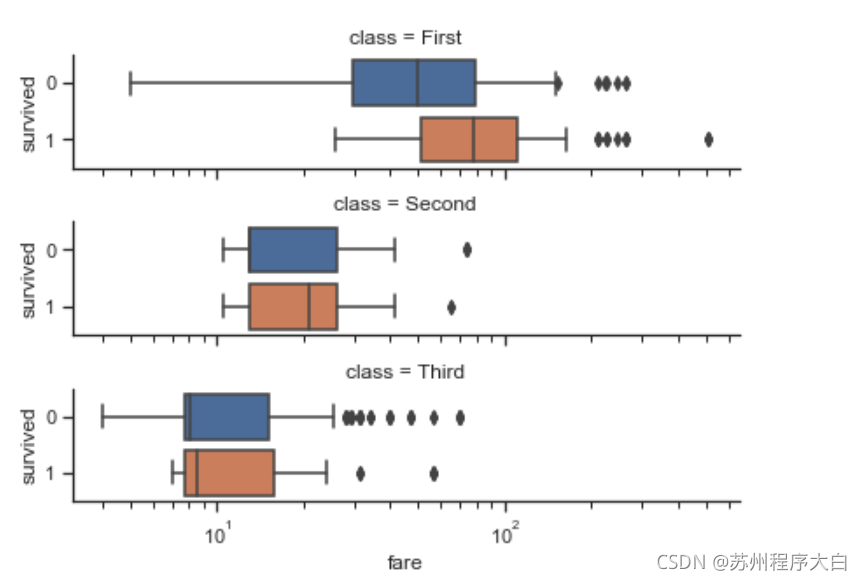
g = sns.catplot(x="fare", y="survived", row="class",
kind="box", orient="h", height=1.5, aspect=4,
data=titanic.query("fare > 0"))
g.set(xscale="log"); # x軸以對數形式顯示
資料分布的可視化 Visualizing the distribution of a dataset
拿到資料集后,通常第一件事就是確定資料的分布,接下來我們看一下對于單變數(unvariable)和雙變數(bivariable)分布如何進行可視化,
繪制單變數分布圖 Ploting univariate distributions
單變數分布的常見可視化模式是直方圖(histogram)或者KDA(kernel debsity estimate),在seaborn中使用的方法是displot(),其中的hist屬性控制是否顯示直方圖(默認開啟),kda屬性控制是否顯示KDA分布(默認開啟),rug屬性控制顯示刻度(默認關閉),
x = np.random.normal(size=100)
sns.distplot(x,hist=True,kde=True, rug=True);
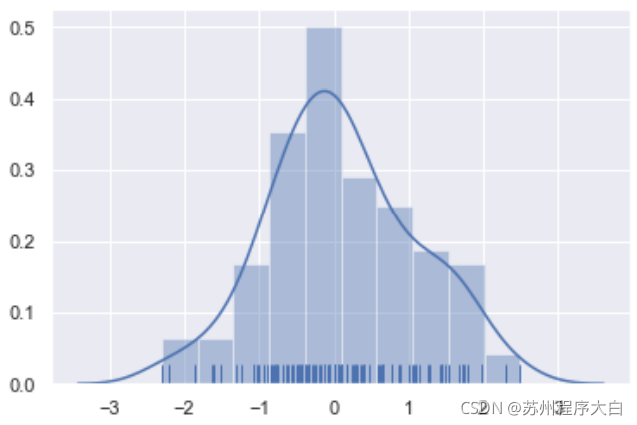
直方圖沒什么說的,是觀察資料分布常見且直觀的一個方法,原理也比較簡單. 這里重點說一下KDE,它本身在很多領域都是極其重要的工具. 繪制kde圖還可以使用kdeplot()方法或者rugplot()方法,例如下面的例子
x = np.random.normal(0, 1, size=30)
sns.kdeplot(x)
sns.kdeplot(x, shade=True, bw=.2, label="bw: .2"); # shade屬性控制是否顯示分布區域陰影
sns.kdeplot(x, bw=2, label="bw: 2")
plt.legend();
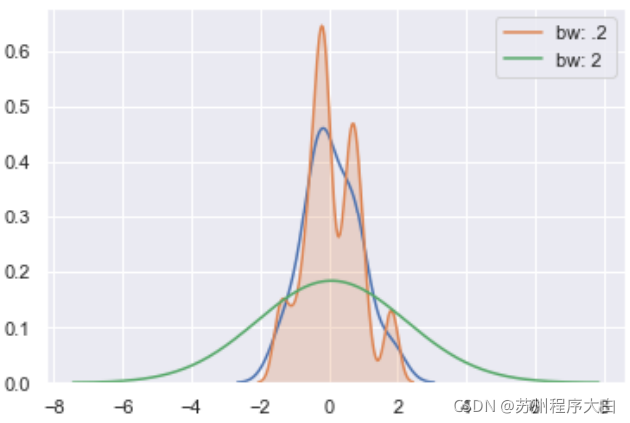
從圖中可以看出,bw屬性控制的是kde曲線的擬合程度,
繪制雙變數分布圖 Ploting bivariate distributions
首先我們創建一個資料集作為例子
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
繪制雙變數分布圖的方法是jointplot(),用多個面板從兩個維度繪制資料分布,seaborn提供了scatterplot(defult),hexbin,kde三種樣式
sns.jointplot(x="x", y="y", data=df);
x, y = np.random.multivariate_normal(mean, cov, 1000).T
with sns.axes_style("white"):
sns.jointplot(x=x, y=y, kind="hex", color="k");
sns.jointplot(x="x", y="y", data=df, kind="kde");
其實kdeplot()也可以實作kde雙變數分布
f, ax = plt.subplots(figsize=(6, 6)) # 設定顯示圖形的大小
sns.kdeplot(df.x, df.y, ax=ax)
sns.rugplot(df.x, color="g", ax=ax)
sns.rugplot(df.y, vertical=True, ax=ax);
可視化資料集中的成對關系 Visualizing pairwise relationships in a dataset
例如呼叫資料集iris(鳶尾屬植物)
iris = sns.load_dataset("iris")
然后使用pairplot()方法
sns.pairplot(iris, hue="species");
四個屬性sepal_width sepa_height和petal_length petal_width的對應關系,
線性關系的可視化 Visualizing linear relationships
線性回歸模型在資料可視化中可以展示資料的分布和趨勢,也可以起到預測資料的作用,我們還是使用小費tips資料集,
tips = sns.load_dataset("tips")
畫線性回歸模型的方法 Functions to draw linear regression models
seaborn提供了兩個方法regplot()和lmplot(),
sns.regplot(x="total_bill", y="tip", data=tips);
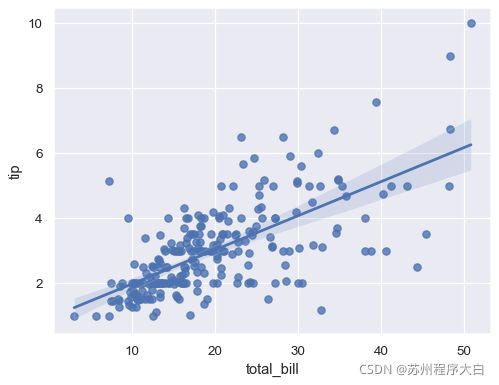
sns.lmplot(x="total_bill", y="tip", data=tips);
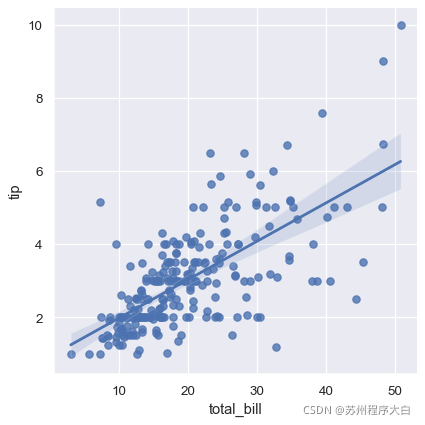
通過上面兩個例子 ,會發現這兩個方法繪制的結果區別不大,但是他們傳入的資料是有區別的:
-
regplot()的x和y軸可以是簡單的numpy陣列,pandasseries物件或者pandasDataFrame物件, -
lmplot()的x,y引數必須指定為字串,
擬合不同種類的資料 Fitting different kinds of models
anscombe = sns.load_dataset("anscombe")
以資料集Anscombe’s quartet(安斯庫姆四重奏)為例,先通過下面的表格簡單了解一下這個資料集,簡單是說就是四組包含<x,y>的資料集:
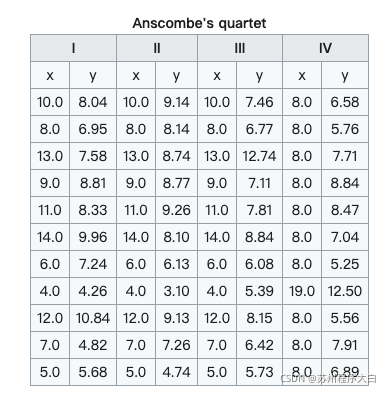
然后plot一下四組資料(注意這里使用lmplot,所以x,y軸對應的是字串),基本作業流程是使用資料集和用于構造網格的變數初始化FacetGrid物件,
sns.lmplot(x="x", y="y", col="dataset", col_wrap=2, data=anscombe,
ci=None,scatter_kws={"s": 80});
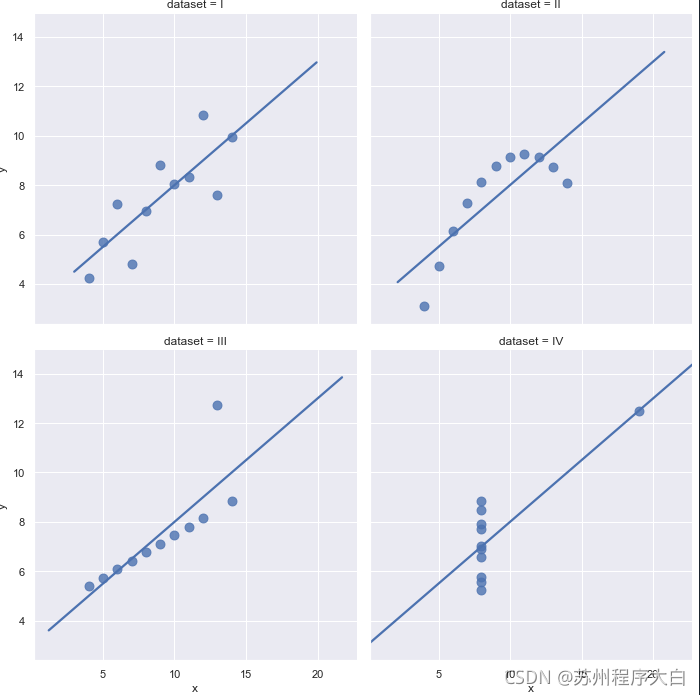
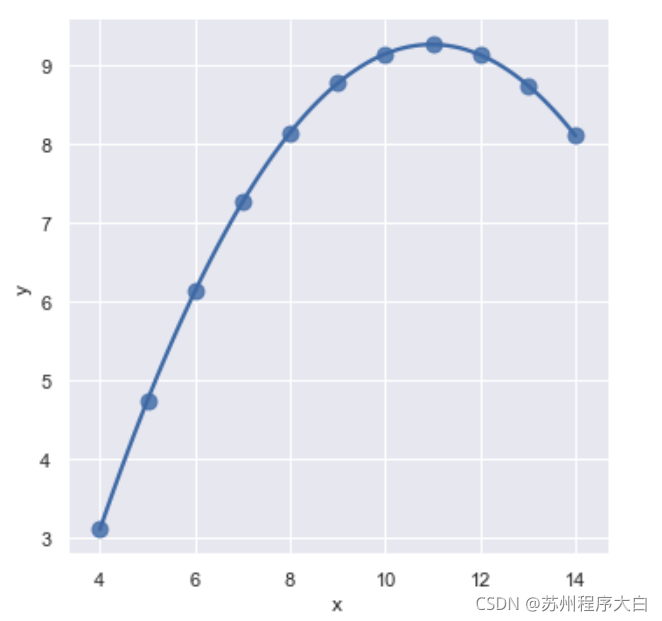
現在分析一下這四個資料集,第一個沒啥顯著特征,觀察第二個資料集可以發現它存在高階關系,可以通過order屬性控制階數,進行多項式回歸擬合
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
order=2, ci=None, scatter_kws={"s": 80});
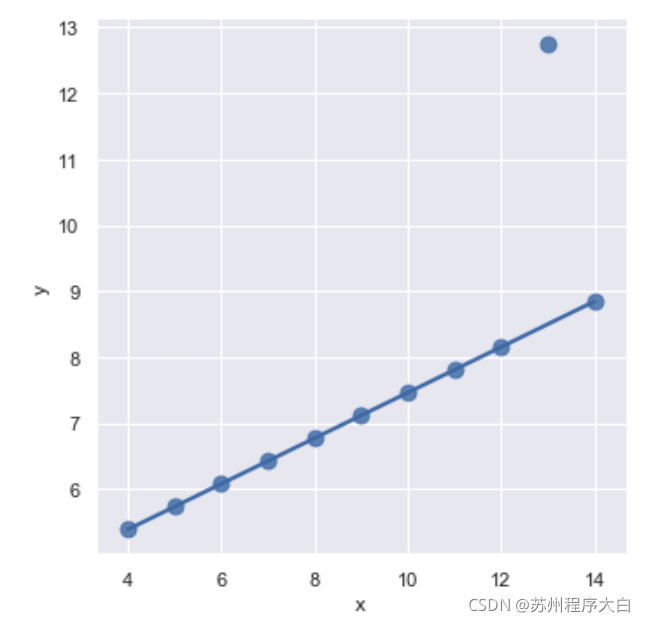
第三個資料集存在一個噪點outlier影響了擬合效果,可以使用roboust屬性保持健壯性
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
robust=True, ci=None, scatter_kws={"s": 80});
🌟作者相關的文章、資源分享🌟
🌟讓天下沒有學不會的技術🌟
學習C#不再是難問題
🌳《C#入門到高級教程》🌳
有關C#實戰專案
👉C#RS232C通訊原始碼👈
👉C#委托資料傳輸👈
👉C# Modbus TCP 源代碼👈
👉C# 倉庫管理系統原始碼👈
👉C# 歐姆龍通訊Demo👈
👉C#+WPF+SQL目前在某市上線的車管所攝像系統👈
👉2021C#與Halcon視覺通用的框架👈
👉2021年視覺專案中利用C#完成三菱PLC與上位機的通訊👈
👉VP聯合開源深度學習編程(WPF)👈
?有關C#專案歡迎各位查看個人主頁?
🌟機器視覺、深度學習🌟
學習機器視覺、深度學習不再是難問題
🌌《Halcon入門到精通》🌌
🌌《深度學習資料與教程》🌌
有關機器視覺、深度學習實戰
👉2021年C#+HALCON視覺軟體👈
👉2021年C#+HALCON實作模板匹配👈
👉C#集成Halcon的深度學習軟體👈
👉C#集成Halcon的深度學習軟體,帶[MNIST例子]資料集👈
👉C#支持等比例縮放拖動的halcon WPF開源表單控制元件👈
👉2021年Labview聯合HALCON👈
👉2021年Labview聯合Visionpro👈
👉基于Halcon及VS的動車組制動閘片厚度自動識別模塊👈
?有關機器視覺、深度學習實戰歡迎各位查看個人主頁?
🌟Java、資料庫教程與專案🌟
學習Java、資料庫教程不再是難問題
🍏《JAVA入門到高級教程》🍏
🍏《資料庫入門到高級教程》🍏
有關Java、資料庫專案實戰
👉Java經典懷舊小霸王網頁游戲機原始碼增強版👈
👉js+css類似網頁版網易音樂原始碼👈
👉Java物業管理系統+小程式原始碼👈
👉JavaWeb家居電子商城👈
👉JAVA酒店客房預定管理系統的設計與實作SQLserver👈
👉JAVA圖書管理系統的研究與開發MYSQL👈
?有關Java、資料庫教程與專案實戰歡迎各位查看個人主頁?
🌟分享Python知識講解、分享🌟
學習Python不再是難問題
🥝《Python知識、專案專欄》🥝
🥝《Python 檢測抖音關注賬號是否封號程》🥝
🥝《手把手教你Python+Qt5安裝與使用》🥝
🥝《用一萬字給小白全面講解python編程基礎問答》🥝
🥝《Python 繪制Android CPU和記憶體增長曲線》🥝
有關Python專案實戰
👉Python基于Django圖書管理系統👈
👉Python管理系統👈
👉2021年9個常用的python爬蟲原始碼👈
👉python二維碼生成器👈
?有關Python教程與專案實戰歡迎各位查看個人主頁?
🌟分享各大公司面試題、面試流程🌟
面試成功不是難事
🍏《2021年金九銀十最新的VUE面試題??《??記得收藏??》》🍏
🍏《只要你認真看完一萬字??Linux作業系統基礎知識??分分鐘鐘都吊打面試官《??記得收藏??》》🍏
🍏《??用一萬字給小白全面講解python編程基礎問答??《😀記得收藏不然看著看著就不見了😀》》🍏
?有關各大公司面試題、面試流程歡迎各位查看個人主頁?

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/306437.html
標籤:python