目錄
一、事務:
事務四大特性:
并發事務帶來哪些問題?(隔離所導致的一些問題)
事務隔離級別有哪些?
MySQL的默認隔離級別:
二、索引:
索引的作用:
索引的分類:
索引準則:
索引的資料結構:
一、事務:
事務是邏輯上的一組操作,要么都成功,要么都失敗!
——————————————————————————————————
1、SQL執行 A:1000元 ——>轉賬200元 B:200元
2、SQL執行 A:800元 ——> B:400元
——————————————————————————————————
將一組SQL放在一個批次中執行
事務四大特性:
ACID原則
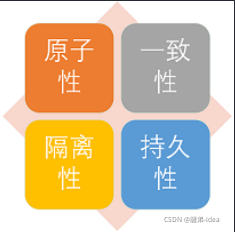
1.原子性(AtomIclty)︰事務是最小的執行單位,不允許分割,事務的原子性確保動作要么全部完成,要么完全不起作用;

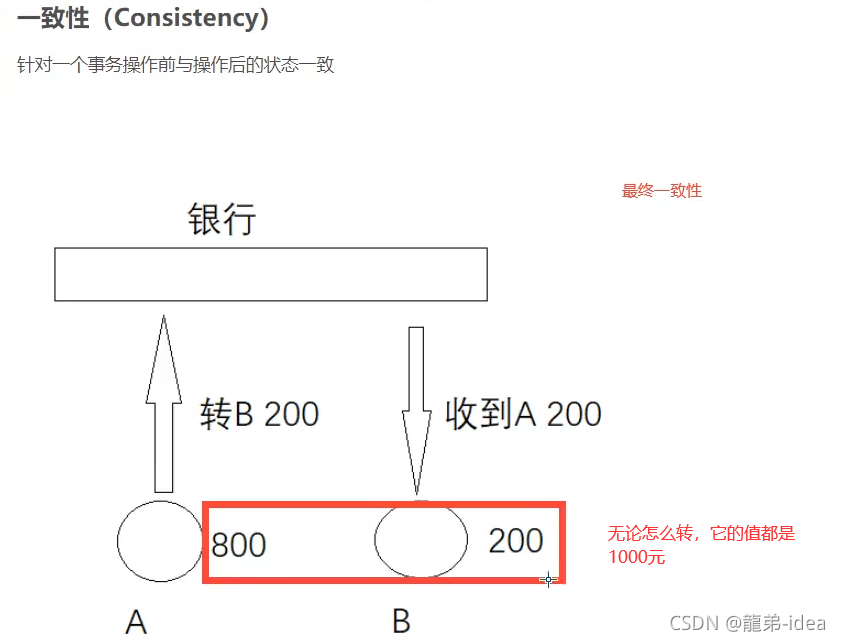
2.一致性(Conslstency):執行事務前后,資料保持一致,多個事務對同一個資料讀取的結
果是相同的;
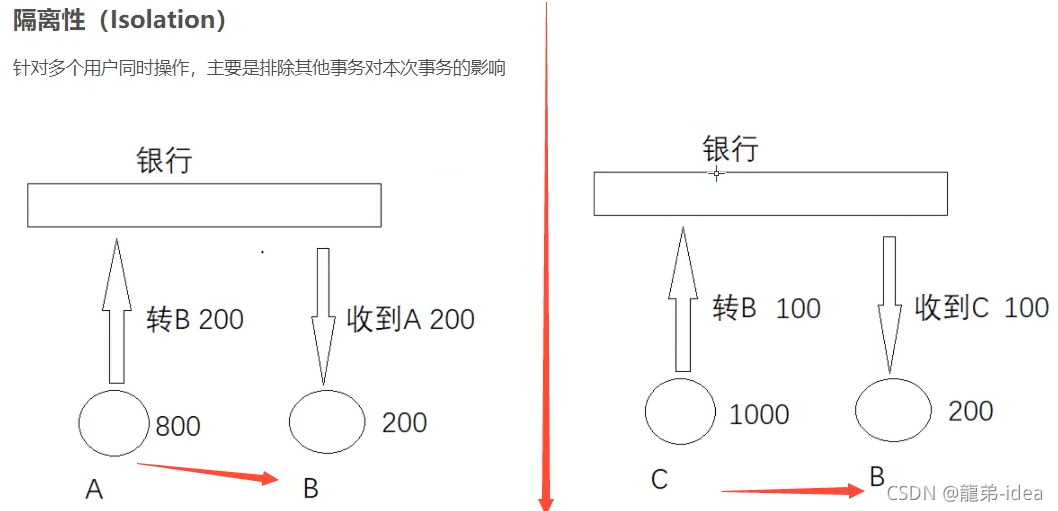
3.隔離性(Isolatlon)︰并發訪問資料庫時,一個用戶的事務不被其他事務所干擾,各并發
事務之間資料庫是獨立的;
4.持久性(Durabllty) :一個事務被提交之后,它對資料庫中資料的改變是持久的,即使數
據庫發生故障也不應該對其有任何影響, --------事務提交

并發事務帶來哪些問題?(隔離所導致的一些問題)
在典型的應用程式中,多個事務并發運行,經常會操作相同的資料來完成各自的任務(多個用戶對同一資料進行操作),并發雖然是必須的,但可能會導致以下的問題,
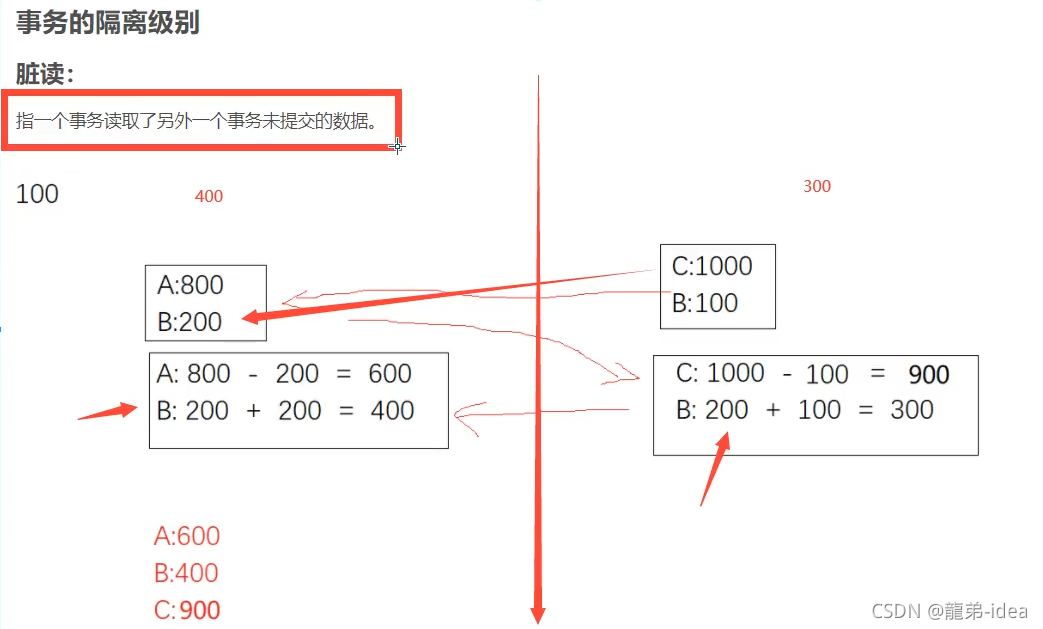
臟讀(DIrty read) :當一個事務正在訪問資料并且對資料進行了修改,而這種修改還沒有提交到資料庫中,這時另外一個事務也訪問了這個資料,然后使用了這個資料,因為這個資料是還沒有提交的資料,那么另外一個事務讀到的這個資料是"臟資料",依據"臟資料"所做的操作可能是不正確的,
丟失修改(Lost to modlify):指在一個事務讀取一個資料時,另外一個事務也訪問了該資料,那么在第一個事務中修改了這個資料后,第二個事務也修改了這個資料,這樣第一個事務內的修改結果就被丟失,因此稱為丟失修改,例如:事務1讀取某表中的資料A=20,事務2也讀取A=20,事務1修改A=A-1,事務2也修改A=A-1,最終結果A=19,事務1的修改被丟失
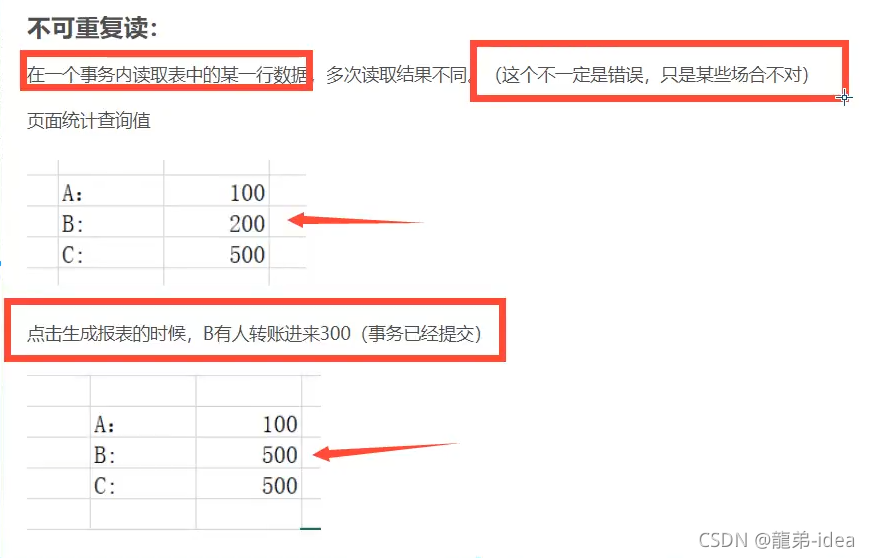
不可重復讀(Unrepeatableread):指在一個事務內多次讀同一資料,在這個事務還沒有結束時,另一個事務也訪問該資料,那么,在第一個事務中的兩次讀資料之間,由于第二個事務的修改導致第一個事務兩次讀取的資料可能不太一樣,這就發生了在一個事務內兩次讀到的資料是不一樣的情況,因此稱為不可重復讀,
幻讀(Phantom read):幻讀與不可重復讀類似,它發生在一個事務(T1)讀取了幾行資料,接著另一個并發事務(T2)插入了一些資料時,在隨后的查詢中,第一個事務(T1)就會發現多了一些原本不存在的記錄,就好像發生了幻覺一樣,所以稱為幻讀,
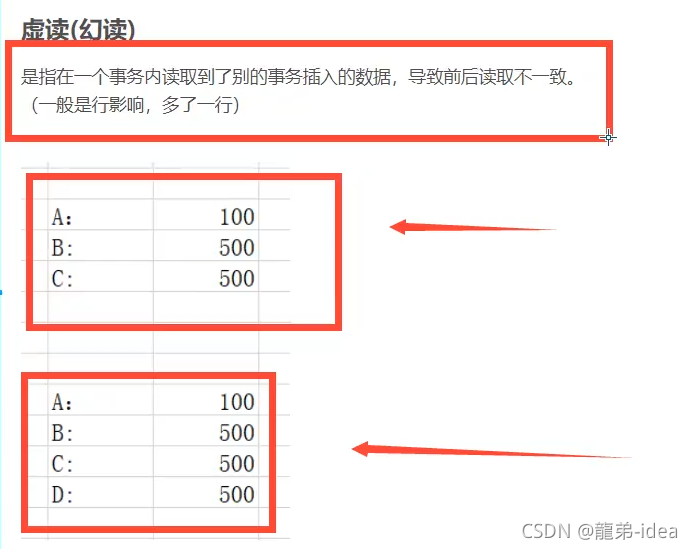
不可重復讀和幻讀區別;
不可重復讀的重點是修改比如多次讀取一條記錄發現其中某些列的值被修改,幻讀的重點在于新增或者洗掉比如多次讀取一條記錄發現記錄增多或減少了,
事務隔離級別有哪些?
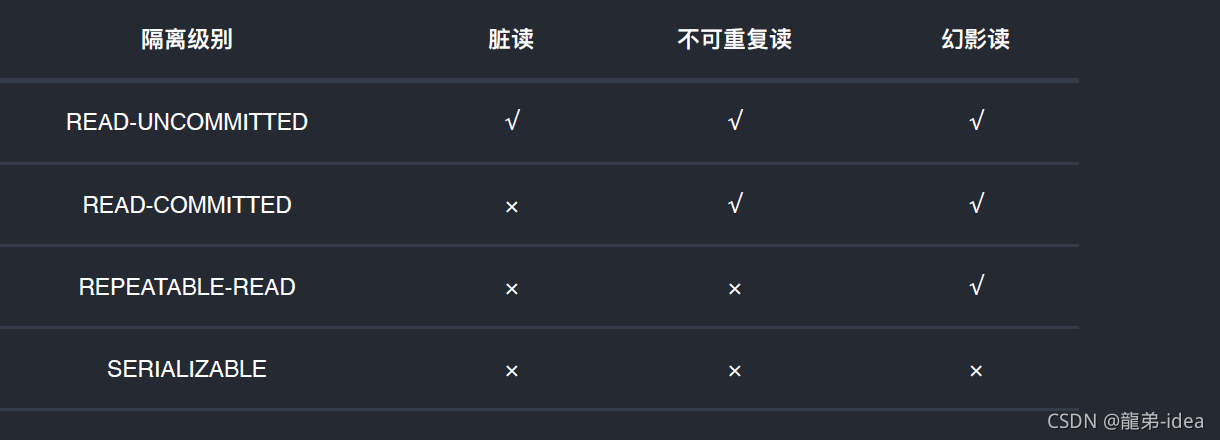
READ-UNCOMMITTED(讀取未提交):最低的隔離級別,允許讀取尚未提交的資料變更,可能會導致臟讀、幻讀或不可重復讀,
READ-COMMITTED(讀取已提交)︰允許讀取并發事務已經提交的資料,可以阻止臟讀,但是幻讀或不可重復讀仍有可能發生,
REPEATABLE-READ(可重復讀):對同一欄位的多次讀取結果都是一致的,除非資料是被本身事務自己所修改,可以阻止臟讀和不可重復讀,但幻讀仍有可能發生,
SERIALIZABLE(可串行化):最高的隔離級別,完全服從ACID的隔離級別,所有的事務依次逐個執行,這樣事務之間就完全不可能產生干擾,也就是說,該級別可以防止臟讀、不可重復讀以及幻讀,
MySQL的默認隔離級別:
MySQL InnoDB存盤引擎的默認支持的隔離級別是REPEATABLE-READ(可重讀),我們可以通過 SELECT @@tx_isolation;命令來查看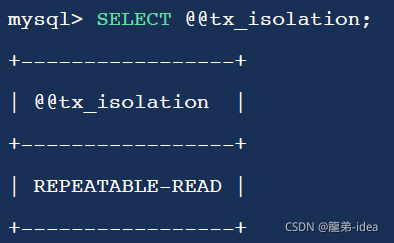
二、索引:
MySQL官方對索引的定義為:索引 (Index)是幫助MySQL高效獲取資料的資料結構,提取句子主干,就可以得到索引的本質:索引是資料結構,
MySQL索引使用的資料結構主要有BTree索引和哈希索引,對于哈希索引來說,底層的資料結構就是哈希表,因此在絕大多數需求為單條記錄查詢的時候,可以選擇哈希索引,查詢性能最快;其余大部分場景,建議選擇BTree索引,
MySQL的BTree索引使用的是B樹中的B+Tree,但對于主要的兩種存盤引擎的實作方式是不同的,
MyISAM: B+Tree葉節點的data域存放的是資料記錄的地址,在索引檢索的時候,首先按照B+Tree搜索演算法搜索索引,如果指定的Key存在,則取出其data域的值,然后以data域的值為地址讀取相應的資料記錄,這被稱為“非聚簇索引”,
InnoDB:其資料檔案本身就是索引檔案,相比MyISAM,索引檔案和資料檔案是分離的,其表資料檔案本身就是按B+Tree組織的一個索引結構,樹的葉節點data域保存了完整的資料記錄,這個索引的key是資料表的主鍵,因此InnoDB表資料檔案本身就是主索引,這被稱為“聚簇索引(或聚集索引)”,而其余的索引都作為輔助索引,輔助索引的data域存盤相應記錄主鍵的值而不是地址,這也是和MyISAM不同的地方,在根據主索引搜索時,直接找到key所在的節點即可取出資料;在根據輔助索引查找時,則需要先取出主鍵的值,再走一遍主索引,因此,在設計表的時候,不建議使用過長的欄位作為主鍵,也不建議使用非單調的欄位作為主鍵,這樣會造成主索引頻繁分裂,
索引的作用:
-
提高查詢速度
-
確保資料的唯一性
-
可以加速表和表之間的連接 , 實作表與表之間的參照完整性
-
使用分組和排序子句進行資料檢索時 , 可以顯著減少分組和排序的時間
-
全文檢索欄位進行搜索優化.
索引的分類:
-
主鍵索引 (Primary Key)
唯一的標識,主鍵不可重復,只能有一個列作為主鍵
-
唯一索引 (Unique)
避免重復的列出現,唯一索引可以重復,多個列都可以標識位唯一索引
-
常規索引 (Index)
默認的, index或key關鍵字來設定
-
全文索引 (FullText)
在特定的資料庫引擎下才有,MylSAM
快速定位資料
索引準則:
-
索引不是越多越好
-
不要對經常變動的資料加索引
-
小資料量的表建議不要加索引
-
索引一般應加在查找條件的欄位
索引的資料結構:
-- 我們可以在創建上述索引的時候,為其指定索引型別,分兩類
hash型別的索引:查詢單條快,范圍查詢慢
btree型別的索引:b+樹,層數越多,資料量指數級增長(我們就用它,因為innodb默認支持它)
-- 不同的存盤引擎支持的索引型別也不一樣
InnoDB 支持事務,支持行級別鎖定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事務,支持表級別鎖定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事務,支持表級別鎖定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
NDB 支持事務,支持行級別鎖定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive 不支持事務,支持表級別鎖定,不支持 B-tree、Hash、Full-text 等索引;轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/307227.html
標籤:java