?
![]() ??
??
又到了吃大閘蟹的季節了,你吃了嗎!那么為什么這么多人喜歡吃大閘蟹呢?大閘蟹有哪些特點,都有哪些大閘蟹品牌值得關注呢?
今天,就跟隨著本文一看究竟吧!讓你買到最好,最靠譜的螃蟹!這樣吃起來才最美味
?
目錄:
-
1. 聊聊大閘蟹
-
2. 資料采集
-
2.1. 頁面分析
-
2.2. 采集程式
-
-
3. 資料清洗
-
4. 資料統計
-
4.1. 商品價格分布
-
4.2. 評論數分布
-
4.3. 店鋪商品數分布
-
4.4. 好評率分布
-
-
5. 其他?
![]()
1. 聊聊大閘蟹
一般來說,我們常常會稱呼螃蟹,而吃螃蟹的人都是很勇敢的人,畢竟要敢于做第一個吃螃蟹的人,
螃蟹一般根據生活水域的不同而分為河蟹和海蟹,比如大閘蟹就是河蟹額一種,帝王蟹那種超大的就是海蟹的一類,
大閘蟹都有哪些營養價值呢?
大閘蟹營養豐富,據《本草綱目》記載:螃蟹具有舒筋益氣、理胃消食、通經絡、散諸熱、散瘀血之功效,蟹肉味咸性寒,有清熱、化瘀、滋陰之功,可治療跌打損傷、筋傷骨折、過敏性皮炎,蟹殼煅灰,調以蜂蜜,外敷可治黃蜂蜇傷或其他無名腫毒,蟹肉也是兒童天然滋補品,經常食用可以補充優質蛋白和各種微量元素,
——百科
美味的大閘蟹!
 ?
?
![]()
膏多的大閘蟹
一般我們看網上的大閘蟹商品,出現較多的字眼就是鮮活、公母以及兩(重量單位),那么這都是什么含義呢?
所謂鮮活,其實就是指你網購且到你手上的大閘蟹是活的狀態,畢竟到手的是死蟹再烹飪誰知道會出現啥例外問題,
 ?
?
![]()
鮮活度判斷-(來自:知乎張美麗)
所謂公母,其實就是大閘蟹的性別雌雄,公蟹的肚臍是尖尖的,而母蟹的肚臍是圓的(畢竟要放卵),一般建議是農歷八九月里可以挑母蟹,農歷九月過后(也就是國慶節后)優先選公蟹,
 ?
?
![]()
公母判斷
所謂兩,就是重量單位指大閘蟹的體重,1兩=50g,當然了,基本上越大越肥美了!!不過,越大價格也越貴~~
 ?
?
![]()
大閘蟹大小對比-(來自:知乎張美麗)
特別注意,在吃大閘蟹的時候,有四個部位不能吃,這些部位主要是有些很多寄生蟲和細菌啥的,
 ?
?
![]()
不要吃的四個部位
大閘蟹的簡單介紹就到這了,接下來我們看看京東中秋節大閘蟹的路子吧!
?
![]()
2. 資料采集
本次才哥采集的是京東商城里帶有 中秋節標簽的 大閘蟹商品資訊,采集程序如下:
2.1. 頁面分析
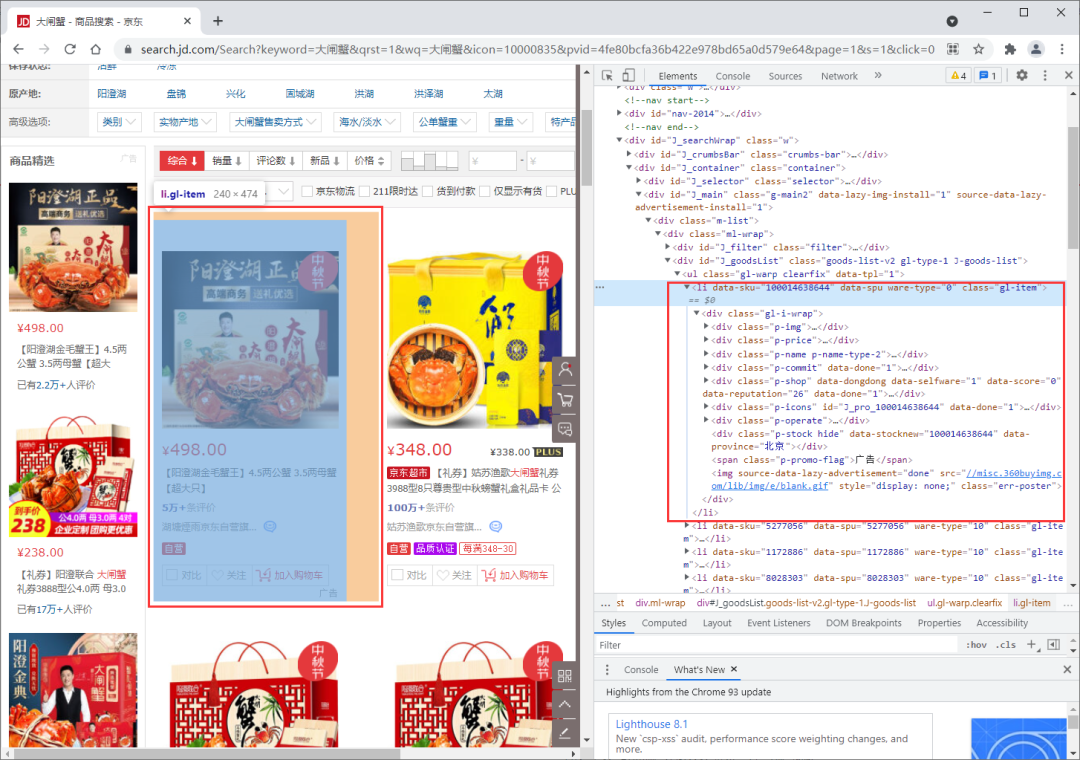 ?
?
![]()
頁面
通過進行下滑操作,我們發現單純從頁面來看默認展示30個商品資訊,下滑會加載另外30個,此時的網頁地址不變;當我們翻頁時,發現網頁地址發生變化,其中page從1變成了3,于是,我們猜測其實每個頁面是兩頁page,于是嘗試手動修改page發現確實如此,最后,我們獲得網頁地址規律如下:
# page是變化的,其他不變
url= f'https://search.jd.com/Search?keyword=%E5%A4%A7%E9%97%B8%E8%9F%B9&qrst=1&wq=%E5%A4%A7%E9%97%B8%E8%9F%B9&icon=10000835&pvid=4fe80bcfa36b422e978bd65a0d579e64&page={page}'
![]()
當然,大家也可以將上面的地址變成基礎地址+引數的形式,其中可變引數為keyword和page,方便進行其他商品的資料采集,這里我就不展開了,
我們通過請求這個網頁地址,可以獲取需要的商品資訊如下:
 ?
?
![]()
商品資訊
不過,實際操作中我們發現請求到的網頁資料中其他資訊都包含但是唯獨不包含評價數資訊,而評價數的資訊需要點進去具體的商品頁面進行采集,好在我們進到商品頁面發現評價信息是以json資料形式存在,比較好決議,而且介面api非常明確,可以直接通過商品id這一個引數即可進行請求獲取,
2.2. 采集程式
經過對頁面的分析以及一些嘗試,我們最終確定了采集方法,
?引入需要的庫
import requests
import pandas as pd
from lxml import etree
import re
import json
headers = {
# "Accept-Encoding": "Gzip", # 使用gzip壓縮傳輸資料讓訪問更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
# "Cookie": cookie
}
采集頁面資訊
頁面資料采集需要傳入的引數只是page頁碼即可
def get_html(page):
url= f'https://search.jd.com/Search?keyword=%E5%A4%A7%E9%97%B8%E8%9F%B9&qrst=1&wq=%E5%A4%A7%E9%97%B8%E8%9F%B9&icon=10000835&pvid=4fe80bcfa36b422e978bd65a0d579e64&page={page}'
r = requests.get(url, headers=headers, timeout=6)
return r
采集評論資料
采集評論資料只需要傳商品id即可,這里需要注意的是這個介面貌似有訪問時間限制或頻次限制(我這邊采集完是用的代理ip)
# 獲取評論資訊
def get_comment(productId):
# time.sleep(0.5)
url = 'https://club.jd.com/comment/skuProductPageComments.action?'
params = {
'callback': 'fetchJSON_comment98',
'productId': productId,
'score': 0,
'sortType': 6,
'page': 0,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1,
}
r = requests.get(url, headers=headers, params=params, timeout=6)
comment_data = re.findall(r'fetchJSON_comment98\((.*)\)', r.text)[0]
comment_data = json.loads(comment_data)
comment_summary = comment_data['productCommentSummary']
return comment_summary
決議頁面其他資訊
頁面顯示一共41頁,所以這里我手動設定的是82頁,決議操作采用的是xpath
def get_data():
df = pd.DataFrame(columns=['productId', 'price', 'name', 'shop', '自營'])
for page in range(1,82):
r = get_html(page)
r_html = etree.HTML(r.text)
lis = r_html.xpath('.//li[@class="gl-item"]')
for li in lis:
item = {
"productId": li.xpath('./@data-sku')[0], # id
"price": li.xpath('./div/div[@class="p-price"]/strong/i/text()')[0], # 價格
"name": ''.join( li.xpath('./div/div[@class="p-name p-name-type-2"]/a/em/text()')) ,# 商品名
"shop": li.xpath('./div/div[@class="p-shop"]/span/a/text()')[0], # 店鋪名
"自營": li.xpath('./div/div[@class="p-icons"]/i/text()'), # 自營
}
comment_summary = get_comment(item['productId'])
item['commentCount'] = comment_summary['commentCountStr']
item['goodRate'] = comment_summary['goodRate']
df = df.append(item, ignore_index=True)
print(f'\r第{page}/82頁資料已經采集', end='')
最終,我們得到的資料如下:
?
 ?
?
![]() ?
?
資料預覽
3. 資料清洗
打開存在本地的資料檔案,發現里面存在大閘蟹的一些衍生品,比如蟹八件、蟹膏等等,這些商品資料是需要洗掉的;此外,像name欄位里存在非字符,commentCount欄位里有+和萬等字眼也需要替換處理;最后就是爬取程序中采集的資料可能存在重復,需要按照productId去重等等,
資料資訊
>>>df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 2653 entries, 0 to 2652 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 productId 2653 non-null int64 1 price 2653 non-null float64 2 name 2653 non-null object 3 shop 2651 non-null object 4 自營 2653 non-null object 5 commentCount 2653 non-null object 6 goodRate 2653 non-null float64 dtypes: float64(2), int64(1), object(4) memory usage: 145.2+ KB
無關資料清理
發現在name商品名稱中,都用到公、母以及兩字眼,我們可以根據這個資訊進行無關資料清理
>>>df = df[(df['name'].str.contains('公|母'))&(df['name'].str.contains('兩'))]
>>>df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1774 entries, 0 to 2272
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 productId 1774 non-null int64
1 price 1774 non-null float64
2 name 1774 non-null object
3 shop 1774 non-null object
4 自營 1774 non-null object
5 commentCount 1774 non-null object
6 goodRate 1774 non-null float64
dtypes: float64(2), int64(1), object(4)
memory usage: 110.9+ KB
一下子清理了好多!!
特殊字符處理
df.name = df.name.str.replace(r'\s','',regex=True)
df.commentCount = df.commentCount.str.replace('+','',regex=True).str.replace('萬','0000',regex=True)
df.head()
?
 ?
?
![]()
無關資料清理
重復資料洗掉
?
>>>df.drop_duplicates(subset='productId', inplace=True) >>>df.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 1546 entries, 0 to 2272 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 productId 1546 non-null int64 1 price 1546 non-null float64 2 name 1546 non-null object 3 shop 1546 non-null object 4 自營 1546 non-null object 5 commentCount 1546 non-null object 6 goodRate 1546 non-null float64 dtypes: float64(2), int64(1), object(4) memory usage: 96.6+ KB
又清理了不少!!
資料型別轉換
我們發現,在各欄位資料型別中,commentCount評論數居然還是數字型別,那就轉化一下吧,
df.commentCount = df['commentCount'].astype('int')
資料清洗完畢,我們開始做簡單的統計分析展示吧!
4. 資料統計
以下,我們將從商品價格分布、評論數分布、店鋪商品數分布和好評率進行統計展示,同時我們也可以將根據商品名稱進行決議出公母以及重量相關資料再做探索!
4.1. 商品價格分布
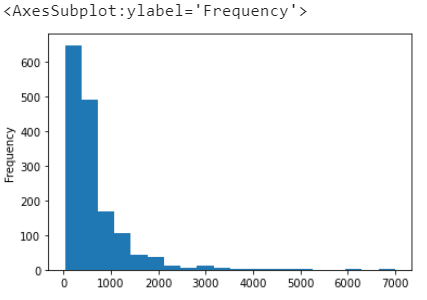
# 直方圖 df.price.plot.hist(stacked=True, bins=20)
?
 ?
?
![]() ?
?
價格直方圖
可以看到,大部分價格在1000以內,超過600/1546件商品價格在300以內,
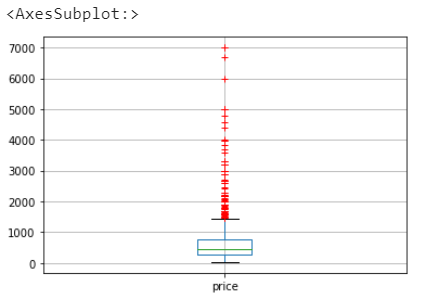
# 箱線圖 df[['price']].boxplot(sym="r+")
?
 ?
?
![]()
價格箱線圖
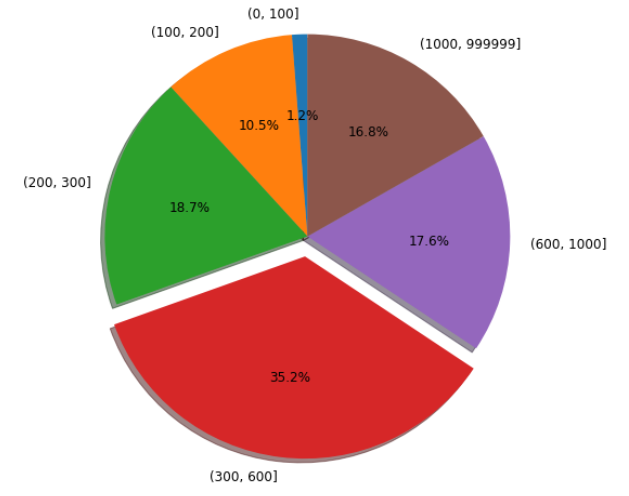
我們按照0-100,100-200,200-300,300-600,600-1000,1000+分類看看,可以發現300-600區間的商品占比最多!!
 ?
?
![]()
?
# 繪圖代碼
import matplotlib.pyplot as plt
from matplotlib import font_manager as fm
bins= [0,100,200,300,600,1000,999999]
price_Num = df['price'].groupby(pd.cut(df.price, bins= bins)).count().to_frame('數量')
labels = price_Num.index
sizes = price_Num['數量']
explode = (0, 0, 0, 0.1, 0, 0)
fig1, ax1 = plt.subplots(figsize=(10,8))
patches, texts, autotexts = ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal')
# 重新設定字體大小
proptease = fm.FontProperties()
proptease.set_size('large')
plt.setp(autotexts, fontproperties=proptease)
plt.setp(texts, fontproperties=proptease)
plt.show()
商品最貴的幾件
可以看到最貴的大閘蟹基本都是重量級的,來自誠蟹一品,不過銷量應該一般,畢竟評論數少,不過是真的大公的都有7兩多,母的都是5-6兩,而常規賣的基本都是4兩左右價格400左右!!
# 單元格資料全顯示
pd.set_option('display.max_colwidth',1000)
df.nlargest(5,'price',keep='first')
?
 ?
?
![]()
最貴大閘蟹
4.2. 評論數分布
大部分的商品評論數集中在200以下,有5個商品的評論數超過10萬,不過,我們基本可以認定像這種10萬+評論數的商品基本都是買的最多的!
?
bins= [0,100,200,500,1000,5000,10000,100000,9999999]
comment_Num = df['commentCount'].groupby(pd.cut(df.commentCount, bins= bins)).count().to_frame('數量')
labels = list(comment_Num.index)[:7]
labels.extend(['10萬+'])
comment_Num = df['commentCount'].groupby(pd.cut(df.commentCount, bins= bins, labels=labels)).count().to_frame('數量')
?
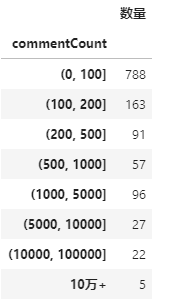 ?
?
![]()
評論數分布
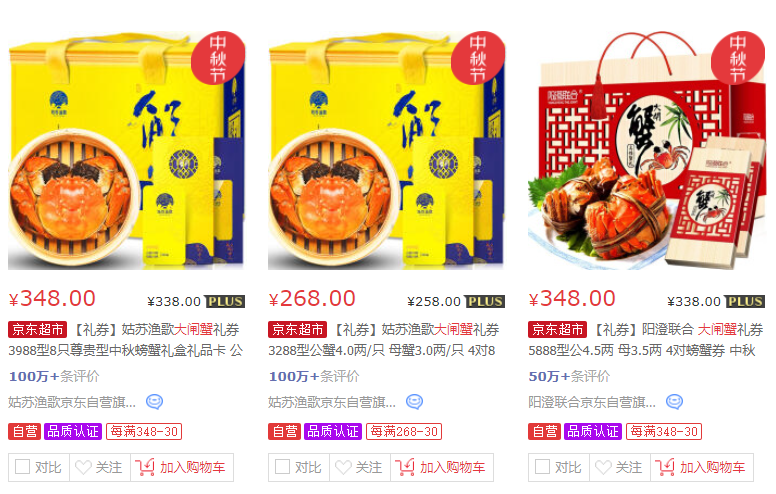
買的人最多的基本都是公蟹4兩左右+母蟹3兩左右的8只組合裝,價格在200-400之間,屬于大眾消費品吧!
df.nlargest(5,'commentCount',keep='first')
![]()
??
 ?
?
![]()
評論數也就是銷量
這些商品基本也是你在京東搜索的時候出現在綜合推薦前幾位的吧!
 ?
?
![]()
綜合推薦前幾
4.3. 店鋪商品數分布
誠蟹一品旗艦店是商品數最多的,高達79款,不過整體銷量一般,感覺看前面他們家高達6000塊以上的禮品盒,大概只做高端吧!
相比之下,姑蘇漁歌京東自營旗艦店的商品數量多且銷量也多,
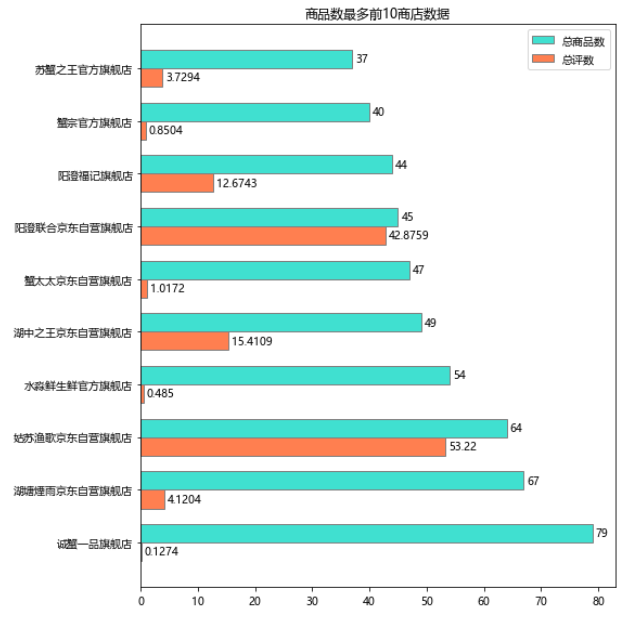 ?
?
![]()
店鋪商品最多
?
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
shopNum1= df.groupby('shop').agg(總商品數=('productId','count'),
總評數=('commentCount',sum)
).sort_values(by='總商品數', ascending=False).head(10)
# 設定柱狀圖顏色
colors = ['turquoise', 'coral']
labels = shopNum1.index
y1 = shopNum1.總商品數
y2 = shopNum1.總評數 / 10000
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(8,8))
rects1 = ax.barh(x + width/2, y1, width, label='總商品數', color=colors[0], edgecolor='grey')
rects2 = ax.barh(x - width/2, y2, width, label='總評數', color=colors[1], edgecolor='grey')
ax.set_title('商品數最多前10商店資料')
y_pos = np.arange(len(labels))
ax.set_yticks(y_pos)
ax.set_yticklabels(labels)
ax.legend()
# 顯示資料標簽
ax.bar_label(rects1, padding=3)
ax.bar_label(rects2, padding=3)
fig.tight_layout()
plt.show()
?
我們再看看銷量高的店鋪都有哪些!
可以看到,三家自營店:今錦上生鮮京東自營旗艦店、姑蘇漁歌京東自營旗艦店、陽澄聯合京東自營旗艦店 銷量遙遙領先!
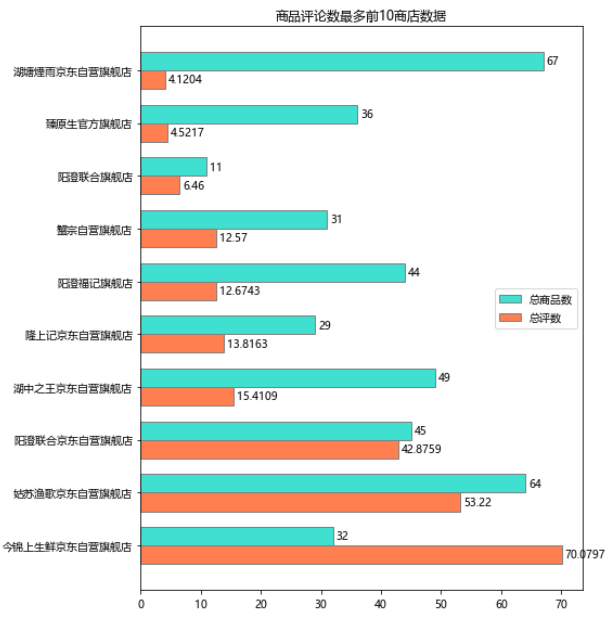 ?
?
![]()
銷量高的店鋪
4.4. 好評率分布
只看評價數超過1萬的商品共27件,有一半商品好評率都在98%以上,相對來說整體都不錯,買就買銷量多且好評率高的吧,就是比較穩!
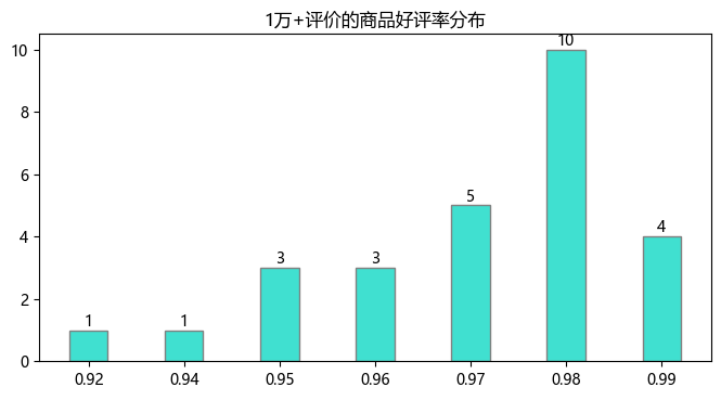 ?
?
![]()
?
import matplotlib.pyplot as plt
# 中文及負數顯示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 創建畫布
fig, ax = plt.subplots(figsize=(8, 4), dpi=100)
# 案例資料
data = goodRateNum.數量
# 作圖引數
index = goodRateNum.index.astype('str')
bar_width = 0.4
# 設定柱狀圖顏色
colors = ['turquoise']
# 柱狀圖
bar = plt.bar(index, data, bar_width, color=colors[0], edgecolor='grey')
# 設定標題
ax.set_title('1萬+評價的商品好評率分布', fontsize=12)
# 顯示資料標簽
ax.bar_label(bar, label_type='edge')
plt.show()
?
關于按照商品名稱中的大閘蟹重量來進行深度探索,大家可以自行試試哦!
?需要此篇文章的完整代碼或教程點這里即可獲取!
![]()
5. 其他
其實,如果你想更深一步了解不同商品的 用戶評價,可以參考 2.2.采集程式中對評價資訊的部分,這部分做回圈然后就可獲取全部的評論資料,然后再進行對應資料分析,
關于京東大閘蟹,通過商品名稱我們可以得到以下熱詞云圖:
基本都是公蟹、母蟹和禮券等關鍵字咯,,,
 ?
?
![]()
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/307245.html
標籤:python