陣列
陣列可以存放多個同一型別資料,陣列也是一種資料型別,在Go中,陣列是值型別
一個養雞場有6只雞,它們的體重分別是3kg,5kg,1kg,3.4kg,2kg,50kg,請問這六只雞的總體重是多少?平均體重是多少?
使用傳統的方法不利于資料的管理和維護
傳統的方法不夠靈活,因此我們引出需要學習的新的資料型別 ==》陣列
//使用陣列的方式來解決問題
var 陣列名 [陣列大小]資料型別
var a [5]int
賦初值 a[0] = 1 a[1] = 30 ...
func main() {
//1.定義一個陣列
var hens [7]float64
//2. 給陣列的每個元素賦值,元素的下標是從0開始的 0 - 6
hens[0] = 3.0 //hens陣列的第1個元素 hens[0]
hens[1] = 5.0 //hens陣列的第2個元素 hens[1]
hens[2] = 1.0
hens[3] = 3.4
hens[4] = 2.0
hens[5] = 50.0
hens[6] = 150.0 //增加一只雞
//3. 遍歷陣列求出總體重
totalWeight := 0.0
for i := 0; i < len(hens); i++ {
totalWeight += hens[i]
}
//4. 求出平均體重
avgWeight := fmt.Sprintf("%.2f",totalWeight / float64(len(hens)))
fmt.Printf("totalWeight = %v avgWeight = %v",totalWeight,avgWeight)
}
//輸出:totalWeight = 214.4 avgWeight = 30.63
使用陣列來解決問題,增加程式的可維護性
而且方法代碼更加清晰,也容易擴展
陣列在記憶體布局
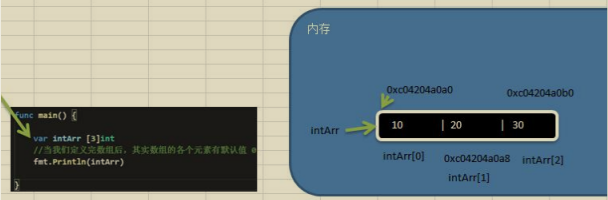
陣列的地址可以通過陣列名來獲取 &intArr
陣列的第一個元素的地址,就是陣列的首地址
陣列的各個元素的地址間隔是依據陣列的型別決定,比如 int64 -> 8 int32 -> 4 ...
func main() {
var intArr [3]int //int占8個位元組
//當我們定義完陣列后,其是陣列的各個元素有默認值 0
fmt.Println(intArr) // 默認值
intArr[0] = 10
intArr[1] = 20
intArr[2] = 30
fmt.Println(intArr)
fmt.Printf("intArr的地址 = %p intArr[0] 地址 = %p intArr[1] 地址 = %p intArr[2] 地址 = %p",
&intArr,&intArr[0],&intArr[1],&intArr[2])
}
//輸出:[0 0 0]
//[10 20 30]
//intArr的地址 = 0xc000010380 intArr[0] 地址 = 0xc000010380 intArr[1] 地址 = 0xc000010388 intArr[2] 地址 = 0xc000010390
陣列的使用
func main() {
var score [5]float64
for i := 0; i < len(score); i++ {
fmt.Printf("請輸入第%d個元素的值\n",i+1)
fmt.Scanln(&score[i])
}
//變數陣列列印
for i := 0; i < len(score); i++ {
fmt.Printf("score[%d] = %v\t",i,score[i])
//訪問陣列元素:陣列名[下標]比如:要使用a陣列的第三個元素 a[2]
}
}
初始化陣列的方式
func main() {
//四種初始化陣列的方式
var numArr01 [3]int = [3]int{1,2,3}
fmt.Println("numArr01 = ",numArr01)
var numArr02 = [3]int{4,5,6}
fmt.Println("numArr02 = ",numArr02)
//這里的 [...]是規定的寫法
var numArr03 = [...]int{7,8,9}
fmt.Println("numArr03 = ",numArr03)
var numArr04 = [...]int{1: 800, 0: 900, 2: 999}
fmt.Println("numArr04 = ",numArr04)
//型別推導
strArr05 := [...]string{1: "zisefeizhu", 0: "jack", 2: "mary"}
fmt.Println("strArr05 = ",strArr05)
}
//輸出:numArr01 = [1 2 3]
//numArr02 = [4 5 6]
//numArr03 = [7 8 9]
//numArr04 = [900 800 999]
//strArr05 = [jack zisefeizhu mary]
陣列的遍歷
方法1: 常規遍歷
遍歷陣列求出總體重
totalWeight := 0.0
for i := 0; i < len(hens); i++ {
totalWeight += hens[i]
}
方法2:for - range 結構遍歷
第一個回傳值index是陣列的下標
第二個value是在該下標位置的值
它們都是僅在for回圈內部可見的區域變數
遍歷陣列元素的時候,如果不想使用下標index,可以直接把下邊index標為下劃線_
index和value的名稱不是固定的,即程式員可以自行指定,一般命名為index和value
//演示for-range遍歷陣列
heroes := [...]string{"宋江","吳用","林沖"}
for i, v := range heroes {
fmt.Printf("i = %v v = %v\n",i, v)
fmt.Printf("heroes[%d] = %v \n",i,heroes[i])
}
for _,v := range heroes {
fmt.Printf("元素的值 = %v\n",v)
}
}
//輸出:i = 0 v = 宋江
//heroes[0] = 宋江
//i = 1 v = 吳用
//heroes[1] = 吳用
//i = 2 v = 林沖
//heroes[2] = 林沖
//元素的值 = 宋江
//元素的值 = 吳用
//元素的值 = 林沖
陣列使用的注意事項和細節
陣列是多個相同型別陣列的組合,一個陣列一旦宣告/定義了,其長度是固定的,不能動態變化
var arr []int 這時 arr就是一個slice切片,切片后面專門講解
陣列中的元素可以是任何資料型別,包括值型別和參考型別,但是不能混合
陣列創建后,如果沒有賦值,有默認值(零值)
數值型別陣列:默認值為0
字串陣列: 默認值為" "
bool陣列: 默認值為false
使用陣列的步驟
1.宣告陣列并開辟空間
2.給陣列各個元素賦值(默認零值)
3.使用陣列
陣列的下標是從0開始的
陣列下標必須在指定范圍內使用,否則報panic:陣列越界,比如
var arr[5]int 則有效下標為 0 - 4
Go的陣列屬于值型別,在默認情況下是值型別,因此會進行值拷貝,陣列間不會相互影響
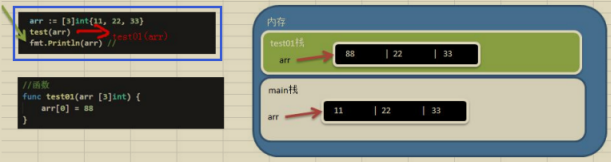
如果想在其它函式中,去修改原來的陣列,可以使用參考傳遞(指標方式)
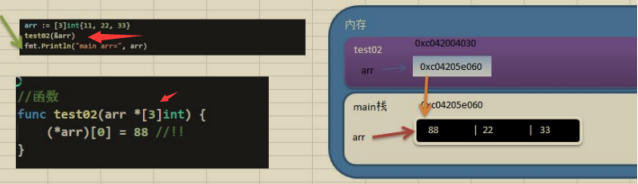
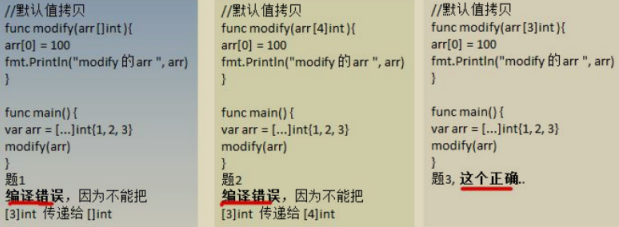
長度是陣列型別的一部分,在傳遞函式引數時,需要考慮陣列的長度
陣列的應用案例
創建一個byte型別的26個元素的陣列,分別放置’A’ - ’Z’,使用for回圈訪問所有元素并列印出來,提示:字符資料運算’A’+1 ->’B’
func main(){
//1)創建一個byte型別的26個元素的陣列,分別放置’A’ - ’Z’,
// 使用for回圈訪問所有元素并列印出來,
// 提示:字符資料運算’A’+1 ->’B’
//思路
//1. 宣告一個陣列 var myChars [26]byte
//2. 使用for回圈,利用 字符可以進行運算的特點來輔助 'A' + 1 = 'B'
//3. 使用for 回圈列印
var myChars [26]byte
for i := 0; i < 26; i++ {
myChars[i] = 'A' + byte(i) //注意需要將i =》 byte
}
for i := 0; i < 26; i++ {
fmt.Printf("%c",myChars[i])
}
//輸出:ABCDEFGHIJKLMNOPQRSTUVWXYZ
}
請求出一個陣列的最大值,并得到對應的下標
func main() {
//思路
//1. 宣告一個陣列 var intArr[5] = [...]int{1,-1,9,90,11}
//2. 假定第一個元素就是最大值,下標就是0
//3. 然后從第二個元素開始回圈比較,如果發現有更大值,則交換
var intArr [6]int = [...]int {1,-1,9,90,11,9000}
maxVal := intArr[0]
maxValIndex := 0
for i := 1; i < len(intArr); i++ {
//從第二個元素開始回圈比較,如果發現有更大,則交換
if maxVal < intArr[i] {
maxVal = intArr[i]
maxValIndex = i
}
}
fmt.Printf("maxVal = %v maxValIndex = %v", maxVal, maxValIndex)
}
//輸出:maxVal = 9000 maxValIndex = 5
請求出一個陣列的和和平均值,for-range
func main() {
//思路
//1. 宣告一個陣列 var intArr[5] = [...]int{1,-1,9,90,11}
//2. 求出和sum
//3. 求出平均值
var intArr [5]int = [...]int{1, -1, 9, 90, 12}
sum := 0
for _,val := range intArr {
//累計求和
sum += val
}
//如何讓平均值保留到小數
fmt.Printf("sum = %v 平均值 = %v", sum, float64(sum) / float64(len(intArr)) )
}
//輸出:sum = 111 平均值 = 22.2
要求:隨機生成五個數,并將其反轉列印,復雜應用
import (
"fmt"
"math/rand"
"time"
)
func main() {
//思路
//1. 隨機生成5個數,rand.Intn()函式
//2. 當我們得到亂數后,就放到一個陣列int陣列
//3. 反轉列印,交換的次數是len/2,倒數第一個和第一個元素交換,倒數第二個和第二個元素交換
var intArr [5]int
//為了每次生成的亂數都不一樣,我們需要給一個seed值
len := len(intArr)
rand.Seed(time.Now().UnixNano())
for i := 0; i < len; i++ {
intArr[i] = rand.Intn(100) //0 <= n < 100
}
fmt.Println("交換前",intArr)
//反轉列印,交換的次數是 len / 2
//倒數第一個和第一個元素交換,倒數第二個和第二個元素交換
temp := 0 //做一個臨時變數
for i := 0; i < len / 2; i++ {
temp = intArr[len - 1 - i]
intArr[len - 1 -i] = intArr[i]
intArr[i] = temp
}
fmt.Println("交換后",intArr)
}
//輸出:交換前 [24 15 90 17 6]
//交換后 [6 17 90 15 24]
陣列練習題
題目要求:
跳水比賽 8個評委打分,運動員的成績去掉一個最高分,去掉一個最低分,剩下的6個分數的平均分就是最后得分,使現
(1)請把最高分,最低分的評委找出
(2)找出最佳評委和最差評委,最佳評委是最后得分差距最小,最差評委最后得分差距最大
分析:
設計一個函式求最高分 最低分 平均分 需要考慮存在多個最低分和最高分的情況
找最有裁判和最差裁判使用abs() 以及切片完成 將絕對值傳入到切片中再遍歷
package main
import (
"fmt"
"math")
func max(array *[8]float64) (mx float64,mi float64,avg float64){
max := 0.0
for i := 0; i < len(array); i++ {
if (*array)[i] > max {
max = (*array)[i]
}
}
min := max
for i := 0; i < len(array); i++ {
if (*array)[i] < min {
min = (*array)[i]
}
}
mx = max
mi = min
sum := 0.0
maxcount,mincount :=0.0,0.0
for i := 0; i < len(array); i++ {
//判斷最大值和最小值出現的次數 1次時直接去掉 多次是需要加上去
if (*array)[i] == max {
maxcount +=1
}
if (*array)[i] == min{
mincount +=1
}
//算出不包含任意一次不包含 最大值、最小值的和
if (*array)[i] != max && (*array)[i] != min{
sum += (*array)[i]
}
}
//fmt.Println(maxcount,mincount)
//處理出現多次最大值或者最小值
if mincount > 1.0 && maxcount > 1.0{
sum += (max*(maxcount-1)+min*(mincount-1))
}else if mincount > 1.0 && maxcount == 1.0{
sum += (min*(mincount-1))
}else if mincount ==1.0 && maxcount > 1.0{
sum += (max*(maxcount-1))
}else {
sum += 0
}
avg = sum/6.0
return mx,min,avg}
func Best(array1 *[8]float64, arry2 []float64, avg float64) {
for i := 0; i < len(array1); i++ {
arry2 = append(arry2, math.Abs((*array1)[i]-avg))
}
max := 0.0
for j :=0;j < len(arry2);j++{
if arry2[j] > max{
max = arry2[j]
}
}
min := max
for i := 0; i < len(arry2); i++ {
if arry2[i] < min {
min = arry2[i]
}
}
for i := 0; i < len(arry2); i++ {
if arry2[i] == min {
fmt.Printf("最優秀評分者為第%v位裁判,評分:%v 和平均分相差%v\n",i+1,(*array1)[i],min)
}
}
for i := 0; i < len(arry2); i++ {
if arry2[i] == max {
fmt.Printf("評分差距最大者為第%v位裁判,評分:%v和平均分相差%v\n",i+1,(*array1)[i],max)
}
}}
var Socre [8]float64
var Socreabs = make([]float64,0,0)
func main() {
//輸入8個裁判的分數
for i := 0;i<len(Socre);i++{
fmt.Printf("請輸入第%v位裁判的的評分:\n",i+1)
fmt.Scanln(&Socre[i])
}
max,min,avg :=max(&Socre)
fmt.Println(Socre)
fmt.Printf("最高分為:%v,最低分為:%v 平均分為:%v\n",max,min,avg)
//知道最大分 最小分 找最大分、最小分的裁判
for k :=0;k<len(Socre);k++{
if Socre[k] == max{
fmt.Printf("最高分為:%v,第%v位裁判\n",max,k+1)
}else if Socre[k] == min {
fmt.Printf("最低分:%v,第%v位裁判\n",min,k+1)
}
}
Best(&Socre,Socreabs,avg)
}
切片
切片的英文是slice
切片是陣列的一個參考,因此切片是參考型別,在進行傳遞時,遵守參考傳遞的機制
切片的使用和陣列類似,遍歷切片、訪問切片的元素和求切片長度len(slice)都一樣
切片的長度是可以變化的,因此切片是一個可以動態變化的陣列
var 切片名 []型別
比如: var a []int
func main() {
//演示切片的基本使用
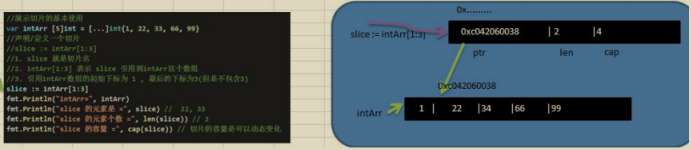
var intArr [5]int = [...]int {1,22,33,66,99}
//宣告/定義一個切片
//1. slice := intArr[1:3]
//2. intArr[1:3]表示slice參考到intArr這個陣列
//3. 參考intArr陣列的起始下標為1,最后的下標為3(但是不包含3)
slice := intArr[1:3]
fmt.Println("intArr = ",intArr)
fmt.Println("slice 的元素是 = ",slice) // 22,33
fmt.Println("slice 的元素個數 = ",len(slice)) // 2
fmt.Println("slice 的容量 = ", cap(slice)) //切片的容量是可以動態變化
}
//輸出:intArr = [1 22 33 66 99]
//slice 的元素是 = [22 33]
//slice 的元素個數 = 2
//slice 的容量 = 4
切片在記憶體中形式【重要】
對上面的分析圖總結
slice的確是一個參考型別
slice從底層來說,其實就是一個資料結構(struct結構體)
type slice struct {
ptr *[2]int
len int
cap int
}
切片的使用
方式1:定義一個陣列,然后讓切片去參考一個已經創建好的陣列
func main() {
//演示切片的基本使用
var intArr [5]int = [...]int {1,22,33,66,99}
//宣告/定義一個切片
//1. slice := intArr[1:3]
//2. intArr[1:3]表示slice參考到intArr這個陣列
//3. 參考intArr陣列的起始下標為1,最后的下標為3(但是不包含3)
slice := intArr[1:3]
fmt.Println("intArr = ",intArr)
fmt.Println("slice 的元素是 = ",slice) // 22,33
fmt.Println("slice 的元素個數 = ",len(slice)) // 2
fmt.Println("slice 的容量 = ", cap(slice)) //切片的容量是可以動態變化
}
//輸出:intArr = [1 22 33 66 99]
//slice 的元素是 = [22 33]
//slice 的元素個數 = 2
//slice 的容量 = 4
方式2:通過make來創建切片
var 切片名 []type = make([]type,len,[cap])
引數說明:
type:就是資料型別
len :大小
cap :指定切片容量,可選,如果分配了cap,則要求cap >= len
func main() {
//演示切片的使用 make
var slice []float64 = make([]float64, 5, 10)
slice[1] = 10
slice[3] = 20
//對于切片,必須make使用
fmt.Println(slice)
fmt.Println("slice的size = ",len(slice))
fmt.Println("slice的cap = ",cap(slice))
}
//輸出:[0 10 0 20 0]
//slice的size = 5
//slice的cap = 10
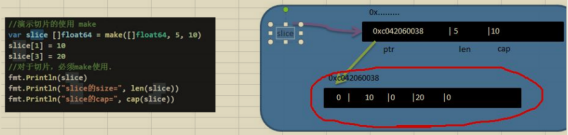
對上面代碼的小結:
1)通過make方式創建切片可以指定切片的大小和容量
2)如果沒有給切片的各個元素賦值,那么就會使用默認值[int, float => 0 string => “ ” bool => false]
3)通過make方式創建的切片對應的陣列是由make底層維護,對外不可見,即只能通過slice去訪問各個元素
方式3:定義一個切片,直接就指定具體陣列,使用原理類似make的方式
func main() {
var strSlice []string = []string {"zisefeizhu","zhujingxing","mayike"}
fmt.Println("strSlice = ", strSlice)
fmt.Println("strSlice size = ",len(strSlice))
fmt.Println("strSlice cap = ",cap(strSlice))
}
//輸出:strSlice = [zisefeizhu jingxing mayike]
//strSlice size = 3
//strSlice cap = 3
方式1和方式2的區別(面試)
方式1是直接參考陣列,這個陣列是事先存在的,程式員是可見的
方式2是通過make來創建切片,make也會創建一個陣列,是由切片在底層進行維護,程式員是看不見的,make創建切片的示意圖

切片的遍歷
func main() {
//使用常規的for回圈遍歷切片
var arr [5]int = [...]int {10, 20, 30, 40, 50}
slice := arr[1:4] // 20, 30, 40
for i := 0; i < len(slice); i++ {
fmt.Printf("slice[%v] = %v \t",i , slice[i])
}
fmt.Println()
//使用for - range 方式遍歷切片
for i, v := range slice {
fmt.Printf("i = %v v = %v \n",i ,v)
}
}
切片使用的注意事項和細節
slice擴充縮容會有記憶體申請釋放也是開銷,且擴容好像是1.25倍
切片初始化時 var slice = arr[startIndex:endIndex]
說明:從arr陣列下標為startIndex,取到下標為endIndex的元素(不含arr[endIndex])
切片初始化時,仍然不能越界,范圍在[0 - len(arr)]之間,但是可以動態增長
var slice = arr[0:end] 可以簡寫 var slice = arr[:end]
var slice = arr[start:len(arr)] 可以簡寫:var slice = arr[start:]
var slice = arr[0:len(arr)] 可以簡寫:var slice = arr[:]
cap是一個內置函式,用于統計切片的容量,即最大可以存放多少個元素
切片定義完后,還不能使用,因為本身是一個空的,需要讓其參考到一個陣列,或者make一個空間供切片來使用
切片可以繼續切片
func main() {
var arr [5]int = [...]int {10, 20, 30, 40, 50}
slice := arr[1:4] // 20, 30, 40
slice2 := slice[1:2] // slice [20,30,40] [30]
slice2[0] = 100 //因為arr slice 和slice2 指向的資料空間是一個,因此slice2[0] =100
fmt.Println("slice2 = ",slice2)
fmt.Println("slice = ",slice)
fmt.Println("arr = ",arr)
}
append內置函式,可以對切片進行動態追加
func main() {
//用append內置函式,可以對切片進行動態追加
var slice []int = []int {100,200,300}
//通過append直接給slice追加具體的元素
slice = append(slice,400,500,600)
fmt.Println("slice",slice) //100, 200, 300, 400, 500, 600
//通過append將切片slice 追加給slice
slice = append(slice,slice...)
fmt.Println("slice",slice) ////slice [100 200 300 400 500 600 100 200 300 400 500 600]
}
切片append操作的底層原理分析
切片append操作的本質就是對陣列擴容
go底層會創建一下新的陣列newArr(安裝擴容后大小)
將slice原來包含的元素拷貝到新的陣列newArr
slice 重新參考到newArr
注意newArr是在底層來維護的,程式員不可見
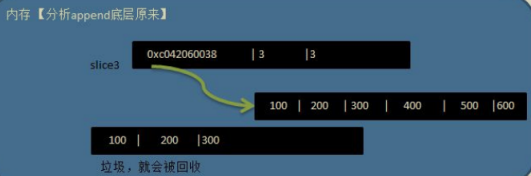
切片的拷貝操作
切片使用copy內置函式完成拷貝,舉例說明
func main() {
//切片的拷貝操作
//切片使用copy內置函式完成拷貝,舉例說明
var slice []int = []int {1,2,3,4,5}
var slice2 = make([]int,10)
copy(slice2,slice)
fmt.Println("slice = ",slice) //slice = [1 2 3 4 5]
fmt.Println("slice2 = ",slice2) //slice2 = [1 2 3 4 5 0 0 0 0 0]
}
copy(para1,para2)引數的資料型別是切片
按照上面的代碼來看,slice和slice2的資料空間是獨立,相互不影響,也就是說slice[0] = 999,slice5[0] 仍然是1
關于拷貝的注意事項
func main() {
var a []int = []int {1,2,3,4,5}
var slice = make([]int,1)
fmt.Println(slice)
copy(slice,a)
fmt.Println(slice)
}
//輸出:[0]
//[1]
切片是參考型別,所以在傳遞時,遵守參考傳遞機制,看兩段代碼,并分析底層原理
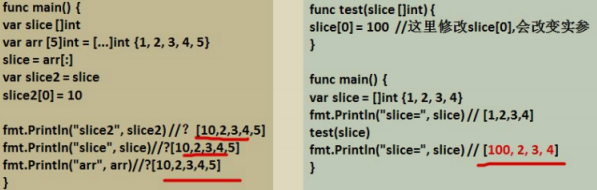
string和slice
string底層是一個byte陣列,因此string也可以進行切片處理
func main(){
str := "hello@zisefeizhu"
//使用切片獲取到zisefeizhu
slice := str[6:]
fmt.Println("slice = ",slice)
}
//輸出:slice = zisefeizhu
string和切片在記憶體的形式,以”abcd”畫出記憶體示意圖
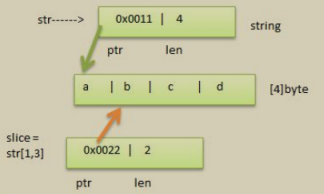
string是不可變的,也就是說不能通過str[0] = ‘z’ 方式來修改字串

如果需要修改字串,可以先將string -> []byte /或者 []rune -> 修改 -> 重寫轉成string
如果需要修改字串,可以先將string -> []byte /或者 []rune -> 修改 -> 重寫轉成string
//"hello@zisefeizhu" => 改成 "zello@zisefeizhu"
arr1 := []byte(str)
arr1[0] = 'z'
str = string(arr1)
fmt.Println("str = ",str)
//細節:我們轉成[]byte后,可以處理英文和數字,但是不能處理中文
//原因是[]byte位元組來處理,而一個漢字,是3個位元組,因此就會出現亂碼
//解決方法是 將 string 轉成 []rune 即可,因為[]rune 是按字符處理,兼容漢字
arr2 := []rune(str)
arr2[0] = '北'
str = string(arr1)
fmt.Println("str = ", str)
}
//輸出:slice = zisefeizhu
//str = zello@zisefeizhu
//str = zello@zisefeizhu
切片練習題
說明:撰寫一個函式 fbn(n int),要求完成
-
可以接收一個n int
-
能夠將斐波那契的數列放到切片中
-
提示,斐波那契的數列形式:
arr[0] = 1; arr[1] = 1; arr[2] = 2; arr[3] = 3; arr[4] = 5; arr[5] = 8
package main
import "fmt"
func fbn(n int) ([]uint64) {
//宣告一個切片,切片大小n
fbnSlice := make([]uint64, n)
//第一個數和第二個數的斐波那契為 1
fbnSlice[0] = 1
fbnSlice[1] = 1
//進行for回圈來存放斐波那契的數列
for i := 2; i < n; i++ {
fbnSlice[i] = fbnSlice[i - 1] + fbnSlice[i - 2]
}
return fbnSlice
}
func main() {
/*
1)可以接收一個n int
2)能夠將斐波那契的數列放到切片中
3)提示,斐波那契的數列形式:
arr[0] = 1; arr[1] = 1; arr[2] = 2; arr[3] = 3; arr[4] = 5; arr[5] = 8
思路
1. 宣告一個函式fbn(n int) ([]uint64)
2. 編程fbn(n int) 進行for回圈來存放斐波那契的數列 0 =》1 1 =》 1
*/
fnbSlice := fbn(20)
fmt.Println("fnbSlice = ",fnbSlice)
}
//輸出:fnbSlice = [1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 6765]
排序
排序
排序是將一組資料,依指定的順序進行排序的程序
排序的分類
1)內部排序:
指將需要處理的所有資料都加載到內部存盤器中進行排序
包括(交換式排序法、選擇式排序法和插入式排序法);
2)外部排序法
資料量過大,無法全部加載到記憶體中,需要借助外部存盤進行排序
包括(合并排序法和直接合并排序法)
冒泡排序的思路分析


冒泡排序實作
//冒泡排序
func BubbleSort(arr *[5]int) {
fmt.Println("排序前arr = ",(*arr))
temp := 0 //臨時變數(用于做交換)
//冒泡排序:一步一步推匯出來的
for i := 0; i < len(*arr) - 1; i++ {
for j := 0; j < len(*arr) -1 - i; j++ {
if (*arr)[j] < (*arr)[j + 1] {
//交換
temp = (*arr)[j]
(*arr)[j] = (*arr)[j + 1]
(*arr)[j + 1] = temp
}
}
}
fmt.Println("排序后arr = ",(*arr))
}
func main() {
//定義陣列
arr := [...]int {24,69,80,57,13}
//將陣列傳遞給一個函式,完成排序
BubbleSort(&arr)
fmt.Println("main arr = ",arr) //有序? 是有序的
}
//輸出:排序前arr = [24 69 80 57 13]
//排序后arr = [80 69 57 24 13]
//main arr = [80 69 57 24 13]
優化
//冒泡排序
func BubbleSort(arr []int) []int {
fmt.Println("排序前arr = ", arr)
flag := true
//冒泡排序:一步一步推匯出來的
for i := 0; i < len(arr) - 1; i++ {
for j := 0; j < len(arr) -1 - i; j++ {
if arr[j] < arr[j + 1] {
//交換
Swap(arr, j , j+1)
flag = false
}
}
//優化不必要的交換
if flag {
break
}
}
return arr
}
func Swap(arr []int, i int, j int ) {
temp := arr[i]
arr[i] = arr[j]
arr[j] = temp
}
func main() {
//定義陣列
arr := []int {24,69,80,57,13}
//將陣列傳遞給一個函式,完成排序
num := BubbleSort(arr)
fmt.Println("main num = ",num)
}
//排序前arr = [24 69 80 57 13]
//main num = [80 69 57 24 13]
冒泡排序練習題
package main
//要求:隨機生成5個元素的陣列,并使用冒泡排序對其排序 從小到大
//思路分析:
//亂數用math/rand生成為了更好的保證其不會重復 使用 rand.New(rand.NewSource(time.Now().UnixNano()))并定義一個隨機生成函式
//用冒泡排序對其排序
import (
"fmt"
"math/rand"
"time"
)
var arrnum [5]int = [5]int{109,137,49,190,87}
//定義冒泡函式
//重復地走訪過要排序的元素列,依次比較兩個相鄰的元素,如果他們的順序(如從大到小、首字母從A到Z)
// 錯誤就把他們交換過來,走訪元素的作業是重復地進行直到沒有相鄰元素需要交換,也就是說該元素已經排序完成
func BubbleSort( arrary *[5]int){
//第一次比較
fmt.Println("排序前arr=",(*arrary))
tmp :=0
for j := 0 ; j <len(arrary)-1 ;j++{
for i :=0;i <len(arrary)-1-j ;i++ {
if arrary[i] > arrary[i+1]{
tmp = arrary[i]
arrary[i] = arrary[i+1]
arrary[i+1] = tmp
}
}
}
fmt.Println("排序后arr=",(*arrary))
}
var Arrname [5]int
func main() {
r := rand.New(rand.NewSource(time.Now().UnixNano()))//生成亂數字
for i := 0; i < len(Arrname) ; i++ {
Arrname[i] = r.Intn(20000) //指定生成亂數的范圍
}
BubbleSort(&Arrname)
}
查找
在Go中,常用的查找有兩種:
-
順序查找
-
二分查找(該陣列是有序)
案例演示
1)有一個數列:白眉鷹王、金毛獅王、紫衫龍王、青翼蝠王
猜數游戲:從鍵盤中任意輸入一個名稱,判斷數列中是否包含此名稱【順序查找】
func main() {
names := [4]string{"白眉鷹王","金毛獅王","紫衫龍王","青翼蝠王"}
var heroName = ""
fmt.Println("請輸入要查找的人名...")
fmt.Scanln(&heroName)
//順序查找:第一種方式
for i := 0; i < len(names); i++ {
if heroName == names[i] {
fmt.Printf("找到%v 下標%v \n",heroName,i)
break
} else if i == (len(names) -1 ) {
fmt.Printf("沒有找到%v \n",heroName)
}
}
//順序查找:第二種方式【推薦...】
index := -1
for i := 0; i < len(names); i++ {
if heroName == names[i] {
index = i //將找到的值對應的下標賦給index
break
}
}
if index != -1 {
fmt.Printf("找到%v,下標%v \n",heroName,index)
} else {
fmt.Println("沒有找到",heroName)
}
}
//輸出:請輸入要查找的人名... 白眉鷹王 找到白眉鷹王 下標0 找到白眉鷹王,下標0
- 請對一個有序陣列進行二分查找 {1,8,10,89,1000,1234},輸入一個數看看該陣列是否存在此數,并且求出下標,如果沒有就提示”沒有這個數”【會使用到遞回】
二分查找的思路分析

//二分法查找
/*
二分查找思路:比如要查找的數是findVal
1. arr是一個有序陣列,并且是從小到大排序
2. 先找到中間的下標middle = (leftIndex + rightIndex)/2,然后讓中間下標的值和findVal進行比較
2.1 如果arr[middle] > findVal 就應該向 leftIndex --- (middle - 1)
2.2 如果arr[middle] < findVal 就應該向 (middle + 1) --- rightIndex
2.3 如果arr[middle] == findVal 就找到
2.4 上面的2.1 2.2 2.3 的邏輯會遞回執行
3. 想一下,怎么樣的情況下,就說明找不到【分析出退出遞回的條件!!】
if leftIndex > rightIndex {
//找不到...
return ...
}
*/
func BinaryFind(arr *[6]int, leftIndex int, rightIndex int, findVal int) {
//判斷leftIndex是否大于rightIndex
if leftIndex > rightIndex {
fmt.Println("找不到")
return
}
//先找到 中間的下標
middle := (leftIndex + rightIndex) / 2
if (*arr)[middle] > findVal {
//說明要查找的數,應該在leftIndex -- (middle - 1)
BinaryFind(arr, leftIndex, middle - 1, findVal)
} else if (*arr)[middle] < findVal {
//說明要查找的數,應該在middle + 1 -- rightIndex
BinaryFind(arr, middle + 1, rightIndex, findVal)
} else {
//找到了
fmt.Printf("找到了,下標為%v \n",middle)
}
}
func main() {
arr := [6]int {1,8,89,1000,1234}
//測驗
BinaryFind(&arr,0,len(arr) - 1, 1234)
}
//輸出:找到了,下標為4
二維陣列
請用二維陣列輸出如下圖形
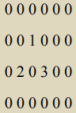
func main() {
//定義/宣告二維陣列
var arr [4][6]int
//賦初值
arr[1][2] = 1
arr[2][1] = 2
arr[2][3] = 3
//遍歷二維陣列,按照要求輸出圖形
for i := 0; i < 4; i++ {
for j := 0; j < 6; j++ {
fmt.Print(arr[i][j]," ")
}
fmt.Println()
}
}
//0 0 0 0 0 0
//0 0 1 0 0 0
//0 2 0 3 0 0
//0 0 0 0 0 0
二維陣列在記憶體的存在形式
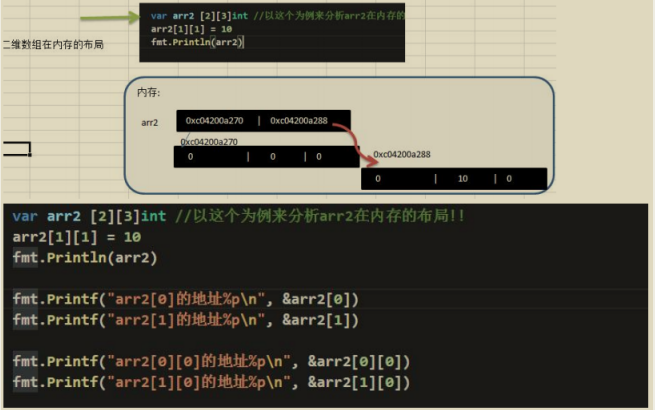
二維陣列在宣告/定義時的寫法
1)var 陣列名 [大小][大小]型別 = [大小][大小]型別{{初值...},{初值...}}
2)var 陣列名 [大小][大小]型別 = [...][大小]型別{{初值...},{初值...}}
3)var 陣列名 = [大小][大小]型別{{初值...},{初值...}}
4)var 陣列名 = [...][大小]型別{{初值...},{初值...}}
二維陣列的遍歷
func main() {
//演示二維陣列的遍歷
var arr = [2][3]int{{1,2,3},{4,5,6}}
//for回圈遍歷
for i := 0; i < len(arr); i++ {
for j := 0; j < len(arr[i]); j++ {
fmt.Printf("%v\t",arr[i][j])
}
fmt.Println()
}
//for-range遍歷二維陣列
for i, v := range arr {
for j, v2 := range v {
fmt.Printf("arr[%v][%v]=%v\t",i,j,v2)
}
fmt.Println()
}
}
二維陣列的應用案例
定義二維陣列,用于保存三個班,每個班五名同學成績,
并求出每個班級平均分、以及所有班級平均分
func main() {
//定義二維陣列,用于保存三個班,每個班五名同學成績,
//并求出每個班級平均分、以及所有班級平均分
//1.定義二維陣列
var scores [3][5]float64
//2.回圈的輸入成績
for i := 0; i < len(scores); i++ {
for j := 0; j < len(scores[i]); j++ {
fmt.Printf("請輸入第%d班的第%d個學生的成績\n",i+1, j+1)
fmt.Scanln(&scores[i][j])
}
}
//fmt.Println(scores)
//3.遍歷輸出成績后的二維陣列,統計平局分
totalSum := 0.0 //定義一個變數,用于累計所有班級的總分
for i := 0; i < len(scores); i++ {
sum := 0.0 //定義一個變數,用于累計各個班級的總分
for j := 0; j < len(scores[i]); j++ {
sum += scores[i][j]
}
totalSum += sum
fmt.Printf("第%d班級的總分為%v,平均分%v\n", i + 1, sum, sum / float64(len(scores[i])))
}
fmt.Printf("所有班級的總分為%v,所有班級平均分%v\n", totalSum, totalSum / 15 )
}
二維陣列練習題
轉置概念:矩陣的行列互換得到的新矩陣稱為轉置矩陣,而二維陣列就是我們通常說的矩陣,
需求:使用Go語言方法實作二維陣列(3*3)的矩陣的轉置
轉置前:
? [ 0, 1, 2]
? [ 4, 5, 6]
? [ 8, 9, 10]
轉置后
? [ 0, 4, 8]
? [ 1, 5, 9]
? [ 2, 6, 10]
type Num struct {
}
func (array Num ) Upserver(Aaaay3 [3][3]int) {
for i :=0; i<len(Aaaay3);i++{
for j:=0;j<i;j++{
Aaaay3[i][j],Aaaay3[j][i] = Aaaay3[j][i],Aaaay3[i][j]
}
}
fmt.Println(Aaaay3)
}
func (array Num ) Upserver2(Aaaay3 [3][3]int) {
temparry :=[3][3]int{}
for i :=0; i<len(Aaaay3);i++{
for j:=0;j<i;j++{
temparry[i][j]=Aaaay3[i][j]
Aaaay3[i][j] =Aaaay3[j][i]
Aaaay3[j][i]=temparry[i][j]
}
}
fmt.Println(Aaaay3)
}
func main() {
arrinfo :=Num{
}
aeey :=[3][3]int{
{0, 1, 2} , /* 第一行索引為 0 */
{4, 5, 6} , /* 第二行索引為 1 */
{8, 9, 10}}
fmt.Println(aeey)
fmt.Println("****")
arrinfo.Upserver(aeey)
arrinfo.Upserver2(aeey)
}
Map
map是key-value資料結構,又稱為欄位或者關聯陣列,類似其它編程語言的集合,在編程中是經常使用到的
v 內部實作
Map是給予散串列來實作,就是我們常說的Hash表,所以我們每次迭代Map的時候,列印的Key和Value是無序的,每次迭代的都不一樣,即使我們按照一定的順序存在也不行,
Map的散串列包含一組桶,每次存盤和查找鍵值對的時候,都要先選擇一個桶,如何選擇桶呢?就是把指定的鍵傳給散列函式,就可以索引到相應的桶了,進而找到對應的鍵值,
這種方式的好處在于,存盤的資料越多,索引分布越均勻,所以我們訪問鍵值對的速度也就越快,當然存盤的細節還有很多,大家可以參考Hash相關的知識,這里我們記住Map存盤的是無序的鍵值對集合
map的宣告
var 變數名 map[keytype]valuetype
key可以是什么型別
Go中的map的key可以是很多種型別,比如bool、數字、string、指標、channel,還可以是只包含前面幾個型別的 介面、結構體、陣列
通常key為int、string
注意:slice、map還有function不可以,因為這幾個沒法用 == 來判斷
valuetype可以是什么型別
valuetype的型別和key基本一樣
通常為:數字(整數,浮點數)、string、map、struct
map宣告的舉例:
var a map[string]string
var a map[string]int
var a map[int]string
var a map[string]map[string]string
注意:宣告是不會分配記憶體的,初始化需要make,分配記憶體后才能賦值和使用
func main() {
//map的宣告和注意事項
var a map[string]string
//在使用map前,需要先make,make的作用就是給map分配資料空間
a = make(map[string]string,10)
a["no1"] = "松江"
a["no2"] = "無用"
a["no1"] = "武松"
a["no3"] = "無用"
fmt.Println(a)
}
//輸出:map[no1:武松 no2:無用 no3:無用]
對上面代碼的說明
1)map在使用前一定要make
2)map的key是不能重復的,如果重復了,則以最后這個key-value為準
3)map的value是可以相同的
4)map的key-value是無序的
5)make內置函式數目
map的使用
方式1:
func main() {
//第一種使用方式
var a map[string]string
//在使用map前,需要先make,make的作用就是給map分配資料空間
a = make(map[string]string,10)
a["no1"] = "松江"
a["no2"] = "無用"
a["no1"] = "武松"
a["no3"] = "無用"
fmt.Println(a)
}
方式2:
func main() {
//第二種方式
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities)
//輸出:map[no1:北京 no2:天津 no3:上海]
方式3:
func main() {
//第三種方式
heroes := map[string]string {
"her01" : "宋江",
"her02" : "吳用",
"her03" : "林沖",
}
heroes["her04"] = "武松"
fmt.Println("heroes = ",heroes)
}
//heroes = map[her01:宋江 her02:吳用 her03:林沖 her04:武松]
map的增刪改查操作
map增加和更新
map["key"] = value //如果key還沒有,就是增加,如果key存在就是修改
func main(){
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities)
//因此no3 這個key已經存在,因此下面的這句就是修改
cities["no3"] = "上海~"
fmt.Println(cities)
}
//輸出:map[no1:北京 no2:天津 no3:上海]
//map[no1:北京 no2:天津 no3:上海~]
map洗掉
delete(map,"key"),delete是一個內置函式,如果key存在,就洗掉該key-value,如果key不存在,不操作,但是也不會報錯

func main(){
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities) //map[no1:北京 no2:天津 no3:上海]
//因此no3 這個key已經存在,因此下面的這句就是修改
cities["no3"] = "上海~"
fmt.Println(cities) //map[no1:北京 no2:天津 no3:上海~]
//演示洗掉
delete(cities,"no1")
fmt.Println(cities) //map[no2:天津 no3:上海~]
//當delete指定的key不存在時,洗掉不會操作,也不會報錯
delete(cities,"no4")
fmt.Println(cities) //map[no2:天津 no3:上海~]
如果要洗掉map的所有key,沒有一個專門的方法一次洗掉,可以遍歷一下key,逐個洗掉或者map = make(...),make一個新的,讓原來的成為垃圾,被gc回收
func main(){
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities) //map[no1:北京 no2:天津 no3:上海]
//因此no3 這個key已經存在,因此下面的這句就是修改
cities["no3"] = "上海~"
fmt.Println(cities) //map[no1:北京 no2:天津 no3:上海~]
//演示洗掉
delete(cities,"no1")
fmt.Println(cities) //map[no2:天津 no3:上海~]
//當delete指定的key不存在時,洗掉不會操作,也不會報錯
delete(cities,"no4")
fmt.Println(cities) //map[no2:天津 no3:上海~]
//如果希望一次性洗掉所有的key
//1. 遍歷所有的key,遍歷逐一洗掉
//2. 直接make一個新的空間
cities = make(map[string]string)
fmt.Println(cities) //map[]
}
map查找
func main(){
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities) //map[no1:北京 no2:天津 no3:上海]
//因此no3 這個key已經存在,因此下面的這句就是修改
cities["no3"] = "上海~"
fmt.Println(cities) //map[no1:北京 no2:天津 no3:上海~]
//演示map 的查找
va1, ok := cities["no2"]
if ok {
fmt.Printf("有no2 key值為%v\n",va1) //有no2 key值為天津
} else {
fmt.Printf("沒有no2 key\n")
}
}
對上面代碼的說明:
說明:如果cities這個map中存在”no2”,那么ok就會回傳true,否則回傳false
map遍歷
案例演示相對復雜的map遍歷:該map的value又是一個map
說明:map的遍歷使用for-range的結構遍歷
func main() {
//使用for-range遍歷map
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
for k,v := range cities {
fmt.Printf("k = %v v = %v\n",k,v)
}
//使用for-range遍歷一個結構比較復雜的map
studentMap := make(map[string]map[string]string)
studentMap["stu01"] = make(map[string]string, 3)
studentMap["stu01"]["name"] = "tom"
studentMap["stu01"]["sex"] = "男"
studentMap["stu01"]["address"] = "北京長安街"
studentMap["stu02"] = make(map[string]string, 3) //這句話不能少!!!
studentMap["stu02"]["name"] = "mary"
studentMap["stu02"]["sex"] = "女"
studentMap["stu02"]["address"] = "上海黃埔江"
for k1, v1 := range studentMap {
fmt.Println("k1 = ",k1)
for k2, v2 := range v1 {
fmt.Printf("\t k2 = %v v2 = %v \n",k2,v2)
}
fmt.Println()
}
}
//輸出:k = no1 v = 北京
//k = no2 v = 天津
//k = no3 v = 上海
//k1 = stu01
// k2 = name v2 = tom
// k2 = sex v2 = 男
// k2 = address v2 = 北京長安街
//
//k1 = stu02
// k2 = name v2 = mary
// k2 = sex v2 = 女
// k2 = address v2 = 上海黃埔江
map的長度
func main() {
//使用for-range遍歷map
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
for k,v := range cities {
fmt.Printf("k = %v v = %v\n",k,v)
}
fmt.Println(len(cities)) //3
}
map切片
切片的資料型別如果是map,則我們稱為slice of map,map切片,這樣使用則map個數就可以動態變化了
案例演示
要求:使用一個map來記錄monster的資訊name和age,也就是說一個monster對應一個map,并且妖怪的個數可以動態的增加=》map切片
package main
import (
"fmt"
_ "unicode"
)
func main() {
var monsters []map[string]string
monsters = make([]map[string]string,2) //準備放入兩個妖怪
//2. 增加第一個妖怪的資訊
if monsters[0] == nil {
monsters[0] = make(map[string]string,2)
monsters[0]["name"] = "牛魔王"
monsters[0]["age"] = "500"
}
if monsters[1] == nil {
monsters[1] = make(map[string]string, 2)
monsters[1]["name"] = "玉兔精"
monsters[1]["age"] = "400"
}
//下面這個寫法越界
//if monsters[2] == nil {
// monsters[2] = make(map[string]string, 2)
// monsters[2]["name"] = "狐貍精"
// monsters[2]["age"] = "300"
// }
//這里需要使用到切片的append函式,可以動態的增加monster
//1. 先定義monster資訊
newMonster := map[string]string {
"name" : "新的妖怪-孫悟空",
"age" : "1500",
}
monsters = append(monsters,newMonster)
fmt.Println(monsters)
}
//輸出:[map[age:500 name:牛魔王] map[age:400 name:玉兔精] map[age:1500 name:新的妖怪-孫悟空]]
map排序
Go中沒有一個專門的方法針對map的key進行排序
Go中的map默認是無序的,注意也不是按照添加的順序存放的,每次遍歷,得到的輸出可能不一樣
Go中map的排序,是先將key進行排序,然后根據key值遍歷輸出即可
案例演示
package main
import (
"fmt"
"sort"
)
func main() {
//map的排序
map1 := make(map[int]int,10)
map1[10] = 100
map1[1] = 13
map1[4] = 56
map1[8] = 90
fmt.Println(map1)
//如果按照map的key的順序進行排序輸出
//1. 先將map的key放入到切片中
//2. 對切片排序
//3. 遍歷切片,然后按照key來輸出map的值
var keys []int
for k, _ := range map1 {
keys = append(keys, k)
}
//排序
sort.Ints(keys)
fmt.Println(keys)
for _, k := range keys {
fmt.Printf("map1[%v] = %v \n", k, map1[k])
}
}
//輸出:map[1:13 4:56 8:90 10:100]
//[1 4 8 10]
//map1[1] = 13
//map1[4] = 56
//map1[8] = 90
//map1[10] = 100
map使用細節
map是參考型別,遵守參考型別傳遞的機制,在一個函式接收map,修改后,會直接修改原來的map
func modify(map1 map[int]int) {
map1[10] = 900
}
func main() {
map1 := make(map[int]int)
map1[1] = 90
map1[2] = 88
map1[10] = 1
map1[20] = 2
modify(map1)
fmt.Println(map1)
}
//輸出:map[1:90 2:88 10:900 20:2]
map的容量達到后,再想map增加元素,會自動擴容,并不會發生panic,也就是說map能動態的增長 鍵值對(key-value)
map的value也經常使用struct類,更適合管理復雜的資料(比前面value是一個map更好),比如value為Student結構體
type Stu struct {
Name string
Age int
Address string
}
func main() {
//3)map的value也經常使用struct型別,
// 更適合管理復雜的資料(比前面value是一個map更好),
// 比如value為Student結構體
//1. map 的 key 為學生的學號,是唯一的
//2. map的value 為結構體,包含學生的名字,年齡,地址
students := make(map[string]Stu, 10)
//創建2個學生
stu1 := Stu{"tom", 18, "北京"}
stu2 := Stu{"mary", 28, "上海"}
students["no1"] = stu1
students["no2"] = stu2
fmt.Println(students)
//遍歷各個學生資訊
for k, v := range students {
fmt.Printf("學生的編號是%v \n",k)
fmt.Printf("學生的名字是%v \n",v.Name)
fmt.Printf("學生的年齡是%v \n",v.Age)
fmt.Printf("學生的地址是%v \n",v.Address)
}
}
//map[no1:{tom 18 北京} no2:{mary 28 上海}]
//學生的編號是no1
//學生的名字是tom
//學生的年齡是18
//學生的地址是北京
//學生的編號是no2
//學生的名字是mary
//學生的年齡是28
//學生的地址是上海
map練習題
演示一個key-value的value是map的案例
? 比如:要存放3個學生資訊,每個學生有name和sex資訊
? 思路: map[string]map[string]string
func main() {
studentMap := make(map[string]map[string]string)
studentMap["stu01"] = make(map[string]string, 3)
studentMap["stu01"]["name"] = "tom"
studentMap["stu01"]["sex"] = "男"
studentMap["stu01"]["address"] = "北京長安街"
studentMap["stu02"] = make(map[string]string, 3) //這句話不能少!!!
studentMap["stu02"]["name"] = "mary"
studentMap["stu02"]["sex"] = "女"
studentMap["stu02"]["address"] = "上海黃埔江"
fmt.Println(studentMap) //map[stu01:map[address:北京長安街 name:tom sex:男] stu02:map[address:上海黃埔江 name:mary sex:女]]
fmt.Println(studentMap["stu02"]) //map[address:上海黃埔江 name:mary sex:女]
fmt.Println(studentMap["stu02"]["address"]) //上海黃埔江
}
撰寫一個函式modifyUser(users map[string]map[string]string,name string)完成上下述功能
-
使用map[string]map[string]string的map型別
-
key:表示用戶名,是唯一的,不可以重復
-
如果某個用戶存在,就將其密碼修改"888888",如果不存在就增加這個用戶資訊(包括昵稱nickname和密碼pwd),
func modifyUser(users map[string]map[string]string,name string) {
//判斷users中是否有name
//v,ok := users[name]
if users[name] != nil {
//有這個用戶
users[name]["pwd"] = "888888"
} else {
//沒有這個用戶
users[name] = make(map[string]string,2)
users[name]["pwd"] = "888888"
users[name]["nickname"] = "昵稱~" + name //示意
}
}
func main() {
users := make(map[string]map[string]string,10)
users["smith"] = make(map[string]string,2)
users["smith"]["pwd"] = "999999"
users["smith"]["nickname"] = "小花貓"
modifyUser(users,"tom")
modifyUser(users,"mary")
modifyUser(users,"smith")
fmt.Println(users)
}
//輸出:map[mary:map[nickname:昵稱~mary pwd:888888] smith:map[nickname:小花貓 pwd:888888] tom:map[nickname:昵稱~tom pwd:888888]]
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/30777.html
標籤:Go
下一篇:go語言系列-面向物件編程