知識點
- requests
- parsel
- re
- os
環境
- python3.8
- pycharm2021
目標網址:
https://mm.enterdesk.com/bizhi/63899-347866.html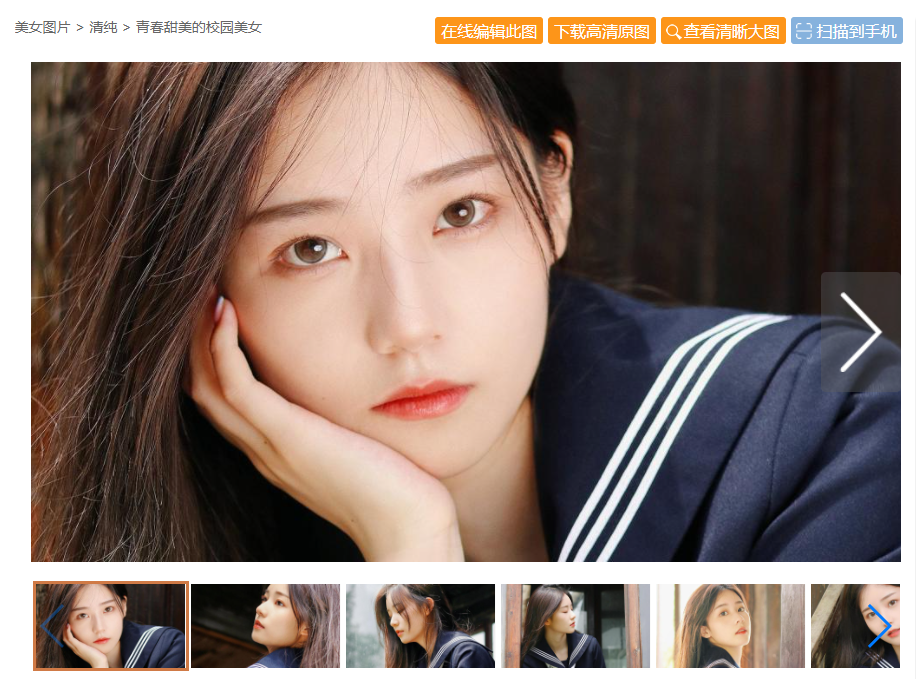
【付費VIP完整版】只要看了就能學會的教程,80集Python基礎入門視頻教學
注意: 在我們查看網頁源代碼的時候 (1. 控制臺為準 2. 以右鍵查看網頁源代碼 3. 元素面板)
- 發送網路請求
- 獲取網頁源代碼
- 提取想要的圖片鏈接
css樣式提取 xpath re正則運算式 bs4 - 替換所有的圖片鏈接 換成大圖
- 保存圖片
爬蟲代碼
匯入模塊
import requests # 第三方庫 pip install requests import parsel # 第三方庫 pip install parsel import os # 新建檔案夾
發送網路請求
response = requests.get('https://mm.enterdesk.com/bizhi/64011-348522.html')
獲取網頁源代碼
data_html = response_1.text
提取每個相冊的詳情頁鏈接地址
selector_1 = parsel.Selector(data_html) photo_url_list = selector_1.css('.egeli_pic_dl dd a::attr(href)').getall() title_list = selector_1.css('.egeli_pic_dl dd a img::attr(title)').getall() for photo_url, title in zip(photo_url_list, title_list): print(f'*****************正在爬取{title}*****************') response = requests.get(photo_url) # <Response [200]>: 請求成功的標識 selector = parsel.Selector(response.text) # 提取想要的圖片鏈接[第一個鏈接, 第二個鏈接,....] img_src_list = selector.css('.swiper-wrapper a img::attr(src)').getall() # 新建一個檔案夾 if not os.path.exists('img/' + title): os.mkdir('img/' + title)
替換所有的圖片鏈接 換成大圖
for img_src in img_src_list: # 字串的替換 img_url = img_src.replace('_360_360', '_source')
保存圖片 圖片名字
# 圖片 音頻 視頻 二進制資料content img_data =https://www.cnblogs.com/qshhl/p/ requests.get(img_url).content # 圖片名稱 字串分割 # 分割完之后 會給我們回傳一個串列 img_title = img_url.split('/')[-1] with open(f'img/{title}/{img_title}', mode='wb') as f: f.write(img_data) print(img_title, '保存成功!!!')
翻頁
page_html = requests.get('https://mm.enterdesk.com/').text counts = parsel.Selector(page_html).css('.wrap.no_a::attr(href)').get().split('/')[-1].split('.')[0] for page in range(1, int(counts) + 1): print(f'------------------------------------正在爬取第{page}頁------------------------------------') 發送網路請求 response_1 = requests.get(f'https://mm.enterdesk.com/{page}.html')
爬取結果

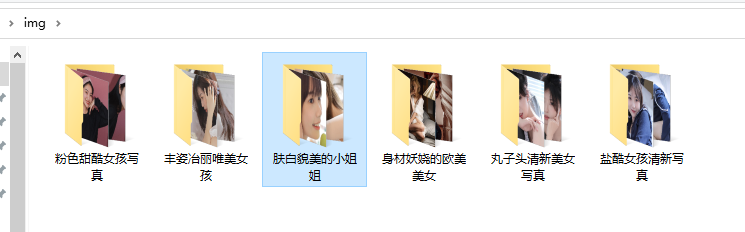
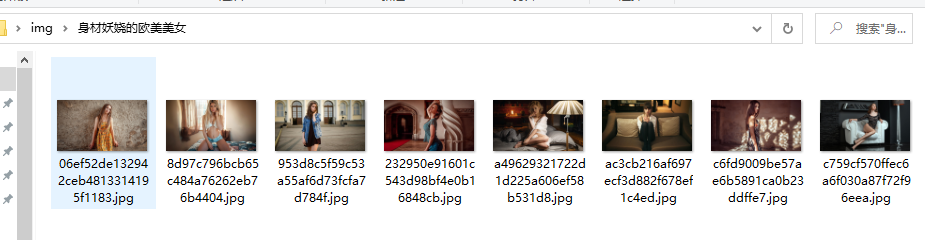
對于本篇文章有疑問,或者想要資料集的同學也加資料分享解答群:1039649593
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/308216.html
標籤:Python
下一篇:pandas學習筆記2