RFM模型
RFM模型是衡量客戶價值和客戶創利能力的重要工具和手段,是一種探索性資料分析方法,在眾多的客戶關系管理(CRM)的分析模式中,RFM模型是最被廣泛提及的,該模型通過3項指標來描述該客戶的價值狀況,根據美國資料庫營銷研究所Arthur Hughes的研究,客戶資料庫中有三個神奇的要素,這三個要素構成了資料分析最好的指標:
- 最近一次消費(Recency):表示用戶最近一次消費距離現在的時間,消費時間越近的客戶價值越大,1年前消費過的用戶肯定沒有1周前消費過的用戶價值大,
- 消費頻率(Frequency) :消費頻率是指用戶在統計周期內購買商品的次數,經常購買的用戶也就是熟客,價值肯定比偶爾來一次的客戶價值大,
- 消費金額(Monetary):消費金額是指用戶在統計周期內消費的總金額,體現了消費者為企業創造利潤的多少,自然是消費越多的用戶價值越大,
企業在推行CRM時,就要根據RFM模型的原理,了解客戶差異,并以此分類進行企業流程重建,才能創新業績與利潤,
客戶分類
基于這三個維度,將每個維度分為高低兩種情況,我們構建出了一個三維的坐標系,分為8個客戶型別維度切片,
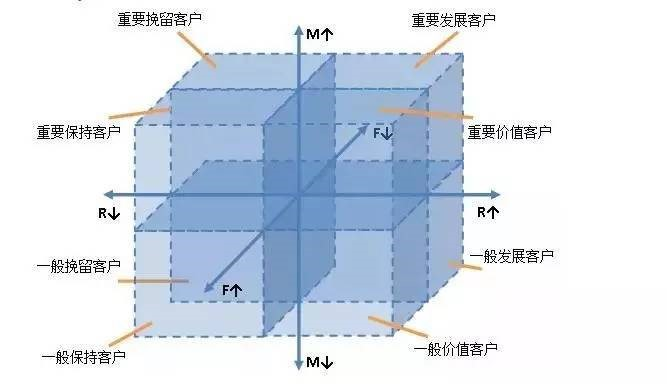
| 客戶型別 | R(最近一次消費時間) | F(消費頻率) | M(消費總金額) |
| 重要價值客戶 | 高 | 高 | 高 |
| 重要發展客戶 | 高 | 低 | 高 |
| 重要保持客戶 | 低 | 高 | 高 |
| 重要挽留客戶 | 低 | 低 | 高 |
| 一般價值客戶 | 高 | 高 | 低 |
| 一般發展客戶 | 高 | 低 | 低 |
| 一般保持客戶 | 低 | 高 | 低 |
| 一般挽留客戶 | 低 | 低 | 低 |
客戶價值分析
RFM評分:由于R值、F值、M值存在量級之間的差距,無法直觀的通過加級訓平均來衡量用戶價值,根據三組資料各個值的特性,采用機器學習特征工程之資料分箱來衡量客戶價值,
關于變數分箱主要分為兩大類:有監督型和無監督型
對應的分箱方法:
A. 無監督:(1) 等寬 (2) 等頻 (3) 聚類 K-Means
B. 有監督:(1) 卡方分箱法(ChiMerge) (2) ID3、C4.5、CART等單變數決策樹演算法 (3) 信用評分建模的IV最大化分箱 等
資料分析
1 import pandas as pd
2 import numpy as np
3
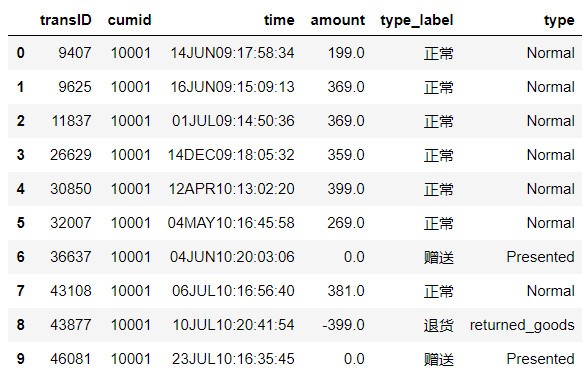
4 #1. 匯入示例交易訂單資料
5 df = pd.read_csv(r'D:\python_test\Data_Mining\data\RFM_TRAD_FLOW.csv', encoding='GBK')
6 df.head(10)
1 # 2.按照RFM方法進行資料處理
2
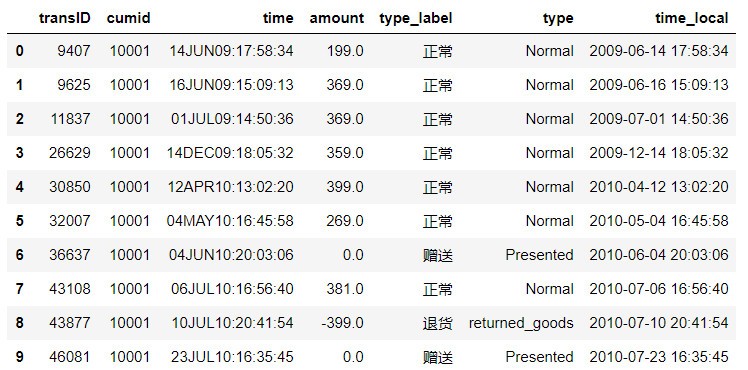
3 # time欄位是英式日期時間標識法,轉換成中國本地日期時間表示法以便于查看,
4 import time
5 df['time_local'] = pd.to_datetime(df['time'], errors='coerce', format='%d%b%y:%H:%M:%S')
6 df.head(10)
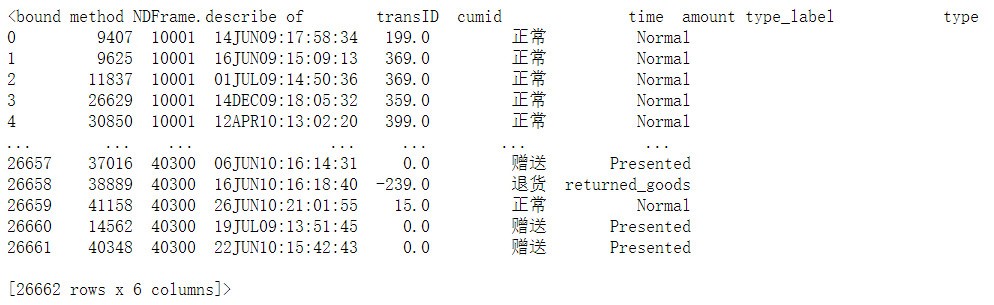
1 # 觀察交易金額資料可以看到有0消費額,有負數消費額,繼續查看交易型別,發現為“贈送”和“退貨”所造成,
2 # 先查看一下資料的基本情況發現是26662行,6列的資料集,
3 df.describe
1 # 查看一下贈送和退貨比例這些<=0占總數的比例是多少?如果很少就洗掉,查看后發現占消費比例竟然達到了33.97 %,
2 # 許多網上分析認為這些是無效資料,但是我個人認為這些型別其實也是消費真實情況的一部分,盡量不要篡改資料是資料分析的基本原則,因此我還是保留了這部分資料納入分析體系,
3 a = 1-df['transID'][df.amount>0].count()/df['transID'].count()
4 print('贈送和退貨比例占總數的{0:^6.2f}%'.format(a*100))

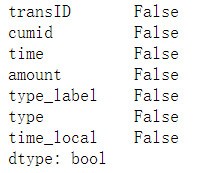
1 # 查看資料中是否存在Na等缺失值,如果有fillna(0)填充, 2 # 結果發現資料完好并不存在缺失值 3 df.isna().any()
資料處理
1 # 將時間字串轉換成時間戳 2 # pandas 用 Timestamp 表示時點數 3 import time 4 df['timestamp'] = df['time'].apply(lambda x:time.mktime(time.strptime(x,'%d%b%y:%H:%M:%S')))
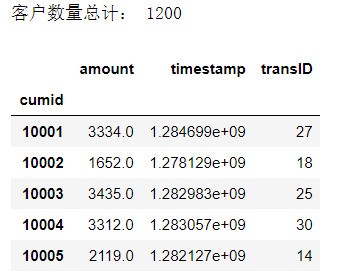
1 # 構造RMF模型的特征值 2 rfm = df.pivot_table( 3 index = 'cumid', 4 values = ['timestamp','transID','amount'], 5 aggfunc = { 6 'timestamp':'max', # R 最近消費時間 7 'transID':'count',# F 消費頻率 8 'amount':'sum', # M 消費總金額 9 }) 10 print('客戶數量總計:',len(rfm)) 11 rfm.head()
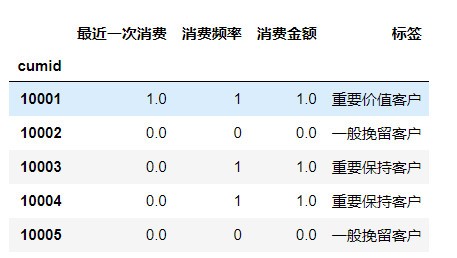
1 ### 構建模型,篩選目標客戶,通過將需要轉換成類別型資料的連續型資料進行二值化,用1,0分別代表高低 2 3 from sklearn import preprocessing 4 5 threshold = pd.qcut(rfm["timestamp"], 2, retbins=True)[1][1] 6 binarizer = preprocessing.Binarizer(threshold=threshold) 7 time_new_q = pd.DataFrame(binarizer.transform(rfm["timestamp"].values.reshape(-1, 1))) 8 time_new_q.index=rfm.index 9 time_new_q.columns=["最近一次消費"] 10 11 threshold = pd.qcut(rfm['transID'], 2, retbins=True)[1][1] 12 binarizer = preprocessing.Binarizer(threshold=threshold) 13 interest_q = pd.DataFrame(binarizer.transform(rfm['transID'].values.reshape(-1, 1))) 14 interest_q.index=rfm.index 15 interest_q.columns=["消費頻率"] 16 17 threshold = pd.qcut(rfm['amount'], 2, retbins=True)[1][1] 18 binarizer = preprocessing.Binarizer(threshold=threshold) 19 value_q = pd.DataFrame(binarizer.transform(rfm['amount'].values.reshape(-1, 1))) 20 value_q.index=rfm.index 21 value_q.columns=["消費金額"] 22 23 24 analysis=pd.concat([time_new_q, interest_q, value_q], axis=1) 25 26 analysis = analysis[['最近一次消費','消費頻率','消費金額']] 27 # analysis.head() 28 29 label = { 30 (1,1,1):'重要價值客戶', 31 (1,0,1):'重要發展客戶', 32 (0,1,1):'重要保持客戶', 33 (0,0,1):'重要挽留客戶', 34 (1,1,0):'一般價值客戶', 35 (1,0,0):'一般發展客戶', 36 (0,1,0):'一般保持客戶', 37 (0,0,0):'一般挽留客戶', 38 } 39 analysis['標簽'] = analysis[['最近一次消費','消費頻率','消費金額']].apply(lambda x: label[(x[0],x[1],x[2])], axis = 1) 40 analysis.head()
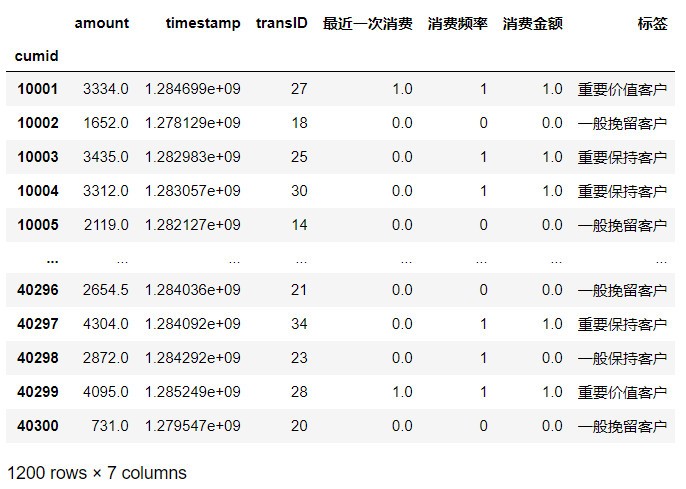
1 # 客戶標簽合并到資料集rfm 2 result = pd.merge(rfm, analysis, on='cumid') 3 result
客戶資料可視化
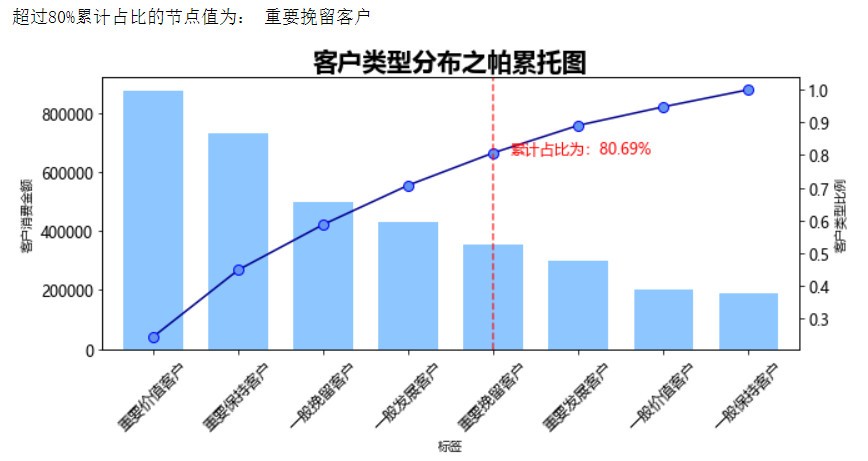
帕累托分析(貢獻度分析) → 帕累托法則:20/80定律,
從帕累托圖看客戶群體的消費金額構成,該公司消費總金額最多的客戶型別屬于 ”重要價值客戶“, 其次是“重要保持客戶”,前5種客戶型別累計消費金額總和超過80.69%,是公司主要客戶群,
值得注意的是排名第三的消費來自“一般挽留客戶”,
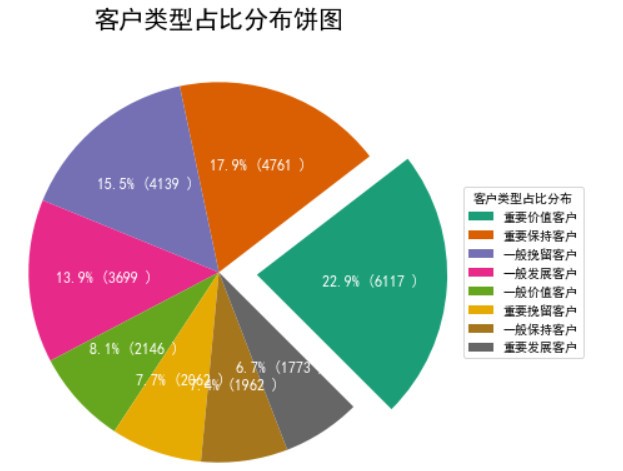
從餅圖看銷售頻率百分比和次數,毫無疑問, ”重要價值客戶“ 型別仍然名列前茅,共占22.9%,其次是“重要保持客戶”占了17.9%,前4名排列不論消費金額還是消費頻率都是一樣,從第5名后才不同,
1 import matplotlib.pyplot as plt 2 3 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] # 這里設定字體,防止中文亂碼 4 plt.rcParams['axes.unicode_minus']=False # #表示可以正常顯示正負號 5 6 ## 帕累托分布分析 7 # 資料的分組以及分組后的組內運算 8 data = https://www.cnblogs.com/fuyudata/p/result.groupby(['標簽'])[['amount']].sum() 9 data = https://www.cnblogs.com/fuyudata/p/data['amount'].copy() 10 11 # 由大到小排列 12 data.sort_values(ascending=False, inplace= True) 13 14 # 創建柱狀圖 15 plt.figure(figsize = (10,4)) 16 data.plot(kind = 'bar', color = 'dodgerblue', alpha = 0.5, width = 0.7) 17 plt.ylabel('客戶消費金額') 18 19 p = data.cumsum()/data.sum() # 創建累計占比 Series 20 key = p[p>0.8].index[0] 21 key_num = data.index.tolist().index(key) 22 print('超過80%累計占比的節點值為:' ,key) # 找到累計占比超過80%時候的index 23 24 p.plot(style = "-", marker="o", markersize=8, markeredgecolor="blue", markeredgewidth=1, 25 markerfacecolor="cornflowerblue", color = 'darkblue', rot = 45, fontsize = 12, secondary_y=True) 26 27 plt.axvline(key_num,color='r',linestyle="--",alpha=0.7) 28 plt.text(key_num+0.2,p[key],'累計占比為:%.2f%%' % (p[key]*100), fontsize = 12, color = 'r') # 累計占比超過80%的節點 29 plt.ylabel('客戶型別比例') 30 plt.title('客戶型別分布之帕累托圖', fontsize=20, fontweight = 'semibold') 31 32 plt.show() # 繪制客戶型別的帕累托累積頻率圖
1 # 對不同客戶型別消費頻率進行占比分析 2 df = result.groupby(['標簽'])[['transID']].sum().reset_index() 3 df.sort_values(by='transID',ascending=False, inplace= True) 4 # df 5 6 # 畫圖 7 fig, ax = plt.subplots(figsize=(12,7), subplot_kw=dict(aspect="equal")) 8 data = https://www.cnblogs.com/fuyudata/p/df['transID'] 9 categories = df['標簽'] 10 explode = [0.2,0,0,0,0,0,0,0] 11 12 def func(pct, allvals): 13 absolute = int(pct/100.*np.sum(allvals)) 14 return "{:.1f}% ({:d} )".format(pct, absolute) 15 16 wedges, texts, autotexts = ax.pie(data, 17 autopct=lambda pct: func(pct, data), 18 textprops=dict(color="w"), 19 colors=plt.cm.Dark2.colors, 20 startangle=-45,# 起始角度從排序第一開始 21 explode=explode) 22 23 # Decoration 24 ax.legend(wedges, categories, title="客戶型別占比分布", loc="center left", bbox_to_anchor=(1, 0, 0.5, 1)) 25 plt.setp(autotexts, size=12, weight=800) 26 ax.set_title("客戶型別占比分布餅圖", fontsize=20, fontweight = 'semibold') 27 plt.show()
客戶營銷策略
資料分析表明最重要的客戶,也就是該企業利潤源泉是重要價值客戶和重要保持客戶
| 客戶型別 | 用戶特征 | 營銷策略 |
| 重要價值客戶 | 最近買過,經常消費,消費金額高 | 重點傾斜更多資源,提供VIP個性化服務,增加更高的消費附加值, |
| 重要發展客戶 | 最近有購買,消費多,但是消費頻率不高 | 郵件電話營銷了解需求,提供積分兌換,推薦其他產品爭取, |
| 重要保持客戶 | 消費多次,消費多,但是最近一段沒有來購買 | 郵件電話營銷拜訪,通過贈送小禮物,更新產品和服務積極喚醒客戶, |
| 重要挽留客戶 | 消費金額不少,但是消費次數不多,而且也一段時間沒來購買 | 郵件電話營銷調查了解客戶真實需求,提高留存率, |
| 一般價值客戶 | 消費多次,最近也常來,但是消費金額不高, | 這型別客戶可能經濟能力有限,但是也是企業利潤的一環,可以提供一些低價促銷的活動來保持, |
| 一般發展客戶 | 最近消費過,但是消費次數不多,消費金額也不高 |
這型別客戶可能是新客戶,未來還可能有潛力發展成重要客戶,不可忽視,可以采用微信公眾號或者會員郵件短信提醒進行營銷,讓這部分客戶活躍起來,組織會員線上線下活動來提高品牌美譽度, |
| 一般保持客戶 | 之前消費次數不少,但消費金額不高,且最近沒來 | 這型別客戶可能經濟能力有限,可以提供一些會員制促銷的產品來保持, |
| 一般挽留客戶 | 來消費次數不多,消費金額不高,且最近也沒來 |
此類客戶指標三低,一般定義是流失客戶,但從資料分析看這是排名第三的銷售金額和消費頻率,可能是過路客,這種情況下就應該廣泛撒網提高曝光率,發發小廣告,至少保持一定的流動率下至少不減少,可以考慮用一些省錢的營銷方式, |
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/30852.html
標籤:Python